 quizlet")
- school Campus Bookshelves
- menu_book Bookshelves
- perm_media Learning Objects
- login Login
- how_to_reg Request Instructor Account
- hub Instructor Commons

Margin Size
- Download Page (PDF)
- Download Full Book (PDF)
- Periodic Table
- Physics Constants
- Scientific Calculator
- Reference & Cite
- Tools expand_more
- Readability
selected template will load here
This action is not available.
6: Research Design
- Last updated
- Save as PDF
- Page ID 2116

- Rice University
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
A research design is the set of methods and procedures used in collecting and analyzing measures of the variables specified in the research problem research. The design of a study defines the study type (descriptive, correlational, semi-experimental, experimental, review, meta-analytic) and sub-type (e.g., descriptive-longitudinal case study), research problem, hypotheses, independent and dependent variables, experimental design, and, if applicable, data collection methods and a statistical analysis plan. Research design is the framework that has been created to find answers to research questions.
- 6.1: Scientific Method To be a proper scientific investigation the data must be collected systematically. However, scientific investigation does not necessarily require experimentation in the sense of manipulating variables and observing the results. Observational studies in the fields of astronomy, developmental psychology, and ethology are common and provide valuable scientific information.
- 6.2: Measurement The collection of data involves measurement. Measurement of some characteristics such as height and weight are relatively straightforward. The measurement of psychological attributes such as self esteem can be complex. A good measurement scale should be both reliable and valid. These concepts will be discussed in turn.
- 6.3: Data Collection Most statistical analyses require that your data be in numerical rather than verbal form (you can’t punch letters into your calculator). Therefore, data collected in verbal form must be coded so that it is represented by numbers.
- 6.4: Sampling Bias Descriptions of various types of sampling such as simple random sampling and stratified random sampling are covered in another section. This section discusses various types of sampling biases including self-selection bias and survivorship bias. Examples of other sampling biases that are not easily categorized will also be given. It is important to keep in mind that sampling bias refers to the method of sampling, not the sample itself.
- 6.5: Experimental Designs There are many ways an experiment can be designed. For example, subjects can all be tested under each of the treatment conditions or a different group of subjects can be used for each treatment. An experiment might have just one independent variable or it might have several. This section describes basic experimental designs and their advantages and disadvantages.
- 6.6: Causation The concept of causation is a complex one in the philosophy of science. Since a full coverage of this topic is well beyond the scope of this text, we focus on two specific topics: (1) the establishment of causation in experiments and (2) the establishment of causation in non-experimental designs.
- 6.7: Statistical Literacy A low level of HDL have long been known to be a risk factor for heart disease. Taking niacin has been shown to increase HDL levels and has been recommended for patients with low levels of HDL. The assumption of this recommendation is that niacin causes HDL to increase thus causing a lower risk for heart disease. What experimental design involving niacin would test whether the relationship between HDL and heart disease is causal?
- 6.E: Research Design (Exercises)
Flowchart of four phases (enrollment, intervention allocation, follow-up, and data analysis) of a parallel randomized trial of two groups. Image use with permission (CC BYT-SA 3.0; PrevMedFellow ).
Contributors and Attributions
Online Statistics Education: A Multimedia Course of Study ( http://onlinestatbook.com/ ). Project Leader: David M. Lane, Rice University.
Chapter 5 Research Design
Research design is a comprehensive plan for data collection in an empirical research project. It is a “blueprint” for empirical research aimed at answering specific research questions or testing specific hypotheses, and must specify at least three processes: (1) the data collection process, (2) the instrument development process, and (3) the sampling process. The instrument development and sampling processes are described in next two chapters, and the data collection process (which is often loosely called “research design”) is introduced in this chapter and is described in further detail in Chapters 9-12.
Broadly speaking, data collection methods can be broadly grouped into two categories: positivist and interpretive. Positivist methods , such as laboratory experiments and survey research, are aimed at theory (or hypotheses) testing, while interpretive methods, such as action research and ethnography, are aimed at theory building. Positivist methods employ a deductive approach to research, starting with a theory and testing theoretical postulates using empirical data. In contrast, interpretive methods employ an inductive approach that starts with data and tries to derive a theory about the phenomenon of interest from the observed data. Often times, these methods are incorrectly equated with quantitative and qualitative research. Quantitative and qualitative methods refers to the type of data being collected (quantitative data involve numeric scores, metrics, and so on, while qualitative data includes interviews, observations, and so forth) and analyzed (i.e., using quantitative techniques such as regression or qualitative techniques such as coding). Positivist research uses predominantly quantitative data, but can also use qualitative data. Interpretive research relies heavily on qualitative data, but can sometimes benefit from including quantitative data as well. Sometimes, joint use of qualitative and quantitative data may help generate unique insight into a complex social phenomenon that are not available from either types of data alone, and hence, mixed-mode designs that combine qualitative and quantitative data are often highly desirable.
Key Attributes of a Research Design
The quality of research designs can be defined in terms of four key design attributes: internal validity, external validity, construct validity, and statistical conclusion validity.
Internal validity , also called causality, examines whether the observed change in a dependent variable is indeed caused by a corresponding change in hypothesized independent variable, and not by variables extraneous to the research context. Causality requires three conditions: (1) covariation of cause and effect (i.e., if cause happens, then effect also happens; and if cause does not happen, effect does not happen), (2) temporal precedence: cause must precede effect in time, (3) no plausible alternative explanation (or spurious correlation). Certain research designs, such as laboratory experiments, are strong in internal validity by virtue of their ability to manipulate the independent variable (cause) via a treatment and observe the effect (dependent variable) of that treatment after a certain point in time, while controlling for the effects of extraneous variables. Other designs, such as field surveys, are poor in internal validity because of their inability to manipulate the independent variable (cause), and because cause and effect are measured at the same point in time which defeats temporal precedence making it equally likely that the expected effect might have influenced the expected cause rather than the reverse. Although higher in internal validity compared to other methods, laboratory experiments are, by no means, immune to threats of internal validity, and are susceptible to history, testing, instrumentation, regression, and other threats that are discussed later in the chapter on experimental designs. Nonetheless, different research designs vary considerably in their respective level of internal validity.
External validity or generalizability refers to whether the observed associations can be generalized from the sample to the population (population validity), or to other people, organizations, contexts, or time (ecological validity). For instance, can results drawn from a sample of financial firms in the United States be generalized to the population of financial firms (population validity) or to other firms within the United States (ecological validity)? Survey research, where data is sourced from a wide variety of individuals, firms, or other units of analysis, tends to have broader generalizability than laboratory experiments where artificially contrived treatments and strong control over extraneous variables render the findings less generalizable to real-life settings where treatments and extraneous variables cannot be controlled. The variation in internal and external validity for a wide range of research designs are shown in Figure 5.1.
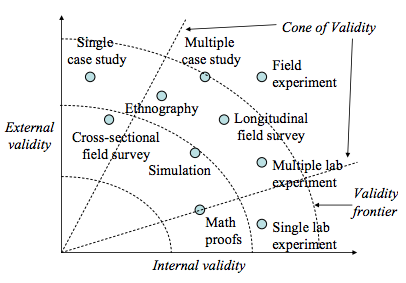
Figure 5.1. Internal and external validity.
Some researchers claim that there is a tradeoff between internal and external validity: higher external validity can come only at the cost of internal validity and vice-versa. But this is not always the case. Research designs such as field experiments, longitudinal field surveys, and multiple case studies have higher degrees of both internal and external validities. Personally, I prefer research designs that have reasonable degrees of both internal and external validities, i.e., those that fall within the cone of validity shown in Figure 5.1. But this should not suggest that designs outside this cone are any less useful or valuable. Researchers’ choice of designs is ultimately a matter of their personal preference and competence, and the level of internal and external validity they desire.
Construct validity examines how well a given measurement scale is measuring the theoretical construct that it is expected to measure. Many constructs used in social science research such as empathy, resistance to change, and organizational learning are difficult to define, much less measure. For instance, construct validity must assure that a measure of empathy is indeed measuring empathy and not compassion, which may be difficult since these constructs are somewhat similar in meaning. Construct validity is assessed in positivist research based on correlational or factor analysis of pilot test data, as described in the next chapter.
Statistical conclusion validity examines the extent to which conclusions derived using a statistical procedure is valid. For example, it examines whether the right statistical method was used for hypotheses testing, whether the variables used meet the assumptions of that statistical test (such as sample size or distributional requirements), and so forth. Because interpretive research designs do not employ statistical test, statistical conclusion validity is not applicable for such analysis. The different kinds of validity and where they exist at the theoretical/empirical levels are illustrated in Figure 5.2.
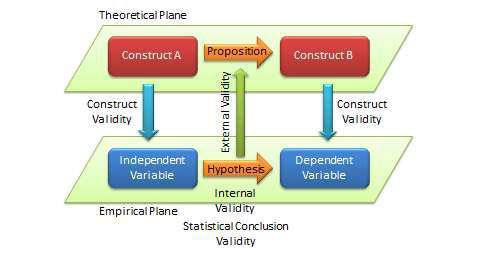
Figure 5.2. Different Types of Validity in Scientific Research
Improving Internal and External Validity
The best research designs are those that can assure high levels of internal and external validity. Such designs would guard against spurious correlations, inspire greater faith in the hypotheses testing, and ensure that the results drawn from a small sample are generalizable to the population at large. Controls are required to assure internal validity (causality) of research designs, and can be accomplished in four ways: (1) manipulation, (2) elimination, (3) inclusion, and (4) statistical control, and (5) randomization.
In manipulation , the researcher manipulates the independent variables in one or more levels (called “treatments”), and compares the effects of the treatments against a control group where subjects do not receive the treatment. Treatments may include a new drug or different dosage of drug (for treating a medical condition), a, a teaching style (for students), and so forth. This type of control is achieved in experimental or quasi-experimental designs but not in non-experimental designs such as surveys. Note that if subjects cannot distinguish adequately between different levels of treatment manipulations, their responses across treatments may not be different, and manipulation would fail.
The elimination technique relies on eliminating extraneous variables by holding them constant across treatments, such as by restricting the study to a single gender or a single socio-economic status. In the inclusion technique, the role of extraneous variables is considered by including them in the research design and separately estimating their effects on the dependent variable, such as via factorial designs where one factor is gender (male versus female). Such technique allows for greater generalizability but also requires substantially larger samples. In statistical control , extraneous variables are measured and used as covariates during the statistical testing process.
Finally, the randomization technique is aimed at canceling out the effects of extraneous variables through a process of random sampling, if it can be assured that these effects are of a random (non-systematic) nature. Two types of randomization are: (1) random selection , where a sample is selected randomly from a population, and (2) random assignment , where subjects selected in a non-random manner are randomly assigned to treatment groups.
Randomization also assures external validity, allowing inferences drawn from the sample to be generalized to the population from which the sample is drawn. Note that random assignment is mandatory when random selection is not possible because of resource or access constraints. However, generalizability across populations is harder to ascertain since populations may differ on multiple dimensions and you can only control for few of those dimensions.
Popular Research Designs
As noted earlier, research designs can be classified into two categories – positivist and interpretive – depending how their goal in scientific research. Positivist designs are meant for theory testing, while interpretive designs are meant for theory building. Positivist designs seek generalized patterns based on an objective view of reality, while interpretive designs seek subjective interpretations of social phenomena from the perspectives of the subjects involved. Some popular examples of positivist designs include laboratory experiments, field experiments, field surveys, secondary data analysis, and case research while examples of interpretive designs include case research, phenomenology, and ethnography. Note that case research can be used for theory building or theory testing, though not at the same time. Not all techniques are suited for all kinds of scientific research. Some techniques such as focus groups are best suited for exploratory research, others such as ethnography are best for descriptive research, and still others such as laboratory experiments are ideal for explanatory research. Following are brief descriptions of some of these designs. Additional details are provided in Chapters 9-12.
Experimental studies are those that are intended to test cause-effect relationships (hypotheses) in a tightly controlled setting by separating the cause from the effect in time, administering the cause to one group of subjects (the “treatment group”) but not to another group (“control group”), and observing how the mean effects vary between subjects in these two groups. For instance, if we design a laboratory experiment to test the efficacy of a new drug in treating a certain ailment, we can get a random sample of people afflicted with that ailment, randomly assign them to one of two groups (treatment and control groups), administer the drug to subjects in the treatment group, but only give a placebo (e.g., a sugar pill with no medicinal value). More complex designs may include multiple treatment groups, such as low versus high dosage of the drug, multiple treatments, such as combining drug administration with dietary interventions. In a true experimental design , subjects must be randomly assigned between each group. If random assignment is not followed, then the design becomes quasi-experimental . Experiments can be conducted in an artificial or laboratory setting such as at a university (laboratory experiments) or in field settings such as in an organization where the phenomenon of interest is actually occurring (field experiments). Laboratory experiments allow the researcher to isolate the variables of interest and control for extraneous variables, which may not be possible in field experiments. Hence, inferences drawn from laboratory experiments tend to be stronger in internal validity, but those from field experiments tend to be stronger in external validity. Experimental data is analyzed using quantitative statistical techniques. The primary strength of the experimental design is its strong internal validity due to its ability to isolate, control, and intensively examine a small number of variables, while its primary weakness is limited external generalizability since real life is often more complex (i.e., involve more extraneous variables) than contrived lab settings. Furthermore, if the research does not identify ex ante relevant extraneous variables and control for such variables, such lack of controls may hurt internal validity and may lead to spurious correlations.
Field surveys are non-experimental designs that do not control for or manipulate independent variables or treatments, but measure these variables and test their effects using statistical methods. Field surveys capture snapshots of practices, beliefs, or situations from a random sample of subjects in field settings through a survey questionnaire or less frequently, through a structured interview. In cross-sectional field surveys , independent and dependent variables are measured at the same point in time (e.g., using a single questionnaire), while in longitudinal field surveys , dependent variables are measured at a later point in time than the independent variables. The strengths of field surveys are their external validity (since data is collected in field settings), their ability to capture and control for a large number of variables, and their ability to study a problem from multiple perspectives or using multiple theories. However, because of their non-temporal nature, internal validity (cause-effect relationships) are difficult to infer, and surveys may be subject to respondent biases (e.g., subjects may provide a “socially desirable” response rather than their true response) which further hurts internal validity.
Secondary data analysis is an analysis of data that has previously been collected and tabulated by other sources. Such data may include data from government agencies such as employment statistics from the U.S. Bureau of Labor Services or development statistics by country from the United Nations Development Program, data collected by other researchers (often used in meta-analytic studies), or publicly available third-party data, such as financial data from stock markets or real-time auction data from eBay. This is in contrast to most other research designs where collecting primary data for research is part of the researcher’s job.
Secondary data analysis may be an effective means of research where primary data collection is too costly or infeasible, and secondary data is available at a level of analysis suitable for answering the researcher’s questions. The limitations of this design are that the data might not have been collected in a systematic or scientific manner and hence unsuitable for scientific research, since the data was collected for a presumably different purpose, they may not adequately address the research questions of interest to the researcher, and interval validity is problematic if the temporal precedence between cause and effect is unclear.
Case research is an in-depth investigation of a problem in one or more real-life settings (case sites) over an extended period of time. Data may be collected using a combination of interviews, personal observations, and internal or external documents. Case studies can be positivist in nature (for hypotheses testing) or interpretive (for theory building). The strength of this research method is its ability to discover a wide variety of social, cultural, and political factors potentially related to the phenomenon of interest that may not be known in advance. Analysis tends to be qualitative in nature, but heavily contextualized and nuanced. However, interpretation of findings may depend on the observational and integrative ability of the researcher, lack of control may make it difficult to establish causality, and findings from a single case site may not be readily generalized to other case sites. Generalizability can be improved by replicating and comparing the analysis in other case sites in a multiple case design .
Focus group research is a type of research that involves bringing in a small group of subjects (typically 6 to 10 people) at one location, and having them discuss a phenomenon of interest for a period of 1.5 to 2 hours. The discussion is moderated and led by a trained facilitator, who sets the agenda and poses an initial set of questions for participants, makes sure that ideas and experiences of all participants are represented, and attempts to build a holistic understanding of the problem situation based on participants’ comments and experiences.
Internal validity cannot be established due to lack of controls and the findings may not be generalized to other settings because of small sample size. Hence, focus groups are not generally used for explanatory or descriptive research, but are more suited for exploratory research.
Action research assumes that complex social phenomena are best understood by introducing interventions or “actions” into those phenomena and observing the effects of those actions. In this method, the researcher is usually a consultant or an organizational member embedded within a social context such as an organization, who initiates an action such as new organizational procedures or new technologies, in response to a real problem such as declining profitability or operational bottlenecks. The researcher’s choice of actions must be based on theory, which should explain why and how such actions may cause the desired change. The researcher then observes the results of that action, modifying it as necessary, while simultaneously learning from the action and generating theoretical insights about the target problem and interventions. The initial theory is validated by the extent to which the chosen action successfully solves the target problem. Simultaneous problem solving and insight generation is the central feature that distinguishes action research from all other research methods, and hence, action research is an excellent method for bridging research and practice. This method is also suited for studying unique social problems that cannot be replicated outside that context, but it is also subject to researcher bias and subjectivity, and the generalizability of findings is often restricted to the context where the study was conducted.
Ethnography is an interpretive research design inspired by anthropology that emphasizes that research phenomenon must be studied within the context of its culture. The researcher is deeply immersed in a certain culture over an extended period of time (8 months to 2 years), and during that period, engages, observes, and records the daily life of the studied culture, and theorizes about the evolution and behaviors in that culture. Data is collected primarily via observational techniques, formal and informal interaction with participants in that culture, and personal field notes, while data analysis involves “sense-making”. The researcher must narrate her experience in great detail so that readers may experience that same culture without necessarily being there. The advantages of this approach are its sensitiveness to the context, the rich and nuanced understanding it generates, and minimal respondent bias. However, this is also an extremely time and resource-intensive approach, and findings are specific to a given culture and less generalizable to other cultures.
Selecting Research Designs
Given the above multitude of research designs, which design should researchers choose for their research? Generally speaking, researchers tend to select those research designs that they are most comfortable with and feel most competent to handle, but ideally, the choice should depend on the nature of the research phenomenon being studied. In the preliminary phases of research, when the research problem is unclear and the researcher wants to scope out the nature and extent of a certain research problem, a focus group (for individual unit of analysis) or a case study (for organizational unit of analysis) is an ideal strategy for exploratory research. As one delves further into the research domain, but finds that there are no good theories to explain the phenomenon of interest and wants to build a theory to fill in the unmet gap in that area, interpretive designs such as case research or ethnography may be useful designs. If competing theories exist and the researcher wishes to test these different theories or integrate them into a larger theory, positivist designs such as experimental design, survey research, or secondary data analysis are more appropriate.
Regardless of the specific research design chosen, the researcher should strive to collect quantitative and qualitative data using a combination of techniques such as questionnaires, interviews, observations, documents, or secondary data. For instance, even in a highly structured survey questionnaire, intended to collect quantitative data, the researcher may leave some room for a few open-ended questions to collect qualitative data that may generate unexpected insights not otherwise available from structured quantitative data alone. Likewise, while case research employ mostly face-to-face interviews to collect most qualitative data, the potential and value of collecting quantitative data should not be ignored. As an example, in a study of organizational decision making processes, the case interviewer can record numeric quantities such as how many months it took to make certain organizational decisions, how many people were involved in that decision process, and how many decision alternatives were considered, which can provide valuable insights not otherwise available from interviewees’ narrative responses. Irrespective of the specific research design employed, the goal of the researcher should be to collect as much and as diverse data as possible that can help generate the best possible insights about the phenomenon of interest.
- Social Science Research: Principles, Methods, and Practices. Authored by : Anol Bhattacherjee. Provided by : University of South Florida. Located at : http://scholarcommons.usf.edu/oa_textbooks/3/ . License : CC BY-NC-SA: Attribution-NonCommercial-ShareAlike
 quizlet")
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Definitions of Research Designs
Systematic reviews & meta-analyses.
- A systematic review critically assesses and evaluates all research that addresses a particular research question and presents a synthesized summary of the literature. The researchers use a systematic methodology to search and screen the literature on a particular topic. Meta-analyses use statistical methods to combine the results of individual studies and synthesize the findings.
- The quality of a systematic review is only as good as the quality of the studies that are included. When evaluating this type of study, you want to assess the methodology of the search strategy and screening of articles to include, and the assessment by the authors of the included studies.
Randomized Controlled Trials (RCT)
- A study design that randomly assigns participants to an experimental group (which receives the intervention) or a control group (which receives either a placebo or no intervention). The only expected difference between the two groups is the variable being studied.
- When critically appraising an RCT, you will evaluate elements of the study such as the allocation of participants, how similar the control group and the experimental group are, and the blinding of the participants and health care workers.
Cohort Studies
- A study type in which people who currently have a certain condition or receive a certain treatment are followed over time and compared with a group of people who are not affected by the condition or treatment.
- When critically appraising a cohort study, you will investigate how the cohort was recruited, if the exposure was accurately measured and bias was minimized, and if authors have identified and taken account of possible confounding factors.
Case Control Studies
- An observational study of people with a disease (or other outcome variable) of interest and a control, comparison, or reference group of people without the disease. The two groups of people are compared to determine what can be attributed to the disease or outcome variable.
- Much like a cohort study, when critically appraising a case series you will examine whether the authors have minimized bias and properly addressed any potential confounding factors.
Some study types are not named on the EBM Pyramid, but are important study designs for answering research questions:
Diagnostic Studies
- This type of research focuses on estimating the sensitivity and/or specificity of a particular diagnostic test, and compares the test to the standard diagnostic test.
- When critically appraising this type of study you will want to determine if the new test was compared with an appropriate standard test, if all patients received both the new test and the standard test, and whether the health care workers administering the tests were properly blinded to the results of the standard test.
Economic Evaluation
- This type of study compares the costs and outcomes of healthcare interventions.
- When critically appraising an economic evaluation, you will determine if there is evidence that the new intervention or program is effective, if the effects of the intervention were measured appropriately, and were the costs valued in a credible manner.
Qualitative Studies
- Qualitative research aims to identify what matters most to patients or populations and how their experience can be improved. In public health, this type of research allows researchers to explore social and behavioral issues and explore other social or human problems.
- Critical appraisal of a qualitative study will determine if there was a clear aim for the research, if the qualitative methodology and research design were appropriate for the aims, and if the data analysis was sufficiently rigorous.
Evidence-Based Practice Copyright © by Various Authors - See Each Chapter Attribution is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.

What Is a Research Design? | Definition, Types & Guide

Introduction
Parts of a research design, types of research methodology in qualitative research, narrative research designs, phenomenological research designs, grounded theory research designs.
- Ethnographic research designs
Case study research design
Important reminders when designing a research study.
A research design in qualitative research is a critical framework that guides the methodological approach to studying complex social phenomena. Qualitative research designs determine how data is collected, analyzed, and interpreted, ensuring that the research captures participants' nuanced and subjective perspectives. Research designs also recognize ethical considerations and involve informed consent, ensuring confidentiality, and handling sensitive topics with the utmost respect and care. These considerations are crucial in qualitative research and other contexts where participants may share personal or sensitive information. A research design should convey coherence as it is essential for producing high-quality qualitative research, often following a recursive and evolving process.

Theoretical concepts and research question
The first step in creating a research design is identifying the main theoretical concepts. To identify these concepts, a researcher should ask which theoretical keywords are implicit in the investigation. The next step is to develop a research question using these theoretical concepts. This can be done by identifying the relationship of interest among the concepts that catch the focus of the investigation. The question should address aspects of the topic that need more knowledge, shed light on new information, and specify which aspects should be prioritized before others. This step is essential in identifying which participants to include or which data collection methods to use. Research questions also put into practice the conceptual framework and make the initial theoretical concepts more explicit. Once the research question has been established, the main objectives of the research can be specified. For example, these objectives may involve identifying shared experiences around a phenomenon or evaluating perceptions of a new treatment.
Methodology
After identifying the theoretical concepts, research question, and objectives, the next step is to determine the methodology that will be implemented. This is the lifeline of a research design and should be coherent with the objectives and questions of the study. The methodology will determine how data is collected, analyzed, and presented. Popular qualitative research methodologies include case studies, ethnography , grounded theory , phenomenology, and narrative research . Each methodology is tailored to specific research questions and facilitates the collection of rich, detailed data. For example, a narrative approach may focus on only one individual and their story, while phenomenology seeks to understand participants' lived common experiences. Qualitative research designs differ significantly from quantitative research, which often involves experimental research, correlational designs, or variance analysis to test hypotheses about relationships between two variables, a dependent variable and an independent variable while controlling for confounding variables.

Literature review
After the methodology is identified, conducting a thorough literature review is integral to the research design. This review identifies gaps in knowledge, positioning the new study within the larger academic dialogue and underlining its contribution and relevance. Meta-analysis, a form of secondary research, can be particularly useful in synthesizing findings from multiple studies to provide a clear picture of the research landscape.
Data collection
The sampling method in qualitative research is designed to delve deeply into specific phenomena rather than to generalize findings across a broader population. The data collection methods—whether interviews, focus groups, observations, or document analysis—should align with the chosen methodology, ethical considerations, and other factors such as sample size. In some cases, repeated measures may be collected to observe changes over time.
Data analysis
Analysis in qualitative research typically involves methods such as coding and thematic analysis to distill patterns from the collected data. This process delineates how the research results will be systematically derived from the data. It is recommended that the researcher ensures that the final interpretations are coherent with the observations and analyses, making clear connections between the data and the conclusions drawn. Reporting should be narrative-rich, offering a comprehensive view of the context and findings.
Overall, a coherent qualitative research design that incorporates these elements facilitates a study that not only adds theoretical and practical value to the field but also adheres to high quality. This methodological thoroughness is essential for achieving significant, insightful findings. Examples of well-executed research designs can be valuable references for other researchers conducting qualitative or quantitative investigations. An effective research design is critical for producing robust and impactful research outcomes.
Each qualitative research design is unique, diverse, and meticulously tailored to answer specific research questions, meet distinct objectives, and explore the unique nature of the phenomenon under investigation. The methodology is the wider framework that a research design follows. Each methodology in a research design consists of methods, tools, or techniques that compile data and analyze it following a specific approach.
The methods enable researchers to collect data effectively across individuals, different groups, or observations, ensuring they are aligned with the research design. The following list includes the most commonly used methodologies employed in qualitative research designs, highlighting how they serve different purposes and utilize distinct methods to gather and analyze data.

The narrative approach in research focuses on the collection and detailed examination of life stories, personal experiences, or narratives to gain insights into individuals' lives as told from their perspectives. It involves constructing a cohesive story out of the diverse experiences shared by participants, often using chronological accounts. It seeks to understand human experience and social phenomena through the form and content of the stories. These can include spontaneous narrations such as memoirs or diaries from participants or diaries solicited by the researcher. Narration helps construct the identity of an individual or a group and can rationalize, persuade, argue, entertain, confront, or make sense of an event or tragedy. To conduct a narrative investigation, it is recommended that researchers follow these steps:
Identify if the research question fits the narrative approach. Its methods are best employed when a researcher wants to learn about the lifestyle and life experience of a single participant or a small number of individuals.
Select the best-suited participants for the research design and spend time compiling their stories using different methods such as observations, diaries, interviewing their family members, or compiling related secondary sources.
Compile the information related to the stories. Narrative researchers collect data based on participants' stories concerning their personal experiences, for example about their workplace or homes, their racial or ethnic culture, and the historical context in which the stories occur.
Analyze the participant stories and "restore" them within a coherent framework. This involves collecting the stories, analyzing them based on key elements such as time, place, plot, and scene, and then rewriting them in a chronological sequence (Ollerenshaw & Creswell, 2000). The framework may also include elements such as a predicament, conflict, or struggle; a protagonist; and a sequence with implicit causality, where the predicament is somehow resolved (Carter, 1993).
Collaborate with participants by actively involving them in the research. Both the researcher and the participant negotiate the meaning of their stories, adding a credibility check to the analysis (Creswell & Miller, 2000).
A narrative investigation includes collecting a large amount of data from the participants and the researcher needs to understand the context of the individual's life. A keen eye is needed to collect particular stories that capture the individual experiences. Active collaboration with the participant is necessary, and researchers need to discuss and reflect on their own beliefs and backgrounds. Multiple questions could arise in the collection, analysis, and storytelling of individual stories that need to be addressed, such as: Whose story is it? Who can tell it? Who can change it? Which version is compelling? What happens when narratives compete? In a community, what do the stories do among them? (Pinnegar & Daynes, 2006).

Make the most of your data with ATLAS.ti
Powerful tools in an intuitive interface, ready for you with a free trial today.
A research design based on phenomenology aims to understand the essence of the lived experiences of a group of people regarding a particular concept or phenomenon. Researchers gather deep insights from individuals who have experienced the phenomenon, striving to describe "what" they experienced and "how" they experienced it. This approach to a research design typically involves detailed interviews and aims to reach a deep existential understanding. The purpose is to reduce individual experiences to a description of the universal essence or understanding the phenomenon's nature (van Manen, 1990). In phenomenology, the following steps are usually followed:
Identify a phenomenon of interest . For example, the phenomenon might be anger, professionalism in the workplace, or what it means to be a fighter.
Recognize and specify the philosophical assumptions of phenomenology , for example, one could reflect on the nature of objective reality and individual experiences.
Collect data from individuals who have experienced the phenomenon . This typically involves conducting in-depth interviews, including multiple sessions with each participant. Additionally, other forms of data may be collected using several methods, such as observations, diaries, art, poetry, music, recorded conversations, written responses, or other secondary sources.
Ask participants two general questions that encompass the phenomenon and how the participant experienced it (Moustakas, 1994). For example, what have you experienced in this phenomenon? And what contexts or situations have typically influenced your experiences within the phenomenon? Other open-ended questions may also be asked, but these two questions particularly focus on collecting research data that will lead to a textural description and a structural description of the experiences, and ultimately provide an understanding of the common experiences of the participants.
Review data from the questions posed to participants . It is recommended that researchers review the answers and highlight "significant statements," phrases, or quotes that explain how participants experienced the phenomenon. The researcher can then develop meaningful clusters from these significant statements into patterns or key elements shared across participants.
Write a textual description of what the participants experienced based on the answers and themes of the two main questions. The answers are also used to write about the characteristics and describe the context that influenced the way the participants experienced the phenomenon, called imaginative variation or structural description. Researchers should also write about their own experiences and context or situations that influenced them.
Write a composite description from the structural and textural description that presents the "essence" of the phenomenon, called the essential and invariant structure.
A phenomenological approach to a research design includes the strict and careful selection of participants in the study where bracketing personal experiences can be difficult to implement. The researcher decides how and in which way their knowledge will be introduced. It also involves some understanding and identification of the broader philosophical assumptions.

Grounded theory is used in a research design when the goal is to inductively develop a theory "grounded" in data that has been systematically gathered and analyzed. Starting from the data collection, researchers identify characteristics, patterns, themes, and relationships, gradually forming a theoretical framework that explains relevant processes, actions, or interactions grounded in the observed reality. A grounded theory study goes beyond descriptions and its objective is to generate a theory, an abstract analytical scheme of a process. Developing a theory doesn't come "out of nothing" but it is constructed and based on clear data collection. We suggest the following steps to follow a grounded theory approach in a research design:
Determine if grounded theory is the best for your research problem . Grounded theory is a good design when a theory is not already available to explain a process.
Develop questions that aim to understand how individuals experienced or enacted the process (e.g., What was the process? How did it unfold?). Data collection and analysis occur in tandem, so that researchers can ask more detailed questions that shape further analysis, such as: What was the focal point of the process (central phenomenon)? What influenced or caused this phenomenon to occur (causal conditions)? What strategies were employed during the process? What effect did it have (consequences)?
Gather relevant data about the topic in question . Data gathering involves questions that are usually asked in interviews, although other forms of data can also be collected, such as observations, documents, and audio-visual materials from different groups.
Carry out the analysis in stages . Grounded theory analysis begins with open coding, where the researcher forms codes that inductively emerge from the data (rather than preconceived categories). Researchers can thus identify specific properties and dimensions relevant to their research question.
Assemble the data in new ways and proceed to axial coding . Axial coding involves using a coding paradigm or logic diagram, such as a visual model, to systematically analyze the data. Begin by identifying a central phenomenon, which is the main category or focus of the research problem. Next, explore the causal conditions, which are the categories of factors that influence the phenomenon. Specify the strategies, which are the actions or interactions associated with the phenomenon. Then, identify the context and intervening conditions—both narrow and broad factors that affect the strategies. Finally, delineate the consequences, which are the outcomes or results of employing the strategies.
Use selective coding to construct a "storyline" that links the categories together. Alternatively, the researcher may formulate propositions or theory-driven questions that specify predicted relationships among these categories.
Develop and visually present a matrix that clarifies the social, historical, and economic conditions influencing the central phenomenon. This optional step encourages viewing the model from the narrowest to the broadest perspective.
Write a substantive-level theory that is closely related to a specific problem or population. This step is optional but provides a focused theoretical framework that can later be tested with quantitative data to explore its generalizability to a broader sample.
Allow theory to emerge through the memo-writing process, where ideas about the theory evolve continuously throughout the stages of open, axial, and selective coding.
The researcher should initially set aside any preconceived theoretical ideas to allow for the emergence of analytical and substantive theories. This is a systematic research approach, particularly when following the methodological steps outlined by Strauss and Corbin (1990). For those seeking more flexibility in their research process, the approach suggested by Charmaz (2006) might be preferable.
One of the challenges when using this method in a research design is determining when categories are sufficiently saturated and when the theory is detailed enough. To achieve saturation, discriminant sampling may be employed, where additional information is gathered from individuals similar to those initially interviewed to verify the applicability of the theory to these new participants. Ultimately, its goal is to develop a theory that comprehensively describes the central phenomenon, causal conditions, strategies, context, and consequences.

Ethnographic research design
An ethnographic approach in research design involves the extended observation and data collection of a group or community. The researcher immerses themselves in the setting, often living within the community for long periods. During this time, they collect data by observing and recording behaviours, conversations, and rituals to understand the group's social dynamics and cultural norms. We suggest following these steps for ethnographic methods in a research design:
Assess whether ethnography is the best approach for the research design and questions. It's suitable if the goal is to describe how a cultural group functions and to delve into their beliefs, language, behaviours, and issues like power, resistance, and domination, particularly if there is limited literature due to the group’s marginal status or unfamiliarity to mainstream society.
Identify and select a cultural group for your research design. Choose one that has a long history together, forming distinct languages, behaviours, and attitudes. This group often might be marginalized within society.
Choose cultural themes or issues to examine within the group. Analyze interactions in everyday settings to identify pervasive patterns such as life cycles, events, and overarching cultural themes. Culture is inferred from the group members' words, actions, and the tension between their actual and expected behaviours, as well as the artifacts they use.
Conduct fieldwork to gather detailed information about the group’s living and working environments. Visit the site, respect the daily lives of the members, and collect a diverse range of materials, considering ethical aspects such as respect and reciprocity.
Compile and analyze cultural data to develop a set of descriptive and thematic insights. Begin with a detailed description of the group based on observations of specific events or activities over time. Then, conduct a thematic analysis to identify patterns or themes that illustrate how the group functions and lives. The final output should be a comprehensive cultural portrait that integrates both the participants (emic) and the researcher’s (etic) perspectives, potentially advocating for the group’s needs or suggesting societal changes to better accommodate them.
Researchers engaging in ethnography need a solid understanding of cultural anthropology and the dynamics of sociocultural systems, which are commonly explored in ethnographic research. The data collection phase is notably extensive, requiring prolonged periods in the field. Ethnographers often employ a literary, quasi-narrative style in their narratives, which can pose challenges for those accustomed to more conventional social science writing methods.
Another potential issue is the risk of researchers "going native," where they become overly assimilated into the community under study, potentially jeopardizing the objectivity and completion of their research. It's crucial for researchers to be aware of their impact on the communities and environments they are studying.
The case study approach in a research design focuses on a detailed examination of a single case or a small number of cases. Cases can be individuals, groups, organizations, or events. Case studies are particularly useful for research designs that aim to understand complex issues in real-life contexts. The aim is to provide a thorough description and contextual analysis of the cases under investigation. We suggest following these steps in a case study design:
Assess if a case study approach suits your research questions . This approach works well when you have distinct cases with defined boundaries and aim to deeply understand these cases or compare multiple cases.
Choose your case or cases. These could involve individuals, groups, programs, events, or activities. Decide whether an individual or collective, multi-site or single-site case study is most appropriate, focusing on specific cases or themes (Stake, 1995; Yin, 2003).
Gather data extensively from diverse sources . Collect information through archival records, interviews, direct and participant observations, and physical artifacts (Yin, 2003).
Analyze the data holistically or in focused segments . Provide a comprehensive overview of the entire case or concentrate on specific aspects. Start with a detailed description including the history of the case and its chronological events then narrow down to key themes. The aim is to delve into the case's complexity rather than generalize findings.
Interpret and report the significance of the case in the final phase . Explain what insights were gained, whether about the subject of the case in an instrumental study or an unusual situation in an intrinsic study (Lincoln & Guba, 1985).
The investigator must carefully select the case or cases to study, recognizing that multiple potential cases could illustrate a chosen topic or issue. This selection process involves deciding whether to focus on a single case for deeper analysis or multiple cases, which may provide broader insights but less depth per case. Each choice requires a well-justified rationale for the selected cases. Researchers face the challenge of defining the boundaries of a case, such as its temporal scope and the events and processes involved. This decision in a research design is crucial as it affects the depth and value of the information presented in the study, and therefore should be planned to ensure a comprehensive portrayal of the case.

Qualitative and quantitative research designs are distinct in their approach to data collection and data analysis. Unlike quantitative research, which focuses on numerical data and statistical analysis, qualitative research prioritizes understanding the depth and richness of human experiences, behaviours, and interactions.
Qualitative methods in a research design have to have internal coherence, meaning that all elements of the research project—research question, data collection, data analysis, findings, and theory—are well-aligned and consistent with each other. This coherence in the research study is especially crucial in inductive qualitative research, where the research process often follows a recursive and evolving path. Ensuring that each component of the research design fits seamlessly with the others enhances the clarity and impact of the study, making the research findings more robust and compelling. Whether it is a descriptive research design, explanatory research design, diagnostic research design, or correlational research design coherence is an important element in both qualitative and quantitative research.
Finally, a good research design ensures that the research is conducted ethically and considers the well-being and rights of participants when managing collected data. The research design guides researchers in providing a clear rationale for their methodologies, which is crucial for justifying the research objectives to the scientific community. A thorough research design also contributes to the body of knowledge, enabling researchers to build upon past research studies and explore new dimensions within their fields. At the core of the design, there is a clear articulation of the research objectives. These objectives should be aligned with the underlying concepts being investigated, offering a concise method to answer the research questions and guiding the direction of the study with proper qualitative methods.
Carter, K. (1993). The place of a story in the study of teaching and teacher education. Educational Researcher, 22(1), 5-12, 18.
Charmaz, K. (2006). Constructing grounded theory. London: Sage.
Creswell, J. W., & Miller, D. L. (2000). Determining validity in qualitative inquiry. Theory Into Practice, 39(3), 124-130.
Lincoln, Y. S., & Guba, E. G. (1985). Naturalistic inquiry. Newbury Park, CA: Sage.
Moustakas, C. (1994). Phenomenological research methods. Thousand Oaks, CA: Sage.
Ollerenshaw, J. A., & Creswell, J. W. (2000, April). Data analysis in narrative research: A comparison of two “restoring” approaches. Paper presented at the annual meeting of the American Educational Research Association, New Orleans, LA.
Stake, R. E. (1995). The art of case study research. Thousand Oaks, CA: Sage.
Strauss, A., & Corbin, J. (1990). Basics of qualitative research: Grounded theory procedures and techniques. Newbury Park, CA: Sage.
van Manen, M. (1990). Researching lived experience: Human science for an action sensitive pedagogy. Ontario, Canada: University of Western Ontario.
Yin, R. K. (2003). Case study research: Design and methods (3rd ed.). Thousand Oaks, CA: Sage

Whatever your research objectives, make it happen with ATLAS.ti!
Download a free trial today.

Organizing Your Social Sciences Research Paper: Types of Research Designs
- Purpose of Guide
- Writing a Research Proposal
- Design Flaws to Avoid
- Independent and Dependent Variables
- Narrowing a Topic Idea
- Broadening a Topic Idea
- The Research Problem/Question
- Academic Writing Style
- Choosing a Title
- Making an Outline
- Paragraph Development
- The C.A.R.S. Model
- Background Information
- Theoretical Framework
- Citation Tracking
- Evaluating Sources
- Reading Research Effectively
- Primary Sources
- Secondary Sources
- What Is Scholarly vs. Popular?
- Is it Peer-Reviewed?
- Qualitative Methods
- Quantitative Methods
- Common Grammar Mistakes
- Writing Concisely
- Avoiding Plagiarism [linked guide]
- Annotated Bibliography
- Grading Someone Else's Paper
Introduction
Before beginning your paper, you need to decide how you plan to design the study .
The research design refers to the overall strategy that you choose to integrate the different components of the study in a coherent and logical way, thereby, ensuring you will effectively address the research problem; it constitutes the blueprint for the collection, measurement, and analysis of data. Note that your research problem determines the type of design you should use, not the other way around!
De Vaus, D. A. Research Design in Social Research . London: SAGE, 2001; Trochim, William M.K. Research Methods Knowledge Base . 2006.
General Structure and Writing Style
The function of a research design is to ensure that the evidence obtained enables you to effectively address the research problem logically and as unambiguously as possible . In social sciences research, obtaining information relevant to the research problem generally entails specifying the type of evidence needed to test a theory, to evaluate a program, or to accurately describe and assess meaning related to an observable phenomenon.
With this in mind, a common mistake made by researchers is that they begin their investigations far too early, before they have thought critically about what information is required to address the research problem. Without attending to these design issues beforehand, the overall research problem will not be adequately addressed and any conclusions drawn will run the risk of being weak and unconvincing. As a consequence, the overall validity of the study will be undermined.
The length and complexity of describing research designs in your paper can vary considerably, but any well-developed design will achieve the following :
- Identify the research problem clearly and justify its selection, particularly in relation to any valid alternative designs that could have been used,
- Review and synthesize previously published literature associated with the research problem,
- Clearly and explicitly specify hypotheses [i.e., research questions] central to the problem,
- Effectively describe the data which will be necessary for an adequate testing of the hypotheses and explain how such data will be obtained, and
- Describe the methods of analysis to be applied to the data in determining whether or not the hypotheses are true or false.
The research design is usually incorporated into the introduction and varies in length depending on the type of design you are using. However, you can get a sense of what to do by reviewing the literature of studies that have utilized the same research design. This can provide an outline to follow for your own paper.
NOTE : Use the SAGE Research Methods Online and Cases and the SAGE Research Methods Videos databases to search for scholarly resources on how to apply specific research designs and methods . The Research Methods Online database contains links to more than 175,000 pages of SAGE publisher's book, journal, and reference content on quantitative, qualitative, and mixed research methodologies. Also included is a collection of case studies of social research projects that can be used to help you better understand abstract or complex methodological concepts. The Research Methods Videos database contains hours of tutorials, interviews, video case studies, and mini-documentaries covering the entire research process.
Creswell, John W. and J. David Creswell. Research Design: Qualitative, Quantitative, and Mixed Methods Approaches . 5th edition. Thousand Oaks, CA: Sage, 2018; De Vaus, D. A. Research Design in Social Research . London: SAGE, 2001; Gorard, Stephen. Research Design: Creating Robust Approaches for the Social Sciences . Thousand Oaks, CA: Sage, 2013; Leedy, Paul D. and Jeanne Ellis Ormrod. Practical Research: Planning and Design . Tenth edition. Boston, MA: Pearson, 2013; Vogt, W. Paul, Dianna C. Gardner, and Lynne M. Haeffele. When to Use What Research Design . New York: Guilford, 2012.
Videos in Business and Management , Criminology and Criminal Justice , Education , and Media, Communication and Cultural Studies specifically created for use in higher education.
A literature review tool that highlights the most influential works in Business & Management, Education, Politics & International Relations, Psychology and Sociology. Does not contain full text of the cited works. Dates vary.
Encyclopedias, handbooks, ebooks, and videos published by Sage and CQ Press. 2000 to present
Causal Design
Definition and Purpose
Causality studies may be thought of as understanding a phenomenon in terms of conditional statements in the form, “If X, then Y.” This type of research is used to measure what impact a specific change will have on existing norms and assumptions. Most social scientists seek causal explanations that reflect tests of hypotheses. Causal effect (nomothetic perspective) occurs when variation in one phenomenon, an independent variable, leads to or results, on average, in variation in another phenomenon, the dependent variable.
Conditions necessary for determining causality:
- Empirical association -- a valid conclusion is based on finding an association between the independent variable and the dependent variable.
- Appropriate time order -- to conclude that causation was involved, one must see that cases were exposed to variation in the independent variable before variation in the dependent variable.
- Nonspuriousness -- a relationship between two variables that is not due to variation in a third variable.
What do these studies tell you ?
- Causality research designs assist researchers in understanding why the world works the way it does through the process of proving a causal link between variables and by the process of eliminating other possibilities.
- Replication is possible.
- There is greater confidence the study has internal validity due to the systematic subject selection and equity of groups being compared.
What these studies don't tell you ?
- Not all relationships are casual! The possibility always exists that, by sheer coincidence, two unrelated events appear to be related [e.g., Punxatawney Phil could accurately predict the duration of Winter for five consecutive years but, the fact remains, he's just a big, furry rodent].
- Conclusions about causal relationships are difficult to determine due to a variety of extraneous and confounding variables that exist in a social environment. This means causality can only be inferred, never proven.
- If two variables are correlated, the cause must come before the effect. However, even though two variables might be causally related, it can sometimes be difficult to determine which variable comes first and, therefore, to establish which variable is the actual cause and which is the actual effect.
Beach, Derek and Rasmus Brun Pedersen. Causal Case Study Methods: Foundations and Guidelines for Comparing, Matching, and Tracing . Ann Arbor, MI: University of Michigan Press, 2016; Bachman, Ronet. The Practice of Research in Criminology and Criminal Justice . Chapter 5, Causation and Research Designs. 3rd ed. Thousand Oaks, CA: Pine Forge Press, 2007; Brewer, Ernest W. and Jennifer Kubn. “Causal-Comparative Design.” In Encyclopedia of Research Design . Neil J. Salkind, editor. (Thousand Oaks, CA: Sage, 2010), pp. 125-132; Causal Research Design: Experimentation. Anonymous SlideShare Presentation ; Gall, Meredith. Educational Research: An Introduction . Chapter 11, Nonexperimental Research: Correlational Designs. 8th ed. Boston, MA: Pearson/Allyn and Bacon, 2007; Trochim, William M.K. Research Methods Knowledge Base . 2006.
Cohort Design
Often used in the medical sciences, but also found in the applied social sciences, a cohort study generally refers to a study conducted over a period of time involving members of a population which the subject or representative member comes from, and who are united by some commonality or similarity. Using a quantitative framework, a cohort study makes note of statistical occurrence within a specialized subgroup, united by same or similar characteristics that are relevant to the research problem being investigated, r ather than studying statistical occurrence within the general population. Using a qualitative framework, cohort studies generally gather data using methods of observation. Cohorts can be either "open" or "closed."
- Open Cohort Studies [dynamic populations, such as the population of Los Angeles] involve a population that is defined just by the state of being a part of the study in question (and being monitored for the outcome). Date of entry and exit from the study is individually defined, therefore, the size of the study population is not constant. In open cohort studies, researchers can only calculate rate based data, such as, incidence rates and variants thereof.
- Closed Cohort Studies [static populations, such as patients entered into a clinical trial] involve participants who enter into the study at one defining point in time and where it is presumed that no new participants can enter the cohort. Given this, the number of study participants remains constant (or can only decrease).
- The use of cohorts is often mandatory because a randomized control study may be unethical. For example, you cannot deliberately expose people to asbestos, you can only study its effects on those who have already been exposed. Research that measures risk factors often relies upon cohort designs.
- Because cohort studies measure potential causes before the outcome has occurred, they can demonstrate that these “causes” preceded the outcome, thereby avoiding the debate as to which is the cause and which is the effect.
- Cohort analysis is highly flexible and can provide insight into effects over time and related to a variety of different types of changes [e.g., social, cultural, political, economic, etc.].
- Either original data or secondary data can be used in this design.
- In cases where a comparative analysis of two cohorts is made [e.g., studying the effects of one group exposed to asbestos and one that has not], a researcher cannot control for all other factors that might differ between the two groups. These factors are known as confounding variables.
- Cohort studies can end up taking a long time to complete if the researcher must wait for the conditions of interest to develop within the group. This also increases the chance that key variables change during the course of the study, potentially impacting the validity of the findings.
- Due to the lack of randominization in the cohort design, its external validity is lower than that of study designs where the researcher randomly assigns participants.
Healy P, Devane D. “Methodological Considerations in Cohort Study Designs.” Nurse Researcher 18 (2011): 32-36; Glenn, Norval D, editor. Cohort Analysis . 2nd edition. Thousand Oaks, CA: Sage, 2005; Levin, Kate Ann. Study Design IV: Cohort Studies. Evidence-Based Dentistry 7 (2003): 51–52; Payne, Geoff. “Cohort Study.” In The SAGE Dictionary of Social Research Methods . Victor Jupp, editor. (Thousand Oaks, CA: Sage, 2006), pp. 31-33; Study Design 101 . Himmelfarb Health Sciences Library. George Washington University, November 2011; Cohort Study . Wikipedia.
Cross-Sectional Design
Cross-sectional research designs have three distinctive features: no time dimension; a reliance on existing differences rather than change following intervention; and, groups are selected based on existing differences rather than random allocation. The cross-sectional design can only measure differences between or from among a variety of people, subjects, or phenomena rather than a process of change. As such, researchers using this design can only employ a relatively passive approach to making causal inferences based on findings.
- Cross-sectional studies provide a clear 'snapshot' of the outcome and the characteristics associated with it, at a specific point in time.
- Unlike an experimental design, where there is an active intervention by the researcher to produce and measure change or to create differences, cross-sectional designs focus on studying and drawing inferences from existing differences between people, subjects, or phenomena.
- Entails collecting data at and concerning one point in time. While longitudinal studies involve taking multiple measures over an extended period of time, cross-sectional research is focused on finding relationships between variables at one moment in time.
- Groups identified for study are purposely selected based upon existing differences in the sample rather than seeking random sampling.
- Cross-section studies are capable of using data from a large number of subjects and, unlike observational studies, is not geographically bound.
- Can estimate prevalence of an outcome of interest because the sample is usually taken from the whole population.
- Because cross-sectional designs generally use survey techniques to gather data, they are relatively inexpensive and take up little time to conduct.
- Finding people, subjects, or phenomena to study that are very similar except in one specific variable can be difficult.
- Results are static and time bound and, therefore, give no indication of a sequence of events or reveal historical or temporal contexts.
- Studies cannot be utilized to establish cause and effect relationships.
- This design only provides a snapshot of analysis so there is always the possibility that a study could have differing results if another time-frame had been chosen.
- There is no follow up to the findings.
Bethlehem, Jelke. "7: Cross-sectional Research." In Research Methodology in the Social, Behavioural and Life Sciences . Herman J Adèr and Gideon J Mellenbergh, editors. (London, England: Sage, 1999), pp. 110-43; Bourque, Linda B. “Cross-Sectional Design.” In The SAGE Encyclopedia of Social Science Research Methods . Michael S. Lewis-Beck, Alan Bryman, and Tim Futing Liao. (Thousand Oaks, CA: 2004), pp. 230-231; Hall, John. “Cross-Sectional Survey Design.” In Encyclopedia of Survey Research Methods . Paul J. Lavrakas, ed. (Thousand Oaks, CA: Sage, 2008), pp. 173-174; Helen Barratt, Maria Kirwan. Cross-Sectional Studies: Design, Application, Strengths and Weaknesses of Cross-Sectional Studies . Healthknowledge, 2009. Cross-Sectional Study . Wikipedia.
Descriptive Design
Descriptive research designs help provide answers to the questions of who, what, when, where, and how associated with a particular research problem; a descriptive study cannot conclusively ascertain answers to why. Descriptive research is used to obtain information concerning the current status of the phenomena and to describe "what exists" with respect to variables or conditions in a situation.
- The subject is being observed in a completely natural and unchanged natural environment. True experiments, whilst giving analyzable data, often adversely influence the normal behavior of the subject [a.k.a., the Heisenberg effect whereby measurements of certain systems cannot be made without affecting the systems].
- Descriptive research is often used as a pre-cursor to more quantitative research designs with the general overview giving some valuable pointers as to what variables are worth testing quantitatively.
- If the limitations are understood, they can be a useful tool in developing a more focused study.
- Descriptive studies can yield rich data that lead to important recommendations in practice.
- Appoach collects a large amount of data for detailed analysis.
- The results from a descriptive research cannot be used to discover a definitive answer or to disprove a hypothesis.
- Because descriptive designs often utilize observational methods [as opposed to quantitative methods], the results cannot be replicated.
- The descriptive function of research is heavily dependent on instrumentation for measurement and observation.
Anastas, Jeane W. Research Design for Social Work and the Human Services . Chapter 5, Flexible Methods: Descriptive Research. 2nd ed. New York: Columbia University Press, 1999; Given, Lisa M. "Descriptive Research." In Encyclopedia of Measurement and Statistics . Neil J. Salkind and Kristin Rasmussen, editors. (Thousand Oaks, CA: Sage, 2007), pp. 251-254; McNabb, Connie. Descriptive Research Methodologies . Powerpoint Presentation; Shuttleworth, Martyn. Descriptive Research Design , September 26, 2008. Explorable.com website.
Experimental Design
A blueprint of the procedure that enables the researcher to maintain control over all factors that may affect the result of an experiment. In doing this, the researcher attempts to determine or predict what may occur. Experimental research is often used where there is time priority in a causal relationship (cause precedes effect), there is consistency in a causal relationship (a cause will always lead to the same effect), and the magnitude of the correlation is great. The classic experimental design specifies an experimental group and a control group. The independent variable is administered to the experimental group and not to the control group, and both groups are measured on the same dependent variable. Subsequent experimental designs have used more groups and more measurements over longer periods. True experiments must have control, randomization, and manipulation.
- Experimental research allows the researcher to control the situation. In so doing, it allows researchers to answer the question, “What causes something to occur?”
- Permits the researcher to identify cause and effect relationships between variables and to distinguish placebo effects from treatment effects.
- Experimental research designs support the ability to limit alternative explanations and to infer direct causal relationships in the study.
- Approach provides the highest level of evidence for single studies.
- The design is artificial, and results may not generalize well to the real world.
- The artificial settings of experiments may alter the behaviors or responses of participants.
- Experimental designs can be costly if special equipment or facilities are needed.
- Some research problems cannot be studied using an experiment because of ethical or technical reasons.
- Difficult to apply ethnographic and other qualitative methods to experimentally designed studies.
Anastas, Jeane W. Research Design for Social Work and the Human Services . Chapter 7, Flexible Methods: Experimental Research. 2nd ed. New York: Columbia University Press, 1999; Chapter 2: Research Design, Experimental Designs . School of Psychology, University of New England, 2000; Chow, Siu L. "Experimental Design." In Encyclopedia of Research Design . Neil J. Salkind, editor. (Thousand Oaks, CA: Sage, 2010), pp. 448-453; "Experimental Design." In Social Research Methods . Nicholas Walliman, editor. (London, England: Sage, 2006), pp, 101-110; Experimental Research . Research Methods by Dummies. Department of Psychology. California State University, Fresno, 2006; Kirk, Roger E. Experimental Design: Procedures for the Behavioral Sciences . 4th edition. Thousand Oaks, CA: Sage, 2013; Trochim, William M.K. Experimental Design . Research Methods Knowledge Base. 2006; Rasool, Shafqat. Experimental Research . Slideshare presentation.
Exploratory Design
An exploratory design is conducted about a research problem when there are few or no earlier studies to refer to or rely upon to predict an outcome . The focus is on gaining insights and familiarity for later investigation or undertaken when research problems are in a preliminary stage of investigation. Exploratory designs are often used to establish an understanding of how best to proceed in studying an issue or what methodology would effectively apply to gathering information about the issue.
The goals of exploratory research are intended to produce the following possible insights:
- Familiarity with basic details, settings, and concerns.
- Well grounded picture of the situation being developed.
- Generation of new ideas and assumptions.
- Development of tentative theories or hypotheses.
- Determination about whether a study is feasible in the future.
- Issues get refined for more systematic investigation and formulation of new research questions.
- Direction for future research and techniques get developed.
- Design is a useful approach for gaining background information on a particular topic.
- Exploratory research is flexible and can address research questions of all types (what, why, how).
- Provides an opportunity to define new terms and clarify existing concepts.
- Exploratory research is often used to generate formal hypotheses and develop more precise research problems.
- In the policy arena or applied to practice, exploratory studies help establish research priorities and where resources should be allocated.
- Exploratory research generally utilizes small sample sizes and, thus, findings are typically not generalizable to the population at large.
- The exploratory nature of the research inhibits an ability to make definitive conclusions about the findings. They provide insight but not definitive conclusions.
- The research process underpinning exploratory studies is flexible but often unstructured, leading to only tentative results that have limited value to decision-makers.
- Design lacks rigorous standards applied to methods of data gathering and analysis because one of the areas for exploration could be to determine what method or methodologies could best fit the research problem.
Cuthill, Michael. “Exploratory Research: Citizen Participation, Local Government, and Sustainable Development in Australia.” Sustainable Development 10 (2002): 79-89; Streb, Christoph K. "Exploratory Case Study." In Encyclopedia of Case Study Research . Albert J. Mills, Gabrielle Durepos and Eiden Wiebe, editors. (Thousand Oaks, CA: Sage, 2010), pp. 372-374; Taylor, P. J., G. Catalano, and D.R.F. Walker. “Exploratory Analysis of the World City Network.” Urban Studies 39 (December 2002): 2377-2394; Exploratory Research . Wikipedia.
Historical Design
The purpose of a historical research design is to collect, verify, and synthesize evidence from the past to establish facts that defend or refute a hypothesis. It uses secondary sources and a variety of primary documentary evidence, such as, diaries, official records, reports, archives, and non-textual information [maps, pictures, audio and visual recordings]. The limitation is that the sources must be both authentic and valid.
- The historical research design is unobtrusive; the act of research does not affect the results of the study.
- The historical approach is well suited for trend analysis.
- Historical records can add important contextual background required to more fully understand and interpret a research problem.
- There is often no possibility of researcher-subject interaction that could affect the findings.
- Historical sources can be used over and over to study different research problems or to replicate a previous study.
- The ability to fulfill the aims of your research are directly related to the amount and quality of documentation available to understand the research problem.
- Since historical research relies on data from the past, there is no way to manipulate it to control for contemporary contexts.
- Interpreting historical sources can be very time consuming.
- The sources of historical materials must be archived consistently to ensure access. This may especially challenging for digital or online-only sources.
- Original authors bring their own perspectives and biases to the interpretation of past events and these biases are more difficult to ascertain in historical resources.
- Due to the lack of control over external variables, historical research is very weak with regard to the demands of internal validity.
- It is rare that the entirety of historical documentation needed to fully address a research problem is available for interpretation, therefore, gaps need to be acknowledged.
Howell, Martha C. and Walter Prevenier. From Reliable Sources: An Introduction to Historical Methods . Ithaca, NY: Cornell University Press, 2001; Lundy, Karen Saucier. "Historical Research." In The Sage Encyclopedia of Qualitative Research Methods . Lisa M. Given, editor. (Thousand Oaks, CA: Sage, 2008), pp. 396-400; Marius, Richard. and Melvin E. Page. A Short Guide to Writing about History . 9th edition. Boston, MA: Pearson, 2015; Savitt, Ronald. “Historical Research in Marketing.” Journal of Marketing 44 (Autumn, 1980): 52-58; Gall, Meredith. Educational Research: An Introduction . Chapter 16, Historical Research. 8th ed. Boston, MA: Pearson/Allyn and Bacon, 2007.
Longitudinal Design
A longitudinal study follows the same sample over time and makes repeated observations. For example, with longitudinal surveys, the same group of people is interviewed at regular intervals, enabling researchers to track changes over time and to relate them to variables that might explain why the changes occur. Longitudinal research designs describe patterns of change and help establish the direction and magnitude of causal relationships. Measurements are taken on each variable over two or more distinct time periods. This allows the researcher to measure change in variables over time. It is a type of observational study sometimes referred to as a panel study.
- Longitudinal data facilitate the analysis of the duration of a particular phenomenon.
- Enables survey researchers to get close to the kinds of causal explanations usually attainable only with experiments.
- The design permits the measurement of differences or change in a variable from one period to another [i.e., the description of patterns of change over time].
- Longitudinal studies facilitate the prediction of future outcomes based upon earlier factors.
- The data collection method may change over time.
- Maintaining the integrity of the original sample can be difficult over an extended period of time.
- It can be difficult to show more than one variable at a time.
- This design often needs qualitative research data to explain fluctuations in the results.
- A longitudinal research design assumes present trends will continue unchanged.
- It can take a long period of time to gather results.
- There is a need to have a large sample size and accurate sampling to reach representativness.
Anastas, Jeane W. Research Design for Social Work and the Human Services . Chapter 6, Flexible Methods: Relational and Longitudinal Research. 2nd ed. New York: Columbia University Press, 1999; Forgues, Bernard, and Isabelle Vandangeon-Derumez. "Longitudinal Analyses." In Doing Management Research . Raymond-Alain Thiétart and Samantha Wauchope, editors. (London, England: Sage, 2001), pp. 332-351; Kalaian, Sema A. and Rafa M. Kasim. "Longitudinal Studies." In Encyclopedia of Survey Research Methods . Paul J. Lavrakas, ed. (Thousand Oaks, CA: Sage, 2008), pp. 440-441; Menard, Scott, editor. Longitudinal Research . Thousand Oaks, CA: Sage, 2002; Ployhart, Robert E. and Robert J. Vandenberg. "Longitudinal Research: The Theory, Design, and Analysis of Change.” Journal of Management 36 (January 2010): 94-120; Longitudinal Study . Wikipedia.
Mixed-Method Design
- Narrative and non-textual information can add meaning to numeric data, while numeric data can add precision to narrative and non-textual information.
- Can utilize existing data while at the same time generating and testing a grounded theory approach to describe and explain the phenomenon under study.
- A broader, more complex research problem can be investigated because the researcher is not constrained by using only one method.
- The strengths of one method can be used to overcome the inherent weaknesses of another method.
- Can provide stronger, more robust evidence to support a conclusion or set of recommendations.
- May generate new knowledge new insights or uncover hidden insights, patterns, or relationships that a single methodological approach might not reveal.
- Produces more complete knowledge and understanding of the research problem that can be used to increase the generalizability of findings applied to theory or practice.
- A researcher must be proficient in understanding how to apply multiple methods to investigating a research problem as well as be proficient in optimizing how to design a study that coherently melds them together.
- Can increase the likelihood of conflicting results or ambiguous findings that inhibit drawing a valid conclusion or setting forth a recommended course of action [e.g., sample interview responses do not support existing statistical data].
- Because the research design can be very complex, reporting the findings requires a well-organized narrative, clear writing style, and precise word choice.
- Design invites collaboration among experts. However, merging different investigative approaches and writing styles requires more attention to the overall research process than studies conducted using only one methodological paradigm.
- Concurrent merging of quantitative and qualitative research requires greater attention to having adequate sample sizes, using comparable samples, and applying a consistent unit of analysis. For sequential designs where one phase of qualitative research builds on the quantitative phase or vice versa, decisions about what results from the first phase to use in the next phase, the choice of samples and estimating reasonable sample sizes for both phases, and the interpretation of results from both phases can be difficult.
- Due to multiple forms of data being collected and analyzed, this design requires extensive time and resources to carry out the multiple steps involved in data gathering and interpretation.
Burch, Patricia and Carolyn J. Heinrich. Mixed Methods for Policy Research and Program Evaluation . Thousand Oaks, CA: Sage, 2016; Creswell, John w. et al. Best Practices for Mixed Methods Research in the Health Sciences . Bethesda, MD: Office of Behavioral and Social Sciences Research, National Institutes of Health, 2010Creswell, John W. Research Design: Qualitative, Quantitative, and Mixed Methods Approaches . 4th edition. Thousand Oaks, CA: Sage Publications, 2014; Domínguez, Silvia, editor. Mixed Methods Social Networks Research . Cambridge, UK: Cambridge University Press, 2014; Hesse-Biber, Sharlene Nagy. Mixed Methods Research: Merging Theory with Practice . New York: Guilford Press, 2010; Niglas, Katrin. “How the Novice Researcher Can Make Sense of Mixed Methods Designs.” International Journal of Multiple Research Approaches 3 (2009): 34-46; Onwuegbuzie, Anthony J. and Nancy L. Leech. “Linking Research Questions to Mixed Methods Data Analysis Procedures.” The Qualitative Report 11 (September 2006): 474-498; Tashakorri, Abbas and John W. Creswell. “The New Era of Mixed Methods.” Journal of Mixed Methods Research 1 (January 2007): 3-7; Zhanga, Wanqing. “Mixed Methods Application in Health Intervention Research: A Multiple Case Study.” International Journal of Multiple Research Approaches 8 (2014): 24-35 .
Observational Design
This type of research design draws a conclusion by comparing subjects against a control group, in cases where the researcher has no control over the experiment. There are two general types of observational designs. In direct observations, people know that you are watching them. Unobtrusive measures involve any method for studying behavior where individuals do not know they are being observed. An observational study allows a useful insight into a phenomenon and avoids the ethical and practical difficulties of setting up a large and cumbersome research project.
- Observational studies are usually flexible and do not necessarily need to be structured around a hypothesis about what you expect to observe [data is emergent rather than pre-existing].
- The researcher is able to collect in-depth information about a particular behavior.
- Can reveal interrelationships among multifaceted dimensions of group interactions.
- You can generalize your results to real life situations.
- Observational research is useful for discovering what variables may be important before applying other methods like experiments.
- Observation research designs account for the complexity of group behaviors.
- Reliability of data is low because seeing behaviors occur over and over again may be a time consuming task and are difficult to replicate.
- In observational research, findings may only reflect a unique sample population and, thus, cannot be generalized to other groups.
- There can be problems with bias as the researcher may only "see what they want to see."
- There is no possibility to determine "cause and effect" relationships since nothing is manipulated.
- Sources or subjects may not all be equally credible.
- Any group that is knowingly studied is altered to some degree by the presence of the researcher, therefore, potentially skewing any data collected.
Atkinson, Paul and Martyn Hammersley. “Ethnography and Participant Observation.” In Handbook of Qualitative Research . Norman K. Denzin and Yvonna S. Lincoln, eds. (Thousand Oaks, CA: Sage, 1994), pp. 248-261; Observational Research . Research Methods by Dummies. Department of Psychology. California State University, Fresno, 2006; Patton Michael Quinn. Qualitiative Research and Evaluation Methods . Chapter 6, Fieldwork Strategies and Observational Methods. 3rd ed. Thousand Oaks, CA: Sage, 2002; Payne, Geoff and Judy Payne. "Observation." In Key Concepts in Social Research . The SAGE Key Concepts series. (London, England: Sage, 2004), pp. 158-162; Rosenbaum, Paul R. Design of Observational Studies . New York: Springer, 2010;Williams, J. Patrick. "Nonparticipant Observation." In The Sage Encyclopedia of Qualitative Research Methods . Lisa M. Given, editor.(Thousand Oaks, CA: Sage, 2008), pp. 562-563.
- << Previous: Writing a Research Proposal
- Next: Design Flaws to Avoid >>
- Last Updated: Sep 8, 2023 12:19 PM
- URL: https://guides.library.txstate.edu/socialscienceresearch
 quizlet")
- school Campus Bookshelves
- menu_book Bookshelves
- perm_media Learning Objects
- login Login
- how_to_reg Request Instructor Account
- hub Instructor Commons
Margin Size
- Download Page (PDF)
- Download Full Book (PDF)
- Periodic Table
- Physics Constants
- Scientific Calculator
- Reference & Cite
- Tools expand_more
- Readability
selected template will load here
This action is not available.
2.4: Research Designs
- Last updated
- Save as PDF
- Page ID 10602

- Christie Napa Scollon
- https://nobaproject.com/ via The Noba Project
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
Psychologists test research questions using a variety of methods. Most research relies on either correlations or experiments. With correlations, researchers measure variables as they naturally occur in people and compute the degree to which two variables go together. With experiments, researchers actively make changes in one variable and watch for changes in another variable. Experiments allow researchers to make causal inferences. Other types of methods include longitudinal and quasi-experimental designs. Many factors, including practical constraints, determine the type of methods researchers use. Often researchers survey people even though it would be better, but more expensive and time consuming, to track them longitudinally.
learning objectives
- Articulate the difference between correlational and experimental designs.
- Understand how to interpret correlations.
- Understand how experiments help us to infer causality.
- Understand how surveys relate to correlational and experimental research.
- Explain what a longitudinal study is.
- List a strength and weakness of different research designs.
Research Designs
In the early 1970’s, a man named Uri Geller tricked the world: he convinced hundreds of thousands of people that he could bend spoons and slow watches using only the power of his mind. In fact, if you were in the audience, you would have likely believed he had psychic powers. Everything looked authentic—this man had to have paranormal abilities! So, why have you probably never heard of him before? Because when Uri was asked to perform his miracles in line with scientific experimentation, he was no longer able to do them. That is, even though it seemed like he was doing the impossible, when he was tested by science, he proved to be nothing more than a clever magician.
When we look at dinosaur bones to make educated guesses about extinct life, or systematically chart the heavens to learn about the relationships between stars and planets, or study magicians to figure out how they perform their tricks, we are forming observations—the foundation of science. Although we are all familiar with the saying “seeing is believing,” conducting science is more than just what your eyes perceive. Science is the result of systematic and intentional study of the natural world. And psychology is no different. In the movie Jerry Maguire , Cuba Gooding, Jr. became famous for using the phrase, “Show me the money!” In psychology, as in all sciences, we might say, “Show me the data!”
One of the important steps in scientific inquiry is to test our research questions, otherwise known as hypotheses. However, there are many ways to test hypotheses in psychological research. Which method you choose will depend on the type of questions you are asking, as well as what resources are available to you. All methods have limitations, which is why the best research uses a variety of methods.
Most psychological research can be divided into two types: experimental and correlational research.
Experimental Research
If somebody gave you $20 that absolutely had to be spent today, how would you choose to spend it? Would you spend it on an item you’ve been eyeing for weeks, or would you donate the money to charity? Which option do you think would bring you the most happiness? If you’re like most people, you’d choose to spend the money on yourself (duh, right?). Our intuition is that we’d be happier if we spent the money on ourselves.

Knowing that our intuition can sometimes be wrong, Professor Elizabeth Dunn (2008) at the University of British Columbia set out to conduct an experiment on spending and happiness. She gave each of the participants in her experiment $20 and then told them they had to spend the money by the end of the day. Some of the participants were told they must spend the money on themselves, and some were told they must spend the money on others (either charity or a gift for someone). At the end of the day she measured participants’ levels of happiness using a self-report questionnaire. (But wait, how do you measure something like happiness when you can’t really see it? Psychologists measure many abstract concepts, such as happiness and intelligence, by beginning with operational definitions of the concepts. See the Noba modules on Intelligence [noba.to/ncb2h79v] and Happiness [noba.to/qnw7g32t], respectively, for more information on specific measurement strategies.)
In an experiment, researchers manipulate, or cause changes, in the independent variable , and observe or measure any impact of those changes in the dependent variable . The independent variable is the one under the experimenter’s control, or the variable that is intentionally altered between groups. In the case of Dunn’s experiment, the independent variable was whether participants spent the money on themselves or on others. The dependent variable is the variable that is not manipulated at all, or the one where the effect happens. One way to help remember this is that the dependent variable “depends” on what happens to the independent variable. In our example, the participants’ happiness (the dependent variable in this experiment) depends on how the participants spend their money (the independent variable). Thus, any observed changes or group differences in happiness can be attributed to whom the money was spent on. What Dunn and her colleagues found was that, after all the spending had been done, the people who had spent the money on others were happier than those who had spent the money on themselves. In other words, spending on others causes us to be happier than spending on ourselves. Do you find this surprising?
But wait! Doesn’t happiness depend on a lot of different factors—for instance, a person’s upbringing or life circumstances? What if some people had happy childhoods and that’s why they’re happier? Or what if some people dropped their toast that morning and it fell jam-side down and ruined their whole day? It is correct to recognize that these factors and many more can easily affect a person’s level of happiness. So how can we accurately conclude that spending money on others causes happiness, as in the case of Dunn’s experiment?
The most important thing about experiments is random assignment . Participants don’t get to pick which condition they are in (e.g., participants didn’t choose whether they were supposed to spend the money on themselves versus others). The experimenter assigns them to a particular condition based on the flip of a coin or the roll of a die or any other random method. Why do researchers do this? With Dunn’s study, there is the obvious reason: you can imagine which condition most people would choose to be in, if given the choice. But another equally important reason is that random assignment makes it so the groups, on average, are similar on all characteristics except what the experimenter manipulates.
By randomly assigning people to conditions (self-spending versus other-spending), some people with happy childhoods should end up in each condition. Likewise, some people who had dropped their toast that morning (or experienced some other disappointment) should end up in each condition. As a result, the distribution of all these factors will generally be consistent across the two groups, and this means that on average the two groups will be relatively equivalent on all these factors. Random assignment is critical to experimentation because if the only difference between the two groups is the independent variable, we can infer that the independent variable is the cause of any observable difference (e.g., in the amount of happiness they feel at the end of the day).
Here’s another example of the importance of random assignment: Let’s say your class is going to form two basketball teams, and you get to be the captain of one team. The class is to be divided evenly between the two teams. If you get to pick the players for your team first, whom will you pick? You’ll probably pick the tallest members of the class or the most athletic. You probably won’t pick the short, uncoordinated people, unless there are no other options. As a result, your team will be taller and more athletic than the other team. But what if we want the teams to be fair? How can we do this when we have people of varying height and ability? All we have to do is randomly assign players to the two teams. Most likely, some tall and some short people will end up on your team, and some tall and some short people will end up on the other team. The average height of the teams will be approximately the same. That is the power of random assignment!
Other considerations
In addition to using random assignment, you should avoid introducing confounds into your experiments. Confounds are things that could undermine your ability to draw causal inferences. For example, if you wanted to test if a new happy pill will make people happier, you could randomly assign participants to take the happy pill or not (the independent variable) and compare these two groups on their self-reported happiness (the dependent variable). However, if some participants know they are getting the happy pill, they might develop expectations that influence their self-reported happiness. This is sometimes known as a placebo effect . Sometimes a person just knowing that he or she is receiving special treatment or something new is enough to actually cause changes in behavior or perception: In other words, even if the participants in the happy pill condition were to report being happier, we wouldn’t know if the pill was actually making them happier or if it was the placebo effect—an example of a confound. A related idea is participant demand . This occurs when participants try to behave in a way they think the experimenter wants them to behave. Placebo effects and participant demand often occur unintentionally. Even experimenter expectations can influence the outcome of a study. For example, if the experimenter knows who took the happy pill and who did not, and the dependent variable is the experimenter’s observations of people’s happiness, then the experimenter might perceive improvements in the happy pill group that are not really there.
One way to prevent these confounds from affecting the results of a study is to use a double-blind procedure. In a double-blind procedure, neither the participant nor the experimenter knows which condition the participant is in. For example, when participants are given the happy pill or the fake pill, they don’t know which one they are receiving. This way the participants shouldn’t experience the placebo effect, and will be unable to behave as the researcher expects (participant demand). Likewise, the researcher doesn’t know which pill each participant is taking (at least in the beginning—later, the researcher will get the results for data-analysis purposes), which means the researcher’s expectations can’t influence his or her observations. Therefore, because both parties are “blind” to the condition, neither will be able to behave in a way that introduces a confound. At the end of the day, the only difference between groups will be which pills the participants received, allowing the researcher to determine if the happy pill actually caused people to be happier.
Correlational Designs
When scientists passively observe and measure phenomena it is called correlational research. Here, we do not intervene and change behavior, as we do in experiments. In correlational research, we identify patterns of relationships, but we usually cannot infer what causes what. Importantly, with correlational research, you can examine only two variables at a time, no more and no less.
So, what if you wanted to test whether spending on others is related to happiness, but you don’t have $20 to give to each participant? You could use a correlational design—which is exactly what Professor Dunn did, too. She asked people how much of their income they spent on others or donated to charity, and later she asked them how happy they were. Do you think these two variables were related? Yes, they were! The more money people reported spending on others, the happier they were.
More details about the correlation
To find out how well two variables correspond, we can plot the relation between the two scores on what is known as a scatterplot (Figure 2.4.1). In the scatterplot, each dot represents a data point. (In this case it’s individuals, but it could be some other unit.) Importantly, each dot provides us with two pieces of information—in this case, information about how good the person rated the past month (x-axis) and how happy the person felt in the past month (y-axis). Which variable is plotted on which axis does not matter.
")
The association between two variables can be summarized statistically using the correlation coefficient (abbreviated as r ). A correlation coefficient provides information about the direction and strength of the association between two variables. For the example above, the direction of the association is positive. This means that people who perceived the past month as being good reported feeling more happy, whereas people who perceived the month as being bad reported feeling less happy.
With a positive correlation, the two variables go up or down together. In a scatterplot, the dots form a pattern that extends from the bottom left to the upper right (just as they do in Figure 2.4.1). The r value for a positive correlation is indicated by a positive number (although, the positive sign is usually omitted). Here, the r value is .81.
A negative correlation is one in which the two variables move in opposite directions. That is, as one variable goes up, the other goes down. Figure 2.4.2 shows the association between the average height of males in a country (y-axis) and the pathogen prevalence (or commonness of disease; x-axis) of that country. In this scatterplot, each dot represents a country. Notice how the dots extend from the top left to the bottom right. What does this mean in real-world terms? It means that people are shorter in parts of the world where there is more disease. The r value for a negative correlation is indicated by a negative number—that is, it has a minus (–) sign in front of it. Here, it is –.83.
.")
The strength of a correlation has to do with how well the two variables align. Recall that in Professor Dunn’s correlational study, spending on others positively correlated with happiness: The more money people reported spending on others, the happier they reported to be. At this point you may be thinking to yourself, I know a very generous person who gave away lots of money to other people but is miserable! Or maybe you know of a very stingy person who is happy as can be. Yes, there might be exceptions. If an association has many exceptions, it is considered a weak correlation. If an association has few or no exceptions, it is considered a strong correlation. A strong correlation is one in which the two variables always, or almost always, go together. In the example of happiness and how good the month has been, the association is strong. The stronger a correlation is, the tighter the dots in the scatterplot will be arranged along a sloped line.
The r value of a strong correlation will have a high absolute value. In other words, you disregard whether there is a negative sign in front of the r value, and just consider the size of the numerical value itself. If the absolute value is large, it is a strong correlation. A weak correlation is one in which the two variables correspond some of the time, but not most of the time. Figure 2.4.3 shows the relation between valuing happiness and grade point average (GPA). People who valued happiness more tended to earn slightly lower grades, but there were lots of exceptions to this. The r value for a weak correlation will have a low absolute value. If two variables are so weakly related as to be unrelated, we say they are uncorrelated, and the r value will be zero or very close to zero. In the previous example, is the correlation between height and pathogen prevalence strong? Compared to Figure 2.4.3, the dots in Figure 2.4.2 are tighter and less dispersed. The absolute value of –.83 is large. Therefore, it is a strong negative correlation.
.")
Can you guess the strength and direction of the correlation between age and year of birth? If you said this is a strong negative correlation, you are correct! Older people always have lower years of birth than younger people (e.g., 1950 vs. 1995), but at the same time, the older people will have a higher age (e.g., 65 vs. 20). In fact, this is a perfect correlation because there are no exceptions to this pattern. I challenge you to find a 10-year-old born before 2003! You can’t.
Problems with the correlation
If generosity and happiness are positively correlated, should we conclude that being generous causes happiness? Similarly, if height and pathogen prevalence are negatively correlated, should we conclude that disease causes shortness? From a correlation alone, we can’t be certain. For example, in the first case it may be that happiness causes generosity, or that generosity causes happiness. Or, a third variable might cause both happiness and generosity, creating the illusion of a direct link between the two. For example, wealth could be the third variable that causes both greater happiness and greater generosity. This is why correlation does not mean causation—an often repeated phrase among psychologists.
Qualitative Designs
Just as correlational research allows us to study topics we can’t experimentally manipulate (e.g., whether you have a large or small income), there are other types of research designs that allow us to investigate these harder-to-study topics. Qualitative designs, including participant observation, case studies, and narrative analysis are examples of such methodologies. Although something as simple as “observation” may seem like it would be a part of all research methods, participant observation is a distinct methodology that involves the researcher embedding him- or herself into a group in order to study its dynamics. For example, Festinger, Riecken, and Shacter (1956) were very interested in the psychology of a particular cult. However, this cult was very secretive and wouldn’t grant interviews to outside members. So, in order to study these people, Festinger and his colleagues pretended to be cult members, allowing them access to the behavior and psychology of the cult. Despite this example, it should be noted that the people being observed in a participant observation study usually know that the researcher is there to study them.
Another qualitative method for research is the case study, which involves an intensive examination of specific individuals or specific contexts. Sigmund Freud, the father of psychoanalysis, was famous for using this type of methodology; however, more current examples of case studies usually involve brain injuries. For instance, imagine that researchers want to know how a very specific brain injury affects people’s experience of happiness. Obviously, the researchers can’t conduct experimental research that involves inflicting this type of injury on people. At the same time, there are too few people who have this type of injury to conduct correlational research. In such an instance, the researcher may examine only one person with this brain injury, but in doing so, the researcher will put the participant through a very extensive round of tests. Hopefully what is learned from this one person can be applied to others; however, even with thorough tests, there is the chance that something unique about this individual (other than the brain injury) will affect his or her happiness. But with such a limited number of possible participants, a case study is really the only type of methodology suitable for researching this brain injury.
The final qualitative method to be discussed in this section is narrative analysis. Narrative analysis centers around the study of stories and personal accounts of people, groups, or cultures. In this methodology, rather than engaging with participants directly, or quantifying their responses or behaviors, researchers will analyze the themes, structure, and dialogue of each person’s narrative. That is, a researcher will examine people’s personal testimonies in order to learn more about the psychology of those individuals or groups. These stories may be written, audio-recorded, or video-recorded, and allow the researcher not only to study what the participant says but how he or she says it. Every person has a unique perspective on the world, and studying the way he or she conveys a story can provide insight into that perspective.
Quasi-Experimental Designs
What if you want to study the effects of marriage on a variable? For example, does marriage make people happier? Can you randomly assign some people to get married and others to remain single? Of course not. So how can you study these important variables? You can use a quasi-experimental design .

A quasi-experimental design is similar to experimental research, except that random assignment to conditions is not used. Instead, we rely on existing group memberships (e.g., married vs. single). We treat these as the independent variables, even though we don’t assign people to the conditions and don’t manipulate the variables. As a result, with quasi-experimental designs causal inference is more difficult. For example, married people might differ on a variety of characteristics from unmarried people. If we find that married participants are happier than single participants, it will be hard to say that marriage causes happiness, because the people who got married might have already been happier than the people who have remained single.
Because experimental and quasi-experimental designs can seem pretty similar, let’s take another example to distinguish them. Imagine you want to know who is a better professor: Dr. Smith or Dr. Khan. To judge their ability, you’re going to look at their students’ final grades. Here, the independent variable is the professor (Dr. Smith vs. Dr. Khan) and the dependent variable is the students’ grades. In an experimental design, you would randomly assign students to one of the two professors and then compare the students’ final grades. However, in real life, researchers can’t randomly force students to take one professor over the other; instead, the researchers would just have to use the preexisting classes and study them as-is (quasi-experimental design). Again, the key difference is random assignment to the conditions of the independent variable. Although the quasi-experimental design (where the students choose which professor they want) may seem random, it’s most likely not. For example, maybe students heard Dr. Smith sets low expectations, so slackers prefer this class, whereas Dr. Khan sets higher expectations, so smarter students prefer that one. This now introduces a confounding variable (student intelligence) that will almost certainly have an effect on students’ final grades, regardless of how skilled the professor is. So, even though a quasi-experimental design is similar to an experimental design (i.e., it has a manipulated independent variable), because there’s no random assignment, you can’t reasonably draw the same conclusions that you would with an experimental design.
Longitudinal Studies
Another powerful research design is the longitudinal study . Longitudinal studies track the same people over time. Some longitudinal studies last a few weeks, some a few months, some a year or more. Some studies that have contributed a lot to psychology followed the same people over decades. For example, one study followed more than 20,000 Germans for two decades. From these longitudinal data, psychologist Rich Lucas (2003) was able to determine that people who end up getting married indeed start off a bit happier than their peers who never marry. Longitudinal studies like this provide valuable evidence for testing many theories in psychology, but they can be quite costly to conduct, especially if they follow many people for many years.

A survey is a way of gathering information, using old-fashioned questionnaires or the Internet. Compared to a study conducted in a psychology laboratory, surveys can reach a larger number of participants at a much lower cost. Although surveys are typically used for correlational research, this is not always the case. An experiment can be carried out using surveys as well. For example, King and Napa (1998) presented participants with different types of stimuli on paper: either a survey completed by a happy person or a survey completed by an unhappy person. They wanted to see whether happy people were judged as more likely to get into heaven compared to unhappy people. Can you figure out the independent and dependent variables in this study? Can you guess what the results were? Happy people (vs. unhappy people; the independent variable) were judged as more likely to go to heaven (the dependent variable) compared to unhappy people!
Likewise, correlational research can be conducted without the use of surveys. For instance, psychologists LeeAnn Harker and Dacher Keltner (2001) examined the smile intensity of women’s college yearbook photos. Smiling in the photos was correlated with being married 10 years later!
Tradeoffs in Research
Even though there are serious limitations to correlational and quasi-experimental research, they are not poor cousins to experiments and longitudinal designs. In addition to selecting a method that is appropriate to the question, many practical concerns may influence the decision to use one method over another. One of these factors is simply resource availability—how much time and money do you have to invest in the research? (Tip: If you’re doing a senior honor’s thesis, do not embark on a lengthy longitudinal study unless you are prepared to delay graduation!) Often, we survey people even though it would be more precise—but much more difficult—to track them longitudinally. Especially in the case of exploratory research, it may make sense to opt for a cheaper and faster method first. Then, if results from the initial study are promising, the researcher can follow up with a more intensive method.
Beyond these practical concerns, another consideration in selecting a research design is the ethics of the study. For example, in cases of brain injury or other neurological abnormalities, it would be unethical for researchers to inflict these impairments on healthy participants. Nonetheless, studying people with these injuries can provide great insight into human psychology (e.g., if we learn that damage to a particular region of the brain interferes with emotions, we may be able to develop treatments for emotional irregularities). In addition to brain injuries, there are numerous other areas of research that could be useful in understanding the human mind but which pose challenges to a true experimental design—such as the experiences of war, long-term isolation, abusive parenting, or prolonged drug use. However, none of these are conditions we could ethically experimentally manipulate and randomly assign people to. Therefore, ethical considerations are another crucial factor in determining an appropriate research design.
Research Methods: Why You Need Them
Just look at any major news outlet and you’ll find research routinely being reported. Sometimes the journalist understands the research methodology, sometimes not (e.g., correlational evidence is often incorrectly represented as causal evidence). Often, the media are quick to draw a conclusion for you. After reading this module, you should recognize that the strength of a scientific finding lies in the strength of its methodology. Therefore, in order to be a savvy consumer of research, you need to understand the pros and cons of different methods and the distinctions among them. Plus, understanding how psychologists systematically go about answering research questions will help you to solve problems in other domains, both personal and professional, not just in psychology.
Outside Resources
Discussion questions.
- What are some key differences between experimental and correlational research?
- Why might researchers sometimes use methods other than experiments?
- How do surveys relate to correlational and experimental designs?
- Chiao, J. (2009). Culture–gene coevolution of individualism – collectivism and the serotonin transporter gene. Proceedings of the Royal Society B, 277 , 529-537. doi: 10.1098/rspb.2009.1650
- Dunn, E. W., Aknin, L. B., & Norton, M. I. (2008). Spending money on others promotes happiness. Science, 319(5870), 1687–1688. doi:10.1126/science.1150952
- Festinger, L., Riecken, H.W., & Schachter, S. (1956). When prophecy fails. Minneapolis, MN: University of Minnesota Press.
- Harker, L. A., & Keltner, D. (2001). Expressions of positive emotion in women\'s college yearbook pictures and their relationship to personality and life outcomes across adulthood. Journal of Personality and Social Psychology, 80, 112–124.
- King, L. A., & Napa, C. K. (1998). What makes a life good? Journal of Personality and Social Psychology, 75, 156–165.
- Lucas, R. E., Clark, A. E., Georgellis, Y., & Diener, E. (2003). Re-examining adaptation and the setpoint model of happiness: Reactions to changes in marital status. Journal of Personality and Social Psychology, 84, 527–539.
Frequently asked questions
What are the main types of research design.
Quantitative research designs can be divided into two main categories:
- Correlational and descriptive designs are used to investigate characteristics, averages, trends, and associations between variables.
- Experimental and quasi-experimental designs are used to test causal relationships .
Qualitative research designs tend to be more flexible. Common types of qualitative design include case study , ethnography , and grounded theory designs.
Frequently asked questions: Methodology
Attrition refers to participants leaving a study. It always happens to some extent—for example, in randomized controlled trials for medical research.
Differential attrition occurs when attrition or dropout rates differ systematically between the intervention and the control group . As a result, the characteristics of the participants who drop out differ from the characteristics of those who stay in the study. Because of this, study results may be biased .
Action research is conducted in order to solve a particular issue immediately, while case studies are often conducted over a longer period of time and focus more on observing and analyzing a particular ongoing phenomenon.
Action research is focused on solving a problem or informing individual and community-based knowledge in a way that impacts teaching, learning, and other related processes. It is less focused on contributing theoretical input, instead producing actionable input.
Action research is particularly popular with educators as a form of systematic inquiry because it prioritizes reflection and bridges the gap between theory and practice. Educators are able to simultaneously investigate an issue as they solve it, and the method is very iterative and flexible.
A cycle of inquiry is another name for action research . It is usually visualized in a spiral shape following a series of steps, such as “planning → acting → observing → reflecting.”
To make quantitative observations , you need to use instruments that are capable of measuring the quantity you want to observe. For example, you might use a ruler to measure the length of an object or a thermometer to measure its temperature.
Criterion validity and construct validity are both types of measurement validity . In other words, they both show you how accurately a method measures something.
While construct validity is the degree to which a test or other measurement method measures what it claims to measure, criterion validity is the degree to which a test can predictively (in the future) or concurrently (in the present) measure something.
Construct validity is often considered the overarching type of measurement validity . You need to have face validity , content validity , and criterion validity in order to achieve construct validity.
Convergent validity and discriminant validity are both subtypes of construct validity . Together, they help you evaluate whether a test measures the concept it was designed to measure.
- Convergent validity indicates whether a test that is designed to measure a particular construct correlates with other tests that assess the same or similar construct.
- Discriminant validity indicates whether two tests that should not be highly related to each other are indeed not related. This type of validity is also called divergent validity .
You need to assess both in order to demonstrate construct validity. Neither one alone is sufficient for establishing construct validity.
- Discriminant validity indicates whether two tests that should not be highly related to each other are indeed not related
Content validity shows you how accurately a test or other measurement method taps into the various aspects of the specific construct you are researching.
In other words, it helps you answer the question: “does the test measure all aspects of the construct I want to measure?” If it does, then the test has high content validity.
The higher the content validity, the more accurate the measurement of the construct.
If the test fails to include parts of the construct, or irrelevant parts are included, the validity of the instrument is threatened, which brings your results into question.
Face validity and content validity are similar in that they both evaluate how suitable the content of a test is. The difference is that face validity is subjective, and assesses content at surface level.
When a test has strong face validity, anyone would agree that the test’s questions appear to measure what they are intended to measure.
For example, looking at a 4th grade math test consisting of problems in which students have to add and multiply, most people would agree that it has strong face validity (i.e., it looks like a math test).
On the other hand, content validity evaluates how well a test represents all the aspects of a topic. Assessing content validity is more systematic and relies on expert evaluation. of each question, analyzing whether each one covers the aspects that the test was designed to cover.
A 4th grade math test would have high content validity if it covered all the skills taught in that grade. Experts(in this case, math teachers), would have to evaluate the content validity by comparing the test to the learning objectives.
Snowball sampling is a non-probability sampling method . Unlike probability sampling (which involves some form of random selection ), the initial individuals selected to be studied are the ones who recruit new participants.
Because not every member of the target population has an equal chance of being recruited into the sample, selection in snowball sampling is non-random.
Snowball sampling is a non-probability sampling method , where there is not an equal chance for every member of the population to be included in the sample .
This means that you cannot use inferential statistics and make generalizations —often the goal of quantitative research . As such, a snowball sample is not representative of the target population and is usually a better fit for qualitative research .
Snowball sampling relies on the use of referrals. Here, the researcher recruits one or more initial participants, who then recruit the next ones.
Participants share similar characteristics and/or know each other. Because of this, not every member of the population has an equal chance of being included in the sample, giving rise to sampling bias .
Snowball sampling is best used in the following cases:
- If there is no sampling frame available (e.g., people with a rare disease)
- If the population of interest is hard to access or locate (e.g., people experiencing homelessness)
- If the research focuses on a sensitive topic (e.g., extramarital affairs)
The reproducibility and replicability of a study can be ensured by writing a transparent, detailed method section and using clear, unambiguous language.
Reproducibility and replicability are related terms.
- Reproducing research entails reanalyzing the existing data in the same manner.
- Replicating (or repeating ) the research entails reconducting the entire analysis, including the collection of new data .
- A successful reproduction shows that the data analyses were conducted in a fair and honest manner.
- A successful replication shows that the reliability of the results is high.
Stratified sampling and quota sampling both involve dividing the population into subgroups and selecting units from each subgroup. The purpose in both cases is to select a representative sample and/or to allow comparisons between subgroups.
The main difference is that in stratified sampling, you draw a random sample from each subgroup ( probability sampling ). In quota sampling you select a predetermined number or proportion of units, in a non-random manner ( non-probability sampling ).
Purposive and convenience sampling are both sampling methods that are typically used in qualitative data collection.
A convenience sample is drawn from a source that is conveniently accessible to the researcher. Convenience sampling does not distinguish characteristics among the participants. On the other hand, purposive sampling focuses on selecting participants possessing characteristics associated with the research study.
The findings of studies based on either convenience or purposive sampling can only be generalized to the (sub)population from which the sample is drawn, and not to the entire population.
Random sampling or probability sampling is based on random selection. This means that each unit has an equal chance (i.e., equal probability) of being included in the sample.
On the other hand, convenience sampling involves stopping people at random, which means that not everyone has an equal chance of being selected depending on the place, time, or day you are collecting your data.
Convenience sampling and quota sampling are both non-probability sampling methods. They both use non-random criteria like availability, geographical proximity, or expert knowledge to recruit study participants.
However, in convenience sampling, you continue to sample units or cases until you reach the required sample size.
In quota sampling, you first need to divide your population of interest into subgroups (strata) and estimate their proportions (quota) in the population. Then you can start your data collection, using convenience sampling to recruit participants, until the proportions in each subgroup coincide with the estimated proportions in the population.
A sampling frame is a list of every member in the entire population . It is important that the sampling frame is as complete as possible, so that your sample accurately reflects your population.
Stratified and cluster sampling may look similar, but bear in mind that groups created in cluster sampling are heterogeneous , so the individual characteristics in the cluster vary. In contrast, groups created in stratified sampling are homogeneous , as units share characteristics.
Relatedly, in cluster sampling you randomly select entire groups and include all units of each group in your sample. However, in stratified sampling, you select some units of all groups and include them in your sample. In this way, both methods can ensure that your sample is representative of the target population .
A systematic review is secondary research because it uses existing research. You don’t collect new data yourself.
The key difference between observational studies and experimental designs is that a well-done observational study does not influence the responses of participants, while experiments do have some sort of treatment condition applied to at least some participants by random assignment .
An observational study is a great choice for you if your research question is based purely on observations. If there are ethical, logistical, or practical concerns that prevent you from conducting a traditional experiment , an observational study may be a good choice. In an observational study, there is no interference or manipulation of the research subjects, as well as no control or treatment groups .
It’s often best to ask a variety of people to review your measurements. You can ask experts, such as other researchers, or laypeople, such as potential participants, to judge the face validity of tests.
While experts have a deep understanding of research methods , the people you’re studying can provide you with valuable insights you may have missed otherwise.
Face validity is important because it’s a simple first step to measuring the overall validity of a test or technique. It’s a relatively intuitive, quick, and easy way to start checking whether a new measure seems useful at first glance.
Good face validity means that anyone who reviews your measure says that it seems to be measuring what it’s supposed to. With poor face validity, someone reviewing your measure may be left confused about what you’re measuring and why you’re using this method.
Face validity is about whether a test appears to measure what it’s supposed to measure. This type of validity is concerned with whether a measure seems relevant and appropriate for what it’s assessing only on the surface.
Statistical analyses are often applied to test validity with data from your measures. You test convergent validity and discriminant validity with correlations to see if results from your test are positively or negatively related to those of other established tests.
You can also use regression analyses to assess whether your measure is actually predictive of outcomes that you expect it to predict theoretically. A regression analysis that supports your expectations strengthens your claim of construct validity .
When designing or evaluating a measure, construct validity helps you ensure you’re actually measuring the construct you’re interested in. If you don’t have construct validity, you may inadvertently measure unrelated or distinct constructs and lose precision in your research.
Construct validity is often considered the overarching type of measurement validity , because it covers all of the other types. You need to have face validity , content validity , and criterion validity to achieve construct validity.
Construct validity is about how well a test measures the concept it was designed to evaluate. It’s one of four types of measurement validity , which includes construct validity, face validity , and criterion validity.
There are two subtypes of construct validity.
- Convergent validity : The extent to which your measure corresponds to measures of related constructs
- Discriminant validity : The extent to which your measure is unrelated or negatively related to measures of distinct constructs
Naturalistic observation is a valuable tool because of its flexibility, external validity , and suitability for topics that can’t be studied in a lab setting.
The downsides of naturalistic observation include its lack of scientific control , ethical considerations , and potential for bias from observers and subjects.
Naturalistic observation is a qualitative research method where you record the behaviors of your research subjects in real world settings. You avoid interfering or influencing anything in a naturalistic observation.
You can think of naturalistic observation as “people watching” with a purpose.
A dependent variable is what changes as a result of the independent variable manipulation in experiments . It’s what you’re interested in measuring, and it “depends” on your independent variable.
In statistics, dependent variables are also called:
- Response variables (they respond to a change in another variable)
- Outcome variables (they represent the outcome you want to measure)
- Left-hand-side variables (they appear on the left-hand side of a regression equation)
An independent variable is the variable you manipulate, control, or vary in an experimental study to explore its effects. It’s called “independent” because it’s not influenced by any other variables in the study.
Independent variables are also called:
- Explanatory variables (they explain an event or outcome)
- Predictor variables (they can be used to predict the value of a dependent variable)
- Right-hand-side variables (they appear on the right-hand side of a regression equation).
As a rule of thumb, questions related to thoughts, beliefs, and feelings work well in focus groups. Take your time formulating strong questions, paying special attention to phrasing. Be careful to avoid leading questions , which can bias your responses.
Overall, your focus group questions should be:
- Open-ended and flexible
- Impossible to answer with “yes” or “no” (questions that start with “why” or “how” are often best)
- Unambiguous, getting straight to the point while still stimulating discussion
- Unbiased and neutral
A structured interview is a data collection method that relies on asking questions in a set order to collect data on a topic. They are often quantitative in nature. Structured interviews are best used when:
- You already have a very clear understanding of your topic. Perhaps significant research has already been conducted, or you have done some prior research yourself, but you already possess a baseline for designing strong structured questions.
- You are constrained in terms of time or resources and need to analyze your data quickly and efficiently.
- Your research question depends on strong parity between participants, with environmental conditions held constant.
More flexible interview options include semi-structured interviews , unstructured interviews , and focus groups .
Social desirability bias is the tendency for interview participants to give responses that will be viewed favorably by the interviewer or other participants. It occurs in all types of interviews and surveys , but is most common in semi-structured interviews , unstructured interviews , and focus groups .
Social desirability bias can be mitigated by ensuring participants feel at ease and comfortable sharing their views. Make sure to pay attention to your own body language and any physical or verbal cues, such as nodding or widening your eyes.
This type of bias can also occur in observations if the participants know they’re being observed. They might alter their behavior accordingly.
The interviewer effect is a type of bias that emerges when a characteristic of an interviewer (race, age, gender identity, etc.) influences the responses given by the interviewee.
There is a risk of an interviewer effect in all types of interviews , but it can be mitigated by writing really high-quality interview questions.
A semi-structured interview is a blend of structured and unstructured types of interviews. Semi-structured interviews are best used when:
- You have prior interview experience. Spontaneous questions are deceptively challenging, and it’s easy to accidentally ask a leading question or make a participant uncomfortable.
- Your research question is exploratory in nature. Participant answers can guide future research questions and help you develop a more robust knowledge base for future research.
An unstructured interview is the most flexible type of interview, but it is not always the best fit for your research topic.
Unstructured interviews are best used when:
- You are an experienced interviewer and have a very strong background in your research topic, since it is challenging to ask spontaneous, colloquial questions.
- Your research question is exploratory in nature. While you may have developed hypotheses, you are open to discovering new or shifting viewpoints through the interview process.
- You are seeking descriptive data, and are ready to ask questions that will deepen and contextualize your initial thoughts and hypotheses.
- Your research depends on forming connections with your participants and making them feel comfortable revealing deeper emotions, lived experiences, or thoughts.
The four most common types of interviews are:
- Structured interviews : The questions are predetermined in both topic and order.
- Semi-structured interviews : A few questions are predetermined, but other questions aren’t planned.
- Unstructured interviews : None of the questions are predetermined.
- Focus group interviews : The questions are presented to a group instead of one individual.
Deductive reasoning is commonly used in scientific research, and it’s especially associated with quantitative research .
In research, you might have come across something called the hypothetico-deductive method . It’s the scientific method of testing hypotheses to check whether your predictions are substantiated by real-world data.
Deductive reasoning is a logical approach where you progress from general ideas to specific conclusions. It’s often contrasted with inductive reasoning , where you start with specific observations and form general conclusions.
Deductive reasoning is also called deductive logic.
There are many different types of inductive reasoning that people use formally or informally.
Here are a few common types:
- Inductive generalization : You use observations about a sample to come to a conclusion about the population it came from.
- Statistical generalization: You use specific numbers about samples to make statements about populations.
- Causal reasoning: You make cause-and-effect links between different things.
- Sign reasoning: You make a conclusion about a correlational relationship between different things.
- Analogical reasoning: You make a conclusion about something based on its similarities to something else.
Inductive reasoning is a bottom-up approach, while deductive reasoning is top-down.
Inductive reasoning takes you from the specific to the general, while in deductive reasoning, you make inferences by going from general premises to specific conclusions.
In inductive research , you start by making observations or gathering data. Then, you take a broad scan of your data and search for patterns. Finally, you make general conclusions that you might incorporate into theories.
Inductive reasoning is a method of drawing conclusions by going from the specific to the general. It’s usually contrasted with deductive reasoning, where you proceed from general information to specific conclusions.
Inductive reasoning is also called inductive logic or bottom-up reasoning.
A hypothesis states your predictions about what your research will find. It is a tentative answer to your research question that has not yet been tested. For some research projects, you might have to write several hypotheses that address different aspects of your research question.
A hypothesis is not just a guess — it should be based on existing theories and knowledge. It also has to be testable, which means you can support or refute it through scientific research methods (such as experiments, observations and statistical analysis of data).
Triangulation can help:
- Reduce research bias that comes from using a single method, theory, or investigator
- Enhance validity by approaching the same topic with different tools
- Establish credibility by giving you a complete picture of the research problem
But triangulation can also pose problems:
- It’s time-consuming and labor-intensive, often involving an interdisciplinary team.
- Your results may be inconsistent or even contradictory.
There are four main types of triangulation :
- Data triangulation : Using data from different times, spaces, and people
- Investigator triangulation : Involving multiple researchers in collecting or analyzing data
- Theory triangulation : Using varying theoretical perspectives in your research
- Methodological triangulation : Using different methodologies to approach the same topic
Many academic fields use peer review , largely to determine whether a manuscript is suitable for publication. Peer review enhances the credibility of the published manuscript.
However, peer review is also common in non-academic settings. The United Nations, the European Union, and many individual nations use peer review to evaluate grant applications. It is also widely used in medical and health-related fields as a teaching or quality-of-care measure.
Peer assessment is often used in the classroom as a pedagogical tool. Both receiving feedback and providing it are thought to enhance the learning process, helping students think critically and collaboratively.
Peer review can stop obviously problematic, falsified, or otherwise untrustworthy research from being published. It also represents an excellent opportunity to get feedback from renowned experts in your field. It acts as a first defense, helping you ensure your argument is clear and that there are no gaps, vague terms, or unanswered questions for readers who weren’t involved in the research process.
Peer-reviewed articles are considered a highly credible source due to this stringent process they go through before publication.
In general, the peer review process follows the following steps:
- First, the author submits the manuscript to the editor.
- Reject the manuscript and send it back to author, or
- Send it onward to the selected peer reviewer(s)
- Next, the peer review process occurs. The reviewer provides feedback, addressing any major or minor issues with the manuscript, and gives their advice regarding what edits should be made.
- Lastly, the edited manuscript is sent back to the author. They input the edits, and resubmit it to the editor for publication.
Exploratory research is often used when the issue you’re studying is new or when the data collection process is challenging for some reason.
You can use exploratory research if you have a general idea or a specific question that you want to study but there is no preexisting knowledge or paradigm with which to study it.
Exploratory research is a methodology approach that explores research questions that have not previously been studied in depth. It is often used when the issue you’re studying is new, or the data collection process is challenging in some way.
Explanatory research is used to investigate how or why a phenomenon occurs. Therefore, this type of research is often one of the first stages in the research process , serving as a jumping-off point for future research.
Exploratory research aims to explore the main aspects of an under-researched problem, while explanatory research aims to explain the causes and consequences of a well-defined problem.
Explanatory research is a research method used to investigate how or why something occurs when only a small amount of information is available pertaining to that topic. It can help you increase your understanding of a given topic.
Clean data are valid, accurate, complete, consistent, unique, and uniform. Dirty data include inconsistencies and errors.
Dirty data can come from any part of the research process, including poor research design , inappropriate measurement materials, or flawed data entry.
Data cleaning takes place between data collection and data analyses. But you can use some methods even before collecting data.
For clean data, you should start by designing measures that collect valid data. Data validation at the time of data entry or collection helps you minimize the amount of data cleaning you’ll need to do.
After data collection, you can use data standardization and data transformation to clean your data. You’ll also deal with any missing values, outliers, and duplicate values.
Every dataset requires different techniques to clean dirty data , but you need to address these issues in a systematic way. You focus on finding and resolving data points that don’t agree or fit with the rest of your dataset.
These data might be missing values, outliers, duplicate values, incorrectly formatted, or irrelevant. You’ll start with screening and diagnosing your data. Then, you’ll often standardize and accept or remove data to make your dataset consistent and valid.
Data cleaning is necessary for valid and appropriate analyses. Dirty data contain inconsistencies or errors , but cleaning your data helps you minimize or resolve these.
Without data cleaning, you could end up with a Type I or II error in your conclusion. These types of erroneous conclusions can be practically significant with important consequences, because they lead to misplaced investments or missed opportunities.
Data cleaning involves spotting and resolving potential data inconsistencies or errors to improve your data quality. An error is any value (e.g., recorded weight) that doesn’t reflect the true value (e.g., actual weight) of something that’s being measured.
In this process, you review, analyze, detect, modify, or remove “dirty” data to make your dataset “clean.” Data cleaning is also called data cleansing or data scrubbing.
Research misconduct means making up or falsifying data, manipulating data analyses, or misrepresenting results in research reports. It’s a form of academic fraud.
These actions are committed intentionally and can have serious consequences; research misconduct is not a simple mistake or a point of disagreement but a serious ethical failure.
Anonymity means you don’t know who the participants are, while confidentiality means you know who they are but remove identifying information from your research report. Both are important ethical considerations .
You can only guarantee anonymity by not collecting any personally identifying information—for example, names, phone numbers, email addresses, IP addresses, physical characteristics, photos, or videos.
You can keep data confidential by using aggregate information in your research report, so that you only refer to groups of participants rather than individuals.
Research ethics matter for scientific integrity, human rights and dignity, and collaboration between science and society. These principles make sure that participation in studies is voluntary, informed, and safe.
Ethical considerations in research are a set of principles that guide your research designs and practices. These principles include voluntary participation, informed consent, anonymity, confidentiality, potential for harm, and results communication.
Scientists and researchers must always adhere to a certain code of conduct when collecting data from others .
These considerations protect the rights of research participants, enhance research validity , and maintain scientific integrity.
In multistage sampling , you can use probability or non-probability sampling methods .
For a probability sample, you have to conduct probability sampling at every stage.
You can mix it up by using simple random sampling , systematic sampling , or stratified sampling to select units at different stages, depending on what is applicable and relevant to your study.
Multistage sampling can simplify data collection when you have large, geographically spread samples, and you can obtain a probability sample without a complete sampling frame.
But multistage sampling may not lead to a representative sample, and larger samples are needed for multistage samples to achieve the statistical properties of simple random samples .
These are four of the most common mixed methods designs :
- Convergent parallel: Quantitative and qualitative data are collected at the same time and analyzed separately. After both analyses are complete, compare your results to draw overall conclusions.
- Embedded: Quantitative and qualitative data are collected at the same time, but within a larger quantitative or qualitative design. One type of data is secondary to the other.
- Explanatory sequential: Quantitative data is collected and analyzed first, followed by qualitative data. You can use this design if you think your qualitative data will explain and contextualize your quantitative findings.
- Exploratory sequential: Qualitative data is collected and analyzed first, followed by quantitative data. You can use this design if you think the quantitative data will confirm or validate your qualitative findings.
Triangulation in research means using multiple datasets, methods, theories and/or investigators to address a research question. It’s a research strategy that can help you enhance the validity and credibility of your findings.
Triangulation is mainly used in qualitative research , but it’s also commonly applied in quantitative research . Mixed methods research always uses triangulation.
In multistage sampling , or multistage cluster sampling, you draw a sample from a population using smaller and smaller groups at each stage.
This method is often used to collect data from a large, geographically spread group of people in national surveys, for example. You take advantage of hierarchical groupings (e.g., from state to city to neighborhood) to create a sample that’s less expensive and time-consuming to collect data from.
No, the steepness or slope of the line isn’t related to the correlation coefficient value. The correlation coefficient only tells you how closely your data fit on a line, so two datasets with the same correlation coefficient can have very different slopes.
To find the slope of the line, you’ll need to perform a regression analysis .
Correlation coefficients always range between -1 and 1.
The sign of the coefficient tells you the direction of the relationship: a positive value means the variables change together in the same direction, while a negative value means they change together in opposite directions.
The absolute value of a number is equal to the number without its sign. The absolute value of a correlation coefficient tells you the magnitude of the correlation: the greater the absolute value, the stronger the correlation.
These are the assumptions your data must meet if you want to use Pearson’s r :
- Both variables are on an interval or ratio level of measurement
- Data from both variables follow normal distributions
- Your data have no outliers
- Your data is from a random or representative sample
- You expect a linear relationship between the two variables
A well-planned research design helps ensure that your methods match your research aims, that you collect high-quality data, and that you use the right kind of analysis to answer your questions, utilizing credible sources . This allows you to draw valid , trustworthy conclusions.
The priorities of a research design can vary depending on the field, but you usually have to specify:
- Your research questions and/or hypotheses
- Your overall approach (e.g., qualitative or quantitative )
- The type of design you’re using (e.g., a survey , experiment , or case study )
- Your sampling methods or criteria for selecting subjects
- Your data collection methods (e.g., questionnaires , observations)
- Your data collection procedures (e.g., operationalization , timing and data management)
- Your data analysis methods (e.g., statistical tests or thematic analysis )
A research design is a strategy for answering your research question . It defines your overall approach and determines how you will collect and analyze data.
Questionnaires can be self-administered or researcher-administered.
Self-administered questionnaires can be delivered online or in paper-and-pen formats, in person or through mail. All questions are standardized so that all respondents receive the same questions with identical wording.
Researcher-administered questionnaires are interviews that take place by phone, in-person, or online between researchers and respondents. You can gain deeper insights by clarifying questions for respondents or asking follow-up questions.
You can organize the questions logically, with a clear progression from simple to complex, or randomly between respondents. A logical flow helps respondents process the questionnaire easier and quicker, but it may lead to bias. Randomization can minimize the bias from order effects.
Closed-ended, or restricted-choice, questions offer respondents a fixed set of choices to select from. These questions are easier to answer quickly.
Open-ended or long-form questions allow respondents to answer in their own words. Because there are no restrictions on their choices, respondents can answer in ways that researchers may not have otherwise considered.
A questionnaire is a data collection tool or instrument, while a survey is an overarching research method that involves collecting and analyzing data from people using questionnaires.
The third variable and directionality problems are two main reasons why correlation isn’t causation .
The third variable problem means that a confounding variable affects both variables to make them seem causally related when they are not.
The directionality problem is when two variables correlate and might actually have a causal relationship, but it’s impossible to conclude which variable causes changes in the other.
Correlation describes an association between variables : when one variable changes, so does the other. A correlation is a statistical indicator of the relationship between variables.
Causation means that changes in one variable brings about changes in the other (i.e., there is a cause-and-effect relationship between variables). The two variables are correlated with each other, and there’s also a causal link between them.
While causation and correlation can exist simultaneously, correlation does not imply causation. In other words, correlation is simply a relationship where A relates to B—but A doesn’t necessarily cause B to happen (or vice versa). Mistaking correlation for causation is a common error and can lead to false cause fallacy .
Controlled experiments establish causality, whereas correlational studies only show associations between variables.
- In an experimental design , you manipulate an independent variable and measure its effect on a dependent variable. Other variables are controlled so they can’t impact the results.
- In a correlational design , you measure variables without manipulating any of them. You can test whether your variables change together, but you can’t be sure that one variable caused a change in another.
In general, correlational research is high in external validity while experimental research is high in internal validity .
A correlation is usually tested for two variables at a time, but you can test correlations between three or more variables.
A correlation coefficient is a single number that describes the strength and direction of the relationship between your variables.
Different types of correlation coefficients might be appropriate for your data based on their levels of measurement and distributions . The Pearson product-moment correlation coefficient (Pearson’s r ) is commonly used to assess a linear relationship between two quantitative variables.
A correlational research design investigates relationships between two variables (or more) without the researcher controlling or manipulating any of them. It’s a non-experimental type of quantitative research .
A correlation reflects the strength and/or direction of the association between two or more variables.
- A positive correlation means that both variables change in the same direction.
- A negative correlation means that the variables change in opposite directions.
- A zero correlation means there’s no relationship between the variables.
Random error is almost always present in scientific studies, even in highly controlled settings. While you can’t eradicate it completely, you can reduce random error by taking repeated measurements, using a large sample, and controlling extraneous variables .
You can avoid systematic error through careful design of your sampling , data collection , and analysis procedures. For example, use triangulation to measure your variables using multiple methods; regularly calibrate instruments or procedures; use random sampling and random assignment ; and apply masking (blinding) where possible.
Systematic error is generally a bigger problem in research.
With random error, multiple measurements will tend to cluster around the true value. When you’re collecting data from a large sample , the errors in different directions will cancel each other out.
Systematic errors are much more problematic because they can skew your data away from the true value. This can lead you to false conclusions ( Type I and II errors ) about the relationship between the variables you’re studying.
Random and systematic error are two types of measurement error.
Random error is a chance difference between the observed and true values of something (e.g., a researcher misreading a weighing scale records an incorrect measurement).
Systematic error is a consistent or proportional difference between the observed and true values of something (e.g., a miscalibrated scale consistently records weights as higher than they actually are).
On graphs, the explanatory variable is conventionally placed on the x-axis, while the response variable is placed on the y-axis.
- If you have quantitative variables , use a scatterplot or a line graph.
- If your response variable is categorical, use a scatterplot or a line graph.
- If your explanatory variable is categorical, use a bar graph.
The term “ explanatory variable ” is sometimes preferred over “ independent variable ” because, in real world contexts, independent variables are often influenced by other variables. This means they aren’t totally independent.
Multiple independent variables may also be correlated with each other, so “explanatory variables” is a more appropriate term.
The difference between explanatory and response variables is simple:
- An explanatory variable is the expected cause, and it explains the results.
- A response variable is the expected effect, and it responds to other variables.
In a controlled experiment , all extraneous variables are held constant so that they can’t influence the results. Controlled experiments require:
- A control group that receives a standard treatment, a fake treatment, or no treatment.
- Random assignment of participants to ensure the groups are equivalent.
Depending on your study topic, there are various other methods of controlling variables .
There are 4 main types of extraneous variables :
- Demand characteristics : environmental cues that encourage participants to conform to researchers’ expectations.
- Experimenter effects : unintentional actions by researchers that influence study outcomes.
- Situational variables : environmental variables that alter participants’ behaviors.
- Participant variables : any characteristic or aspect of a participant’s background that could affect study results.
An extraneous variable is any variable that you’re not investigating that can potentially affect the dependent variable of your research study.
A confounding variable is a type of extraneous variable that not only affects the dependent variable, but is also related to the independent variable.
In a factorial design, multiple independent variables are tested.
If you test two variables, each level of one independent variable is combined with each level of the other independent variable to create different conditions.
Within-subjects designs have many potential threats to internal validity , but they are also very statistically powerful .
Advantages:
- Only requires small samples
- Statistically powerful
- Removes the effects of individual differences on the outcomes
Disadvantages:
- Internal validity threats reduce the likelihood of establishing a direct relationship between variables
- Time-related effects, such as growth, can influence the outcomes
- Carryover effects mean that the specific order of different treatments affect the outcomes
While a between-subjects design has fewer threats to internal validity , it also requires more participants for high statistical power than a within-subjects design .
- Prevents carryover effects of learning and fatigue.
- Shorter study duration.
- Needs larger samples for high power.
- Uses more resources to recruit participants, administer sessions, cover costs, etc.
- Individual differences may be an alternative explanation for results.
Yes. Between-subjects and within-subjects designs can be combined in a single study when you have two or more independent variables (a factorial design). In a mixed factorial design, one variable is altered between subjects and another is altered within subjects.
In a between-subjects design , every participant experiences only one condition, and researchers assess group differences between participants in various conditions.
In a within-subjects design , each participant experiences all conditions, and researchers test the same participants repeatedly for differences between conditions.
The word “between” means that you’re comparing different conditions between groups, while the word “within” means you’re comparing different conditions within the same group.
Random assignment is used in experiments with a between-groups or independent measures design. In this research design, there’s usually a control group and one or more experimental groups. Random assignment helps ensure that the groups are comparable.
In general, you should always use random assignment in this type of experimental design when it is ethically possible and makes sense for your study topic.
To implement random assignment , assign a unique number to every member of your study’s sample .
Then, you can use a random number generator or a lottery method to randomly assign each number to a control or experimental group. You can also do so manually, by flipping a coin or rolling a dice to randomly assign participants to groups.
Random selection, or random sampling , is a way of selecting members of a population for your study’s sample.
In contrast, random assignment is a way of sorting the sample into control and experimental groups.
Random sampling enhances the external validity or generalizability of your results, while random assignment improves the internal validity of your study.
In experimental research, random assignment is a way of placing participants from your sample into different groups using randomization. With this method, every member of the sample has a known or equal chance of being placed in a control group or an experimental group.
“Controlling for a variable” means measuring extraneous variables and accounting for them statistically to remove their effects on other variables.
Researchers often model control variable data along with independent and dependent variable data in regression analyses and ANCOVAs . That way, you can isolate the control variable’s effects from the relationship between the variables of interest.
Control variables help you establish a correlational or causal relationship between variables by enhancing internal validity .
If you don’t control relevant extraneous variables , they may influence the outcomes of your study, and you may not be able to demonstrate that your results are really an effect of your independent variable .
A control variable is any variable that’s held constant in a research study. It’s not a variable of interest in the study, but it’s controlled because it could influence the outcomes.
Including mediators and moderators in your research helps you go beyond studying a simple relationship between two variables for a fuller picture of the real world. They are important to consider when studying complex correlational or causal relationships.
Mediators are part of the causal pathway of an effect, and they tell you how or why an effect takes place. Moderators usually help you judge the external validity of your study by identifying the limitations of when the relationship between variables holds.
If something is a mediating variable :
- It’s caused by the independent variable .
- It influences the dependent variable
- When it’s taken into account, the statistical correlation between the independent and dependent variables is higher than when it isn’t considered.
A confounder is a third variable that affects variables of interest and makes them seem related when they are not. In contrast, a mediator is the mechanism of a relationship between two variables: it explains the process by which they are related.
A mediator variable explains the process through which two variables are related, while a moderator variable affects the strength and direction of that relationship.
There are three key steps in systematic sampling :
- Define and list your population , ensuring that it is not ordered in a cyclical or periodic order.
- Decide on your sample size and calculate your interval, k , by dividing your population by your target sample size.
- Choose every k th member of the population as your sample.
Systematic sampling is a probability sampling method where researchers select members of the population at a regular interval – for example, by selecting every 15th person on a list of the population. If the population is in a random order, this can imitate the benefits of simple random sampling .
Yes, you can create a stratified sample using multiple characteristics, but you must ensure that every participant in your study belongs to one and only one subgroup. In this case, you multiply the numbers of subgroups for each characteristic to get the total number of groups.
For example, if you were stratifying by location with three subgroups (urban, rural, or suburban) and marital status with five subgroups (single, divorced, widowed, married, or partnered), you would have 3 x 5 = 15 subgroups.
You should use stratified sampling when your sample can be divided into mutually exclusive and exhaustive subgroups that you believe will take on different mean values for the variable that you’re studying.
Using stratified sampling will allow you to obtain more precise (with lower variance ) statistical estimates of whatever you are trying to measure.
For example, say you want to investigate how income differs based on educational attainment, but you know that this relationship can vary based on race. Using stratified sampling, you can ensure you obtain a large enough sample from each racial group, allowing you to draw more precise conclusions.
In stratified sampling , researchers divide subjects into subgroups called strata based on characteristics that they share (e.g., race, gender, educational attainment).
Once divided, each subgroup is randomly sampled using another probability sampling method.
Cluster sampling is more time- and cost-efficient than other probability sampling methods , particularly when it comes to large samples spread across a wide geographical area.
However, it provides less statistical certainty than other methods, such as simple random sampling , because it is difficult to ensure that your clusters properly represent the population as a whole.
There are three types of cluster sampling : single-stage, double-stage and multi-stage clustering. In all three types, you first divide the population into clusters, then randomly select clusters for use in your sample.
- In single-stage sampling , you collect data from every unit within the selected clusters.
- In double-stage sampling , you select a random sample of units from within the clusters.
- In multi-stage sampling , you repeat the procedure of randomly sampling elements from within the clusters until you have reached a manageable sample.
Cluster sampling is a probability sampling method in which you divide a population into clusters, such as districts or schools, and then randomly select some of these clusters as your sample.
The clusters should ideally each be mini-representations of the population as a whole.
If properly implemented, simple random sampling is usually the best sampling method for ensuring both internal and external validity . However, it can sometimes be impractical and expensive to implement, depending on the size of the population to be studied,
If you have a list of every member of the population and the ability to reach whichever members are selected, you can use simple random sampling.
The American Community Survey is an example of simple random sampling . In order to collect detailed data on the population of the US, the Census Bureau officials randomly select 3.5 million households per year and use a variety of methods to convince them to fill out the survey.
Simple random sampling is a type of probability sampling in which the researcher randomly selects a subset of participants from a population . Each member of the population has an equal chance of being selected. Data is then collected from as large a percentage as possible of this random subset.
Quasi-experimental design is most useful in situations where it would be unethical or impractical to run a true experiment .
Quasi-experiments have lower internal validity than true experiments, but they often have higher external validity as they can use real-world interventions instead of artificial laboratory settings.
A quasi-experiment is a type of research design that attempts to establish a cause-and-effect relationship. The main difference with a true experiment is that the groups are not randomly assigned.
Blinding is important to reduce research bias (e.g., observer bias , demand characteristics ) and ensure a study’s internal validity .
If participants know whether they are in a control or treatment group , they may adjust their behavior in ways that affect the outcome that researchers are trying to measure. If the people administering the treatment are aware of group assignment, they may treat participants differently and thus directly or indirectly influence the final results.
- In a single-blind study , only the participants are blinded.
- In a double-blind study , both participants and experimenters are blinded.
- In a triple-blind study , the assignment is hidden not only from participants and experimenters, but also from the researchers analyzing the data.
Blinding means hiding who is assigned to the treatment group and who is assigned to the control group in an experiment .
A true experiment (a.k.a. a controlled experiment) always includes at least one control group that doesn’t receive the experimental treatment.
However, some experiments use a within-subjects design to test treatments without a control group. In these designs, you usually compare one group’s outcomes before and after a treatment (instead of comparing outcomes between different groups).
For strong internal validity , it’s usually best to include a control group if possible. Without a control group, it’s harder to be certain that the outcome was caused by the experimental treatment and not by other variables.
An experimental group, also known as a treatment group, receives the treatment whose effect researchers wish to study, whereas a control group does not. They should be identical in all other ways.
Individual Likert-type questions are generally considered ordinal data , because the items have clear rank order, but don’t have an even distribution.
Overall Likert scale scores are sometimes treated as interval data. These scores are considered to have directionality and even spacing between them.
The type of data determines what statistical tests you should use to analyze your data.
A Likert scale is a rating scale that quantitatively assesses opinions, attitudes, or behaviors. It is made up of 4 or more questions that measure a single attitude or trait when response scores are combined.
To use a Likert scale in a survey , you present participants with Likert-type questions or statements, and a continuum of items, usually with 5 or 7 possible responses, to capture their degree of agreement.
In scientific research, concepts are the abstract ideas or phenomena that are being studied (e.g., educational achievement). Variables are properties or characteristics of the concept (e.g., performance at school), while indicators are ways of measuring or quantifying variables (e.g., yearly grade reports).
The process of turning abstract concepts into measurable variables and indicators is called operationalization .
There are various approaches to qualitative data analysis , but they all share five steps in common:
- Prepare and organize your data.
- Review and explore your data.
- Develop a data coding system.
- Assign codes to the data.
- Identify recurring themes.
The specifics of each step depend on the focus of the analysis. Some common approaches include textual analysis , thematic analysis , and discourse analysis .
There are five common approaches to qualitative research :
- Grounded theory involves collecting data in order to develop new theories.
- Ethnography involves immersing yourself in a group or organization to understand its culture.
- Narrative research involves interpreting stories to understand how people make sense of their experiences and perceptions.
- Phenomenological research involves investigating phenomena through people’s lived experiences.
- Action research links theory and practice in several cycles to drive innovative changes.
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics. It is used by scientists to test specific predictions, called hypotheses , by calculating how likely it is that a pattern or relationship between variables could have arisen by chance.
Operationalization means turning abstract conceptual ideas into measurable observations.
For example, the concept of social anxiety isn’t directly observable, but it can be operationally defined in terms of self-rating scores, behavioral avoidance of crowded places, or physical anxiety symptoms in social situations.
Before collecting data , it’s important to consider how you will operationalize the variables that you want to measure.
When conducting research, collecting original data has significant advantages:
- You can tailor data collection to your specific research aims (e.g. understanding the needs of your consumers or user testing your website)
- You can control and standardize the process for high reliability and validity (e.g. choosing appropriate measurements and sampling methods )
However, there are also some drawbacks: data collection can be time-consuming, labor-intensive and expensive. In some cases, it’s more efficient to use secondary data that has already been collected by someone else, but the data might be less reliable.
Data collection is the systematic process by which observations or measurements are gathered in research. It is used in many different contexts by academics, governments, businesses, and other organizations.
There are several methods you can use to decrease the impact of confounding variables on your research: restriction, matching, statistical control and randomization.
In restriction , you restrict your sample by only including certain subjects that have the same values of potential confounding variables.
In matching , you match each of the subjects in your treatment group with a counterpart in the comparison group. The matched subjects have the same values on any potential confounding variables, and only differ in the independent variable .
In statistical control , you include potential confounders as variables in your regression .
In randomization , you randomly assign the treatment (or independent variable) in your study to a sufficiently large number of subjects, which allows you to control for all potential confounding variables.
A confounding variable is closely related to both the independent and dependent variables in a study. An independent variable represents the supposed cause , while the dependent variable is the supposed effect . A confounding variable is a third variable that influences both the independent and dependent variables.
Failing to account for confounding variables can cause you to wrongly estimate the relationship between your independent and dependent variables.
To ensure the internal validity of your research, you must consider the impact of confounding variables. If you fail to account for them, you might over- or underestimate the causal relationship between your independent and dependent variables , or even find a causal relationship where none exists.
Yes, but including more than one of either type requires multiple research questions .
For example, if you are interested in the effect of a diet on health, you can use multiple measures of health: blood sugar, blood pressure, weight, pulse, and many more. Each of these is its own dependent variable with its own research question.
You could also choose to look at the effect of exercise levels as well as diet, or even the additional effect of the two combined. Each of these is a separate independent variable .
To ensure the internal validity of an experiment , you should only change one independent variable at a time.
No. The value of a dependent variable depends on an independent variable, so a variable cannot be both independent and dependent at the same time. It must be either the cause or the effect, not both!
You want to find out how blood sugar levels are affected by drinking diet soda and regular soda, so you conduct an experiment .
- The type of soda – diet or regular – is the independent variable .
- The level of blood sugar that you measure is the dependent variable – it changes depending on the type of soda.
Determining cause and effect is one of the most important parts of scientific research. It’s essential to know which is the cause – the independent variable – and which is the effect – the dependent variable.
In non-probability sampling , the sample is selected based on non-random criteria, and not every member of the population has a chance of being included.
Common non-probability sampling methods include convenience sampling , voluntary response sampling, purposive sampling , snowball sampling, and quota sampling .
Probability sampling means that every member of the target population has a known chance of being included in the sample.
Probability sampling methods include simple random sampling , systematic sampling , stratified sampling , and cluster sampling .
Using careful research design and sampling procedures can help you avoid sampling bias . Oversampling can be used to correct undercoverage bias .
Some common types of sampling bias include self-selection bias , nonresponse bias , undercoverage bias , survivorship bias , pre-screening or advertising bias, and healthy user bias.
Sampling bias is a threat to external validity – it limits the generalizability of your findings to a broader group of people.
A sampling error is the difference between a population parameter and a sample statistic .
A statistic refers to measures about the sample , while a parameter refers to measures about the population .
Populations are used when a research question requires data from every member of the population. This is usually only feasible when the population is small and easily accessible.
Samples are used to make inferences about populations . Samples are easier to collect data from because they are practical, cost-effective, convenient, and manageable.
There are seven threats to external validity : selection bias , history, experimenter effect, Hawthorne effect , testing effect, aptitude-treatment and situation effect.
The two types of external validity are population validity (whether you can generalize to other groups of people) and ecological validity (whether you can generalize to other situations and settings).
The external validity of a study is the extent to which you can generalize your findings to different groups of people, situations, and measures.
Cross-sectional studies cannot establish a cause-and-effect relationship or analyze behavior over a period of time. To investigate cause and effect, you need to do a longitudinal study or an experimental study .
Cross-sectional studies are less expensive and time-consuming than many other types of study. They can provide useful insights into a population’s characteristics and identify correlations for further research.
Sometimes only cross-sectional data is available for analysis; other times your research question may only require a cross-sectional study to answer it.
Longitudinal studies can last anywhere from weeks to decades, although they tend to be at least a year long.
The 1970 British Cohort Study , which has collected data on the lives of 17,000 Brits since their births in 1970, is one well-known example of a longitudinal study .
Longitudinal studies are better to establish the correct sequence of events, identify changes over time, and provide insight into cause-and-effect relationships, but they also tend to be more expensive and time-consuming than other types of studies.
Longitudinal studies and cross-sectional studies are two different types of research design . In a cross-sectional study you collect data from a population at a specific point in time; in a longitudinal study you repeatedly collect data from the same sample over an extended period of time.
| Longitudinal study | Cross-sectional study |
|---|---|
| observations | Observations at a in time |
| Observes the multiple times | Observes (a “cross-section”) in the population |
| Follows in participants over time | Provides of society at a given point |
There are eight threats to internal validity : history, maturation, instrumentation, testing, selection bias , regression to the mean, social interaction and attrition .
Internal validity is the extent to which you can be confident that a cause-and-effect relationship established in a study cannot be explained by other factors.
In mixed methods research , you use both qualitative and quantitative data collection and analysis methods to answer your research question .
The research methods you use depend on the type of data you need to answer your research question .
- If you want to measure something or test a hypothesis , use quantitative methods . If you want to explore ideas, thoughts and meanings, use qualitative methods .
- If you want to analyze a large amount of readily-available data, use secondary data. If you want data specific to your purposes with control over how it is generated, collect primary data.
- If you want to establish cause-and-effect relationships between variables , use experimental methods. If you want to understand the characteristics of a research subject, use descriptive methods.
A confounding variable , also called a confounder or confounding factor, is a third variable in a study examining a potential cause-and-effect relationship.
A confounding variable is related to both the supposed cause and the supposed effect of the study. It can be difficult to separate the true effect of the independent variable from the effect of the confounding variable.
In your research design , it’s important to identify potential confounding variables and plan how you will reduce their impact.
Discrete and continuous variables are two types of quantitative variables :
- Discrete variables represent counts (e.g. the number of objects in a collection).
- Continuous variables represent measurable amounts (e.g. water volume or weight).
Quantitative variables are any variables where the data represent amounts (e.g. height, weight, or age).
Categorical variables are any variables where the data represent groups. This includes rankings (e.g. finishing places in a race), classifications (e.g. brands of cereal), and binary outcomes (e.g. coin flips).
You need to know what type of variables you are working with to choose the right statistical test for your data and interpret your results .
You can think of independent and dependent variables in terms of cause and effect: an independent variable is the variable you think is the cause , while a dependent variable is the effect .
In an experiment, you manipulate the independent variable and measure the outcome in the dependent variable. For example, in an experiment about the effect of nutrients on crop growth:
- The independent variable is the amount of nutrients added to the crop field.
- The dependent variable is the biomass of the crops at harvest time.
Defining your variables, and deciding how you will manipulate and measure them, is an important part of experimental design .
Experimental design means planning a set of procedures to investigate a relationship between variables . To design a controlled experiment, you need:
- A testable hypothesis
- At least one independent variable that can be precisely manipulated
- At least one dependent variable that can be precisely measured
When designing the experiment, you decide:
- How you will manipulate the variable(s)
- How you will control for any potential confounding variables
- How many subjects or samples will be included in the study
- How subjects will be assigned to treatment levels
Experimental design is essential to the internal and external validity of your experiment.
I nternal validity is the degree of confidence that the causal relationship you are testing is not influenced by other factors or variables .
External validity is the extent to which your results can be generalized to other contexts.
The validity of your experiment depends on your experimental design .
Reliability and validity are both about how well a method measures something:
- Reliability refers to the consistency of a measure (whether the results can be reproduced under the same conditions).
- Validity refers to the accuracy of a measure (whether the results really do represent what they are supposed to measure).
If you are doing experimental research, you also have to consider the internal and external validity of your experiment.
A sample is a subset of individuals from a larger population . Sampling means selecting the group that you will actually collect data from in your research. For example, if you are researching the opinions of students in your university, you could survey a sample of 100 students.
In statistics, sampling allows you to test a hypothesis about the characteristics of a population.
Quantitative research deals with numbers and statistics, while qualitative research deals with words and meanings.
Quantitative methods allow you to systematically measure variables and test hypotheses . Qualitative methods allow you to explore concepts and experiences in more detail.
Methodology refers to the overarching strategy and rationale of your research project . It involves studying the methods used in your field and the theories or principles behind them, in order to develop an approach that matches your objectives.
Methods are the specific tools and procedures you use to collect and analyze data (for example, experiments, surveys , and statistical tests ).
In shorter scientific papers, where the aim is to report the findings of a specific study, you might simply describe what you did in a methods section .
In a longer or more complex research project, such as a thesis or dissertation , you will probably include a methodology section , where you explain your approach to answering the research questions and cite relevant sources to support your choice of methods.
Ask our team
Want to contact us directly? No problem. We are always here for you.
- Email [email protected]
- Start live chat
- Call +1 (510) 822-8066
- WhatsApp +31 20 261 6040
 quizlet")
Our team helps students graduate by offering:
- A world-class citation generator
- Plagiarism Checker software powered by Turnitin
- Innovative Citation Checker software
- Professional proofreading services
- Over 300 helpful articles about academic writing, citing sources, plagiarism, and more
Scribbr specializes in editing study-related documents . We proofread:
- PhD dissertations
- Research proposals
- Personal statements
- Admission essays
- Motivation letters
- Reflection papers
- Journal articles
- Capstone projects
Scribbr’s Plagiarism Checker is powered by elements of Turnitin’s Similarity Checker , namely the plagiarism detection software and the Internet Archive and Premium Scholarly Publications content databases .
The add-on AI detector is powered by Scribbr’s proprietary software.
The Scribbr Citation Generator is developed using the open-source Citation Style Language (CSL) project and Frank Bennett’s citeproc-js . It’s the same technology used by dozens of other popular citation tools, including Mendeley and Zotero.
You can find all the citation styles and locales used in the Scribbr Citation Generator in our publicly accessible repository on Github .
- Privacy Policy
Home » Research Design – Types, Methods and Examples
Research Design – Types, Methods and Examples
Table of Contents
 quizlet")
Research Design
Definition:
Research design refers to the overall strategy or plan for conducting a research study. It outlines the methods and procedures that will be used to collect and analyze data, as well as the goals and objectives of the study. Research design is important because it guides the entire research process and ensures that the study is conducted in a systematic and rigorous manner.
Types of Research Design
Types of Research Design are as follows:
Descriptive Research Design
This type of research design is used to describe a phenomenon or situation. It involves collecting data through surveys, questionnaires, interviews, and observations. The aim of descriptive research is to provide an accurate and detailed portrayal of a particular group, event, or situation. It can be useful in identifying patterns, trends, and relationships in the data.
Correlational Research Design
Correlational research design is used to determine if there is a relationship between two or more variables. This type of research design involves collecting data from participants and analyzing the relationship between the variables using statistical methods. The aim of correlational research is to identify the strength and direction of the relationship between the variables.
Experimental Research Design
Experimental research design is used to investigate cause-and-effect relationships between variables. This type of research design involves manipulating one variable and measuring the effect on another variable. It usually involves randomly assigning participants to groups and manipulating an independent variable to determine its effect on a dependent variable. The aim of experimental research is to establish causality.
Quasi-experimental Research Design
Quasi-experimental research design is similar to experimental research design, but it lacks one or more of the features of a true experiment. For example, there may not be random assignment to groups or a control group. This type of research design is used when it is not feasible or ethical to conduct a true experiment.
Case Study Research Design
Case study research design is used to investigate a single case or a small number of cases in depth. It involves collecting data through various methods, such as interviews, observations, and document analysis. The aim of case study research is to provide an in-depth understanding of a particular case or situation.
Longitudinal Research Design
Longitudinal research design is used to study changes in a particular phenomenon over time. It involves collecting data at multiple time points and analyzing the changes that occur. The aim of longitudinal research is to provide insights into the development, growth, or decline of a particular phenomenon over time.
Structure of Research Design
The format of a research design typically includes the following sections:
- Introduction : This section provides an overview of the research problem, the research questions, and the importance of the study. It also includes a brief literature review that summarizes previous research on the topic and identifies gaps in the existing knowledge.
- Research Questions or Hypotheses: This section identifies the specific research questions or hypotheses that the study will address. These questions should be clear, specific, and testable.
- Research Methods : This section describes the methods that will be used to collect and analyze data. It includes details about the study design, the sampling strategy, the data collection instruments, and the data analysis techniques.
- Data Collection: This section describes how the data will be collected, including the sample size, data collection procedures, and any ethical considerations.
- Data Analysis: This section describes how the data will be analyzed, including the statistical techniques that will be used to test the research questions or hypotheses.
- Results : This section presents the findings of the study, including descriptive statistics and statistical tests.
- Discussion and Conclusion : This section summarizes the key findings of the study, interprets the results, and discusses the implications of the findings. It also includes recommendations for future research.
- References : This section lists the sources cited in the research design.
Example of Research Design
An Example of Research Design could be:
Research question: Does the use of social media affect the academic performance of high school students?
Research design:
- Research approach : The research approach will be quantitative as it involves collecting numerical data to test the hypothesis.
- Research design : The research design will be a quasi-experimental design, with a pretest-posttest control group design.
- Sample : The sample will be 200 high school students from two schools, with 100 students in the experimental group and 100 students in the control group.
- Data collection : The data will be collected through surveys administered to the students at the beginning and end of the academic year. The surveys will include questions about their social media usage and academic performance.
- Data analysis : The data collected will be analyzed using statistical software. The mean scores of the experimental and control groups will be compared to determine whether there is a significant difference in academic performance between the two groups.
- Limitations : The limitations of the study will be acknowledged, including the fact that social media usage can vary greatly among individuals, and the study only focuses on two schools, which may not be representative of the entire population.
- Ethical considerations: Ethical considerations will be taken into account, such as obtaining informed consent from the participants and ensuring their anonymity and confidentiality.
How to Write Research Design
Writing a research design involves planning and outlining the methodology and approach that will be used to answer a research question or hypothesis. Here are some steps to help you write a research design:
- Define the research question or hypothesis : Before beginning your research design, you should clearly define your research question or hypothesis. This will guide your research design and help you select appropriate methods.
- Select a research design: There are many different research designs to choose from, including experimental, survey, case study, and qualitative designs. Choose a design that best fits your research question and objectives.
- Develop a sampling plan : If your research involves collecting data from a sample, you will need to develop a sampling plan. This should outline how you will select participants and how many participants you will include.
- Define variables: Clearly define the variables you will be measuring or manipulating in your study. This will help ensure that your results are meaningful and relevant to your research question.
- Choose data collection methods : Decide on the data collection methods you will use to gather information. This may include surveys, interviews, observations, experiments, or secondary data sources.
- Create a data analysis plan: Develop a plan for analyzing your data, including the statistical or qualitative techniques you will use.
- Consider ethical concerns : Finally, be sure to consider any ethical concerns related to your research, such as participant confidentiality or potential harm.
When to Write Research Design
Research design should be written before conducting any research study. It is an important planning phase that outlines the research methodology, data collection methods, and data analysis techniques that will be used to investigate a research question or problem. The research design helps to ensure that the research is conducted in a systematic and logical manner, and that the data collected is relevant and reliable.
Ideally, the research design should be developed as early as possible in the research process, before any data is collected. This allows the researcher to carefully consider the research question, identify the most appropriate research methodology, and plan the data collection and analysis procedures in advance. By doing so, the research can be conducted in a more efficient and effective manner, and the results are more likely to be valid and reliable.
Purpose of Research Design
The purpose of research design is to plan and structure a research study in a way that enables the researcher to achieve the desired research goals with accuracy, validity, and reliability. Research design is the blueprint or the framework for conducting a study that outlines the methods, procedures, techniques, and tools for data collection and analysis.
Some of the key purposes of research design include:
- Providing a clear and concise plan of action for the research study.
- Ensuring that the research is conducted ethically and with rigor.
- Maximizing the accuracy and reliability of the research findings.
- Minimizing the possibility of errors, biases, or confounding variables.
- Ensuring that the research is feasible, practical, and cost-effective.
- Determining the appropriate research methodology to answer the research question(s).
- Identifying the sample size, sampling method, and data collection techniques.
- Determining the data analysis method and statistical tests to be used.
- Facilitating the replication of the study by other researchers.
- Enhancing the validity and generalizability of the research findings.
Applications of Research Design
There are numerous applications of research design in various fields, some of which are:
- Social sciences: In fields such as psychology, sociology, and anthropology, research design is used to investigate human behavior and social phenomena. Researchers use various research designs, such as experimental, quasi-experimental, and correlational designs, to study different aspects of social behavior.
- Education : Research design is essential in the field of education to investigate the effectiveness of different teaching methods and learning strategies. Researchers use various designs such as experimental, quasi-experimental, and case study designs to understand how students learn and how to improve teaching practices.
- Health sciences : In the health sciences, research design is used to investigate the causes, prevention, and treatment of diseases. Researchers use various designs, such as randomized controlled trials, cohort studies, and case-control studies, to study different aspects of health and healthcare.
- Business : Research design is used in the field of business to investigate consumer behavior, marketing strategies, and the impact of different business practices. Researchers use various designs, such as survey research, experimental research, and case studies, to study different aspects of the business world.
- Engineering : In the field of engineering, research design is used to investigate the development and implementation of new technologies. Researchers use various designs, such as experimental research and case studies, to study the effectiveness of new technologies and to identify areas for improvement.
Advantages of Research Design
Here are some advantages of research design:
- Systematic and organized approach : A well-designed research plan ensures that the research is conducted in a systematic and organized manner, which makes it easier to manage and analyze the data.
- Clear objectives: The research design helps to clarify the objectives of the study, which makes it easier to identify the variables that need to be measured, and the methods that need to be used to collect and analyze data.
- Minimizes bias: A well-designed research plan minimizes the chances of bias, by ensuring that the data is collected and analyzed objectively, and that the results are not influenced by the researcher’s personal biases or preferences.
- Efficient use of resources: A well-designed research plan helps to ensure that the resources (time, money, and personnel) are used efficiently and effectively, by focusing on the most important variables and methods.
- Replicability: A well-designed research plan makes it easier for other researchers to replicate the study, which enhances the credibility and reliability of the findings.
- Validity: A well-designed research plan helps to ensure that the findings are valid, by ensuring that the methods used to collect and analyze data are appropriate for the research question.
- Generalizability : A well-designed research plan helps to ensure that the findings can be generalized to other populations, settings, or situations, which increases the external validity of the study.
Research Design Vs Research Methodology
| Research Design | Research Methodology |
|---|---|
| The plan and structure for conducting research that outlines the procedures to be followed to collect and analyze data. | The set of principles, techniques, and tools used to carry out the research plan and achieve research objectives. |
| Describes the overall approach and strategy used to conduct research, including the type of data to be collected, the sources of data, and the methods for collecting and analyzing data. | Refers to the techniques and methods used to gather, analyze and interpret data, including sampling techniques, data collection methods, and data analysis techniques. |
| Helps to ensure that the research is conducted in a systematic, rigorous, and valid way, so that the results are reliable and can be used to make sound conclusions. | Includes a set of procedures and tools that enable researchers to collect and analyze data in a consistent and valid manner, regardless of the research design used. |
| Common research designs include experimental, quasi-experimental, correlational, and descriptive studies. | Common research methodologies include qualitative, quantitative, and mixed-methods approaches. |
| Determines the overall structure of the research project and sets the stage for the selection of appropriate research methodologies. | Guides the researcher in selecting the most appropriate research methods based on the research question, research design, and other contextual factors. |
| Helps to ensure that the research project is feasible, relevant, and ethical. | Helps to ensure that the data collected is accurate, valid, and reliable, and that the research findings can be interpreted and generalized to the population of interest. |
About the author
 quizlet")
Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like
 quizlet")
Appendices – Writing Guide, Types and Examples
 quizlet")
Figures in Research Paper – Examples and Guide
 quizlet")
Problem Statement – Writing Guide, Examples and...
 quizlet")
Tables in Research Paper – Types, Creating Guide...
 quizlet")
Dissertation vs Thesis – Key Differences
 quizlet")
Research Topics – Ideas and Examples
Leave a comment x.
Save my name, email, and website in this browser for the next time I comment.
Have an account?
 quizlet")
Research Design
English, social studies.
 quizlet")
10 questions
Introducing new Paper mode
No student devices needed. Know more
A research design is a blueprint for the collection, measurement, and analysis of data, based on _____ of the study
the purpose
the research questions
the introduction
An exploratory study is undertaken when not much is known about _____ at hand, or no information is available on how similar problems have been solved in the past.
the situation
the characteristics
Examples of exploratory research design EXCEPT:
A study into the role of social networking sites as an effective marketing communication channel
An investigation into the ways of improvement of quality of customer services within hospitality sector in London
Market researchers that want to observe habits of consumers.
Exploratory research often relies on _____ research such as review of the literature and/or _____ approaches to data gathering.
primary, quantitative
secondary, quantitative
primary, qualitative
secondary, qualitative
Descriptive research's objective is to _____.
Descriptive studies may help the research to EXCEPT:
Understand the characteristics of a group in a given situation.
Think systematically about aspects in a given situation.
Explore new areas of research.
TWO examples of descriptive research:
A specialty food group launching a new range of barbecue rubs would like to understand what flavors of rubs are favored by different sets of people.
An assessment of the role of corporate social responsibility on consumer behavior in pharmaceutical industry in the USA.
A company that wants to evaluate the morale of its staff.
TWO advantages of descriptive research design:
Effective in laying the groundwork that will lead to future studies.
The opportunity to integrate the qualitative and quantitative methods of data collection
Helping the researcher to understand the characteristics of a group
Causal research tests whether or not one variable causes another to change.
Examples of research objectives for causal research design EXCEPT:
To assess the impacts of foreign direct investment on the levels of economic growth in Taiwan.
To analyse the effects of re-branding initiatives on the levels of customer loyalty.
To investigate the work ethic values of employees working in branch A are different from those in branch B.
Explore all questions with a free account
Continue with email
Continue with phone
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
5 Research design
Research design is a comprehensive plan for data collection in an empirical research project. It is a ‘blueprint’ for empirical research aimed at answering specific research questions or testing specific hypotheses, and must specify at least three processes: the data collection process, the instrument development process, and the sampling process. The instrument development and sampling processes are described in the next two chapters, and the data collection process—which is often loosely called ‘research design’—is introduced in this chapter and is described in further detail in Chapters 9–12.
Broadly speaking, data collection methods can be grouped into two categories: positivist and interpretive. Positivist methods , such as laboratory experiments and survey research, are aimed at theory (or hypotheses) testing, while interpretive methods, such as action research and ethnography, are aimed at theory building. Positivist methods employ a deductive approach to research, starting with a theory and testing theoretical postulates using empirical data. In contrast, interpretive methods employ an inductive approach that starts with data and tries to derive a theory about the phenomenon of interest from the observed data. Often times, these methods are incorrectly equated with quantitative and qualitative research. Quantitative and qualitative methods refers to the type of data being collected—quantitative data involve numeric scores, metrics, and so on, while qualitative data includes interviews, observations, and so forth—and analysed (i.e., using quantitative techniques such as regression or qualitative techniques such as coding). Positivist research uses predominantly quantitative data, but can also use qualitative data. Interpretive research relies heavily on qualitative data, but can sometimes benefit from including quantitative data as well. Sometimes, joint use of qualitative and quantitative data may help generate unique insight into a complex social phenomenon that is not available from either type of data alone, and hence, mixed-mode designs that combine qualitative and quantitative data are often highly desirable.
Key attributes of a research design
The quality of research designs can be defined in terms of four key design attributes: internal validity, external validity, construct validity, and statistical conclusion validity.
Internal validity , also called causality, examines whether the observed change in a dependent variable is indeed caused by a corresponding change in a hypothesised independent variable, and not by variables extraneous to the research context. Causality requires three conditions: covariation of cause and effect (i.e., if cause happens, then effect also happens; if cause does not happen, effect does not happen), temporal precedence (cause must precede effect in time), and spurious correlation, or there is no plausible alternative explanation for the change. Certain research designs, such as laboratory experiments, are strong in internal validity by virtue of their ability to manipulate the independent variable (cause) via a treatment and observe the effect (dependent variable) of that treatment after a certain point in time, while controlling for the effects of extraneous variables. Other designs, such as field surveys, are poor in internal validity because of their inability to manipulate the independent variable (cause), and because cause and effect are measured at the same point in time which defeats temporal precedence making it equally likely that the expected effect might have influenced the expected cause rather than the reverse. Although higher in internal validity compared to other methods, laboratory experiments are by no means immune to threats of internal validity, and are susceptible to history, testing, instrumentation, regression, and other threats that are discussed later in the chapter on experimental designs. Nonetheless, different research designs vary considerably in their respective level of internal validity.
External validity or generalisability refers to whether the observed associations can be generalised from the sample to the population (population validity), or to other people, organisations, contexts, or time (ecological validity). For instance, can results drawn from a sample of financial firms in the United States be generalised to the population of financial firms (population validity) or to other firms within the United States (ecological validity)? Survey research, where data is sourced from a wide variety of individuals, firms, or other units of analysis, tends to have broader generalisability than laboratory experiments where treatments and extraneous variables are more controlled. The variation in internal and external validity for a wide range of research designs is shown in Figure 5.1.
 quizlet")
Some researchers claim that there is a trade-off between internal and external validity—higher external validity can come only at the cost of internal validity and vice versa. But this is not always the case. Research designs such as field experiments, longitudinal field surveys, and multiple case studies have higher degrees of both internal and external validities. Personally, I prefer research designs that have reasonable degrees of both internal and external validities, i.e., those that fall within the cone of validity shown in Figure 5.1. But this should not suggest that designs outside this cone are any less useful or valuable. Researchers’ choice of designs are ultimately a matter of their personal preference and competence, and the level of internal and external validity they desire.
Construct validity examines how well a given measurement scale is measuring the theoretical construct that it is expected to measure. Many constructs used in social science research such as empathy, resistance to change, and organisational learning are difficult to define, much less measure. For instance, construct validity must ensure that a measure of empathy is indeed measuring empathy and not compassion, which may be difficult since these constructs are somewhat similar in meaning. Construct validity is assessed in positivist research based on correlational or factor analysis of pilot test data, as described in the next chapter.
Statistical conclusion validity examines the extent to which conclusions derived using a statistical procedure are valid. For example, it examines whether the right statistical method was used for hypotheses testing, whether the variables used meet the assumptions of that statistical test (such as sample size or distributional requirements), and so forth. Because interpretive research designs do not employ statistical tests, statistical conclusion validity is not applicable for such analysis. The different kinds of validity and where they exist at the theoretical/empirical levels are illustrated in Figure 5.2.
 quizlet")
Improving internal and external validity
The best research designs are those that can ensure high levels of internal and external validity. Such designs would guard against spurious correlations, inspire greater faith in the hypotheses testing, and ensure that the results drawn from a small sample are generalisable to the population at large. Controls are required to ensure internal validity (causality) of research designs, and can be accomplished in five ways: manipulation, elimination, inclusion, and statistical control, and randomisation.
In manipulation , the researcher manipulates the independent variables in one or more levels (called ‘treatments’), and compares the effects of the treatments against a control group where subjects do not receive the treatment. Treatments may include a new drug or different dosage of drug (for treating a medical condition), a teaching style (for students), and so forth. This type of control is achieved in experimental or quasi-experimental designs, but not in non-experimental designs such as surveys. Note that if subjects cannot distinguish adequately between different levels of treatment manipulations, their responses across treatments may not be different, and manipulation would fail.
The elimination technique relies on eliminating extraneous variables by holding them constant across treatments, such as by restricting the study to a single gender or a single socioeconomic status. In the inclusion technique, the role of extraneous variables is considered by including them in the research design and separately estimating their effects on the dependent variable, such as via factorial designs where one factor is gender (male versus female). Such technique allows for greater generalisability, but also requires substantially larger samples. In statistical control , extraneous variables are measured and used as covariates during the statistical testing process.
Finally, the randomisation technique is aimed at cancelling out the effects of extraneous variables through a process of random sampling, if it can be assured that these effects are of a random (non-systematic) nature. Two types of randomisation are: random selection , where a sample is selected randomly from a population, and random assignment , where subjects selected in a non-random manner are randomly assigned to treatment groups.
Randomisation also ensures external validity, allowing inferences drawn from the sample to be generalised to the population from which the sample is drawn. Note that random assignment is mandatory when random selection is not possible because of resource or access constraints. However, generalisability across populations is harder to ascertain since populations may differ on multiple dimensions and you can only control for a few of those dimensions.
Popular research designs
As noted earlier, research designs can be classified into two categories—positivist and interpretive—depending on the goal of the research. Positivist designs are meant for theory testing, while interpretive designs are meant for theory building. Positivist designs seek generalised patterns based on an objective view of reality, while interpretive designs seek subjective interpretations of social phenomena from the perspectives of the subjects involved. Some popular examples of positivist designs include laboratory experiments, field experiments, field surveys, secondary data analysis, and case research, while examples of interpretive designs include case research, phenomenology, and ethnography. Note that case research can be used for theory building or theory testing, though not at the same time. Not all techniques are suited for all kinds of scientific research. Some techniques such as focus groups are best suited for exploratory research, others such as ethnography are best for descriptive research, and still others such as laboratory experiments are ideal for explanatory research. Following are brief descriptions of some of these designs. Additional details are provided in Chapters 9–12.
Experimental studies are those that are intended to test cause-effect relationships (hypotheses) in a tightly controlled setting by separating the cause from the effect in time, administering the cause to one group of subjects (the ‘treatment group’) but not to another group (‘control group’), and observing how the mean effects vary between subjects in these two groups. For instance, if we design a laboratory experiment to test the efficacy of a new drug in treating a certain ailment, we can get a random sample of people afflicted with that ailment, randomly assign them to one of two groups (treatment and control groups), administer the drug to subjects in the treatment group, but only give a placebo (e.g., a sugar pill with no medicinal value) to subjects in the control group. More complex designs may include multiple treatment groups, such as low versus high dosage of the drug or combining drug administration with dietary interventions. In a true experimental design , subjects must be randomly assigned to each group. If random assignment is not followed, then the design becomes quasi-experimental . Experiments can be conducted in an artificial or laboratory setting such as at a university (laboratory experiments) or in field settings such as in an organisation where the phenomenon of interest is actually occurring (field experiments). Laboratory experiments allow the researcher to isolate the variables of interest and control for extraneous variables, which may not be possible in field experiments. Hence, inferences drawn from laboratory experiments tend to be stronger in internal validity, but those from field experiments tend to be stronger in external validity. Experimental data is analysed using quantitative statistical techniques. The primary strength of the experimental design is its strong internal validity due to its ability to isolate, control, and intensively examine a small number of variables, while its primary weakness is limited external generalisability since real life is often more complex (i.e., involving more extraneous variables) than contrived lab settings. Furthermore, if the research does not identify ex ante relevant extraneous variables and control for such variables, such lack of controls may hurt internal validity and may lead to spurious correlations.
Field surveys are non-experimental designs that do not control for or manipulate independent variables or treatments, but measure these variables and test their effects using statistical methods. Field surveys capture snapshots of practices, beliefs, or situations from a random sample of subjects in field settings through a survey questionnaire or less frequently, through a structured interview. In cross-sectional field surveys , independent and dependent variables are measured at the same point in time (e.g., using a single questionnaire), while in longitudinal field surveys , dependent variables are measured at a later point in time than the independent variables. The strengths of field surveys are their external validity (since data is collected in field settings), their ability to capture and control for a large number of variables, and their ability to study a problem from multiple perspectives or using multiple theories. However, because of their non-temporal nature, internal validity (cause-effect relationships) are difficult to infer, and surveys may be subject to respondent biases (e.g., subjects may provide a ‘socially desirable’ response rather than their true response) which further hurts internal validity.
Secondary data analysis is an analysis of data that has previously been collected and tabulated by other sources. Such data may include data from government agencies such as employment statistics from the U.S. Bureau of Labor Services or development statistics by countries from the United Nations Development Program, data collected by other researchers (often used in meta-analytic studies), or publicly available third-party data, such as financial data from stock markets or real-time auction data from eBay. This is in contrast to most other research designs where collecting primary data for research is part of the researcher’s job. Secondary data analysis may be an effective means of research where primary data collection is too costly or infeasible, and secondary data is available at a level of analysis suitable for answering the researcher’s questions. The limitations of this design are that the data might not have been collected in a systematic or scientific manner and hence unsuitable for scientific research, since the data was collected for a presumably different purpose, they may not adequately address the research questions of interest to the researcher, and interval validity is problematic if the temporal precedence between cause and effect is unclear.
Case research is an in-depth investigation of a problem in one or more real-life settings (case sites) over an extended period of time. Data may be collected using a combination of interviews, personal observations, and internal or external documents. Case studies can be positivist in nature (for hypotheses testing) or interpretive (for theory building). The strength of this research method is its ability to discover a wide variety of social, cultural, and political factors potentially related to the phenomenon of interest that may not be known in advance. Analysis tends to be qualitative in nature, but heavily contextualised and nuanced. However, interpretation of findings may depend on the observational and integrative ability of the researcher, lack of control may make it difficult to establish causality, and findings from a single case site may not be readily generalised to other case sites. Generalisability can be improved by replicating and comparing the analysis in other case sites in a multiple case design .
Focus group research is a type of research that involves bringing in a small group of subjects (typically six to ten people) at one location, and having them discuss a phenomenon of interest for a period of one and a half to two hours. The discussion is moderated and led by a trained facilitator, who sets the agenda and poses an initial set of questions for participants, makes sure that the ideas and experiences of all participants are represented, and attempts to build a holistic understanding of the problem situation based on participants’ comments and experiences. Internal validity cannot be established due to lack of controls and the findings may not be generalised to other settings because of the small sample size. Hence, focus groups are not generally used for explanatory or descriptive research, but are more suited for exploratory research.
Action research assumes that complex social phenomena are best understood by introducing interventions or ‘actions’ into those phenomena and observing the effects of those actions. In this method, the researcher is embedded within a social context such as an organisation and initiates an action—such as new organisational procedures or new technologies—in response to a real problem such as declining profitability or operational bottlenecks. The researcher’s choice of actions must be based on theory, which should explain why and how such actions may cause the desired change. The researcher then observes the results of that action, modifying it as necessary, while simultaneously learning from the action and generating theoretical insights about the target problem and interventions. The initial theory is validated by the extent to which the chosen action successfully solves the target problem. Simultaneous problem solving and insight generation is the central feature that distinguishes action research from all other research methods, and hence, action research is an excellent method for bridging research and practice. This method is also suited for studying unique social problems that cannot be replicated outside that context, but it is also subject to researcher bias and subjectivity, and the generalisability of findings is often restricted to the context where the study was conducted.
Ethnography is an interpretive research design inspired by anthropology that emphasises that research phenomenon must be studied within the context of its culture. The researcher is deeply immersed in a certain culture over an extended period of time—eight months to two years—and during that period, engages, observes, and records the daily life of the studied culture, and theorises about the evolution and behaviours in that culture. Data is collected primarily via observational techniques, formal and informal interaction with participants in that culture, and personal field notes, while data analysis involves ‘sense-making’. The researcher must narrate her experience in great detail so that readers may experience that same culture without necessarily being there. The advantages of this approach are its sensitiveness to the context, the rich and nuanced understanding it generates, and minimal respondent bias. However, this is also an extremely time and resource-intensive approach, and findings are specific to a given culture and less generalisable to other cultures.
Selecting research designs
Given the above multitude of research designs, which design should researchers choose for their research? Generally speaking, researchers tend to select those research designs that they are most comfortable with and feel most competent to handle, but ideally, the choice should depend on the nature of the research phenomenon being studied. In the preliminary phases of research, when the research problem is unclear and the researcher wants to scope out the nature and extent of a certain research problem, a focus group (for an individual unit of analysis) or a case study (for an organisational unit of analysis) is an ideal strategy for exploratory research. As one delves further into the research domain, but finds that there are no good theories to explain the phenomenon of interest and wants to build a theory to fill in the unmet gap in that area, interpretive designs such as case research or ethnography may be useful designs. If competing theories exist and the researcher wishes to test these different theories or integrate them into a larger theory, positivist designs such as experimental design, survey research, or secondary data analysis are more appropriate.
Regardless of the specific research design chosen, the researcher should strive to collect quantitative and qualitative data using a combination of techniques such as questionnaires, interviews, observations, documents, or secondary data. For instance, even in a highly structured survey questionnaire, intended to collect quantitative data, the researcher may leave some room for a few open-ended questions to collect qualitative data that may generate unexpected insights not otherwise available from structured quantitative data alone. Likewise, while case research employ mostly face-to-face interviews to collect most qualitative data, the potential and value of collecting quantitative data should not be ignored. As an example, in a study of organisational decision-making processes, the case interviewer can record numeric quantities such as how many months it took to make certain organisational decisions, how many people were involved in that decision process, and how many decision alternatives were considered, which can provide valuable insights not otherwise available from interviewees’ narrative responses. Irrespective of the specific research design employed, the goal of the researcher should be to collect as much and as diverse data as possible that can help generate the best possible insights about the phenomenon of interest.
Social Science Research: Principles, Methods and Practices (Revised edition) Copyright © 2019 by Anol Bhattacherjee is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
Advertisement
Supported by
How Two Beluga Whales Made It to Safety From Ukraine
A pair of whales were extricated from the besieged city of Kharkiv and taken to an aquarium in Spain with help from experts around the world.
- Share full article
 quizlet")
By Marc Santora and Emily Anthes
Marc Santora reported from Kyiv, Ukraine, and Emily Anthes from New York.
It was a whale of an evacuation. Actually, two.
In what experts said was among the most complex marine mammal rescue ever undertaken, the pair of beluga whales were extricated from an aquarium in the battered city of Kharkiv in eastern Ukraine and transported to Europe’s largest aquarium in Valencia, Spain, on Wednesday morning.
As Russian aerial bombardments of Kharkiv, Ukraine’s second-largest city, have intensified, the evacuation of Plombir, a 15-year-old male, and Miranda, a 14-year-old female, came just in time, marine mammal experts said.
“If they had continued in Kharkiv, their chances of survival would have been very slim,” said Daniel Garcia-Párraga, director of zoological operations at Oceanogràfic de Valencia, who helped lead the rescue.
Belugas, whose natural habitat is the Arctic, need cold water to survive. The devastation of the power grid in Kharkiv meant that the aquarium there had to rely on generator power, making it challenging to keep the waters cooled.
At the same time, the whales’ diets were halved recently amid shortages of the 132 pounds of squid, herring, mackerel and other fresh fish the pair needed daily, Dr. Garcia-Párraga said. Ukrainian caregivers were even considering using discarded fish from restaurants and markets.
And in recent weeks, bombs exploded close enough to ripple the waters of their home at the NEMO Dolphinarium. As the conditions grew more precarious, the Ukrainians decided the whales required evacuation.
We are having trouble retrieving the article content.
Please enable JavaScript in your browser settings.
Thank you for your patience while we verify access. If you are in Reader mode please exit and log into your Times account, or subscribe for all of The Times.
Thank you for your patience while we verify access.
Already a subscriber? Log in .
Want all of The Times? Subscribe .
IMAGES
VIDEO
COMMENTS
The research design is a ________ that specifies the methods that will be used to collect and analyze the information needed for a research project. Master Plan. Knowledge of research design is important in: Developing the research for the corporate strategic plan. Once the researcher knows the basic research design, ________ may be made to ...
A research design is a(n) a.indicator of attitudes, behavior, or characteristics of people or organizations. b.speculative statement about the relationship between two or more variables. c.explanation of an abstract concept that is specific enough to allow a researcher to measure the concept. d.detailed plan or method for scientifically ...
quizlette2160452. Preview. Terms in this set (8) What is a research design. A research design is the blue print of the study. The design of the study defines the study type. A framework that has been created to seek answers to research questions. How many study types? Descriptive, Cor-relational, semi experimental, experimental, review, meta ...
Terms in this set (40) What is a research design? Blueprint or detailed plan for conducting a study. Purpose, review of literature, and framework provide the basis for the design. Maximizes control over factors to increase validity of the findings. Guides the researcher in planning and implementing a study. Study Purpose.
Research Design. 1. Describe and differentiate between qualitative and quantitative research. 2. Describe experimental, quasi‐experimental and nonexperimental research designs. 3. Describe research designs used for questions about diagnostic tests, clinical measures, prognostic factors, interventions, clinical prediction rules and outcomes. 4 ...
a research design in which the researcher controls exposure to the test factor or independent variable, the assignment of subjects to groups, and the measurement of responses. external validity. the ability to generalize from one set of research findings to other situations. extraneous factors.
Terms in this set (14) research design. a blue print for your study; the overall strategy for integrating the components of a study in a coherent and logical way to ensure that the research problem is effectively addressed. what determines the research design.
A research design is a strategy for answering your research question using empirical data. Creating a research design means making decisions about: Your overall research objectives and approach. Whether you'll rely on primary research or secondary research. Your sampling methods or criteria for selecting subjects. Your data collection methods.
This page titled 6: Research Design is shared under a Public Domain license and was authored, remixed, and/or curated by David Lane via source content that was edited to the style and standards of the LibreTexts platform; a detailed edit history is available upon request. A research design is the set of methods and procedures used in collecting ...
Chapter 5 Research Design. Research design is a comprehensive plan for data collection in an empirical research project. It is a "blueprint" for empirical research aimed at answering specific research questions or testing specific hypotheses, and must specify at least three processes: (1) the data collection process, (2) the instrument ...
Question 7. What is a cross-sectional design? a) A comparison of two or more variables longitudinally. b) A design that is devised when the researcher is in a bad mood. c) The collection of data from more than one case at one moment in time. d) Research into one particular section of society, e.g. the middle classes.
A research design is defined as the overall plan or structure that guides the process of conducting research. It is a critical component of the research process and serves as a blueprint for how a study will be carried out, including the methods and techniques that will be used to collect and analyze data.
A study design that randomly assigns participants to an experimental group (which receives the intervention) or a control group (which receives either a placebo or no intervention). The only expected difference between the two groups is the variable being studied. When critically appraising an RCT, you will evaluate elements of the study such ...
Introduction. A research design in qualitative research is a critical framework that guides the methodological approach to studying complex social phenomena. Qualitative research designs determine how data is collected, analyzed, and interpreted, ensuring that the research captures participants' nuanced and subjective perspectives.
The function of a research design is to ensure that the evidence obtained enables you to effectively address the research problem logically and as unambiguously as possible. In social sciences research, obtaining information relevant to the research problem generally entails specifying the type of evidence needed to test a theory, to evaluate a ...
The quality of research designs can be defined in terms of four key design attributes: internal validity, external validity, construct validity, and statistical conclusion validity. Internal validity, also called causality, examines whether the observed change in a dependent variable is indeed caused by a corresponding change in hypothesized ...
2.4: Research Designs. Psychologists test research questions using a variety of methods. Most research relies on either correlations or experiments. With correlations, researchers measure variables as they naturally occur in people and compute the degree to which two variables go together.
Quantitative research designs can be divided into two main categories: Correlational and descriptive designs are used to investigate characteristics, averages, trends, and associations between variables. Experimental and quasi-experimental designs are used to test causal relationships. Qualitative research designs tend to be more flexible.
58 : At a minimum, how many participants would be needed for a matched-subjects design comparing three different treatment conditions with 20 scores in each treatment? A : 20 B : 60 C : 90 D : 120. Correct Answer : B. 59 : The most appropriate hypothesis test for a within-subjects design that compares three treatment conditions is a(n) ____.
The purpose of research design is to plan and structure a research study in a way that enables the researcher to achieve the desired research goals with accuracy, validity, and reliability. Research design is the blueprint or the framework for conducting a study that outlines the methods, procedures, techniques, and tools for data collection ...
A research design is a blueprint for the collection, measurement, and analysis of data, based on _____ of the study. the purpose. the research questions. the introduction. 2. Multiple Choice. 30 seconds. 1 pt. An exploratory study is undertaken when not much is known about _____ at hand, or no information is available on how similar problems ...
Question 9 In terms of quantitative research design's features, experimental studies often have: Correct Answer active introduction of an intervention to the experimental group limited control of confounding/ extraneous variables performance of an intervention at a single point in time only The retrospective approach of data collection ...
Research design is a comprehensive plan for data collection in an empirical research project. It is a 'blueprint' for empirical research aimed at answering specific research questions or testing specific hypotheses, and must specify at least three processes: the data collection process, the instrument development process, and the sampling ...
A pair of whales were extricated from the besieged city of Kharkiv and taken to an aquarium in Spain with help from experts around the world. By Marc Santora and Emily Anthes Marc Santora reported ...