Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
- Type I & Type II Errors | Differences, Examples, Visualizations

Type I & Type II Errors | Differences, Examples, Visualizations
Published on January 18, 2021 by Pritha Bhandari . Revised on June 22, 2023.
In statistics , a Type I error is a false positive conclusion, while a Type II error is a false negative conclusion.
Making a statistical decision always involves uncertainties, so the risks of making these errors are unavoidable in hypothesis testing .
The probability of making a Type I error is the significance level , or alpha (α), while the probability of making a Type II error is beta (β). These risks can be minimized through careful planning in your study design.
- Type I error (false positive) : the test result says you have coronavirus, but you actually don’t.
- Type II error (false negative) : the test result says you don’t have coronavirus, but you actually do.
Table of contents
Error in statistical decision-making, type i error, type ii error, trade-off between type i and type ii errors, is a type i or type ii error worse, other interesting articles, frequently asked questions about type i and ii errors.
Using hypothesis testing, you can make decisions about whether your data support or refute your research predictions with null and alternative hypotheses .
Hypothesis testing starts with the assumption of no difference between groups or no relationship between variables in the population—this is the null hypothesis . It’s always paired with an alternative hypothesis , which is your research prediction of an actual difference between groups or a true relationship between variables .
In this case:
- The null hypothesis (H 0 ) is that the new drug has no effect on symptoms of the disease.
- The alternative hypothesis (H 1 ) is that the drug is effective for alleviating symptoms of the disease.
Then , you decide whether the null hypothesis can be rejected based on your data and the results of a statistical test . Since these decisions are based on probabilities, there is always a risk of making the wrong conclusion.
- If your results show statistical significance , that means they are very unlikely to occur if the null hypothesis is true. In this case, you would reject your null hypothesis. But sometimes, this may actually be a Type I error.
- If your findings do not show statistical significance, they have a high chance of occurring if the null hypothesis is true. Therefore, you fail to reject your null hypothesis. But sometimes, this may be a Type II error.

Receive feedback on language, structure, and formatting
Professional editors proofread and edit your paper by focusing on:
- Academic style
- Vague sentences
- Style consistency
See an example

A Type I error means rejecting the null hypothesis when it’s actually true. It means concluding that results are statistically significant when, in reality, they came about purely by chance or because of unrelated factors.
The risk of committing this error is the significance level (alpha or α) you choose. That’s a value that you set at the beginning of your study to assess the statistical probability of obtaining your results ( p value).
The significance level is usually set at 0.05 or 5%. This means that your results only have a 5% chance of occurring, or less, if the null hypothesis is actually true.
If the p value of your test is lower than the significance level, it means your results are statistically significant and consistent with the alternative hypothesis. If your p value is higher than the significance level, then your results are considered statistically non-significant.
To reduce the Type I error probability, you can simply set a lower significance level.
Type I error rate
The null hypothesis distribution curve below shows the probabilities of obtaining all possible results if the study were repeated with new samples and the null hypothesis were true in the population .
At the tail end, the shaded area represents alpha. It’s also called a critical region in statistics.
If your results fall in the critical region of this curve, they are considered statistically significant and the null hypothesis is rejected. However, this is a false positive conclusion, because the null hypothesis is actually true in this case!

A Type II error means not rejecting the null hypothesis when it’s actually false. This is not quite the same as “accepting” the null hypothesis, because hypothesis testing can only tell you whether to reject the null hypothesis.
Instead, a Type II error means failing to conclude there was an effect when there actually was. In reality, your study may not have had enough statistical power to detect an effect of a certain size.
Power is the extent to which a test can correctly detect a real effect when there is one. A power level of 80% or higher is usually considered acceptable.
The risk of a Type II error is inversely related to the statistical power of a study. The higher the statistical power, the lower the probability of making a Type II error.
Statistical power is determined by:
- Size of the effect : Larger effects are more easily detected.
- Measurement error : Systematic and random errors in recorded data reduce power.
- Sample size : Larger samples reduce sampling error and increase power.
- Significance level : Increasing the significance level increases power.
To (indirectly) reduce the risk of a Type II error, you can increase the sample size or the significance level.
Type II error rate
The alternative hypothesis distribution curve below shows the probabilities of obtaining all possible results if the study were repeated with new samples and the alternative hypothesis were true in the population .
The Type II error rate is beta (β), represented by the shaded area on the left side. The remaining area under the curve represents statistical power, which is 1 – β.
Increasing the statistical power of your test directly decreases the risk of making a Type II error.

The Type I and Type II error rates influence each other. That’s because the significance level (the Type I error rate) affects statistical power, which is inversely related to the Type II error rate.
This means there’s an important tradeoff between Type I and Type II errors:
- Setting a lower significance level decreases a Type I error risk, but increases a Type II error risk.
- Increasing the power of a test decreases a Type II error risk, but increases a Type I error risk.
This trade-off is visualized in the graph below. It shows two curves:
- The null hypothesis distribution shows all possible results you’d obtain if the null hypothesis is true. The correct conclusion for any point on this distribution means not rejecting the null hypothesis.
- The alternative hypothesis distribution shows all possible results you’d obtain if the alternative hypothesis is true. The correct conclusion for any point on this distribution means rejecting the null hypothesis.
Type I and Type II errors occur where these two distributions overlap. The blue shaded area represents alpha, the Type I error rate, and the green shaded area represents beta, the Type II error rate.
By setting the Type I error rate, you indirectly influence the size of the Type II error rate as well.

It’s important to strike a balance between the risks of making Type I and Type II errors. Reducing the alpha always comes at the cost of increasing beta, and vice versa .
Here's why students love Scribbr's proofreading services
Discover proofreading & editing
For statisticians, a Type I error is usually worse. In practical terms, however, either type of error could be worse depending on your research context.
A Type I error means mistakenly going against the main statistical assumption of a null hypothesis. This may lead to new policies, practices or treatments that are inadequate or a waste of resources.
In contrast, a Type II error means failing to reject a null hypothesis. It may only result in missed opportunities to innovate, but these can also have important practical consequences.
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Normal distribution
- Descriptive statistics
- Measures of central tendency
- Correlation coefficient
- Null hypothesis
Methodology
- Cluster sampling
- Stratified sampling
- Types of interviews
- Cohort study
- Thematic analysis
Research bias
- Implicit bias
- Cognitive bias
- Survivorship bias
- Availability heuristic
- Nonresponse bias
- Regression to the mean
In statistics, a Type I error means rejecting the null hypothesis when it’s actually true, while a Type II error means failing to reject the null hypothesis when it’s actually false.
The risk of making a Type I error is the significance level (or alpha) that you choose. That’s a value that you set at the beginning of your study to assess the statistical probability of obtaining your results ( p value ).
To reduce the Type I error probability, you can set a lower significance level.
The risk of making a Type II error is inversely related to the statistical power of a test. Power is the extent to which a test can correctly detect a real effect when there is one.
To (indirectly) reduce the risk of a Type II error, you can increase the sample size or the significance level to increase statistical power.
Statistical significance is a term used by researchers to state that it is unlikely their observations could have occurred under the null hypothesis of a statistical test . Significance is usually denoted by a p -value , or probability value.
Statistical significance is arbitrary – it depends on the threshold, or alpha value, chosen by the researcher. The most common threshold is p < 0.05, which means that the data is likely to occur less than 5% of the time under the null hypothesis .
When the p -value falls below the chosen alpha value, then we say the result of the test is statistically significant.
In statistics, power refers to the likelihood of a hypothesis test detecting a true effect if there is one. A statistically powerful test is more likely to reject a false negative (a Type II error).
If you don’t ensure enough power in your study, you may not be able to detect a statistically significant result even when it has practical significance. Your study might not have the ability to answer your research question.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Bhandari, P. (2023, June 22). Type I & Type II Errors | Differences, Examples, Visualizations. Scribbr. Retrieved July 27, 2024, from https://www.scribbr.com/statistics/type-i-and-type-ii-errors/
Is this article helpful?

Pritha Bhandari
Other students also liked, an easy introduction to statistical significance (with examples), understanding p values | definition and examples, statistical power and why it matters | a simple introduction, what is your plagiarism score.
Type 1 and Type 2 Errors in Statistics
Saul Mcleod, PhD
Editor-in-Chief for Simply Psychology
BSc (Hons) Psychology, MRes, PhD, University of Manchester
Saul Mcleod, PhD., is a qualified psychology teacher with over 18 years of experience in further and higher education. He has been published in peer-reviewed journals, including the Journal of Clinical Psychology.
Learn about our Editorial Process
On This Page:
A statistically significant result cannot prove that a research hypothesis is correct (which implies 100% certainty). Because a p -value is based on probabilities, there is always a chance of making an incorrect conclusion regarding accepting or rejecting the null hypothesis ( H 0 ).
Anytime we make a decision using statistics, there are four possible outcomes, with two representing correct decisions and two representing errors.

The chances of committing these two types of errors are inversely proportional: that is, decreasing type I error rate increases type II error rate and vice versa.
As the significance level (α) increases, it becomes easier to reject the null hypothesis, decreasing the chance of missing a real effect (Type II error, β). If the significance level (α) goes down, it becomes harder to reject the null hypothesis , increasing the chance of missing an effect while reducing the risk of falsely finding one (Type I error).
Type I error
A type 1 error is also known as a false positive and occurs when a researcher incorrectly rejects a true null hypothesis. Simply put, it’s a false alarm.
This means that you report that your findings are significant when they have occurred by chance.
The probability of making a type 1 error is represented by your alpha level (α), the p- value below which you reject the null hypothesis.
A p -value of 0.05 indicates that you are willing to accept a 5% chance of getting the observed data (or something more extreme) when the null hypothesis is true.
You can reduce your risk of committing a type 1 error by setting a lower alpha level (like α = 0.01). For example, a p-value of 0.01 would mean there is a 1% chance of committing a Type I error.
However, using a lower value for alpha means that you will be less likely to detect a true difference if one really exists (thus risking a type II error).
Scenario: Drug Efficacy Study
Imagine a pharmaceutical company is testing a new drug, named “MediCure”, to determine if it’s more effective than a placebo at reducing fever. They experimented with two groups: one receives MediCure, and the other received a placebo.
- Null Hypothesis (H0) : MediCure is no more effective at reducing fever than the placebo.
- Alternative Hypothesis (H1) : MediCure is more effective at reducing fever than the placebo.
After conducting the study and analyzing the results, the researchers found a p-value of 0.04.
If they use an alpha (α) level of 0.05, this p-value is considered statistically significant, leading them to reject the null hypothesis and conclude that MediCure is more effective than the placebo.
However, MediCure has no actual effect, and the observed difference was due to random variation or some other confounding factor. In this case, the researchers have incorrectly rejected a true null hypothesis.
Error : The researchers have made a Type 1 error by concluding that MediCure is more effective when it isn’t.
Implications
Resource Allocation : Making a Type I error can lead to wastage of resources. If a business believes a new strategy is effective when it’s not (based on a Type I error), they might allocate significant financial and human resources toward that ineffective strategy.
Unnecessary Interventions : In medical trials, a Type I error might lead to the belief that a new treatment is effective when it isn’t. As a result, patients might undergo unnecessary treatments, risking potential side effects without any benefit.
Reputation and Credibility : For researchers, making repeated Type I errors can harm their professional reputation. If they frequently claim groundbreaking results that are later refuted, their credibility in the scientific community might diminish.
Type II error
A type 2 error (or false negative) happens when you accept the null hypothesis when it should actually be rejected.
Here, a researcher concludes there is not a significant effect when actually there really is.
The probability of making a type II error is called Beta (β), which is related to the power of the statistical test (power = 1- β). You can decrease your risk of committing a type II error by ensuring your test has enough power.
You can do this by ensuring your sample size is large enough to detect a practical difference when one truly exists.
Scenario: Efficacy of a New Teaching Method
Educational psychologists are investigating the potential benefits of a new interactive teaching method, named “EduInteract”, which utilizes virtual reality (VR) technology to teach history to middle school students.
They hypothesize that this method will lead to better retention and understanding compared to the traditional textbook-based approach.
- Null Hypothesis (H0) : The EduInteract VR teaching method does not result in significantly better retention and understanding of history content than the traditional textbook method.
- Alternative Hypothesis (H1) : The EduInteract VR teaching method results in significantly better retention and understanding of history content than the traditional textbook method.
The researchers designed an experiment where one group of students learns a history module using the EduInteract VR method, while a control group learns the same module using a traditional textbook.
After a week, the student’s retention and understanding are tested using a standardized assessment.
Upon analyzing the results, the psychologists found a p-value of 0.06. Using an alpha (α) level of 0.05, this p-value isn’t statistically significant.
Therefore, they fail to reject the null hypothesis and conclude that the EduInteract VR method isn’t more effective than the traditional textbook approach.
However, let’s assume that in the real world, the EduInteract VR truly enhances retention and understanding, but the study failed to detect this benefit due to reasons like small sample size, variability in students’ prior knowledge, or perhaps the assessment wasn’t sensitive enough to detect the nuances of VR-based learning.
Error : By concluding that the EduInteract VR method isn’t more effective than the traditional method when it is, the researchers have made a Type 2 error.
This could prevent schools from adopting a potentially superior teaching method that might benefit students’ learning experiences.
Missed Opportunities : A Type II error can lead to missed opportunities for improvement or innovation. For example, in education, if a more effective teaching method is overlooked because of a Type II error, students might miss out on a better learning experience.
Potential Risks : In healthcare, a Type II error might mean overlooking a harmful side effect of a medication because the research didn’t detect its harmful impacts. As a result, patients might continue using a harmful treatment.
Stagnation : In the business world, making a Type II error can result in continued investment in outdated or less efficient methods. This can lead to stagnation and the inability to compete effectively in the marketplace.
How do Type I and Type II errors relate to psychological research and experiments?
Type I errors are like false alarms, while Type II errors are like missed opportunities. Both errors can impact the validity and reliability of psychological findings, so researchers strive to minimize them to draw accurate conclusions from their studies.
How does sample size influence the likelihood of Type I and Type II errors in psychological research?
Sample size in psychological research influences the likelihood of Type I and Type II errors. A larger sample size reduces the chances of Type I errors, which means researchers are less likely to mistakenly find a significant effect when there isn’t one.
A larger sample size also increases the chances of detecting true effects, reducing the likelihood of Type II errors.
Are there any ethical implications associated with Type I and Type II errors in psychological research?
Yes, there are ethical implications associated with Type I and Type II errors in psychological research.
Type I errors may lead to false positive findings, resulting in misleading conclusions and potentially wasting resources on ineffective interventions. This can harm individuals who are falsely diagnosed or receive unnecessary treatments.
Type II errors, on the other hand, may result in missed opportunities to identify important effects or relationships, leading to a lack of appropriate interventions or support. This can also have negative consequences for individuals who genuinely require assistance.
Therefore, minimizing these errors is crucial for ethical research and ensuring the well-being of participants.
Further Information
- Publication manual of the American Psychological Association
- Statistics for Psychology Book Download
- Skip to secondary menu
- Skip to main content
- Skip to primary sidebar
Statistics By Jim
Making statistics intuitive
Types I & Type II Errors in Hypothesis Testing
By Jim Frost 8 Comments
In hypothesis testing, a Type I error is a false positive while a Type II error is a false negative. In this blog post, you will learn about these two types of errors, their causes, and how to manage them.
Hypothesis tests use sample data to make inferences about the properties of a population . You gain tremendous benefits by working with random samples because it is usually impossible to measure the entire population.
However, there are tradeoffs when you use samples. The samples we use are typically a minuscule percentage of the entire population. Consequently, they occasionally misrepresent the population severely enough to cause hypothesis tests to make Type I and Type II errors.
Potential Outcomes in Hypothesis Testing
Hypothesis testing is a procedure in inferential statistics that assesses two mutually exclusive theories about the properties of a population. For a generic hypothesis test, the two hypotheses are as follows:
- Null hypothesis : There is no effect
- Alternative hypothesis : There is an effect.
The sample data must provide sufficient evidence to reject the null hypothesis and conclude that the effect exists in the population. Ideally, a hypothesis test fails to reject the null hypothesis when the effect is not present in the population, and it rejects the null hypothesis when the effect exists.
Statisticians define two types of errors in hypothesis testing. Creatively, they call these errors Type I and Type II errors. Both types of error relate to incorrect conclusions about the null hypothesis.
The table summarizes the four possible outcomes for a hypothesis test.
|
|
| |
|
|
|
Related post : How Hypothesis Tests Work: P-values and the Significance Level
Fire alarm analogy for the types of errors

Using hypothesis tests correctly improves your chances of drawing trustworthy conclusions. However, errors are bound to occur.
Unlike the fire alarm analogy, there is no sure way to determine whether an error occurred after you perform a hypothesis test. Typically, a clearer picture develops over time as other researchers conduct similar studies and an overall pattern of results appears. Seeing how your results fit in with similar studies is a crucial step in assessing your study’s findings.
Now, let’s take a look at each type of error in more depth.
Type I Error: False Positives
When you see a p-value that is less than your significance level , you get excited because your results are statistically significant. However, it could be a type I error . The supposed effect might not exist in the population. Again, there is usually no warning when this occurs.
Why do these errors occur? It comes down to sample error. Your random sample has overestimated the effect by chance. It was the luck of the draw. This type of error doesn’t indicate that the researchers did anything wrong. The experimental design, data collection, data validity , and statistical analysis can all be correct, and yet this type of error still occurs.
Even though we don’t know for sure which studies have false positive results, we do know their rate of occurrence. The rate of occurrence for Type I errors equals the significance level of the hypothesis test, which is also known as alpha (α).
The significance level is an evidentiary standard that you set to determine whether your sample data are strong enough to reject the null hypothesis. Hypothesis tests define that standard using the probability of rejecting a null hypothesis that is actually true. You set this value based on your willingness to risk a false positive.
Related post : How to Interpret P-values Correctly
Using the significance level to set the Type I error rate
When the significance level is 0.05 and the null hypothesis is true, there is a 5% chance that the test will reject the null hypothesis incorrectly. If you set alpha to 0.01, there is a 1% of a false positive. If 5% is good, then 1% seems even better, right? As you’ll see, there is a tradeoff between Type I and Type II errors. If you hold everything else constant, as you reduce the chance for a false positive, you increase the opportunity for a false negative.
Type I errors are relatively straightforward. The math is beyond the scope of this article, but statisticians designed hypothesis tests to incorporate everything that affects this error rate so that you can specify it for your studies. As long as your experimental design is sound, you collect valid data, and the data satisfy the assumptions of the hypothesis test, the Type I error rate equals the significance level that you specify. However, if there is a problem in one of those areas, it can affect the false positive rate.
Warning about a potential misinterpretation of Type I errors and the Significance Level
When the null hypothesis is correct for the population, the probability that a test produces a false positive equals the significance level. However, when you look at a statistically significant test result, you cannot state that there is a 5% chance that it represents a false positive.
Why is that the case? Imagine that we perform 100 studies on a population where the null hypothesis is true. If we use a significance level of 0.05, we’d expect that five of the studies will produce statistically significant results—false positives. Afterward, when we go to look at those significant studies, what is the probability that each one is a false positive? Not 5 percent but 100%!
That scenario also illustrates a point that I made earlier. The true picture becomes more evident after repeated experimentation. Given the pattern of results that are predominantly not significant, it is unlikely that an effect exists in the population.
Type II Error: False Negatives
When you perform a hypothesis test and your p-value is greater than your significance level, your results are not statistically significant. That’s disappointing because your sample provides insufficient evidence for concluding that the effect you’re studying exists in the population. However, there is a chance that the effect is present in the population even though the test results don’t support it. If that’s the case, you’ve just experienced a Type II error . The probability of making a Type II error is known as beta (β).
What causes Type II errors? Whereas Type I errors are caused by one thing, sample error, there are a host of possible reasons for Type II errors—small effect sizes, small sample sizes, and high data variability. Furthermore, unlike Type I errors, you can’t set the Type II error rate for your analysis. Instead, the best that you can do is estimate it before you begin your study by approximating properties of the alternative hypothesis that you’re studying. When you do this type of estimation, it’s called power analysis.
To estimate the Type II error rate, you create a hypothetical probability distribution that represents the properties of a true alternative hypothesis. However, when you’re performing a hypothesis test, you typically don’t know which hypothesis is true, much less the specific properties of the distribution for the alternative hypothesis. Consequently, the true Type II error rate is usually unknown!
Type II errors and the power of the analysis
The Type II error rate (beta) is the probability of a false negative. Therefore, the inverse of Type II errors is the probability of correctly detecting an effect. Statisticians refer to this concept as the power of a hypothesis test. Consequently, 1 – β = the statistical power. Analysts typically estimate power rather than beta directly.
If you read my post about power and sample size analysis , you know that the three factors that affect power are sample size, variability in the population, and the effect size. As you design your experiment, you can enter estimates of these three factors into statistical software and it calculates the estimated power for your test.
Suppose you perform a power analysis for an upcoming study and calculate an estimated power of 90%. For this study, the estimated Type II error rate is 10% (1 – 0.9). Keep in mind that variability and effect size are based on estimates and guesses. Consequently, power and the Type II error rate are just estimates rather than something you set directly. These estimates are only as good as the inputs into your power analysis.
Low variability and larger effect sizes decrease the Type II error rate, which increases the statistical power. However, researchers usually have less control over those aspects of a hypothesis test. Typically, researchers have the most control over sample size, making it the critical way to manage your Type II error rate. Holding everything else constant, increasing the sample size reduces the Type II error rate and increases power.
Learn more about Power in Statistics .
Graphing Type I and Type II Errors
The graph below illustrates the two types of errors using two sampling distributions. The critical region line represents the point at which you reject or fail to reject the null hypothesis. Of course, when you perform the hypothesis test, you don’t know which hypothesis is correct. And, the properties of the distribution for the alternative hypothesis are usually unknown. However, use this graph to understand the general nature of these errors and how they are related.

The distribution on the left represents the null hypothesis. If the null hypothesis is true, you only need to worry about Type I errors, which is the shaded portion of the null hypothesis distribution. The rest of the null distribution represents the correct decision of failing to reject the null.
On the other hand, if the alternative hypothesis is true, you need to worry about Type II errors. The shaded region on the alternative hypothesis distribution represents the Type II error rate. The rest of the alternative distribution represents the probability of correctly detecting an effect—power.
Moving the critical value line is equivalent to changing the significance level. If you move the line to the left, you’re increasing the significance level (e.g., α 0.05 to 0.10). Holding everything else constant, this adjustment increases the Type I error rate while reducing the Type II error rate. Moving the line to the right reduces the significance level (e.g., α 0.05 to 0.01), which decreases the Type I error rate but increases the type II error rate.
Is One Error Worse Than the Other?
As you’ve seen, the nature of the two types of error, their causes, and the certainty of their rates of occurrence are all very different.
A common question is whether one type of error is worse than the other? Statisticians designed hypothesis tests to control Type I errors while Type II errors are much less defined. Consequently, many statisticians state that it is better to fail to detect an effect when it exists than it is to conclude an effect exists when it doesn’t. That is to say, there is a tendency to assume that Type I errors are worse.
However, reality is more complex than that. You should carefully consider the consequences of each type of error for your specific test.
Suppose you are assessing the strength of a new jet engine part that is under consideration. Peoples lives are riding on the part’s strength. A false negative in this scenario merely means that the part is strong enough but the test fails to detect it. This situation does not put anyone’s life at risk. On the other hand, Type I errors are worse in this situation because they indicate the part is strong enough when it is not.
Now suppose that the jet engine part is already in use but there are concerns about it failing. In this case, you want the test to be more sensitive to detecting problems even at the risk of false positives. Type II errors are worse in this scenario because the test fails to recognize the problem and leaves these problematic parts in use for longer.
Using hypothesis tests effectively requires that you understand their error rates. By setting the significance level and estimating your test’s power, you can manage both error rates so they meet your requirements.
The error rates in this post are all for individual tests. If you need to perform multiple comparisons, such as comparing group means in ANOVA, you’ll need to use post hoc tests to control the experiment-wise error rate or use the Bonferroni correction .
Share this:

Reader Interactions

June 4, 2024 at 2:04 pm
Very informative.

June 9, 2023 at 9:54 am
Hi Jim- I just signed up for your newsletter and this is my first question to you. I am not a statistician but work with them in my professional life as a QC consultant in biopharmaceutical development. I have a question about Type I and Type II errors in the realm of equivalence testing using two one sided difference testing (TOST). In a recent 2020 publication that I co-authored with a statistician, we stated that the probability of concluding non-equivalence when that is the truth, (which is the opposite of power, the probability of concluding equivalence when it is correct) is 1-2*alpha. This made sense to me because one uses a 90% confidence interval on a mean to evaluate whether the result is within established equivalence bounds with an alpha set to 0.05. However, it appears that specificity (1-alpha) is always the case as is power always being 1-beta. For equivalence testing the latter is 1-2*beta/2 but for specificity it stays as 1-alpha because only one of the null hypotheses in a two-sided test can fail at one time. I still see 1-2*alpha as making more sense as we show in Figure 3 of our paper which shows the white space under the distribution of the alternative hypothesis as 1-2 alpha. The paper can be downloaded as open access here if that would make my question more clear. https://bioprocessingjournal.com/index.php/article-downloads/890-vol-19-open-access-2020-defining-therapeutic-window-for-viral-vectors-a-statistical-framework-to-improve-consistency-in-assigning-product-dose-values I have consulted with other statistical colleagues and cannot get consensus so I would love your opinion and explanation! Thanks in advance!

June 10, 2023 at 1:00 am
Let me preface my response by saying that I’m not an expert in equivalence testing. But here’s my best guess about your question.
The alpha is for each of the hypothesis tests. Each one has a type I error rate of 0.05. Or, as you say, a specificity of 1-alpha. However, there are two tests so we need to consider the family-wise error rate. The formula is the following:
FWER = 1 – (1 – α)^N
Where N is the number of hypothesis tests.
For two tests, there’s a family-wise error rate of 0.0975. Or a family-wise specificity of 0.9025.
However, I believe they use 90% CI for a different reason (although it’s a very close match to the family-wise error rate). The 90% CI provides consistent results with the two one-side 95% tests. In other words, if the 90% CI is within the equivalency bounds, then the two tests will be significant. If the CI extends above the upper bound, the corresponding test won’t be significant. Etc.
However, using either rational, I’d say the overall type I error rate is about 0.1.
I hope that answers your question. And, again, I’m not an expert in this particular test.

July 18, 2022 at 5:15 am
Thank you for your valuable content. I have a question regarding correcting for multiple tests. My question is: for exactly how many tests should I correct in the scenario below?
Background: I’m testing for differences between groups A (patient group) and B (control group) in variable X. Variable X is a biological variable present in the body’s left and right side. Variable Y is a questionnaire for group A.
Step 1. Is there a significant difference within groups in the weight of left and right variable X? (I will conduct two paired sample t-tests)
If I find a significant difference in step 1, then I will conduct steps 2A and 2B. However, if I don’t find a significant difference in step 1, then I will only conduct step 2C.
Step 2A. Is there a significant difference between groups in left variable X? (I will conduct one independent sample t-test) Step 2B. Is there a significant difference between groups in right variable X? (I will conduct one independent sample t-test)
Step 2C. Is there a significant difference between groups in total variable X (left + right variable X)? (I will conduct one independent sample t-test)
If I find a significant difference in step 1, then I will conduct with steps 3A and 3B. However, if I don’t find a significant difference in step 1, then I will only conduct step 3C.
Step 3A. Is there a significant correlation between left variable X in group A and variable Y? (I will conduct Pearson correlation) Step 3B. Is there a significant correlation between right variable X in group A and variable Y? (I will conduct Pearson correlation)
Step 3C. Is there a significant correlation between total variable X in group A and variable Y? (I will conduct a Pearson correlation)
Regards, De

January 2, 2021 at 1:57 pm
I should say that being a budding statistician, this site seems to be pretty reliable. I have few doubts in here. It would be great if you can clarify it:
“A significance level of 0.05 indicates a 5% risk of concluding that a difference exists when there is no actual difference. ”
My understanding : When we say that the significance level is 0.05 then it means we are taking 5% risk to support alternate hypothesis even though there is no difference ?( I think i am not allowed to say Null is true, because null is assumed to be true/ Right)
January 2, 2021 at 6:48 pm
The sentence as I write it is correct. Here’s a simple way to understand it. Imagine you’re conducting a computer simulation where you control the population parameters and have the computer draw random samples from the populations that you define. Now, imagine you draw samples from two populations where the means and standard deviations are equal. You know this for a fact because you set the parameters yourself. Then you conduct a series of 2-sample t-tests.
In this example, you know the null hypothesis is correct. However, thanks to random sampling error, some proportion of the t-tests will have statistically significant results (i.e., false positives or Type I errors). The proportion of false positives will equal your significance level over the long run.
Of course, in real-world experiments, you never know for sure whether the null is true or not. However, given the properties of the hypothesis, you do know what proportion of tests will give you a false positive IF the null is true–and that’s the significance level.
I’m thinking through the wording of how you wrote it and I believe it is equivalent to what I wrote. If there is no difference (the null is true), then you have a 5% chance of incorrectly supporting the alternative. And, again, you’re correct that in the real world you don’t know for sure whether the null is true. But, you can still know the false positive (Type I) error rate. For more information about that property, read my post about how hypothesis tests work .

July 9, 2018 at 11:43 am
I like to use the analogy of a trial. The null hypothesis is that the defendant is innocent. A type I error would be convicting an innocent person and a type II error would be acquitting a guilty one. I like to think that our system makes a type I error very unlikely with the trade off being that a type II error is greater.
July 9, 2018 at 12:03 pm
Hi Doug, I think that is an excellent analogy on multiple levels. As you mention, a trial would set a high bar for the significance level by choosing a very low value for alpha. This helps prevent innocent people from being convicted (Type I error) but does increase the probability of allowing the guilty to go free (Type II error). I often refer to the significant level as a evidentiary standard with this legalistic analogy in mind.
Additionally, in the justice system in the U.S., there is a presumption of innocence and the prosecutor must present sufficient evidence to prove that the defendant is guilty. That’s just like in a hypothesis test where the assumption is that the null hypothesis is true and your sample must contain sufficient evidence to be able to reject the null hypothesis and suggest that the effect exists in the population.
This analogy even works for the similarities behind the phrases “Not guilty” and “Fail to reject the null hypothesis.” In both cases, you aren’t proving innocence or that the null hypothesis is true. When a defendant is “not guilty” it might be that the evidence was insufficient to convince the jury. In a hypothesis test, when you fail to reject the null hypothesis, it’s possible that an effect exists in the population but you have insufficient evidence to detect it. Perhaps the effect exists but the sample size or effect size is too small, or the variability might be too high.
Comments and Questions Cancel reply
Have a thesis expert improve your writing
Check your thesis for plagiarism in 10 minutes, generate your apa citations for free.
- Knowledge Base
- Type I & Type II Errors | Differences, Examples, Visualizations
Type I & Type II Errors | Differences, Examples, Visualizations
Published on 18 January 2021 by Pritha Bhandari . Revised on 2 February 2023.
In statistics , a Type I error is a false positive conclusion, while a Type II error is a false negative conclusion.
Making a statistical decision always involves uncertainties, so the risks of making these errors are unavoidable in hypothesis testing .
The probability of making a Type I error is the significance level , or alpha (α), while the probability of making a Type II error is beta (β). These risks can be minimized through careful planning in your study design.
- Type I error (false positive) : the test result says you have coronavirus, but you actually don’t.
- Type II error (false negative) : the test result says you don’t have coronavirus, but you actually do.
Table of contents
Error in statistical decision-making, type i error, type ii error, trade-off between type i and type ii errors, is a type i or type ii error worse, frequently asked questions about type i and ii errors.
Using hypothesis testing, you can make decisions about whether your data support or refute your research predictions with null and alternative hypotheses .
Hypothesis testing starts with the assumption of no difference between groups or no relationship between variables in the population—this is the null hypothesis . It’s always paired with an alternative hypothesis , which is your research prediction of an actual difference between groups or a true relationship between variables .
In this case:
- The null hypothesis (H 0 ) is that the new drug has no effect on symptoms of the disease.
- The alternative hypothesis (H 1 ) is that the drug is effective for alleviating symptoms of the disease.
Then , you decide whether the null hypothesis can be rejected based on your data and the results of a statistical test . Since these decisions are based on probabilities, there is always a risk of making the wrong conclusion.
- If your results show statistical significance , that means they are very unlikely to occur if the null hypothesis is true. In this case, you would reject your null hypothesis. But sometimes, this may actually be a Type I error.
- If your findings do not show statistical significance, they have a high chance of occurring if the null hypothesis is true. Therefore, you fail to reject your null hypothesis. But sometimes, this may be a Type II error.

A Type I error means rejecting the null hypothesis when it’s actually true. It means concluding that results are statistically significant when, in reality, they came about purely by chance or because of unrelated factors.
The risk of committing this error is the significance level (alpha or α) you choose. That’s a value that you set at the beginning of your study to assess the statistical probability of obtaining your results ( p value).
The significance level is usually set at 0.05 or 5%. This means that your results only have a 5% chance of occurring, or less, if the null hypothesis is actually true.
If the p value of your test is lower than the significance level, it means your results are statistically significant and consistent with the alternative hypothesis. If your p value is higher than the significance level, then your results are considered statistically non-significant.
To reduce the Type I error probability, you can simply set a lower significance level.
Type I error rate
The null hypothesis distribution curve below shows the probabilities of obtaining all possible results if the study were repeated with new samples and the null hypothesis were true in the population .
At the tail end, the shaded area represents alpha. It’s also called a critical region in statistics.
If your results fall in the critical region of this curve, they are considered statistically significant and the null hypothesis is rejected. However, this is a false positive conclusion, because the null hypothesis is actually true in this case!

A Type II error means not rejecting the null hypothesis when it’s actually false. This is not quite the same as “accepting” the null hypothesis, because hypothesis testing can only tell you whether to reject the null hypothesis.
Instead, a Type II error means failing to conclude there was an effect when there actually was. In reality, your study may not have had enough statistical power to detect an effect of a certain size.
Power is the extent to which a test can correctly detect a real effect when there is one. A power level of 80% or higher is usually considered acceptable.
The risk of a Type II error is inversely related to the statistical power of a study. The higher the statistical power, the lower the probability of making a Type II error.
Statistical power is determined by:
- Size of the effect : Larger effects are more easily detected.
- Measurement error : Systematic and random errors in recorded data reduce power.
- Sample size : Larger samples reduce sampling error and increase power.
- Significance level : Increasing the significance level increases power.
To (indirectly) reduce the risk of a Type II error, you can increase the sample size or the significance level.
Type II error rate
The alternative hypothesis distribution curve below shows the probabilities of obtaining all possible results if the study were repeated with new samples and the alternative hypothesis were true in the population .
The Type II error rate is beta (β), represented by the shaded area on the left side. The remaining area under the curve represents statistical power, which is 1 – β.
Increasing the statistical power of your test directly decreases the risk of making a Type II error.

The Type I and Type II error rates influence each other. That’s because the significance level (the Type I error rate) affects statistical power, which is inversely related to the Type II error rate.
This means there’s an important tradeoff between Type I and Type II errors:
- Setting a lower significance level decreases a Type I error risk, but increases a Type II error risk.
- Increasing the power of a test decreases a Type II error risk, but increases a Type I error risk.
This trade-off is visualized in the graph below. It shows two curves:
- The null hypothesis distribution shows all possible results you’d obtain if the null hypothesis is true. The correct conclusion for any point on this distribution means not rejecting the null hypothesis.
- The alternative hypothesis distribution shows all possible results you’d obtain if the alternative hypothesis is true. The correct conclusion for any point on this distribution means rejecting the null hypothesis.
Type I and Type II errors occur where these two distributions overlap. The blue shaded area represents alpha, the Type I error rate, and the green shaded area represents beta, the Type II error rate.
By setting the Type I error rate, you indirectly influence the size of the Type II error rate as well.

It’s important to strike a balance between the risks of making Type I and Type II errors. Reducing the alpha always comes at the cost of increasing beta, and vice versa .
For statisticians, a Type I error is usually worse. In practical terms, however, either type of error could be worse depending on your research context.
A Type I error means mistakenly going against the main statistical assumption of a null hypothesis. This may lead to new policies, practices or treatments that are inadequate or a waste of resources.
In contrast, a Type II error means failing to reject a null hypothesis. It may only result in missed opportunities to innovate, but these can also have important practical consequences.
In statistics, a Type I error means rejecting the null hypothesis when it’s actually true, while a Type II error means failing to reject the null hypothesis when it’s actually false.
The risk of making a Type I error is the significance level (or alpha) that you choose. That’s a value that you set at the beginning of your study to assess the statistical probability of obtaining your results ( p value ).
To reduce the Type I error probability, you can set a lower significance level.
The risk of making a Type II error is inversely related to the statistical power of a test. Power is the extent to which a test can correctly detect a real effect when there is one.
To (indirectly) reduce the risk of a Type II error, you can increase the sample size or the significance level to increase statistical power.
Statistical significance is a term used by researchers to state that it is unlikely their observations could have occurred under the null hypothesis of a statistical test . Significance is usually denoted by a p -value , or probability value.
Statistical significance is arbitrary – it depends on the threshold, or alpha value, chosen by the researcher. The most common threshold is p < 0.05, which means that the data is likely to occur less than 5% of the time under the null hypothesis .
When the p -value falls below the chosen alpha value, then we say the result of the test is statistically significant.
In statistics, power refers to the likelihood of a hypothesis test detecting a true effect if there is one. A statistically powerful test is more likely to reject a false negative (a Type II error).
If you don’t ensure enough power in your study, you may not be able to detect a statistically significant result even when it has practical significance. Your study might not have the ability to answer your research question.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the ‘Cite this Scribbr article’ button to automatically add the citation to our free Reference Generator.
Bhandari, P. (2023, February 02). Type I & Type II Errors | Differences, Examples, Visualizations. Scribbr. Retrieved 27 July 2024, from https://www.scribbr.co.uk/stats/type-i-and-type-ii-error/
Is this article helpful?

Pritha Bhandari
- Type I vs Type II Errors: Causes, Examples & Prevention

There are two common types of errors, type I and type II errors you’ll likely encounter when testing a statistical hypothesis. The mistaken rejection of the finding or the null hypothesis is known as a type I error. In other words, type I error is the false-positive finding in hypothesis testing . Type II error on the other hand is the false-negative finding in hypothesis testing.
To better understand the two types of errors, here’s an example:
Let’s assume you notice some flu-like symptoms and decide to go to a hospital to get tested for the presence of malaria. There is a possibility of two errors occurring:
- In type I error (False positive): The result of the test shows you have malaria but you actually don’t have it.
- Type II error (false negative): The test result indicates that you don’t have malaria when you in fact do.
Type I error and Type II error are extensively used in areas such as computer science, Engineering, Statistics, and many more.
The chance of committing a type I error is known as alpha (α), while the chance of committing a type II error is known as beta (β). If you carefully plan your study design, you can minimize the probability of committing either of the errors.
Read: Survey Errors To Avoid: Types, Sources, Examples, Mitigation
What are Type I Errors?
Type I error is an omission that happens when a null hypothesis is reprobated during hypothesis testing. This is when it is indeed precise or positive and should not have been initially disapproved. So if a null hypothesis is erroneously rejected when it is positive, it is called a Type I error.
What this means is that results are concluded to be significant when in actual fact, it was obtained by chance.
When conducting hypothesis testing, a null hypothesis is determined before carrying out the actual test. The null hypothesis may presume that there is no chain of circumstances between the items being tested which may cause an outcome for the test.
When a null hypothesis is rejected, it means a chain of circumstances has been established between the items being tested even though it is a false alarm or false positive. This could lead to an error or many errors in a test, known as a Type I error.
It is worthy of note that statistical outcomes of every testing involve uncertainties, so making errors while performing these hypothesis testings is unavoidable. It is inherent that type I error may be considered as an error of commission in the sense that the producer or researcher mistakenly decides on a false outcome.
Read: Systematic Errors in Research: Definition, Examples
Causes of Type I Error
- When a factor other than the variable affects the variables being tested. This factor that causes the effect produces a result that supports the decision to reject the null hypothesis.
- When the result of a hypothesis testing is caused by chance, it is a Type I error.
- Lastly, because a null hypothesis and the significance level are decided before conducting a hypothesis test, and also the sample size is not considered, a type I error may occur due to chance.
Read: Margin of error – Definition, Formula + Application
Risk Factor and Probability of Type I Error
- The risk factor and probability of Type I error are mostly set in advance and the level of significance of the hypothesis testing is known.
- The level of significance in a test is represented by α and it signifies the rate of the possibility of Type I error.
- While it is possible to reduce the rate of Type I error by using a determined sample size. The consequence of this, however, is that the possibility of a Type II error occurring in a test will increase.
- In a case where Type I error is decided at 5 percent, it means in the null hypothesis ( H 0), chances are there that 5 in the 100 hypotheses even if true will be rejected.
- Another risk factor is that both Type I and Type II errors can not be changed simultaneously. To reduce the possibility of one error occurring means the possibility of the other error will increase. Hence changing the outcome of one test inherently affects the outcome of the other test.
Read: Sampling Bias: Definition, Types + [Examples]
Consequences of a Type I Error
A type I error will result in a false alarm. The outcome of the hypothesis testing will be a false positive. This implies that the researcher decided the result of a hypothesis testing is true when in fact, it is not.
For a sales group, the consequences of a type I error may result in losing potential market and missing out on probable sales because the findings of a test are faulty.
What are Type II Errors?
A Type II error means a researcher or producer did not disapprove of the alternate hypothesis when it is in fact negative or false. This does not mean the null hypothesis is accepted as positive as hypothesis testing only indicates if a null hypothesis should be rejected.
A Type II error means a conclusion on the effect of the test wasn’t recognized when an effect truly existed. Before a test can be said to have a real effect, it has to have a power level that is 80% or more.
This implies the statistical power of a test determines the risk of a type II error. The probability of a type II error occurring largely depends on how high the statistical power is.
Note: Null hypothesis is represented as (H0) and alternative hypothesis is represented as (H1)
Causes of Type II Error
- Type II error is mainly caused by the statistical power of a test being low. A Type II error will occur if the statistical test is not powerful enough.
- The size of the sample can also lead to a Type I error because the outcome of the test will be affected. A small sample size might hide the significant level of the items being tested.
- Another cause of Type Ii error is the possibility that a researcher may disapprove of the actual outcome of a hypothesis even when it is correct.
Probability of Type II Error
- To arrive at the possibility of a Type II error occurring, the power of the test must be deducted from type 1.
- The level of significance in a test is represented by β and it shows the rate of the possibility of Type I error.
- It is possible to reduce the rate of Type II error if the significance level of the test is increased.
- In a case where Type II error is decided at 5 percent, it means in the null hypothesis ( H 0), chances are there that 5 in the 100 hypotheses even if it is false will be accepted.
- Type I error and Type II error are connected. Hence, to reduce the possibility of one type of error from occurring means the possibility of the other error will increase.
- It is important to decide which error has lesser effects on the test.
Consequences of a Type II Error
Type II errors can also result in a wrong decision that will affect the outcomes of a test and have real-life consequences.
Note that even if you proved your test hypothesis, your conversion result can invalidate the outcome unintended. This turn of events can be discouraging, hence the need to be extra careful when conducting hypothesis testing.
How to Avoid Type I and II errors
Type I error and type II errors can not be entirely avoided in hypothesis testing, but the researcher can reduce the probability of them occurring.
For Type I error, minimize the significance level to avoid making errors. This can be determined by the researcher.
To avoid type II errors, ensure the test has high statistical power. The higher the statistical power, the higher the chance of avoiding an error. Set your statistical power to 80% and above and conduct your test.
Increase the sample size of the hypothesis testing.
The Type II error can also be avoided if the significance level of the test hypothesis is chosen.
How to Detect Type I and Type II Errors in Data
After completing a study, the researcher can conduct any of the available statistical tests to reject the default hypothesis in favor of its alternative. If the study is free of bias, there are four possible outcomes. See the image below;
Image source: IPJ
If the findings in the sample and reality in the population match, the researchers’ inferences will be correct. However, if in any of the situations a type I or II error has been made, the inference will be incorrect.
Key Differences between Type I & II Errors
- In statistical hypothesis testing, a type I error is caused by disapproving a null hypothesis that is otherwise correct while in contrast, Type II error occurs when the null hypothesis is not rejected even though it is not true.
- Type I error is the same as a false alarm or false positive while Type II error is also referred to as false negative.
- A Type I error is represented by α while a Type II error is represented by β.
- The level of significance determines the possibility of a type I error while type II error is the possibility of deducting the power of the test from 1.
- You can decrease the possibility of Type I error by reducing the level of significance. The same way you can reduce the probability of a Type II error by increasing the significance level of the test.
- Type I error occurs when you reject the null hypothesis, in contrast, Type II error occurs when you accept an incorrect outcome of a false hypothesis
Examples of Type I & II errors
Type i error examples.
To understand the statistical significance of Type I error, let us look at this example.
In this hypothesis, a driver wants to determine the relationship between him getting a new driving wheel and the number of passengers he carries in a week.
Now, if the number of passengers he carries in a week increases after he got a new driving wheel than the number of passengers he carried in a week with the old driving wheel, this driver might assume that there is a relationship between the new wheel and the increase in the number of passengers and support the alternative hypothesis.
However, the increment in the number of passengers he carried in a week, might have been influenced by chance and not by the new wheel which results in type I error.
By this indication, the driver should have supported the null hypothesis because the increment of his passengers might have been due to chance and not fact.
Type II error examples
For Type II error and statistical power, let us assume a hypothesis where a farmer that rears birds assumes none of his birds have bird-flu. He observes his birds for four days to find out if there are symptoms of the flu.
If after four days, the farmer sees no symptoms of the flu in his birds, he might assume his birds are indeed free from bird flu whereas the bird flu might have affected his birds and the symptoms are obvious on the sixth day.
By this indication, the farmer accepts that no flu exists in his birds. This leads to a type II error where it supports the null hypothesis when it is in fact false.
Frequently Asked Questions about Type I and II Errors
- Is a Type I or Type II error worse?
Both Type I and type II errors could be worse based on the type of research being conducted.
A Type I error means an incorrect assumption has been made when the assumption is in reality not true. The consequence of this is that other alternatives are disapproved of to accept this conclusion. A type II error implies that a null hypothesis was not rejected. This means that a significant outcome wouldn’t have any benefit in reality.
A Type I error however may be terrible for statisticians. It is difficult to decide which of the errors is worse than the other but both types of errors could do enough damage to your research.
- Does sample size affect type 1 error?
Small or large sample size does not affect type I error . So sample size will not increase the occurrence of Type I error.
The only principle is that your test has a normal sample size. If the sample size is small in Type II errors, the level of significance will decrease.
This may cause a false assumption from the researcher and discredit the outcome of the hypothesis testing.
- What is statistical power as it relates to Type I or Type II errors
Statistical power is used in type II to deduce the measurement error. This is because random errors reduce the statistical power of hypothesis testing. Not only that, the larger the size of the effect, the more detectable the errors are.
The statistical power of a hypothesis increases when the level of significance increases. The statistical power also increases when a larger sample size is being tested thereby reducing the errors. If you want the risk of Type II error to reduce, increase the level of significance of the test.
- What is statistical significance as it relates to Type I or Type II errors
Statistical significance relates to Type I error. Researchers sometimes assume that the outcome of a test is statistically significant when they are not and the researcher then rejects the null hypothesis. The fact is, the outcome might have happened due to chance.
A type I error decreases when a lower significance level is set.
If your test power is lower compared to the significance level, then the alternative hypothesis is relevant to the statistical significance of your test, then the outcome is relevant.
In this article, we have extensively discussed Type I error and Type II error. We have also discussed their causes, the probabilities of their occurrence, and how to avoid them. We have seen that both Types of errors have their usefulness and limitations. The best approach as a researcher is to know which to apply and when.
Connect to Formplus, Get Started Now - It's Free!
- alternative vs null hypothesis
- hypothesis testing
- level of errors
- level of significance
- statistical hypothesis
- statistical power
- type i errors
- type ii errors
- busayo.longe
You may also like:
Alternative vs Null Hypothesis: Pros, Cons, Uses & Examples
We are going to discuss alternative hypotheses and null hypotheses in this post and how they work in research.
Hypothesis Testing: Definition, Uses, Limitations + Examples
The process of research validation involves testing and it is in this context that we will explore hypothesis testing.
What is Pure or Basic Research? + [Examples & Method]
Simple guide on pure or basic research, its methods, characteristics, advantages, and examples in science, medicine, education and psychology
Internal Validity in Research: Definition, Threats, Examples
In this article, we will discuss the concept of internal validity, some clear examples, its importance, and how to test it.
Formplus - For Seamless Data Collection
Collect data the right way with a versatile data collection tool. try formplus and transform your work productivity today..
User Preferences
Content preview.
Arcu felis bibendum ut tristique et egestas quis:
- Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris
- Duis aute irure dolor in reprehenderit in voluptate
- Excepteur sint occaecat cupidatat non proident
Keyboard Shortcuts
6.1 - type i and type ii errors.
When conducting a hypothesis test there are two possible decisions: reject the null hypothesis or fail to reject the null hypothesis. You should remember though, hypothesis testing uses data from a sample to make an inference about a population. When conducting a hypothesis test we do not know the population parameters. In most cases, we don't know if our inference is correct or incorrect.
When we reject the null hypothesis there are two possibilities. There could really be a difference in the population, in which case we made a correct decision. Or, it is possible that there is not a difference in the population (i.e., \(H_0\) is true) but our sample was different from the hypothesized value due to random sampling variation. In that case we made an error. This is known as a Type I error.
When we fail to reject the null hypothesis there are also two possibilities. If the null hypothesis is really true, and there is not a difference in the population, then we made the correct decision. If there is a difference in the population, and we failed to reject it, then we made a Type II error.
Rejecting \(H_0\) when \(H_0\) is really true, denoted by \(\alpha\) ("alpha") and commonly set at .05
\(\alpha=P(Type\;I\;error)\)
Failing to reject \(H_0\) when \(H_0\) is really false, denoted by \(\beta\) ("beta")
\(\beta=P(Type\;II\;error)\)
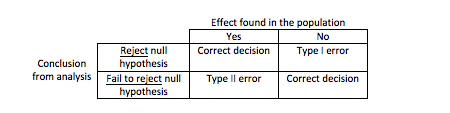
| Decision | Reality | |
|---|---|---|
| \(H_0\) is true | \(H_0\) is false | |
| Reject \(H_0\), (conclude \(H_a\)) | Type I error | Correct decision |
| Fail to reject \(H_0\) | Correct decision | Type II error |
Example: Trial Section
A man goes to trial where he is being tried for the murder of his wife.
We can put it in a hypothesis testing framework. The hypotheses being tested are:
- \(H_0\) : Not Guilty
- \(H_a\) : Guilty
Type I error is committed if we reject \(H_0\) when it is true. In other words, did not kill his wife but was found guilty and is punished for a crime he did not really commit.
Type II error is committed if we fail to reject \(H_0\) when it is false. In other words, if the man did kill his wife but was found not guilty and was not punished.
Example: Culinary Arts Study Section

A group of culinary arts students is comparing two methods for preparing asparagus: traditional steaming and a new frying method. They want to know if patrons of their school restaurant prefer their new frying method over the traditional steaming method. A sample of patrons are given asparagus prepared using each method and asked to select their preference. A statistical analysis is performed to determine if more than 50% of participants prefer the new frying method:
- \(H_{0}: p = .50\)
- \(H_{a}: p>.50\)
Type I error occurs if they reject the null hypothesis and conclude that their new frying method is preferred when in reality is it not. This may occur if, by random sampling error, they happen to get a sample that prefers the new frying method more than the overall population does. If this does occur, the consequence is that the students will have an incorrect belief that their new method of frying asparagus is superior to the traditional method of steaming.
Type II error occurs if they fail to reject the null hypothesis and conclude that their new method is not superior when in reality it is. If this does occur, the consequence is that the students will have an incorrect belief that their new method is not superior to the traditional method when in reality it is.
- En español – ExME
- Em português – EME
What are Type I and Type II Errors?
Posted on 21st April 2017 by Priscilla Wittkopf

When conducting a hypothesis test, we could:
- Reject the null hypothesis when there is a genuine effect in the population;
- Fail to reject the null hypothesis when there isn’t a genuine effect in the population.
However, as we are inferring results from samples and using probabilities to do so, we are never working with 100% certainty of the presence or absence of an effect. There are two other possible outcomes of a hypothesis test.
- Reject the null hypothesis when there isn’t a genuine effect – we have a false positive result and this is called Type I error .
- Fail to reject the null hypothesis when there is a genuine effect – we have a false negative result and this is called Type II error .
So in simple terms, a type I error is erroneously detecting an effect that is not present , while a type II error is the failure to detect an effect that is present.
Type I error
This error occurs when we reject the null hypothesis when we should have retained it. That means that we believe we found a genuine effect when in reality there isn’t one. The probability of a type I error occurring is represented by α and as a convention the threshold is set at 0.05 (also known as significance level). When setting a threshold at 0.05 we are accepting that there is a 5% probability of identifying an effect when actually there isn’t one.
Type II error
This error occurs when we fail to reject the null hypothesis. In other words, we believe that there isn’t a genuine effect when actually there is one. The probability of a Type II error is represented as β and this is related to the power of the test (power = 1- β). Cohen (1998) proposed that the maximum accepted probability of a Type II error should be 20% (β = 0.2).
When designing and planning a study the researcher should decide the values of α and β, bearing in mind that inferential statistics involve a balance between Type I and Type II errors. If α is set at a very small value the researcher is more rigorous with the standards of rejection of the null hypothesis. For example, if α = 0.01 the researcher is accepting a probability of 1% of erroneously rejecting the null hypothesis, but there is an increase in the probability of a Type II error.
In summary, we can see on the table the possible outcomes of a hypothesis test:
Have this table in mind when designing, analysing and reading studies, it will help when interpreting findings.
COHEN, J. 1990. Things I have learned (so far). American psychologist, 45 , 1304.
COHEN, J. 1998. Statistical Power Analysis for the Behavioral Sciences , Lawrence Erlbaum Associates.
FIELD, A. 2013. Discovering statistics using IBM SPSS statistics , Sage.

Priscilla Wittkopf
Leave a reply cancel reply.
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
No Comments on What are Type I and Type II Errors?

I’m pretty sure “erroneous” is not the word you’re looking for in the opening sentence!

You’re quite right. This was an editorial issue rather than the fault of the author and has now been amended. Many thanks.
Subscribe to our newsletter
You will receive our monthly newsletter and free access to Trip Premium.
Related Articles

Making sense of medical statistics: a bite sized visual guide
This blog is a review of a newly published book, which has the overall aim of giving health professionals a ‘working understanding’ of medical statistics.

A Brief Introduction to Statistical Averages
This tutorial provides an introduction to statistical averages (mean, median and mode) for beginners to the topic.

An Introduction to Probability
A tutorial for understanding and calculating probability. We go back to basics for beginners or for those just wanting a refresher.
The Difference Between Type I and Type II Errors in Hypothesis Testing
- Inferential Statistics
- Statistics Tutorials
- Probability & Games
- Descriptive Statistics
- Applications Of Statistics
- Math Tutorials
- Pre Algebra & Algebra
- Exponential Decay
- Worksheets By Grade
- Ph.D., Mathematics, Purdue University
- M.S., Mathematics, Purdue University
- B.A., Mathematics, Physics, and Chemistry, Anderson University
The statistical practice of hypothesis testing is widespread not only in statistics but also throughout the natural and social sciences. When we conduct a hypothesis test there a couple of things that could go wrong. There are two kinds of errors, which by design cannot be avoided, and we must be aware that these errors exist. The errors are given the quite pedestrian names of type I and type II errors. What are type I and type II errors, and how we distinguish between them? Briefly:
- Type I errors happen when we reject a true null hypothesis
- Type II errors happen when we fail to reject a false null hypothesis
We will explore more background behind these types of errors with the goal of understanding these statements.
Hypothesis Testing
The process of hypothesis testing can seem to be quite varied with a multitude of test statistics. But the general process is the same. Hypothesis testing involves the statement of a null hypothesis and the selection of a level of significance . The null hypothesis is either true or false and represents the default claim for a treatment or procedure. For example, when examining the effectiveness of a drug, the null hypothesis would be that the drug has no effect on a disease.
After formulating the null hypothesis and choosing a level of significance, we acquire data through observation. Statistical calculations tell us whether or not we should reject the null hypothesis.
In an ideal world, we would always reject the null hypothesis when it is false, and we would not reject the null hypothesis when it is indeed true. But there are two other scenarios that are possible, each of which will result in an error.
Type I Error
The first kind of error that is possible involves the rejection of a null hypothesis that is actually true. This kind of error is called a type I error and is sometimes called an error of the first kind.
Type I errors are equivalent to false positives. Let’s go back to the example of a drug being used to treat a disease. If we reject the null hypothesis in this situation, then our claim is that the drug does, in fact, have some effect on a disease. But if the null hypothesis is true, then, in reality, the drug does not combat the disease at all. The drug is falsely claimed to have a positive effect on a disease.
Type I errors can be controlled. The value of alpha, which is related to the level of significance that we selected has a direct bearing on type I errors. Alpha is the maximum probability that we have a type I error. For a 95% confidence level, the value of alpha is 0.05. This means that there is a 5% probability that we will reject a true null hypothesis. In the long run, one out of every twenty hypothesis tests that we perform at this level will result in a type I error.
Type II Error
The other kind of error that is possible occurs when we do not reject a null hypothesis that is false. This sort of error is called a type II error and is also referred to as an error of the second kind.
Type II errors are equivalent to false negatives. If we think back again to the scenario in which we are testing a drug, what would a type II error look like? A type II error would occur if we accepted that the drug had no effect on a disease, but in reality, it did.
The probability of a type II error is given by the Greek letter beta. This number is related to the power or sensitivity of the hypothesis test, denoted by 1 – beta.
How to Avoid Errors
Type I and type II errors are part of the process of hypothesis testing. Although the errors cannot be completely eliminated, we can minimize one type of error.
Typically when we try to decrease the probability one type of error, the probability for the other type increases. We could decrease the value of alpha from 0.05 to 0.01, corresponding to a 99% level of confidence . However, if everything else remains the same, then the probability of a type II error will nearly always increase.
Many times the real world application of our hypothesis test will determine if we are more accepting of type I or type II errors. This will then be used when we design our statistical experiment.
- What Level of Alpha Determines Statistical Significance?
- Null Hypothesis Examples
- How to Find Critical Values with a Chi-Square Table
- Type I and Type II Errors in Statistics
- Hypothesis Test Example
- What Is the Difference Between Alpha and P-Values?
- How to Conduct a Hypothesis Test
- Example of a Chi-Square Goodness of Fit Test
- What Is ANOVA?
- What Is a P-Value?
- An Example of a Hypothesis Test
- Hypothesis Test for the Difference of Two Population Proportions
- Scientific Method Vocabulary Terms
- Random Error vs. Systematic Error
- What 'Fail to Reject' Means in a Hypothesis Test
- Null Hypothesis and Alternative Hypothesis
- Key Differences
Know the Differences & Comparisons
Difference Between Type I and Type II Errors

The testing of hypothesis is a common procedure; that researcher use to prove the validity, that determines whether a specific hypothesis is correct or not. The result of testing is a cornerstone for accepting or rejecting the null hypothesis (H 0 ). The null hypothesis is a proposition; that does not expect any difference or effect. An alternative hypothesis (H 1 ) is a premise that expects some difference or effect.
There are slight and subtle differences between type I and type II errors, that we are going to discuss in this article.
Content: Type I Error Vs Type II Error
Comparison chart, possible outcomes.
| Basis for Comparison | Type I Error | Type II Error |
|---|---|---|
| Meaning | Type I error refers to non-acceptance of hypothesis which ought to be accepted. | Type II error is the acceptance of hypothesis which ought to be rejected. |
| Equivalent to | False positive | False negative |
| What is it? | It is incorrect rejection of true null hypothesis. | It is incorrect acceptance of false null hypothesis. |
| Represents | A false hit | A miss |
| Probability of committing error | Equals the level of significance. | Equals the power of test. |
| Indicated by | Greek letter 'α' | Greek letter 'β' |
Definition of Type I Error
In statistics, type I error is defined as an error that occurs when the sample results cause the rejection of the null hypothesis, in spite of the fact that it is true. In simple terms, the error of agreeing to the alternative hypothesis, when the results can be ascribed to chance.
Also known as the alpha error, it leads the researcher to infer that there is a variation between two observances when they are identical. The likelihood of type I error, is equal to the level of significance, that the researcher sets for his test. Here the level of significance refers to the chances of making type I error.
E.g. Suppose on the basis of data, the research team of a firm concluded that more than 50% of the total customers like the new service started by the company, which is, in fact, less than 50%.
Definition of Type II Error
When on the basis of data, the null hypothesis is accepted, when it is actually false, then this kind of error is known as Type II Error. It arises when the researcher fails to deny the false null hypothesis. It is denoted by Greek letter ‘beta (β)’ and often known as beta error.
Type II error is the failure of the researcher in agreeing to an alternative hypothesis, although it is true. It validates a proposition; that ought to be refused. The researcher concludes that the two observances are identical when in fact they are not.
The likelihood of making such error is analogous to the power of the test. Here, the power of test alludes to the probability of rejecting of the null hypothesis, which is false and needs to be rejected. As the sample size increases, the power of test also increases, that results in the reduction in risk of making type II error.
E.g. Suppose on the basis of sample results, the research team of an organisation claims that less than 50% of the total customers like the new service started by the company, which is, in fact, greater than 50%.
Key Differences Between Type I and Type II Error
The points given below are substantial so far as the differences between type I and type II error is concerned:
- Type I error is an error that takes place when the outcome is a rejection of null hypothesis which is, in fact, true. Type II error occurs when the sample results in the acceptance of null hypothesis, which is actually false.
- Type I error or otherwise known as false positives, in essence, the positive result is equivalent to the refusal of the null hypothesis. In contrast, Type II error is also known as false negatives, i.e. negative result, leads to the acceptance of the null hypothesis.
- When the null hypothesis is true but mistakenly rejected, it is type I error. As against this, when the null hypothesis is false but erroneously accepted, it is type II error.
- Type I error tends to assert something that is not really present, i.e. it is a false hit. On the contrary, type II error fails in identifying something, that is present, i.e. it is a miss.
- The probability of committing type I error is the sample as the level of significance. Conversely, the likelihood of committing type II error is same as the power of the test.
- Greek letter ‘α’ indicates type I error. Unlike, type II error which is denoted by Greek letter ‘β’.

By and large, Type I error crops up when the researcher notice some difference, when in fact, there is none, whereas type II error arises when the researcher does not discover any difference when in truth there is one. The occurrence of the two kinds of errors is very common as they are a part of testing process. These two errors cannot be removed completely but can be reduced to a certain level.
You Might Also Like:

Sajib banik says
January 19, 2017 at 11:00 pm
useful information
Tomisi says
May 10, 2018 at 11:48 pm
Thanks, the simplicity of your illusrations in essay and tables is great contribution to the demystification of statistics.
Tika Ram Khatiwada says
January 9, 2019 at 1:39 pm
Very simply and clearly defined.
sanjaya says
January 9, 2019 at 3:56 pm
Good article..
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
Microbe Notes
Type I Error and Type II Error: 10 Differences, Examples

Image Source: AB Tasty .
Table of Contents
Interesting Science Videos
Type 1 error definition
- Type 1 error, in statistical hypothesis testing, is the error caused by rejecting a null hypothesis when it is true.
- Type 1 error is caused when the hypothesis that should have been accepted is rejected.
- Type I error is denoted by α (alpha), known as an error, also called the level of significance of the test.
- This type of error is a false positive error where the null hypothesis is rejected based on some error during the testing.
- The null hypothesis is set to state that there is no relationship between two variables and the cause-effect relationship between two variables, if present, is caused by chance.
- Type 1 error occurs when the null hypothesis is rejected even when there is no relationship between the variables.
- As a result of this error, the researcher might believe that the hypothesis works even when it doesn’t.
Type 1 error causes
- Type 1 error is caused when something other than the variable affects the other variable, which results in an outcome that supports the rejection of the null hypothesis.
- Under such conditions, the outcome appears to have happened due to some causes than chance when it is caused by chance.
- Before a hypothesis is tested, a probability is set as a level of significance which means that the hypothesis is being tested while taking a chance where the null hypothesis is rejected even when it is true.
- Thus, type 1 error might be due to the chance/ level of significance set before the test without considering the test duration and sample size.
Probability of type 1 error
- The probability of Type I error is usually determined in advance and is understood as the significance level of testing the hypothesis.
- If the Type I error is fixed at 5 percent, there are about five chances in 100 that the null hypothesis, H0, will be rejected when it is true.
- The rate or probability of type 1 error is symbolized by α and is also termed the level os significance in a test.
- It is possible to reduce type 1 error at a fixed size of the sample; however, while doing so, the probability of type II error increases.
- There is a trade-off between the two errors where decreasing the probability of one error increases the probability of another. It is not possible to reduce both errors simultaneously.
- Thus, depending on the type and nature of the test, the researchers need to decide the appropriate level of type 1 error after evaluating the consequences of the errors.
Type 1 error examples
- For this, let us take a hypothesis where a player is trying to find the relationship between him wearing new shoes and the number of wins for his team.
- Here, if the number of wins for his team is more when he was wearing his new shoes is more than the number of wins for his team otherwise, he might accept the alternative hypothesis and determine that there is a relationship.
- However, the winning of his team might be influenced by just chance rather than his shoes which results in a type 1 error.
- In this case, he should’ve accepted the null hypothesis because the winning of a team might happen due to chance or luck.

Type II error definition
- Type II error is the error that occurs when the null hypothesis is accepted when it is not true.
- In simple words, Type II error means accepting the hypothesis when it should not have been accepted.
- The type II error results in a false negative result.
- In other words, type II is the error of failing to accept an alternative hypothesis when the researcher doesn’t have adequate power.
- The Type II error is denoted by β (beta) and is also termed the beta error.
- The null hypothesis states that there is no relationship between two variables, and the cause-effect relationship between two variables, if present, is caused by chance.
- Type II error occurs when the null hypothesis is acceptable considering that the relationship between the variables is because of chance or luck, and even when there is a relationship between the variables.
- As a result of this error, the researcher might believe that the hypothesis doesn’t work even when it should.
Type II error causes
- The primary cause of type II error, like a Type II error, is the low power of the statistical test.
- This occurs when the statistical is not powerful and thus results in a Type II error.
- Other factors, like the sample size, might also affect the test results.
- When small sample size is selected, the relationship between the two variables being tested might not be significant even when it does exist.
- The researcher might assume the relationship is due to chance and thus reject the alternative hypothesis even when it is true.
- There it is important to select an appropriate size of the sample before beginning the test.
Probability of type II error
- The probability of committing a Type II error is calculated by subtracting the power of the test from 1.
- If Type II error is fixed at 2 percent, there are about two chances in 100 that the null hypothesis, H0, will be accepted when it is not true.
- The rate or probability of type II error is symbolized by β and is also termed the error of the second type.
- It is possible to reduce the probability of Type II error by increasing the significance level.
- In this case, the probability of rejecting the null hypothesis even when it is true also increases, decreasing the chances of accepting the null hypothesis when it is not true.
- However, because type I and Type II error are interconnected, reducing one tends to increase the probability of the other.
- Therefore, depending on the nature of the test, it is important to determine which one of the errors is less detrimental to the test.
- For this, if a type I error involves the time and effort of retesting the chemicals used in medicine, that should have been accepted. In contrast, the type II error involves the chances of several users of this medicine being poisoned, and it is wise to accept the type I error over type II.
Type II error examples
- For this, let us take a hypothesis where a shepherd thinks there is no wolf in the village, and he wakes up all night for five nights to determine the wolf’s existence.
- If he sees no wolf for five nights, he might assume that there is no wolf in the village where the wolf might exist and attack the sixth night.
- In this case, when the shepherd accepts that no wolf exists, a type II error results where he agrees with the null hypothesis even when it is not true.

Type I Error vs. Type II Error
| Type 1 error, in statistical hypothesis testing, is the error caused by rejecting a null hypothesis when it is true. | Type II error is the error that occurs when the null hypothesis is accepted when it is not true. | |
| Type I error is equivalent to a false positive. | Type II error is equivalent to a false negative. | |
| It is a false rejection of a true hypothesis. | It is the false acceptance of an incorrect hypothesis. | |
| Type I error is denoted by α. | Type II error is denoted by β. | |
| The probability of type I error is equal to the level of significance. | The probability of type II error is equal to one minus the power of the test. | |
| It can be reduced by decreasing the level of significance. | It can be reduced by increasing the level of significance. | |
| It is caused by luck or chance. | It is caused by smaller sample size or a less powerful test. | |
| Type I error is similar to a false hit. | Type II error is similar to a miss. | |
| Type I error is associated with rejecting the null hypothesis. | Type II error is associated with rejecting the alternative hypothesis. | |
| It happens when the acceptance levels are set too lenient. | It happens when the acceptance levels are set too stringent. |
Type I Error vs. Type II Error Video

References and Sources
- R. Kothari (1990) Research Methodology. Vishwa Prakasan. India.
- https://magoosh.com/statistics/type-i-error-definition-and-examples/
- https://corporatefinanceinstitute.com/resources/knowledge/other/type-ii-error/
- https://keydifferences.com/difference-between-type-i-and-type-ii-errors.html
- 3% – https://www.investopedia.com/terms/t/type-ii-error.asp
- 1% – https://www.thoughtco.com/null-hypothesis-examples-609097
- 1% – https://www.thoughtco.com/hypothesis-test-example-3126384
- 1% – https://www.stt.msu.edu/~lepage/STT200_Sp10/3-1-10key.pdf
- 1% – https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2996198/
- 1% – https://www.chegg.com/homework-help/questions-and-answers/following-table-shows-number-wins-eight-teams-football-season-also-shown-average-points-te-q13303251
- 1% – https://stattrek.com/hypothesis-test/power-of-test.aspx
- 1% – https://statisticsbyjim.com/hypothesis-testing/failing-reject-null-hypothesis/
- 1% – https://simplyeducate.me/2014/05/29/what-is-a-statistically-significant-relationship-between-two-variables/
- 1% – https://abrarrazakhan.files.wordpress.com/2014/04/mcq-testing-of-hypothesis-with-correct-answers.pdf
- <1% – https://www.nature.com/articles/s41524-017-0047-6
- <1% – https://www.dummies.com/education/math/statistics/understanding-type-i-and-type-ii-errors/
- <1% – https://www.chegg.com/homework-help/questions-and-answers/null-hypothesis-true-possibility-making-type-error-true-false-believe-s-false-want-make-su-q4115439
- <1% – https://stepupanalytics.com/hypothesis-testing-examples/
- <1% – https://statistics.laerd.com/statistical-guides/hypothesis-testing-3.php
- <1% – https://mpra.ub.uni-muenchen.de/66373/1/MPRA_paper_66373.pdf
- <1% – https://en.wikipedia.org/wiki/Probability_of_error
- <1% – https://educationalresearchtechniques.com/2016/02/03/type-i-and-type-ii-error/
About Author

Anupama Sapkota
Leave a Comment Cancel reply
Save my name, email, and website in this browser for the next time I comment.
This site uses Akismet to reduce spam. Learn how your comment data is processed .
- Foundations
- Write Paper
Search form
- Experiments
- Anthropology
- Self-Esteem
- Social Anxiety
Type I Error and Type II Error
Experimental errors in research.
While you might not have heard of Type I error or Type II error, you’re probably familiar with the terms “false positive” and “false negative.”
This article is a part of the guide:
- Null Hypothesis
- Research Hypothesis
- Defining a Research Problem
- Selecting Method
Browse Full Outline
- 1 Scientific Method
- 2.1.1 Null Hypothesis
- 2.1.2 Research Hypothesis
- 2.2 Prediction
- 2.3 Conceptual Variable
- 3.1 Operationalization
- 3.2 Selecting Method
- 3.3 Measurements
- 3.4 Scientific Observation
- 4.1 Empirical Evidence
- 5.1 Generalization
- 5.2 Errors in Conclusion
A common medical example is a patient who takes an HIV test which promises a 99.9% accuracy rate. This means that in 0.1% of cases, or 1 in every 1000, the test gives a 'false positive,' informing a patient that they have the virus when they do not.
On the other hand, the test could also show a false negative reading, giving a person who is actually HIV positive the all-clear. This is why most medical tests require duplicate samples, to stack the odds in our favor. A 1 in 1000 chance of a false positive becomes a 1 in 1 000 000 chance of two false positives, if two tests are taken.
With any scientific process , there is no such thing as total proof or total rejection, whether of test results or of a null hypothesis . Researchers must work instead with probabilities. So even if the probabilities are lowered to 1 in 1000 000, there is still the chance that the results may be wrong.

How Does This Translate to Science?
Type i error.
A Type I error is often referred to as a “false positive” and is the incorrect rejection of the true null hypothesis in favor of the alternative.
In the example above, the null hypothesis refers to the natural state of things or the absence of the tested effect or phenomenon, i.e. stating that the patient is HIV negative. The alternative hypothesis states that the patient is HIV positive. Many medical tests will have the disease they are testing for as the alternative hypothesis and the lack of that disease as the null hypothesis.
A Type I error would thus occur when the patient doesn’t have the virus but the test shows that they do. In other words, the test incorrectly rejects the true null hypothesis that the patient is HIV negative.
Type II Error
A Type II error is the inverse of a Type I error and is the false acceptance of a null hypothesis that is not actually true, i.e. a false negative. A Type II error would entail the test telling the patient they are free of HIV when they are not.
Considering this HIV example, which error type do you think is more acceptable? In other words, would you rather have a test that was more prone to Type I or Type II error? With HIV, it’s likely that the momentary stress of a false positive is better than feeling relieved at a false negative and then failing to take steps to treat the disease. Pregnancy tests, blood tests and any diagnostic tool that has serious consequences for the health of a patient are usually overly sensitive for this reason – it is much better for them to err on the side of a false positive.
But in most fields of science, Type II errors are seen as less serious than Type I errors. With the Type II error, a chance to reject the null hypothesis was lost, and no conclusion is inferred from a non-rejected null. But the Type I error is more serious, because you have wrongly rejected the null hypothesis and ultimately made a claim that is not true. In science, finding a phenomenon where there is none is more egregious than failing to find a phenomenon where there is. Therefore in most research designs, effort is made to err on the side of a false negative.

Replication
This is the key reason why scientific experiments must be replicable.
Even if the highest level of proof is reached, where P < 0.01 ( probability is less than 1%), out of every 100 experiments, there will still be one false result. To a certain extent, duplicate or triplicate samples reduce the chance of error , but may still mask chance if the error -causing variable is present in all samples.
But if other researchers, using the same equipment, replicate the experiment and find that the results are the same, the chances of 5 or 10 experiments giving false results is unbelievably small. This is how science regulates and minimizes the potential for both Type I and Type II errors.
Of course, in certain experiments and medical diagnoses, replication is not always possible, so the possibility of Type I and II errors is always a factor.
One area that is guilty of forgetting about Type I and II errors is in the legal system, where a jury is seldom told that fingerprint and DNA tests may produce false results. There have been many documented failures of justice involving such tests. Today courts will no longer accept these tests alone as proof of guilt, and require other evidence to reduce the possibility of error to acceptable levels.
Type III Errors
Some statisticians are now adopting a third type of error, Type III, which is where the null hypothesis was correctly rejected …but for the wrong reason.
In an experiment, a researcher might postulate a hypothesis and perform research. After analyzing the results statistically, the null hypothesis is rejected.
The problem is that there may indeed be some relationship between the variables , but it’s not the one stated in the hypothesis. There is no error in rejecting the null here, but the error lies in accepting an incorrect alternative hypothesis. Hence a still unknown process may underlie the relationship, and the researchers are none the wiser.
As an example, researchers may be interested to see if there is any difference in two group means, and find that there is one. So they reject the null hypothesis but don’t notice that the difference is actually in the opposite direction to what their results found. Perhaps random chance led them to collect low scores from the group that is in reality higher and high scores from the group that is in reality lower. This is a curious way of being both correct and incorrect at the same time! As you can imagine, Type III errors are rare.
Economist Howard Raiffa gives a different definition for Type III error, one that others have called Type 0: getting the correct answer to an incorrect question.
Additionally, a Type IV error has been defined as incorrectly interpreting a null hypothesis that has been correctly rejected. Type IV error comes down to faulty analysis, bias or fumbling with the data to arrive at incorrect conclusions.
Errors of all types should be taken into account by scientists when conducting research.
Whilst replication can minimize the chances of an inaccurate result, it is no substitute for clear and logical research design, and careful analysis of results.
Many scientists do not accept quasi-experiments , because they are difficult to replicate and analyze, and therefore have a higher risk of being affected by error.
- Psychology 101
- Flags and Countries
- Capitals and Countries
Martyn Shuttleworth , Lyndsay T Wilson (Nov 24, 2008). Type I Error and Type II Error. Retrieved Jul 26, 2024 from Explorable.com: https://explorable.com/type-i-error
You Are Allowed To Copy The Text
The text in this article is licensed under the Creative Commons-License Attribution 4.0 International (CC BY 4.0) .
This means you're free to copy, share and adapt any parts (or all) of the text in the article, as long as you give appropriate credit and provide a link/reference to this page.
That is it. You don't need our permission to copy the article; just include a link/reference back to this page. You can use it freely (with some kind of link), and we're also okay with people reprinting in publications like books, blogs, newsletters, course-material, papers, wikipedia and presentations (with clear attribution).
Related articles
economist.com
Want to stay up to date? Follow us!
Get all these articles in 1 guide.
Want the full version to study at home, take to school or just scribble on?
Whether you are an academic novice, or you simply want to brush up your skills, this book will take your academic writing skills to the next level.

Download electronic versions: - Epub for mobiles and tablets - For Kindle here - PDF version here
Save this course for later
Don't have time for it all now? No problem, save it as a course and come back to it later.
Footer bottom
- Privacy Policy

- Subscribe to our RSS Feed
- Like us on Facebook
- Follow us on Twitter
✂️ The Future of Marketing Is Personal: Personalize Experiences at Scale with Ninetailed AI Platform Ninetailed AI →
Type 1 and Type 2 Errors
What is type 1 error.
A Type 1 error, also known as a false positive, is when a test incorrectly indicates that a condition is present when it is not.
For example, if a new drug is tested and the null hypothesis is that the drug is ineffective but actually effective, then a Type 1 error has occurred. This error can have serious consequences, as patients may be needlessly exposed to harmful side effects or may miss out on treatment altogether.
Type 1 errors are often due to chance, but they can also be caused by errors in the testing process itself. For example, if the sample size is too small or there is bias in the selection of participants, this can increase the likelihood of a Type 1 error. It's important to consider these factors when designing a study, as they can greatly impact the results.
When interpreting results from a test, it's important to consider the potential for Type 1 errors. If the consequences of a false positive are serious, then a higher level of proof may be needed to make sure that the results are accurate. On the other hand, if the consequences of a false positive are not so serious, then a lower level of proof may be acceptable.
It's also worth considering the Type 2 error, which is when a test incorrectly indicates that a condition is not present when it actually is. This error can have just as serious consequences as a Type 1 error, so it's important to be aware of both when interpreting test results.
Type 1 and Type 2 errors can be reduced by using more reliable tests and increasing the sample size. However, it's not always possible to completely eliminate these errors, so it's important to be aware of their potential impact when interpreting test results.
What Causes a Type 1 Error
There are several factors that can contribute to a type 1 error.
First, the researcher sets the level of significance (alpha). The higher the alpha level, the more likely it is that a type 1 error will occur.
Second, the sample size also plays a role in the likelihood of a type 1 error. The larger the sample size, the less likely it is that a type 1 error will occur.
Third, the power of the test also affects the likelihood of a type 1 error. The higher the power of the test, the less likely it is that a type 1 error will occur.
Finally, if there are multiple tests being conducted, the Bonferroni correction can be used to control for the possibility of a type 1 error.
All of these factors contribute to the likelihood of a type 1 error. The level of significance, sample size, power of the test, and the Bonferroni correction are all important considerations when trying to avoid a type 1 error.
Why Is It Important to Understand Type 1 Errors
It's important to understand type 1 errors because it can help you avoid making decisions based on incorrect information. If you know that there's a chance of a false positive, you can be more cautious in your interpretation of results. This is especially important when the consequences of a wrong decision could be serious.
Type 1 error is also important to understand from a statistical standpoint. When designing studies and analyzing data, researchers need to account for the possibility of false positives. Otherwise, their results could be skewed.
Overall, it's essential to have a good understanding of type 1 errors. It can help you avoid making incorrect decisions and ensure accurate research studies.
How to Reduce Type 1 Errors
Type 1 errors, also known as false positives, can occur when a test or experiment rejects the null hypothesis incorrectly. This means that there is evidence to support the alternative hypothesis when in reality, there is none. Type 1 errors can have serious consequences, especially in the field of medicine or criminal justice. For example, if a new drug is tested and found to be effective but later discovered that it actually causes more harm than good, this would be a type 1 error.
There are several ways to reduce the risk of making a type 1 error:
Use a larger sample size: The larger the sample size, the less likely it is that a type 1 error will occur. This is because there is more data to work with, and the results are more likely to be representative of the population as a whole.
Use a stricter criterion: A stricter criterion means that there is less of a chance that a false positive will be found. For example, if a medical test is looking for a very rare disease, setting a high threshold for what constitutes a positive result will help reduce the chances of a type 1 error.
Replicate the study: If possible, try to replicate the study using a different sample or method. This can help to confirm the results and reduce the chance of error.
Use multiple testing methods: Using more than one method to test for something can also help to reduce the chances of error. For example, animal and human subjects can help confirm the results if a new drug is being tested.
Be aware of potential biases: Many different types of bias can affect a study's results. Try to be aware of these and take steps to avoid them.
Use objective measures: If possible, use objective measures rather than subjective ones. Objective measures are less likely to be influenced by personal biases or preconceptions.
Be cautious in interpreting results: Remember that even if a study shows significant results, this does not necessarily mean that the null hypothesis is false. There could still be some other explanation for the results. Therefore, it is important to be cautious in interpreting the results of any study.
Type 1 errors can have serious consequences, but there are ways to reduce the risk of making one. By using large sample size, setting a strict criterion, replicating the study, or using multiple testing methods, the chances of making a type 1 error can be reduced. However, it is also important to be aware of potential biases and to interpret the results of any study cautiously.
What Is Type 2 Error
A Type II error is when we fail to reject a null hypothesis when it is actually false. This error is also known as a false negative.
Type II errors are much more serious than Type I errors. This is because if we make a Type II error, we may be making a decision that could have harmful consequences. For example, imagine that we are testing a new drug to see if it is effective in treating cancer. If we make a Type I error, we may give the drug to patients who don’t actually need it. This may not be harmful, as the drug may have no side effects. However, if we make a Type II error, we may fail to give the drug to patients who could benefit from it. This could have deadly consequences.
It is important to note that, while Type I and Type II errors are both possible, it is impossible to make both errors at the same time. This is because they are opposite errors; if we reject the null hypothesis when it is true, then we cannot fail to reject the null hypothesis when it is false (and vice versa).
What Causes a Type 2 Error
A type 2 error occurs when you fail to reject the null hypothesis, even though it is false. In other words, you conclude that there is no difference when there actually is a difference. Type 2 errors are often called false negatives.
There are several reasons why a type 2 error can occur. One reason is that the sample size is too small. With a small sample size, there is simply not enough power to detect a difference, even if one exists.
Another reason for a type 2 error is poor study design. If the study is not well-designed, it may be biased in such a way that it fails to detect a difference that actually exists. For example, if there is selection bias in the recruitment of participants, this can lead to a type 2 error.
Finally, chance plays a role in all statistical tests. Even with a large sample size and a well-designed study, there is always a possibility that a type 2 error will occur simply by chance. This is why it is important to report the p-value in addition to the significance level when presenting the results of a statistical test. The p-value tells you how likely it is that a type 2 error has occurred.
Why Is It Important to Understand Type 2 Errors
It's important to understand type 2 errors because, if you don't, you could make some serious mistakes in your research. Type 2 error is when you conclude that there is no difference between two groups when there actually is a difference. This might not seem like a big deal, but it can have some pretty serious consequences.
For example, let's say you're doing a study on the effect of a new drug. You give the drug to one group of people and a placebo to another group. After taking the drug, you measure how well each group does on a test. If there's no difference between the two groups, you might conclude that the drug doesn't work. But if there is actually a difference, and you just didn't see it because of a type 2 error, you might be keeping people from getting the help they need.
How to Reduce Type 2 Errors
There are several ways to reduce the likelihood of making a Type II error in hypothesis testing. One way is to ensure that the null and alternative hypotheses are well-defined and that the test statistic is appropriately chosen.
Another way to reduce Type II error is to increase the power of the test. This can be done by increasing the sample size or by using a more powerful test statistic.
Ultimately, it is important to consider the consequences of both Type I and Type II errors when designing a hypothesis test. Both types of errors can have serious implications, so it is important to choose a test that will minimize the probability of both types of errors.
What Is the Difference Between a Type 1 and Type 2 Error?
Two types of errors can occur when conducting statistical tests: type 1 and type 2. These terms are often used interchangeably, but there is a crucial distinction between them.
A type 1 error, also known as a false positive, occurs when the test incorrectly rejects the null hypothesis. In other words, a type 1 error means that you've concluded there is a difference when in reality, there isn't one.
A type 2 error, or false negative, happens when the test fails to reject the null hypothesis when there actually is a difference. So a type 2 error represents missing an important opportunity.
Get a weekly roundup of Ninetailed updates, curated posts, and helpful insights about the digital experience, MACH, composable, and more right into your inbox
Keep Reading on This Topic

In this blog post, we will explore nine of the most common personalization challenges and discuss how to overcome them.

What is the difference between first-party data and zero-party data? How consumer privacy affects the future of data? How to personalize customer experiences based on first-party and zero-party data?
5. Differences between means: type I and type II errors and power
Large sample standard error of difference between means.

- 3 $\begingroup$ See xkcd.com/882 for an illustrated example of Type I errors in a "real time scenario." Perhaps after reading that you could come up with an analogous example of Type II errors. $\endgroup$ – whuber ♦ Commented Aug 3, 2014 at 15:26
- 1 $\begingroup$ It is not obvious to me what "real time scenarios" means. Do you mean "real world" perhaps? $\endgroup$ – Thomas Commented Aug 3, 2014 at 19:36
- 1 $\begingroup$ Yeah Thomas,I meant real world.I have been reading few examples as given below,but what I wanted to know is that the reason why that happens.Does it have to do something with the sample size or kind of sample we take? $\endgroup$ – maddy Commented Aug 9, 2014 at 15:22
- $\begingroup$ Wikipedia makes this sound way way more complicated than it is, so thanks all answerers for the simpler explanation :) en.wikipedia.org/wiki/Type_I_and_type_II_errors#Example $\endgroup$ – Nathan majicvr.com Commented Aug 2, 2022 at 2:08
5 Answers 5
A picture is worth a thousand words. Null hypothesis: patient is not pregnant .

Image via Paul Ellis .
- $\begingroup$ ...and a word generates a thousand images. For the benefit of all readers, of all levels of knowledge and understanding, perhaps it would be useful after the picture, to explain how and why it represents examples of type I and type II errors. $\endgroup$ – Alecos Papadopoulos Commented Aug 3, 2014 at 18:36
- 1 $\begingroup$ @AlecosPapadopoulos And yet explaining humor carries its own problems. The OP has already indicated a familiarity with textbook explanation. $\endgroup$ – Alexis Commented Aug 3, 2014 at 20:03
- $\begingroup$ So, I guess the null hypothesis in the left picture is "Pregnant" and the doctor falsely asserts it ("false positive"), while in the right picture the null hypothesis is also "Pregnant" and the doctor falsely negates it (false negative)? $\endgroup$ – Alecos Papadopoulos Commented Aug 3, 2014 at 20:43
- 1 $\begingroup$ Not sure how you get that. The null hypothesis on the left is "not pregnant", and the error is Type I. Har har. The null hypothesis on the right is also "not pregnant" and the error is Type II. Har har. $\endgroup$ – Alexis Commented Aug 3, 2014 at 21:44
- $\begingroup$ You seem to have mistakenly edited your post to mention that the null hypothesis is "pregnant", whereas it is of course "not pregnant". $\endgroup$ – amoeba Commented Aug 3, 2014 at 21:55
Let's say you are testing a new drug for some disease. In a test of its effectiveness, a type I error would be to say it has an effect when it does not; a type II error would be to say it has no effect when it does.
Type I error /false positive: is same as rejecting the null when it is true.
Few Examples:
- (With the null hypothesis that the person is innocent), convicting an innocent person
- (With the null hypothesis that e-mail is non-spam), non-spam mail is sent to spam box
- (With the null hypothesis that there is no metal present in passenger's bag), metal detector beeps (detects metal) for a bag with no metal
Type II error /false negative: is similar to accepting the null when it is false.
(With the null hypothesis that the person is innocent), letting a guilty person go free.
(With the null hypothesis that e-mail is non-spam), Spam mail is sent to Inbox
(With the null hypothesis that there is no metal present in passenger's bag), metal detector fails to beep (does not detect metal) for a bag with metal in it
Other beautiful examples in layman's terms are give here:
Is there a way to remember the definitions of Type I and Type II Errors?
- $\begingroup$ In Type II (false negative), shouldn't it be "spam email is sent to inbox"? $\endgroup$ – Celdor Commented Dec 18, 2017 at 13:01
The boy who cried wolf.
I am not sure who is who in the fable but the basic idea is that the two types of errors (Type I and Type II) are timely ordered in the famous fable.
Type I : villagers ( scientists ) believe there is a wolf ( effect in population ), since the boy cried wolf, but in reality there is not any.
Type II : villagers ( scientists ) believe there is not any wolf ( effect in population ), although the boy cries wolf, and in reality there is a wolf.
Never been a fan of a examples that taught which one is "worse" as (in my opinion) it is dependent on a problem at hand.
Null hypothesis is: "Today is not my friends birthday."
- Type I error: My friend does not have birthday today but I will wish her happy birthday.
- Type II error: My friend has birthday today but I don't wish her happy birthday.
- 1 $\begingroup$ These are not serious answers. $\endgroup$ – Michael R. Chernick Commented Feb 14, 2018 at 17:35
Your Answer
Sign up or log in, post as a guest.
Required, but never shown
By clicking “Post Your Answer”, you agree to our terms of service and acknowledge you have read our privacy policy .
Not the answer you're looking for? Browse other questions tagged statistical-significance type-i-and-ii-errors or ask your own question .
- Featured on Meta
- Upcoming initiatives on Stack Overflow and across the Stack Exchange network...
- Announcing a change to the data-dump process
Hot Network Questions
- Incompatibility between times and tcolorbox with breakable
- Tale of two servers. What could be limiting queries to running on two cores? MDOP set to 16
- What factors need to be taken into account in assessing the meaning of "the will of God" in Mark 3:35?
- Translation closest to original Heraclitus quote "no man steps in the same river twice, for it is not the same river and he is not the same man"
- What magic items can a druid in animal form still access?
- Why would these two populations be genetically compatible?
- Can one be restricted from carrying a gun on the metro in New York city?
- Why did Kamala Harris once describe her own appearance at the start of an important meeting?
- How were the permutations calculated in God's Playground?
- Examples of the most subordinate infinitive clauses combined in one sentence
- How does one go from wavefunctions to fields?
- Short story where a scientist develops a virus that renders everyone on Earth sterile
- Factoriadic Fraction Addition
- What are applicable skills and abilities for dealing with paperwork, administration and law in 5e?
- When we say "roll out" a product, do we mean like a carpet or like a car?
- Alternatives to mathml for PDF Tagging
- Canola and dishwasher
- What to do about chain rubbing on unusually placed chainstay?
- How do jet engine turbines blades rotate in different directions?
- What is the intuition behind calculation of the area of circle?
- "mdadm --grow" is stuck. How can I safely cancel the operation?
- How to choose correct resistor values when designing a circuit?
- Seeking optimization modelling problems involving non-continuous or non-interval defined functions for teaching
- N-MOS failing short on my PCB

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
Curbing type I and type II errors
Kenneth j. rothman.
RTI Health Solutions, Research Triangle Park, NC USA
The statistical education of scientists emphasizes a flawed approach to data analysis that should have been discarded long ago. This defective method is statistical significance testing. It degrades quantitative findings into a qualitative decision about the data. Its underlying statistic, the P -value, conflates two important but distinct aspects of the data, effect size and precision [ 1 ]. It has produced countless misinterpretations of data that are often amusing for their folly, but also hair-raising in view of the serious consequences.
Significance testing maintains its hold through brilliant marketing tactics—the appeal of having a “significant” result is nearly irresistible—and through a herd mentality. Novices quickly learn that significant findings are the key to publication and promotion, and that statistical significance is the mantra of many senior scientists who will judge their efforts. Stang et al. [ 2 ], in this issue of the journal, liken the grip of statistical significance testing on the biomedical sciences to tyranny, as did Loftus in the social sciences two decades ago [ 3 ]. The tyranny depends on collaborators to maintain its stranglehold. Some collude because they do not know better. Others do so because they lack the backbone to swim against the tide.
Students of significance testing are warned about two types of errors, type I and II, also known as alpha and beta errors. A type I error is a false positive, rejecting a null hypothesis that is correct. A type II error is a false negative, a failure to reject a null hypothesis that is false. A large literature, much of it devoted to the topic of multiple comparisons, subgroup analysis, pre-specification of hypotheses, and related topics, are aimed at reducing type I errors [ 4 ]. This lopsided emphasis on type I errors comes at the expense of type II errors. The type I error, the false positive, is only possible if the null hypothesis is true. If the null hypothesis is false, a type I error is impossible, but a type II error, the false negative, can occur.
Type I and type II errors are the product of forcing the results of a quantitative analysis into the mold of a decision, which is whether to reject or not to reject the null hypothesis. Reducing interpretations to a dichotomy, however, seriously degrades the information. The consequence is often a misinterpretation of study results, stemming from a failure to separate effect size from precision. Both effect size and precision need to be assessed, but they need to be assessed separately, rather than blended into the P -value, which is then degraded into a dichotomous decision about statistical significance.
As an example of what can happen when significance testing is exalted beyond reason, consider the case of the Wall Street Journal investigative reporter who broke the news of a scandal about a medical device maker, Boston Scientific, having supposedly distorted study results [ 5 ]. Boston Scientific reported to the FDA that a new device was better than a competing device. They based their conclusion in part on results from a randomized trial in which the significance test showing the superiority of their device had a P -value of 0.049, just under the criterion of 0.05 that the FDA used statistical significance. The reporter found, however, that the P -value was not significant when calculated using 16 other test procedures that he tried. The P -values from those procedures averaged 0.051. According to the news story, that small difference between the reported P -value of 0.049 and the journalist’s recalculated P -value of 0.051 was “the difference between success and failure” [ 5 ]. Regardless of what the “correct” P -value is for the data in question, it should be obvious that it is absurd to classify the success or failure of this new device according to whether or not the P -value falls barely on one side or the other of an arbitrary line, especially when the discussion revolves around the third decimal place of the P -value. No sensible interpretation of the data from the study should be affected by the news in this newspaper report. Unfortunately, the arbitrary standard imposed by regulatory agencies, which foster that focus on the P -value, reduces the prospects for more sensible evaluations.
In their article, Stang et al. [ 2 ] not only describe the problems with significance testing, but also allude to the solution, which is to rely on estimation using confidence intervals. Sadly, although the use of confidence intervals is increasing, for many readers and authors they are used only as surrogate tests of statistical significance [ 6 ], to note whether the null hypothesis value falls inside the interval or not. This dichotomy is equivalent to the dichotomous interpretation that results from significance testing. When confidence intervals are misused in this way, the entire conclusion can depend on whether the boundary of the interval is located precisely on one side or the other of an artificial criterion point. This is just the kind of mistake that tripped up the Wall Street Journal reporter. Using a confidence interval as a significance test is an opportunity lost.
How should a confidence interval be interpreted? It should be approached in the spirit of a quantitative estimate. A confidence interval allows a measurement of both effect size and precision, the two aspects of study data that are conflated in a P -value. A properly interpreted confidence interval allows these two aspects of the results to be inferred separately and quantitatively. The effect size is measured directly by the point estimate, which, if not given explicitly, can be calculated from the two confidence limits. For a difference measure, the point estimate is the arithmetic mean of the two limits, and for a ratio measure, it is the geometric mean. Precision is measured by the narrowness of the confidence interval. Thus, the two limits of a confidence interval convey information on both effect size and precision. The single number that is the P -value, even without degrading it into categories of “significant” and “not significant”, cannot measure two distinct things. Instead the P -value mixes effect size and precision in a way that by itself reveals little about either.
Scientists who wish to avoid type I or type II errors at all costs may have chosen the wrong profession, because making and correcting mistakes are inherent to science. There is a way, however, to minimize both type I and type II errors. All that is needed is simply to abandon significance testing. If one does not impose an artificial and potentially misleading dichotomous interpretation upon the data, one can reduce all type I and type II errors to zero. Instead of significance testing, one can rely on confidence intervals, interpreted quantitatively, not simply as surrogate significance tests. Only then would the analyses be truly quantitative.
Finally, here is a gratuitous bit of advice for testers and estimators alike: both P -values and confidence intervals are calculated and all too often interpreted as if the study they came from were free of bias. In reality, every study is biased to some extent. Even those who wisely eschew significance testing should keep in mind that if any study were increased in size, its precision would improve and thus all its confidence intervals would shrink, but as they do, they would eventually converge around incorrect values as a result of bias. The final interpretation should measure effect size and precision separately, while considering bias and even correcting for it [ 7 ].
Open Access
This article is distributed under the terms of the Creative Commons Attribution Noncommercial License which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
- School Guide
- Mathematics
- Number System and Arithmetic
- Trigonometry
- Probability
- Mensuration
- Maths Formulas
- Class 8 Maths Notes
- Class 9 Maths Notes
- Class 10 Maths Notes
- Class 11 Maths Notes
- Class 12 Maths Notes
Type I and Type II Errors
Type I and Type II Errors are central for hypothesis testing in general, which subsequently impacts various aspects of science including but not limited to statistical analysis. False discovery refers to a Type I error where a true Null Hypothesis is incorrectly rejected. On the other end of the spectrum, Type II errors occur when a true null hypothesis fails to get rejected.
In this article, we will discuss Type I and Type II Errors in detail, including examples and differences.

Table of Content
Type I and Type II Error in Statistics
What is error, what is type i error (false positive), what is type ii error (false negative), type i and type ii errors – table, type i and type ii errors examples, examples of type i error, examples of type ii error, factors affecting type i and type ii errors, how to minimize type i and type ii errors, difference between type i and type ii errors.
In statistics , Type I and Type II errors represent two kinds of errors that can occur when making a decision about a hypothesis based on sample data. Understanding these errors is crucial for interpreting the results of hypothesis tests.
In the statistics and hypothesis testing , an error refers to the emergence of discrepancies between the result value based on observation or calculation and the actual value or expected value.
The failures may happen in different factors, such as turbulent sampling, unclear implementation, or faulty assumptions. Errors can be of many types, such as
- Measurement Error
- Calculation Error
- Human Error
- Systematic Error
- Random Error
In hypothesis testing, it is often clear which kind of error is the problem, either a Type I error or a Type II one.
Type I error, also known as a false positive , occurs in statistical hypothesis testing when a null hypothesis that is actually true is rejected. In other words, it’s the error of incorrectly concluding that there is a significant effect or difference when there isn’t one in reality.
In hypothesis testing, there are two competing hypotheses:
- Null Hypothesis (H 0 ): This hypothesis represents a default assumption that there is no effect, no difference, or no relationship in the population being studied.
- Alternative Hypothesis (H 1 ): This hypothesis represents the opposite of the null hypothesis. It suggests that there is a significant effect, difference, or relationship in the population.
A Type I error occurs when the null hypothesis is rejected based on the sample data, even though it is actually true in the population.
Type II error, also known as a false negative , occurs in statistical hypothesis testing when a null hypothesis that is actually false is not rejected. In other words, it’s the error of failing to detect a significant effect or difference when one exists in reality.
A Type II error occurs when the null hypothesis is not rejected based on the sample data, even though it is actually false in the population. In other words, it’s a failure to recognize a real effect or difference.
Suppose a medical researcher is testing a new drug to see if it’s effective in treating a certain condition. The null hypothesis (H 0 ) states that the drug has no effect, while the alternative hypothesis (H 1 ) suggests that the drug is effective. If the researcher conducts a statistical test and fails to reject the null hypothesis (H 0 ), concluding that the drug is not effective, when in fact it does have an effect, this would be a Type II error.
The table given below shows the relationship between True and False:
| Error Type | Description | Also Known as | When It Occurs |
|---|---|---|---|
| Type I | Rejecting a true null hypothesis | False Positive | You believe there is an effect or difference when there isn’t |
| Type II | Failing to reject a false null hypothesis | False Negative | You believe there is no effect or difference when there is |
Some of examples of type I error include:
- Medical Testing : Suppose a medical test is designed to diagnose a particular disease. The null hypothesis ( H 0 ) is that the person does not have the disease, and the alternative hypothesis ( H 1 ) is that the person does have the disease. A Type I error occurs if the test incorrectly indicates that a person has the disease (rejects the null hypothesis) when they do not actually have it.
- Legal System : In a criminal trial, the null hypothesis ( H 0 ) is that the defendant is innocent, while the alternative hypothesis ( H 1 ) is that the defendant is guilty. A Type I error occurs if the jury convicts the defendant (rejects the null hypothesis) when they are actually innocent.
- Quality Control : In manufacturing, quality control inspectors may test products to ensure they meet certain specifications. The null hypothesis ( H 0 ) is that the product meets the required standard, while the alternative hypothesis ( H 1 ) is that the product does not meet the standard. A Type I error occurs if a product is rejected (null hypothesis is rejected) as defective when it actually meets the required standard.
Using the same H 0 and H 1 , some examples of type II error include:
- Medical Testing : In a medical test designed to diagnose a disease, a Type II error occurs if the test incorrectly indicates that a person does not have the disease (fails to reject the null hypothesis) when they actually do have it.
- Legal System : In a criminal trial, a Type II error occurs if the jury acquits the defendant (fails to reject the null hypothesis) when they are actually guilty.
- Quality Control : In manufacturing, a Type II error occurs if a defective product is accepted (fails to reject the null hypothesis) as meeting the required standard.
Some of the common factors affecting errors are:
- Sample Size: In statistical hypothesis testing, larger sample sizes generally reduce the probability of both Type I and Type II errors. With larger samples, the estimates tend to be more precise, resulting in more accurate conclusions.
- Significance Level: The significance level (α) in hypothesis testing determines the probability of committing a Type I error. Choosing a lower significance level reduces the risk of Type I error but increases the risk of Type II error, and vice versa.
- Effect Size: The magnitude of the effect or difference being tested influences the probability of Type II error. Smaller effect sizes are more challenging to detect, increasing the likelihood of failing to reject the null hypothesis when it’s false.
- Statistical Power: The power of Statistics (1 – β) dictates that the opportunity for rejecting a wrong null hypothesis is based on the inverse of the chance of committing a Type II error. The power level of the test rises, thus a chance of the Type II error dropping.
To minimize Type I and Type II errors in hypothesis testing, there are several strategies that can be employed based on the information from the sources provided:
- By setting a lower significance level, the chances of incorrectly rejecting the null hypothesis decrease, thus minimizing Type I errors.
- Increasing the sample size reduces the variability of the statistic, making it less likely to fall in the non-rejection region when it should be rejected, thus minimizing Type II errors.
Some of the key differences between Type I and Type II Errors are listed in the following table:
| Aspect | Type I Error | Type II Error |
|---|---|---|
| Definition | Incorrectly rejecting a true null hypothesis | Failing to reject a false null hypothesis |
| Also known as | False positive | False negative |
| Probability symbol | α (alpha) | β (beta) |
| Example | Concluding that a person has a disease when they do not (false alarm) | Concluding that a person does not have a disease when they do (missed diagnosis) |
| Prevention strategy | Adjusting the significance level (α) | Increasing sample size or effect size (to increase power) |
Conclusion – Type I and Type II Errors
In conclusion, type I errors occur when we mistakenly reject a true null hypothesis, while Type II errors happen when we fail to reject a false null hypothesis. Being aware of these errors helps us make more informed decisions, minimizing the risks of false conclusions.
People Also Read:
Difference between Null and Alternate Hypothesis Z-Score Table
Type I and Type II Errors – FAQs
What is type i error.
Type I Error occurs when a null hypothesis is incorrectly rejected, indicating a false positive result, concluding that there is an effect or difference when there isn’t one.
What is an Example of a Type 1 Error?
An example of Type I Error is that convicting an innocent person (null hypothesis: innocence) based on insufficient evidence, incorrectly rejecting the null hypothesis of innocence.
What is Type II Error?
Type II Error happens when a null hypothesis is incorrectly accepted, failing to detect a true effect or difference when one actually exists.
What is an Example of a Type 2 Error?
An example of type 2 error is that failing to diagnose a disease in a patient (null hypothesis: absence of disease) despite them actually having the disease, incorrectly failing to reject the null hypothesis.
What is the difference between Type 1 and Type 2 Errors?
Type I error involves incorrectly rejecting a true null hypothesis, while Type II error involves failing to reject a false null hypothesis. In simpler terms, Type I error is a false positive, while Type II error is a false negative.
What is Type 3 Error?
Type 3 Error is not a standard statistical term. It’s sometimes informally used to describe situations where the researcher correctly rejects the null hypothesis but for the wrong reason, often due to a flaw in the experimental design or analysis.
How are Type I and Type II Errors related to hypothesis testing?
In hypothesis testing, Type I Error relates to the significance level (α), which represents the probability of rejecting a true null hypothesis. Type II Error relates to the power of the test (β), which represents the probability of failing to reject a false null hypothesis.
What are some examples of Type I and Type II Errors?
Type I Error: Rejecting a null hypothesis that a new drug has no side effects when it actually does (false positive). Type II Error: Failing to reject a null hypothesis that a new drug has no effect when it actually does (false negative).
How can one minimize Type I and Type II Errors?
Type I Error can be minimized by choosing a lower significance level (α) for hypothesis testing. Type II Error can be minimized by increasing the sample size or improving the sensitivity of the test.
What is the relationship between Type I and Type II Errors?
There is often a trade-off between Type I and Type II Errors. Decreasing the probability of one type of error typically increases the probability of the other.
How do Type I and Type II Errors impact decision-making?
Type I Errors can lead to false conclusions, such as mistakenly believing a treatment is effective when it’s not. Type II Errors can result in missed opportunities, such as failing to identify an effective treatment.
In which fields are Type I and Type II Errors commonly encountered?
Type I and Type II Errors are encountered in various fields, including medical research, quality control, criminal justice, and market research.

Please Login to comment...
Similar reads, improve your coding skills with practice.
What kind of Experience do you want to share?
Data Management Analyst III
Apply now Job no: 532410 Work type: Staff Full-Time Location: Main Campus (Gainesville, FL) Categories: Computer Science, Information Technology, Artificial Intelligence, Engineering, Physical/Mathematical Sciences Department: 29240101 - MD-HOBI-GENERAL
| Classification Title: | Data Management Analyst III |
|---|---|
| Job Description: | |
| Expected Salary: | $85,000; Commensurate with education and experience. |
| Minimum Requirements: | Master’s degree in an appropriate area and two years of relevant experience; or a bachelor’s degree in an appropriate area and four years of relevant experience. |
| Preferred Qualifications: | Doctorate or master’s degree in outcomes research, statistics, information systems, biomedical informatics or related field and two years of relevant experience. In-depth knowledge of health outcomes study design. Experience with general statistical software (e.g. R, SAS). Experience with machine learning frameworks (R, Python, Weka, RapidMiner, etc). Excellent technical writing and communication skills. Knowledge of basic principles of clinical and data science research. Ability to plan, organize and coordinate work assignments. Ability to work effectively and independently. Ability to communicate effectively verbally and in writing. Ability to establish and maintain effective working relationships with others. |
| Special Instructions to Applicants: | In order to be considered, you must upload your cover letter and resume. Application must be submitted by 11:55 p.m. (ET) of the posting end date. This is a time limited position. The University of Florida is committed to non-discrimination with respect to race, creed, color, religion, age, disability, sex, sexual orientation, gender identity and expression, marital status, national origin, political opinions or affiliations, genetic information and veteran status in all aspects of employment including recruitment, hiring, promotions, transfers, discipline, terminations, wage and salary administration, benefits, and training. |
| Health Assessment Required: | No |
Advertised: 22 Jul 2024 Eastern Daylight Time Applications close: 04 Aug 2024 Eastern Daylight Time
Back to search results Apply now Refer a friend
Search results
| Position | Department | Location | Closes |
|---|---|---|---|
| 29240101 - MD-HOBI-GENERAL | Main Campus (Gainesville, FL) | ||
| We are recruiting a Data Management Analyst III in the Department of Health Outcomes and Biomedical Informatics (HOBI) at the University of Florida. The Data Management Analyst will participate in data driven research activities in the UF Health Cancer Center Cancer Informatics Shared Resource. This position will work with large real-world clinical datasets such as electronic health records in the OneFlorida+ Clinical Research Consortium and UF Health IDR. Responsibilities include: 1) Designing and managing data analysis projects using the above databases. 2) Participation in the design and implementation of research and evaluation studies. 3) Developing data queries and processing scripts to prepare raw data for analysis. 4) Conducting statistical data analyses and interpreting results. 5) Assisting with data collection, reporting and contributing to scientific reports, conference papers, and journal articles. | |||
Current Opportunities
Powered by PageUp
Refine search
- Staff Full-Time 1
- Artificial Intelligence 1
- Computer Science 1
- Engineering 1
- Information Technology 1
- Physical/Mathematical Sciences 1
- Main Campus (Gainesville, FL) 1
- 29240101 - MD-HOBI-GENERAL 1
- Frequently Asked Questions
- Veteran Preference
- Applicant Tutorial
- UF Hiring Policies
- Disclosure of Campus Security Policy and Campus Crime Statistics
- Institute of Food and Agricultural Sciences Faculty Positions
- Labor Condition Application (ETA Form 9035): Notice of Filings
- Application for Permanent Employment Certification (ETA Form 9089): Notice of Job Availability
- Search Committee Public Meeting Notices
- Accessibility at UF
- Drug and Alcohol Abuse Prevention Program (DAAPP)
- Drug-Free Workplace
Equal Opportunity Employer
The University is committed to non-discrimination with respect to race, creed, color, religion, age, disability, sex, sexual orientation, gender identity and expression, marital status, national origin, political opinions or affiliations, genetic information and veteran status in all aspects of employment including recruitment, hiring, promotions, transfers, discipline, terminations, wage and salary administration, benefits, and training.
We will email you new jobs that match this search.
Ok, we will send you jobs like this.
The email address was invalid, please check for errors.
You must agree to the privacy statement
IMAGES
VIDEO
COMMENTS
Using hypothesis testing, you can make decisions about whether your data support or refute your research predictions with null and alternative hypotheses. ... Type I & Type II Errors | Differences, Examples, Visualizations. Scribbr.
Yes, there are ethical implications associated with Type I and Type II errors in psychological research. Type I errors may lead to false positive findings, resulting in misleading conclusions and potentially wasting resources on ineffective interventions. This can harm individuals who are falsely diagnosed or receive unnecessary treatments.
Healthcare professionals, when determining the impact of patient interventions in clinical studies or research endeavors that provide evidence for clinical practice, must distinguish well-designed studies with valid results from studies with research design or statistical flaws. This article will help providers determine the likelihood of type I or type II errors and judge adequacy of ...
Since in a real experiment it is impossible to avoid all type I and type II errors, it is important to consider the amount of risk one is willing to take to falsely reject H 0 or accept H 0.The solution to this question would be to report the p-value or significance level α of the statistic. For example, if the p-value of a test statistic result is estimated at 0.0596, then there is a ...
Potential Outcomes in Hypothesis Testing. Hypothesis testing is a procedure in inferential statistics that assesses two mutually exclusive theories about the properties of a population. For a generic hypothesis test, the two hypotheses are as follows:
Statistical significance is a term used by researchers to state that it is unlikely their observations could have occurred under the null hypothesis of a statistical test.Significance is usually denoted by a p-value, or probability value.. Statistical significance is arbitrary - it depends on the threshold, or alpha value, chosen by the researcher.
Schematic example of type I and type II errors. Figure 1 shows a schematic example of relative sampling distributions under a null hypothesis (H 0) and an alternative hypothesis (H 1). Let's suppose they are two sampling distributions of sample means (X).
Internal Validity in Research: Definition, Threats, Examples. In this article, we will discuss the concept of internal validity, some clear examples, its importance, and how to test it.
In this setting, Type I and Type II errors are fundamental concepts to help us interpret the results of the hypothesis test. 1 They are also vital components when calculating a study sample size. 2, 3 We have already briefly met these concepts in previous Research Design and Statistics articles 2, 4 and here we shall consider them in more detail.
6.1 - Type I and Type II Errors. When conducting a hypothesis test there are two possible decisions: reject the null hypothesis or fail to reject the null hypothesis. You should remember though, hypothesis testing uses data from a sample to make an inference about a population. When conducting a hypothesis test we do not know the population ...
When conducting a hypothesis test, we could: Reject the null hypothesis when there is a genuine effect in the population;; Fail to reject the null hypothesis when there isn't a genuine effect in the population.; However, as we are inferring results from samples and using probabilities to do so, we are never working with 100% certainty of the presence or absence of an effect.
This will help to keep the research effort focused on the primary objective and create a stronger basis for interpreting the study's results as compared to a hypothesis that emerges as a result of inspecting the data. ... The investigator establishes the maximum chance of making type I and type II errors in advance of the study. The ...
Briefly: Type I errors happen when we reject a true null hypothesis. Type II errors happen when we fail to reject a false null hypothesis. We will explore more background behind these types of errors with the goal of understanding these statements.
The remainder of this article explores how type I and type II errors arise in research. First, the symbols that are used throughout the article are explained, including a summary table. The next section examines the initial decision-making process regarding the formation of hypothesis. More specifically, attention is given to the reasons for ...
Thanks, the simplicity of your illusrations in essay and tables is great contribution to the demystification of statistics.
Anupama Sapkota has a bachelor's degree (B.Sc.) in Microbiology from St. Xavier's College, Kathmandu, Nepal. She is particularly interested in studies regarding antibiotic resistance with a focus on drug discovery.
Replication. This is the key reason why scientific experiments must be replicable.. Even if the highest level of proof is reached, where P < 0.01 (probability is less than 1%), out of every 100 experiments, there will still be one false result.To a certain extent, duplicate or triplicate samples reduce the chance of error, but may still mask chance if the error-causing variable is present in ...
Two types of errors can occur when conducting statistical tests: type 1 and type 2. These terms are often used interchangeably, but there is a crucial distinction between them. A type 1 error, also known as a false positive, occurs when the test incorrectly rejects the null hypothesis.
Research. Education. News & Views. Campaigns. Jobs. Archive For authors Hosted. Search. covid-19. Research. Education. News & Views ... Differences between means: type I and type II errors and power. Exercises. 5.1 In one group of 62 patients with iron deficiency anaemia the haemoglobin level was 1 2.2 g/dl, standard deviation 1.8 g/dl; in ...
1. Null hypothesis is: "Today is not my friends birthday." Type I error: My friend does not have birthday today but I will wish her happy birthday. Type II error: My friend has birthday today but I don't wish her happy birthday. Share.
Type I and type II errors are the product of forcing the results of a quantitative analysis into the mold of a decision, which is whether to reject or not to reject the null hypothesis. Reducing interpretations to a dichotomy, however, seriously degrades the information. The consequence is often a misinterpretation of study results, stemming ...
Type I and Type II Errors are central for hypothesis testing in general, which subsequently impacts various aspects of science including but not limited to statistical analysis. ... Type I and Type II Errors are encountered in various fields, including medical research, quality control, criminal justice, and market research. indrasingh_dhurve ...
OneFlorida+ Clinical Research Consortium and UF Health IDR. Responsibilities include: 1) Designing and managing data analysis projects using the above databases. 2) Participation in the design and implementation of research and evaluation studies. 3) Developing data queries and processing scripts to prepare raw data for analysis.