Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, automatically generate references for free.
- Knowledge Base
- Methodology

Research Design | Step-by-Step Guide with Examples
Published on 5 May 2022 by Shona McCombes . Revised on 20 March 2023.
A research design is a strategy for answering your research question using empirical data. Creating a research design means making decisions about:
- Your overall aims and approach
- The type of research design you’ll use
- Your sampling methods or criteria for selecting subjects
- Your data collection methods
- The procedures you’ll follow to collect data
- Your data analysis methods
A well-planned research design helps ensure that your methods match your research aims and that you use the right kind of analysis for your data.
Table of contents
Step 1: consider your aims and approach, step 2: choose a type of research design, step 3: identify your population and sampling method, step 4: choose your data collection methods, step 5: plan your data collection procedures, step 6: decide on your data analysis strategies, frequently asked questions.
- Introduction
Before you can start designing your research, you should already have a clear idea of the research question you want to investigate.
There are many different ways you could go about answering this question. Your research design choices should be driven by your aims and priorities – start by thinking carefully about what you want to achieve.
The first choice you need to make is whether you’ll take a qualitative or quantitative approach.
| Qualitative approach | Quantitative approach |
|---|---|
Qualitative research designs tend to be more flexible and inductive , allowing you to adjust your approach based on what you find throughout the research process.
Quantitative research designs tend to be more fixed and deductive , with variables and hypotheses clearly defined in advance of data collection.
It’s also possible to use a mixed methods design that integrates aspects of both approaches. By combining qualitative and quantitative insights, you can gain a more complete picture of the problem you’re studying and strengthen the credibility of your conclusions.
Practical and ethical considerations when designing research
As well as scientific considerations, you need to think practically when designing your research. If your research involves people or animals, you also need to consider research ethics .
- How much time do you have to collect data and write up the research?
- Will you be able to gain access to the data you need (e.g., by travelling to a specific location or contacting specific people)?
- Do you have the necessary research skills (e.g., statistical analysis or interview techniques)?
- Will you need ethical approval ?
At each stage of the research design process, make sure that your choices are practically feasible.
Prevent plagiarism, run a free check.
Within both qualitative and quantitative approaches, there are several types of research design to choose from. Each type provides a framework for the overall shape of your research.
Types of quantitative research designs
Quantitative designs can be split into four main types. Experimental and quasi-experimental designs allow you to test cause-and-effect relationships, while descriptive and correlational designs allow you to measure variables and describe relationships between them.
| Type of design | Purpose and characteristics |
|---|---|
| Experimental | |
| Quasi-experimental | |
| Correlational | |
| Descriptive |
With descriptive and correlational designs, you can get a clear picture of characteristics, trends, and relationships as they exist in the real world. However, you can’t draw conclusions about cause and effect (because correlation doesn’t imply causation ).
Experiments are the strongest way to test cause-and-effect relationships without the risk of other variables influencing the results. However, their controlled conditions may not always reflect how things work in the real world. They’re often also more difficult and expensive to implement.
Types of qualitative research designs
Qualitative designs are less strictly defined. This approach is about gaining a rich, detailed understanding of a specific context or phenomenon, and you can often be more creative and flexible in designing your research.
The table below shows some common types of qualitative design. They often have similar approaches in terms of data collection, but focus on different aspects when analysing the data.
| Type of design | Purpose and characteristics |
|---|---|
| Grounded theory | |
| Phenomenology |
Your research design should clearly define who or what your research will focus on, and how you’ll go about choosing your participants or subjects.
In research, a population is the entire group that you want to draw conclusions about, while a sample is the smaller group of individuals you’ll actually collect data from.
Defining the population
A population can be made up of anything you want to study – plants, animals, organisations, texts, countries, etc. In the social sciences, it most often refers to a group of people.
For example, will you focus on people from a specific demographic, region, or background? Are you interested in people with a certain job or medical condition, or users of a particular product?
The more precisely you define your population, the easier it will be to gather a representative sample.
Sampling methods
Even with a narrowly defined population, it’s rarely possible to collect data from every individual. Instead, you’ll collect data from a sample.
To select a sample, there are two main approaches: probability sampling and non-probability sampling . The sampling method you use affects how confidently you can generalise your results to the population as a whole.
| Probability sampling | Non-probability sampling |
|---|---|
Probability sampling is the most statistically valid option, but it’s often difficult to achieve unless you’re dealing with a very small and accessible population.
For practical reasons, many studies use non-probability sampling, but it’s important to be aware of the limitations and carefully consider potential biases. You should always make an effort to gather a sample that’s as representative as possible of the population.
Case selection in qualitative research
In some types of qualitative designs, sampling may not be relevant.
For example, in an ethnography or a case study, your aim is to deeply understand a specific context, not to generalise to a population. Instead of sampling, you may simply aim to collect as much data as possible about the context you are studying.
In these types of design, you still have to carefully consider your choice of case or community. You should have a clear rationale for why this particular case is suitable for answering your research question.
For example, you might choose a case study that reveals an unusual or neglected aspect of your research problem, or you might choose several very similar or very different cases in order to compare them.
Data collection methods are ways of directly measuring variables and gathering information. They allow you to gain first-hand knowledge and original insights into your research problem.
You can choose just one data collection method, or use several methods in the same study.
Survey methods
Surveys allow you to collect data about opinions, behaviours, experiences, and characteristics by asking people directly. There are two main survey methods to choose from: questionnaires and interviews.
| Questionnaires | Interviews |
|---|---|
Observation methods
Observations allow you to collect data unobtrusively, observing characteristics, behaviours, or social interactions without relying on self-reporting.
Observations may be conducted in real time, taking notes as you observe, or you might make audiovisual recordings for later analysis. They can be qualitative or quantitative.
| Quantitative observation | |
|---|---|
Other methods of data collection
There are many other ways you might collect data depending on your field and topic.
| Field | Examples of data collection methods |
|---|---|
| Media & communication | Collecting a sample of texts (e.g., speeches, articles, or social media posts) for data on cultural norms and narratives |
| Psychology | Using technologies like neuroimaging, eye-tracking, or computer-based tasks to collect data on things like attention, emotional response, or reaction time |
| Education | Using tests or assignments to collect data on knowledge and skills |
| Physical sciences | Using scientific instruments to collect data on things like weight, blood pressure, or chemical composition |
If you’re not sure which methods will work best for your research design, try reading some papers in your field to see what data collection methods they used.
Secondary data
If you don’t have the time or resources to collect data from the population you’re interested in, you can also choose to use secondary data that other researchers already collected – for example, datasets from government surveys or previous studies on your topic.
With this raw data, you can do your own analysis to answer new research questions that weren’t addressed by the original study.
Using secondary data can expand the scope of your research, as you may be able to access much larger and more varied samples than you could collect yourself.
However, it also means you don’t have any control over which variables to measure or how to measure them, so the conclusions you can draw may be limited.
As well as deciding on your methods, you need to plan exactly how you’ll use these methods to collect data that’s consistent, accurate, and unbiased.
Planning systematic procedures is especially important in quantitative research, where you need to precisely define your variables and ensure your measurements are reliable and valid.
Operationalisation
Some variables, like height or age, are easily measured. But often you’ll be dealing with more abstract concepts, like satisfaction, anxiety, or competence. Operationalisation means turning these fuzzy ideas into measurable indicators.
If you’re using observations , which events or actions will you count?
If you’re using surveys , which questions will you ask and what range of responses will be offered?
You may also choose to use or adapt existing materials designed to measure the concept you’re interested in – for example, questionnaires or inventories whose reliability and validity has already been established.
Reliability and validity
Reliability means your results can be consistently reproduced , while validity means that you’re actually measuring the concept you’re interested in.
| Reliability | Validity |
|---|---|
For valid and reliable results, your measurement materials should be thoroughly researched and carefully designed. Plan your procedures to make sure you carry out the same steps in the same way for each participant.
If you’re developing a new questionnaire or other instrument to measure a specific concept, running a pilot study allows you to check its validity and reliability in advance.
Sampling procedures
As well as choosing an appropriate sampling method, you need a concrete plan for how you’ll actually contact and recruit your selected sample.
That means making decisions about things like:
- How many participants do you need for an adequate sample size?
- What inclusion and exclusion criteria will you use to identify eligible participants?
- How will you contact your sample – by mail, online, by phone, or in person?
If you’re using a probability sampling method, it’s important that everyone who is randomly selected actually participates in the study. How will you ensure a high response rate?
If you’re using a non-probability method, how will you avoid bias and ensure a representative sample?
Data management
It’s also important to create a data management plan for organising and storing your data.
Will you need to transcribe interviews or perform data entry for observations? You should anonymise and safeguard any sensitive data, and make sure it’s backed up regularly.
Keeping your data well organised will save time when it comes to analysing them. It can also help other researchers validate and add to your findings.
On their own, raw data can’t answer your research question. The last step of designing your research is planning how you’ll analyse the data.
Quantitative data analysis
In quantitative research, you’ll most likely use some form of statistical analysis . With statistics, you can summarise your sample data, make estimates, and test hypotheses.
Using descriptive statistics , you can summarise your sample data in terms of:
- The distribution of the data (e.g., the frequency of each score on a test)
- The central tendency of the data (e.g., the mean to describe the average score)
- The variability of the data (e.g., the standard deviation to describe how spread out the scores are)
The specific calculations you can do depend on the level of measurement of your variables.
Using inferential statistics , you can:
- Make estimates about the population based on your sample data.
- Test hypotheses about a relationship between variables.
Regression and correlation tests look for associations between two or more variables, while comparison tests (such as t tests and ANOVAs ) look for differences in the outcomes of different groups.
Your choice of statistical test depends on various aspects of your research design, including the types of variables you’re dealing with and the distribution of your data.
Qualitative data analysis
In qualitative research, your data will usually be very dense with information and ideas. Instead of summing it up in numbers, you’ll need to comb through the data in detail, interpret its meanings, identify patterns, and extract the parts that are most relevant to your research question.
Two of the most common approaches to doing this are thematic analysis and discourse analysis .
| Approach | Characteristics |
|---|---|
| Thematic analysis | |
| Discourse analysis |
There are many other ways of analysing qualitative data depending on the aims of your research. To get a sense of potential approaches, try reading some qualitative research papers in your field.
A sample is a subset of individuals from a larger population. Sampling means selecting the group that you will actually collect data from in your research.
For example, if you are researching the opinions of students in your university, you could survey a sample of 100 students.
Statistical sampling allows you to test a hypothesis about the characteristics of a population. There are various sampling methods you can use to ensure that your sample is representative of the population as a whole.
Operationalisation means turning abstract conceptual ideas into measurable observations.
For example, the concept of social anxiety isn’t directly observable, but it can be operationally defined in terms of self-rating scores, behavioural avoidance of crowded places, or physical anxiety symptoms in social situations.
Before collecting data , it’s important to consider how you will operationalise the variables that you want to measure.
The research methods you use depend on the type of data you need to answer your research question .
- If you want to measure something or test a hypothesis , use quantitative methods . If you want to explore ideas, thoughts, and meanings, use qualitative methods .
- If you want to analyse a large amount of readily available data, use secondary data. If you want data specific to your purposes with control over how they are generated, collect primary data.
- If you want to establish cause-and-effect relationships between variables , use experimental methods. If you want to understand the characteristics of a research subject, use descriptive methods.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the ‘Cite this Scribbr article’ button to automatically add the citation to our free Reference Generator.
McCombes, S. (2023, March 20). Research Design | Step-by-Step Guide with Examples. Scribbr. Retrieved 16 July 2024, from https://www.scribbr.co.uk/research-methods/research-design/
Is this article helpful?

Shona McCombes
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
Methodology
- Guide to Experimental Design | Overview, Steps, & Examples
Guide to Experimental Design | Overview, 5 steps & Examples
Published on December 3, 2019 by Rebecca Bevans . Revised on June 21, 2023.
Experiments are used to study causal relationships . You manipulate one or more independent variables and measure their effect on one or more dependent variables.
Experimental design create a set of procedures to systematically test a hypothesis . A good experimental design requires a strong understanding of the system you are studying.
There are five key steps in designing an experiment:
- Consider your variables and how they are related
- Write a specific, testable hypothesis
- Design experimental treatments to manipulate your independent variable
- Assign subjects to groups, either between-subjects or within-subjects
- Plan how you will measure your dependent variable
For valid conclusions, you also need to select a representative sample and control any extraneous variables that might influence your results. If random assignment of participants to control and treatment groups is impossible, unethical, or highly difficult, consider an observational study instead. This minimizes several types of research bias, particularly sampling bias , survivorship bias , and attrition bias as time passes.
Table of contents
Step 1: define your variables, step 2: write your hypothesis, step 3: design your experimental treatments, step 4: assign your subjects to treatment groups, step 5: measure your dependent variable, other interesting articles, frequently asked questions about experiments.
You should begin with a specific research question . We will work with two research question examples, one from health sciences and one from ecology:
To translate your research question into an experimental hypothesis, you need to define the main variables and make predictions about how they are related.
Start by simply listing the independent and dependent variables .
| Research question | Independent variable | Dependent variable |
|---|---|---|
| Phone use and sleep | Minutes of phone use before sleep | Hours of sleep per night |
| Temperature and soil respiration | Air temperature just above the soil surface | CO2 respired from soil |
Then you need to think about possible extraneous and confounding variables and consider how you might control them in your experiment.
| Extraneous variable | How to control | |
|---|---|---|
| Phone use and sleep | in sleep patterns among individuals. | measure the average difference between sleep with phone use and sleep without phone use rather than the average amount of sleep per treatment group. |
| Temperature and soil respiration | also affects respiration, and moisture can decrease with increasing temperature. | monitor soil moisture and add water to make sure that soil moisture is consistent across all treatment plots. |
Finally, you can put these variables together into a diagram. Use arrows to show the possible relationships between variables and include signs to show the expected direction of the relationships.

Here we predict that increasing temperature will increase soil respiration and decrease soil moisture, while decreasing soil moisture will lead to decreased soil respiration.
Prevent plagiarism. Run a free check.
Now that you have a strong conceptual understanding of the system you are studying, you should be able to write a specific, testable hypothesis that addresses your research question.
| Null hypothesis (H ) | Alternate hypothesis (H ) | |
|---|---|---|
| Phone use and sleep | Phone use before sleep does not correlate with the amount of sleep a person gets. | Increasing phone use before sleep leads to a decrease in sleep. |
| Temperature and soil respiration | Air temperature does not correlate with soil respiration. | Increased air temperature leads to increased soil respiration. |
The next steps will describe how to design a controlled experiment . In a controlled experiment, you must be able to:
- Systematically and precisely manipulate the independent variable(s).
- Precisely measure the dependent variable(s).
- Control any potential confounding variables.
If your study system doesn’t match these criteria, there are other types of research you can use to answer your research question.
How you manipulate the independent variable can affect the experiment’s external validity – that is, the extent to which the results can be generalized and applied to the broader world.
First, you may need to decide how widely to vary your independent variable.
- just slightly above the natural range for your study region.
- over a wider range of temperatures to mimic future warming.
- over an extreme range that is beyond any possible natural variation.
Second, you may need to choose how finely to vary your independent variable. Sometimes this choice is made for you by your experimental system, but often you will need to decide, and this will affect how much you can infer from your results.
- a categorical variable : either as binary (yes/no) or as levels of a factor (no phone use, low phone use, high phone use).
- a continuous variable (minutes of phone use measured every night).
How you apply your experimental treatments to your test subjects is crucial for obtaining valid and reliable results.
First, you need to consider the study size : how many individuals will be included in the experiment? In general, the more subjects you include, the greater your experiment’s statistical power , which determines how much confidence you can have in your results.
Then you need to randomly assign your subjects to treatment groups . Each group receives a different level of the treatment (e.g. no phone use, low phone use, high phone use).
You should also include a control group , which receives no treatment. The control group tells us what would have happened to your test subjects without any experimental intervention.
When assigning your subjects to groups, there are two main choices you need to make:
- A completely randomized design vs a randomized block design .
- A between-subjects design vs a within-subjects design .
Randomization
An experiment can be completely randomized or randomized within blocks (aka strata):
- In a completely randomized design , every subject is assigned to a treatment group at random.
- In a randomized block design (aka stratified random design), subjects are first grouped according to a characteristic they share, and then randomly assigned to treatments within those groups.
| Completely randomized design | Randomized block design | |
|---|---|---|
| Phone use and sleep | Subjects are all randomly assigned a level of phone use using a random number generator. | Subjects are first grouped by age, and then phone use treatments are randomly assigned within these groups. |
| Temperature and soil respiration | Warming treatments are assigned to soil plots at random by using a number generator to generate map coordinates within the study area. | Soils are first grouped by average rainfall, and then treatment plots are randomly assigned within these groups. |
Sometimes randomization isn’t practical or ethical , so researchers create partially-random or even non-random designs. An experimental design where treatments aren’t randomly assigned is called a quasi-experimental design .
Between-subjects vs. within-subjects
In a between-subjects design (also known as an independent measures design or classic ANOVA design), individuals receive only one of the possible levels of an experimental treatment.
In medical or social research, you might also use matched pairs within your between-subjects design to make sure that each treatment group contains the same variety of test subjects in the same proportions.
In a within-subjects design (also known as a repeated measures design), every individual receives each of the experimental treatments consecutively, and their responses to each treatment are measured.
Within-subjects or repeated measures can also refer to an experimental design where an effect emerges over time, and individual responses are measured over time in order to measure this effect as it emerges.
Counterbalancing (randomizing or reversing the order of treatments among subjects) is often used in within-subjects designs to ensure that the order of treatment application doesn’t influence the results of the experiment.
| Between-subjects (independent measures) design | Within-subjects (repeated measures) design | |
|---|---|---|
| Phone use and sleep | Subjects are randomly assigned a level of phone use (none, low, or high) and follow that level of phone use throughout the experiment. | Subjects are assigned consecutively to zero, low, and high levels of phone use throughout the experiment, and the order in which they follow these treatments is randomized. |
| Temperature and soil respiration | Warming treatments are assigned to soil plots at random and the soils are kept at this temperature throughout the experiment. | Every plot receives each warming treatment (1, 3, 5, 8, and 10C above ambient temperatures) consecutively over the course of the experiment, and the order in which they receive these treatments is randomized. |
Finally, you need to decide how you’ll collect data on your dependent variable outcomes. You should aim for reliable and valid measurements that minimize research bias or error.
Some variables, like temperature, can be objectively measured with scientific instruments. Others may need to be operationalized to turn them into measurable observations.
- Ask participants to record what time they go to sleep and get up each day.
- Ask participants to wear a sleep tracker.
How precisely you measure your dependent variable also affects the kinds of statistical analysis you can use on your data.
Experiments are always context-dependent, and a good experimental design will take into account all of the unique considerations of your study system to produce information that is both valid and relevant to your research question.
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Student’s t -distribution
- Normal distribution
- Null and Alternative Hypotheses
- Chi square tests
- Confidence interval
- Cluster sampling
- Stratified sampling
- Data cleansing
- Reproducibility vs Replicability
- Peer review
- Likert scale
Research bias
- Implicit bias
- Framing effect
- Cognitive bias
- Placebo effect
- Hawthorne effect
- Hindsight bias
- Affect heuristic
Experimental design means planning a set of procedures to investigate a relationship between variables . To design a controlled experiment, you need:
- A testable hypothesis
- At least one independent variable that can be precisely manipulated
- At least one dependent variable that can be precisely measured
When designing the experiment, you decide:
- How you will manipulate the variable(s)
- How you will control for any potential confounding variables
- How many subjects or samples will be included in the study
- How subjects will be assigned to treatment levels
Experimental design is essential to the internal and external validity of your experiment.
The key difference between observational studies and experimental designs is that a well-done observational study does not influence the responses of participants, while experiments do have some sort of treatment condition applied to at least some participants by random assignment .
A confounding variable , also called a confounder or confounding factor, is a third variable in a study examining a potential cause-and-effect relationship.
A confounding variable is related to both the supposed cause and the supposed effect of the study. It can be difficult to separate the true effect of the independent variable from the effect of the confounding variable.
In your research design , it’s important to identify potential confounding variables and plan how you will reduce their impact.
In a between-subjects design , every participant experiences only one condition, and researchers assess group differences between participants in various conditions.
In a within-subjects design , each participant experiences all conditions, and researchers test the same participants repeatedly for differences between conditions.
The word “between” means that you’re comparing different conditions between groups, while the word “within” means you’re comparing different conditions within the same group.
An experimental group, also known as a treatment group, receives the treatment whose effect researchers wish to study, whereas a control group does not. They should be identical in all other ways.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Bevans, R. (2023, June 21). Guide to Experimental Design | Overview, 5 steps & Examples. Scribbr. Retrieved July 16, 2024, from https://www.scribbr.com/methodology/experimental-design/
Is this article helpful?

Rebecca Bevans
Other students also liked, random assignment in experiments | introduction & examples, quasi-experimental design | definition, types & examples, how to write a lab report, what is your plagiarism score.
Experimental Design: Types, Examples & Methods
Saul Mcleod, PhD
Editor-in-Chief for Simply Psychology
BSc (Hons) Psychology, MRes, PhD, University of Manchester
Saul Mcleod, PhD., is a qualified psychology teacher with over 18 years of experience in further and higher education. He has been published in peer-reviewed journals, including the Journal of Clinical Psychology.
Learn about our Editorial Process
Olivia Guy-Evans, MSc
Associate Editor for Simply Psychology
BSc (Hons) Psychology, MSc Psychology of Education
Olivia Guy-Evans is a writer and associate editor for Simply Psychology. She has previously worked in healthcare and educational sectors.
On This Page:
Experimental design refers to how participants are allocated to different groups in an experiment. Types of design include repeated measures, independent groups, and matched pairs designs.
Probably the most common way to design an experiment in psychology is to divide the participants into two groups, the experimental group and the control group, and then introduce a change to the experimental group, not the control group.
The researcher must decide how he/she will allocate their sample to the different experimental groups. For example, if there are 10 participants, will all 10 participants participate in both groups (e.g., repeated measures), or will the participants be split in half and take part in only one group each?
Three types of experimental designs are commonly used:
1. Independent Measures
Independent measures design, also known as between-groups , is an experimental design where different participants are used in each condition of the independent variable. This means that each condition of the experiment includes a different group of participants.
This should be done by random allocation, ensuring that each participant has an equal chance of being assigned to one group.
Independent measures involve using two separate groups of participants, one in each condition. For example:

- Con : More people are needed than with the repeated measures design (i.e., more time-consuming).
- Pro : Avoids order effects (such as practice or fatigue) as people participate in one condition only. If a person is involved in several conditions, they may become bored, tired, and fed up by the time they come to the second condition or become wise to the requirements of the experiment!
- Con : Differences between participants in the groups may affect results, for example, variations in age, gender, or social background. These differences are known as participant variables (i.e., a type of extraneous variable ).
- Control : After the participants have been recruited, they should be randomly assigned to their groups. This should ensure the groups are similar, on average (reducing participant variables).
2. Repeated Measures Design
Repeated Measures design is an experimental design where the same participants participate in each independent variable condition. This means that each experiment condition includes the same group of participants.
Repeated Measures design is also known as within-groups or within-subjects design .
- Pro : As the same participants are used in each condition, participant variables (i.e., individual differences) are reduced.
- Con : There may be order effects. Order effects refer to the order of the conditions affecting the participants’ behavior. Performance in the second condition may be better because the participants know what to do (i.e., practice effect). Or their performance might be worse in the second condition because they are tired (i.e., fatigue effect). This limitation can be controlled using counterbalancing.
- Pro : Fewer people are needed as they participate in all conditions (i.e., saves time).
- Control : To combat order effects, the researcher counter-balances the order of the conditions for the participants. Alternating the order in which participants perform in different conditions of an experiment.
Counterbalancing
Suppose we used a repeated measures design in which all of the participants first learned words in “loud noise” and then learned them in “no noise.”
We expect the participants to learn better in “no noise” because of order effects, such as practice. However, a researcher can control for order effects using counterbalancing.
The sample would be split into two groups: experimental (A) and control (B). For example, group 1 does ‘A’ then ‘B,’ and group 2 does ‘B’ then ‘A.’ This is to eliminate order effects.
Although order effects occur for each participant, they balance each other out in the results because they occur equally in both groups.

3. Matched Pairs Design
A matched pairs design is an experimental design where pairs of participants are matched in terms of key variables, such as age or socioeconomic status. One member of each pair is then placed into the experimental group and the other member into the control group .
One member of each matched pair must be randomly assigned to the experimental group and the other to the control group.

- Con : If one participant drops out, you lose 2 PPs’ data.
- Pro : Reduces participant variables because the researcher has tried to pair up the participants so that each condition has people with similar abilities and characteristics.
- Con : Very time-consuming trying to find closely matched pairs.
- Pro : It avoids order effects, so counterbalancing is not necessary.
- Con : Impossible to match people exactly unless they are identical twins!
- Control : Members of each pair should be randomly assigned to conditions. However, this does not solve all these problems.
Experimental design refers to how participants are allocated to an experiment’s different conditions (or IV levels). There are three types:
1. Independent measures / between-groups : Different participants are used in each condition of the independent variable.
2. Repeated measures /within groups : The same participants take part in each condition of the independent variable.
3. Matched pairs : Each condition uses different participants, but they are matched in terms of important characteristics, e.g., gender, age, intelligence, etc.
Learning Check
Read about each of the experiments below. For each experiment, identify (1) which experimental design was used; and (2) why the researcher might have used that design.
1 . To compare the effectiveness of two different types of therapy for depression, depressed patients were assigned to receive either cognitive therapy or behavior therapy for a 12-week period.
The researchers attempted to ensure that the patients in the two groups had similar severity of depressed symptoms by administering a standardized test of depression to each participant, then pairing them according to the severity of their symptoms.
2 . To assess the difference in reading comprehension between 7 and 9-year-olds, a researcher recruited each group from a local primary school. They were given the same passage of text to read and then asked a series of questions to assess their understanding.
3 . To assess the effectiveness of two different ways of teaching reading, a group of 5-year-olds was recruited from a primary school. Their level of reading ability was assessed, and then they were taught using scheme one for 20 weeks.
At the end of this period, their reading was reassessed, and a reading improvement score was calculated. They were then taught using scheme two for a further 20 weeks, and another reading improvement score for this period was calculated. The reading improvement scores for each child were then compared.
4 . To assess the effect of the organization on recall, a researcher randomly assigned student volunteers to two conditions.
Condition one attempted to recall a list of words that were organized into meaningful categories; condition two attempted to recall the same words, randomly grouped on the page.
Experiment Terminology
Ecological validity.
The degree to which an investigation represents real-life experiences.
Experimenter effects
These are the ways that the experimenter can accidentally influence the participant through their appearance or behavior.
Demand characteristics
The clues in an experiment lead the participants to think they know what the researcher is looking for (e.g., the experimenter’s body language).
Independent variable (IV)
The variable the experimenter manipulates (i.e., changes) is assumed to have a direct effect on the dependent variable.
Dependent variable (DV)
Variable the experimenter measures. This is the outcome (i.e., the result) of a study.
Extraneous variables (EV)
All variables which are not independent variables but could affect the results (DV) of the experiment. Extraneous variables should be controlled where possible.
Confounding variables
Variable(s) that have affected the results (DV), apart from the IV. A confounding variable could be an extraneous variable that has not been controlled.
Random Allocation
Randomly allocating participants to independent variable conditions means that all participants should have an equal chance of taking part in each condition.
The principle of random allocation is to avoid bias in how the experiment is carried out and limit the effects of participant variables.
Order effects
Changes in participants’ performance due to their repeating the same or similar test more than once. Examples of order effects include:
(i) practice effect: an improvement in performance on a task due to repetition, for example, because of familiarity with the task;
(ii) fatigue effect: a decrease in performance of a task due to repetition, for example, because of boredom or tiredness.
- Privacy Policy
Home » Experimental Design – Types, Methods, Guide
Experimental Design – Types, Methods, Guide
Table of Contents

Experimental Design
Experimental design is a process of planning and conducting scientific experiments to investigate a hypothesis or research question. It involves carefully designing an experiment that can test the hypothesis, and controlling for other variables that may influence the results.
Experimental design typically includes identifying the variables that will be manipulated or measured, defining the sample or population to be studied, selecting an appropriate method of sampling, choosing a method for data collection and analysis, and determining the appropriate statistical tests to use.
Types of Experimental Design
Here are the different types of experimental design:
Completely Randomized Design
In this design, participants are randomly assigned to one of two or more groups, and each group is exposed to a different treatment or condition.
Randomized Block Design
This design involves dividing participants into blocks based on a specific characteristic, such as age or gender, and then randomly assigning participants within each block to one of two or more treatment groups.
Factorial Design
In a factorial design, participants are randomly assigned to one of several groups, each of which receives a different combination of two or more independent variables.
Repeated Measures Design
In this design, each participant is exposed to all of the different treatments or conditions, either in a random order or in a predetermined order.
Crossover Design
This design involves randomly assigning participants to one of two or more treatment groups, with each group receiving one treatment during the first phase of the study and then switching to a different treatment during the second phase.
Split-plot Design
In this design, the researcher manipulates one or more variables at different levels and uses a randomized block design to control for other variables.
Nested Design
This design involves grouping participants within larger units, such as schools or households, and then randomly assigning these units to different treatment groups.
Laboratory Experiment
Laboratory experiments are conducted under controlled conditions, which allows for greater precision and accuracy. However, because laboratory conditions are not always representative of real-world conditions, the results of these experiments may not be generalizable to the population at large.
Field Experiment
Field experiments are conducted in naturalistic settings and allow for more realistic observations. However, because field experiments are not as controlled as laboratory experiments, they may be subject to more sources of error.
Experimental Design Methods
Experimental design methods refer to the techniques and procedures used to design and conduct experiments in scientific research. Here are some common experimental design methods:
Randomization
This involves randomly assigning participants to different groups or treatments to ensure that any observed differences between groups are due to the treatment and not to other factors.
Control Group
The use of a control group is an important experimental design method that involves having a group of participants that do not receive the treatment or intervention being studied. The control group is used as a baseline to compare the effects of the treatment group.
Blinding involves keeping participants, researchers, or both unaware of which treatment group participants are in, in order to reduce the risk of bias in the results.
Counterbalancing
This involves systematically varying the order in which participants receive treatments or interventions in order to control for order effects.
Replication
Replication involves conducting the same experiment with different samples or under different conditions to increase the reliability and validity of the results.
This experimental design method involves manipulating multiple independent variables simultaneously to investigate their combined effects on the dependent variable.
This involves dividing participants into subgroups or blocks based on specific characteristics, such as age or gender, in order to reduce the risk of confounding variables.
Data Collection Method
Experimental design data collection methods are techniques and procedures used to collect data in experimental research. Here are some common experimental design data collection methods:
Direct Observation
This method involves observing and recording the behavior or phenomenon of interest in real time. It may involve the use of structured or unstructured observation, and may be conducted in a laboratory or naturalistic setting.
Self-report Measures
Self-report measures involve asking participants to report their thoughts, feelings, or behaviors using questionnaires, surveys, or interviews. These measures may be administered in person or online.
Behavioral Measures
Behavioral measures involve measuring participants’ behavior directly, such as through reaction time tasks or performance tests. These measures may be administered using specialized equipment or software.
Physiological Measures
Physiological measures involve measuring participants’ physiological responses, such as heart rate, blood pressure, or brain activity, using specialized equipment. These measures may be invasive or non-invasive, and may be administered in a laboratory or clinical setting.
Archival Data
Archival data involves using existing records or data, such as medical records, administrative records, or historical documents, as a source of information. These data may be collected from public or private sources.
Computerized Measures
Computerized measures involve using software or computer programs to collect data on participants’ behavior or responses. These measures may include reaction time tasks, cognitive tests, or other types of computer-based assessments.
Video Recording
Video recording involves recording participants’ behavior or interactions using cameras or other recording equipment. This method can be used to capture detailed information about participants’ behavior or to analyze social interactions.
Data Analysis Method
Experimental design data analysis methods refer to the statistical techniques and procedures used to analyze data collected in experimental research. Here are some common experimental design data analysis methods:
Descriptive Statistics
Descriptive statistics are used to summarize and describe the data collected in the study. This includes measures such as mean, median, mode, range, and standard deviation.
Inferential Statistics
Inferential statistics are used to make inferences or generalizations about a larger population based on the data collected in the study. This includes hypothesis testing and estimation.
Analysis of Variance (ANOVA)
ANOVA is a statistical technique used to compare means across two or more groups in order to determine whether there are significant differences between the groups. There are several types of ANOVA, including one-way ANOVA, two-way ANOVA, and repeated measures ANOVA.
Regression Analysis
Regression analysis is used to model the relationship between two or more variables in order to determine the strength and direction of the relationship. There are several types of regression analysis, including linear regression, logistic regression, and multiple regression.
Factor Analysis
Factor analysis is used to identify underlying factors or dimensions in a set of variables. This can be used to reduce the complexity of the data and identify patterns in the data.
Structural Equation Modeling (SEM)
SEM is a statistical technique used to model complex relationships between variables. It can be used to test complex theories and models of causality.
Cluster Analysis
Cluster analysis is used to group similar cases or observations together based on similarities or differences in their characteristics.
Time Series Analysis
Time series analysis is used to analyze data collected over time in order to identify trends, patterns, or changes in the data.
Multilevel Modeling
Multilevel modeling is used to analyze data that is nested within multiple levels, such as students nested within schools or employees nested within companies.
Applications of Experimental Design
Experimental design is a versatile research methodology that can be applied in many fields. Here are some applications of experimental design:
- Medical Research: Experimental design is commonly used to test new treatments or medications for various medical conditions. This includes clinical trials to evaluate the safety and effectiveness of new drugs or medical devices.
- Agriculture : Experimental design is used to test new crop varieties, fertilizers, and other agricultural practices. This includes randomized field trials to evaluate the effects of different treatments on crop yield, quality, and pest resistance.
- Environmental science: Experimental design is used to study the effects of environmental factors, such as pollution or climate change, on ecosystems and wildlife. This includes controlled experiments to study the effects of pollutants on plant growth or animal behavior.
- Psychology : Experimental design is used to study human behavior and cognitive processes. This includes experiments to test the effects of different interventions, such as therapy or medication, on mental health outcomes.
- Engineering : Experimental design is used to test new materials, designs, and manufacturing processes in engineering applications. This includes laboratory experiments to test the strength and durability of new materials, or field experiments to test the performance of new technologies.
- Education : Experimental design is used to evaluate the effectiveness of teaching methods, educational interventions, and programs. This includes randomized controlled trials to compare different teaching methods or evaluate the impact of educational programs on student outcomes.
- Marketing : Experimental design is used to test the effectiveness of marketing campaigns, pricing strategies, and product designs. This includes experiments to test the impact of different marketing messages or pricing schemes on consumer behavior.
Examples of Experimental Design
Here are some examples of experimental design in different fields:
- Example in Medical research : A study that investigates the effectiveness of a new drug treatment for a particular condition. Patients are randomly assigned to either a treatment group or a control group, with the treatment group receiving the new drug and the control group receiving a placebo. The outcomes, such as improvement in symptoms or side effects, are measured and compared between the two groups.
- Example in Education research: A study that examines the impact of a new teaching method on student learning outcomes. Students are randomly assigned to either a group that receives the new teaching method or a group that receives the traditional teaching method. Student achievement is measured before and after the intervention, and the results are compared between the two groups.
- Example in Environmental science: A study that tests the effectiveness of a new method for reducing pollution in a river. Two sections of the river are selected, with one section treated with the new method and the other section left untreated. The water quality is measured before and after the intervention, and the results are compared between the two sections.
- Example in Marketing research: A study that investigates the impact of a new advertising campaign on consumer behavior. Participants are randomly assigned to either a group that is exposed to the new campaign or a group that is not. Their behavior, such as purchasing or product awareness, is measured and compared between the two groups.
- Example in Social psychology: A study that examines the effect of a new social intervention on reducing prejudice towards a marginalized group. Participants are randomly assigned to either a group that receives the intervention or a control group that does not. Their attitudes and behavior towards the marginalized group are measured before and after the intervention, and the results are compared between the two groups.
When to use Experimental Research Design
Experimental research design should be used when a researcher wants to establish a cause-and-effect relationship between variables. It is particularly useful when studying the impact of an intervention or treatment on a particular outcome.
Here are some situations where experimental research design may be appropriate:
- When studying the effects of a new drug or medical treatment: Experimental research design is commonly used in medical research to test the effectiveness and safety of new drugs or medical treatments. By randomly assigning patients to treatment and control groups, researchers can determine whether the treatment is effective in improving health outcomes.
- When evaluating the effectiveness of an educational intervention: An experimental research design can be used to evaluate the impact of a new teaching method or educational program on student learning outcomes. By randomly assigning students to treatment and control groups, researchers can determine whether the intervention is effective in improving academic performance.
- When testing the effectiveness of a marketing campaign: An experimental research design can be used to test the effectiveness of different marketing messages or strategies. By randomly assigning participants to treatment and control groups, researchers can determine whether the marketing campaign is effective in changing consumer behavior.
- When studying the effects of an environmental intervention: Experimental research design can be used to study the impact of environmental interventions, such as pollution reduction programs or conservation efforts. By randomly assigning locations or areas to treatment and control groups, researchers can determine whether the intervention is effective in improving environmental outcomes.
- When testing the effects of a new technology: An experimental research design can be used to test the effectiveness and safety of new technologies or engineering designs. By randomly assigning participants or locations to treatment and control groups, researchers can determine whether the new technology is effective in achieving its intended purpose.
How to Conduct Experimental Research
Here are the steps to conduct Experimental Research:
- Identify a Research Question : Start by identifying a research question that you want to answer through the experiment. The question should be clear, specific, and testable.
- Develop a Hypothesis: Based on your research question, develop a hypothesis that predicts the relationship between the independent and dependent variables. The hypothesis should be clear and testable.
- Design the Experiment : Determine the type of experimental design you will use, such as a between-subjects design or a within-subjects design. Also, decide on the experimental conditions, such as the number of independent variables, the levels of the independent variable, and the dependent variable to be measured.
- Select Participants: Select the participants who will take part in the experiment. They should be representative of the population you are interested in studying.
- Randomly Assign Participants to Groups: If you are using a between-subjects design, randomly assign participants to groups to control for individual differences.
- Conduct the Experiment : Conduct the experiment by manipulating the independent variable(s) and measuring the dependent variable(s) across the different conditions.
- Analyze the Data: Analyze the data using appropriate statistical methods to determine if there is a significant effect of the independent variable(s) on the dependent variable(s).
- Draw Conclusions: Based on the data analysis, draw conclusions about the relationship between the independent and dependent variables. If the results support the hypothesis, then it is accepted. If the results do not support the hypothesis, then it is rejected.
- Communicate the Results: Finally, communicate the results of the experiment through a research report or presentation. Include the purpose of the study, the methods used, the results obtained, and the conclusions drawn.
Purpose of Experimental Design
The purpose of experimental design is to control and manipulate one or more independent variables to determine their effect on a dependent variable. Experimental design allows researchers to systematically investigate causal relationships between variables, and to establish cause-and-effect relationships between the independent and dependent variables. Through experimental design, researchers can test hypotheses and make inferences about the population from which the sample was drawn.
Experimental design provides a structured approach to designing and conducting experiments, ensuring that the results are reliable and valid. By carefully controlling for extraneous variables that may affect the outcome of the study, experimental design allows researchers to isolate the effect of the independent variable(s) on the dependent variable(s), and to minimize the influence of other factors that may confound the results.
Experimental design also allows researchers to generalize their findings to the larger population from which the sample was drawn. By randomly selecting participants and using statistical techniques to analyze the data, researchers can make inferences about the larger population with a high degree of confidence.
Overall, the purpose of experimental design is to provide a rigorous, systematic, and scientific method for testing hypotheses and establishing cause-and-effect relationships between variables. Experimental design is a powerful tool for advancing scientific knowledge and informing evidence-based practice in various fields, including psychology, biology, medicine, engineering, and social sciences.
Advantages of Experimental Design
Experimental design offers several advantages in research. Here are some of the main advantages:
- Control over extraneous variables: Experimental design allows researchers to control for extraneous variables that may affect the outcome of the study. By manipulating the independent variable and holding all other variables constant, researchers can isolate the effect of the independent variable on the dependent variable.
- Establishing causality: Experimental design allows researchers to establish causality by manipulating the independent variable and observing its effect on the dependent variable. This allows researchers to determine whether changes in the independent variable cause changes in the dependent variable.
- Replication : Experimental design allows researchers to replicate their experiments to ensure that the findings are consistent and reliable. Replication is important for establishing the validity and generalizability of the findings.
- Random assignment: Experimental design often involves randomly assigning participants to conditions. This helps to ensure that individual differences between participants are evenly distributed across conditions, which increases the internal validity of the study.
- Precision : Experimental design allows researchers to measure variables with precision, which can increase the accuracy and reliability of the data.
- Generalizability : If the study is well-designed, experimental design can increase the generalizability of the findings. By controlling for extraneous variables and using random assignment, researchers can increase the likelihood that the findings will apply to other populations and contexts.
Limitations of Experimental Design
Experimental design has some limitations that researchers should be aware of. Here are some of the main limitations:
- Artificiality : Experimental design often involves creating artificial situations that may not reflect real-world situations. This can limit the external validity of the findings, or the extent to which the findings can be generalized to real-world settings.
- Ethical concerns: Some experimental designs may raise ethical concerns, particularly if they involve manipulating variables that could cause harm to participants or if they involve deception.
- Participant bias : Participants in experimental studies may modify their behavior in response to the experiment, which can lead to participant bias.
- Limited generalizability: The conditions of the experiment may not reflect the complexities of real-world situations. As a result, the findings may not be applicable to all populations and contexts.
- Cost and time : Experimental design can be expensive and time-consuming, particularly if the experiment requires specialized equipment or if the sample size is large.
- Researcher bias : Researchers may unintentionally bias the results of the experiment if they have expectations or preferences for certain outcomes.
- Lack of feasibility : Experimental design may not be feasible in some cases, particularly if the research question involves variables that cannot be manipulated or controlled.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Survey Research – Types, Methods, Examples

One-to-One Interview – Methods and Guide

Quantitative Research – Methods, Types and...

Exploratory Research – Types, Methods and...

Focus Groups – Steps, Examples and Guide

Textual Analysis – Types, Examples and Guide
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
5 Research design
Research design is a comprehensive plan for data collection in an empirical research project. It is a ‘blueprint’ for empirical research aimed at answering specific research questions or testing specific hypotheses, and must specify at least three processes: the data collection process, the instrument development process, and the sampling process. The instrument development and sampling processes are described in the next two chapters, and the data collection process—which is often loosely called ‘research design’—is introduced in this chapter and is described in further detail in Chapters 9–12.
Broadly speaking, data collection methods can be grouped into two categories: positivist and interpretive. Positivist methods , such as laboratory experiments and survey research, are aimed at theory (or hypotheses) testing, while interpretive methods, such as action research and ethnography, are aimed at theory building. Positivist methods employ a deductive approach to research, starting with a theory and testing theoretical postulates using empirical data. In contrast, interpretive methods employ an inductive approach that starts with data and tries to derive a theory about the phenomenon of interest from the observed data. Often times, these methods are incorrectly equated with quantitative and qualitative research. Quantitative and qualitative methods refers to the type of data being collected—quantitative data involve numeric scores, metrics, and so on, while qualitative data includes interviews, observations, and so forth—and analysed (i.e., using quantitative techniques such as regression or qualitative techniques such as coding). Positivist research uses predominantly quantitative data, but can also use qualitative data. Interpretive research relies heavily on qualitative data, but can sometimes benefit from including quantitative data as well. Sometimes, joint use of qualitative and quantitative data may help generate unique insight into a complex social phenomenon that is not available from either type of data alone, and hence, mixed-mode designs that combine qualitative and quantitative data are often highly desirable.
Key attributes of a research design
The quality of research designs can be defined in terms of four key design attributes: internal validity, external validity, construct validity, and statistical conclusion validity.
Internal validity , also called causality, examines whether the observed change in a dependent variable is indeed caused by a corresponding change in a hypothesised independent variable, and not by variables extraneous to the research context. Causality requires three conditions: covariation of cause and effect (i.e., if cause happens, then effect also happens; if cause does not happen, effect does not happen), temporal precedence (cause must precede effect in time), and spurious correlation, or there is no plausible alternative explanation for the change. Certain research designs, such as laboratory experiments, are strong in internal validity by virtue of their ability to manipulate the independent variable (cause) via a treatment and observe the effect (dependent variable) of that treatment after a certain point in time, while controlling for the effects of extraneous variables. Other designs, such as field surveys, are poor in internal validity because of their inability to manipulate the independent variable (cause), and because cause and effect are measured at the same point in time which defeats temporal precedence making it equally likely that the expected effect might have influenced the expected cause rather than the reverse. Although higher in internal validity compared to other methods, laboratory experiments are by no means immune to threats of internal validity, and are susceptible to history, testing, instrumentation, regression, and other threats that are discussed later in the chapter on experimental designs. Nonetheless, different research designs vary considerably in their respective level of internal validity.
External validity or generalisability refers to whether the observed associations can be generalised from the sample to the population (population validity), or to other people, organisations, contexts, or time (ecological validity). For instance, can results drawn from a sample of financial firms in the United States be generalised to the population of financial firms (population validity) or to other firms within the United States (ecological validity)? Survey research, where data is sourced from a wide variety of individuals, firms, or other units of analysis, tends to have broader generalisability than laboratory experiments where treatments and extraneous variables are more controlled. The variation in internal and external validity for a wide range of research designs is shown in Figure 5.1.

Some researchers claim that there is a trade-off between internal and external validity—higher external validity can come only at the cost of internal validity and vice versa. But this is not always the case. Research designs such as field experiments, longitudinal field surveys, and multiple case studies have higher degrees of both internal and external validities. Personally, I prefer research designs that have reasonable degrees of both internal and external validities, i.e., those that fall within the cone of validity shown in Figure 5.1. But this should not suggest that designs outside this cone are any less useful or valuable. Researchers’ choice of designs are ultimately a matter of their personal preference and competence, and the level of internal and external validity they desire.
Construct validity examines how well a given measurement scale is measuring the theoretical construct that it is expected to measure. Many constructs used in social science research such as empathy, resistance to change, and organisational learning are difficult to define, much less measure. For instance, construct validity must ensure that a measure of empathy is indeed measuring empathy and not compassion, which may be difficult since these constructs are somewhat similar in meaning. Construct validity is assessed in positivist research based on correlational or factor analysis of pilot test data, as described in the next chapter.
Statistical conclusion validity examines the extent to which conclusions derived using a statistical procedure are valid. For example, it examines whether the right statistical method was used for hypotheses testing, whether the variables used meet the assumptions of that statistical test (such as sample size or distributional requirements), and so forth. Because interpretive research designs do not employ statistical tests, statistical conclusion validity is not applicable for such analysis. The different kinds of validity and where they exist at the theoretical/empirical levels are illustrated in Figure 5.2.

Improving internal and external validity
The best research designs are those that can ensure high levels of internal and external validity. Such designs would guard against spurious correlations, inspire greater faith in the hypotheses testing, and ensure that the results drawn from a small sample are generalisable to the population at large. Controls are required to ensure internal validity (causality) of research designs, and can be accomplished in five ways: manipulation, elimination, inclusion, and statistical control, and randomisation.
In manipulation , the researcher manipulates the independent variables in one or more levels (called ‘treatments’), and compares the effects of the treatments against a control group where subjects do not receive the treatment. Treatments may include a new drug or different dosage of drug (for treating a medical condition), a teaching style (for students), and so forth. This type of control is achieved in experimental or quasi-experimental designs, but not in non-experimental designs such as surveys. Note that if subjects cannot distinguish adequately between different levels of treatment manipulations, their responses across treatments may not be different, and manipulation would fail.
The elimination technique relies on eliminating extraneous variables by holding them constant across treatments, such as by restricting the study to a single gender or a single socioeconomic status. In the inclusion technique, the role of extraneous variables is considered by including them in the research design and separately estimating their effects on the dependent variable, such as via factorial designs where one factor is gender (male versus female). Such technique allows for greater generalisability, but also requires substantially larger samples. In statistical control , extraneous variables are measured and used as covariates during the statistical testing process.
Finally, the randomisation technique is aimed at cancelling out the effects of extraneous variables through a process of random sampling, if it can be assured that these effects are of a random (non-systematic) nature. Two types of randomisation are: random selection , where a sample is selected randomly from a population, and random assignment , where subjects selected in a non-random manner are randomly assigned to treatment groups.
Randomisation also ensures external validity, allowing inferences drawn from the sample to be generalised to the population from which the sample is drawn. Note that random assignment is mandatory when random selection is not possible because of resource or access constraints. However, generalisability across populations is harder to ascertain since populations may differ on multiple dimensions and you can only control for a few of those dimensions.
Popular research designs
As noted earlier, research designs can be classified into two categories—positivist and interpretive—depending on the goal of the research. Positivist designs are meant for theory testing, while interpretive designs are meant for theory building. Positivist designs seek generalised patterns based on an objective view of reality, while interpretive designs seek subjective interpretations of social phenomena from the perspectives of the subjects involved. Some popular examples of positivist designs include laboratory experiments, field experiments, field surveys, secondary data analysis, and case research, while examples of interpretive designs include case research, phenomenology, and ethnography. Note that case research can be used for theory building or theory testing, though not at the same time. Not all techniques are suited for all kinds of scientific research. Some techniques such as focus groups are best suited for exploratory research, others such as ethnography are best for descriptive research, and still others such as laboratory experiments are ideal for explanatory research. Following are brief descriptions of some of these designs. Additional details are provided in Chapters 9–12.
Experimental studies are those that are intended to test cause-effect relationships (hypotheses) in a tightly controlled setting by separating the cause from the effect in time, administering the cause to one group of subjects (the ‘treatment group’) but not to another group (‘control group’), and observing how the mean effects vary between subjects in these two groups. For instance, if we design a laboratory experiment to test the efficacy of a new drug in treating a certain ailment, we can get a random sample of people afflicted with that ailment, randomly assign them to one of two groups (treatment and control groups), administer the drug to subjects in the treatment group, but only give a placebo (e.g., a sugar pill with no medicinal value) to subjects in the control group. More complex designs may include multiple treatment groups, such as low versus high dosage of the drug or combining drug administration with dietary interventions. In a true experimental design , subjects must be randomly assigned to each group. If random assignment is not followed, then the design becomes quasi-experimental . Experiments can be conducted in an artificial or laboratory setting such as at a university (laboratory experiments) or in field settings such as in an organisation where the phenomenon of interest is actually occurring (field experiments). Laboratory experiments allow the researcher to isolate the variables of interest and control for extraneous variables, which may not be possible in field experiments. Hence, inferences drawn from laboratory experiments tend to be stronger in internal validity, but those from field experiments tend to be stronger in external validity. Experimental data is analysed using quantitative statistical techniques. The primary strength of the experimental design is its strong internal validity due to its ability to isolate, control, and intensively examine a small number of variables, while its primary weakness is limited external generalisability since real life is often more complex (i.e., involving more extraneous variables) than contrived lab settings. Furthermore, if the research does not identify ex ante relevant extraneous variables and control for such variables, such lack of controls may hurt internal validity and may lead to spurious correlations.
Field surveys are non-experimental designs that do not control for or manipulate independent variables or treatments, but measure these variables and test their effects using statistical methods. Field surveys capture snapshots of practices, beliefs, or situations from a random sample of subjects in field settings through a survey questionnaire or less frequently, through a structured interview. In cross-sectional field surveys , independent and dependent variables are measured at the same point in time (e.g., using a single questionnaire), while in longitudinal field surveys , dependent variables are measured at a later point in time than the independent variables. The strengths of field surveys are their external validity (since data is collected in field settings), their ability to capture and control for a large number of variables, and their ability to study a problem from multiple perspectives or using multiple theories. However, because of their non-temporal nature, internal validity (cause-effect relationships) are difficult to infer, and surveys may be subject to respondent biases (e.g., subjects may provide a ‘socially desirable’ response rather than their true response) which further hurts internal validity.
Secondary data analysis is an analysis of data that has previously been collected and tabulated by other sources. Such data may include data from government agencies such as employment statistics from the U.S. Bureau of Labor Services or development statistics by countries from the United Nations Development Program, data collected by other researchers (often used in meta-analytic studies), or publicly available third-party data, such as financial data from stock markets or real-time auction data from eBay. This is in contrast to most other research designs where collecting primary data for research is part of the researcher’s job. Secondary data analysis may be an effective means of research where primary data collection is too costly or infeasible, and secondary data is available at a level of analysis suitable for answering the researcher’s questions. The limitations of this design are that the data might not have been collected in a systematic or scientific manner and hence unsuitable for scientific research, since the data was collected for a presumably different purpose, they may not adequately address the research questions of interest to the researcher, and interval validity is problematic if the temporal precedence between cause and effect is unclear.
Case research is an in-depth investigation of a problem in one or more real-life settings (case sites) over an extended period of time. Data may be collected using a combination of interviews, personal observations, and internal or external documents. Case studies can be positivist in nature (for hypotheses testing) or interpretive (for theory building). The strength of this research method is its ability to discover a wide variety of social, cultural, and political factors potentially related to the phenomenon of interest that may not be known in advance. Analysis tends to be qualitative in nature, but heavily contextualised and nuanced. However, interpretation of findings may depend on the observational and integrative ability of the researcher, lack of control may make it difficult to establish causality, and findings from a single case site may not be readily generalised to other case sites. Generalisability can be improved by replicating and comparing the analysis in other case sites in a multiple case design .
Focus group research is a type of research that involves bringing in a small group of subjects (typically six to ten people) at one location, and having them discuss a phenomenon of interest for a period of one and a half to two hours. The discussion is moderated and led by a trained facilitator, who sets the agenda and poses an initial set of questions for participants, makes sure that the ideas and experiences of all participants are represented, and attempts to build a holistic understanding of the problem situation based on participants’ comments and experiences. Internal validity cannot be established due to lack of controls and the findings may not be generalised to other settings because of the small sample size. Hence, focus groups are not generally used for explanatory or descriptive research, but are more suited for exploratory research.
Action research assumes that complex social phenomena are best understood by introducing interventions or ‘actions’ into those phenomena and observing the effects of those actions. In this method, the researcher is embedded within a social context such as an organisation and initiates an action—such as new organisational procedures or new technologies—in response to a real problem such as declining profitability or operational bottlenecks. The researcher’s choice of actions must be based on theory, which should explain why and how such actions may cause the desired change. The researcher then observes the results of that action, modifying it as necessary, while simultaneously learning from the action and generating theoretical insights about the target problem and interventions. The initial theory is validated by the extent to which the chosen action successfully solves the target problem. Simultaneous problem solving and insight generation is the central feature that distinguishes action research from all other research methods, and hence, action research is an excellent method for bridging research and practice. This method is also suited for studying unique social problems that cannot be replicated outside that context, but it is also subject to researcher bias and subjectivity, and the generalisability of findings is often restricted to the context where the study was conducted.
Ethnography is an interpretive research design inspired by anthropology that emphasises that research phenomenon must be studied within the context of its culture. The researcher is deeply immersed in a certain culture over an extended period of time—eight months to two years—and during that period, engages, observes, and records the daily life of the studied culture, and theorises about the evolution and behaviours in that culture. Data is collected primarily via observational techniques, formal and informal interaction with participants in that culture, and personal field notes, while data analysis involves ‘sense-making’. The researcher must narrate her experience in great detail so that readers may experience that same culture without necessarily being there. The advantages of this approach are its sensitiveness to the context, the rich and nuanced understanding it generates, and minimal respondent bias. However, this is also an extremely time and resource-intensive approach, and findings are specific to a given culture and less generalisable to other cultures.
Selecting research designs
Given the above multitude of research designs, which design should researchers choose for their research? Generally speaking, researchers tend to select those research designs that they are most comfortable with and feel most competent to handle, but ideally, the choice should depend on the nature of the research phenomenon being studied. In the preliminary phases of research, when the research problem is unclear and the researcher wants to scope out the nature and extent of a certain research problem, a focus group (for an individual unit of analysis) or a case study (for an organisational unit of analysis) is an ideal strategy for exploratory research. As one delves further into the research domain, but finds that there are no good theories to explain the phenomenon of interest and wants to build a theory to fill in the unmet gap in that area, interpretive designs such as case research or ethnography may be useful designs. If competing theories exist and the researcher wishes to test these different theories or integrate them into a larger theory, positivist designs such as experimental design, survey research, or secondary data analysis are more appropriate.
Regardless of the specific research design chosen, the researcher should strive to collect quantitative and qualitative data using a combination of techniques such as questionnaires, interviews, observations, documents, or secondary data. For instance, even in a highly structured survey questionnaire, intended to collect quantitative data, the researcher may leave some room for a few open-ended questions to collect qualitative data that may generate unexpected insights not otherwise available from structured quantitative data alone. Likewise, while case research employ mostly face-to-face interviews to collect most qualitative data, the potential and value of collecting quantitative data should not be ignored. As an example, in a study of organisational decision-making processes, the case interviewer can record numeric quantities such as how many months it took to make certain organisational decisions, how many people were involved in that decision process, and how many decision alternatives were considered, which can provide valuable insights not otherwise available from interviewees’ narrative responses. Irrespective of the specific research design employed, the goal of the researcher should be to collect as much and as diverse data as possible that can help generate the best possible insights about the phenomenon of interest.
Social Science Research: Principles, Methods and Practices (Revised edition) Copyright © 2019 by Anol Bhattacherjee is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Chapter 6: Experimental Research
Experimental Design
Learning Objectives
- Explain the difference between between-subjects and within-subjects experiments, list some of the pros and cons of each approach, and decide which approach to use to answer a particular research question.
- Define random assignment, distinguish it from random sampling, explain its purpose in experimental research, and use some simple strategies to implement it.
- Define what a control condition is, explain its purpose in research on treatment effectiveness, and describe some alternative types of control conditions.
- Define several types of carryover effect, give examples of each, and explain how counterbalancing helps to deal with them.
In this section, we look at some different ways to design an experiment. The primary distinction we will make is between approaches in which each participant experiences one level of the independent variable and approaches in which each participant experiences all levels of the independent variable. The former are called between-subjects experiments and the latter are called within-subjects experiments.
Between-Subjects Experiments
In a between-subjects experiment , each participant is tested in only one condition. For example, a researcher with a sample of 100 university students might assign half of them to write about a traumatic event and the other half write about a neutral event. Or a researcher with a sample of 60 people with severe agoraphobia (fear of open spaces) might assign 20 of them to receive each of three different treatments for that disorder. It is essential in a between-subjects experiment that the researcher assign participants to conditions so that the different groups are, on average, highly similar to each other. Those in a trauma condition and a neutral condition, for example, should include a similar proportion of men and women, and they should have similar average intelligence quotients (IQs), similar average levels of motivation, similar average numbers of health problems, and so on. This matching is a matter of controlling these extraneous participant variables across conditions so that they do not become confounding variables.
Random Assignment
The primary way that researchers accomplish this kind of control of extraneous variables across conditions is called random assignment , which means using a random process to decide which participants are tested in which conditions. Do not confuse random assignment with random sampling. Random sampling is a method for selecting a sample from a population, and it is rarely used in psychological research. Random assignment is a method for assigning participants in a sample to the different conditions, and it is an important element of all experimental research in psychology and other fields too.
In its strictest sense, random assignment should meet two criteria. One is that each participant has an equal chance of being assigned to each condition (e.g., a 50% chance of being assigned to each of two conditions). The second is that each participant is assigned to a condition independently of other participants. Thus one way to assign participants to two conditions would be to flip a coin for each one. If the coin lands heads, the participant is assigned to Condition A, and if it lands tails, the participant is assigned to Condition B. For three conditions, one could use a computer to generate a random integer from 1 to 3 for each participant. If the integer is 1, the participant is assigned to Condition A; if it is 2, the participant is assigned to Condition B; and if it is 3, the participant is assigned to Condition C. In practice, a full sequence of conditions—one for each participant expected to be in the experiment—is usually created ahead of time, and each new participant is assigned to the next condition in the sequence as he or she is tested. When the procedure is computerized, the computer program often handles the random assignment.
One problem with coin flipping and other strict procedures for random assignment is that they are likely to result in unequal sample sizes in the different conditions. Unequal sample sizes are generally not a serious problem, and you should never throw away data you have already collected to achieve equal sample sizes. However, for a fixed number of participants, it is statistically most efficient to divide them into equal-sized groups. It is standard practice, therefore, to use a kind of modified random assignment that keeps the number of participants in each group as similar as possible. One approach is block randomization . In block randomization, all the conditions occur once in the sequence before any of them is repeated. Then they all occur again before any of them is repeated again. Within each of these “blocks,” the conditions occur in a random order. Again, the sequence of conditions is usually generated before any participants are tested, and each new participant is assigned to the next condition in the sequence. Table 6.2 shows such a sequence for assigning nine participants to three conditions. The Research Randomizer website will generate block randomization sequences for any number of participants and conditions. Again, when the procedure is computerized, the computer program often handles the block randomization.
| Participant | Condition |
|---|---|
| 1 | A |
| 2 | C |
| 3 | B |
| 4 | B |
| 5 | C |
| 6 | A |
| 7 | C |
| 8 | B |
| 9 | A |
Random assignment is not guaranteed to control all extraneous variables across conditions. It is always possible that just by chance, the participants in one condition might turn out to be substantially older, less tired, more motivated, or less depressed on average than the participants in another condition. However, there are some reasons that this possibility is not a major concern. One is that random assignment works better than one might expect, especially for large samples. Another is that the inferential statistics that researchers use to decide whether a difference between groups reflects a difference in the population takes the “fallibility” of random assignment into account. Yet another reason is that even if random assignment does result in a confounding variable and therefore produces misleading results, this confound is likely to be detected when the experiment is replicated. The upshot is that random assignment to conditions—although not infallible in terms of controlling extraneous variables—is always considered a strength of a research design.
Treatment and Control Conditions
Between-subjects experiments are often used to determine whether a treatment works. In psychological research, a treatment is any intervention meant to change people’s behaviour for the better. This intervention includes psychotherapies and medical treatments for psychological disorders but also interventions designed to improve learning, promote conservation, reduce prejudice, and so on. To determine whether a treatment works, participants are randomly assigned to either a treatment condition , in which they receive the treatment, or a control condition , in which they do not receive the treatment. If participants in the treatment condition end up better off than participants in the control condition—for example, they are less depressed, learn faster, conserve more, express less prejudice—then the researcher can conclude that the treatment works. In research on the effectiveness of psychotherapies and medical treatments, this type of experiment is often called a randomized clinical trial .
There are different types of control conditions. In a no-treatment control condition , participants receive no treatment whatsoever. One problem with this approach, however, is the existence of placebo effects. A placebo is a simulated treatment that lacks any active ingredient or element that should make it effective, and a placebo effect is a positive effect of such a treatment. Many folk remedies that seem to work—such as eating chicken soup for a cold or placing soap under the bedsheets to stop nighttime leg cramps—are probably nothing more than placebos. Although placebo effects are not well understood, they are probably driven primarily by people’s expectations that they will improve. Having the expectation to improve can result in reduced stress, anxiety, and depression, which can alter perceptions and even improve immune system functioning (Price, Finniss, & Benedetti, 2008) [1] .
Placebo effects are interesting in their own right (see Note “The Powerful Placebo” ), but they also pose a serious problem for researchers who want to determine whether a treatment works. Figure 6.2 shows some hypothetical results in which participants in a treatment condition improved more on average than participants in a no-treatment control condition. If these conditions (the two leftmost bars in Figure 6.2 ) were the only conditions in this experiment, however, one could not conclude that the treatment worked. It could be instead that participants in the treatment group improved more because they expected to improve, while those in the no-treatment control condition did not.

Fortunately, there are several solutions to this problem. One is to include a placebo control condition , in which participants receive a placebo that looks much like the treatment but lacks the active ingredient or element thought to be responsible for the treatment’s effectiveness. When participants in a treatment condition take a pill, for example, then those in a placebo control condition would take an identical-looking pill that lacks the active ingredient in the treatment (a “sugar pill”). In research on psychotherapy effectiveness, the placebo might involve going to a psychotherapist and talking in an unstructured way about one’s problems. The idea is that if participants in both the treatment and the placebo control groups expect to improve, then any improvement in the treatment group over and above that in the placebo control group must have been caused by the treatment and not by participants’ expectations. This difference is what is shown by a comparison of the two outer bars in Figure 6.2 .
Of course, the principle of informed consent requires that participants be told that they will be assigned to either a treatment or a placebo control condition—even though they cannot be told which until the experiment ends. In many cases the participants who had been in the control condition are then offered an opportunity to have the real treatment. An alternative approach is to use a waitlist control condition , in which participants are told that they will receive the treatment but must wait until the participants in the treatment condition have already received it. This disclosure allows researchers to compare participants who have received the treatment with participants who are not currently receiving it but who still expect to improve (eventually). A final solution to the problem of placebo effects is to leave out the control condition completely and compare any new treatment with the best available alternative treatment. For example, a new treatment for simple phobia could be compared with standard exposure therapy. Because participants in both conditions receive a treatment, their expectations about improvement should be similar. This approach also makes sense because once there is an effective treatment, the interesting question about a new treatment is not simply “Does it work?” but “Does it work better than what is already available?
The Powerful Placebo
Many people are not surprised that placebos can have a positive effect on disorders that seem fundamentally psychological, including depression, anxiety, and insomnia. However, placebos can also have a positive effect on disorders that most people think of as fundamentally physiological. These include asthma, ulcers, and warts (Shapiro & Shapiro, 1999) [2] . There is even evidence that placebo surgery—also called “sham surgery”—can be as effective as actual surgery.
Medical researcher J. Bruce Moseley and his colleagues conducted a study on the effectiveness of two arthroscopic surgery procedures for osteoarthritis of the knee (Moseley et al., 2002) [3] . The control participants in this study were prepped for surgery, received a tranquilizer, and even received three small incisions in their knees. But they did not receive the actual arthroscopic surgical procedure. The surprising result was that all participants improved in terms of both knee pain and function, and the sham surgery group improved just as much as the treatment groups. According to the researchers, “This study provides strong evidence that arthroscopic lavage with or without débridement [the surgical procedures used] is not better than and appears to be equivalent to a placebo procedure in improving knee pain and self-reported function” (p. 85).
Within-Subjects Experiments
In a within-subjects experiment , each participant is tested under all conditions. Consider an experiment on the effect of a defendant’s physical attractiveness on judgments of his guilt. Again, in a between-subjects experiment, one group of participants would be shown an attractive defendant and asked to judge his guilt, and another group of participants would be shown an unattractive defendant and asked to judge his guilt. In a within-subjects experiment, however, the same group of participants would judge the guilt of both an attractive and an unattractive defendant.
The primary advantage of this approach is that it provides maximum control of extraneous participant variables. Participants in all conditions have the same mean IQ, same socioeconomic status, same number of siblings, and so on—because they are the very same people. Within-subjects experiments also make it possible to use statistical procedures that remove the effect of these extraneous participant variables on the dependent variable and therefore make the data less “noisy” and the effect of the independent variable easier to detect. We will look more closely at this idea later in the book. However, not all experiments can use a within-subjects design nor would it be desirable to.
Carryover Effects and Counterbalancing
The primary disad vantage of within-subjects designs is that they can result in carryover effects. A carryover effect is an effect of being tested in one condition on participants’ behaviour in later conditions. One type of carryover effect is a practice effect , where participants perform a task better in later conditions because they have had a chance to practice it. Another type is a fatigue effect , where participants perform a task worse in later conditions because they become tired or bored. Being tested in one condition can also change how participants perceive stimuli or interpret their task in later conditions. This type of effect is called a context effect . For example, an average-looking defendant might be judged more harshly when participants have just judged an attractive defendant than when they have just judged an unattractive defendant. Within-subjects experiments also make it easier for participants to guess the hypothesis. For example, a participant who is asked to judge the guilt of an attractive defendant and then is asked to judge the guilt of an unattractive defendant is likely to guess that the hypothesis is that defendant attractiveness affects judgments of guilt. This knowledge could lead the participant to judge the unattractive defendant more harshly because he thinks this is what he is expected to do. Or it could make participants judge the two defendants similarly in an effort to be “fair.”
Carryover effects can be interesting in their own right. (Does the attractiveness of one person depend on the attractiveness of other people that we have seen recently?) But when they are not the focus of the research, carryover effects can be problematic. Imagine, for example, that participants judge the guilt of an attractive defendant and then judge the guilt of an unattractive defendant. If they judge the unattractive defendant more harshly, this might be because of his unattractiveness. But it could be instead that they judge him more harshly because they are becoming bored or tired. In other words, the order of the conditions is a confounding variable. The attractive condition is always the first condition and the unattractive condition the second. Thus any difference between the conditions in terms of the dependent variable could be caused by the order of the conditions and not the independent variable itself.
There is a solution to the problem of order effects, however, that can be used in many situations. It is counterbalancing , which means testing different participants in different orders. For example, some participants would be tested in the attractive defendant condition followed by the unattractive defendant condition, and others would be tested in the unattractive condition followed by the attractive condition. With three conditions, there would be six different orders (ABC, ACB, BAC, BCA, CAB, and CBA), so some participants would be tested in each of the six orders. With counterbalancing, participants are assigned to orders randomly, using the techniques we have already discussed. Thus random assignment plays an important role in within-subjects designs just as in between-subjects designs. Here, instead of randomly assigning to conditions, they are randomly assigned to different orders of conditions. In fact, it can safely be said that if a study does not involve random assignment in one form or another, it is not an experiment.
An efficient way of counterbalancing is through a Latin square design which randomizes through having equal rows and columns. For example, if you have four treatments, you must have four versions. Like a Sudoku puzzle, no treatment can repeat in a row or column. For four versions of four treatments, the Latin square design would look like:
| A | B | C | D |
| B | C | D | A |
| C | D | A | B |
| D | A | B | C |
There are two ways to think about what counterbalancing accomplishes. One is that it controls the order of conditions so that it is no longer a confounding variable. Instead of the attractive condition always being first and the unattractive condition always being second, the attractive condition comes first for some participants and second for others. Likewise, the unattractive condition comes first for some participants and second for others. Thus any overall difference in the dependent variable between the two conditions cannot have been caused by the order of conditions. A second way to think about what counterbalancing accomplishes is that if there are carryover effects, it makes it possible to detect them. One can analyze the data separately for each order to see whether it had an effect.
When 9 is “larger” than 221
Researcher Michael Birnbaum has argued that the lack of context provided by between-subjects designs is often a bigger problem than the context effects created by within-subjects designs. To demonstrate this problem, he asked participants to rate two numbers on how large they were on a scale of 1-to-10 where 1 was “very very small” and 10 was “very very large”. One group of participants were asked to rate the number 9 and another group was asked to rate the number 221 (Birnbaum, 1999) [4] . Participants in this between-subjects design gave the number 9 a mean rating of 5.13 and the number 221 a mean rating of 3.10. In other words, they rated 9 as larger than 221! According to Birnbaum, this difference is because participants spontaneously compared 9 with other one-digit numbers (in which case it is relatively large) and compared 221 with other three-digit numbers (in which case it is relatively small) .
Simultaneous Within-Subjects Designs
So far, we have discussed an approach to within-subjects designs in which participants are tested in one condition at a time. There is another approach, however, that is often used when participants make multiple responses in each condition. Imagine, for example, that participants judge the guilt of 10 attractive defendants and 10 unattractive defendants. Instead of having people make judgments about all 10 defendants of one type followed by all 10 defendants of the other type, the researcher could present all 20 defendants in a sequence that mixed the two types. The researcher could then compute each participant’s mean rating for each type of defendant. Or imagine an experiment designed to see whether people with social anxiety disorder remember negative adjectives (e.g., “stupid,” “incompetent”) better than positive ones (e.g., “happy,” “productive”). The researcher could have participants study a single list that includes both kinds of words and then have them try to recall as many words as possible. The researcher could then count the number of each type of word that was recalled. There are many ways to determine the order in which the stimuli are presented, but one common way is to generate a different random order for each participant.
Between-Subjects or Within-Subjects?
Almost every experiment can be conducted using either a between-subjects design or a within-subjects design. This possibility means that researchers must choose between the two approaches based on their relative merits for the particular situation.
Between-subjects experiments have the advantage of being conceptually simpler and requiring less testing time per participant. They also avoid carryover effects without the need for counterbalancing. Within-subjects experiments have the advantage of controlling extraneous participant variables, which generally reduces noise in the data and makes it easier to detect a relationship between the independent and dependent variables.
A good rule of thumb, then, is that if it is possible to conduct a within-subjects experiment (with proper counterbalancing) in the time that is available per participant—and you have no serious concerns about carryover effects—this design is probably the best option. If a within-subjects design would be difficult or impossible to carry out, then you should consider a between-subjects design instead. For example, if you were testing participants in a doctor’s waiting room or shoppers in line at a grocery store, you might not have enough time to test each participant in all conditions and therefore would opt for a between-subjects design. Or imagine you were trying to reduce people’s level of prejudice by having them interact with someone of another race. A within-subjects design with counterbalancing would require testing some participants in the treatment condition first and then in a control condition. But if the treatment works and reduces people’s level of prejudice, then they would no longer be suitable for testing in the control condition. This difficulty is true for many designs that involve a treatment meant to produce long-term change in participants’ behaviour (e.g., studies testing the effectiveness of psychotherapy). Clearly, a between-subjects design would be necessary here.
Remember also that using one type of design does not preclude using the other type in a different study. There is no reason that a researcher could not use both a between-subjects design and a within-subjects design to answer the same research question. In fact, professional researchers often take exactly this type of mixed methods approach.
Key Takeaways
- Experiments can be conducted using either between-subjects or within-subjects designs. Deciding which to use in a particular situation requires careful consideration of the pros and cons of each approach.
- Random assignment to conditions in between-subjects experiments or to orders of conditions in within-subjects experiments is a fundamental element of experimental research. Its purpose is to control extraneous variables so that they do not become confounding variables.
- Experimental research on the effectiveness of a treatment requires both a treatment condition and a control condition, which can be a no-treatment control condition, a placebo control condition, or a waitlist control condition. Experimental treatments can also be compared with the best available alternative.
- You want to test the relative effectiveness of two training programs for running a marathon.
- Using photographs of people as stimuli, you want to see if smiling people are perceived as more intelligent than people who are not smiling.
- In a field experiment, you want to see if the way a panhandler is dressed (neatly vs. sloppily) affects whether or not passersby give him any money.
- You want to see if concrete nouns (e.g., dog ) are recalled better than abstract nouns (e.g., truth ).
- Discussion: Imagine that an experiment shows that participants who receive psychodynamic therapy for a dog phobia improve more than participants in a no-treatment control group. Explain a fundamental problem with this research design and at least two ways that it might be corrected.
- Price, D. D., Finniss, D. G., & Benedetti, F. (2008). A comprehensive review of the placebo effect: Recent advances and current thought. Annual Review of Psychology, 59 , 565–590. ↵
- Shapiro, A. K., & Shapiro, E. (1999). The powerful placebo: From ancient priest to modern physician . Baltimore, MD: Johns Hopkins University Press. ↵
- Moseley, J. B., O’Malley, K., Petersen, N. J., Menke, T. J., Brody, B. A., Kuykendall, D. H., … Wray, N. P. (2002). A controlled trial of arthroscopic surgery for osteoarthritis of the knee. The New England Journal of Medicine, 347 , 81–88. ↵
- Birnbaum, M.H. (1999). How to show that 9>221: Collect judgments in a between-subjects design. Psychological Methods, 4(3), 243-249. ↵
An experiment in which each participant is only tested in one condition.
A method of controlling extraneous variables across conditions by using a random process to decide which participants will be tested in the different conditions.
All the conditions of an experiment occur once in the sequence before any of them is repeated.
Any intervention meant to change people’s behaviour for the better.
A condition in a study where participants receive treatment.
A condition in a study that the other condition is compared to. This group does not receive the treatment or intervention that the other conditions do.
A type of experiment to research the effectiveness of psychotherapies and medical treatments.
A type of control condition in which participants receive no treatment.
A simulated treatment that lacks any active ingredient or element that should make it effective.
A positive effect of a treatment that lacks any active ingredient or element to make it effective.
Participants receive a placebo that looks like the treatment but lacks the active ingredient or element thought to be responsible for the treatment’s effectiveness.
Participants are told that they will receive the treatment but must wait until the participants in the treatment condition have already received it.
Each participant is tested under all conditions.
An effect of being tested in one condition on participants’ behaviour in later conditions.
Participants perform a task better in later conditions because they have had a chance to practice it.
Participants perform a task worse in later conditions because they become tired or bored.
Being tested in one condition can also change how participants perceive stimuli or interpret their task in later conditions.
Testing different participants in different orders.
Research Methods in Psychology - 2nd Canadian Edition Copyright © 2015 by Paul C. Price, Rajiv Jhangiani, & I-Chant A. Chiang is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
educational research techniques
Research techniques and education.

Experimental Design: Treatment Conditions and Group Comparision
A key component of experimental design involves making decisions about the manipulation of the treatment conditions. In this post, we will look at the following traits of treatment conditions
- Treatment Variables
- Experimental treatment
- Interventions
Lastly, we will examine group comparison.

Measured variables are variables that are measured by are not manipulated by the researcher. Examples include age, gender, height, weight, etc.
An experimental treatment is the intervention of the researcher to alter the conditions of an experiment. This is done by keeping all other factors constant and only manipulating the experimental treatment, it allows for the potential establishment of a cause-effect relationship. In other words, the experimental treatment is a term for the use of a treatment variable.
Treatment variables usually have different conditions or levels in them. For example, if I am looking at sleep’s affect on academic performance. I may manipulate the treatment variable by creating several categories of the amount of sleep. Such as high, medium, and low amounts of sleep.
Intervention is a term that means the actual application of the treatment variables. In other words, I broke my sample into several groups and caused one group to get plenty of sleep the second group to lack a little bit of sleep and the last group got nothing. Experimental treatment and intervention mean the same thing.
The outcome measure is the experience of measuring the outcome variable. In our example, the outcome variable is academic performance.
Group Comparison
Experimental design often focuses on comparing groups. Groups can be compared between groups and within groups. Returning to the example of sleep and academic performance, a between group comparison would be to compare the different groups based on the amount of sleep they received. A within group comparison would be to compare the participants who received the same amount of sleep.
Often there are at least three groups in an experimental study, which are the controlled, comparison, and experimental group. The controlled group receives no intervention or treatment variable. This group often serves as a baseline for comparing the other groups.
The comparison group is exposed to everything but the actual treatment of the study. They are highly similar to the experimental group with the experience of the treatment. Lastly, the experimental group experiences the treatment of the study.
Experiments involve treatment conditions and groups. As such, researchers need to understand their options for treatment conditions as well as what types of groups they should include in a study.
Share this:
1 thought on “ experimental design: treatment conditions and group comparision ”.
Pingback: Experimental Design: Treatment Conditions and G...
Leave a Reply Cancel reply
Discover more from educational research techniques.
Subscribe now to keep reading and get access to the full archive.
Type your email…
Continue reading
Organizing Academic Research Papers: Types of Research Designs
- Purpose of Guide
- Design Flaws to Avoid
- Glossary of Research Terms
- Narrowing a Topic Idea
- Broadening a Topic Idea
- Extending the Timeliness of a Topic Idea
- Academic Writing Style
- Choosing a Title
- Making an Outline
- Paragraph Development
- Executive Summary
- Background Information
- The Research Problem/Question
- Theoretical Framework
- Citation Tracking
- Content Alert Services
- Evaluating Sources
- Primary Sources
- Secondary Sources
- Tertiary Sources
- What Is Scholarly vs. Popular?
- Qualitative Methods
- Quantitative Methods
- Using Non-Textual Elements
- Limitations of the Study
- Common Grammar Mistakes
- Avoiding Plagiarism
- Footnotes or Endnotes?
- Further Readings
- Annotated Bibliography
- Dealing with Nervousness
- Using Visual Aids
- Grading Someone Else's Paper
- How to Manage Group Projects
- Multiple Book Review Essay
- Reviewing Collected Essays
- About Informed Consent
- Writing Field Notes
- Writing a Policy Memo
- Writing a Research Proposal
- Acknowledgements
Introduction
Before beginning your paper, you need to decide how you plan to design the study .
The research design refers to the overall strategy that you choose to integrate the different components of the study in a coherent and logical way, thereby, ensuring you will effectively address the research problem; it constitutes the blueprint for the collection, measurement, and analysis of data. Note that your research problem determines the type of design you can use, not the other way around!
General Structure and Writing Style
Action research design, case study design, causal design, cohort design, cross-sectional design, descriptive design, experimental design, exploratory design, historical design, longitudinal design, observational design, philosophical design, sequential design.
Kirshenblatt-Gimblett, Barbara. Part 1, What Is Research Design? The Context of Design. Performance Studies Methods Course syllabus . New York University, Spring 2006; Trochim, William M.K. Research Methods Knowledge Base . 2006.
The function of a research design is to ensure that the evidence obtained enables you to effectively address the research problem as unambiguously as possible. In social sciences research, obtaining evidence relevant to the research problem generally entails specifying the type of evidence needed to test a theory, to evaluate a program, or to accurately describe a phenomenon. However, researchers can often begin their investigations far too early, before they have thought critically about about what information is required to answer the study's research questions. Without attending to these design issues beforehand, the conclusions drawn risk being weak and unconvincing and, consequently, will fail to adequate address the overall research problem.
Given this, the length and complexity of research designs can vary considerably, but any sound design will do the following things:
- Identify the research problem clearly and justify its selection,
- Review previously published literature associated with the problem area,
- Clearly and explicitly specify hypotheses [i.e., research questions] central to the problem selected,
- Effectively describe the data which will be necessary for an adequate test of the hypotheses and explain how such data will be obtained, and
- Describe the methods of analysis which will be applied to the data in determining whether or not the hypotheses are true or false.
Kirshenblatt-Gimblett, Barbara. Part 1, What Is Research Design? The Context of Design. Performance Studies Methods Course syllabus . New Yortk University, Spring 2006.
Definition and Purpose
The essentials of action research design follow a characteristic cycle whereby initially an exploratory stance is adopted, where an understanding of a problem is developed and plans are made for some form of interventionary strategy. Then the intervention is carried out (the action in Action Research) during which time, pertinent observations are collected in various forms. The new interventional strategies are carried out, and the cyclic process repeats, continuing until a sufficient understanding of (or implement able solution for) the problem is achieved. The protocol is iterative or cyclical in nature and is intended to foster deeper understanding of a given situation, starting with conceptualizing and particularizing the problem and moving through several interventions and evaluations.
What do these studies tell you?
- A collaborative and adaptive research design that lends itself to use in work or community situations.
- Design focuses on pragmatic and solution-driven research rather than testing theories.
- When practitioners use action research it has the potential to increase the amount they learn consciously from their experience. The action research cycle can also be regarded as a learning cycle.
- Action search studies often have direct and obvious relevance to practice.
- There are no hidden controls or preemption of direction by the researcher.
What these studies don't tell you?
- It is harder to do than conducting conventional studies because the researcher takes on responsibilities for encouraging change as well as for research.
- Action research is much harder to write up because you probably can’t use a standard format to report your findings effectively.
- Personal over-involvement of the researcher may bias research results.
- The cyclic nature of action research to achieve its twin outcomes of action (e.g. change) and research (e.g. understanding) is time-consuming and complex to conduct.
Gall, Meredith. Educational Research: An Introduction . Chapter 18, Action Research. 8th ed. Boston, MA: Pearson/Allyn and Bacon, 2007; Kemmis, Stephen and Robin McTaggart. “Participatory Action Research.” In Handbook of Qualitative Research . Norman Denzin and Yvonna S. Locoln, eds. 2nd ed. (Thousand Oaks, CA: SAGE, 2000), pp. 567-605.; Reason, Peter and Hilary Bradbury. Handbook of Action Research: Participative Inquiry and Practice . Thousand Oaks, CA: SAGE, 2001.
A case study is an in-depth study of a particular research problem rather than a sweeping statistical survey. It is often used to narrow down a very broad field of research into one or a few easily researchable examples. The case study research design is also useful for testing whether a specific theory and model actually applies to phenomena in the real world. It is a useful design when not much is known about a phenomenon.
- Approach excels at bringing us to an understanding of a complex issue through detailed contextual analysis of a limited number of events or conditions and their relationships.
- A researcher using a case study design can apply a vaiety of methodologies and rely on a variety of sources to investigate a research problem.
- Design can extend experience or add strength to what is already known through previous research.
- Social scientists, in particular, make wide use of this research design to examine contemporary real-life situations and provide the basis for the application of concepts and theories and extension of methods.
- The design can provide detailed descriptions of specific and rare cases.
- A single or small number of cases offers little basis for establishing reliability or to generalize the findings to a wider population of people, places, or things.
- The intense exposure to study of the case may bias a researcher's interpretation of the findings.
- Design does not facilitate assessment of cause and effect relationships.
- Vital information may be missing, making the case hard to interpret.
- The case may not be representative or typical of the larger problem being investigated.
- If the criteria for selecting a case is because it represents a very unusual or unique phenomenon or problem for study, then your intepretation of the findings can only apply to that particular case.
Anastas, Jeane W. Research Design for Social Work and the Human Services . Chapter 4, Flexible Methods: Case Study Design. 2nd ed. New York: Columbia University Press, 1999; Stake, Robert E. The Art of Case Study Research . Thousand Oaks, CA: SAGE, 1995; Yin, Robert K. Case Study Research: Design and Theory . Applied Social Research Methods Series, no. 5. 3rd ed. Thousand Oaks, CA: SAGE, 2003.
Causality studies may be thought of as understanding a phenomenon in terms of conditional statements in the form, “If X, then Y.” This type of research is used to measure what impact a specific change will have on existing norms and assumptions. Most social scientists seek causal explanations that reflect tests of hypotheses. Causal effect (nomothetic perspective) occurs when variation in one phenomenon, an independent variable, leads to or results, on average, in variation in another phenomenon, the dependent variable.
Conditions necessary for determining causality:
- Empirical association--a valid conclusion is based on finding an association between the independent variable and the dependent variable.
- Appropriate time order--to conclude that causation was involved, one must see that cases were exposed to variation in the independent variable before variation in the dependent variable.
- Nonspuriousness--a relationship between two variables that is not due to variation in a third variable.
- Causality research designs helps researchers understand why the world works the way it does through the process of proving a causal link between variables and eliminating other possibilities.
- Replication is possible.
- There is greater confidence the study has internal validity due to the systematic subject selection and equity of groups being compared.
- Not all relationships are casual! The possibility always exists that, by sheer coincidence, two unrelated events appear to be related [e.g., Punxatawney Phil could accurately predict the duration of Winter for five consecutive years but, the fact remains, he's just a big, furry rodent].
- Conclusions about causal relationships are difficult to determine due to a variety of extraneous and confounding variables that exist in a social environment. This means causality can only be inferred, never proven.
- If two variables are correlated, the cause must come before the effect. However, even though two variables might be causally related, it can sometimes be difficult to determine which variable comes first and therefore to establish which variable is the actual cause and which is the actual effect.
Bachman, Ronet. The Practice of Research in Criminology and Criminal Justice . Chapter 5, Causation and Research Designs. 3rd ed. Thousand Oaks, CA: Pine Forge Press, 2007; Causal Research Design: Experimentation. Anonymous SlideShare Presentation ; Gall, Meredith. Educational Research: An Introduction . Chapter 11, Nonexperimental Research: Correlational Designs. 8th ed. Boston, MA: Pearson/Allyn and Bacon, 2007; Trochim, William M.K. Research Methods Knowledge Base . 2006.
Often used in the medical sciences, but also found in the applied social sciences, a cohort study generally refers to a study conducted over a period of time involving members of a population which the subject or representative member comes from, and who are united by some commonality or similarity. Using a quantitative framework, a cohort study makes note of statistical occurrence within a specialized subgroup, united by same or similar characteristics that are relevant to the research problem being investigated, r ather than studying statistical occurrence within the general population. Using a qualitative framework, cohort studies generally gather data using methods of observation. Cohorts can be either "open" or "closed."
- Open Cohort Studies [dynamic populations, such as the population of Los Angeles] involve a population that is defined just by the state of being a part of the study in question (and being monitored for the outcome). Date of entry and exit from the study is individually defined, therefore, the size of the study population is not constant. In open cohort studies, researchers can only calculate rate based data, such as, incidence rates and variants thereof.
- Closed Cohort Studies [static populations, such as patients entered into a clinical trial] involve participants who enter into the study at one defining point in time and where it is presumed that no new participants can enter the cohort. Given this, the number of study participants remains constant (or can only decrease).
- The use of cohorts is often mandatory because a randomized control study may be unethical. For example, you cannot deliberately expose people to asbestos, you can only study its effects on those who have already been exposed. Research that measures risk factors often relies on cohort designs.
- Because cohort studies measure potential causes before the outcome has occurred, they can demonstrate that these “causes” preceded the outcome, thereby avoiding the debate as to which is the cause and which is the effect.
- Cohort analysis is highly flexible and can provide insight into effects over time and related to a variety of different types of changes [e.g., social, cultural, political, economic, etc.].
- Either original data or secondary data can be used in this design.
- In cases where a comparative analysis of two cohorts is made [e.g., studying the effects of one group exposed to asbestos and one that has not], a researcher cannot control for all other factors that might differ between the two groups. These factors are known as confounding variables.
- Cohort studies can end up taking a long time to complete if the researcher must wait for the conditions of interest to develop within the group. This also increases the chance that key variables change during the course of the study, potentially impacting the validity of the findings.
- Because of the lack of randominization in the cohort design, its external validity is lower than that of study designs where the researcher randomly assigns participants.
Healy P, Devane D. “Methodological Considerations in Cohort Study Designs.” Nurse Researcher 18 (2011): 32-36; Levin, Kate Ann. Study Design IV: Cohort Studies. Evidence-Based Dentistry 7 (2003): 51–52; Study Design 101 . Himmelfarb Health Sciences Library. George Washington University, November 2011; Cohort Study . Wikipedia.
Cross-sectional research designs have three distinctive features: no time dimension, a reliance on existing differences rather than change following intervention; and, groups are selected based on existing differences rather than random allocation. The cross-sectional design can only measure diffrerences between or from among a variety of people, subjects, or phenomena rather than change. As such, researchers using this design can only employ a relative passive approach to making causal inferences based on findings.
- Cross-sectional studies provide a 'snapshot' of the outcome and the characteristics associated with it, at a specific point in time.
- Unlike the experimental design where there is an active intervention by the researcher to produce and measure change or to create differences, cross-sectional designs focus on studying and drawing inferences from existing differences between people, subjects, or phenomena.
- Entails collecting data at and concerning one point in time. While longitudinal studies involve taking multiple measures over an extended period of time, cross-sectional research is focused on finding relationships between variables at one moment in time.
- Groups identified for study are purposely selected based upon existing differences in the sample rather than seeking random sampling.
- Cross-section studies are capable of using data from a large number of subjects and, unlike observational studies, is not geographically bound.
- Can estimate prevalence of an outcome of interest because the sample is usually taken from the whole population.
- Because cross-sectional designs generally use survey techniques to gather data, they are relatively inexpensive and take up little time to conduct.
- Finding people, subjects, or phenomena to study that are very similar except in one specific variable can be difficult.
- Results are static and time bound and, therefore, give no indication of a sequence of events or reveal historical contexts.
- Studies cannot be utilized to establish cause and effect relationships.
- Provide only a snapshot of analysis so there is always the possibility that a study could have differing results if another time-frame had been chosen.
- There is no follow up to the findings.
Hall, John. “Cross-Sectional Survey Design.” In Encyclopedia of Survey Research Methods. Paul J. Lavrakas, ed. (Thousand Oaks, CA: Sage, 2008), pp. 173-174; Helen Barratt, Maria Kirwan. Cross-Sectional Studies: Design, Application, Strengths and Weaknesses of Cross-Sectional Studies . Healthknowledge, 2009. Cross-Sectional Study . Wikipedia.
Descriptive research designs help provide answers to the questions of who, what, when, where, and how associated with a particular research problem; a descriptive study cannot conclusively ascertain answers to why. Descriptive research is used to obtain information concerning the current status of the phenomena and to describe "what exists" with respect to variables or conditions in a situation.
- The subject is being observed in a completely natural and unchanged natural environment. True experiments, whilst giving analyzable data, often adversely influence the normal behavior of the subject.
- Descriptive research is often used as a pre-cursor to more quantitatively research designs, the general overview giving some valuable pointers as to what variables are worth testing quantitatively.
- If the limitations are understood, they can be a useful tool in developing a more focused study.
- Descriptive studies can yield rich data that lead to important recommendations.
- Appoach collects a large amount of data for detailed analysis.
- The results from a descriptive research can not be used to discover a definitive answer or to disprove a hypothesis.
- Because descriptive designs often utilize observational methods [as opposed to quantitative methods], the results cannot be replicated.
- The descriptive function of research is heavily dependent on instrumentation for measurement and observation.
Anastas, Jeane W. Research Design for Social Work and the Human Services . Chapter 5, Flexible Methods: Descriptive Research. 2nd ed. New York: Columbia University Press, 1999; McNabb, Connie. Descriptive Research Methodologies . Powerpoint Presentation; Shuttleworth, Martyn. Descriptive Research Design , September 26, 2008. Explorable.com website.
A blueprint of the procedure that enables the researcher to maintain control over all factors that may affect the result of an experiment. In doing this, the researcher attempts to determine or predict what may occur. Experimental Research is often used where there is time priority in a causal relationship (cause precedes effect), there is consistency in a causal relationship (a cause will always lead to the same effect), and the magnitude of the correlation is great. The classic experimental design specifies an experimental group and a control group. The independent variable is administered to the experimental group and not to the control group, and both groups are measured on the same dependent variable. Subsequent experimental designs have used more groups and more measurements over longer periods. True experiments must have control, randomization, and manipulation.
- Experimental research allows the researcher to control the situation. In so doing, it allows researchers to answer the question, “what causes something to occur?”
- Permits the researcher to identify cause and effect relationships between variables and to distinguish placebo effects from treatment effects.
- Experimental research designs support the ability to limit alternative explanations and to infer direct causal relationships in the study.
- Approach provides the highest level of evidence for single studies.
- The design is artificial, and results may not generalize well to the real world.
- The artificial settings of experiments may alter subject behaviors or responses.
- Experimental designs can be costly if special equipment or facilities are needed.
- Some research problems cannot be studied using an experiment because of ethical or technical reasons.
- Difficult to apply ethnographic and other qualitative methods to experimental designed research studies.
Anastas, Jeane W. Research Design for Social Work and the Human Services . Chapter 7, Flexible Methods: Experimental Research. 2nd ed. New York: Columbia University Press, 1999; Chapter 2: Research Design, Experimental Designs . School of Psychology, University of New England, 2000; Experimental Research. Research Methods by Dummies. Department of Psychology. California State University, Fresno, 2006; Trochim, William M.K. Experimental Design . Research Methods Knowledge Base. 2006; Rasool, Shafqat. Experimental Research . Slideshare presentation.
An exploratory design is conducted about a research problem when there are few or no earlier studies to refer to. The focus is on gaining insights and familiarity for later investigation or undertaken when problems are in a preliminary stage of investigation.
The goals of exploratory research are intended to produce the following possible insights:
- Familiarity with basic details, settings and concerns.
- Well grounded picture of the situation being developed.
- Generation of new ideas and assumption, development of tentative theories or hypotheses.
- Determination about whether a study is feasible in the future.
- Issues get refined for more systematic investigation and formulation of new research questions.
- Direction for future research and techniques get developed.
- Design is a useful approach for gaining background information on a particular topic.
- Exploratory research is flexible and can address research questions of all types (what, why, how).
- Provides an opportunity to define new terms and clarify existing concepts.
- Exploratory research is often used to generate formal hypotheses and develop more precise research problems.
- Exploratory studies help establish research priorities.
- Exploratory research generally utilizes small sample sizes and, thus, findings are typically not generalizable to the population at large.
- The exploratory nature of the research inhibits an ability to make definitive conclusions about the findings.
- The research process underpinning exploratory studies is flexible but often unstructured, leading to only tentative results that have limited value in decision-making.
- Design lacks rigorous standards applied to methods of data gathering and analysis because one of the areas for exploration could be to determine what method or methodologies could best fit the research problem.
Cuthill, Michael. “Exploratory Research: Citizen Participation, Local Government, and Sustainable Development in Australia.” Sustainable Development 10 (2002): 79-89; Taylor, P. J., G. Catalano, and D.R.F. Walker. “Exploratory Analysis of the World City Network.” Urban Studies 39 (December 2002): 2377-2394; Exploratory Research . Wikipedia.
The purpose of a historical research design is to collect, verify, and synthesize evidence from the past to establish facts that defend or refute your hypothesis. It uses secondary sources and a variety of primary documentary evidence, such as, logs, diaries, official records, reports, archives, and non-textual information [maps, pictures, audio and visual recordings]. The limitation is that the sources must be both authentic and valid.
- The historical research design is unobtrusive; the act of research does not affect the results of the study.
- The historical approach is well suited for trend analysis.
- Historical records can add important contextual background required to more fully understand and interpret a research problem.
- There is no possibility of researcher-subject interaction that could affect the findings.
- Historical sources can be used over and over to study different research problems or to replicate a previous study.
- The ability to fulfill the aims of your research are directly related to the amount and quality of documentation available to understand the research problem.
- Since historical research relies on data from the past, there is no way to manipulate it to control for contemporary contexts.
- Interpreting historical sources can be very time consuming.
- The sources of historical materials must be archived consistentally to ensure access.
- Original authors bring their own perspectives and biases to the interpretation of past events and these biases are more difficult to ascertain in historical resources.
- Due to the lack of control over external variables, historical research is very weak with regard to the demands of internal validity.
- It rare that the entirety of historical documentation needed to fully address a research problem is available for interpretation, therefore, gaps need to be acknowledged.
Savitt, Ronald. “Historical Research in Marketing.” Journal of Marketing 44 (Autumn, 1980): 52-58; Gall, Meredith. Educational Research: An Introduction . Chapter 16, Historical Research. 8th ed. Boston, MA: Pearson/Allyn and Bacon, 2007.
A longitudinal study follows the same sample over time and makes repeated observations. With longitudinal surveys, for example, the same group of people is interviewed at regular intervals, enabling researchers to track changes over time and to relate them to variables that might explain why the changes occur. Longitudinal research designs describe patterns of change and help establish the direction and magnitude of causal relationships. Measurements are taken on each variable over two or more distinct time periods. This allows the researcher to measure change in variables over time. It is a type of observational study and is sometimes referred to as a panel study.
- Longitudinal data allow the analysis of duration of a particular phenomenon.
- Enables survey researchers to get close to the kinds of causal explanations usually attainable only with experiments.
- The design permits the measurement of differences or change in a variable from one period to another [i.e., the description of patterns of change over time].
- Longitudinal studies facilitate the prediction of future outcomes based upon earlier factors.
- The data collection method may change over time.
- Maintaining the integrity of the original sample can be difficult over an extended period of time.
- It can be difficult to show more than one variable at a time.
- This design often needs qualitative research to explain fluctuations in the data.
- A longitudinal research design assumes present trends will continue unchanged.
- It can take a long period of time to gather results.
- There is a need to have a large sample size and accurate sampling to reach representativness.
Anastas, Jeane W. Research Design for Social Work and the Human Services . Chapter 6, Flexible Methods: Relational and Longitudinal Research. 2nd ed. New York: Columbia University Press, 1999; Kalaian, Sema A. and Rafa M. Kasim. "Longitudinal Studies." In Encyclopedia of Survey Research Methods . Paul J. Lavrakas, ed. (Thousand Oaks, CA: Sage, 2008), pp. 440-441; Ployhart, Robert E. and Robert J. Vandenberg. "Longitudinal Research: The Theory, Design, and Analysis of Change.” Journal of Management 36 (January 2010): 94-120; Longitudinal Study . Wikipedia.
This type of research design draws a conclusion by comparing subjects against a control group, in cases where the researcher has no control over the experiment. There are two general types of observational designs. In direct observations, people know that you are watching them. Unobtrusive measures involve any method for studying behavior where individuals do not know they are being observed. An observational study allows a useful insight into a phenomenon and avoids the ethical and practical difficulties of setting up a large and cumbersome research project.
- Observational studies are usually flexible and do not necessarily need to be structured around a hypothesis about what you expect to observe (data is emergent rather than pre-existing).
- The researcher is able to collect a depth of information about a particular behavior.
- Can reveal interrelationships among multifaceted dimensions of group interactions.
- You can generalize your results to real life situations.
- Observational research is useful for discovering what variables may be important before applying other methods like experiments.
- Observation researchd esigns account for the complexity of group behaviors.
- Reliability of data is low because seeing behaviors occur over and over again may be a time consuming task and difficult to replicate.
- In observational research, findings may only reflect a unique sample population and, thus, cannot be generalized to other groups.
- There can be problems with bias as the researcher may only "see what they want to see."
- There is no possiblility to determine "cause and effect" relationships since nothing is manipulated.
- Sources or subjects may not all be equally credible.
- Any group that is studied is altered to some degree by the very presence of the researcher, therefore, skewing to some degree any data collected (the Heisenburg Uncertainty Principle).
Atkinson, Paul and Martyn Hammersley. “Ethnography and Participant Observation.” In Handbook of Qualitative Research . Norman K. Denzin and Yvonna S. Lincoln, eds. (Thousand Oaks, CA: Sage, 1994), pp. 248-261; Observational Research. Research Methods by Dummies. Department of Psychology. California State University, Fresno, 2006; Patton Michael Quinn. Qualitiative Research and Evaluation Methods . Chapter 6, Fieldwork Strategies and Observational Methods. 3rd ed. Thousand Oaks, CA: Sage, 2002; Rosenbaum, Paul R. Design of Observational Studies . New York: Springer, 2010.
Understood more as an broad approach to examining a research problem than a methodological design, philosophical analysis and argumentation is intended to challenge deeply embedded, often intractable, assumptions underpinning an area of study. This approach uses the tools of argumentation derived from philosophical traditions, concepts, models, and theories to critically explore and challenge, for example, the relevance of logic and evidence in academic debates, to analyze arguments about fundamental issues, or to discuss the root of existing discourse about a research problem. These overarching tools of analysis can be framed in three ways:
- Ontology -- the study that describes the nature of reality; for example, what is real and what is not, what is fundamental and what is derivative?
- Epistemology -- the study that explores the nature of knowledge; for example, on what does knowledge and understanding depend upon and how can we be certain of what we know?
- Axiology -- the study of values; for example, what values does an individual or group hold and why? How are values related to interest, desire, will, experience, and means-to-end? And, what is the difference between a matter of fact and a matter of value?
- Can provide a basis for applying ethical decision-making to practice.
- Functions as a means of gaining greater self-understanding and self-knowledge about the purposes of research.
- Brings clarity to general guiding practices and principles of an individual or group.
- Philosophy informs methodology.
- Refine concepts and theories that are invoked in relatively unreflective modes of thought and discourse.
- Beyond methodology, philosophy also informs critical thinking about epistemology and the structure of reality (metaphysics).
- Offers clarity and definition to the practical and theoretical uses of terms, concepts, and ideas.
- Limited application to specific research problems [answering the "So What?" question in social science research].
- Analysis can be abstract, argumentative, and limited in its practical application to real-life issues.
- While a philosophical analysis may render problematic that which was once simple or taken-for-granted, the writing can be dense and subject to unnecessary jargon, overstatement, and/or excessive quotation and documentation.
- There are limitations in the use of metaphor as a vehicle of philosophical analysis.
- There can be analytical difficulties in moving from philosophy to advocacy and between abstract thought and application to the phenomenal world.
Chapter 4, Research Methodology and Design . Unisa Institutional Repository (UnisaIR), University of South Africa; Labaree, Robert V. and Ross Scimeca. “The Philosophical Problem of Truth in Librarianship.” The Library Quarterly 78 (January 2008): 43-70; Maykut, Pamela S. Beginning Qualitative Research: A Philosophic and Practical Guide . Washington, D.C.: Falmer Press, 1994; Stanford Encyclopedia of Philosophy . Metaphysics Research Lab, CSLI, Stanford University, 2013.
- The researcher has a limitless option when it comes to sample size and the sampling schedule.
- Due to the repetitive nature of this research design, minor changes and adjustments can be done during the initial parts of the study to correct and hone the research method. Useful design for exploratory studies.
- There is very little effort on the part of the researcher when performing this technique. It is generally not expensive, time consuming, or workforce extensive.
- Because the study is conducted serially, the results of one sample are known before the next sample is taken and analyzed.
- The sampling method is not representative of the entire population. The only possibility of approaching representativeness is when the researcher chooses to use a very large sample size significant enough to represent a significant portion of the entire population. In this case, moving on to study a second or more sample can be difficult.
- Because the sampling technique is not randomized, the design cannot be used to create conclusions and interpretations that pertain to an entire population. Generalizability from findings is limited.
- Difficult to account for and interpret variation from one sample to another over time, particularly when using qualitative methods of data collection.
Rebecca Betensky, Harvard University, Course Lecture Note slides ; Cresswell, John W. Et al. “Advanced Mixed-Methods Research Designs.” In Handbook of Mixed Methods in Social and Behavioral Research . Abbas Tashakkori and Charles Teddle, eds. (Thousand Oaks, CA: Sage, 2003), pp. 209-240; Nataliya V. Ivankova. “Using Mixed-Methods Sequential Explanatory Design: From Theory to Practice.” Field Methods 18 (February 2006): 3-20; Bovaird, James A. and Kevin A. Kupzyk. “Sequential Design.” In Encyclopedia of Research Design . Neil J. Salkind, ed. Thousand Oaks, CA: Sage, 2010; Sequential Analysis . Wikipedia.
- << Previous: Purpose of Guide
- Next: Design Flaws to Avoid >>
- Last Updated: Jul 18, 2023 11:58 AM
- URL: https://library.sacredheart.edu/c.php?g=29803
- QuickSearch
- Library Catalog
- Databases A-Z
- Publication Finder
- Course Reserves
- Citation Linker
- Digital Commons
- Our Website
Research Support
- Ask a Librarian
- Appointments
- Interlibrary Loan (ILL)
- Research Guides
- Databases by Subject
- Citation Help
Using the Library
- Reserve a Group Study Room
- Renew Books
- Honors Study Rooms
- Off-Campus Access
- Library Policies
- Library Technology
User Information
- Grad Students
- Online Students
- COVID-19 Updates
- Staff Directory
- News & Announcements
- Library Newsletter
My Accounts
- Interlibrary Loan
- Staff Site Login
FIND US ON
Advertisement
The Role of Patient-Reported Outcomes to Measure Treatment Satisfaction in Drug Development
- Leading Article
- Open access
- Published: 08 July 2024
Cite this article
You have full access to this open access article

- Carolina Navas ORCID: orcid.org/0000-0002-3717-398X 1 ,
- Alexandra Palmer Minton 2 &
- Ana Maria Rodriguez-Leboeuf 1
289 Accesses
2 Altmetric
Explore all metrics
Treatment satisfaction is a person’s rating of his or her treatment experience, including processes and outcomes. It is directly related to treatment adherence, which may be predictive of treatment effectiveness in clinical and real-world research. Consequently, patient-reported outcome (PRO) instruments have been developed to incorporate patient experience throughout various stages of drug development and routine care. PRO instruments enable clinicians and researchers to evaluate and compare treatment satisfaction data in different clinical settings. It is important to select fit-for-purpose PRO instruments that have demonstrated adequate levels of reliability, validity, and sensitivity to change to support their use. Some of these instruments are unidimensional while some are multidimensional; some are generic and can be applied across different therapeutic areas, while others have been developed for use in a specific treatment modality or condition. This article describes the role of treatment satisfaction in drug development as well as regulatory and Health Technology Assessment (HTA) decision making and calls for more widespread use of carefully selected treatment satisfaction PRO instruments in early- and late-phase drug development.
Similar content being viewed by others
One programme, four stakeholders: an overview of the utilisation of patient-reported outcomes in intervention development to meet the needs of regulators, payers, healthcare professionals and patients, fit for purpose and modern validity theory in clinical outcomes assessment.

Using Individual Experiences With Experimental Medications to Predict Medication-Taking Behavior Postauthorization: A DIA Study Endpoints Workstream
Avoid common mistakes on your manuscript.
This paper provides an overview of the role of treatment satisfaction in drug development, regulatory and HTA decision making. |
The main goal is to call for more extensive use of fit-for-purpose PRO instruments to assess treatment satisfaction in all phases of drug development. |
1 Introduction
In the era of patient-centered drug development, it is critical for drug developers, regulators, payers, and researchers to collect and understand the patients’ perspectives on drugs (and other treatments) during their development [ 1 , 2 ]. When a treatment is approved and made available for clinical use, data on how patients feel whilst taking the treatment provides healthcare professionals and patients with valuable insights, enabling the delivery of evidence-based medicine. Evidence-based medicine refers to the application of the best available research to clinical care, which requires the integration of evidence with clinical expertise and patient values [ 3 ]. The measurement of treatment satisfaction using a PRO instrument offers a standardized way of generating such data during treatment development.
2 Treatment Satisfaction Definition
Treatment satisfaction is defined as the individual’s rating of important attributes of the process and outcomes of their treatment experience [ 4 , 5 ]. An individual’s satisfaction with a treatment will be influenced by their knowledge and experience of the treatment. Specifically, perceived or experienced treatment effectiveness, administration complexity and convenience, discomfort and side effects (see the Decisional Balance Model of Treatment Satisfaction [ 6 ]; Fig. 1 a), as well as cost of the treatment will inform how satisfied or dissatisfied an individual is with a treatment [ 7 ]. Patient expectations, demographic characteristics (age and education), and personal preferences can also affect treatment satisfaction, as can prior experience with disease and with treatment [ 8 ].

Treatment satisfaction framework: a Decision balance model of treatment satisfaction. b Adaptation of Weaver and colleagues' conceptual model of treatment satisfaction [ 9 ]
Treatment satisfaction can be a useful concept for researchers, intervention developers, and healthcare professionals wishing to understand the patient experience with treatment, and to differentiate among alternative treatments. Understanding treatment satisfaction can also help with understanding the likelihood of adherence and persistence to treatment [ 4 ]. This can ultimately lead to improved health status as depicted in the conceptual framework of treatment satisfaction developed by Weaver and colleagues [ 9 ] (Fig. 1 b).
The association between treatment satisfaction, adherence, and persistence is clinically intuitive. If a patient is not satisfied with treatment, this feeling may negatively affect his or her behavior in terms of regimen execution as well as his or her willingness to persist with the treatment [ 6 ]. The connection between treatment satisfaction and persistence is even more important in chronic diseases where up to one half of patients make medication-related decisions without seeking medical advice [ 10 ]. Indeed, in chronic diseases, patient dissatisfaction (rather than clinical consultation and decision making) is one of the main drivers of treatment discontinuation [ 6 , 11 , 12 , 13 ], which in turn can lead to an increased rate of complications, deterioration in health, and ultimately death [ 6 , 14 , 15 ].
Understanding treatment satisfaction across multiple treatments can also help to predict patient preferences for alternative treatments—an important consideration when there are several options for treatment that involve alternate routes of administration, types of medication, or drug regimens [ 16 ] [ 17 ]. Research in oncology has shown, for instance, that treatment satisfaction and adherence are highest when people are offered treatment that is in line with their own preferences [ 18 ].
3 Treatment Satisfaction Measurement
Treatment satisfaction is a highly individual and personal experience. To understand this concept, researchers as well as healthcare providers must rely on patients’ reports [ 4 ]. Patient reports can be generated in two ways: through narrative exploration (i.e., by talking to patients to qualitatively understand their experiences) or through PRO instruments (i.e., using standardized questionnaires to generate quantitative data).
Qualitative research offers the opportunity to explore satisfaction in depth, including drivers of satisfaction and implications of being satisfied/dissatisfied in terms of feelings and behaviors. Qualitative research can, however, be intrusive; reactive to personalities, moods and interpersonal dynamics between interviewer and interviewee; expensive; and time consuming [ 19 ].
PRO instruments are measures of a patient’s perspective as reported directly from the patient without added interpretation by a healthcare worker or anyone else [ 20 ]. PRO instruments offer a way to collect patient information quickly and in a standardized manner and are thus frequently used to evaluate the impact of disease and treatments on the patient’s functioning, well-being, and everyday life in clinical trials [ 4 ].
There are a large number of PRO instruments measuring treatment satisfaction [ 21 ]. They differ on a number of parameters, including number of items, measurement properties, and targeted use.
3.1 Number of Items
Some treatment satisfaction PRO instruments consist of a single item measuring global treatment satisfaction [ 22 ]. Other intruments include multiple items, some of which may contribute to one overall rating of satisfaction, or they may measure different dimensions of satisfaction (efficacy, side effects, convenience) [ 23 ]. Single-item measures offer simplicity and speed. However, use of a single item can mean the loss of important information about how patients view a treatment. Most of the patients that answer single-item questionnaires, for example, report high levels of satisfaction regardless of other negative information [ 24 ].
3.2 Measurement Properties
PRO instruments need to demonstrate that they measure what they were designed to measure in a reliable, valid, and an interpretable way in order to be considered ‘fit for purpose’ to support regulatory, payer, and healthcare decision making. A ‘fit for purpose’ PRO instrument demonstrates the following measurement properties: reliability (internal consistency and test re-test), validity (content and construct), and responsiveness (sensitivity to change) [ 25 ]. Sound measurement properties are not just critical for PRO instruments but rather applicable to all measurement methodologies for data collection [ 26 ]. Without evidence of reliability, validity, and sensitivity to change, the PRO instrument may produce inconsistent results that cannot be replicated or compared across studies, leading to inaccurate or misleading study results and a risk of misattribution of outcomes to the treatment under investigation [ 26 ].
3.3 Targeted Use
Treatment satisfaction PRO instruments can be generic (i.e., designed for use across different disease/therapeutic populations) or disease/context-specific (i.e., built to address those aspects of satisfaction that are important for a particular and specific group of patients) [ 27 ] [ 28 ]. Generic instruments allow for comparisons between diseases, across different populations, or across medication types and patient conditions [ 29 ]. Whereas disease/context-specific instruments arguably possess greater potential for showing differences between competing therapies, they cannot be applied across populations [ 30 ]. Examples of generic and disease-specific questionnaires developed for use in routine care and drug development to assess treatment satisfaction from patients are presented in Tables 1 and 2 , respectively [ 31 , 32 , 33 , 34 , 35 , 36 , 37 , 38 , 39 , 40 , 41 , 42 , 43 , 44 , 45 , 46 , 47 , 48 ].
4 Treatment Satisfaction in Drug Development
The measurement of treatment satisfaction should not be prioritized over efficacy, safety, or survival data (which have been frequently used as primary indicators for drug development [ 52 ]). However, as barriers to developing new products increase, and the number of markets with generic competition or at least multiple alternative treatments grow, satisfaction can be an important secondary endpoint to provide information about how people feel about the treatment they took in the trial and provide evidence of the value (or concerns) of certain treatments. This can support key efficacy, safety, and survival endpoints [ 53 ].
Thus, treatment satisfaction has become an important outcome for drug development [ 54 ], particularly in trials (1) comparing treatments that present differences in terms of efficacy or side effects; (2) comparing treatments that are similar in terms of efficacy but have different routes of administration or dosing schedules; or (3) where demonstration of satisfaction with a medication relative to a comparator is considered to indicate adherence benefits [ 16 ] and/or treatment effectiveness [ 55 ]. Generic and disease-specific, multidimensional, and single-item PRO instruments can be useful to measure treatment satisfaction in clinical trials for novel drugs in development. But to do so, they must have demonstrated evidence of reliability, validity, and responsiveness for the intended use.
The use of PRO treatment satisfaction instruments in clinical research has increased in recent years, in line with various initiatives focusing on increasing the patient perspective in drug development [ 56 ]. From the authors’ recently completed review of clinicaltrials.gov data , it was found that 4978 clinical studies assessed a treatment satisfaction endpoint between 2004 and 2015, and 8488 clinical studies assessed a treatment satisfaction endpoint between 2016 and 2023 (data on file). The evaluation of treatment satisfaction as an outcome in drug development, however, only represents a small fraction of the total studies undertaken during this time (3.3%). The recent development of clear guidelines from regulators for the use of PRO instruments to support clinical trial evidence (e.g., the FDA Patient-Focused Drug Development [PFDD] [ 20 ] guidance), an increased concern towards patient centricity throughout the product evidence lifecycle, and an increase in the development of drugs that differentiate through non-efficacy parameters (e.g., by frequency or modality of administration, side-effect profiles, etc.) suggests that treatment satisfaction endpoints in clinical trials are likely to increase in coming years.
Where treatment satisfaction has been measured in clinical trials, it has tended to be in the later phases of drug development. An analysis of clinicaltrials.gov data on the use of the Treatment Satisfaction Questionnaire for Medication (TSQM) over the 5-year period between 2016–2021 demonstrates that TSQM has been more frequently used in phase III interventional studies than in phase II or phase I trials [ 54 ]. Its use in later phase trials makes sense. Once the safety and efficacy of a drug have been explored in an early phase study, measuring domains of satisfaction helps researchers and sponsors understand why one compound, dose, or method of administration may be preferred over another, predict adherence, and support messages regarding the value of the product to patients. However, treatment satisfaction may also have an important role to play in earlier phases of drug development. Treatment satisfaction in dose finding research (phase I/II) can inform the selection of doses for later trials, especially for products used for the treatment of chronic conditions that require adherence to medication over long periods of time. In such trials, an understanding of satisfaction with treatment can offer some insight and hypotheses [ 24 ]. For example, treatment satisfaction data can evaluate medical treatment in clinical trials, contributes to quality assurance, and facilitates product differentiation [ 57 ]. Specifically, in the field of cancer clinical trials, reported levels of treatment satisfaction added a unique view for the evaluation of treatment efficacy [ 58 ].
Treatment satisfaction data is also important in post-registration (phase IIIb/IV) real-world settings because it can provide valuable insight into the economic valuations and cost-effectiveness assessments of medical products, such as whether or not a treatment is worthy of reimbursement [ 59 ]. Real-world evidence (RWE) studies involve a greater number of diverse patients and in general a more representative population [ 60 ], which can further help inform regulatory decisions, reimbursement, and health policy-making. There are several measures of treatment satisfaction that have been used in RWE studies. For example, the TSQM has been used to measure treatment satisfaction in amyotrophic lateral sclerosis [ 61 ] [ 62 ], the Treatment Satisfaction with Medicines Questionnaire (SATMED-Q) in acromegalia patients [ 63 ], the Diabetes Treatment Satisfaction Questionnaire (DTSQ) in patients with type 2 diabetes [ 64 ], and the Cancer Therapy Satisfaction Questionnaire (CTSQ) in metastatic squamous cell carcinoma of the head and neck [ 65 ].
Patient-centered drug development is a shift in the way that drugs are developed, involving patients in all phases of drug development. In patient-centered research, patients are considered co-researchers informing the decisions about unmet needs, trial endpoints, trial design, and execution. Drug development companies that incorporate patient voice through treatment satisfaction PRO instruments are more likely to ensure a fit of their product to the patients’ needs in routine practice and provide the benefits patients are seeking. Specifically, treatment satisfaction measures allow for treatment comparison in clinical trials or the identification of the need to switch a patient's treatment in clinical practice. Additionally, these measures can address, among other outcomes, the willingness of patients to accept the negative effects of their treatment, adherence to the prescribed medication, and can be related to the overall effectiveness of their treatment [ 23 ]. Therefore, we highly recommend assessing treatment satisfaction in the different stages of drug development: during the initial development and validation, as well as at the point of implementation and communication of the results. Furthermore, it is more probable that this data can be proactively utilized to aid in regulatory decision making.
5 Treatment Satisfaction in Regulatory Decision Making
The regulatory environment is primed to consider data on treatment satisfaction from drug development. Both the US Food and Drug Administration (FDA) and the European Medicines Agency (EMA) have noted the critical importance of involving patients in the identification of health priorities and the outcomes desired from health interventions and in understanding the patient experience with these interventions [ 66 ]. Data from reliable, valid, and responsive PRO instruments can be considered as ‘fit for purpose’ and help regulators make approval decisions [ 49 , 50 , 51 ].
The EMA has a long history of working with patients and patient data. In 2005, a reflection paper was developed as a framework for interaction between EMA and patients, consumers, and consumer organizations to encourage the collection of PRO data [ 67 ]. In EMA’s ‘Regulatory Science Strategy to 2025,’ one core recommendation is to “ensure the patient voice is incorporated all along the regulatory lifecycle of a medicine”, reflecting the importance the Agency places on such engagement [ 67 ]. The FDA also has a long history of patient engagement, starting from 1988 with the formation of an office to work with patient advocates [ 66 ]. In 2009, the FDA developed the PRO Guidance that outlines the rigor used by regulators to review and evaluate existing, modified, or newly developed PRO instruments to support label claims [ 68 ]. More recently, the FDA launched its PFDD initiative as a commitment to capture and submit patient experience data and other relevant information from patients for drug development and regulatory decision making more systematically [ 20 ].
At the FDA and EMA, evidence supporting efficacy and safety of the medication being developed is included in the ‘label’ at the point of approval (FDA ‘label’ is the US Prescribing Information; EMA label is the Summary of Product Characteristics). The primary purpose of drug labeling is to give healthcare professionals the information they need to prescribe the medicine appropriately [ 69 ]. The label cannot include promotional, false, or misleading statements [ 69 ]. It can, however, include other information deemed to be relevant and important in understanding the medication, assuming that the data is derived from fit-for-purpose measurement in adequate and well-controlled clinical investigations. The EMA considers both single and multidimensional domains—such as health status and satisfaction with treatment—for inclusion in labelling [ 70 ]. While traditionally more focused on core signs and symptoms of disease, recent PFDD guidance and workshop discussion from FDA proposes satisfaction as one component of a benefit–risk appraisal [ 20 ] [ 71 ].
Data extracted from 2010 until 2023 indicates that 57 drugs or medical products have included treatment satisfaction claims in their label, all using PRO instruments [ 43 ]. The EMA has approved 19 drugs (33.3%) and 38 (66.6%) have been approved by the FDA. Various PRO instruments have been used to support these claims, including the aforementioned TSQM which meets the evidence needed by regulators to support label decisions in certain contexts of use [ 57 ]. The TSQM supported six of the aforementioned treatment satisfaction label claims (5/19 drugs the EMA approved with treatment satisfaction claims in their label and 1/38 drugs the FDA approved with treatment satisfaction claims in their label) [ 72 , 73 , 74 , 75 , 76 , 77 ]. However, this represents only a small fraction of drugs approved in this timescale.
Therefore, treatment satisfaction is appealing to agencies because of its utility as a well-known patient-reported endpoint that captures patient experience [ 54 , 57 ]. The assessment of treatment satisfaction plays an increasingly important role in regulatory decision making which ultimately improves the quality and value of health care [ 78 ] [ 79 ].
6 Treatment Satisfaction in Health Technology Assessment (HTA)
HTA agencies play a vital role in assessing the safety, efficacy, cost, and benefits of new treatments [ 80 ], which requires consideration of the patient experience with the given treatment. Patients are going to be the first beneficiaries of health innovation and are best suited to evaluate treatment satisfaction. Therefore, some HTA agencies have been utilizing PRO instruments to capture the patient's voice when evaluating pharmacotherapies or medical technologies.
PRO instruments are a key component of decision making during the benefit–risk appraisal of new drugs or biologic products across different therapeutic areas [ 81 ]. Data from reliable, valid, and responsive (i.e., ‘fit for purpose’) PRO instruments can help HTA bodies make access decisions [ 49 , 50 , 51 ]. For example, when assessing the effectiveness of a drug, not only are the clinical outcomes significant to regulatory and reimbursement agencies, but also the drug's influence on patients’ daily lives, functional status, treatment satisfaction, preferences, and adherence [ 82 ]. The inclusion of treatment satisfaction measures is an effective way to assess and evaluate patient experience with the new treatment by HTA agencies. For example, treatment satisfaction measures can help HTA bodies choose between two treatments that have similar biomedical effects but present differences in terms of side effects, convenience, and mode of administration. Moreover, HTAs look for evidence to help inform formulary decisions, both at launch and during post-launch reviews. They may find that treatment satisfaction data can support and complement the traditional efficacy and safety data available from classical clinical endpoints [ 82 ]. However, there are substantial differences in HTA reimbursement decisions that could be explained by the different processes and policies in place at different HTA agencies, such as criteria for the extent of added value versus cost effectiveness [ 83 ]. Such discrepancies across countries make it challenging for sponsors not only to identify and utilize appropriate PRO instruments to capture the patient experience but also to develop appropriate methodologies for capturing these data within both clinical trial and real-world settings. However, HTA bodies have recognized treatment satisfaction can confirm clinical benefits and support reimbursement recommendations, and thus it is essential to continue to include treatment satisfaction as a key assessment throughout the drug development and commercialization process.
7 A Call to Action
Patients are in a unique position to provide treatment satisfaction assessment as they are the ones who experience the effectiveness and side effects of the therapy. Several PRO instruments offer robust fit-for-purpose (reliable, valid, sensitive) measurement of treatment satisfaction, and research has shown these can predict the likelihood of patients continuing to use their medication, the correct usage of the medication, and adherence to the treatment. It is also known that treatment satisfaction can support drug development and needs to be considered by most of the stakeholders involved in the healthcare system, from development to launch of a product and within routine clinical practice use. Moreover, the FDA and EMA have approved treatment satisfaction in label claims of certain medications. Measuring treatment satisfaction more frequently in clinical trials and studies will give us a comprehensive understanding of patient health status, facilitating appropriate and optimal treatment decisions and improving future drug development.
We encourage measuring treatment satisfaction across the phases of interventional studies and RWE studies as doing so can be beneficial for the different stakeholders involved in drug development and regulatory decision making: (1) for pharmaceutical companies, satisfaction with a specific type of medication should lead to a differential advantage in the marketplace, product success, manufacturer profitability, and better market access; (2) for healthcare systems, understanding patient satisfaction is a critical pillar to develop more efficient and effective care models; (3) for patients, higher treatment satisfaction can lead to increased treatment adherence and better clinical outcomes.
Algorri M, Cauchon NS, Christian T, O’Connell C, Vaidya P. Patient-centric product development: a summary of select regulatory CMC and device considerations. J Pharm Sci. 2023;112(4):922–36. https://doi.org/10.1016/j.xphs.2023.01.029 . ( Epub 2023 Feb 3 ).
Article CAS PubMed Google Scholar
van Overbeeke E, Vanbinst I, Jimenez-Moreno AC, Huys I. Patient centricity in patient preference studies: the patient perspective. Front Med. 2020;7:93.
Article Google Scholar
Reena Pattani, Sharon E. Straus. What is EBM?.BMJ Best Practice. 2023. https://bestpractice.bmj.com/info/toolkit/learn-ebm/what-is-ebm/ . Accessed 10 Oct 2023.
Revicki D. Patient assessment of treatment satisfaction: methods and practical issue. Gut. 2004. https://doi.org/10.1136/gut.2003.0343225 .
Article PubMed PubMed Central Google Scholar
Salame N, Perez-Chada LM, Singh S, CallisDuffin K, Garg A, Gottlieb AB, et al. Are your patients satisfied a systematic review of treatment satisfaction measures in psoriasis. Dermatology. 2018;234(5–6):157–65.
Article PubMed Google Scholar
Atkinson MJ, Sinha A, Hass SL, Colman SS, Kumar RN, Brod M, et al. Validation of a general measure of treatment satisfaction, the Treatment Satisfaction Questionnaire for Medication (TSQM), using a national panel study of chronic disease. Health Qual Life Outcomes. 2004;2(1):12.
Barbosa CD, Balp MM, Kulich K, Germain N, Rofail D. A literature review to explore the link between treatment satisfaction and adherence, compliance, and persistence. Patient Prefer Adherence. 2012;6:39–48.
Kravitz RL. Patients’ expectations for medical care: an expanded formulation based on review of the literature. Med Care Res Rev MCRR. 1996;53(1):3–27.
Weaver M, Patrick DL, Markson LE, Martin D, Frederic I, Berger M. Issues in the measurement of satisfaction with treatment. Am J Manag Care. 1997;3(4):579–94 ( PMID: 10169526 ).
CAS PubMed Google Scholar
Lemay J, Waheedi M, Al-Sharqawi S, Bayoud T. Medication adherence in chronic illness: do beliefs about medications play a role? Patient Prefer Adherence. 2018;12:1687–98.
Fernandez-Lazaro CI, García-González JM, Adams DP, Fernandez-Lazaro D, Mielgo-Ayuso J, Caballero-Garcia A, et al. Adherence to treatment and related factors among patients with chronic conditions in primary care: a cross-sectional study. BMC Fam Pract. 2019;20(1):132.
Schoemaker JH, Vingerhoets AJJM, Emsley RA. Factors associated with poor satisfaction with treatment and trial discontinuation in chronic schizophrenia. CNS Spectr. 2019;24(4):380–9.
Baryakova TH, Pogostin BH, Langer R, McHugh KJ. Overcoming barriers to patient adherence: the case for developing innovative drug delivery systems. Nat Rev Drug Discov. 2023;22(5):387–409.
Article CAS PubMed PubMed Central Google Scholar
Fenton JJ, Jerant AF, Bertakis KD, Franks P. The cost of satisfaction: a national study of patient satisfaction, health care utilization, expenditures, and mortality. Arch Intern Med. 2012;172(5):405–11.
Hamine S, Gerth-Guyette E, Faulx D, Green BB, Ginsburg AS. Impact of mHealth chronic disease management on treatment adherence and patient outcomes: a systematic review. J Med Internet Res. 2015;17(2): e3951.
Shikiar R, Rentz AM. Satisfaction with medication: an overview of conceptual, methodologic, and regulatory issues. Value Health J Int Soc Pharmacoecon Outcomes Res. 2004;7(2):204–15.
Lindhiem O, Bennett CB, Trentacosta CJ, McLear C. Client preferences affect treatment satisfaction, completion, and clinical outcome: a meta-analysis. Clin Psychol Rev. 2014;34(6):506–17.
Fallowfield L, Osborne S, Langridge C, Monson K, Kilkerr J, Jenkins V. Implications of subcutaneous or intravenous delivery of trastuzumab; further insight from patient interviews in the PrefHer study. Breast. 2015;24(2):166–70. https://doi.org/10.1016/j.breast.2015.01.002 . ( Epub 2015 Jan 24 PMID: 25623753 ).
Matrisch L, Rau Y, Karsten H, Graßhoff H, Riemekasten G. The Lübeck medication satisfaction questionnaire—a novel measurement tool for therapy satisfaction. J Pers Med. 2023;13(3):505.
Research C for DE and. FDA Patient-Focused Drug Development Guidance Series for Enhancing the Incorporation of the Patient’s Voice in Medical Product Development and Regulatory Decision Making. FDA [Internet]. 2023; https://www.fda.gov/drugs/development-approval-process-drugs/fda-patient-focused-drug-development-guidance-series-enhancing-incorporation-patients-voice-medical . Accessed 10 Oct 2023
Churruca K, Pomare C, Ellis LA, Long JC, Henderson SB, Murphy LED, et al. Patient-reported outcome measures (PROMs): A review of generic and condition-specific measures and a discussion of trends and issues. Health Expect Int J Public Particip Health Care Health Policy. 2021;24(4):1015–24.
Google Scholar
Waltz TJ, Campbell DG, Kirchner JE, Lombardero A, Bolkan C, Zivin K, et al. Veterans with depression in primary care: provider preferences, matching, and care satisfaction. Fam Syst Health. 2014;32(4):367–77.
Speight J. Assessing patient satisfaction: concepts, applications, and measurement. Value Health. 2005;8:S6-8.
Hareendran A, Abraham L. Using a treatment satisfaction measure in an early trial to inform the evaluation of a new treatment for benign prostatic hyperplasia. Value Health. 2005;8(Suppl 1):S35-40. https://doi.org/10.1111/j.1524-4733.2005.00074.x . ( PMID: 16336487 ).
Ahmed I, Ishtiaq S. Reliability and validity importance in medical research. J Pak Med Assoc. 2021;8(71):2403.
Clinton-McHarg T, Yoong SL, Tzelepis F, Regan T, Fielding A, Skelton E, et al. Psychometric properties of implementation measures for public health and community settings and mapping of constructs against the Consolidated Framework for Implementation Research: a systematic review. Implement Sci. 2016;11(1):148.
Liberato ACS, Rodrigues RCM, São-João TM, Alexandre NMC, Gallani MCBJ. Satisfaction with medication in coronary disease treatment: psychometrics of the Treatment Satisfaction Questionnaire for Medication. Rev Lat Am Enfermagem. 2016;24(e2705):S0104-11692016000100334.
PubMed Google Scholar
Usmani SZ, Mateos MV, Hungria V, Iida S, Bahlis NJ, Nahi H, et al. Greater treatment satisfaction in patients receiving daratumumab subcutaneous vs. intravenous for relapsed or refractory multiple myeloma: COLUMBA clinical trial results. J Cancer Res Clin Oncol. 2021;147(2):619–31.
Delestras S, Roustit M, Bedouch P, Minoves M, Dobremez V, Mazet R, et al. Comparison between two generic questionnaires to assess satisfaction with medication in chronic diseases. PLoS ONE. 2013;8(2): e56247.
McKenna SP. Measuring patient-reported outcomes: moving beyond misplaced common sense to hard science. BMC Med. 2011;14(9):86.
Ruiz MA, Pardo A, Rejas J, Soto J, Villasante F, Aranguren JL. Development and validation of the “Treatment Satisfaction with Medicines Questionnaire” (SATMED-Q). Value Health J Int Soc Pharmacoecon Outcomes Res. 2008;11(5):913–26.
Rejas J, Ruiz M, Pardo A, Soto J. Detecting changes in patient treatment satisfaction with medicines: the SATMED-Q. Value Health. 2013;16(1):88–96.
Atkinson MJ, Kumar R, Cappelleri JC, Hass SL. Hierarchical construct validity of the treatment satisfaction questionnaire for medication (TSQM Version II) among Outpatient Pharmacy Consumers. Value Health. 2005;8:S9-24.
Bharmal M, Payne K, Atkinson MJ, Desrosiers MP, Morisky DE, Gemmen E. Validation of an abbreviated Treatment Satisfaction Questionnaire for Medication (TSQM-9) among patients on antihypertensive medications. Health Qual Life Outcomes. 2009;7(1):36.
Regnault A, Balp MM, Kulich K, Viala-Danten M. Validation of the treatment satisfaction questionnaire for medication in patients with cystic fibrosis. J Cyst Fibros Off J Eur Cyst Fibros Soc. 2012;11(6):494–501.
Zyoud SH, Al-Jabi SW, Sweileh WM, Morisky DE. Relationship of treatment satisfaction to medication adherence: findings from a cross-sectional survey among hypertensive patients in Palestine. Health Qual Life Outcomes. 2013;11(1):191.
Contoli M, Rogliani P, Di Marco F, Braido F, Corsico AG, Amici CA, et al. Satisfaction with chronic obstructive pulmonary disease treatment: results from a multicenter, observational study. Ther Adv Respir Dis. 2019;13:1753466619888128.
Hao J, Pitcavage J, Jones JB, Hoegerl C, Graham J. Measuring adherence and outcomes in the treatment of patients with multiple sclerosis. J Osteopath Med. 2017;117(12):737–47.
Khdour MR, Awadallah HB, Al-Hamed DH. Treatment satisfaction and quality of life among type 2 diabetes patients: a cross-sectional study in West Bank, Palestine. J Diabetes Res. 2020;25(2020):1834534.
Abdshah A, Parsaeian M, Nasimi M, Ghiasi M. Validating the “Treatment Satisfaction Questionnaire for Medication” in Persian and Evaluating Treatment Satisfaction Among Patients With Psoriasis. Value Health Reg Issues. 2022;29:16–20.
Fijen LM, Klein PCG, Cohn DM, Kanters TA. The disease burden and societal costs of hereditary angioedema. J Allergy Clin Immunol Pract. 2023;11(8):2468-2475.e2.
Peipert JD, Beaumont JL, Bode R, Cella D, Garcia SF, Hahn EA. Development and validation of the functional assessment of chronic illness therapy treatment satisfaction (FACIT TS) measures. Qual Life Res. 2014;23(3):815–24.
ePROVIDE TM -Online Support for Clinical Outcome Assessments [Internet]. ePROVIDE - Mapi Research Trust. https://eprovide.mapi-trust.org/ . Accessed 10 Oct 2023
Bradley C, Plowright R, Stewart J, Valentine J, Witthaus E. The Diabetes Treatment Satisfaction Questionnaire change version (DTSQc) evaluated in insulin glargine trials shows greater responsiveness to improvements than the original DTSQ. Health Qual Life Outcomes. 2007;10(5):57.
DTSQ - Diabetes Treatment Satisfaction Questionnaire [Internet]. Health Psychology Research Ltd. [cited 2023 Dec 18]. Available from: https://healthpsychologyresearch.com/guidelines/dtsq-diabetes-treatment-satisfaction-questionnaire/ .
Abetz L, Coombs JH, Keininger DL, Earle CC, Wade C, Bury-Maynard D, et al. Development of the cancer therapy satisfaction questionnaire: item generation and content validity testing. Value Health J Int Soc Pharmacoeconomics Outcomes Res. 2005;8(Suppl 1):S41-53.
Trask PC, Tellefsen C, Espindle D, Getter C, Hsu MA. Psychometric validation of the cancer therapy satisfaction questionnaire. Value Health J Int Soc Pharmacoecon Outcomes Res. 2008;11(4):669–79.
Althof SE, Corty EW, Levine SB, Levine F, Burnett AL, McVary K, et al. EDITS: development of questionnaires for evaluating satisfaction with treatments for erectile dysfunction 1. Urology. 1999;53(4):793–9.
Gilbride CJ, Wilson A, Bradley-Gilbride A, Bayfield J, Gibson K, Gohel M, et al. Design of a treatment satisfaction measure for patients undergoing varicose vein treatment: Venous Treatment Satisfaction Questionnaire (VenousTSQ). Br J Surg. 2023;110(2):200–8.
Friedel AL, Siegel S, Kirstein CF, Gerigk M, Bingel U, Diehl A, et al. Measuring patient experience and patient satisfaction—how are we doing it and why does it matter? A comparison of European and U.S. American Approaches. Healthcare. 2023;11(6):797.
Khanna PP, Shiozawa A, Walker V, Bancroft T, Essoi B, Akhras KS, et al. Health-related quality of life and treatment satisfaction in patients with gout: results from a cross-sectional study in a managed care setting. Patient Prefer Adherence. 2015;9(9):971–81.
PubMed PubMed Central Google Scholar
Lenderking WR. Brief reflections on treatment satisfaction. Value Health. 2005;8(s1):s2-5.
Doward LC, Gnanasakthy A, Baker MG. Patient reported outcomes: looking beyond the label claim. Health Qual Life Outcomes. 2010;20(8):89. https://doi.org/10.1186/1477-7525-8-89.PMID:20727176;PMCID:PMC2936442 .
Using Patient Reported Treatment Satisfaction in Clinical Research and Beyond [Internet]. 2023. https://www.iqvia.com/events/2023/08/using-patient-reported-treatment-satisfaction-in-clinical-research-and-beyond . Accessed 10 Oct 2023.
Mehari EA, Muche EA, Gonete KA, Shiferaw KB. Treatment satisfaction and its associated factors of dolutegravir based regimen in a resource limited setting. Patient Prefer Adherence. 2021;15:1177–85.
Rosenberg S. Trial Participants Are Heroes, Let’s Treat Them That Way. Appl Clin Trials [Internet]. 2023 Sep 8 [cited 2023 Sep 24];31(5). Available from: https://www.appliedclinicaltrialsonline.com/view/measuring-patient-satisfaction-as-a-primary-outcome-for-patient-centric-initiatives . Accessed 10 Oct 2023.
Rodriguez AM, Gemmen E, Minton AP, Parmenter L. Satisfaction With Treatment. [Internet]. https://www.iqvia.com/-/media/iqvia/pdfs/library/white-papers/satisfaction-with-treatment.pdf . Accessed 10 Oct 2023.
Brédart A, Bottomley A. Treatment satisfaction as an outcome measure in cancer clinical treatment trials. Expert Rev Pharmacoecon Outcomes Res. 2002;2(6):597–606.
Naidoo P, Bouharati C, Rambiritch V, Jose N, Karamchand S, Chilton R, et al. Real-world evidence and product development: opportunities, challenges and risk mitigation. Wien Klin Wochenschr. 2021;133(15–16):840–6.
Ziemssen T, Richter S, Mäurer M, Buttmann M, Kreusel B, Poehler AM, et al. OzEAN study to collect real-world evidence of persistent use, effectiveness, and safety of ozanimod over 5 years in patients with relapsing-remitting multiple sclerosis in Germany. Front Neurol [Internet]. 2022. https://doi.org/10.3389/fneur.2022.913616 .
Witzel S, Maier A, Steinbach R, Grosskreutz J, Koch JC, Sarikidi A, et al. Safety and effectiveness of long-term intravenous administration of edaravone for treatment of patients with amyotrophic lateral sclerosis. JAMA Neurol. 2022;79(2):121–30.
Meyer T. Real world experience of patients with amyotrophic lateral sclerosis (ALS) in the treatment of spasticity using tetrahydrocannabinol:cannabidiol (THC:CBD). 2019;
Cámara R, Venegas E, García-Arnés JA, Cordido F, Aller J, Samaniego ML, Mir N, Sánchez-Cenizo L. Treatment adherence to pegvisomant in patients with acromegaly in Spain: PEGASO study. Pituitary. 2019;22(2):137–45. https://doi.org/10.1007/s11102-019-00943-1 . ( PMID: 30756345 ).
Yale JF, Bodholdt U, Catarig AM, Catrina S, Clark A, Ekberg NR, et al. Real-world use of once-weekly semaglutide in patients with type 2 diabetes: pooled analysis of data from four SURE studies by baseline characteristic subgroups. BMJ Open Diabetes Res Care. 2022;10(2): e002619.
Gogate A, Bennett B, Poonja Z, Stewart G, Medina Colmenero A, Szturz P, et al. Phase 4 multinational multicenter retrospective and prospective real-world study of nivolumab in recurrent and metastatic squamous cell carcinoma of the head and neck. Cancers. 2023;15(14):3552.
Boutin M, Dewulf L, Hoos A, Geissler J, Todaro V, Schneider RF, et al. Culture and process change as a priority for patient engagement in medicines development. Ther Innov Regul Sci. 2017;51(1):29–38.
Committee for medicinal products human use. Reflection paper on the regulatory guidance for the use of health-related quality of life (HRQOL) measures in the evaluation of medicinal products. EMA. 2023; https://www.ema.europa.eu/en/documents/scientific-guideline/reflection-paper-regulatory-guidance-use-health-related-quality-life-hrql-measures-evaluation_en.pdf . Accessed 10 Oct 2023.
Reaney M, Whitsett J. Our Perspectives on the US FDA Patient-Focused Drug Development (PFDD) Guidance 3 and 4 Integrating patient experience data into endpoints to inform a COA endpoint strategy. IQVIA. https://www.iqvia.com/-/media/iqvia/pdfs/library/white-papers/our-perspectives-on-the-us-fda-patient-focused-drug-development-pfdd-guidance-3-and-4.pdf . Accessed 10 Oct 2023
Fang H, Harris S, Liu Z, Thakkar S, Yang J, Ingle T, et al. FDALabel for drug repurposing studies and beyond. Nat Biotechnol. 2020;38(12):1378–9.
Jarosławski S, Auquier P, Borissov B, Dussart C, Toumi M. Patient-reported outcome claims in European and United States orphan drug approvals. J Mark Access Health Policy. 2018;6(1):1542920.
Methods to Identify What is Important to Patients & Select, Develop or Modify Fit-for-Purpose Clinical Outcomes Assessments. [Internet]. 2018. https://www.fda.gov/media/116276/download . Accessed 8 Apr 2024.
Afinitor : EPAR - Summary for the public [Internet]. 2018. https://www.ema.europa.eu/en/medicines/human/EPAR/afinitor . Accessed 8 Apr 2024.
Humira : EPAR - Medicine overview.pdf.. [Internet]. 2020. https://www.ema.europa.eu/en/medicines/human/EPAR/humira Accessed 8 Apr 2024.
Assessment report for paediatric studies submitted according to Article 46 of the Regulation (EC) No 1901/2006 .pdf.. [Internet]. 2006. https://www.ema.europa.eu/en/documents/variation-report/novoeight-h-c-2719-p46-0111-epar-assessment-report_en.pdf . Accessed 8 Apr 2024.
Tysabri : EPAR - Medicine overview.pdf. [Internet]. 2020. https://www.ema.europa.eu/en/documents/product-information/tysabri-epar-product-information_en.pdf . Accessed 8 Apr 2024.
Picato : EPAR - Summary for the public.pdf [Internet]. 2020. https://www.ema.europa.eu/en/medicines/human/EPAR/picato . Accessed 8 Apr 2024.
Package Insert - CUVITRU.pdf. [Internet]. 2016. https://www.fda.gov/media/100531/download . Accessed 8 Apr 2024.
HTA and Evaluation Methods Qualitative: 1. Introduction | EUPATI Open Classroom [Internet]. 2024. https://learning.eupati.eu/mod/page/view.php?id=492 . Accessed 8 Apr 2024.
Cizek J. How payers can use outcomes data to enhance care and member experience [Internet]. 2023. https://clarifyhealth.com/insights/blog/how-payers-can-use-outcomes-data-to-enhance-care-and-member-experience/ Accessed 8 Apr 2024.
Wale JL, Thomas S, Hamerlijnck D, Hollander R. Patients and public are important stakeholders in health technology assessment but the level of involvement is low - a call to action. Res Involv Engagem. 2021;7(1):1. https://doi.org/10.1186/s40900-020-00248-9 . ( PMID:33402216;PMCID:PMC7783693 ).
Brettschneider C, Lühmann D, Raspe H. Informative value of Patient Reported Outcomes (PRO) in Health Technology Assessment (HTA). GMS Health Technol Assess. 2011;7:Doc01. https://doi.org/10.3205/hta000092 . ( PMID: 21468289; PMCID: PMC3070434 ).
Chassany O, Engen AV, Lai L, Borhade K, Ravi M, Harnett J, Chen CI, Quek RG. A call to action to harmonize patient-reported outcomes evidence requirements across key European HTA bodies in oncology. Future Oncol. 2022;18(29):3323–34. https://doi.org/10.2217/fon-2022-0374 . ( Epub 2022 Sep 2 PMID: 36053168 ).
Oderda G, Brixner D, Biskupiak J, Burgoyne D, Arondekar B, Deal LS, et al. Payer perceptions on the use of patient-reported outcomes in oncology decision making. J Manag Care Spec Pharm. 2022;28(2):188–95.
Download references
Acknowledgments
We would like to extend our sincere gratitude to Dr Matthew Reaney, Dr David Bard, and Jodi Andrews for useful discussions and insightful comments.
Author information
Authors and affiliations.
IQVIA, Patient-Centered Solutions, Madrid, Spain
Carolina Navas & Ana Maria Rodriguez-Leboeuf
IQVIA, Patient Centered Solutions, Boston, MA, USA
Alexandra Palmer Minton
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Carolina Navas .
Ethics declarations
No external funding was received to assist with the preparation of this manuscript. All authors are IQVIA employees.
Data availability
Not applicable.
Author Contributions
All authors contributed to the study conception and design. The first draft of the manuscript was written by Carolina Navas and all authors commented on previous versions of the manuscript. All authors read, edited, and approved the final manuscript.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License, which permits any non-commercial use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc/4.0/ .
Reprints and permissions
About this article
Navas, C., Minton, A.P. & Rodriguez-Leboeuf, A.M. The Role of Patient-Reported Outcomes to Measure Treatment Satisfaction in Drug Development. Patient (2024). https://doi.org/10.1007/s40271-024-00702-w
Download citation
Accepted : 22 May 2024
Published : 08 July 2024
DOI : https://doi.org/10.1007/s40271-024-00702-w
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Find a journal
- Publish with us
- Track your research

The UK Faculty of Public Health has recently taken ownership of the Health Knowledge resource. This new, advert-free website is still under development and there may be some issues accessing content. Additionally, the content has not been audited or verified by the Faculty of Public Health as part of an ongoing quality assurance process and as such certain material included maybe out of date. If you have any concerns regarding content you should seek to independently verify this.
Study design for assessing effectiveness, efficiency and acceptability of services including measures of structure, process, service quality, and outcome of health care
Health care evaluation is the critical assessment, through rigorous processes, of an aspect of healthcare to assess whether it fulfils its objectives. Aspects of healthcare which can be assessed include:
- Effectiveness – the benefits of healthcare measured by improvements in health
- Efficiency – relates the cost of healthcare to the outputs or benefits obtained
- Acceptability – the social, psychological and ethical acceptability regarding the way people are treated in relation to healthcare
- Equity - the fair distribution of healthcare amongst individuals or groups
Healthcare evaluation can be carried out during a healthcare intervention, so that findings of the evaluation inform the ongoing programme (known as formative evaluation) or can be carried out at the end of a programme (known as summative evaluation).
Evaluation can be undertaken prospectively or retrospectively. Evaluating on a prospective basis has the advantage of ensuring that data collection can be adequately planned and hence be specific to the question posed (as opposed to retrospective data dredging for proxy indicators) as well as being more likely to be complete. Prospective evaluation processes can be built in as an intrinsic part of a service or project (usually ensuring that systems are designed to support the ongoing process of review).
There are several eponymous frameworks for undertaking healthcare evaluation. These are set out in detail in the Healthcare Evaluation frameworks section of this website and different frameworks are best used for evaluating differing aspects of healthcare as set out above. The steps involved in designing an evaluation are described below.
Steps in designing an evaluation
Firstly it is important to give thought to the purpose of the evaluation, audience for the results, and potential impact of the findings. This can help guide which dimensions are to be evaluated – inputs, process, outputs, outcomes, efficiency etc. Which of these components will give context to, go toward answering the question of interest and be useful to the key audience of the evaluation?
Objectives for the evaluation itself should be set (remember SMART) –
S - specific – effectiveness/efficiency/acceptability/equity M - measurable A - achievable – are objectives achievable R - realistic (can objectives realistically be achieved within available resources?) T - time- when do you want to achieve objectives by?
Having identified what the evaluation is attempting to achieve, the following 3 steps should be considered:
1. What study design should be used?
When considering study design, several factors must be taken into account:
- How will the population / service being evaluated be defined?
- Will the approach be quantitative / qualitative / mixed? (Qualitative evaluation can help answer the ‘why’ questions which can complement quantitative evaluation for instance in explaining the context of the intervention). Level of data collection and analysis - will it be possible to collect what is needed or is it possible to access routinely collected data (e.g. Hospital Episode Statistics if this data is appropriate to answer the questions being asked)?
- The design should seek to eliminate bias and confounding as far as possible – is it possible to have a comparator group?
- The strengths and weaknesses of each approach should be weighed up when finalising a design and the implication on the interpretation of the findings noted.
Study designs include:
a) Randomised methods
- Through the random allocation of an intervention, confounders are equally distributed. Randomised controlled trials can be expensive to undertake rigorously and are not always practical in the service setting. This is usually carried out prospectively.
- Development of matched control methods has been used to retrospectively undertake a high quality evaluation. A guide to undertaking evaluations of complex health and care inteventions using this method can be found here: http://www.nuffieldtrust.org.uk/sites/files/nuffield/publication/evaluation_report_final_0.pdf
- ‘Zelen’s design’ offers an alternative method incorporating randomisation to evaluate an intervention in a healthcare setting.
b) Non randomised methods
- Cohort studies - involve the non-random allocation of an intervention, can be retrospective or prospective, but adjustment must be made for confounders
- Case-control studies – investigate rare outcomes, participants are defined on the basis of outcome rather than healthcare. There is a need to match controls however the control group selection itself is a major form of bias.
c) Ecological studies
- cheap and quick, cruder and less sensitive than individual level studies, can be useful for studying the impact of health policy
d) Descriptive studies
- used to generate hypotheses, help understand complexities of a situation and gain insight into processes e.g. case series.
e) Health technology assessment
- examines what technology can best deliver benefits to a particular patient or population group. It assesses the cost-effectiveness of treatments against current or next best treatments. See economic evaluation section of this website for more details.
f) Qualitative studies
- Methods are covered in section 1d of this textbook.
- Researchers-in-residence are an innovative method used in evaluation whereby the researcher becomes a member of the operational team and brings a focus to optimising effectiveness of the intervention or programme rather than assessing effectiveness.
2. What measures should be used?
The choice of measure will depend on the study design or indeed evaluation framework used as well as the objectives of the evaluation. For example, the Donabedian approach considers a programme or intervention in terms of inputs, process, outputs and outcomes.
- Inputs - (also known as structure) describes what has gone into an intervention to make it happen e.g. people, time, money
- Process - describes how it has happened e.g. strategy development, a patient pathway
- Outputs - describe what the intervention or programme has produced e.g. throughput of patients
- Outcomes - describes the actual benefits or disbenefits of that intervention or programme.
The table below gives some further examples of measures that can be used for each aspect of the evaluation. Such an evaluation could measure process against outcomes, inputs versus outputs or any combination.
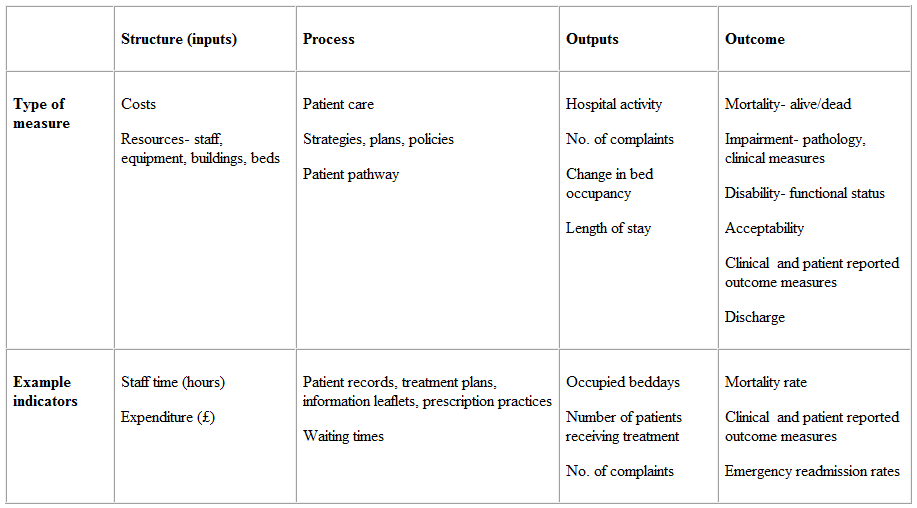
3. How and when to collect data?
The choice of qualitative versus quantitative data collection will influence the timing of such collection, as will the choice of the evaluation being carried out prospectively or retrospectively. The amount of data that needs to be collected will also impact on timing, and sample-size calculations at the beginning of the evaluation will be an important part of planning.
For qualitative studies, the sample must be big enough that enlargement is unlikely to yield additional insights e.g. undertaking another interview with a member of staff is unlikely to identify any new themes. Most qualitative approaches, in real life, would ensure that all relevant staff groups were sampled.
For quantitative studies the following must be considered (using statistical software packages such as Stata):
- the size of the treatment effect that would be of clinical/social/public health significance
- the required power of the study
- acceptable level of statistical significance
- variability between individuals in the outcome measure of interest
If the evaluation is of a longitudinal design, the follow up time is important to consider, although in some instances may be dictated by availability of data. There may also be measures which are typically reported over defined lengths of time such as readmission rates which are often measured at 7 days and 30 days.
Trends in health services evaluation
Evaluation from the patient perspective has increasingly become an established part of working in the health service. Assessment of service user opinion can include results from surveys, external assessment (such as NHS patient experience surveys led by the CQC) as well as outcomes reported by patients themselves (patient reported outcome measures) which from April 2009 are a mandatory part of commissioners’ service contracts with provider organisations and are currently collected for four clinical procedures; hip replacements, knee replacements, groin hernia and varicose veins procedures.
© Rosalind Blackwood 2009, Claire Currie 2016
- Skip to secondary menu
- Skip to main content
- Skip to primary sidebar
Statistics By Jim
Making statistics intuitive
Repeated Measures Designs: Benefits and an ANOVA Example
By Jim Frost 25 Comments
Repeated measures designs, also known as a within-subjects designs, can seem like oddball experiments. When you think of a typical experiment, you probably picture an experimental design that uses mutually exclusive, independent groups. These experiments have a control group and treatment groups that have clear divisions between them. Each subject is in only one of these groups.
These rules for experiments seem crucial, but repeated measures designs regularly violate them! For example, a subject is often in all the experimental groups. Far from causing problems, repeated measures designs can yield significant benefits.
In this post, I’ll explain how repeated measures designs work along with their benefits and drawbacks. Additionally, I’ll work through a repeated measures ANOVA example to show you how to analyze this type of design and interpret the results.
To learn more about ANOVA tests, read my ANOVA Overview .
Drawbacks of Independent Groups Designs
To understand the benefits of repeated measures designs, let’s first look at the independent groups design to highlight a problem. Suppose you’re conducting an experiment on drugs that might improve memory. In a typical independent groups design, each subject is in one experimental group. They’re either in the control group or one of the treatment groups. After the experiment, you score them on a memory test and then compare the group means.
In this design, you obtain only one score from each subject. You don’t know whether a subject scores higher or lower on the test because of an inherently better or worse memory. Some portion of the observed scores is based on the memory traits of the subjects rather than because of the drug. This example illustrates how people introduce an uncontrollable factor into the study.
Imagine that a person in the control group scores high while someone else in a treatment group scores low, not due to the treatment, but due to differing baseline memory capabilities. This “fuzziness” makes it harder to assess differences between the groups.
If only there were some way to know whether subjects tend to measure high or low. We need some way of incorporating each person’s variability into the model. Oh wait, that’s what we’re talking about—repeated measures designs!
How Repeated Measures Designs Work
As the name implies, you need to measure each subject multiple times in a repeated measures design. Shocking! They are longitudinal studies. However, there’s more to it. The subjects usually experience all of the experimental conditions, which allow them to serve as experimental blocks or as their own control. Statisticians refer to this as dependent samples because one observation provides information about another observation. What does that mean? Let me break this down one piece at a time.
The effects of the controllable factors in an experiment are what you really want to learn. However, as we saw in our example above, there can also be uncontrolled sources of variation that make it harder to learn about those things that we can control.
Experimental blocks explain some of the uncontrolled variability in an experiment. While you can’t control the blocks, you can include them in the model to reduce the amount of unexplained variability. By accounting for more of the uncontrolled variability, you can learn more about the controllable variables that are the entire point of your experiment.
Let’s go back to our longitudinal study for the drug’s effectiveness. We saw how subjects are an uncontrolled factor that makes it harder to assess the effects of the drugs. However, if we took multiple measurements from each person, we gain more information about their personal outcome measures under a variety of conditions. We might see that some subjects tend to score high or low on the memory tests. Then, we can compare their scores for each treatment group to their general baseline.
And, that’s how repeated measures designs work. You understand each person better so that you can place their personal reaction to each experimental condition into their particular context. Repeated measures designs use dependent samples because one observation provides information about another observation.
Related posts : Independent and Dependent Samples and Longitudinal Studies: Overview, Examples & Benefits .
Benefits of Repeated Measures Designs
In statistical terms, we say that experimental blocks reduce the variance and bias of the model’s error by controlling for factors that cause variability between subjects. The error term contains only the variability within-subjects and not the variability between subjects. The result is that the error term tends to be smaller, which produces the following benefits:
Greater statistical power : By controlling for differences between subjects, this type of design can have much more statistical power . If an effect exists, your statistical test is more likely to detect it.
Requires a smaller number of subjects: Because of the increased power, you can recruit fewer people and still have a good probability of detecting an effect that truly exists. If you’d need 20 people in each group for a design with independent groups, you might only need a total of 20 for repeated measures.
Faster and less expensive: The time and costs associated with administering repeated measures designs can be much lower because there are fewer people to recruit, train, and compensate.
Time-related effects: As we saw, an independent groups design collects only one measurement from each person. By collecting data from multiple points in time for each subject, repeated measures designs can assess effects over time. This tracking is particularly useful when there are potential time effects, such as learning or fatigue.
Managing the Challenges of Repeated Measures Designs
Repeated measures designs have some great benefits, but there are a few drawbacks that you should consider. The largest downside is the problem of order effects, which can happen when you expose subjects to multiple treatments. These effects are associated with the treatment order but are not caused by the treatment.
Order effects can impede the ability of the model to estimate the effects correctly. For example, in a wine taste test, subjects might give a dry wine a lower score if they sample it after a sweet wine.
You can use different strategies to minimize this problem. These approaches include randomizing or reversing the treatment order and providing sufficient time between treatments. Don’t forget, using an independent groups design is an efficient way to eliminate order effects.
Crossover Repeated Measures Designs
I’ve diagramed a crossover repeated measures design, which is a very common type of experiment. Study volunteers are assigned randomly to one of the two groups. Everyone in the study receives all of the treatments, but the order is reversed for the second group to reduce the problems of order effects. In the diagram, there are two treatments, but the experimenter can add more treatment groups.

Studies from a diverse array of subject areas use crossover designs. These areas include weight loss plans, marketing campaigns, and educational programs among many others. Even our theoretical memory pill study can use it.
Repeated measures designs come in many flavors, and it’s impossible to cover them all here. You need to look at your study area and research goals to determine which type of design best meets your requirements. Weigh the benefits and challenges of repeated measures designs to decide whether you can use one for your study.
Repeated Measures ANOVA Example
Let’s imagine that we used a repeated measures design to study our hypothetical memory drug. For our study, we recruited five people, and we tested four memory drugs. Everyone in the study tried all four drugs and took a memory test after each one. We obtain the data below. You can also download the CSV file for the Repeated_measures_data .

In the dataset, you can see that each subject has an ID number so we can associate each person with all of their scores. We also know which drug they took for each score. Together, this allows the model to develop a baseline for each subject and then compare the drug specific scores to that baseline.
How do we fit this model? In your preferred statistical software package, you need to fit an ANOVA model like this:
- Score is the response variable.
- Subject and Drug are the factors,
- Subject should be a random factor .
Subject is a random factor because we randomly selected the subjects from the population and we want them to represent the entire population. If we were to include Subject as a fixed factor, the results would apply only to these five people and would not be generalizable to the larger population.
Drug is a fixed factor because we picked these drugs intentionally and we want to estimate the effects of these four drugs particularly.
Repeated Measures ANOVA Results
After we fit the repeated measures ANOVA model, we obtain the following results.

The P-value for Drug is 0.000. This low P-value indicates that all four group means are not equal. Because the model includes Subjects, we know that the Drug effect and its P-value accounts for the variability between subjects.
Below is the main effects plot for Drug, which displays the fitted mean for each drug.

Clearly, drug 4 is the best. Tukey’s multiple comparisons (not shown) indicate that Drug 4 – Drug 3 and Drug 4 – Drug 2 are statistically significant.
Have you used a repeated measures design for your study?
Share this:

Reader Interactions

December 15, 2023 at 2:24 pm
thanks for these posts and comments. question – in a repeated measures analysis within SPSS, the first output is the multivariate effect, and the second is the within-subjects effect. I imagine both analyses approach the effect from a different point of view. I’m trying to understand the difference, similarity, when to use multivariate vs. within-subjects. My data has three time points. one between-subjects factor.

November 30, 2022 at 11:14 am
Hi Jim – Thank you for your posts, which are always comprehensive and value-adding.
If my subjects are not individual respondents, but an aggregated group of respondents in a geography (example: respondents in a geographic area forms my subjects G1, G2, …,Gn), do I need to normalize the output variable to handle the fluctuation across the subjects due to population variations across geographies? Or will the Repeated Measures ANOVA handle that if I add Subject (Geography) as my factor?

September 26, 2022 at 6:37 am
Hi and thank you for a calrifying page! But I still haven’t found what I’m looking for… I have conducted a test with 2 groups, approx 25 persons randomly allocated to each group. They were given two different drug treatments. We measured several variables before the drug was given. After the drug was given, the same variables were measured after 1, 5, 20 and 60 minutes. Let’s say these variables were AA, BB, CC, DD and EE. Let’s assume they are normally distributed at all times. Variable types are Heart Rate, Blood Pressure, and such. How am I supposed to perform statistics in this case? Just comparing drug effects at each time point will inevitably produce Type I errors? These are Repeated Measurements but is really R.M. ANOVA appropriate here?

September 26, 2022 at 8:28 pm
Hi Tony, yes, I think you need to use repeated measures MANOVA. That should allow you to accomplish all that while controlling Type I errors by avoiding multiple tests.

August 3, 2022 at 3:56 am
Hi Jim, I have 3 samples(say A, B&C) that being tasted and rated in hedonic scale by panelists. Each panelist will be given 3 samples(one at a time) to be tasted or evaluated. A total of 100 respondents are selected from particular population. can repeated measure ANOVA be used? this is consider related right? if not, can you suggest the appropriate test to use.

June 25, 2022 at 1:06 am
I’m very mathematically challenged and your posts really simplify things. I’m trying to help a singer determine which factors interactively determine his commission during livestreams, as the commission is different each time. For each date, I have the amount of coins gifted from viewers, the average viewer count, the total number of viewers, and the average time viewers have spent watching. The dependent variable is the commission. Would I use an ANOVA for this?

December 7, 2021 at 11:24 pm
Hi Jim Please if I have the following data, which Test is most appropriate Comparing mean of BMI, diastolic pressure, cholesterol between two age groups (15 to 30) and above 30 years? Thank you
December 9, 2021 at 6:21 pm
Hi Salma, I’m not sure about your IV and DVs. What’s your design? I can’t answer your question without knowing what you want to test. What do you want to learn using those variables?

October 25, 2021 at 4:32 pm
Jim, Isn’t there a sphericity requirement for data in repeated measures anova?
October 25, 2021 at 10:48 pm
Spherical errors are those that have no autocorrelation and have a constant variance. In my post about OLS assumptions , they’re assumptions #4 and #5 with a note to that effect in the text for #5. It’s a standard linear models assumption.

May 6, 2021 at 5:09 pm
Hi Jim, we have data from analysis of different sources of gluten free flour analysed together and compared to wheat flour for different properties. What would be the best test to use in this case please.

September 14, 2020 at 6:41 pm
Hi Jim, I found you post helpful and was wondering if the repeating measures ANOVA would be an appropriate analysis for a project I am working on. I have collected pre, post, and delayed post survey data. All participants first complete a pre survey, then engage in an intervention, direct after the intervention they all complete a post survey. Then 4 months later they all complete a delayed post survey. My interest is to see if there are any long-term impact of the intervention. Would the repeating measures ANOVA be appropriate to use to compare the participants’ pre, post, and delayed post scores?

June 12, 2020 at 8:28 pm
Thank you for another great post! I am doing a study protocol and the primary hypothesis is that a VR intervention will show improvement in postural control (4 CoP parameters), comparing the experimental and inactive control group (post-intervention). I was advised to use a repeated measures ANOVA to test the primary hypothesis but reading your post made me realize that might not be correct because my study subjects are not experiencing all the experimental conditions. Do you recommend another type of ANOVA?
Thanks in advance.
June 12, 2020 at 9:07 pm
I should probably clarify this better in the post. The subject don’t have to experience all the treatment conditions, but many studies use these designs for this reason. But, it’s not a requirement. If you’ve measured your subjects multiple times, you probably do need to use a repeated measures design.

June 2, 2020 at 11:31 am
Thank you so much for your helpful posts about statistics! I’ve tried doing a repeated measures analysis but have gotten a bit confused. I administered 3 different questionnaires on social behavior (all continuous outcomes, but on different scales [two ranging 0-50, the third 0-90]) on 4 different time points. The questionnaires are correlated to each other so I would prefer to put them in the same analysis. I was planning on doing this by making one within subject variable “time” and one within subject variable “questionnaire”. I would like to know what the effect is of time on social behavior and whether this effect is different depending on the specific questionnaire used. Is it ok to add these questionnaires in the same analysis even though they do not have the same range of scores or should I first center the total scores of the questionnaires?
Many thanks, Laura
June 3, 2020 at 7:44 pm
ANOVA can handle DVs that use different measurement units/scales without problems. However, if you want to determine which DV/survey is more important, you might consider standardizing them. Read more about that in my post about identifying the most important variables in your model . It discusses it in the regression context but the same applies to ANOVA.
You’ll obtain valid and consistent results using either standardized and unstandardized values. It just depends on what you want to learn.
I hope that helps!

May 30, 2020 at 4:53 pm
Hi Jim, thanks for your effort and time to make statics understandable to the wider public. Your style of teaching is quite simple.
I didn’t any questions nor responses for 2019 to data, but I hope you’re still there anyway.
I have this stat problem I need your opinion on. There are 8 drinking water wells clustered at different distances around an injection well. To simulate direction and concentration of contaminant within subsurface around the well area, a contaminant was injected/pumped continuously into the subsurface through the injection well. This happened for 6 weeks; pH samples were taken from the 8 wells daily for the 6 weeks. I need to test for 2 things, namely: 1. Is there any significant statistical difference in pH within the wells within the 6 weeks (6 weeks as a single time period) 2. Is there any statistical significant difference in pH for each well within the weeks (6 weeks time step)
Which statistical test best captures this analysis? I think of repeated measure ANOVA, what do you think please?
May 30, 2020 at 4:55 pm
Yes, because you’re looking at the same subjects (wells) over time, you need repeated measures ANOVA.

December 24, 2018 at 2:31 pm
Name: Vidya Kulkarni
Email: [email protected]
Comment: Shall appreciate a reply. My friend has performed experiments with rats in 3 groups by administering certain drug. Group 1 is not given any drug, Group 2 is given 50 mg and group 3 is given 100 mg. In each group there are 3 rats and for each of these rats their their tumor volume has been recorded for 9 consecutive days. Thus for each group we have 27 observations. We want to show the difference in their means is significantly different at some confidence level. Please let me know what statistical test should we use and if you can send a link to some similar example, that would be a great help. Looking forward to quick help. Thanks

December 11, 2018 at 8:44 pm
I wanted to tank you for your post! It was really helpful for me. In my design I have 30 subjects with 10 readings (from different electrodes on the scalp) for each subject in two sessions (immediate test, post test). I used repeated measure anova and I found a significant main effect of sessions and also significant interaction of sessions and electrodes. Main effect means I have significant difference between session1 data and session2 data but I am not sure about the interaction effect. I would appreciate if you help me with that.
Thanks, Mary
December 12, 2018 at 9:32 am
I’m not sure what your outcome variable is or what the electrodes variable measures precisely. But, here’s how you’d interpret the results generally.
The relationship between sessions and your outcome variable depends on the value of your electrodes variable. While there is a significant difference between sessions, that difference depends on the value of electrodes. If you create an interactions plot, it should be easier to see what is going on! For more information, see my post about interaction effects .

October 23, 2018 at 4:12 pm
Hello Jim ! I am very pleased to meet you and I greatly appreciate your work !
The Repeated Measures ANOVA that I have encountered in my study is as follows :
A number of subject groups, of n – people each, selected e.g by age, are tested repeatedly for the same number of times all, with the same drug ! I.e there is only one drug !
The score is the effectiveness of the drug on a specific body parameter, e.g on blood pressure. And the question is to assess the efectiveness of the drug.
Subjects group is not a random factor, as it is an age group Score also is not an independent r.v as it reflects the effect of the previous day of the drug
Do you have any notes on this type of problems or recommend a literature I can access from web ?
My best regards Elias Athens / Greece
October 24, 2018 at 4:26 pm
It’s OK to not have more than one drug. You just need to be able to compare the one drug to not taking the drug. You can do that both in a traditional control group/treatment group setting or by using repeated measures. However, given that you talk about repeated measures and everyone taking the drug, my guess is that it is some type of crossover design, which I describe in this post.
In this scenario, everyone would eventually take the same drug over the course of the study, but some subjects might start out by not taking the drug while the other subjects do. Then, the subjects switch.
You can include Subjects as a random factor if you randomly selected them from them population. Then, include Age as an additional Fixed factor if you’re specifying the age groups or as a covariate if you’re using their actual age (rather than dividing them into groups based on age ranges).
I hope this helps!

August 27, 2018 at 2:24 pm
I am getting conflicting advice. I ran a: pre-test, intervention, post-test study. Where I had 4 groups (3 experimental and one control). I tested hamstring strength. In my repeated measures ANOVA I had an effect of time but NO interaction effect. I have been told due to no interaction effect I do NOT run a post-hoc analysis. Is this correct as someone else has told me the complete opposite (I only run a post-hoc analysis when I do not have an interaction effect)?
August 28, 2018 at 11:11 pm
The correct action to do depends on the specifics of your study, which might be why you’re getting conflicting advice!
As a general statistical principle, it’s perfectly fine to perform post-hoc tests regardless of whether the interaction effect is significant or not. The only time that it makes no sense to perform a post hoc test is when no terms in your model are statistically significant. Although, even in that case, post hoc tests can sometimes detect statistical significance–but that’s another story. But, in a nutshell, you can perform post hoc tests whether or not your interaction term is significant.
However, I suspect that the real question is whether it makes sense the pre-test post-test nature of your study. You have measurements before and after the intervention. If the intervention is effective, you’d expect the differences to show up after the intervention but not before. Consequently, that is an interaction effect because it depends on the time of measurement. Read my blog post about interaction effects to see how these are “it depends” effects. So, if your interaction effect is not significant, it might not make sense to analyze your data further.
If the main effect for the treatment group variable is significant but not the interaction effect, it’s a bit difficult because it says that the treatment groups cause a difference between group means even in the pre-test measurement! That might represent only the differences between the subjects within those groups–it’s hard to say. You really want that interaction term to be significant!
If only the time effect is significant and nothing else, it’s probably not worth further investigation.
One thing I can say definitively is that the person who said that you can only perform a post-hoc analysis when the interaction is not significant is wrong! As a general principle, it’s OK to perform post-hoc analyses when an interaction term is significant. For your study, you particularly want a significant interaction term!
Comments and Questions Cancel reply

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Perspect Clin Res
- v.10(3); Jul-Sep 2019
Study designs: Part 4 – Interventional studies
Rakesh aggarwal.
Director, Jawaharlal Institute of Postgraduate Medical Education and Research, Puducherry, India
Priya Ranganathan
1 Department of Anaesthesiology, Tata Memorial Centre, Mumbai, Maharashtra, India
In the fourth piece of this series on research study designs, we look at interventional studies (clinical trials). These studies differ from observational studies in that the investigator decides whether or not a participant will receive the exposure (or intervention). In this article, we describe the key features and types of interventional studies.
INTRODUCTION
In previous articles in this series, we introduced the concept of study designs[ 1 ] and have described in detail the observational study designs – descriptive[ 2 ] as well as analytical.[ 3 ] In this and another future piece, we will discuss the interventional study designs.
In observational studies, a researcher merely documents the presence of exposure(s) and outcome(s) as they occur, without trying to alter the course of natural events. By contrast, in interventional studies, the researcher actively interferes with nature – by performing an intervention in some or all study participants – to determine the effect of exposure to the intervention on the natural course of events. An example would be a study in which the investigator randomly assigns the participants to receive either aspirin or a placebo for a specific duration to determine whether the drug has an effect on the future risk of developing cerebrovascular events. In this example, aspirin (the “intervention”) is the “exposure,” and the risk of cerebrovascular events is the “outcome.” Interventional studies in humans are also commonly referred to as “trials.”
Interventional studies, by their very design, are prospective. This sometimes leads to confusion between interventional and prospective cohort study designs. For instance, the study design in the above example appears analogous to that of a prospective cohort study in which people attending a wellness clinic are asked whether they take aspirin regularly and then followed for a few years for occurrence of cerebrovascular events. The basic difference is that in the interventional study, it is the investigators who assign each person to take or not to take aspirin, whereas in the cohort study, this is determined by an extraneous factor.
Interventional studies can be divided broadly into two main types: (i) “controlled clinical trials” (or simply “clinical trials” or “trials”), in which individuals are assigned to one of two or more competing interventions, and (ii) “community trials” (or field trials), in which entire groups, e.g., villages, neighbourhoods, schools or districts, are assigned to different interventions.
The interventions can be quite varied; examples include administration of a drug or vaccine or dietary supplement, performance of a diagnostic or therapeutic procedure, and introduction of an educational tool. Depending on whether the intervention is aimed at preventing the occurrence of a disease (e.g., administration of a vaccine, boiling of water, distribution of condoms or of an educational pamphlet) or at providing relief to or curing patients with a disease (e.g., antiretroviral drugs in HIV-infected persons), a trial may also be referred to as “preventive trial” or “therapeutic trial”.
VARIOUS TYPES OF INTERVENTIONAL STUDY DESIGNS
Several variations of interventional study designs with varying complexity are possible, and each of these is described below. Of these, the most commonly used and possibly the strongest design is a randomized controlled trial (RCT).
Randomized controlled trials
In an RCT, a group of participants fulfilling certain inclusion and exclusion criteria is “randomly” assigned to two separate groups, each receiving a different intervention. Random assignment implies that each participant has an equal chance of being allocated to the two groups.
The use of randomization is a major distinguishing feature and strength of this study design. A well-implemented randomization procedure is expected to result in two groups that are comparable overall, when both measured and unmeasured factors are taken into account. Thus, theoretically, the two groups differ only in the intervention received, and any difference in outcomes between them is thus related to the effect of intervention.
The term “controlled” refers to the presence of a concurrent control or comparator group. These studies have two or more groups – treatment and control. The control group receives no intervention or another intervention that resembles the test intervention in some ways but lacks its activity (e.g., placebo or sham procedure, referred to also as “placebo-controlled” or “sham-controlled” trials) or another active treatment (e.g., the current standard of care). The outcomes are then compared between the intervention and the comparator groups.
If an effort is made to ensure that other factors are similar across groups, then the availability of data from the comparator group allows a stronger inference about the effect of the intervention being tested than is possible in studies that lack a control group.
Some additional methodological features are often added to this study design to further improve the validity of a trial. These include allocation concealment, blinding, intention-to-treat analysis, measurement of compliance, minimizing the dropouts, and ensuring appropriate sample size. These will be discussed in the next piece.
Nonrandomized controlled clinical trials
In this design, participants are assigned to different intervention arms without following a “random” procedure. For instance, this may be based on the investigator's convenience or whether the participant can afford a particular drug or not. Although such a design can suggest a possible relationship between the intervention and the outcome, it is susceptible to bias – with patients in the two groups being potentially dissimilar – and hence validity of the results obtained is low.
Interventional studies without concurrent controls
When a new intervention, e.g., a new drug, becomes available, it is possible to a researcher to assign a group of persons to receive it and compare the outcome in them to that in a similar group of persons followed up in the past without this treatment (”historical controls”). This is liable to a high risk of bias, e.g., through differences in the severity of disease or other factors in the two groups or through improvement over time in the available supportive care.
Before–after (pre–post) studies
In this design, a variable of interest is measured before and after an intervention in the same participants. Examples include measurement of glycated hemoglobin of a group of persons before and after administration of a new drug (in a particular dose schedule and at a particular time in relation to it) or number of traffic accident deaths in a city before and after implementation of a policy of mandatory helmet use for two-wheeler drivers.
Such studies have a single arm and lack a comparator arm. The only basis of deriving a conclusion from these studies is the temporal relationship of the measurements to the intervention. However, the outcome can instead be related to other changes that occurred around the same time as the intervention, e.g., change in diet or implementation of alcohol use restrictions, respectively, in the above examples. The change can also represent a natural variation (e.g., diurnal or seasonal) in the variable of interest or a change in the instrument used to measure it. Thus, the outcomes observed in such studies cannot be reliably attributed to the specific intervention, making this a weaker design than RCT.
Some believe that the before-after design is comparable to observational design and that only studies with a “comparator” group, as discussed above, are truly interventional studies.
Factorial study design
If two (or more) interventions are available for a particular disease condition, the relevant question is not only whether each drug is efficacious but also whether a combination of the two is more efficacious than either of them alone.
The simplest factorial design is a 2 × 2 factorial design. Let us think of two interventions: A and B. The participants are randomly allocated to one of four combinations of these interventions – A alone, B alone, both A and B, and neither A nor B (control). This design allows (i) comparison of each intervention with the control group, (ii) comparison of the two interventions with each other, and (iii) investigation of possible interactions between the two treatments (whether the effect of the combination differs from the sum of effects of A and B when given separately). As an example, in a recent study, infants in South India being administered a rotavirus vaccine were randomly assigned to receive a zinc supplement and a probiotic, only probiotic (with zinc placebo), only zinc supplement (with probiotic placebo), or neither (probiotic placebo and zinc placebo).[ 4 ] Neither zinc nor probiotic led to any change in the immunogenicity of the vaccine, but the group receiving the zinc-probiotic combination had a modest improvement.
This design allows the study of two interventions in the same trial without unduly increasing the required number of participants, as also the study of interaction between the two treatments.
Crossover study design
This is a special type of interventional study design, in which study participants intentionally “crossover” to the other intervention arm. Each participant first receives one intervention (usually by random allocation, as described above). At the end of this “ first” intervention, each participant is switched over to the other intervention. Most often, the two interventions are separated by a washout period to get rid of the effect of the first intervention and to allow each participant to return to the baseline state. For example, in a recent study, obese participants underwent two 5-day inpatient stays – with a 1-month washout period between them, during which they consumed a smoothie containing 48-g walnuts or a macronutrient-matched placebo smoothie without nuts and underwent measurement of several blood analytes, hemodynamics, and gut microbiota.[ 5 ]
This design has the advantages of (i) each participant serving as his/her own control, thereby reducing the effect of interindividual variability, and (ii) needing fewer participants than a parallel-arm RCT. However, this design can be used only for disease conditions which are stable and cannot be cured, and where interventions provide only transient relief. For instance, this design would be highly useful for comparing the effect of two anti-inflammatory drugs on symptoms in patients with long-standing rheumatoid arthritis.
Cluster randomized trials
Sometimes, an intervention cannot be easily administered to individuals but can be applied to groups. In such cases, a trial can be done by assigning “clusters” – some logical groups of participants – to receive or not receive the intervention.
As an example, a study in Greece looked at the effect of providing meals in schools on household food security.[ 6 ] The 51 schools in this study were randomly allocated to provide or not provide a healthy meal every day to students; schools in both the groups provided an educational intervention.
However, such studies need a somewhat larger sample size than individual-randomized studies and the use of special statistical tools for data analysis.
Financial support and sponsorship
Conflicts of interest.
There are no conflicts of interest.
Information
- Author Services
Initiatives
You are accessing a machine-readable page. In order to be human-readable, please install an RSS reader.
All articles published by MDPI are made immediately available worldwide under an open access license. No special permission is required to reuse all or part of the article published by MDPI, including figures and tables. For articles published under an open access Creative Common CC BY license, any part of the article may be reused without permission provided that the original article is clearly cited. For more information, please refer to https://www.mdpi.com/openaccess .
Feature papers represent the most advanced research with significant potential for high impact in the field. A Feature Paper should be a substantial original Article that involves several techniques or approaches, provides an outlook for future research directions and describes possible research applications.
Feature papers are submitted upon individual invitation or recommendation by the scientific editors and must receive positive feedback from the reviewers.
Editor’s Choice articles are based on recommendations by the scientific editors of MDPI journals from around the world. Editors select a small number of articles recently published in the journal that they believe will be particularly interesting to readers, or important in the respective research area. The aim is to provide a snapshot of some of the most exciting work published in the various research areas of the journal.
Original Submission Date Received: .
- Active Journals
- Find a Journal
- Proceedings Series
- For Authors
- For Reviewers
- For Editors
- For Librarians
- For Publishers
- For Societies
- For Conference Organizers
- Open Access Policy
- Institutional Open Access Program
- Special Issues Guidelines
- Editorial Process
- Research and Publication Ethics
- Article Processing Charges
- Testimonials
- Preprints.org
- SciProfiles
- Encyclopedia
Article Menu
- Subscribe SciFeed
- Recommended Articles
- Google Scholar
- on Google Scholar
- Table of Contents
Find support for a specific problem in the support section of our website.
Please let us know what you think of our products and services.
Visit our dedicated information section to learn more about MDPI.
JSmol Viewer
Algorithm-based modular psychotherapy alleviates brain inflammation in generalized anxiety disorder.

1. Introduction
2. materials and methods, 2.1. study design, 2.2. participants, 2.3. clinical assessment, 2.4. interventions, 2.5. magnetic resonance imaging (mri), 2.6. data analysis, 3.1. clinical symptoms, 3.2. mri markers of neuroinflammation, 3.3. correlations between changes in clinical symptoms and inflammatory markers, 3.4. effects of sex, 4. discussion, 5. conclusions, author contributions, institutional review board statement, informed consent statement, data availability statement, acknowledgments, conflicts of interest.
- Association, A.P. Diagnostic and Statistical Manual of Mental Disorders , 5th ed.; American Psychiatric Press: Washington, DC, USA, 2013. [ Google Scholar ]
- Kessler, R.C.; Avenevoli, S.; Costello, J.; Green, J.G.; Gruber, M.J.; McLaughlin, K.A.; Petukhova, M.; Sampson, N.A.; Zaslavsky, A.M.; Merikangas, K.R. Severity of 12-month DSM-IV disorders in the National Comorbidity Survey Replication Adolescent Supplement. Arch. Gen. Psychiatry 2012 , 69 , 381–389. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Wittchen, H.U.; Hoyer, J. Generalized anxiety disorder: Nature and course. J. Clin. Psychiatry 2001 , 62 (Suppl. 11), 15–19, discussion 20–11. [ Google Scholar ]
- Yonkers, K.A.; Warshaw, M.G.; Massion, A.O.; Keller, M.B. Phenomenology and course of generalised anxiety disorder. Br. J. Psychiatry 1996 , 168 , 308–313. [ Google Scholar ] [ CrossRef ]
- Strawn, J.R.; Geracioti, L.; Rajdev, N.; Clemenza, K.; Levine, A.A. Pharmacotherapy for generalized anxiety disorder in adult and pediatric patients: An evidence-based treatment review. Expert Opin. Pharmacother. 2018 , 19 , 1057–1070. [ Google Scholar ] [ CrossRef ]
- Baldwin, D.S.; Ajel, K.I.; Garner, M. Pharmacological treatment of generalized anxiety disorder. Curr. Top. Behav. Neurosci. 2010 , 2 , 453–467. [ Google Scholar ] [ CrossRef ]
- Kong, W.; Deng, H.-w.; Wan, J.-q.; Zhou, Y.; Zhou, Y.; Song, B.; Wang, X. Comparative Remission Rates and Tolerability of Drugs for Generalised Anxiety Disorder: A Systematic Review and Network Meta-analysis of Double-Blind Randomized Controlled Trials. Front. Pharmacol. 2020 , 11 , 580858. [ Google Scholar ] [ CrossRef ]
- Bhattacharya, S.; Goicoechea, C.; Heshmati, S.; Carpenter, J.K.; Hofmann, S.G. Efficacy of Cognitive Behavioral Therapy for Anxiety-Related Disorders: A Meta-Analysis of Recent Literature. Curr. Psychiatry Rep. 2023 , 25 , 19–30. [ Google Scholar ] [ CrossRef ]
- Cuijpers, P.; Cristea, I.A.; Karyotaki, E.; Reijnders, M.; Huibers, M.J. How effective are cognitive behavior therapies for major depression and anxiety disorders? A meta-analytic update of the evidence. World Psychiatry 2016 , 15 , 245–258. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Papola, D.; Miguel, C.; Mazzaglia, M.; Franco, P.; Tedeschi, F.; Romero, S.A.; Patel, A.R.; Ostuzzi, G.; Gastaldon, C.; Karyotaki, E.; et al. Psychotherapies for Generalized Anxiety Disorder in Adults: A Systematic Review and Network Meta-Analysis of Randomized Clinical Trials. JAMA Psychiatry 2024 , 81 , 250–259. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Renna, M.E.; O’Toole, M.S.; Spaeth, P.E.; Lekander, M.; Mennin, D.S. The association between anxiety, traumatic stress, and obsessive-compulsive disorders and chronic inflammation: A systematic review and meta-analysis. Depress Anxiety 2018 , 35 , 1081–1094. [ Google Scholar ] [ CrossRef ]
- Milaneschi, Y.; Kappelmann, N.; Ye, Z.; Lamers, F.; Moser, S.; Jones, P.B.; Burgess, S.; Penninx, B.; Khandaker, G.M. Association of inflammation with depression and anxiety: Evidence for symptom-specificity and potential causality from UK Biobank and NESDA cohorts. Mol. Psychiatry 2021 , 26 , 7393–7402. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Michopoulos, V.; Powers, A.; Gillespie, C.F.; Ressler, K.J.; Jovanovic, T. Inflammation in Fear- and Anxiety-Based Disorders: PTSD, GAD, and Beyond. Neuropsychopharmacology 2017 , 42 , 254–270. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Glaus, J.; von Känel, R.; Lasserre, A.M.; Strippoli, M.F.; Vandeleur, C.L.; Castelao, E.; Gholam-Rezaee, M.; Marangoni, C.; Wagner, E.N.; Marques-Vidal, P.; et al. The bidirectional relationship between anxiety disorders and circulating levels of inflammatory markers: Results from a large longitudinal population-based study. Depress. Anxiety 2018 , 35 , 360–371. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Costello, H.; Gould, R.L.; Abrol, E.; Howard, R. Systematic review and meta-analysis of the association between peripheral inflammatory cytokines and generalised anxiety disorder. BMJ Open 2019 , 9 , e027925. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Miller, A.H.; Raison, C.L. The role of inflammation in depression: From evolutionary imperative to modern treatment target. Nat. Rev. Immunol. 2016 , 16 , 22–34. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Rosenblat, J.D.; Cha, D.S.; Mansur, R.B.; McIntyre, R.S. Inflamed moods: A review of the interactions between inflammation and mood disorders. Prog. Neuropsychopharmacol. Biol. Psychiatry 2014 , 53 , 23–34. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Fries, G.R.; Saldana, V.A.; Finnstein, J.; Rein, T. Molecular pathways of major depressive disorder converge on the synapse. Mol. Psychiatry 2023 , 28 , 284–297. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Valiati, F.E.; Feiten, J.G.; Géa, L.P.; Silveira Júnior, É.M.; Scotton, E.; Caldieraro, M.A.; Salum, G.A.; Kauer-Sant’Anna, M. Inflammation and damage-associated molecular patterns in major psychiatric disorders. Trends Psychiatry Psychother. 2023 , 45 , e20220576. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Goldsmith, D.R.; Bekhbat, M.; Mehta, N.D.; Felger, J.C. Inflammation-Related Functional and Structural Dysconnectivity as a Pathway to Psychopathology. Biol. Psychiatry 2023 , 93 , 405–418. [ Google Scholar ] [ CrossRef ]
- Bourgognon, J.-M.; Cavanagh, J. The role of cytokines in modulating learning and memory and brain plasticity. Brain Neurosci. Adv. 2020 , 4 , 2398212820979802. [ Google Scholar ] [ CrossRef ]
- Tang, Z.; Ye, G.; Chen, X.; Pan, M.; Fu, J.; Fu, T.; Liu, Q.; Gao, Z.; Baldwin, D.S.; Hou, R. Peripheral proinflammatory cytokines in Chinese patients with generalised anxiety disorder. J. Affect. Disord. 2018 , 225 , 593–598. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Felger, J.C.; Treadway, M.T. Inflammation Effects on Motivation and Motor Activity: Role of Dopamine. Neuropsychopharmacology 2017 , 42 , 216–241. [ Google Scholar ] [ CrossRef ]
- Izquierdo, I.; Furini, C.R.; Myskiw, J.C. Fear Memory. Physiol. Rev. 2016 , 96 , 695–750. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Lai, C.H. Task MRI-Based Functional Brain Network of Anxiety. Adv. Exp. Med. Biol. 2020 , 1191 , 3–20. [ Google Scholar ] [ CrossRef ]
- Rezaei, S.; Gharepapagh, E.; Rashidi, F.; Cattarinussi, G.; Sanjari Moghaddam, H.; Di Camillo, F.; Schiena, G.; Sambataro, F.; Brambilla, P.; Delvecchio, G. Machine learning applied to functional magnetic resonance imaging in anxiety disorders. J. Affect. Disord. 2023 , 342 , 54–62. [ Google Scholar ] [ CrossRef ]
- Sangha, S.; Diehl, M.M.; Bergstrom, H.C.; Drew, M.R. Know safety, no fear. Neurosci. Biobehav. Rev. 2020 , 108 , 218–230. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Taschereau-Dumouchel, V.; Michel, M.; Lau, H.; Hofmann, S.G.; LeDoux, J.E. Putting the “mental” back in “mental disorders”: A perspective from research on fear and anxiety. Mol. Psychiatry 2022 , 27 , 1322–1330. [ Google Scholar ] [ CrossRef ]
- Rauch, S.L.; Shin, L.M.; Wright, C.I. Neuroimaging studies of amygdala function in anxiety disorders. Ann. N. Y. Acad Sci. 2003 , 985 , 389–410. [ Google Scholar ] [ CrossRef ]
- McEwen, B.S. Glucocorticoids, depression, and mood disorders: Structural remodeling in the brain. Metabolism 2005 , 54 , 20–23. [ Google Scholar ] [ CrossRef ]
- Kolesar, T.A.; Bilevicius, E.; Wilson, A.D.; Kornelsen, J. Systematic review and meta-analyses of neural structural and functional differences in generalized anxiety disorder and healthy controls using magnetic resonance imaging. NeuroImage Clin. 2019 , 24 , 102016. [ Google Scholar ] [ CrossRef ]
- Ortiz, S.; Latsko, M.S.; Fouty, J.L.; Dutta, S.; Adkins, J.M.; Jasnow, A.M. Anterior Cingulate Cortex and Ventral Hippocampal Inputs to the Basolateral Amygdala Selectively Control Generalized Fear. J. Neurosci. 2019 , 39 , 6526–6539. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Irle, E.; Ruhleder, M.; Lange, C.; Seidler-Brandler, U.; Salzer, S.; Dechent, P.; Weniger, G.; Leibing, E.; Leichsenring, F. Reduced amygdalar and hippocampal size in adults with generalized social phobia. J. Psychiatry Neurosci. 2010 , 35 , 126–131. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Felger, J.C. Imaging the Role of Inflammation in Mood and Anxiety-related Disorders. Curr. Neuropharmacol. 2018 , 16 , 533–558. [ Google Scholar ] [ CrossRef ]
- Yirmiya, R.; Goshen, I. Immune modulation of learning, memory, neural plasticity and neurogenesis. Brain Behav. Immun. 2011 , 25 , 181–213. [ Google Scholar ] [ CrossRef ]
- Zhang, W.; Rutlin, J.; Eisenstein, S.A.; Wang, Y.; Barch, D.M.; Hershey, T.; Bogdan, R.; Bijsterbosch, J.D. Neuroinflammation in the Amygdala Is Associated With Recent Depressive Symptoms. Biol. Psychiatry Cogn. Neurosci. Neuroimaging 2023 , 8 , 967–975. [ Google Scholar ] [ CrossRef ]
- Chen, J.; Song, Y.; Yang, J.; Zhang, Y.; Zhao, P.; Zhu, X.J.; Su, H.C. The contribution of TNF-α in the amygdala to anxiety in mice with persistent inflammatory pain. Neurosci. Lett. 2013 , 541 , 275–280. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Zheng, Z.H.; Tu, J.L.; Li, X.H.; Hua, Q.; Liu, W.Z.; Liu, Y.; Pan, B.X.; Hu, P.; Zhang, W.H. Neuroinflammation induces anxiety- and depressive-like behavior by modulating neuronal plasticity in the basolateral amygdala. Brain Behav. Immun. 2021 , 91 , 505–518. [ Google Scholar ] [ CrossRef ]
- Mehta, N.D.; Haroon, E.; Xu, X.; Woolwine, B.J.; Li, Z.; Felger, J.C. Inflammation negatively correlates with amygdala-ventromedial prefrontal functional connectivity in association with anxiety in patients with depression: Preliminary results. Brain Behav. Immun. 2018 , 73 , 725–730. [ Google Scholar ] [ CrossRef ]
- Munshi, S.; Loh, M.K.; Ferrara, N.; DeJoseph, M.R.; Ritger, A.; Padival, M.; Record, M.J.; Urban, J.H.; Rosenkranz, J.A. Repeated stress induces a pro-inflammatory state, increases amygdala neuronal and microglial activation, and causes anxiety in adult male rats. Brain Behav. Immun. 2020 , 84 , 180–199. [ Google Scholar ] [ CrossRef ]
- Yang, L.; Wang, M.; Guo, Y.Y.; Sun, T.; Li, Y.J.; Yang, Q.; Zhang, K.; Liu, S.B.; Zhao, M.G.; Wu, Y.M. Systemic inflammation induces anxiety disorder through CXCL12/CXCR4 pathway. Brain Behav. Immun. 2016 , 56 , 352–362. [ Google Scholar ] [ CrossRef ]
- Matsuura, S.; Nishimoto, Y.; Endo, A.; Shiraki, H.; Suzuki, K.; Segi-Nishida, E. Hippocampal Inflammation and Gene Expression Changes in Peripheral Lipopolysaccharide Challenged Mice Showing Sickness and Anxiety-Like Behaviors. Biol. Pharm. Bull. 2023 , 46 , 1176–1183. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Herpertz, S.C.; Schramm, E. Modulare Psychotherapie: Ein Mechanismus—Basiertes, Personalisiertes Vorgehen ; Schattauer: Stuttgart, Germany, 2022. [ Google Scholar ]
- Huibers, M.J.H.; Lorenzo-Luaces, L.; Cuijpers, P.; Kazantzis, N. On the Road to Personalized Psychotherapy: A Research Agenda Based on Cognitive Behavior Therapy for Depression. Front. Psychiatry 2020 , 11 , 607508. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Purgato, M.; Singh, R.; Acarturk, C.; Cuijpers, P. Moving beyond a ‘one-size-fits-all’ rationale in global mental health: Prospects of a precision psychology paradigm. Epidemiol. Psychiatr. Sci. 2021 , 30 , e63. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Schramm, E.; Elsaesser, M.; Jenkner, C.; Hautzinger, M.; Herpertz, S.C. Algorithm-based modular psychotherapy vs. cognitive-behavioral therapy for patients with depression, psychiatric comorbidities and early trauma: A proof-of-concept randomized controlled trial. World Psychiatry 2024 , 23 , 257–266. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Vøllestad, J.; Nielsen, M.B.; Nielsen, G.H. Mindfulness- and acceptance-based interventions for anxiety disorders: A systematic review and meta-analysis. Br. J. Clin. Psychol. 2012 , 51 , 239–260. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Timulak, L.; McElvaney, J. Emotion-Focused Therapy for Generalized Anxiety Disorder: An Overview of the Model. J. Contemp. Psychother. 2016 , 46 , 41–52. [ Google Scholar ] [ CrossRef ]
- Ballesio, A.; Zagaria, A.; Vacca, M.; Pariante, C.M.; Lombardo, C. Comparative efficacy of psychological interventions on immune biomarkers: A systematic review and network meta-analysis (NMA). Brain Behav. Immun. 2023 , 111 , 424–435. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Black, D.S.; Slavich, G.M. Mindfulness meditation and the immune system: A systematic review of randomized controlled trials. Ann. N. Y. Acad. Sci. 2016 , 1373 , 13–24. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Ma, H.; Xu, J.; Li, R.; McIntyre, R.S.; Teopiz, K.M.; Cao, B.; Yang, F. The Impact of Cognitive Behavioral Therapy on Peripheral Interleukin-6 Levels in Depression: A Systematic Review and Meta-Analysis. Front. Psychiatry 2022 , 13 , 844176. [ Google Scholar ] [ CrossRef ]
- O’Toole, M.S.; Bovbjerg, D.H.; Renna, M.E.; Lekander, M.; Mennin, D.S.; Zachariae, R. Effects of psychological interventions on systemic levels of inflammatory biomarkers in humans: A systematic review and meta-analysis. Brain Behav. Immun. 2018 , 74 , 68–78. [ Google Scholar ] [ CrossRef ]
- Sanada, K.; Montero-Marin, J.; Barceló-Soler, A.; Ikuse, D.; Ota, M.; Hirata, A.; Yoshizawa, A.; Hatanaka, R.; Valero, M.S.; Demarzo, M.; et al. Effects of Mindfulness-Based Interventions on Biomarkers and Low-Grade Inflammation in Patients with Psychiatric Disorders: A Meta-Analytic Review. Int. J. Mol. Sci. 2020 , 21 , 2484. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Gandarela, L.; Sampaio, T.P.D.A.; Marçal, L.; Burdmann, E.A.; Neto, F.L.; Bernik, M.A. Inflammatory markers changes following acceptance-based behavioral psychotherapy in generalized anxiety disorder patients: Evidence from a randomized controlled trial. Brain Behav. Immun. Health 2024 , 38 , 100779. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Grasmann, J.; Almenräder, F.; Voracek, M.; Tran, U.S. Only Small Effects of Mindfulness-Based Interventions on Biomarker Levels of Inflammation and Stress: A Preregistered Systematic Review and Two Three-Level Meta-Analyses. Int. J. Mol. Sci. 2023 , 24 , 4445. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Memon, A.A.; Sundquist, K.; Ahmad, A.; Wang, X.; Hedelius, A.; Sundquist, J. Role of IL-8, CRP and epidermal growth factor in depression and anxiety patients treated with mindfulness-based therapy or cognitive behavioral therapy in primary health care. Psychiatry Res. 2017 , 254 , 311–316. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Kéri, S.; Szabó, C.; Kelemen, O. Expression of Toll-Like Receptors in peripheral blood mononuclear cells and response to cognitive-behavioral therapy in major depressive disorder. Brain Behav. Immun. 2014 , 40 , 235–243. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Wang, Y.; Wang, Q.; Haldar, J.P.; Yeh, F.C.; Xie, M.; Sun, P.; Tu, T.W.; Trinkaus, K.; Klein, R.S.; Cross, A.H.; et al. Quantification of increased cellularity during inflammatory demyelination. Brain 2011 , 134 , 3590–3601. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Cross, A.H.; Song, S.K. A new imaging modality to non-invasively assess multiple sclerosis pathology. J. Neuroimmunol. 2017 , 304 , 81–85. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Samara, A.; Murphy, T.; Strain, J.; Rutlin, J.; Sun, P.; Neyman, O.; Sreevalsan, N.; Shimony, J.S.; Ances, B.M.; Song, S.K.; et al. Neuroinflammation and White Matter Alterations in Obesity Assessed by Diffusion Basis Spectrum Imaging. Front. Hum. Neurosci. 2019 , 13 , 464. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Wang, Q.; Wang, Y.; Liu, J.; Sutphen, C.L.; Cruchaga, C.; Blazey, T.; Gordon, B.A.; Su, Y.; Chen, C.; Shimony, J.S.; et al. Quantification of white matter cellularity and damage in preclinical and early symptomatic Alzheimer’s disease. Neuroimage Clin. 2019 , 22 , 101767. [ Google Scholar ] [ CrossRef ]
- Kéri, S.; Kelemen, O. Signatures of neuroinflammation in the hippocampus and amygdala in individuals with religious or spiritual problem. In Religion Brain and Behavior ; Taylor & Francis: Abingdon, UK, 2024; pp. 1–13. [ Google Scholar ] [ CrossRef ]
- Narvaez Linares, N.F.; Charron, V.; Ouimet, A.J.; Labelle, P.R.; Plamondon, H. A systematic review of the Trier Social Stress Test methodology: Issues in promoting study comparison and replicable research. Neurobiol. Stress 2020 , 13 , 100235. [ Google Scholar ] [ CrossRef ]
- First, M.B.; Williams, J.B.W.; Karg, R.S.; Spitzer, R.L. Structured Clinical Interview for DSM-5 Disorders—Clinician Version (SCID-5-CV) ; American Psychiatric Association Publishing: Washington, DC, USA, 2016. [ Google Scholar ]
- Maier, W.; Buller, R.; Philipp, M.; Heuser, I. The Hamilton Anxiety Scale: Reliability, validity and sensitivity to change in anxiety and depressive disorders. J. Affect. Disord. 1988 , 14 , 61–68. [ Google Scholar ] [ CrossRef ]
- Spitzer, R.L.; Kroenke, K.; Williams, J.B.; Löwe, B. A brief measure for assessing generalized anxiety disorder: The GAD-7. Arch. Intern. Med. 2006 , 166 , 1092–1097. [ Google Scholar ] [ CrossRef ]
- Wang, Y.P.; Gorenstein, C. Psychometric properties of the Beck Depression Inventory-II: A comprehensive review. Braz. J. Psychiatry 2013 , 35 , 416–431. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Robichaud, M.; Koerner, N.; Dugas, M.J. Cognitive Behavioral Treatment for Generalized Anxiety Disorder ; Taylor & Francis: Oxfordshire, UK, 2019. [ Google Scholar ]
- McCown, D.; Reibel, D.; Micozzi, M.S. Teaching Mindfulness. A Practical Guide for Clinicians and Educators ; Springer: New York, NY, USA, 2011. [ Google Scholar ]
- Segal, Z.; Williams, M.; Teasdale, J. Mindfulness-Based Cognitive Therapy for Depression ; Guilford: New York, NY, USA, 2018. [ Google Scholar ]
- Yager, J.; Feinstein, R.E. Potential Applications of the National Institute of Mental Health’s Research Domain Criteria (RDoC) to Clinical Psychiatric Practice: How RDoC Might Be Used in Assessment, Diagnostic Processes, Case Formulation, Treatment Planning, and Clinical Notes. J. Clin. Psychiatry 2017 , 78 , 423–432. [ Google Scholar ] [ CrossRef ]
- Alfaro-Almagro, F.; Jenkinson, M.; Bangerter, N.K.; Andersson, J.L.R.; Griffanti, L.; Douaud, G.; Sotiropoulos, S.N.; Jbabdi, S.; Hernandez-Fernandez, M.; Vallee, E.; et al. Image processing and Quality Control for the first 10,000 brain imaging datasets from UK Biobank. Neuroimage 2018 , 166 , 400–424. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Miller, K.L.; Alfaro-Almagro, F.; Bangerter, N.K.; Thomas, D.L.; Yacoub, E.; Xu, J.; Bartsch, A.J.; Jbabdi, S.; Sotiropoulos, S.N.; Andersson, J.L.; et al. Multimodal population brain imaging in the UK Biobank prospective epidemiological study. Nat. Neurosci. 2016 , 19 , 1523–1536. [ Google Scholar ] [ CrossRef ]
- Fischl, B. FreeSurfer. NeuroImage 2012 , 62 , 774–781. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Fischl, B.; Salat, D.H.; Busa, E.; Albert, M.; Dieterich, M.; Haselgrove, C.; van der Kouwe, A.; Killiany, R.; Kennedy, D.; Klaveness, S.; et al. Whole brain segmentation: Automated labeling of neuroanatomical structures in the human brain. Neuron 2002 , 33 , 341–355. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Jenkinson, M.; Beckmann, C.F.; Behrens, T.E.J.; Woolrich, M.W.; Smith, S.M. FSL. NeuroImage 2012 , 62 , 782–790. [ Google Scholar ] [ CrossRef ]
- Zhang, Y.; Brady, M.; Smith, S. Segmentation of brain MR images through a hidden Markov random field model and the expectation-maximization algorithm. IEEE Trans. Med. Imaging 2001 , 20 , 45–57. [ Google Scholar ] [ CrossRef ]
- Eysenck, H.J. The effects of psychotherapy: An evaluation. 1952. J. Consult. Clin. Psychol. 1992 , 60 , 659–663. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Cuijpers, P.; Karyotaki, E.; Reijnders, M.; Ebert, D.D. Was Eysenck right after all? A reassessment of the effects of psychotherapy for adult depression. Epidemiol. Psychiatr. Sci. 2019 , 28 , 21–30. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Munder, T.; Flückiger, C.; Leichsenring, F.; Abbass, A.A.; Hilsenroth, M.J.; Luyten, P.; Rabung, S.; Steinert, C.; Wampold, B.E. Is psychotherapy effective? A re-analysis of treatments for depression. Epidemiol. Psychiatr. Sci. 2019 , 28 , 268–274. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Dillon, D.G.; Rosso, I.M.; Pechtel, P.; Killgore, W.D.; Rauch, S.L.; Pizzagalli, D.A. Peril and pleasure: An rdoc-inspired examination of threat responses and reward processing in anxiety and depression. Depress. Anxiety 2014 , 31 , 233–249. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Lang, P.J.; McTeague, L.M.; Bradley, M.M. RDoC, DSM, and the reflex physiology of fear: A biodimensional analysis of the anxiety disorders spectrum. Psychophysiology 2016 , 53 , 336–347. [ Google Scholar ] [ CrossRef ]
- Frank, B.; Jacobson, N.C.; Hurley, L.; McKay, D. A theoretical and empirical modeling of anxiety integrated with RDoC and temporal dynamics. J. Anxiety Disord. 2017 , 51 , 39–46. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Cuthbert, B.N. The role of RDoC in future classification of mental disorders. Dialogues Clin. Neurosci. 2020 , 22 , 81–85. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Nusslock, R.; Walden, K.; Harmon-Jones, E. Asymmetrical frontal cortical activity associated with differential risk for mood and anxiety disorder symptoms: An RDoC perspective. Int. J. Psychophysiol. 2015 , 98 , 249–261. [ Google Scholar ] [ CrossRef ]
- Li, H.; Sagar, A.P.; Kéri, S. Translocator protein (18kDa TSPO) binding, a marker of microglia, is reduced in major depression during cognitive-behavioral therapy. Prog. Neuropsychopharmacol. Biol. Psychiatry 2018 , 83 , 1–7. [ Google Scholar ] [ CrossRef ]
Click here to enlarge figure
| GAD (n = 50) | Healthy Controls (n = 50) | |||
|---|---|---|---|---|
| Age (years) | 39.9 (11.6) | 39.6 (12.4) | ||
| Education (years) | 11.5 (3.5) | 12.1 (3.2) | ||
| Sex (male/female) | 21/29 | 21/29 | ||
| Smoking (smokers/non-smokers) | 17/33 | 17/33 | ||
| Alcohol consumption (units/week) | 8.3 (5.8) | 9.4 (5.4) | ||
| Body mass index (BMI) | 28.5 (9.1) | 26.8 (8.8) | ||
| Before and after MoBa | Before | After | Before | After |
| BDI-II | 10.4 (6.0) | 8.0 (4.7) * | - | - |
| HAM-A | 23.2 (4.2) | 19.1 (5.5) * | - | - |
| GAD-7 | 14.5 (3.9) | 9.7 (5.0) * | - | - |
| The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
Share and Cite
Kéri, S.; Kancsev, A.; Kelemen, O. Algorithm-Based Modular Psychotherapy Alleviates Brain Inflammation in Generalized Anxiety Disorder. Life 2024 , 14 , 887. https://doi.org/10.3390/life14070887
Kéri S, Kancsev A, Kelemen O. Algorithm-Based Modular Psychotherapy Alleviates Brain Inflammation in Generalized Anxiety Disorder. Life . 2024; 14(7):887. https://doi.org/10.3390/life14070887
Kéri, Szabolcs, Alexander Kancsev, and Oguz Kelemen. 2024. "Algorithm-Based Modular Psychotherapy Alleviates Brain Inflammation in Generalized Anxiety Disorder" Life 14, no. 7: 887. https://doi.org/10.3390/life14070887
Article Metrics
Article access statistics, further information, mdpi initiatives, follow mdpi.
Subscribe to receive issue release notifications and newsletters from MDPI journals
Transforming the understanding and treatment of mental illnesses.
Información en español
Celebrating 75 Years! Learn More >>
- Science News
- Meetings and Events
- Social Media
- Press Resources
- Email Updates
- Innovation Speaker Series
Saving Lives Through the Science of Suicide Prevention
November 13, 2023 • Feature Story • 75th Anniversary
At a Glance
- Suicide is among the leading causes of death in the United States.
- Recognizing the urgency of this issue, NIMH has invested in large-scale research efforts to improve suicide risk screening, assessment, and intervention.
- NIMH-supported research showed that universal suicide risk screening paired with follow-up interventions can reduce suicide risk.
- Intramural researchers at NIMH have developed a suicide risk screening toolkit to support screening in health care settings.
- Research continues to build on these advances, translating science into clinical practice.
If you asked people about the most common causes of death in the United States, they’d likely mention conditions like heart disease, stroke, or diabetes. And they’d be right. But there's another leading cause that often goes unmentioned: suicide. This stark reality is reflected in the data : In 2020, suicide was among the top four causes of death among people ages 10 to 44, and the 12th leading cause of death overall in the United States.
The issue has never been more urgent.
“No one should die by suicide,” said Joshua A. Gordon, M.D., Ph.D., Director of the National Institute of Mental Health (NIMH). “We can’t afford to wait—which is why NIMH is investing in research to identify practical, hands-on tools and approaches that can help us prevent suicide now.”
NIMH has made suicide prevention a priority , spurring large-scale research efforts to improve screening, risk assessment, and intervention. As a result, evidence-based strategies are now being implemented in health care settings across the country as a core component of the suicide prevention toolkit.
Addressing urgent needs
In the spring of 2006, Lisa Horowitz, Ph.D., M.P.H., visited NIH to interview for a position on the psychiatry consult service at the NIH Clinical Center. Just a few months earlier, a patient receiving inpatient medical care at the Clinical Center had died by suicide .
“When I came to apply for the job, the whole building was still reverberating around this suicide,” recalled Horowitz, who is now a senior research associate in the NIMH Intramural Research Program.
As a research fellow at Boston Children’s Hospital, Horowitz developed a triage tool that nurses could use in the emergency department to screen pediatric mental health patients for suicide risk. Her interview with NIMH Clinical Director Maryland Pao, M.D., planted the seed for what would turn into an entire line of research at NIMH.
“We were having lunch at the conference table in her office, and Dr. Pao asked, ‘Do you think we could use your screening tool for all patients, not just mental health patients?’”
To find out, Horowitz and Pao collaborated with researchers at several pediatric hospitals to launch a multisite study in pediatric emergency departments. Their aim was to develop a suicide risk screening tool that would allow clinicians to quickly identify which patients need further assessment.

Results from the study, published in 2012 , showed that a “yes” response to any one of four screening questions identified 97% of young people who met the criteria for “clinically significant” risk on a standard 30-item suicide risk questionnaire. Notably, the screener—now known as the Ask Suicide- Screening Questions tool , or ASQ—only took about 20 seconds to administer.
Although other suicide risk screening tools existed at the time, the ASQ added a brief, easy-to-use option to the screening toolkit.
Since the original study, the ASQ has been validated in other medical settings, including inpatient medical-surgical units and outpatient specialty care and primary care clinics. It has been validated for use with adults, as well.
Casting a wide net
On the surface, asking every patient who receives care in a medical setting to complete a suicide risk screening may seem unnecessary or excessive. But research shows that this approach, known as universal screening, identifies many people at risk who would otherwise be missed.
“What we’ve learned is that people who come to the emergency department with a physical complaint may also be at risk of suicide, but they might not reveal that unless you ask them directly,” said Jane Pearson, Ph.D., Special Advisor on Suicide Research to the NIMH Director.
With universal screening tools, clinicians don’t have to discern which patients are at risk.
“It’s not realistic to expect health care providers to be able to figure out who they should screen and who they shouldn’t,” said Stephen O’Connor, Ph.D., Chief of the NIMH Suicide Prevention Research Program. “When screening is universal, it becomes standardized, and it sets the expectation that every patient will be screened.”
This is critical because health care providers are in a unique position to identify people at risk—indeed, data show that more than half of people who die by suicide saw a health care provider in the month before their death. Research also shows that screening results can predict later suicidal behavior, which means screening tools present an opportunity to intervene early.
As part of NIMH’s commitment to prioritizing suicide prevention research, the institute supports innovative extramural projects focused on universal suicide risk screening. Among these projects is the Emergency Department Screening for Teens at Risk for Suicide (ED-STARS) study , launched in 2014.
In collaboration with the Pediatric Emergency Care Applied Research Network, ED-STARS researchers analyzed youth screening data from 13 emergency departments to develop the Computerized Adaptive Screen for Suicidal Youth (CASSY) . They designed CASSY to adjust the screening questions based on patients’ previous responses to assess their overall level of suicide risk.
The researchers then tested whether CASSY predicted real-world behavior in a separate sample of more than 2,700 youth. The results showed that CASSY accurately identified more than 80% of youth who went on to attempt suicide in the 3 months after the screening.
Integrating interventions
While evidence clearly shows that universal screening can aid suicide prevention efforts, it also shows that screening is just the beginning.
“Screening is one part of the story,” said O’Connor. “When people screen positive for suicide risk, it’s important to follow that with a full assessment and evidence-based approaches for intervention and follow-up care.”
Key findings come from the NIMH-supported Emergency Department Safety Assessment and Follow-Up Evaluation (ED-SAFE) study . Designed as a multi-phase clinical trial, the ED-SAFE study allowed researchers to assess the impacts of universal suicide risk screening and follow-up interventions in eight emergency departments over 5 years.

In the first phase, adult patients seeking care at a participating emergency department received treatment as usual. The second phase introduced universal suicide risk screening—all emergency department patients completed a brief screening tool called the Patient Safety Screener.
The third phrase added a three-part intervention. Patients who screened positive on the Patient Safety Screener completed a secondary suicide risk screening, developed a personalized safety plan, and received a series of supportive phone calls in the following months.
As a result of universal screening, the screening rate rose from about 3% to 84%, and the detection rate of patients at risk for suicide rose from about 3% to almost 6%.
Importantly, findings from the third phase showed that it was screening combined with the multi-part intervention that actually reduced patients’ suicide risk. Patients who received the intervention had 30% fewer suicide attempts than those who received only screening or treatment as usual.
Laying out a roadmap
Ensuring that health care providers have a clearly delineated clinical pathway that links universal screening to the appropriate next steps can help them accurately assess and address their patients’ needs.
Patients may worry that they’ll automatically be hospitalized if they tell their health care provider that they’ve had suicidal thoughts in the past. But the reality is that only a small proportion of patients who screen positive on the initial screen will need urgent inpatient care—the majority are more likely to benefit from outpatient follow-up and other types of mental health care.
“With a clinical pathway, clinicians can have a conversation with their patients and give them an idea of what to expect,” said Pearson. “Screening has to be part of a workflow that accounts for different levels of risk, and you have to put all those pieces together.”

To health care providers already under considerable strain, rolling out universal suicide risk screening may seem like a tall order. But NIMH-supported research shows that it can work across a range of settings, from small specialty clinics to large health care systems.
Building on this work, Horowitz and colleagues in the NIMH Intramural Research Program have developed an ASQ toolkit that includes clinical pathways, scripts, and other resources tailored to the medical setting and patient age. These evidence-based clinical pathways, in turn, provided a scientific basis for the Blueprint for Youth Suicide Prevention developed by the American Academy of Pediatrics and the American Foundation for Suicide Prevention.
“The biggest thing I’ve learned is it has to be flexible,” noted Horowitz. “You’re not going to have the same access to care in rural Alaska that you’d have in New York City, so it’s important to help clinicians figure out how to adapt a pathway for their setting or practice.”
For example, large health care systems may be able to adopt certain technologies, such as computer algorithms, that can integrate electronic health record data into the screening and identification process. NIMH-supported research is exploring this data-based approach to risk identification in Veterans Health Administration hospitals , managed health care systems , and other large-scale settings .
However, other medical settings—including many primary and specialty care clinics—may prefer lower-resource approaches that are easy to adapt, such as brief, self-report screening tools.
“Having options is important for implementation. It depends on how health systems can leverage resources and incorporate them into the workflow,” said Pearson. “That’s why NIMH is investing in research on multiple, complementary approaches.”
Putting science into practice
To accelerate research that can make a difference in the near term, NIMH has launched a Practice-Based Suicide Prevention Research Centers program . The program aims to support clinical practice settings as real-world laboratories where multidisciplinary research teams can develop, test, and refine suicide prevention practices at each step of the clinical pathway. The centers are engaging with service users, families, health care providers, and administrators to ensure services are relevant, practicable, and rapidly integrated into the clinical workflow.
“The intent is that these practice-based centers will serve as national resources,” explained Pearson. “Each center has the opportunity to do pilot work, and they’ll be talking to each other to identify synergies across the centers.”
In line with NIMH’s commitment to addressing mental health disparities, the centers are focused on suicide prevention among groups and populations that are known to have higher suicide risk or are experiencing rapidly increasing suicide rates, especially those that face inequities in access to mental health services.
Addressing mental health disparities is also a pressing concern for Horowitz and colleagues as they continue their work with the ASQ.
“Right now, we’re focused on implementation and health equity,” said Horowitz. “It’s important to understand whether and how screening tools work for different populations that are known to have higher suicide risk.
American Indian/Alaska Native communities are one such priority population. Building on earlier pilot work, Horowitz and colleagues are collaborating with the Indian Health Service (IHS) to roll out suicide risk screening in IHS medical settings, including 22 emergency departments, around the United States.
Working directly with providers and administrators in different health care settings allows researchers to understand how contextual factors and structural constraints affect implementation.
“We’ve learned from researchers working in emergency departments, for example, that it’s difficult to bill for intervention components like safety planning and follow-up phone calls,” said Pearson. “That can pose a real problem when the interventions are key ingredients that help reduce people’s risk.”
This kind of work also underscores that successful implementation isn’t a one-time thing, but a continuous effort that is reinforced over time. For example, an extension of the ED-SAFE study suggests that quality improvement processes that promote ongoing training and monitoring can help sustain the effects of suicide prevention efforts.
Bending the curve
Soon after assuming the helm as NIMH Director in 2016, Dr. Gordon wrote about his commitment to suicide prevention as one of the institute’s top research priorities. He noted that building on promising findings from ED-SAFE and other NIMH-supported studies would give us “a chance to bend the curve on suicide rates, to save the lives of thousands of individuals.”

No one knew then that the coronavirus pandemic would upend life around the world just 3 years later, changing the landscape of mental health and mental health care in the process. Although it will take time to unpack the nuances of the pandemic’s long-term impacts, data point to wide-ranging effects on people’s mental health, including increased suicide risk for some.
“This is why research on suicide prevention in real-world settings is more important than ever,” said Pearson. “We’ve learned a lot since 2016, and a lot of the implementation work is just beginning. We hope this research will speed the translation of science into practice to help save lives.”
Publications
Aguinaldo, L. D., Sullivan, S., Lanzillo, E. C., Ross, A., He, J. P., Bradley-Ewing, A., Bridge, J. A., Horowitz, L. M., & Wharff, E. A. (2021). Validation of the Ask Suicide-Screening Questions (ASQ) with youth in outpatient specialty and primary care clinics. General Hospital Psychiatry , 68 , 52–58. https://doi.org/10.1016/j.genhosppsych.2020.11.006
Ahmedani, B. K., Westphal, J., Autio, K., Elsiss, F., Peterson, E. L., Beck, A., Waitzfelder, B. E., Rossom, R. C., Owen-Smith, A. A., Lynch, F., Lu, C. Y., Frank, C., Prabhakar, D., Braciszewski, J. M., Miller-Matero, L. R., Yeh, H.-H., Hu, Y., Doshi, R., Waring, S. C., & Simon, G. E. (2019). Variation in patterns of health care before suicide: A population case-control study. Preventive Medicine , 127 , Article 105796. https://doi.org/10.1016/j.ypmed.2019.105796
Boudreaux, E. D., Camargo, C. A., Jr., Arias, S. A., Sullivan, A. F., Allen, M. H., Goldstein, A. B., Manton, A. P., Espinola, J. A., & Miller, I. W. (2016). Improving suicide risk screening and detection in the emergency department. American Journal of Preventive Medicine , 50 (4), 445–453. https://doi.org/10.1016/j.amepre.2015.09.029
Boudreaux, E. D., Larkin, C., Vallejo Sefair, A., Ma, Y., Li, Y. F., Ibrahim, A. F., Zeger, W., Brown, G. K., Pelletier, L., Miller, I., & ED-SAFE Investigators. (2023). Effect of an emergency department process improvement package on suicide prevention: The ED-SAFE 2 cluster randomized clinical trial. JAMA Psychiatry , 80 (7), 665–674. https://doi.org/10.1001/jamapsychiatry.2023.1304
Centers for Disease Control and Prevention. (2023, October 12). WISQARS™ — Web-based Injury Statistics Query and Reporting System . National Center for Injury Prevention and Control, Centers for Disease Control and Prevention. https://www.cdc.gov/injury/wisqars/index.html
Czeisler, M. É., Lane, R. I., Petrosky E., Wiley, J. F., Christensen, A., Njai, R., Weaver, M. D., Robbins, R., Facer-Childs, E. R., Barger, L. K., Czeisler, C. A., Howard, M. E., & Rajaratnam, S. M. (2020). Mental health, substance use, and suicidal ideation during the COVID-19 pandemic — United States, June 24–30, 2020. Morbidity Mortality Weekly Report (MMWR) , 69 (32) , 1049–1057. http://dx.doi.org/10.15585/mmwr.mm6932a1
Fontanella, C. A., Warner, L. A., Steelesmith, D., Bridge, J. A., Sweeney, H. A., & Campo, J. V. (2020). Clinical profiles and health services patterns of Medicaid-enrolled youths who died by suicide. JAMA Pediatrics , 174 (5), 470–477. https://doi.org/10.1001/jamapediatrics.2020.0002
Gordon, J. A., Avenevoli, S., & Pearson, J. L. (2020). Suicide prevention research priorities in health care. JAMA Psychiatry , 77 (9), 885–886. https://doi.org/10.1001/jamapsychiatry.2020.1042
Horowitz, L. M., Bridge, J. A., Teach, S. J., Ballard, E., Klima, J., Rosenstein, D. L., Wharff, E. A., Ginnis, K., Cannon, E., Joshi, P., & Pao, M. (2012). Ask Suicide-Screening Questions (ASQ): A brief instrument for the pediatric emergency department. Archives of Pediatrics & Adolescent Medicine , 166 (12), 1170–1176. https://doi.org/10.1001/archpediatrics.2012.1276
Horowitz, L. M., Snyder, D. J., Boudreaux, E. D., He, J.-P., Harrington, C. J., Cai, J., Claassen, C. A., Salhany, J. E., Dao, T., Chaves, J. F., Jobes, D. A., Merikangas, K. R., Bridge, J. A., Pao, M. (2020). Validation of the Ask Suicide-Screening Questions for adult medical inpatients: A brief tool for all ages. Psychosomatics , 61 (6), 713−722. https://doi.org/10.1016/j.psym.2020.04.008
Horowitz, L. M., Wharff, E. A., Mournet, A. M., Ross, A. M., McBee-Strayer, S., He, J.-P., Lanzillo, E. C., White, E., Bergdoll, E., Powell, D. S., Solages, M., Merikangas, K. R., Pao, M., & Bridge, J. A. (2020). Validation and feasibility of the ASQ among pediatric medical and surgical inpatients. Hospital Pediatrics , 10 (9), 750–757. https://doi.org/10.1542/hpeds.2020-0087
King, C. A., Brent, D., Grupp-Phelan, J., Casper, T. C., Dean, J. M., Chernick, L. S., Fein, J. A., Mahabee-Gittens, E. M., Patel, S. J., Mistry, R. D., Duffy, S., Melzer-Lange, M., Rogers, A., Cohen, D. M., Keller, A., Shenoi, R., Hickey, R. W., Rea, M., Cwik, M., Page, K., … Pediatric Emergency Care Applied Research Network. (2021). Prospective development and validation of the Computerized Adaptive Screen for Suicidal Youth. JAMA Psychiatry , 78 (5), 540–549. https://doi.org/10.1001/jamapsychiatry.2020.4576
McKnight-Eily, L. R., Okoro, C. A., Strine, T. W., Verlenden, J., Hollis, N. D., Njai, R., Mitchell, E. W., Board, A., Puddy, R., & Thomas, C. (2021). Racial and ethnic disparities in the prevalence of stress and worry, mental health conditions, and increased substance use among adults during the COVID-19 Pandemic — United States, April and May 2020. Morbidity and Mortality Weekly Report , 70 (5), 162–166. https://doi.org/10.15585/mmwr.mm7005a3
Miller, I. W., Camargo, C. A., Arias, S. A., Sullivan, A. F., Allen, M. H., Goldstein, A. B., Manton, A. P., Espinola, J. A., Jones, R., Hasegawa, K., Boudreaux, E. D., & ED-SAFE Investigators. (2017). Suicide prevention in an emergency department population: The ED-SAFE Study. JAMA Psychiatry , 74 (6), 563–570. https://doi.org/10.1001/jamapsychiatry.2017.0678
Mitchell, T. O., & Li, L. (2021). State-level data on suicide mortality during COVID-19 quarantine: Early evidence of a disproportionate impact on minorities. Psychiatry Research , 295 , Article 113629. https://doi.org/10.1016/j.psychres.2020.113629
Roaten, K., Horowitz, L. M., Bridge, J. A., Goans, C. R. R., McKintosh, C., Genzel, R., Johnson, C., North, C. S. (2021). Universal pediatric suicide risk screening in a health care system: 90,000 patient encounters. Journal of the Academy of Consultation-Liaison Psychiatry , 62 (4), 421−429. https://doi.org/10.1016/j.jaclp.2020.12.002
Center for Behavioral Health Statistics and Quality, Substance Abuse and Mental Health Services Administration. (2022). Key substance use and mental health indicators in the United States: Results from the 2021 National Survey on Drug Use and Health (HHS Publication No. PEP22-07-01-005, NSDUH Series H-57). U.S. Department of Health and Human Services. https://www.samhsa.gov/data/report/2021-nsduh-annual-national-report
- NIMH Priority Research Area Page: Suicide Research
- NIMH Health Information Page: Suicide Prevention
- NIMH Publications: Suicide Prevention
- NIMH Digital Shareables: Suicide Prevention
- NIMH Statistics Page: Suicide
Ohio State nav bar
The Ohio State University
- BuckeyeLink
- Find People
- Search Ohio State

What fat cats on a diet may tell us about obesity in humans
Study hints at impact of dietary effects on gut bacteria.
Pet cats may be excellent animal models for the study of obesity origins and treatment in humans, a new study of feline gut microbes suggests – and both species would likely get healthier in the research process, scientists say.
Veterinary researchers analyzed fecal samples from fat cats as the animals lost and maintained weight over the course of four dietary changes, including strict calorie reduction. The team found that food-related changes to the cats’ gut microbiome – the assortment of bacteria and molecules those bacteria produce and consume – have striking similarities to dietary effects on the gut previously seen in humans.

Though there is still a lot to learn, the findings place pet cats at the top of the list of animals whose gut bacteria may tell us a lot about our own – and whether gut microbe-based therapy could be one way to battle obesity.
“Animals share our beds. They share our ice cream. There are all these things that people do with their pets that highlight they are a naturally occurring disease model with similar environmental exposures as humans,” said lead study author Jenessa Winston , assistant professor of veterinary clinical sciences at The Ohio State University .
“Being able to see changes in cats that come up in the context of obesity and type 2 diabetes in people makes them a really good model to start looking at more microbiome-directed therapeutics for obesity in humans if we’re seeing a similar shift,” she said. “Microbes we saw in this study also come up again and again in human studies – and clearly, people aren’t eating cat chow, right?”
The study was published recently in the journal Scientific Reports .
An estimated 60% of cats are obese or overweight in developed countries, and more than 2 in 5 adults in the United States have obesity, according to the Centers for Disease Control and Prevention .
At Ohio State, Winston oversees two large clinical trials exploring the potential for fecal transplants from lean dogs and cats to help their overweight pet peers lose weight.
“My lab is focused on how we can harness the therapeutic power of microbes,” she said. “In order to do that, we have to understand how disease states may be different from health so that we can better try and figure out and target, mechanistically, changes that occur in the microbiome.”
In this study, researchers fed seven obese cats a four-phase diet over 16 weeks: free-feeding of commercial cat food for two weeks, free-feeding of a specially formulated weight-loss diet for one week, calorie-restricted feeding of the weight-loss diet to achieve 1-2% body weight reduction per week for 11 weeks, and a return to the original maintenance diet.
The analysis of fecal samples taken during the different diet phases focused on changes in the presence of short-chain fatty acids metabolites, molecules produced by bacteria during digestion. Fatty acids are of interest because they prompt specific types of communication between gut microbes and tissue in the rest of the body – including hormonal signals that can relate to inflammation and insulin resistance.
The team found that the abundance of a short-chain fatty acid called propionic acid – shown in other mammals to regulate appetite, reduce fat accumulation and protect against obesity and diabetes – was increased in feces when the cats were losing weight on the calorie-restricted diet. Greater propionic acid composition was associated with an increase in the bacterium Prevotella 9 copri . Though direct production of propionic acid by Prevotella couldn’t be determined in this study, the finding that these increases occurred at the same time, when cats were dropping weight, was intriguing. Previous research has linked Prevotella 9 copri in the human gut to weight loss and better blood sugar control.
“When the cats are on the special diet formulated for weight loss, propionic acid goes up and stays high, and then goes back down when they’re put back on the maintenance diet. So it really is a dietary change,” Winston said. “This paper highlights that when we calorie-restrict cats that are obese, we can alter their microbial ecosystem – and those community shifts that we see likely correlate with some metabolic outcomes.
“I think that those parallels that we’re seeing in how the ecosystems change in a similar way is helpful,” she said.
The gut microbiome’s precise role in mammal obesity remains a mystery, but Winston said decades of evidence suggests these organisms and molecules they produce are part of the problem behind what is now known to be a very complex disease. This study’s findings in felines suggest the pet cat gut profile could provide meaningful answers for both species, she said.
The weight-loss diet in the study was provided by Nestle Purina, which also provided funding for the project. Winston and some co-authors are paid speakers for Nestle Purina.
Co-authors include John Rowe, Valerie Parker and Adam Rudinsky of Ohio State; Katie McCool of North Carolina State University; Jan Suchodolski, Rosana Lopes and Jörg Steiner of Texas A&M University; and Chen Gilor of the University of Florida.
More Ohio State News
Chemists design novel method for generating sustainable fuel.
Chemists have been working to synthesize high-value materials from waste molecules for years.
President Carter discusses university mission, affordability, new first-year class
The Ohio State University President Walter “Ted” Carter Jr. addressed his vision for the university, the value of a college degree and a robust first-year class at a community forum this week, with the start of a new academic year just weeks away.
Sports Dentistry Club makes free mouthguards for local students
As team dentist at The Ohio State University, Deborah Mendel is familiar with the toll sports take on players’ mouths. Teeth can be mis-positioned or pushed into lips or, worst of all, knocked out entirely. Mouthguards, Mendel said, are crucial to keeping student-athletes safe.
Contact: Admissions | Webmaster | Page maintained by University Communications
Request an alternate format of this page | Web Services Status | Nondiscrimination notice
Log in using your username and password
- Search More Search for this keyword Advanced search
- Latest content
- Current issue
- BMJ Journals
You are here
- Online First
- Impact of NICE clinical guidelines for prevention and treatment of neonatal infections on antibiotic use in very preterm infants in England and Wales: an interrupted time series analysis
- Article Text
- Article info
- Citation Tools
- Rapid Responses
- Article metrics
- http://orcid.org/0000-0001-9109-6164 Mike Saunders 1 ,
- http://orcid.org/0000-0001-5668-4227 Shalini Ojha 2 , 3 ,
- http://orcid.org/0000-0003-3295-5891 Lisa Szatkowski 2
- 1 University of Nottingham School of Medicine , Nottingham , UK
- 2 Centre for Perinatal Research , University of Nottingham School of Medicine , Nottingham , UK
- 3 Neonatal Unit , University Hospitals of Derby and Burton NHS Foundation Trust , Derby , UK
- Correspondence to Dr Lisa Szatkowski; Lisa.Szatkowski{at}nottingham.ac.uk
Objective To assess the impact of publication of UK National Institute for Health and Care Excellence (NICE) guidelines on the prevention and treatment of early-onset infections (EOIs) in neonates (clinical guideline 149 (CG149), published in 2012, and its 2021 update (NG195) on antibiotic use in very preterm infants.
Design Interrupted time series analysis using data from the National Neonatal Research Database.
Setting Neonatal units in England and Wales.
Participants Infants born at 22–31 weeks’ gestation from 1 January 2010 to 31 December 2022 and survived to discharge.
Interventions Publication of CG149 (August 2012) and NG195 (April 2021).
Main outcome measures Measures of antibiotic use, aggregated by month of birth: antibiotic use rate (AUR), the proportion of care days in receipt of at least one antibiotic; percentage of infants who received ≥1 day of antibiotics on days 1–3 for EOI and after day 3 for late-onset infection (LOI); percentage who received ≥1 prolonged antibiotic course ≥5 days for EOI and LOI.
Results 96% of infants received an antibiotic during inpatient stay. AUR declined at publication of CG149, without further impact at NG195 publication. There was no impact of CG149 on the underlying trend in infants receiving ≥1 day antibiotics for EOI or LOI, but post-NG195 the monthly trend began to decline for EOI (−0.20%, −0.26 to −0.14) and LOI (−0.23%, −0.33 to −0.12). Use of prolonged antibiotic courses for EOI and LOI declined at publication of CG149 and for LOI this trend accelerated post-NG195.
Conclusions Publications of NICE guidance were associated with reductions in antibiotic use; however neonatal antibiotic exposure remains extremely high.
- Neonatology
- Epidemiology
Data availability statement
Data may be obtained from a third party and are not publicly available. National Neonatal Research Database data may be obtained from a third party with relevant approvals.
This is an open access article distributed in accordance with the Creative Commons Attribution Non Commercial (CC BY-NC 4.0) license, which permits others to distribute, remix, adapt, build upon this work non-commercially, and license their derivative works on different terms, provided the original work is properly cited, appropriate credit is given, any changes made indicated, and the use is non-commercial. See: http://creativecommons.org/licenses/by-nc/4.0/ .
https://doi.org/10.1136/archdischild-2024-326983
Statistics from Altmetric.com
Request permissions.
If you wish to reuse any or all of this article please use the link below which will take you to the Copyright Clearance Center’s RightsLink service. You will be able to get a quick price and instant permission to reuse the content in many different ways.
WHAT IS ALREADY KNOWN ON THIS TOPIC
Antibiotics are very often prescribed to preterm infants, though irrational use is associated with harm. The National Institute for Health and Care Excellence published clinical guideline 149 (CG149) in 2012 and updated guidance in 2021 (NG195), with recommendations for neonatal antibiotic prescribing. The national impact of CG149 and NG195 on antibiotic use has not been studied.
WHAT THIS STUDY ADDS
Interrupted time series analysis quantified the impact of publication of CG149 and NG195 on measures of antibiotic initiation and prolonged use. Publication of CG149 was associated with decreases in the proportion of care days infants received at least one antibiotic and exposure to a prolonged antibiotic course, though with smaller or no change for extremely premature infants and those with bacterial infection or recorded indication(s) for antibiotics. Publication of NG195 was associated with decreases in antibiotic use for late onset infection. Over 95% of preterm infants studied were exposed to antibiotics.
HOW THIS STUDY MIGHT AFFECT RESEARCH, PRACTICE OR POLICY
This study finds that publication of national guidance CG149 and NG195 was associated with reductions in neonatal antibiotic use, possibly through more conservative and consistent antibiotic prescribing. However, antibiotic use remains extremely high among preterm infants. Further research is required to find evidence-based approaches to empiric antibiotic prescribing in newborn infants to identify reliable and safe means of optimising and safely reducing avoidable antibiotic exposure.
Introduction
Neonatal infection is common and burdensome. 1 2 Clinical manifestations can be non-specific and difficult to distinguish from other pathology. 3 Preterm infants have higher incidence and mortality of early-onset infection (EOI, within 72 hours of birth) and late-onset infection (LOI, ≥72 hours from birth) than term infants 2 4 5 and have prolonged hospital stays which carry risk of healthcare-associated infection.
Neonatal antibiotic use is empirical (given prior to confirmation of infection) and based on risk and clinical assessment, 4 as investigations may yield false negative results 3 and delay could risk deterioration. 6 Antibiotics are very commonly prescribed in neonatal units 7–9 and save lives but use risks drug toxicity, side effects 4 and antibiotic resistance. Prolonged antibiotic use is associated with harm, including necrotising enterocolitis (NEC), neurological injury, LOI, 8 10–12 invasive fungal diseases 13 and disruption of gut microbiota. 3
The National Institute for Health and Care Excellence (NICE) produces and publishes evidence-based clinical guidelines in the UK. Before 2012, there was no UK national guidance on preventing and treating neonatal infections. NICE published a consensus-based clinical guideline (CG149) in August 2012 2 with recommendations for intrapartum antibiotic prophylaxis, risk factors for and possible clinical signs of EOI, and indications for investigation and empirical treatment of EOI.
CG149 had potential limitations. Preterm birth after spontaneous labour with prolonged preterm rupture of membranes necessitated antibiotic use, meaning many premature babies receive antibiotics as default. Additionally, in practice a low threshold is used to manage maternal perinatal fever as sepsis 14 which obligated neonatal antibiotic prescribing. Clinical indicators of neonatal sepsis were non-specific, 1 based on low-quality evidence 2 and risked subjective interpretation. Additionally, antibiotic course length recommendations were unclear, the impact of intrapartum antibiotic prophylaxis on neonatal management was not described, and there were no recommendations for LOI.
New guidance (NG195) superseded CG149 in April 2021, 15 which introduced recommendations for managing LOI. The main recommendations in this revision were again introduced without any evidence-base or evaluation of impact of antibiotic exposure on babies. Based on evidence from the USA, NG195 permits the alternative of using the Kaiser Permanente neonatal sepsis risk calculator 16 (KP-SRC) to inform clinical decisions on EOI management. The KP-SRC, however, is only applicable to babies born at ≥34 weeks’ gestation and the recommendations for most preterm babies therefore remained consensus based.
It is not known whether the introduction of NICE CG149 and NG195 (summarised in online supplemental figure 1 ) altered antibiotic prescribing patterns. This is pertinent to ensure antibiotics are used wisely and prevent avoidable harms. This study aims to assess their impact on measures of antibiotic use in very and extremely preterm infants admitted to neonatal units in England and Wales.
Supplemental material
Data management and analysis were conducted using R V.4.3.2 17 and Stata V.18 (Stata, College Station, Texas, USA).
Data source and study population
We used data from the UK National Neonatal Research Database (NNRD), 18 derived from the electronic patient records of all infants admitted to NHS neonatal units in England and Wales, for very preterm infants (born at 28–31 weeks gestational age, GA) and extremely preterm infants (22–27 weeks GA) born from 1 January 2010 to 31 December 2022. Infants were excluded if missing data on sex, birth weight, final discharge destination, episodes of care; died; or were discharged for ongoing care. We also excluded infants with implausible birth weight for GA z-scores >4 SD above or below the mean, admitted >24 hours after birth or born with a lethal congenital anomaly ( online supplemental table 1 ).
Outcome measures
NNRD data on antibiotic exposure in the first 14 days are accurate. 18 Antibiotic use was identified by searching the NNRD daily drugs field for character strings matching antibiotic names with intravenous preparations ( online supplemental table 2 ), identified from the British National Formulary for Children (version September 2021). 19 Prophylactic, oral and topical preparations were excluded.
We calculated several measures of antibiotic use aggregated by month of birth. The antibiotic use rate (AUR) was the aggregate percentage of inpatient days in receipt of at least one antibiotic. We calculated the percentage of infants exposed to one or more days of antibiotics initiated day 1–3 (presumed to be for EOI) and initiated day 4 or later (presumed to be for LOI), with day of birth defined as day 1. We identified the percentage of infants who received a prolonged antibiotic course (≥5 consecutive days) for EOI or LOI. LOI antibiotic prescribing was defined using a ‘washout’ period of 2 days without antibiotics to exclude a continuing EOI antibiotic course. Finally, for the first day of antibiotic prescription for EOI and LOI, we identified which antibiotic(s) were prescribed.
Statistical methods
The study period is divided into three periods: (1) before CG149 publication (January 2010–July 2012); (2) between publication of CG149 and NG195 (August 2012–March 2021); (3) after NG195 publication (April 2021–December 2022). Characteristics of the study population by period were described.
We used segmented regression to investigate the impact of publications on the outcomes. 20 The regression models estimate (1) the monthly trend in each outcome in period 1; (2) any immediate absolute change in magnitude or trend in period 2 relative to period 1 and (3) any immediate absolute change in magnitude or trend in period 3 relative to period 2.
We built a parsimonious model for each outcome through backwards elimination of non-statistically significant variables, based on a significance level of 0.05. The autocorrelation function, partial autocorrelation function and Ljung-Box test demonstrated no significant autocorrelation of model residuals.
Subgroup analysis
We conducted prespecified subgroup analyses to investigate variations in impact defined by characteristics considered likely to influence antibiotic use: (1) very versus extremely preterm infants; (2) infants with versus without evidence of bacterial infection; (3) infants with versus without a recorded antibiotic indication(s) (based on presence of diagnosis codes for bacterial infection, isolation of an antibiotic-resistant organism or NEC). We identified characteristics for subgroup analyses 2 and 3 by searching for character strings in daily and episodic diagnoses records matching a list of diagnoses ( online supplemental table 3 ). We excluded diagnoses indicating risk of infection, suspected but unconfirmed infection and infections not specific to a bacterial cause.
Type(s) of antibiotic prescribed
We plotted the most frequently prescribed antibiotic monotherapy and combinations for EOI and LOI by birth year to illustrate changes over time. We present the top seven most frequently prescribed antibiotic(s) with the remainder categorised as ‘other’.
Data were available for 97 387 infants born at 22–31 weeks GA during the study period and admitted to neonatal units in England and Wales. After exclusions ( online supplemental table 4 ), 84 626 infants were included. Table 1 describes the population by time period.
- View inline
Description of characteristics of study population
On average, 546 infants were born each month, with relatively fewer per month in period 3. The proportion of infants first admitted to a neonatal intensive care unit increased over time but there were no clinically relevant differences in median GA, birth weight, birth weight for GA z-score and length of stay.
Table 2 describes overall use of antibiotics and indications for use. Almost all infants (96.0%, n=81 278) received at least one antibiotic during their stay. The percentage of infants who had a recorded antibiotic indication, evidence of bacterial infection or NEC declined over time, but there was little difference in the percentage with an antibiotic-resistant organism.
Antibiotic use and indications for use by study period
Table 3 shows the results of the interrupted time series analysis, and figures 1 and 2 show the fitted regression lines from the parsimonious models.
- Download figure
- Open in new tab
- Download powerpoint
Changes in the overall antibiotic use rate before and after the publication of CG149 and NG195. CG149, clinical guideline 149; NG195, NICE guideline 195.
Changes in the percentage of infants who received ≥1 day, and ≥1 prolonged course, of antibiotics for EOI (A and C) and LOI (B and D). CG149, clinical guideline 149; NG195, NICE guideline 195; EOI, early-onset infection; LOI, late-onset infection.
Month-on-month absolute percentage changes (with 95% CIs) in antibiotic use before and after the publication of CG149 and NG195
The median (IQR) AUR across the study period was 19.5% (18.5–20.2) of total care days per month. In period 1, AUR was increasing by 0.03% per month. This immediately declined by 1.02% in period 2 and the trend reversed, resulting in an absolute decrease of 0.02% per month, which did not change during period 3. Over the study period, the AUR declined from 20.5% to 17.5% of total care days, which equates to approximately 1000 fewer days of antibiotic use per month (approximately 2 fewer days of antibiotics per infant) on average.
Almost all (93.4%, n=79 006) infants received antibiotics for EOI. The prevalence was stable in periods 1 and 2, though declined in period 3 by 0.20% per month. Just over half (54.0%, n=45 684) received antibiotics for LOI. Prevalence was increasing by 0.02% per month in period 1 and did not change until period 3, where it declined by 0.23% per month.
Approximately one-third (35.7%, n=30 201) of infants received a prolonged EOI antibiotic course. The prevalence dropped by 1.87% in period 2 and continued to decline by 0.08% per month thereafter. Similarly, one-third (32.9%, n=27 796) were exposed to a prolonged LOI antibiotic course. Prevalence initially increased by 0.12% per month but immediately declined by 0.02% per month in period 2, accelerating to a decline of 0.14% per month in period 3.
Online supplemental table 5 and online supplemental figure 2 show the subgroup analyses. The number of infants born per month in some subgroups was small, resulting in greater monthly outcome variability and reduced power to detect small changes.
Extreme prematurity, bacterial infection and a recorded antibiotic indication were associated with a higher AUR and exposure to antibiotic(s) for ≥1 day, or ≥1 prolonged course, than the respective comparison subgroup.
Very premature infants observed a greater reduction in AUR, EOI antibiotic exposure and prolonged LOI exposure than extremely premature infants in period 2. During period 3, extremely premature babies observed greater reductions in AUR and EOI and LOI antibiotic exposure than very premature babies.
In period 2, the trend in AUR reduced for infants without bacterial infection, and EOI and LOI antibiotic use immediately reduced for infants with evidence of bacterial infection, but without a change in trend. Over the same period, infants without infection saw a temporary increase in EOI antibiotic use with a reduction in trend and no changes in LOI antibiotic use.
Figure 3 shows changes over time in the type of antibiotics prescribed on the first day of prescribing for EOI and LOI (full data in online supplemental table 6 ). For EOI, the percentage of infants receiving benzylpenicillin plus gentamicin increased from 72.3% in 2010 to 83.0% in 2014, remaining relatively stable since. Prescribing for LOI was more variable. Flucloxacillin plus gentamicin was the most frequent combination, received by 28.2% of infants, followed by cefotaxime and vancomycin (7.6%).
Type and combination of antibiotics prescribed on the first day of prescribing for EOI (A) and LOI (B), by year of birth. EOI, early-onset infection; LOI, late-onset infection.
We found that publication of NICE guidance in 2012 (CG149) and its update in 2021 (NG195) were associated with some reductions in antibiotic use for extremely and very preterm infants in England and Wales, resulting in more consistent antibiotic use, with defined course lengths. This may explain the temporary changes in antibiotic prescribing for LOI seen in 2012, with sustained decreasing trends only seen following the update of the guidance in 2021 when recommendations on antibiotic use for LOI were first introduced.
Choice of antibiotics for EOI has become increasingly consistent with NICE guidance. However, choice for LOI continues to vary substantially, perhaps due to omission of recommendations for LOI in 2012 and only a broad recommendation to use ‘a combination of narrow-spectrum antibiotics’ in 2021. 15
This is the first national evaluation of the impact of NICE guidelines on antibiotic use in preterms, though other studies have investigated the impact on term and near-term infants. 21 22 Almost all extremely and very preterm infants received antibiotics, reiterating that neonatal units are a priority setting to reduce avoidable antibiotic use.
For EOI antibiotic use in term and near-term infants, NICE now recommends an alternative approach, the KP-SRC. 16 While NICE standard recommendations are largely opinion based, the KP-SRC is based on a multivariable risk prediction model using data from large cohorts of infants born at ≥35 weeks’ gestation in California, USA. 16 The KP-SRC and other strategies recommended by the US American Academy of Paediatics, 23 similar to NICE, identify risk factors for EOI and clinical indicators of illness and need for repeat observations. The KP-SRC has been widely adopted in the UK and observational studies show large reductions in antibiotic use and laboratory testing compared with NICE 2012 (Goel 24 ) but there is a concern that more conservative use of antibiotics and fewer babies screened for EOI incurs a risk of missing a significant number of infants with infection. 25 Use of the KP-SRC has been subjected to numerous observational studies in the UK, but there is no randomised comparison with NICE 2021, although an ongoing trial is comparing a similar approach to NICE 2021 with the KP-SRC in the Netherlands. 26 It remains a strong priority to compare the approaches, to reduce antibiotic use without risk of delayed treatment leading to harm. Furthermore, the KP-SRC is designed for ≥35 weeks’ gestation and most premature infants, who are both at a higher risk of infection and disproportionately affected by antibiotic associated harm, are excluded. The only guidance in the UK for this population is the NICE recommendations, highlighting the need for developing an evidence-based approach to rationalise antibiotic use in this group.
Preterm infants often have clinical indicators of possible EOI as listed in the 2021 NICE guidance (eg, apnoea, feeding difficulty, temperature instability) due to prematurity and related comorbidities. Both iterations of NICE guidance combine recommendations for mature and preterm infants, overlooking the impact of prematurity on clinical presentation. Consequently, almost all very and extremely preterm infants receive antibiotics which may cause harm in the short term, such as increased risk of NEC, and via alterations in gut microbiome, impact long-term health of survivors of prematurity.
Interrupted time series analysis is the strongest quasi-experimental study design to evaluate the impact of national guidance over time. 20 There were few substantial changes in the study population case-mix over time, reducing the likelihood of confounding. This analysis assumed an instantaneous impact of guidance on antibiotic use, though this may not reflect reality. Anticipatory and lag effects were not assessed given the absence of literature to inform a defined time period of potential effect. It is also unclear to what extent NICE guidance is consistently implemented. An attempt to assess guidance compliance in did not specifically assess antibiotic prescribing. 27 Adherence to a similar guideline in the Netherlands was low, 28 especially non-prescribing. Similarly, German neonatal units also found gaps between national guidance and practice. 29
While our findings demonstrate a temporal association between guidance publication and antibiotic use, we cannot infer causality. This segmented regression approach assumes preintervention trends would have continued without intervention, which cannot be verified. Changes in trends may be alternatively explained by other contemporaneous changes in practice or interventions, such as local quality improvement projects.
From NNRD data, it is challenging to distinguish suspected from confirmed infection, and indications for prescribing are not recorded. Excluding infants who died, who may have had very high AURs which would have skewed the overall measure, likely under-reports the full extent of neonatal antibiotic prescribing.
Reducing avoidable antibiotic prescribing can prevent antibiotic-associated harm, antibiotic resistance and health system costs. 30 Future guidance must consider the impact of prematurity on presentation and treatment to avoid antibiotic prescribing in preterm infants in situations where risk exceeds benefit. We corroborate international findings of overall reductions in antibiotic use though neonatal antibiotic use remains extremely high. It will be essential to monitor the impact of NG195 on antibiotic prescribing and apply findings to guidance development.
Ethics statements
Patient consent for publication.
Not applicable.
Ethics approval
The NNRD has NHS Research Ethics Committee (REC) approval for compilation of electronic patient record data from individual neonatal units (ref: 16/LO/1930). Parents are able to withdraw consent for inclusion of their child’s data in the NNRD. Ethics approval for this study was granted by the Yorkshire & The Humber Leeds East REC (18/YH/0209), the South East Scotland REC01 (IRAS323099) and the Health Research Authority and Health and Care Research Wales (IRAS323099).
Acknowledgments
Electronic patient data recorded at participating neonatal units that collectively form the UK Neonatal Collaborative are transmitted to the Neonatal Data Analysis Unit to form the National Neonatal Research Database (NNRD). We are grateful to all the families that agreed to the inclusion of their baby’s data in the NNRD, the health professionals who recorded data and the Neonatal Data Analysis Unit team. This project is funded by the National Institute for Health and Care Research (NIHR) under its Research for Patient Benefit (RfPB) Programme (Grant Reference Number NIHR203590). The views expressed are those of the author(s) and not necessarily those of the NIHR or the Department of Health and Social Care.
- Caffrey Osvald E ,
- National Institute for Health and Care Excellence
- Klingenberg C ,
- Kornelisse RF ,
- Buonocore G , et al
- Mukhopadhyay S ,
- Sengupta S ,
- Kortsalioudaki C ,
- Buttery J , et al
- Vergnano S ,
- Kortsalioudaki C , et al
- Al-Turkait A ,
- Szatkowski L ,
- Choonara I , et al
- Roberts A , et al
- Bancalari A , et al
- Roberts A ,
- Sherlock R , et al
- Kuppala VS ,
- Meinzen-Derr J ,
- Morrow AL , et al
- Cotten CM ,
- McDonald S ,
- Stoll B , et al
- Fitzgerald DJ ,
- Knowles SJ ,
- Downey P , et al
- Kuzniewicz MW ,
- Puopolo KM ,
- Fischer A , et al
- R Core Team
- Battersby C ,
- Statnikov Y ,
- Santhakumaran S , et al
- Wagner AK ,
- Soumerai SB ,
- Zhang F , et al
- Mukherjee A ,
- Davidson L ,
- Anguvaa L , et al
- Macaskill L ,
- van Hasselt TJ , et al
- Benitz WE ,
- Zaoutis TE , et al
- Cannell S ,
- Davies G , et al
- Achten NB ,
- Klingenberg C , et al
- van der Weijden BM ,
- van der Weide MC ,
- Plötz FB , et al
- Ramalingaiah B ,
- Kennea N , et al
- Bekhof J , et al
- Goedicke-Fritz S ,
- Härtel C , et al
- Flannery DD ,
Supplementary materials
Supplementary data.
This web only file has been produced by the BMJ Publishing Group from an electronic file supplied by the author(s) and has not been edited for content.
- Data supplement 1
X @DrMikePSaunders, @shaliniojha7
Correction notice This article has been updated since it was first published. An Orcid ID has been added to the first author's name.
Contributors MS designed and conceptualised the study, analysed and interpreted the data and drafted and revised the manuscript. LS designed and conceptualised the study, participated in analysis and interpretation of data, drafted and revised the manuscript, and is guarantor. SO designed and conceptualised the study, participated in interpretation of data and revised the manuscript.
Funding National Institute for Health and Care Research, Research for Patient Benefit Programme, NIHR203590.
Competing interests None declared.
Provenance and peer review Not commissioned; externally peer reviewed.
Supplemental material This content has been supplied by the author(s). It has not been vetted by BMJ Publishing Group Limited (BMJ) and may not have been peer-reviewed. Any opinions or recommendations discussed are solely those of the author(s) and are not endorsed by BMJ. BMJ disclaims all liability and responsibility arising from any reliance placed on the content. Where the content includes any translated material, BMJ does not warrant the accuracy and reliability of the translations (including but not limited to local regulations, clinical guidelines, terminology, drug names and drug dosages), and is not responsible for any error and/or omissions arising from translation and adaptation or otherwise.
Read the full text or download the PDF:
Chapter 5 Research Design
Research design is a comprehensive plan for data collection in an empirical research project. It is a “blueprint” for empirical research aimed at answering specific research questions or testing specific hypotheses, and must specify at least three processes: (1) the data collection process, (2) the instrument development process, and (3) the sampling process. The instrument development and sampling processes are described in next two chapters, and the data collection process (which is often loosely called “research design”) is introduced in this chapter and is described in further detail in Chapters 9-12.
Broadly speaking, data collection methods can be broadly grouped into two categories: positivist and interpretive. Positivist methods , such as laboratory experiments and survey research, are aimed at theory (or hypotheses) testing, while interpretive methods, such as action research and ethnography, are aimed at theory building. Positivist methods employ a deductive approach to research, starting with a theory and testing theoretical postulates using empirical data. In contrast, interpretive methods employ an inductive approach that starts with data and tries to derive a theory about the phenomenon of interest from the observed data. Often times, these methods are incorrectly equated with quantitative and qualitative research. Quantitative and qualitative methods refers to the type of data being collected (quantitative data involve numeric scores, metrics, and so on, while qualitative data includes interviews, observations, and so forth) and analyzed (i.e., using quantitative techniques such as regression or qualitative techniques such as coding). Positivist research uses predominantly quantitative data, but can also use qualitative data. Interpretive research relies heavily on qualitative data, but can sometimes benefit from including quantitative data as well. Sometimes, joint use of qualitative and quantitative data may help generate unique insight into a complex social phenomenon that are not available from either types of data alone, and hence, mixed-mode designs that combine qualitative and quantitative data are often highly desirable.
Key Attributes of a Research Design
The quality of research designs can be defined in terms of four key design attributes: internal validity, external validity, construct validity, and statistical conclusion validity.
Internal validity , also called causality, examines whether the observed change in a dependent variable is indeed caused by a corresponding change in hypothesized independent variable, and not by variables extraneous to the research context. Causality requires three conditions: (1) covariation of cause and effect (i.e., if cause happens, then effect also happens; and if cause does not happen, effect does not happen), (2) temporal precedence: cause must precede effect in time, (3) no plausible alternative explanation (or spurious correlation). Certain research designs, such as laboratory experiments, are strong in internal validity by virtue of their ability to manipulate the independent variable (cause) via a treatment and observe the effect (dependent variable) of that treatment after a certain point in time, while controlling for the effects of extraneous variables. Other designs, such as field surveys, are poor in internal validity because of their inability to manipulate the independent variable (cause), and because cause and effect are measured at the same point in time which defeats temporal precedence making it equally likely that the expected effect might have influenced the expected cause rather than the reverse. Although higher in internal validity compared to other methods, laboratory experiments are, by no means, immune to threats of internal validity, and are susceptible to history, testing, instrumentation, regression, and other threats that are discussed later in the chapter on experimental designs. Nonetheless, different research designs vary considerably in their respective level of internal validity.
External validity or generalizability refers to whether the observed associations can be generalized from the sample to the population (population validity), or to other people, organizations, contexts, or time (ecological validity). For instance, can results drawn from a sample of financial firms in the United States be generalized to the population of financial firms (population validity) or to other firms within the United States (ecological validity)? Survey research, where data is sourced from a wide variety of individuals, firms, or other units of analysis, tends to have broader generalizability than laboratory experiments where artificially contrived treatments and strong control over extraneous variables render the findings less generalizable to real-life settings where treatments and extraneous variables cannot be controlled. The variation in internal and external validity for a wide range of research designs are shown in Figure 5.1.
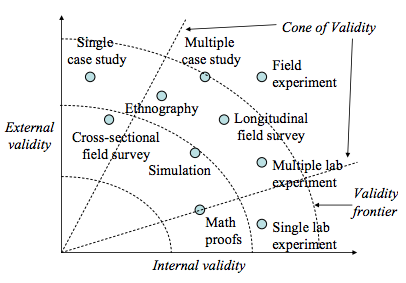
Figure 5.1. Internal and external validity.
Some researchers claim that there is a tradeoff between internal and external validity: higher external validity can come only at the cost of internal validity and vice-versa. But this is not always the case. Research designs such as field experiments, longitudinal field surveys, and multiple case studies have higher degrees of both internal and external validities. Personally, I prefer research designs that have reasonable degrees of both internal and external validities, i.e., those that fall within the cone of validity shown in Figure 5.1. But this should not suggest that designs outside this cone are any less useful or valuable. Researchers’ choice of designs is ultimately a matter of their personal preference and competence, and the level of internal and external validity they desire.
Construct validity examines how well a given measurement scale is measuring the theoretical construct that it is expected to measure. Many constructs used in social science research such as empathy, resistance to change, and organizational learning are difficult to define, much less measure. For instance, construct validity must assure that a measure of empathy is indeed measuring empathy and not compassion, which may be difficult since these constructs are somewhat similar in meaning. Construct validity is assessed in positivist research based on correlational or factor analysis of pilot test data, as described in the next chapter.
Statistical conclusion validity examines the extent to which conclusions derived using a statistical procedure is valid. For example, it examines whether the right statistical method was used for hypotheses testing, whether the variables used meet the assumptions of that statistical test (such as sample size or distributional requirements), and so forth. Because interpretive research designs do not employ statistical test, statistical conclusion validity is not applicable for such analysis. The different kinds of validity and where they exist at the theoretical/empirical levels are illustrated in Figure 5.2.
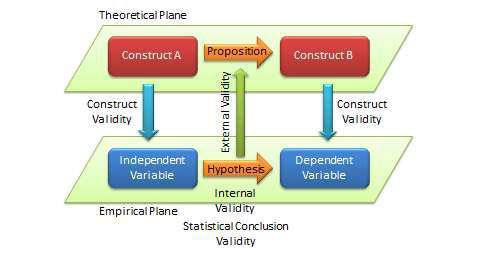
Figure 5.2. Different Types of Validity in Scientific Research
Improving Internal and External Validity
The best research designs are those that can assure high levels of internal and external validity. Such designs would guard against spurious correlations, inspire greater faith in the hypotheses testing, and ensure that the results drawn from a small sample are generalizable to the population at large. Controls are required to assure internal validity (causality) of research designs, and can be accomplished in four ways: (1) manipulation, (2) elimination, (3) inclusion, and (4) statistical control, and (5) randomization.
In manipulation , the researcher manipulates the independent variables in one or more levels (called “treatments”), and compares the effects of the treatments against a control group where subjects do not receive the treatment. Treatments may include a new drug or different dosage of drug (for treating a medical condition), a, a teaching style (for students), and so forth. This type of control is achieved in experimental or quasi-experimental designs but not in non-experimental designs such as surveys. Note that if subjects cannot distinguish adequately between different levels of treatment manipulations, their responses across treatments may not be different, and manipulation would fail.
The elimination technique relies on eliminating extraneous variables by holding them constant across treatments, such as by restricting the study to a single gender or a single socio-economic status. In the inclusion technique, the role of extraneous variables is considered by including them in the research design and separately estimating their effects on the dependent variable, such as via factorial designs where one factor is gender (male versus female). Such technique allows for greater generalizability but also requires substantially larger samples. In statistical control , extraneous variables are measured and used as covariates during the statistical testing process.
Finally, the randomization technique is aimed at canceling out the effects of extraneous variables through a process of random sampling, if it can be assured that these effects are of a random (non-systematic) nature. Two types of randomization are: (1) random selection , where a sample is selected randomly from a population, and (2) random assignment , where subjects selected in a non-random manner are randomly assigned to treatment groups.
Randomization also assures external validity, allowing inferences drawn from the sample to be generalized to the population from which the sample is drawn. Note that random assignment is mandatory when random selection is not possible because of resource or access constraints. However, generalizability across populations is harder to ascertain since populations may differ on multiple dimensions and you can only control for few of those dimensions.
Popular Research Designs
As noted earlier, research designs can be classified into two categories – positivist and interpretive – depending how their goal in scientific research. Positivist designs are meant for theory testing, while interpretive designs are meant for theory building. Positivist designs seek generalized patterns based on an objective view of reality, while interpretive designs seek subjective interpretations of social phenomena from the perspectives of the subjects involved. Some popular examples of positivist designs include laboratory experiments, field experiments, field surveys, secondary data analysis, and case research while examples of interpretive designs include case research, phenomenology, and ethnography. Note that case research can be used for theory building or theory testing, though not at the same time. Not all techniques are suited for all kinds of scientific research. Some techniques such as focus groups are best suited for exploratory research, others such as ethnography are best for descriptive research, and still others such as laboratory experiments are ideal for explanatory research. Following are brief descriptions of some of these designs. Additional details are provided in Chapters 9-12.
Experimental studies are those that are intended to test cause-effect relationships (hypotheses) in a tightly controlled setting by separating the cause from the effect in time, administering the cause to one group of subjects (the “treatment group”) but not to another group (“control group”), and observing how the mean effects vary between subjects in these two groups. For instance, if we design a laboratory experiment to test the efficacy of a new drug in treating a certain ailment, we can get a random sample of people afflicted with that ailment, randomly assign them to one of two groups (treatment and control groups), administer the drug to subjects in the treatment group, but only give a placebo (e.g., a sugar pill with no medicinal value). More complex designs may include multiple treatment groups, such as low versus high dosage of the drug, multiple treatments, such as combining drug administration with dietary interventions. In a true experimental design , subjects must be randomly assigned between each group. If random assignment is not followed, then the design becomes quasi-experimental . Experiments can be conducted in an artificial or laboratory setting such as at a university (laboratory experiments) or in field settings such as in an organization where the phenomenon of interest is actually occurring (field experiments). Laboratory experiments allow the researcher to isolate the variables of interest and control for extraneous variables, which may not be possible in field experiments. Hence, inferences drawn from laboratory experiments tend to be stronger in internal validity, but those from field experiments tend to be stronger in external validity. Experimental data is analyzed using quantitative statistical techniques. The primary strength of the experimental design is its strong internal validity due to its ability to isolate, control, and intensively examine a small number of variables, while its primary weakness is limited external generalizability since real life is often more complex (i.e., involve more extraneous variables) than contrived lab settings. Furthermore, if the research does not identify ex ante relevant extraneous variables and control for such variables, such lack of controls may hurt internal validity and may lead to spurious correlations.
Field surveys are non-experimental designs that do not control for or manipulate independent variables or treatments, but measure these variables and test their effects using statistical methods. Field surveys capture snapshots of practices, beliefs, or situations from a random sample of subjects in field settings through a survey questionnaire or less frequently, through a structured interview. In cross-sectional field surveys , independent and dependent variables are measured at the same point in time (e.g., using a single questionnaire), while in longitudinal field surveys , dependent variables are measured at a later point in time than the independent variables. The strengths of field surveys are their external validity (since data is collected in field settings), their ability to capture and control for a large number of variables, and their ability to study a problem from multiple perspectives or using multiple theories. However, because of their non-temporal nature, internal validity (cause-effect relationships) are difficult to infer, and surveys may be subject to respondent biases (e.g., subjects may provide a “socially desirable” response rather than their true response) which further hurts internal validity.
Secondary data analysis is an analysis of data that has previously been collected and tabulated by other sources. Such data may include data from government agencies such as employment statistics from the U.S. Bureau of Labor Services or development statistics by country from the United Nations Development Program, data collected by other researchers (often used in meta-analytic studies), or publicly available third-party data, such as financial data from stock markets or real-time auction data from eBay. This is in contrast to most other research designs where collecting primary data for research is part of the researcher’s job.
Secondary data analysis may be an effective means of research where primary data collection is too costly or infeasible, and secondary data is available at a level of analysis suitable for answering the researcher’s questions. The limitations of this design are that the data might not have been collected in a systematic or scientific manner and hence unsuitable for scientific research, since the data was collected for a presumably different purpose, they may not adequately address the research questions of interest to the researcher, and interval validity is problematic if the temporal precedence between cause and effect is unclear.
Case research is an in-depth investigation of a problem in one or more real-life settings (case sites) over an extended period of time. Data may be collected using a combination of interviews, personal observations, and internal or external documents. Case studies can be positivist in nature (for hypotheses testing) or interpretive (for theory building). The strength of this research method is its ability to discover a wide variety of social, cultural, and political factors potentially related to the phenomenon of interest that may not be known in advance. Analysis tends to be qualitative in nature, but heavily contextualized and nuanced. However, interpretation of findings may depend on the observational and integrative ability of the researcher, lack of control may make it difficult to establish causality, and findings from a single case site may not be readily generalized to other case sites. Generalizability can be improved by replicating and comparing the analysis in other case sites in a multiple case design .
Focus group research is a type of research that involves bringing in a small group of subjects (typically 6 to 10 people) at one location, and having them discuss a phenomenon of interest for a period of 1.5 to 2 hours. The discussion is moderated and led by a trained facilitator, who sets the agenda and poses an initial set of questions for participants, makes sure that ideas and experiences of all participants are represented, and attempts to build a holistic understanding of the problem situation based on participants’ comments and experiences.
Internal validity cannot be established due to lack of controls and the findings may not be generalized to other settings because of small sample size. Hence, focus groups are not generally used for explanatory or descriptive research, but are more suited for exploratory research.
Action research assumes that complex social phenomena are best understood by introducing interventions or “actions” into those phenomena and observing the effects of those actions. In this method, the researcher is usually a consultant or an organizational member embedded within a social context such as an organization, who initiates an action such as new organizational procedures or new technologies, in response to a real problem such as declining profitability or operational bottlenecks. The researcher’s choice of actions must be based on theory, which should explain why and how such actions may cause the desired change. The researcher then observes the results of that action, modifying it as necessary, while simultaneously learning from the action and generating theoretical insights about the target problem and interventions. The initial theory is validated by the extent to which the chosen action successfully solves the target problem. Simultaneous problem solving and insight generation is the central feature that distinguishes action research from all other research methods, and hence, action research is an excellent method for bridging research and practice. This method is also suited for studying unique social problems that cannot be replicated outside that context, but it is also subject to researcher bias and subjectivity, and the generalizability of findings is often restricted to the context where the study was conducted.
Ethnography is an interpretive research design inspired by anthropology that emphasizes that research phenomenon must be studied within the context of its culture. The researcher is deeply immersed in a certain culture over an extended period of time (8 months to 2 years), and during that period, engages, observes, and records the daily life of the studied culture, and theorizes about the evolution and behaviors in that culture. Data is collected primarily via observational techniques, formal and informal interaction with participants in that culture, and personal field notes, while data analysis involves “sense-making”. The researcher must narrate her experience in great detail so that readers may experience that same culture without necessarily being there. The advantages of this approach are its sensitiveness to the context, the rich and nuanced understanding it generates, and minimal respondent bias. However, this is also an extremely time and resource-intensive approach, and findings are specific to a given culture and less generalizable to other cultures.
Selecting Research Designs
Given the above multitude of research designs, which design should researchers choose for their research? Generally speaking, researchers tend to select those research designs that they are most comfortable with and feel most competent to handle, but ideally, the choice should depend on the nature of the research phenomenon being studied. In the preliminary phases of research, when the research problem is unclear and the researcher wants to scope out the nature and extent of a certain research problem, a focus group (for individual unit of analysis) or a case study (for organizational unit of analysis) is an ideal strategy for exploratory research. As one delves further into the research domain, but finds that there are no good theories to explain the phenomenon of interest and wants to build a theory to fill in the unmet gap in that area, interpretive designs such as case research or ethnography may be useful designs. If competing theories exist and the researcher wishes to test these different theories or integrate them into a larger theory, positivist designs such as experimental design, survey research, or secondary data analysis are more appropriate.
Regardless of the specific research design chosen, the researcher should strive to collect quantitative and qualitative data using a combination of techniques such as questionnaires, interviews, observations, documents, or secondary data. For instance, even in a highly structured survey questionnaire, intended to collect quantitative data, the researcher may leave some room for a few open-ended questions to collect qualitative data that may generate unexpected insights not otherwise available from structured quantitative data alone. Likewise, while case research employ mostly face-to-face interviews to collect most qualitative data, the potential and value of collecting quantitative data should not be ignored. As an example, in a study of organizational decision making processes, the case interviewer can record numeric quantities such as how many months it took to make certain organizational decisions, how many people were involved in that decision process, and how many decision alternatives were considered, which can provide valuable insights not otherwise available from interviewees’ narrative responses. Irrespective of the specific research design employed, the goal of the researcher should be to collect as much and as diverse data as possible that can help generate the best possible insights about the phenomenon of interest.
- Social Science Research: Principles, Methods, and Practices. Authored by : Anol Bhattacherjee. Provided by : University of South Florida. Located at : http://scholarcommons.usf.edu/oa_textbooks/3/ . License : CC BY-NC-SA: Attribution-NonCommercial-ShareAlike
IMAGES
VIDEO
COMMENTS
A research design is a strategy for answering your research question using empirical data. Creating a research design means making decisions about: Your overall research objectives and approach. Whether you'll rely on primary research or secondary research. Your sampling methods or criteria for selecting subjects. Your data collection methods.
Introduction. In clinical research, our aim is to design a study, which would be able to derive a valid and meaningful scientific conclusion using appropriate statistical methods that can be translated to the "real world" setting. 1 Before choosing a study design, one must establish aims and objectives of the study, and choose an appropriate target population that is most representative of ...
A research design is a strategy for answering your research question using empirical data. Creating a research design means making decisions about: ... Test the effectiveness of a new treatment, program, or product; ... You can use this type of research to measure learning outcomes like grades and test scores.
In a between-subjects design (also known as an independent measures design or classic ANOVA design), individuals receive only one of the possible levels of an experimental treatment. In medical or social research, you might also use matched pairs within your between-subjects design to make sure that each treatment group contains the same ...
Research design: The research design will be a quasi-experimental design, with a pretest-posttest control group design. ... Health sciences: In the health sciences, research design is used to investigate the causes, prevention, and treatment of diseases. Researchers use various designs, such as randomized controlled trials, cohort studies, and ...
Three types of experimental designs are commonly used: 1. Independent Measures. Independent measures design, also known as between-groups, is an experimental design where different participants are used in each condition of the independent variable. This means that each condition of the experiment includes a different group of participants.
Repeated Measures Design. In this design, each participant is exposed to all of the different treatments or conditions, either in a random order or in a predetermined order. ... When studying the effects of a new drug or medical treatment: Experimental research design is commonly used in medical research to test the effectiveness and safety of ...
Research design is a comprehensive plan for data collection in an empirical research project. It is a 'blueprint' for empirical research aimed at answering specific research questions or testing specific hypotheses, and must specify at least three processes: the data collection process, the instrument development process, and the sampling process.
Single-case Research Designs. Single-case research designs (SCDs; single-subject, single-participant, n=1, intra-subject designs) include the repeated observation of outcomes (dependent variables) across time under different levels of at least one intervention (manipulated independent variable. 7 These studies include phases that can vary in length from minutes to months or longer during which ...
Random assignment is a method for assigning participants in a sample to the different conditions, and it is an important element of all experimental research in psychology and other fields too. In its strictest sense, random assignment should meet two criteria. One is that each participant has an equal chance of being assigned to each condition ...
Abstract. Single-case experimental designs (SCEDs) represent a family of research designs that use experimental methods to study the effects of treatments on outcomes. The fundamental unit of analysis is the single case—which can be an individual, clinic, or community—ideally with replications of effects within and/or between cases.
Research design is the first methodological issue a clinical social worker must identify in appraising the quality of a research study. ... and O 2 stands for the posttest, done after treatment, but using the same measure. More than two groups may be included in a quasi-experimental study. There may also be additional follow-up posttests to ...
Experimental treatment and intervention mean the same thing. The outcome measure is the experience of measuring the outcome variable. In our example, the outcome variable is academic performance. Group Comparison. Experimental design often focuses on comparing groups.
Study design selection is influenced by factors such as objectives, therapeutic area, treatment comparison, outcome, and trial phase [8].The study design can be broadly classified into ...
Anastas, Jeane W. Research Design for Social Work and the Human Services. Chapter 7, Flexible Methods: Experimental Research. 2nd ed. New York: Columbia University Press, 1999; Chapter 2: Research Design, Experimental Designs. School of Psychology, University of New England, 2000; Experimental Research. Research Methods by Dummies.
The study design is usually a randomized, controlled study to rigorously test the treatment, comparing it to either no-treat-ment, treatment-as-usual in the community, or an existing alternative treatment with known efficacy (e.g., in the field of addictions, comparing a new treatment to 12-step drug counseling).
Treatment satisfaction is a person's rating of his or her treatment experience, including processes and outcomes. It is directly related to treatment adherence, which may be predictive of treatment effectiveness in clinical and real-world research. Consequently, patient-reported outcome (PRO) instruments have been developed to incorporate patient experience throughout various stages of drug ...
2. What measures should be used? The choice of measure will depend on the study design or indeed evaluation framework used as well as the objectives of the evaluation. For example, the Donabedian approach considers a programme or intervention in terms of inputs, process, outputs and outcomes.
Repeated measures designs, also known as a within-subjects designs, can seem like oddball experiments. When you think of a typical experiment, you probably picture an experimental design that uses mutually exclusive, independent groups. These experiments have a control group and treatment groups that have clear divisions between them.
Random assignment is a method for assigning participants in a sample to the different conditions, and it is an important element of all experimental research in psychology and other fields too. In its strictest sense, random assignment should meet two criteria. One is that each participant has an equal chance of being assigned to each condition ...
In the fourth piece of this series on research study designs, we look at interventional studies (clinical trials). These studies differ from observational studies in that the investigator decides whether or not a participant will receive the exposure (or intervention). In this article, we describe the key features and types of interventional ...
Furthermore, these methods would require at a minimum to have measures of preintervention (baseline), postintervention, and follow-up data. ... (2005), contamination is a violation of the stable unit treatment value assumption, which posits that for RCTs to work, the actions of one ... Research design: Qualitative, quantitative, and mixed ...
A research design in which the different groups of scores are all obtained from the same group of participants. Also known as repeated-measures design. independent-measures t statistic. In a between-subjects design, a hypothesis test that evaluates the statistical significance of the mean difference between two separate groups of participants.
One example of research that has bridged the divide between science and policy is the Recovery After an Initial Schizophrenia Episode, or RAISE, studies. Research has shown that young people with schizophrenia and related psychotic disorders have much better outcomes when they receive effective treatment within months of their first symptoms.
Objectives: This study was part of a process evaluation for a single‐blind, randomized controlled pilot study comparing Better Conversations with Primary Progressive Aphasia (BCPPA), an approach to communication partner training, with no speech and language therapy treatment. It was necessary to explore fidelity of delivery (delivery of intervention components) and intervention enactment ...
This study aimed to explore the efficacy of algorithm-based modular psychotherapy (MoBa), a combination of CBT and mindfulness meditation as validated by the research domain criteria (RDoC), in reducing anxiety and neuroinflammation in GAD. A longitudinal design was used, with 50 patients with GAD undergoing a 12-week MoBa treatment.
NIMH-supported research showed that universal suicide risk screening paired with follow-up interventions can reduce suicide risk. Intramural researchers at NIMH have developed a suicide risk screening toolkit to support screening in health care settings. Research continues to build on these advances, translating science into clinical practice.
Pet cats may be excellent animal models for the study of obesity origins and treatment in humans, a new study of feline gut microbes suggests - and both species would likely get healthier in the research process, scientists say. Veterinary researchers analyzed fecal samples from fat cats as the animals lost and maintained weight over the cours...
Objective To assess the impact of publication of UK National Institute for Health and Care Excellence (NICE) guidelines on the prevention and treatment of early-onset infections (EOIs) in neonates (clinical guideline 149 (CG149), published in 2012, and its 2021 update (NG195) on antibiotic use in very preterm infants. Design Interrupted time series analysis using data from the National ...
Chapter 5 Research Design. Research design is a comprehensive plan for data collection in an empirical research project. It is a "blueprint" for empirical research aimed at answering specific research questions or testing specific hypotheses, and must specify at least three processes: (1) the data collection process, (2) the instrument ...