

Top 25 SQL Case Expression Interview Questions and Answers
Prepare for your next interview with our comprehensive guide on SQL Case Expression. This article offers a detailed rundown of potential interview questions and answers to help you succeed.

SQL, or Structured Query Language, is a standardized programming language that’s used for managing and manipulating relational databases. Among its many features, the SQL Case Expression holds a special place due to its versatility and practicality in various scenarios. It provides developers with the ability to perform conditional logic in SQL statements, thus adding a layer of dynamism to data retrieval and manipulation.
In the realm of SQL, the CASE expression is akin to IF-THEN-ELSE statements found in other programming languages. It allows us to create different outputs in our SELECT clause based on conditions in our data. This powerful tool can greatly enhance your SQL queries, making them more efficient and adaptable.
In this article, we’ve compiled an extensive list of interview questions focused on the SQL Case Expression. These questions will not only test your understanding of this particular feature but also illustrate its application in real-world situations, thereby enhancing your overall proficiency in SQL.
1. Can you explain what a SQL Case Expression is and where it is typically used?
A SQL Case Expression is a conditional statement that provides a way to perform IF-THEN-ELSE logic within an SQL query. It allows for complex, multi-condition queries and can be used in any clause or statement that accepts a valid expression. There are two types: Simple CASE (compares an expression to set values) and Searched CASE (evaluates multiple Boolean expressions).
Typically, it’s used in SELECT, UPDATE, DELETE, and WHERE clauses to create more flexible data manipulation statements. For instance, you might use it to categorize data into different groups based on certain criteria, or to update specific rows of data depending on their current values.
2. How does the SQL Case Expression differ from the If-Then-Else structure?
The SQL Case Expression and If-Then-Else structure both allow for conditional logic in programming, but they differ significantly. The Case expression is a part of SQL language used within queries to manipulate data based on certain conditions. It’s more flexible as it can handle multiple conditions and return different results accordingly.
On the other hand, If-Then-Else is a control flow statement found in most procedural languages like Python or Java. It executes different blocks of code depending on whether a condition is true or false. However, it’s less versatile than Case when dealing with multiple conditions because nested If-Then-Else structures are needed, which can lead to complex and hard-to-read code.
3. Can you provide a detailed example of how you would use a SQL Case Expression to categorize data?
A SQL Case Expression allows for conditional logic in queries. It’s useful when categorizing data based on specific conditions.
SELECT EmployeeID, FirstName, LastName, (CASE WHEN Salary > 50000 THEN ‘High’ WHEN Salary BETWEEN 30000 AND 50000 THEN (CASE WHEN YearsExperience > 5 THEN ‘Mid-High’ ELSE ‘Mid-Low’
5. How does the SQL CASE Expression handle NULL values?
The SQL CASE expression treats NULL values as unknown. It doesn’t equate them to any value, not even another NULL. When a NULL is encountered in the WHEN clause of a CASE statement, it’s skipped and the next condition is evaluated. If no conditions are met and there’s an ELSE clause, its result is returned; if there’s no ELSE, NULL is returned. This behavior can be leveraged for handling NULLs by using IS NULL or IS NOT NULL in the WHEN clause, or coalescing NULLs to a default in the ELSE clause.
6. What is the difference between simple and searched CASE Expressions? Can you provide an example of each?
A simple CASE expression in SQL compares an expression to a set of expressions to determine the result. It’s similar to using multiple IF-THEN statements in programming languages. For example:
SELECT ProductName, CASE CategoryID WHEN 1 THEN ‘Beverage’ WHEN 2 THEN ‘Condiment’
7. How would you use a CASE Expression in a WHERE clause? Provide a sample SQL statement.
A CASE expression in a WHERE clause can be used to conditionally filter data. It allows for complex logical tests and returns different values based on the test outcome.
Here’s an example of how it could be implemented:
SELECT CustomerID, CASE WHEN SUM(PurchaseAmount) > 10000 THEN ‘High’ WHEN SUM(PurchaseAmount) BETWEEN 5000 AND 10000 THEN ‘Medium’ ELSE ‘Low’
10. How would you use a CASE Expression in an ORDER BY clause? Provide a sample SQL statement.
A CASE expression in an ORDER BY clause allows for custom sorting of results. It’s used to change the order based on a condition. For example, if we have a table ‘Employees’ with columns ‘Name’, ‘Position’ and ‘Salary’. We want to sort by position but prioritize ‘Manager’ over others.
Here is a sample SQL statement:
13. What are the limitations or pitfalls of using SQL Case Expressions?
SQL Case Expressions, while useful, have limitations. They can’t return different data types in the THEN clause; all must be implicitly convertible to a single type. This restricts flexibility. Also, they don’t support ELSE IF structure directly, making complex conditions challenging. Performance issues arise when used in WHERE clauses as indexes may not be utilized effectively, leading to slower query execution. Additionally, CASE expressions are evaluated sequentially from top to bottom and once a condition is met, it exits, ignoring subsequent WHEN statements. This could lead to unexpected results if not carefully structured. Lastly, there’s no guarantee that SQL Server will short-circuit a CASE expression, potentially causing errors with NULL values.
14. Can you create a SQL statement using a Case Expression inside a JOIN statement?
Yes, a SQL statement can incorporate a Case Expression within a JOIN statement. This is useful when you need to conditionally join tables based on certain criteria. Here’s an example:
CREATE FUNCTION case_example(@input INT) RETURNS VARCHAR(20) AS BEGIN DECLARE @result VARCHAR(20)
16. Can you write a complex case expression for filtering records based on multiple conditions?
Yes, a complex case expression can be written in SQL to filter records based on multiple conditions. Here’s an example:
SELECT OrderID, Quantity, Price, (CASE WHEN Quantity > 100 THEN Price * 0.9 ELSE Price
19. Can you explain the difference between a CASE statement and a CASE expression in SQL?
A CASE expression in SQL is used to create conditional expressions within a query. It allows for the return of values based on certain conditions, similar to an IF-THEN-ELSE statement in other programming languages.
On the other hand, a CASE statement is not native to SQL and does not exist as a standalone construct. Instead, it’s often confused with the CASE expression or misnamed when referring to control flow statements in procedural SQL extensions like PL/SQL (Oracle) or T-SQL (Microsoft), where it functions similarly to switch-case constructs in other languages.
20. How can you use a Case Expression to transpose rows into columns?
A CASE expression in SQL can be used to transpose rows into columns by creating a new column for each unique row value. This is done by using the CASE statement within the SELECT clause of your query.
For example, consider a table ‘Orders’ with columns ‘OrderID’, ‘CustomerID’, and ‘Product’. If we want to create a new column for each unique product, we would use a CASE expression like this:
SELECT COUNT(CASE WHEN condition THEN 1
22. Can you present a scenario where you would prefer DECODE over CASE Expression?
DECODE is preferable over CASE expression in scenarios where we need to perform simple equality checks. For instance, when translating codes into descriptions or performing transformations on a single column’s values. DECODE has a simpler syntax for these tasks and can be more readable.
Consider an example of a student grading system. If we want to translate numerical grades into letter grades (A, B, C, D, F), using DECODE would look like this:
In contrast, the equivalent CASE expression would be longer and potentially less clear:
SELECT column1, column2, CASE WHEN column2 = 0 THEN ‘Error: Division by Zero’ ELSE column1 / column2
24. Can you write a SQL query using a Case Expression to return values from multiple columns based on certain conditions?
Yes, a SQL query using a Case Expression can return values from multiple columns based on certain conditions. Here’s an example:
` SELECT EmployeeID, FirstName, LastName, CASE WHEN Salary > 50000 THEN ‘High’ WHEN Salary BETWEEN 30000 AND 50000 THEN ‘Medium’ ELSE ‘Low’
25. How would you tackle performance issues while using multiple Case Expressions?
To tackle performance issues with multiple Case Expressions in SQL, it’s crucial to optimize the query. One way is by reducing the number of case expressions used. If possible, combine similar conditions into one expression or use ELSE for default cases. Another method is indexing columns involved in the CASE statement. This can significantly speed up the search process. Also, consider using temporary tables for complex queries. They store intermediate results and reduce computation time. Lastly, ensure your database statistics are updated regularly as outdated stats may lead to inefficient execution plans.
Top 25 Binomial Distribution Interview Questions and Answers
Top 25 jquery events interview questions and answers, you may also be interested in..., top 25 apache spark interview questions and answers, top 25 pointers interview questions and answers, top 25 accessibility interview questions and answers, top 25 3d modeling interview questions and answers.

Top 13 SQL Scenario Based Interview Questions with Answers (2024)
According to a 2021 developer survey , each of the top four most common database management systems uses SQL. If you have an interview coming up for a data-based role, you should expect and practice SQL interview questions .
SQL scenario-based questions don’t just test your knowledge of SQL queries, but also how well you can apply them in certain situations. The situations or scenarios used will typically mimic real-world problems, and you’ll need your technical and comprehension skills to tackle them.
These scenario-based SQL interview questions can be classified as easy, intermediate, or hard, based on: The difficulty in defining or understanding the problem. The complexity of the query is required to solve the problem.
We’ve compiled 13 SQL scenario-based interview questions you can practice to pinpoint your skill level and improve. The problems and solutions are well-explained to assist you in understanding how you can approach similar questions in an actual interview!
Easy SQL Scenario Based Interview Questions
Easy SQL scenario based interview questions will test your ability to apply simple queries and solve basic problems. There will be limited use of subqueries or multiple tables.
1. Write a query to display the highest salaries in each department.
More context: You have been provided with a table called ‘salaries’ that has three columns: EmployeeID, Department, and Salary.
The goal here is to list the single highest salary in each department. The output will consist of one column for the department and another column for the highest salary paid to a person in that department.
If there are four UNIQUE departments in the table, there should be four rows in the output.The GROUP BY function can be used to solve this problem as follows:
2. Several employees are yet to be assigned a department in your company. How would you find their details?
This question tests two different things. The first is a basic ability to filter data. You are looking through a list of employees to find only those who meet a particular criterion, in this case, if they have been assigned a department. The WHERE clause is commonly used for this purpose in SQL.
This question also tests whether you know how empty entries are stored in an SQL database. In SQL, empty values are stored as NULL , which can be used to locate empty entries by pairing the WHERE clause and the IS NULL operator.
For this question, you can find all employees without assigned departments with a query like:

3. Show all employees hired between 2015 and 2020.
When you need to find records of activities that took place within a specific time frame, you can use the BETWEEN comparator in SQL. It’s important to remember the format of the date used in the database. Here’s how you can write the query:
Note: Although dates are compared like other values, they still need the quotes around them to avoid errors.
4. How would you display the records of the top 15 students in the most recent exam?
Some of the tables you’ll be working with will contain thousands or even millions of records. You’ll often want to limit the amount of data displayed, so you can preview the relevant records efficiently.
This can be quickly achieved by employing the LIMIT clause in SQL. For this question, this could simply be:
While the above query will yield a result, it may not be the correct one. The question asks for the “top”’ students. This means that the student’s records must first be organized from highest to lowest based on their examination results before a LIMIT clause is applied.
This can be handled using the ORDER BY clause as shown below:
5. You have been tasked with finding new sales areas to target. Find the neighborhoods with no current users.
More context: You have been given a ‘users’ table and a ‘neighborhoods’ table.
The fact that you have two tables means you’ll probably need to use a JOIN clause, but that’s just half the story.
The neighborhoods being asked about in this question are those with no existing users. This means that you need to join the two tables and find the neighborhoods that appear on the ‘neighborhoods’ table but don’t have a single user in them in the ‘users’ table.
Assuming the ‘neighborhoods’ table is on the left, you can use LEFT JOIN to identify all the neighborhoods. The WHERE clause can then be used to filter out any neighborhood that shows up in the ‘users’ table.
Hint: The IS NULL operator can be handy in solving this problem.
6. Find the last record in a table of daily transactions.
More context: You have a single table with columns for the transaction ID, the time of the transaction, and the value of the transaction.
Like many questions in data science, there is more than one way to arrive at the answer to this question. A straightforward approach is to use a combination of data sorting and the limit function.
Date and time data can be sorted in ascending or descending order with the latest date-time considered the higher value. With this in mind, you can find the last transaction on a given day using the query below:
The query above will display only one record, and, thanks to the DESC clause, it will be the transaction with the highest date-time value.
An alternative approach to answering this question uses the MAX function. Can you figure out what the query will be?
Intermediate SQL Scenario Based Interview Questions
Intermediate SQL scenario based interview questions will push your comprehension and query writing skills. These scenarios will usually require working with two or more tables. You’ll also want to take time to understand the problem posed and the possible ways of solving it, before jumping into possible solutions.
7. Write a query to display each city where the company has customers from two different states and the number of customers in each city.
More context: You have been provided with two tables with identical columns for two different states. The tables contain columns for customer ID, and their cities within the two states.
The count() function and the GROUP BY clause would have sufficed if all the records were on one table. However, this problem is slightly more challenging since the records are in two separate tables.
You can solve this question by taking advantage of subqueries. In this case, the UNION ALL clause can be used in the subquery to append the customers’ cities from the two tables. The customer IDs from each city are then grouped and counted.
The subquery used in the FROM clause must have an alias so it can be referenced in the query. The query would look as shown below:
Ensure you use the UNION ALL and not the UNION clause. The latter would append each city once to the combined list of cities, leading to each city showing just one customer.
8. How can you identify the customers who have made more than ‘X’ number of purchases in the past year?
Context: You have a purchases table and a users table
Once again, having two tables usually means needing to use a UNION or JOIN clause. In this case, the purchases table should have a customer ID column to uniquely identify which customer made which purchase.
Based on this, an INNER JOIN can be performed on the two tables, outputting a table with transaction IDs and the IDs of the customers who made the transactions.
The transactions can then be grouped by the customer IDs and the number of transactions associated with each customer added.
This question tests your ability to use JOINs and Subqueries, as well as your ability to apply the GROUP BY clause with a filter.
Hint: You may need to use the HAVING clause.
9. How would you write a query to find the second or third-highest bonuses paid out the previous month?
This type of question is common and it can be solved in different ways. Some solutions are not as elegant as others but the logic is easy to follow..
In the less elegant approach, you can use subqueries or nested queries to find the maximum bonus in a list of all bonuses that are less than the maximum bonus. The query to find the second-highest bonus using this approach looks like this:
By adding an identical subquery inside the first subquery, you can create the query that gives the third highest bonus. This can look like this:
The more elegant approach is to order the bonuses from highest to lowest, limit the result to one, and use an offset to choose the 2nd or 3rd highest bonuses as shown here:
You can change the offset to 2 to see the third-highest bonus or change the limit to 2 to view the second and third-highest bonuses at the same time.
Advanced SQL Scenario Based Interview Question
At this level, you can expect SQL scenario based interview questions to be highly challenging. The scenario may not be well-defined and may require you to fill in some blanks with informed assumptions. Furthermore, the questions may be straightforward, but will require using specific functions that a beginner may not be familiar with.
10. Suggest a new online connection based on mutual likes and mutual friends.
More Context: You’ve been provided with four tables; ‘users’, ‘friends’, ‘likes’, and ‘blocked’. You are to suggest one friend to a user in the ‘users’ table based on the number of mutual friends and mutually liked pages. Current friends and anyone already blocked by the user are disqualified. Each mutual friend gives a potential friend 3 points, and each mutually liked page gives them 2 points.
This is the type of question you may encounter in an interview for a social media company where a key goal is to get users to connect with others. The idea here is that two people are more likely to connect if they like similar things or associate with the same people.
Solving this question will require you to identify the chosen user’s existing friends, their page likes, and users they’ve already blocked. You’ll also need to calculate the points to be assigned to the other users for mutual friends and likes so you can identify those with the highest points.
Finally, you’ll need to compile the list of potential friends, rank them, and eliminate existing friends or blocked individuals.
HINT: Common table expressions (CTEs) can help tackle the different operations needed to complete this task.
11. Calculate the daily three-day rolling average for deposits made to a bank .
More Context: You have been provided with a table containing columns for user ID, transaction amount, and time of transaction in datetime format. The positive transactions in the table are deposits and the negative transactions are withdrawals. The date in the output should be in the format ‘%Y-%m-%d’
There are different scenarios where calculating rolling averages would be important. A similar question could show up when interviewing for companies involved in stock or crypto trading. The most important columns in this table are for transactions and dates.
The first step to solving this problem is to sum the deposits made on each date. We can do this with the help of a CTE.
The above code outputs the total amount of deposits for each day. The next challenge is calculating the rolling 3-day average. If you had to use a JOIN clause, how would you solve this second part of the problem?
12. Write a query that repeats an integer as many times as the value of the integer itself.
More Context: You have a table with a column of integers. If the number in a row is 3, the integer 3 should be repeated three times in the output. This should be done sequentially for each integer in the table.
When an interviewer asks this type of question, they are probably testing your knowledge of advanced SQL queries. This type of problem can be solved in languages like Python using loops. In SQL you can employ the concept of recursion instead. This uses the RECURSIVE clause.
Recursion is a unique form of looping where the output from one iteration becomes the input for the next iteration.
In this scenario, the output of each iteration is a counter and the unchanged integer from the table. If the integer in the table is three, the first iteration will select 3 and a counter.
The value of the counter is the only one that changes in each iteration, but each time, the value of the number from the table, 3, is selected until the value of the counter is equal to it.
13. Write a query to calculate the percentage of users who recommended each page and are in the same postal code as that page.
More Context: There are three tables provided - ‘page_sponsorships’, ‘recommendations’, and ‘users’. The ‘sponsorship’ table has columns for page_id, postal_code, and price, i.e., the value of the sponsorship. The ‘recommendations’ table contains the user_id and the page_id of the recommended page. The ‘users’ table holds the user IDs and their postal codes. Pages are allowed to sponsor more than one postal code.
This type of question will test your comprehension. Several criteria must be met by the output and they require inputs from all three tables.
A distinction must be made between users who recommend a page and share its sponsored postal code and those who recommend the page and don’t share its postal code. The SUM CASE WHEN conditional statement can be handy here.
All three tables will have to be joined so the postal codes of the users who recommended a page and those sponsored by the page can be compared.
Grouping will have to be done based on two columns to separately aggregate users in different postal codes sponsored by the same page.
How To Solve Scenario Based Interview Questions in SQL
You may find scenario based SQL questions challenging, but with the right steps, you can learn to handle them with ease. Here are some ways you can improve your success rate with SQL scenario based questions.
1. Know what the question is asking before you start
Scenario based questions are used to test your understanding, and not just your ability to write SQL queries. Go over the question a few times and try to distill the question down to its simplest parts.
2. Clarify Assumptions
The interviewer may be targeting a specific answer when asking a specific question. Confirm any assumptions you may have and get a clearer picture of what the problem is.
3. Consider Similar Problems
The questions above reveal that many problems in SQL can be solved through similar steps. For example, questions involving multiple tables will require that the tables be joined in some way and a filter applied to the data left after joining.
4. Think of the steps logically
When working with subqueries, which will be often, it helps to think of the steps logically. Some actions cannot be performed unless other actions have been performed first. This can give you an entry point that allows you to work towards the final solution.
5. Practice writing queries
There are more scenarios that an interviewer can come up with than anyone could possibly cover. That’s why the best way of getting better at solving SQL scenario based interview questions is to answer as many practice questions as possible.
Practicing more SQL questions will allow you to master what you already know, and expose you to approaches you may never have considered.
Check out guides such as ‘ How to Use MAX CASE WHEN in SQL ’, ‘ How To Use CASE WHEN With SUM ’, and more for more resources.
40+ scenario-based SQL interview questions to ask programmers
Find the most skilled sql developers using testgorilla.

Structured Query Language (SQL) is a programming language used to manage the data in a relational database. When you hire programming professionals who work with this language, you need to know they are proficient in SQL and meet your role’s requirements.
Though you can use aptitude assessments to evaluate your candidates’ skills, you still need to get to know them in person and confirm that they can think on their feet and solve problems quickly.
We have created this list of more than 40 scenario-based SQL interview questions to help you gauge your candidates’ understanding of SQL. Use these questions to find the most skilled SQL developer .
Table of contents
30 beginner scenario-based sql interview questions, 5 essential beginner scenario-based sql interview questions with answers, 10 intermediate scenario-based sql questions, 5 essential intermediate scenario-based sql questions with answers, 8 advanced scenario-based sql interview questions, 5 essential advanced scenario-based sql interview questions with answers, which roles can you ask scenario-based sql interview questions for, when should you ask scenario-based sql interview questions during the hiring process, make your list of scenario-based sql questions to assess your candidates.
Rather than making the interview feel like an hour-long exam, it’s better to have some quick-fire questions ready to ask your candidates. Ask applicants some of these 30 scenario-based questions to quickly learn about their knowledge and abilities.
How would you convert seconds into time format?
How would you display the number of weekends in the current month?
How would you display the common records in two tables that can’t be joined?
What query would you use to display the third-last record in a table?
How would you display a date in the format DD-MM-YYYY?
What query would you use to drop all user tables from Oracle?
How would you view the month-wise maximum salary for a specific department?
What query would give you the second-highest salary in an employee table?
How would you get a list of all employees and their managers?
How would you find the previous month’s last day with a query?
How would you gather the admission date of a student in Year-Day-Date format?
What query would you use to create a new table with the Student table structure?
How do you view only common records from two different tables?
How do you view employees’ monthly salaries based on their annual salaries?
If a Student table holds comma-separated values, how would you view the number of values?
How would you retrieve employee information when the employee has not been assigned to a department?
How would you use the rank function to display the third-highest salary?
How would you display all employees with a salary greater than $30,000 who joined in 2019?
How would you display a string vertically?
How would you display the first 25% of records from a Student table?
How would you display the last 25% of records from a Student table?
How would you convert the system time into seconds?
What query would you use to show numbers between 1 and 100?
How would you show the DDL of a table?
How would you show only the odd rows in a Student table?
Another employee needs help and asks you to explain what a database is. What would your response be?
You’re assisting a less knowledgeable employee. How would you explain the difference between a DBMS and an RDBMS?
How would you select unique records from a table using a SQL query?
How do you delete duplicate records from a table using a SQL query?
How do you read the top five records from a database using a SQL query?
To ensure you have enough questions for your interview, choose between 5 and 15 of the questions listed above. Though you may be unable to ask all of them, it’s better to have too many than too few.

To review your applicants’ responses, use these straightforward sample answers to our scenario-based SQL interview questions.
1. Another employee needs help and asks you to explain what a database is. What would your response be?
Often, companies have departments and teams made up of employees with different skill sets and knowledge. Teams that communicate effectively have up to 25% higher productivity . This is why you need programmers who can provide support for employees who are less knowledgeable when it comes to the technical aspects of the business.
If an employee from one department needs assistance with managing a database, it would be helpful for them to understand what a database is.
The ideal candidate should explain that a database is a collection of structured data that can be accessed, retrieved, managed, and stored in a digitized computer system. Databases are built with a design and modeling approach and can be stored on a file system, a computer cluster, or cloud storage, depending on their size.
The more straightforward and easy to understand their answer is, the better your candidate will be at communicating with less knowledgeable employees about databases.
2. You’re assisting a less knowledgeable employee. How would you explain the difference between a DBMS and an RDBMS?
You need to know that your candidate can explain complex SQL topics to a less knowledgeable person. When you ask this question, ensure the employee answers in layperson’s terms using clear language.
They should be able to explain that a DBMS is a database management system, a system that enables professionals to manage databases and retrieve information from them. It structures and organizes data to make it easily accessible. A DBMS only allows the user to access one data element at a time.
An RDBMS, on the other hand, stores data in a table structure, helping professionals access multiple data elements more efficiently.
3. How would you select unique records from a table using a SQL query?
This is a practical question relating to SQL that your ideal candidate will be able to answer quickly. Your interviewee might provide a couple of acceptable answers:
You can use the GROUP BY and SELECT clauses to collect data from multiple records and group them by columns. Using the GROUP BY function enables you to view unique records from your selected columns and query them.
You can use the ROW_NUMBER() function to assign consecutive numbering to the rows in your result. This way, you can assign row numbers to your unique records for your query.
Asking this question will help you learn if candidates can clearly convey technical information and understand SQL queries.
4. How do you delete duplicate records from a table using a SQL query?
Streamlining your database and reducing duplicate data can help you free up storage space and improve efficiency by speeding up data retrieval. If your database is filled with duplicate records, this could impact your computer processing speed and cloud storage space.
Your candidate should know how to perform the basic task of deleting duplicate records from a table using a SQL query.
One method is using the GROUP BY and HAVING clauses to retrieve duplicate records. You could then create a temporary table or subquery to store the duplicate records. Finally, you can use the DELETE statement to delete the duplicate records from the original table.
Take note of candidates who provide multiple answers and describe when they would use each solution. Those who offer more information may be more conscientious and have strong problem-solving skills.
5. How do you read the top five records from a database using a SQL query?
Your ideal candidate should be able to easily retrieve the top five records in a database. Pay attention to applicants who can quickly answer this question.
They should mention that the ROWNUM function enables them to allocate a pseudocolumn to the results, providing a number order. From there, they can select the top five results using a SQL query.
Here are some intermediate scenario-based SQL questions to ask once your candidate is comfortable and settled into the interview.
How do you read the last five records from a database using a SQL query?
Write a SQL query that will provide you with the 10th-highest employee salary from an Employee table.
Explain what an execution plan is, and give an example of when you need one.
What is the difference between UNION and UNION ALL ?
List all joins supported in SQL.
Find the fourth-highest score from a Student table using self-join.
Show the number of employees who joined in the past three years.
Select all records from the Student table, excluding X and Y.
Get the DDL of a table.
How would you show the Nth record in the Student table?

To help you analyze your candidate’s answers correctly, here are some of the most important intermediate-level SQL questions with answers.
1. How do you read the last five records from a database using a SQL query?
Your candidate’s answer to this question should be similar to the one for the question above. However, they must also mention that using the minus factor to ensure the result only pulls the last five records and not the first five.
2. Write a SQL query that will provide you with the 10th-highest employee salary from an Employee table.
Presenting your candidate with a task like this during the interview will give you an idea of their working speed, which directly affects their productivity. You can closely observe how quickly they can develop a SQL query and test the query to see if it works.
You should also ask candidates to explain their answer. Their response will help you understand their reasoning and why they wrote the query using this method and not another.
3. Explain what an execution plan is, and give an example of when you might need one.
An execution plan is a guide that dictates the data retrieval methods selected by the server’s query optimizer. It is useful in helping a SQL professional analyze the efficiency of stored procedures. The execution plan enables the programming professional to better understand their query procedures to optimize query performance.
4. What is the difference between UNION and UNION ALL ?
UNION and UNION ALL are SQL operators that your programmer should be able to distinguish between. They should explain that UNION combines multiple datasets into one, removing any duplicate rows from the combined result set.
UNION ALL performs the same function, except it does not delete duplicate records. So, if you wish to keep all records without deleting duplicates, you should use UNION ALL instead of UNION .
5. List all joins supported in SQL.
Your candidate should know which joins are supported in SQL. They should be able to list all of the joins supported, which are:
The candidate should be able to explain what each join does. Ask them to provide examples of when they would use each join to gauge their level of practical knowledge and experience.
Here are some advanced scenario-based SQL interview questions to challenge your candidates and help you apply some pressure.
Write a query to get the last record from a table.
When would you use a linked server? Explain why.
Explain the different types of authentication modes.
How do you add email validation using only one query?
Where should usernames and passwords be stored in a SQL server?
What do you do when you cannot find the correct query?
Which questions did you find the hardest? Explain why.
Do you have any other relevant programming knowledge we should know of?

To challenge your candidate’s knowledge during the interview, ask a few questions they may be unable to answer. Evaluate their responses against the five sample answers to these SQL interview questions.
1. Write a query to get the last record from a table.
For this question, it’s best to provide the candidate with an example table for which they can write and test a query.
2. When would you use a linked server? Explain why.
Of course, your candidate should understand how to write SQL queries. But they also require strategic knowledge that informs their decision-making. Candidates need to know that professionals use linked servers to link to a remote database.
Asking them when they should use a linked server will help you learn whether the candidate has practical experience, not just knowledge of writing SQL queries.
3. Explain the different types of authentication modes.
Your SQL professional should be able to describe the different types of authentication modes to you. They may explain that SQL servers support two primary authentication modes: Windows authentication mode and mixed mode.
Ask follow-up questions to check if your applicants have experience using these modes and can explain what each does. They should know that Windows authentication disables SQL server authentication and that mixed mode enables both of these modes.
4. How do you add email validation using only one query?
In their response, your candidate should specify which RDBMS the query is compatible with. For instance, they should state that they would use the query PATINDEX(‘%[^a-z,0-9,@,.,_]%’, REPLACE(email, ‘-‘, ‘a’)) = 0; , which would be compatible with Microsoft SQL Server .
5. Where should usernames and passwords be stored in SQL Server?
Ask the candidate to explain that the usernames and passwords in a SQL server are stored in the master database in the sysxlogins table. They should also explain that passwords are stored in a hashed format rather than plaintext to enhance security.
To help you understand whether you’ll need SQL interview questions for the position you’re hiring for, here are some examples of roles that require SQL knowledge:
Data engineer/analyst
Business analyst/business intelligence developer
Software developer/engineer
Database architect
Database administrator
If you’re hiring for any of the above positions, you’ll need candidates proficient in SQL and query creation. Even if a candidate doesn’t have official experience with SQL, they may have knowledge that you can test using a skills assessment and interview.
Start building your SQL skills assessment and hire candidates who are a good fit.

If you’re hiring SQL professionals, you must devise an effective hiring strategy. On average, a job opening attracts 250 resumes . That’s why you need a more effective screening method than reviewing resumes manually. Fortunately, a skills assessment can completely replace resume screening.
Before you ask your candidates any scenario-based SQL questions, use skills assessments to create a shortlist of candidates to invite for an interview.
You can build a SQL skills assessment that suits your SQL role by choosing from our SQLite (Coding): Entry-Level Database Operations test , SQLite (Coding): Intermediate-Level Querying test , and other relevant tests.
You can rank applicants from most to least skilled based on their test scores. Invite the best candidates to an interview after receiving their results, and ask questions about their personality, career, and education. From there, you can begin testing their knowledge with scenario-based SQL interview questions.
Any position that requires the management or use of databases needs a candidate skilled in SQL. However, experience and training don’t always translate to the ability to use the language practically.
This is why using skills assessments and asking the right scenario-based SQL questions during the interview is essential to putting your candidate to the test.
At TestGorilla, we have a range of skills tests you can choose from to find the right candidate for your position. Learn more about how TestGorilla’s platform works with a free 30-minute session with our team.
Related posts

TestGorilla vs. Topgrading

70 payroll interview questions to hire skilled payroll staff

Why do younger generations prefer skills-based hiring?
Hire the best candidates with TestGorilla
Create pre-employment assessments in minutes to screen candidates, save time, and hire the best talent.

Latest posts

The best advice in pre-employment testing, in your inbox.
No spam. Unsubscribe at any time.
Hire the best. No bias. No stress.
Our screening tests identify the best candidates and make your hiring decisions faster, easier, and bias-free.
Free resources

This checklist covers key features you should look for when choosing a skills testing platform

This resource will help you develop an onboarding checklist for new hires.

How to assess your candidates' attention to detail.

Learn how to get human resources certified through HRCI or SHRM.

Learn how you can improve the level of talent at your company.

Learn how CapitalT reduced hiring bias with online skills assessments.

Learn how to make the resume process more efficient and more effective.

Improve your hiring strategy with these 7 critical recruitment metrics.

Learn how Sukhi decreased time spent reviewing resumes by 83%!

Hire more efficiently with these hacks that 99% of recruiters aren't using.

Make a business case for diversity and inclusion initiatives with this data.
SQL Scenario based Interview Questions
1. how to select unique records from a table using a sql query.
Consider below EMPLOYEE table as the source data
| 100 | Jennifer | 4400 |
| 100 | Jennifer | 4400 |
| 101 | Michael | 13000 |
| 101 | Michael | 13000 |
| 101 | Michael | 13000 |
| 102 | Pat | 6000 |
| 102 | Pat | 6000 |
| 103 | Den | 11000 |
METHOD-1: Using GROUP BY Function
GROUP BY clause is used with SELECT statement to collect data from multiple records and group the results by one or more columns. The GROUP BY clause returns one row per group. By applying GROUP BY function on all the source columns, unique records can be queried from the table.
Below is the query to fetch the unique records using GROUP BY function.
| 100 | Jennifer | 4400 |
| 101 | Michael | 13000 |
| 102 | Pat | 6000 |
| 103 | Den | 11000 |
Related Article: GROUP BY ALL Function
METHOD-2: Using ROW_NUMBER Analytic Function
The ROW_NUMBER Analytic function is used to provide consecutive numbering of the rows in the result by the ORDER selected for each PARTITION specified in the OVER clause. It will assign the value 1 for the first row and increase the number of the subsequent rows.
Using ROW_NUMBER Analytic function, assign row numbers to each unique set of records.
| 100 | Jennifer | 4400 | 1 |
| 100 | Jennifer | 4400 | 2 |
| 101 | Michael | 13000 | 1 |
| 101 | Michael | 13000 | 2 |
| 101 | Michael | 13000 | 3 |
| 102 | Pat | 6000 | 1 |
| 102 | Pat | 6000 | 2 |
| 103 | Den | 11000 | 1 |
Once row numbers are assigned, by querying the rows with row number 1 will give the unique records from the table.
| 101 | Michael | 13000 |
| 100 | Jennifer | 4400 |
| 102 | Pat | 6000 |
| 103 | Den | 11000 |
Related Article: Filter Window Functions using QUALIFY Clause
2. How to delete DUPLICATE records from a table using a SQL Query?
Consider the same EMPLOYEE table as source discussed in previous question
METHOD-1: Using ROWID and ROW_NUMBER Analytic Function
An Oracle server assigns each row in each table with a unique ROWID to identify the row in the table. The ROWID is the address of the row which contains the data object number, the data block of the row, the row position and data file.
STEP-1: Using ROW_NUMBER Analytic function, assign row numbers to each unique set of records. Select ROWID of the rows along with the source columns
| AAASnBAAEAAACrWAAA | 100 | Jennifer | 4400 | 1 |
| AAASnBAAEAAACrWAAB | 100 | Jennifer | 4400 | 2 |
| AAASnBAAEAAACrWAAC | 101 | Michael | 13000 | 1 |
| AAASnBAAEAAACrWAAD | 101 | Michael | 13000 | 2 |
| AAASnBAAEAAACrWAAE | 101 | Michael | 13000 | 3 |
| AAASnBAAEAAACrWAAF | 102 | Pat | 6000 | 1 |
| AAASnBAAEAAACrWAAG | 102 | Pat | 6000 | 2 |
| AAASnBAAEAAACrWAAH | 103 | Den | 11000 | 1 |
STEP-2: Select ROWID of records with ROW_NUMBER > 1
| AAASnBAAEAAACrWAAB |
| AAASnBAAEAAACrWAAD |
| AAASnBAAEAAACrWAAE |
| AAASnBAAEAAACrWAAG |
STEP-3: Delete the records from the source table using the ROWID values fetched in previous step
The table EMPLOYEE will have below records after deleting the duplicates
| AAASnBAAEAAACrWAAA | 100 | Jennifer | 4400 |
| AAASnBAAEAAACrWAAC | 101 | Michael | 13000 |
| AAASnBAAEAAACrWAAF | 102 | Pat | 6000 |
| AAASnBAAEAAACrWAAH | 103 | Den | 11000 |
METHOD-2: Using ROWID and Correlated subquery
Correlated subquery is used for row-by-row processing. With a normal nested subquery, the inner SELECT query runs once and executes first. The returning values will be used by the main query. A correlated subquery, however, executes once for every row of the outer query. In other words, the inner query is driven by the outer query.
In the below query, we are comparing the ROWIDs’ of the unique set of records and keeping the record with MIN ROWID and deleting all other rows.
The opposite of above discussed case can be implemented by keeping the record with MAX ROWID from the unique set of records and delete all other duplicates by executing below query.
Related Article: How to Remove Duplicates in Snowflake?
3. How to read TOP 5 records from a table using a SQL query?
Consider below table DEPARTMENTS as the source data
| 10 | Administration |
| 20 | Marketing |
| 30 | Purchasing |
| 40 | Human Resources |
| 50 | Shipping |
| 60 | IT |
| 70 | Public Relations |
| 80 | Sales |
ROWNUM is a “Pseudocolumn” that assigns a number to each row returned by a query indicating the order in which Oracle selects the row from a table. The first row selected has a ROWNUM of 1, the second has 2, and so on.
| 10 | Administration |
| 20 | Marketing |
| 30 | Purchasing |
| 40 | Human Resources |
| 50 | Shipping |
4. How to read LAST 5 records from a table using a SQL query?
Consider the same DEPARTMENTS table as source discussed in previous question.
In order to select the last 5 records we need to find ( count of total number of records – 5 ) which gives the count of records from first to last but 5 records.
Using the MINUS function we can compare all records from DEPARTMENTS table with records from first to last but 5 from DEPARTMENTS table which give the last 5 records of the table as result.
MINUS operator is used to return all rows in the first SELECT statement that are not present in the second SELECT statement.
| 40 | Human Resources |
| 50 | Shipping |
| 60 | IT |
| 70 | Public Relations |
| 80 | Sales |
5. What is the result of Normal Join, Left Outer Join, Right Outer Join and Full Outer Join between the tables A & B?
| 1 |
| 1 |
| 0 |
| null |
| 1 |
| 0 |
| null |
| null |
Normal Join :
Normal Join or Inner Join is the most common type of join. It returns the rows that are exact match between both the tables.
The following Venn diagram illustrates a Normal join when combining two result sets:
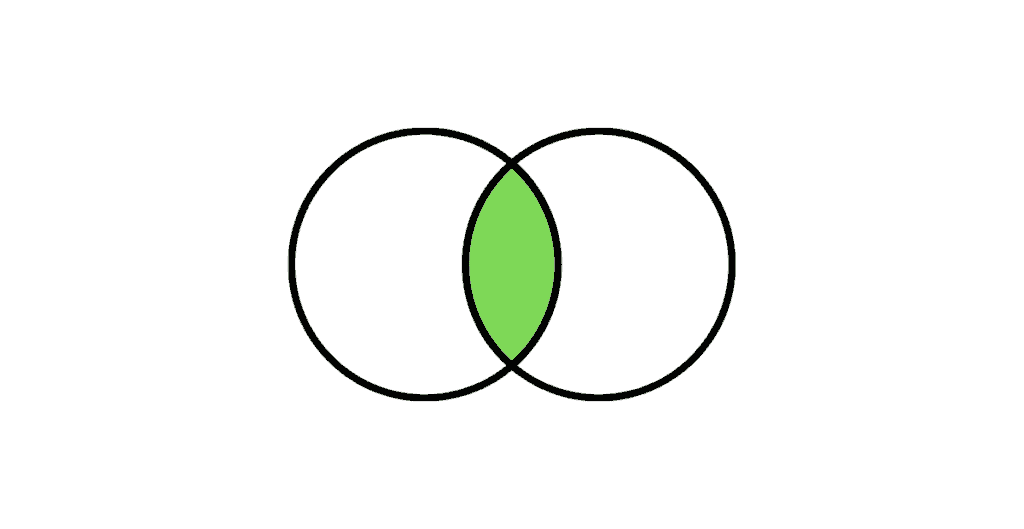
| 1 | 1 |
| 1 | 1 |
| 0 | 0 |
Left Outer Join :
The Left Outer Join returns all the rows from the left table and only the matching rows from the right table. If there is no matching row found from the right table, the left outer join will have NULL values for the columns from right table.
The following Venn diagram illustrates a Left join when combining two result sets:
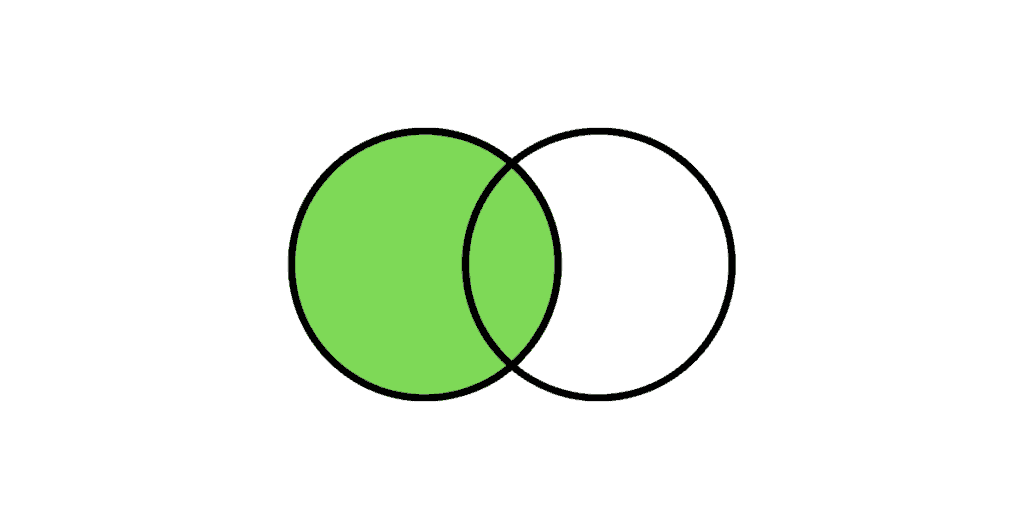
| 1 | 1 |
| 1 | 1 |
| 0 | 0 |
| NULL | NULL |
Right Outer Join:
The Right Outer Join returns all the rows from the right table and only the matching rows from the left table. If there is no matching row found from the left table, the right outer join will have NULL values for the columns from left table.
The following Venn diagram illustrates a Right join when combining two result sets:
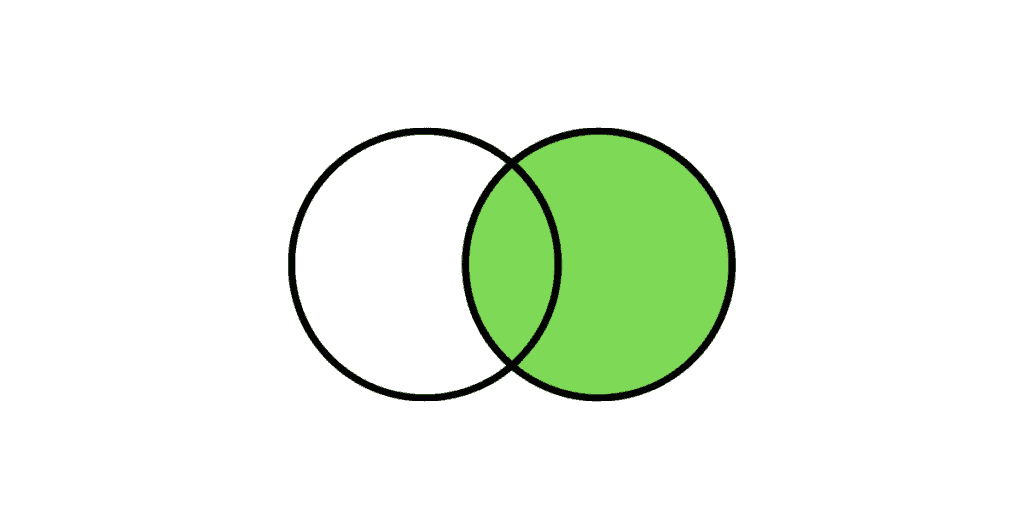
| 1 | 1 |
| 1 | 1 |
| 0 | 0 |
| NULL | NULL |
| NULL | NULL |
Full Outer Join:
The Full Outer Join returns all the rows from both the right table and the left table. If there is no matching row found, the missing side columns will have NULL values.
The following Venn diagram illustrates a Full join when combining two result sets:
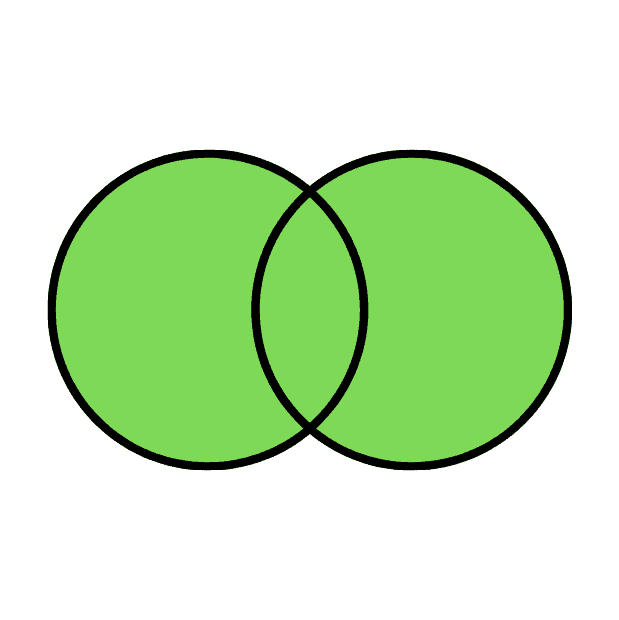
| 1 | 1 |
| 1 | 1 |
| 0 | 0 |
| NULL | NULL |
| NULL | NULL |
| NULL | NULL |
NOTE: NULL do not match with NULL
6. How to find the employee with second MAX Salary using a SQL query?
Consider below EMPLOYEES table as the source data
| 100 | Jennifer | 4400 |
| 101 | Michael | 13000 |
| 102 | Pat | 6000 |
| 103 | Den | 11000 |
| 104 | Alexander | 3100 |
| 105 | Shelli | 2900 |
| 106 | Sigel | 2800 |
| 107 | Guy | 2600 |
| 108 | Karen | 2500 |
METHOD-1: Without using SQL Analytic Functions
In order to find the second MAX salary, employee record with MAX salary needs to be eliminated. It can be achieved by using below SQL query.
| 11000 |
The above query only gives the second MAX salary value. In order to fetch the entire employee record with second MAX salary we need to do a self-join on Employee table based on Salary value.
| 103 | Den | 11000 |
METHOD-2: Using SQL Analytic Functions
The DENSE_RANK is an analytic function that calculates the rank of a row in an ordered set of rows starting from 1. Unlike the RANK function, the DENSE_RANK function returns rank values as consecutive integers.
By replacing the value of SALARY_RANK, any highest salary rank can be found easily.
Related Article: SQL Analytic Functions Interview Questions
7. How to find the employee with third MAX Salary using a SQL query without using Analytic Functions?
Consider the same EMPLOYEES table as source discussed in previous question
In order to find the third MAX salary, we need to eliminate the top 2 salary records. But we cannot use the same method we used for finding second MAX salary (not a best practice). Imagine if we have to find the fifth MAX salary. We should not be writing a query with four nested sub queries.
The approach here is to first list all the records based on Salary in the descending order with MAX salary on top and MIN salary at bottom. Next, using ROWNUM select the top 2 records.
| 13000 |
| 11000 |
Next find the MAX salary from EMPLOYEE table which is not one of top two salary values fetched in the earlier step.
| 6000 |
In order to fetch the entire employee record with third MAX salary we need to do a self-join on Employee table based on Salary value.
| 102 | Pat | 6000 |
In order to find the employee with nth highest salary, replace the rownum value with n in above query.
8. Write an SQL query to find authors with more than one book and an average book price exceeding $10.
Consider below BOOKS table as the source data .
| BOOK-1 | AUTHOR-1 | 10.99 |
| BOOK-2 | AUTHOR-2 | 12.99 |
| BOOK-3 | AUTHOR-3 | 8.99 |
| BOOK-4 | AUTHOR-4 | 9.99 |
| BOOK-5 | AUTHOR-2 | 9.99 |
| BOOK-6 | AUTHOR-2 | 15.99 |
| BOOK-7 | AUTHOR-3 | 13.99 |
| BOOK-8 | AUTHOR-4 | 7.99 |
Using HAVING Clause :
HAVING clause in SQL is used in conjunction with the GROUP BY clause to filter the results of a query based on aggregated values. Unlike the WHERE clause, which filters individual rows before they are grouped, the HAVING clause filters the result set after the grouping and aggregation process.
Using GROUP BY clause, we can find the number of books published and the average price of books published by each author as shown below.
| AUTHOR-1 | 1 | 10.99 |
| AUTHOR-2 | 3 | 12.99 |
| AUTHOR-3 | 2 | 11.49 |
| AUTHOR-4 | 2 | 8.99 |
Then the HAVING clause can be applied to filter the results of the grouped data as shown below.
| AUTHOR-2 | 3 | 12.99 |
| AUTHOR-3 | 2 | 11.49 |
To display only the Author information, retrieve the Author details from the previous query as shown below.
| AUTHOR-2 |
| AUTHOR-2 |
9. How to update records in a table based on the values from another table using a SQL query?
Consider below EMPLOYEES and DEPARTMENTS tables as the source data. Both tables can be linked using the DEPARTMENT_ID fields in each of the tables.
| 101 | Michael | 13000 | 10 |
| 100 | Jennifer | 4400 | 20 |
| 102 | Pat | 6000 | 20 |
| 103 | Den | 11000 | 30 |
| 104 | Steve | 5000 | 40 |
DEPARTMENTS:
| 10 | HR |
| 20 | IT |
| 30 | Sales |
| 40 | Finance |
Scenario-1: Update Salary of all employees by 5% belonging to department id 20
This is straightforward forward and the data in employees can be updated using UPDATE statement as shown below.
Scenario-2: Update Salary of all employees by 5% belonging to IT department
In this scenario, we do not have information of department name in the employees table. We need to join EMPLOYEES table with DEPARTMENTS table using DEPARTMENT_ID field to get information of employees belonging to IT department.
Method-1: Using Sub-Queries
The below query updates Salary of all employees by 5% belonging to IT department employing a subquery for the department identification.
Method-2: Using UPDATE…FROM
The UPDATE…FROM statement allows you to update values in a table based on data from another table, similar to how you would use a join in a SELECT statement.
The below query updates Salary of all employees by 5% belonging to IT department using UPDATE…FROM syntax.
The UPDATE…FROM syntax often leads to more concise and readable code compared to using subqueries. The syntax also allows for a more straightforward representation of complex update scenarios involving multiple tables and conditions.
10. How to delete records in a table based on the values from another table using a SQL query?
Scenario-1: Delete records of all employees by belonging to department id 20
This is straight forward and the data in employees can be deleted using DELETE statement as shown below.
Scenario-2: Delete records of all employees belonging to IT department
The below query deletes records of all employees belonging to IT department employing a subquery for the department identification.
Method-2: Using DELETE…USING
The DELETE…USING statement allows you to update values in a table based on data from another table, similar to how you would use a join in a SELECT statement.
The below query deletes records of all employees belonging to IT department using DELETE…USING syntax.
The DELETE…USING syntax is more commonly associated with databases like Snowflake, PostgreSQL, where it allows you to specify additional tables to be used in the DELETE operation. This can be useful when you need to delete records from one table based on conditions involving another table(s).
It’s important to note that the exact syntax and features might not be supported in some databases.
Subscribe to our Newsletter !!
Related Articles:

26 thoughts on “SQL Scenario based Interview Questions”
Very nice explanation
Thank you Vikash !!
Hello, The questions as well as the answers are really clear. Thank you so much for putting up this content. It was really helpful, while preparing for technical rounds.
Thanks Nivi. Appreciate your feedback!!
It is very useful ….
Thank you Manoj
Good informative questions
Thanks Shubham!!
Most of these questions are asked me in Accenture Data Engineering interview
This is really nice and helpful. Been all over the place looking for such. Thanks for putting this up.
Thanks for your feedback..Glad it helped!!
Excellent, Great Blog , Very nice Explanation Thumbs Up.
Thank you!!
amazing and very practical scenarios cover advanced interview scenarios
Very Clear explanation Thank you so much.
Thanks Gayathri.. Glad it helped!!
really superb..thanks a lot by giving answers with full clarity…..
Thanks Siva!!
Nice way of explanation!
Thanks Shweta!!
this is actually what I am looking and you fulfilled it. thumbs-up….👍
Thanks for the feedback. Glad it helped !!
This Blog has detailed explanation for every question. Great work!!!
Thanks Raghava. Glad it is helpful!!
Explained clearly thank you.
Leave a Comment Cancel reply
Save my name, email, and website in this browser for the next time I comment.
Related Posts

Date Functions in Informatica Cloud (IICS)

Informatica Cloud (IICS) Functions Guide

HOW TO: Run Informatica Cloud Taskflow with Run Using option?
41 Essential SQL Interview Questions *
Toptal sourced essential questions that the best sql developers and engineers can answer. driven from our community, we encourage experts to submit questions and offer feedback..
Interview Questions
What does UNION do? What is the difference between UNION and UNION ALL ?
UNION merges the contents of two structurally-compatible tables into a single combined table. The difference between UNION and UNION ALL is that UNION will omit duplicate records whereas UNION ALL will include duplicate records.
It is important to note that the performance of UNION ALL will typically be better than UNION , since UNION requires the server to do the additional work of removing any duplicates. So, in cases where is is certain that there will not be any duplicates, or where having duplicates is not a problem, use of UNION ALL would be recommended for performance reasons.
List and explain the different types of JOIN clauses supported in ANSI-standard SQL.
ANSI-standard SQL specifies five types of JOIN clauses as follows:
INNER JOIN (a.k.a. “simple join”): Returns all rows for which there is at least one match in BOTH tables. This is the default type of join if no specific JOIN type is specified.
LEFT JOIN (or LEFT OUTER JOIN ): Returns all rows from the left table, and the matched rows from the right table; i.e., the results will contain all records from the left table, even if the JOIN condition doesn’t find any matching records in the right table. This means that if the ON clause doesn’t match any records in the right table, the JOIN will still return a row in the result for that record in the left table, but with NULL in each column from the right table.
RIGHT JOIN (or RIGHT OUTER JOIN ): Returns all rows from the right table, and the matched rows from the left table. This is the exact opposite of a LEFT JOIN ; i.e., the results will contain all records from the right table, even if the JOIN condition doesn’t find any matching records in the left table. This means that if the ON clause doesn’t match any records in the left table, the JOIN will still return a row in the result for that record in the right table, but with NULL in each column from the left table.
FULL JOIN (or FULL OUTER JOIN ): Returns all rows for which there is a match in EITHER of the tables. Conceptually, a FULL JOIN combines the effect of applying both a LEFT JOIN and a RIGHT JOIN ; i.e., its result set is equivalent to performing a UNION of the results of left and right outer queries.
CROSS JOIN : Returns all records where each row from the first table is combined with each row from the second table (i.e., returns the Cartesian product of the sets of rows from the joined tables). Note that a CROSS JOIN can either be specified using the CROSS JOIN syntax (“explicit join notation”) or (b) listing the tables in the FROM clause separated by commas without using a WHERE clause to supply join criteria (“implicit join notation”).
Given the following tables:
What will be the result of the query below?
Explain your answer and also provide an alternative version of this query that will avoid the issue that it exposes.
Surprisingly, given the sample data provided, the result of this query will be an empty set. The reason for this is as follows: If the set being evaluated by the SQL NOT IN condition contains any values that are null, then the outer query here will return an empty set, even if there are many runner ids that match winner_ids in the races table.
Knowing this, a query that avoids this issue would be as follows:
Note, this is assuming the standard SQL behavior that you get without modifying the default ANSI_NULLS setting.
Apply to Join Toptal's Development Network
and enjoy reliable, steady, remote Freelance SQL Developer Jobs
Given two tables created and populated as follows:
What will the result be from the following query:
Explain your answer.
The result of the query will be as follows:
The EXISTS clause in the above query is a red herring. It will always be true since ID is not a member of dbo.docs . As such, it will refer to the envelope table comparing itself to itself!
The idnum value of NULL will not be set since the join of NULL will not return a result when attempting a match with any value of envelope .
Assume a schema of Emp ( Id, Name, DeptId ) , Dept ( Id, Name) .
If there are 10 records in the Emp table and 5 records in the Dept table, how many rows will be displayed in the result of the following SQL query:
The query will result in 50 rows as a “cartesian product” or “cross join”, which is the default whenever the ‘where’ clause is omitted.
Given two tables created as follows
Write a query to fetch values in table test_a that are and not in test_b without using the NOT keyword.
Note, Oracle does not support the above INSERT syntax, so you would need this instead:
In SQL Server, PostgreSQL, and SQLite, this can be done using the except keyword as follows:
In Oracle, the minus keyword is used instead. Note that if there are multiple columns, say ID and Name, the column should be explicitly stated in Oracle queries: Select ID from test_a minus select ID from test_b
MySQL does not support the except function. However, there is a standard SQL solution that works in all of the above engines, including MySQL:
Write a SQL query to find the 10th highest employee salary from an Employee table. Explain your answer.
(Note: You may assume that there are at least 10 records in the Employee table.)
This can be done as follows:
This works as follows:
First, the SELECT DISTINCT TOP (10) Salary FROM Employee ORDER BY Salary DESC query will select the top 10 salaried employees in the table. However, those salaries will be listed in descending order. That was necessary for the first query to work, but now picking the top 1 from that list will give you the highest salary not the the 10th highest salary.
Therefore, the second query reorders the 10 records in ascending order (which the default sort order) and then selects the top record (which will now be the lowest of those 10 salaries).
Not all databases support the TOP keyword. For example, MySQL and PostreSQL use the LIMIT keyword, as follows:
Or even more concisely, in MySQL this can be:
And in PostgreSQL this can be:
Write a SQL query using UNION ALL ( not UNION ) that uses the WHERE clause to eliminate duplicates. Why might you want to do this?
You can avoid duplicates using UNION ALL and still run much faster than UNION DISTINCT (which is actually same as UNION) by running a query like this:
The key is the AND a!=X part. This gives you the benefits of the UNION (a.k.a., UNION DISTINCT ) command, while avoiding much of its performance hit.
Write a query to to get the list of users who took the a training lesson more than once in the same day, grouped by user and training lesson, each ordered from the most recent lesson date to oldest date.
What is an execution plan? When would you use it? How would you view the execution plan?
An execution plan is basically a road map that graphically or textually shows the data retrieval methods chosen by the SQL server’s query optimizer for a stored procedure or ad hoc query. Execution plans are very useful for helping a developer understand and analyze the performance characteristics of a query or stored procedure, since the plan is used to execute the query or stored procedure.
In many SQL systems, a textual execution plan can be obtained using a keyword such as EXPLAIN , and visual representations can often be obtained as well. In Microsoft SQL Server, the Query Analyzer has an option called “Show Execution Plan” (located on the Query drop down menu). If this option is turned on, it will display query execution plans in a separate window when a query is run.
List and explain each of the ACID properties that collectively guarantee that database transactions are processed reliably.
ACID (Atomicity, Consistency, Isolation, Durability) is a set of properties that guarantee that database transactions are processed reliably. They are defined as follows:
- Atomicity. Atomicity requires that each transaction be “all or nothing”: if one part of the transaction fails, the entire transaction fails, and the database state is left unchanged. An atomic system must guarantee atomicity in each and every situation, including power failures, errors, and crashes.
- Consistency. The consistency property ensures that any transaction will bring the database from one valid state to another. Any data written to the database must be valid according to all defined rules, including constraints, cascades, triggers, and any combination thereof.
- Isolation. The isolation property ensures that the concurrent execution of transactions results in a system state that would be obtained if transactions were executed serially, i.e., one after the other. Providing isolation is the main goal of concurrency control. Depending on concurrency control method (i.e. if it uses strict - as opposed to relaxed - serializability), the effects of an incomplete transaction might not even be visible to another transaction.
- Durability. Durability means that once a transaction has been committed, it will remain so, even in the event of power loss, crashes, or errors. In a relational database, for instance, once a group of SQL statements execute, the results need to be stored permanently (even if the database crashes immediately thereafter). To defend against power loss, transactions (or their effects) must be recorded in a non-volatile memory.
Given a table dbo.users where the column user_id is a unique numeric identifier, how can you efficiently select the first 100 odd user_id values from the table?
(Assume the table contains well over 100 records with odd user_id values.)
SELECT TOP 100 user_id FROM dbo.users WHERE user_id % 2 = 1 ORDER BY user_id
What are the NVL and the NVL2 functions in SQL? How do they differ?
Both the NVL(exp1, exp2) and NVL2(exp1, exp2, exp3) functions check the value exp1 to see if it is null.
With the NVL(exp1, exp2) function, if exp1 is not null, then the value of exp1 is returned; otherwise, the value of exp2 is returned, but case to the same data type as that of exp1 .
With the NVL2(exp1, exp2, exp3) function, if exp1 is not null, then exp2 is returned; otherwise, the value of exp3 is returned.
How can you select all the even number records from a table? All the odd number records?
To select all the even number records from a table:
To select all the odd number records from a table:
What is the difference between the RANK() and DENSE_RANK() functions? Provide an example.
The only difference between the RANK() and DENSE_RANK() functions is in cases where there is a “tie”; i.e., in cases where multiple values in a set have the same ranking. In such cases, RANK() will assign non-consecutive “ranks” to the values in the set (resulting in gaps between the integer ranking values when there is a tie), whereas DENSE_RANK() will assign consecutive ranks to the values in the set (so there will be no gaps between the integer ranking values in the case of a tie).
For example, consider the set {25, 25, 50, 75, 75, 100} . For such a set, RANK() will return {1, 1, 3, 4, 4, 6} (note that the values 2 and 5 are skipped), whereas DENSE_RANK() will return {1,1,2,3,3,4} .
What is the difference between the WHERE and HAVING clauses?
When GROUP BY is not used, the WHERE and HAVING clauses are essentially equivalent.
However, when GROUP BY is used:
- The WHERE clause is used to filter records from a result. The filtering occurs before any groupings are made.
- The HAVING clause is used to filter values from a group (i.e., to check conditions after aggregation into groups has been performed).
Given a table Employee having columns empName and empId , what will be the result of the SQL query below?
“Order by 2” is only valid when there are at least two columns being used in select statement. However, in this query, even though the Employee table has 2 columns, the query is only selecting 1 column name, so “Order by 2” will cause the statement to throw an error while executing the above sql query.
What will be the output of the below query, given an Employee table having 10 records?
This query will return 10 records as TRUNCATE was executed in the transaction. TRUNCATE does not itself keep a log but BEGIN TRANSACTION keeps track of the TRUNCATE command.
- What is the difference between single-row functions and multiple-row functions?
- What is the group by clause used for?
- Single-row functions work with single row at a time. Multiple-row functions work with data of multiple rows at a time.
- The group by clause combines all those records that have identical values in a particular field or any group of fields.
Imagine a single column in a table that is populated with either a single digit (0-9) or a single character (a-z, A-Z). Write a SQL query to print ‘Fizz’ for a numeric value or ‘Buzz’ for alphabetical value for all values in that column.
['d', 'x', 'T', 8, 'a', 9, 6, 2, 'V']
…should output:
['Buzz', 'Buzz', 'Buzz', 'Fizz', 'Buzz','Fizz', 'Fizz', 'Fizz', 'Buzz']
What is the difference between char and varchar2 ?
When stored in a database, varchar2 uses only the allocated space. E.g. if you have a varchar2(1999) and put 50 bytes in the table, it will use 52 bytes.
But when stored in a database, char always uses the maximum length and is blank-padded. E.g. if you have char(1999) and put 50 bytes in the table, it will consume 2000 bytes.
Write an SQL query to display the text CAPONE as:
Or in other words, an SQL query to transpose text.
In Oracle SQL, this can be done as follows:
Can we insert a row for identity column implicitly?
Yes, like so:
Given this table:
What will be the output of below snippet?
Table is as follows:
| ID | C1 | C2 | C3 |
|---|---|---|---|
| 1 | Red | Yellow | Blue |
| 2 | NULL | Red | Green |
| 3 | Yellow | NULL | Violet |
Print the rows which have ‘Yellow’ in one of the columns C1, C2, or C3, but without using OR .
Write a query to insert/update Col2 ’s values to look exactly opposite to Col1 ’s values.
| Col1 | Col2 |
|---|---|
| 1 | 0 |
| 0 | 1 |
| 0 | 1 |
| 0 | 1 |
| 1 | 0 |
| 0 | 1 |
| 1 | 0 |
| 1 | 0 |
Or if the type is numeric:
How do you get the last id without the max function?
In SQL Server:
What is the difference between IN and EXISTS ?
- Works on List result set
- Doesn’t work on subqueries resulting in Virtual tables with multiple columns
- Compares every value in the result list
- Performance is comparatively SLOW for larger resultset of subquery
- Works on Virtual tables
- Is used with co-related queries
- Exits comparison when match is found
- Performance is comparatively FAST for larger resultset of subquery
Suppose in a table, seven records are there.
The column is an identity column.
Now the client wants to insert a record after the identity value 7 with its identity value starting from 10 .
Is it possible? If so, how? If not, why not?
Yes, it is possible, using a DBCC command:
How can you use a CTE to return the fifth highest (or Nth highest) salary from a table?
Given the following table named A :
Write a single query to calculate the sum of all positive values of x and he sum of all negative values of x .
Given the table mass_table :
| weight |
|---|
| 5.67 |
| 34.567 |
| 365.253 |
| 34 |
Write a query that produces the output:
| weight | kg | gms |
|---|---|---|
| 5.67 | 5 | 67 |
| 34.567 | 34 | 567 |
| 365.253 | 365 | 253 |
| 34 | 34 | 0 |
Consider the Employee table below.
| Emp_Id | Emp_name | Salary | Manager_Id |
|---|---|---|---|
| 10 | Anil | 50000 | 18 |
| 11 | Vikas | 75000 | 16 |
| 12 | Nisha | 40000 | 18 |
| 13 | Nidhi | 60000 | 17 |
| 14 | Priya | 80000 | 18 |
| 15 | Mohit | 45000 | 18 |
| 16 | Rajesh | 90000 | – |
| 17 | Raman | 55000 | 16 |
| 18 | Santosh | 65000 | 17 |
Write a query to generate below output:
| Manager_Id | Manager | Average_Salary_Under_Manager |
|---|---|---|
| 16 | Rajesh | 65000 |
| 17 | Raman | 62500 |
| 18 | Santosh | 53750 |
How do you copy data from one table to another table ?
Find the SQL statement below that is equal to the following: SELECT name FROM customer WHERE state = 'VA';
- SELECT name IN customer WHERE state IN ('VA');
- SELECT name IN customer WHERE state = 'VA';
- SELECT name IN customer WHERE state = 'V';
- SELECT name FROM customer WHERE state IN ('VA');
Given these contents of the Customers table:
Here is a query written to return the list of customers not referred by Jane Smith:
What will be the result of the query? Why? What would be a better way to write it?
Although there are 4 customers not referred by Jane Smith (including Jane Smith herself), the query will only return one: Pat Richards. All the customers who were referred by nobody at all (and therefore have NULL in their ReferredBy column) don’t show up. But certainly those customers weren’t referred by Jane Smith, and certainly NULL is not equal to 2, so why didn’t they show up?
SQL Server uses three-valued logic, which can be troublesome for programmers accustomed to the more satisfying two-valued logic (TRUE or FALSE) most programming languages use. In most languages, if you were presented with two predicates: ReferredBy = 2 and ReferredBy <> 2, you would expect one of them to be true and one of them to be false, given the same value of ReferredBy. In SQL Server, however, if ReferredBy is NULL, neither of them are true and neither of them are false. Anything compared to NULL evaluates to the third value in three-valued logic: UNKNOWN.
The query should be written in one of two ways:
Watch out for the following, though!
This will return the same faulty set as the original. Why? We already covered that: Anything compared to NULL evaluates to the third value in the three-valued logic: UNKNOWN. That “anything” includes NULL itself! That’s why SQL Server provides the IS NULL and IS NOT NULL operators to specifically check for NULL. Those particular operators will always evaluate to true or false.
Even if a candidate doesn’t have a great amount of experience with SQL Server, diving into the intricacies of three-valued logic in general can give a good indication of whether they have the ability learn it quickly or whether they will struggle with it.
Given a table TBL with a field Nmbr that has rows with the following values:
1, 0, 0, 1, 1, 1, 1, 0, 0, 1, 0, 1, 0, 1, 0, 1
Write a query to add 2 where Nmbr is 0 and add 3 where Nmbr is 1.
Suppose we have a Customer table containing the following data:
Write a single SQL statement to concatenate all the customer names into the following single semicolon-separated string:
This is close, but will have an undesired trailing ; . One way of fixing that could be:
In PostgreSQL one can also use this syntax to achieve the fully correct result:
How do you get the Nth-highest salary from the Employee table without a subquery or CTE?
This will give the third-highest salary from the Employee table. Accordingly we can find out Nth salary using LIMIT (N-1),1 .
But MS SQL Server doesn’t support that syntax, so in that case:
OFFSET ’s parameter corresponds to the (N-1) above.
How to find a duplicate record?
duplicate records with one field
duplicate records with more than one field
Considering the database schema displayed in the SQLServer-style diagram below, write a SQL query to return a list of all the invoices. For each invoice, show the Invoice ID, the billing date, the customer’s name, and the name of the customer who referred that customer (if any). The list should be ordered by billing date.
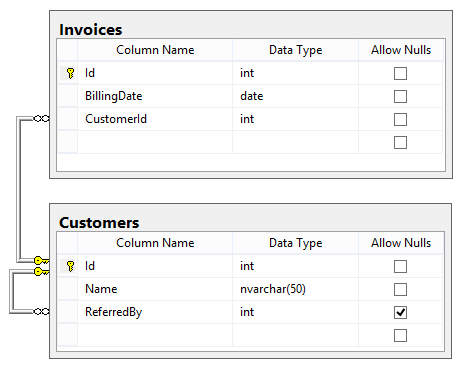
This question simply tests the candidate’s ability take a plain-English requirement and write a corresponding SQL query. There is nothing tricky in this one, it just covers the basics:
Did the candidate remember to use a LEFT JOIN instead of an inner JOIN when joining the customer table for the referring customer name? If not, any invoices by customers not referred by somebody will be left out altogether.
Did the candidate alias the tables in the JOIN? Most experienced T-SQL programmers always do this, because repeating the full table name each time it needs to be referenced gets tedious quickly. In this case, the query would actually break if at least the Customer table wasn’t aliased, because it is referenced twice in different contexts (once as the table which contains the name of the invoiced customer, and once as the table which contains the name of the referring customer).
Did the candidate disambiguate the Id and Name columns in the SELECT? Again, this is something most experienced programmers do automatically, whether or not there would be a conflict. And again, in this case there would be a conflict, so the query would break if the candidate neglected to do so.
Note that this query will not return Invoices that do not have an associated Customer. This may be the correct behavior for most cases (e.g., it is guaranteed that every Invoice is associated with a Customer, or unmatched Invoices are not of interest). However, in order to guarantee that all Invoices are returned no matter what, the Invoices table should be joined with Customers using LEFT JOIN:
There is more to interviewing than tricky technical questions, so these are intended merely as a guide. Not every “A” candidate worth hiring will be able to answer them all, nor does answering them all guarantee an “A” candidate. At the end of the day, hiring remains an art, a science — and a lot of work .
Tired of interviewing candidates? Not sure what to ask to get you a top hire?
Let Toptal find the best people for you.
Our Exclusive Network of SQL Developers
Looking to land a job as a SQL Developer?
Let Toptal find the right job for you.
Job Opportunities From Our Network
Submit an interview question
Submitted questions and answers are subject to review and editing, and may or may not be selected for posting, at the sole discretion of Toptal, LLC.
Looking for SQL Developers?
Looking for SQL Developers ? Check out Toptal’s SQL developers.

Andrea Angiolini
Andrea's been working in hospitality technology for over 20 years and has been involved in almost every aspect of it: database administration, SQL reports, database development (PL/SQL), product management, project management, design of new products, implementation, process automation, support, training, and senior management. Andrea has delivered several projects involving coordinating teams, including OTA-based integrations, full end-to-end solutions, and a full customer intelligence database.

Jeremy Barrio
Jeremy is a Microsoft SQL Server database administrator and T-SQL developer offering nearly 15 years of experience working with SQL Server 2008-2019, developing T-SQL queries and stored procedures, managing database-related projects, monitoring and optimizing databases, and developing and maintaining recurring automated processes using SQL jobs, SSIS, and PowerShell. Jeremy enjoys learning new technologies and excels with replication, HA/DR, and clustering.

Pedro Correia
Pedro has been working with Microsoft technologies since the early days of MS-DOS and GW-BASIC when he became fascinated with DBMS and used SQL Server 6.5 for the first time. During the last 20 years, he's implemented numerous web and Windows solutions in .NET, using SQL Server on the back end. Also, he taught several official Microsoft courses where he shared his expertise in the field. In one sentence, Pedro is eager to learn, inspired by challenges, and motivated to share.
Toptal Connects the Top 3% of Freelance Talent All Over The World.
Join the Toptal community.
Navigation Menu
Search code, repositories, users, issues, pull requests..., provide feedback.
We read every piece of feedback, and take your input very seriously.
Saved searches
Use saved searches to filter your results more quickly.
To see all available qualifiers, see our documentation .
- Notifications You must be signed in to change notification settings
A comprehensive collection of SQL case studies, queries, and solutions for real-world scenarios. This repository provides a hands-on approach to mastering SQL skills through a series of case studies, including table structures, sample data, and SQL queries.
tituHere/SQL-Case-Study
Folders and files.
| Name | Name | |||
|---|---|---|---|---|
| 1 Commit | ||||
Practice Interview Questions
Get 1:1 Coaching
20 Advanced SQL Interview Questions (With Answers!)
By Nick Singh
(Ex-Facebook & Best-Selling Data Science Author)
Currently, he’s the best-selling author of Ace the Data Science Interview, and Founder & CEO of DataLemur.
March 25, 2024
Looking to ace your next SQL interview with confidence? Test yourself with these 20 advanced SQL interview questions, each accompanied by detailed answers to help you impress recruiters and land that dream job.
These questions cover everything from complex queries to data manipulation and optimization techniques, and equip you with the knowledge you need to excel in any SQL interview scenario .
How many questions can you solve?
Advanced SQL Interview Questions
Interview questions that test practical and conceptual SQL skills are to test the candidate's ability to translate knowledge into effective solutions. The following questions are 20 SQL interview questions pulled from REAL interviews, that helped managers assess candidates' SQL skills.
While we have included sample answers for each question, remember that these are not the only correct answers. There are often multiple ways to achieve the same goal. Focus on writing clean and functional code.
1. Repeated Payments [Stripe SQL Interview Question]
Stripe asked this tricky SQL interview question, about identifying any payments made at the same merchant with the same credit card for the same amount within 10 minutes of each other and reporting the count of such repeated payments.
Input/Output Data
Example Input:
| 1 | 101 | 1 | 100 | 09/25/2022 12:00:00 |
| 2 | 101 | 1 | 100 | 09/25/2022 12:08:00 |
| 3 | 101 | 1 | 100 | 09/25/2022 12:28:00 |
| 4 | 102 | 2 | 300 | 09/25/2022 12:00:00 |
| 6 | 102 | 2 | 400 | 09/25/2022 14:00:00 |
Example Output:
| 1 |
You can solve this Stripe SQL problem interactively and get a full solution explanation:
2. Describe how recursive queries work in SQL. Provide an example scenario where a recursive query would be beneficial.
Recursive queries in SQL enable iteration over hierarchical data structures like organizational charts, bill-of-materials, or nested comments. For example, you could use a recursive query to traverse a hierarchical data structure and retrieve all descendants of a specific node.
3. Median Google Search Frequency [Google SQL Interview Question]
Google’s Marketing Team needed to add a simple statistic to their upcoming Superbowl Ad: the median number of searches made per year. You were given a summary table that tells you the number of searches made last year, write a query to report the median searches made per user.
| Column Name | Type |
|---|---|
| searches | integer |
| num_users | integer |
Input/Output Data:
| searches | num_users |
|---|---|
| 1 | 2 |
| 2 | 2 |
| 3 | 3 |
| 4 | 1 |
| median |
|---|
| 2.5 |
You can solve this Google SQL problem interactively, and get the full solution explanation .
Enjoyed this one? p.s. here's more Google SQL Interview Questions to practice!
4. What are ACID properties in SQL?
ACID properties are:
- Atomicity: Changes in the data must be like a single operation.
- Consistency: The data must be consistent before and after the transaction.
- Isolation: Multiple transactions can be done without any hindrance.
- Durability: Transaction gets successful in case of system failures.
5. Monthly Merchant Balance [Visa SQL Interview Question]
Say you have access to all the transactions for a given merchant account. Write a query to print the cumulative balance of the merchant account at the end of each day, with the total balance reset back to zero at the end of the month. Output the transaction date and cumulative balance.
| Column Name | Type |
|---|---|
| transaction_id | integer |
| type | string ('deposit', 'withdrawal') |
| amount | decimal |
| transaction_date | timestamp |
| transaction_id | type | amount | transaction_date |
|---|---|---|---|
| 19153 | deposit | 65.90 | 07/10/2022 10:00:00 |
| 53151 | deposit | 178.55 | 07/08/2022 10:00:00 |
| 29776 | withdrawal | 25.90 | 07/08/2022 10:00:00 |
| 16461 | withdrawal | 45.99 | 07/08/2022 10:00:00 |
| 77134 | deposit | 32.60 | 07/10/2022 10:00:00 |
| transaction_date | balance |
|---|---|
| 07/08/2022 12:00:00 | 106.66 |
| 07/10/2022 12:00:00 | 205.16 |
You can solve this Visa SQL problem interactively, and get the full solution explanation .
6. Explain the concept of correlated subqueries in SQL. Can you provide an example of how you can use them?
Correlated subqueries are executed once for each row of the outer query and depend on the outer query for results. For example, you could use a correlated subquery to retrieve data from one table according to conditions in a separate table.
7. Server Utilization Time [Amazon SQL Interview Question]
Fleets of servers power Amazon Web Services (AWS). Senior management has requested data-driven solutions to optimize server usage.
Write a query that calculates the total time that the fleet of servers was running. The output should be in units of full days .
Assumptions:
- Each server might start and stop several times.
- The total time in which the server fleet is running can be calculated as the sum of each server's uptime.
| server_id | integer |
| status_time | timestamp |
| session_status | string |
| server_id | status_time | session_status |
|---|---|---|
| 1 | 08/02/2022 10:00:00 | start |
| 1 | 08/04/2022 10:00:00 | stop |
| 2 | 08/17/2022 10:00:00 | start |
| 2 | 08/24/2022 10:00:00 | stop |
| total_uptime_days |
|---|
| 21 |
You can solve this Amazon SQL problem interactively, and get the full solution explanation .
Looking for more Amazon SQL Interview Questions? Check out our Amazon SQL Interview Guide for access to even more questions and solutions!
8. Explain how indexing works in a relational database. What are the benefits and potential drawbacks of indexing?
Indexing in a relational database involves creating data structures (indexes) that allow for faster data retrieval by providing direct access to rows based on the indexed columns. The benefits of indexing include improved query performance and faster data retrieval, especially for large datasets. However, indexing can also introduce overhead during data modification operations (such as INSERT, UPDATE, and DELETE) and increased storage requirements.
9. Uniquely Staffed Consultants [Accenture SQL Interview Questions]
As a Data Analyst on the People Operations team at Accenture, you are tasked with understanding how many consultants are staffed to each client, and how many consultants are exclusively staffed to a single client.
Write a query that displays the outputs of client name and the number of uniquely and exclusively staffed consultants ordered by client name.
| employee_id | integer |
| engagement_id | integer |
| employee_id | engagement_id |
|---|---|
| 1001 | 1 |
| 1001 | 2 |
| 1002 | 1 |
| 1003 | 3 |
| 1004 | 4 |
| engagement_id | integer |
| project_name | string |
| client_name | string |
| engagement_id | project_name | client_name |
|---|---|---|
| 1 | SAP Logistics Modernization | Department of Defense |
| 2 | Oracle Cloud Migration | Department of Education |
| 3 | Trust & Safety Operations | |
| 4 | SAP IoT Cloud Integration |
| client_name | total_staffed | exclusive_staffed |
|---|---|---|
| Department of Defense | 2 | 1 |
| Department of Education | 1 | 0 |
| 2 | 2 |
You can solve this Accenture SQL problem interactively, and get the full solution explanation .
10. Compare and contrast stored procedures and user-defined functions in SQL. When would you choose to use one over the other?
Stored procedures and user-defined functions (UDFs) are both reusable pieces of code in SQL, but they have some key differences. Stored procedures can perform DML operations and transaction management, while UDFs are limited to returning values and cannot perform DML operations. Stored procedures are typically used for procedural tasks and complex business logic, while UDFs are often used for calculations and data transformations.
11. Event Friends Recommendation [Facebook SQL Interview Questions]
Facebook wants to recommend new friends to people who show interest in attending 2 or more of the same private events.
Sort your results in order of user_a_id and user_b_id (refer to the Example Output below). Table:
| Column Name | Type |
|---|---|
| user_a_id | integer |
| user_b_id | integer |
| status | enum ('friends', 'not_friends') |
Each row of this table indicates the status of the friendship between user_a_id and user_b_id.
| user_a_id | user_b_id | status |
|---|---|---|
| 111 | 333 | not_friends |
| 222 | 333 | not_friends |
| 333 | 222 | not_friends |
| 222 | 111 | friends |
| 111 | 222 | friends |
| 333 | 111 | not_friends |
| Column Name | Type |
|---|---|
| user_id | integer |
| event_id | integer |
| event_type | enum ('public', 'private') |
| attendance_status | enum ('going', 'maybe', 'not_going') |
| event_date | date |
| user_id | event_id | event_type | attendance_status | event_date |
|---|---|---|---|---|
| 111 | 567 | public | going | 07/12/2022 |
| 222 | 789 | private | going | 07/15/2022 |
| 333 | 789 | private | maybe | 07/15/2022 |
| 111 | 234 | private | not_going | 07/18/2022 |
| 222 | 234 | private | going | 07/18/2022 |
| 333 | 234 | private | going | 07/18/2022 |
| user_a_id | user_b_id |
|---|---|
| 222 | 333 |
| 333 | 222 |
Users 222 and 333 who are not friends have shown interest in attending 2 or more of the same private events.
You can solve this Facebook SQL problem interactively, and get the full solution explanation .
Looking for more Facebook SQL Interview Questions? Check out our Facebook SQL Interview Guide for access to even more questions and solutions!
12. Explain the purpose of the MERGE statement in SQL. Provide an example.
The MERGE statement performs INSERT, UPDATE, or DELETE operations on a target table based on the results of a join with a source table.
13. 3-Topping Pizzas [McKinsey SQL Interview Question]
You’re a consultant for a major pizza chain that will be running a promotion where all 3-topping pizzas will be sold for a fixed price, and are trying to understand the costs involved.
Given a list of pizza toppings, consider all the possible 3-topping pizzas, and print out the total cost of those 3 toppings. Sort the results with the highest total cost on the top followed by pizza toppings in ascending order.
Break ties by listing the ingredients in alphabetical order, starting from the first ingredient, followed by the second and third.
** Table:**
| topping_name | varchar(255) |
| ingredient_cost | decimal(10,2) |
| Pepperoni | 0.50 |
| Sausage | 0.70 |
| Chicken | 0.55 |
| Extra Cheese | 0.40 |
| Chicken,Pepperoni,Sausage | 1.75 |
| Chicken,Extra Cheese,Sausage | 1.65 |
| Extra Cheese,Pepperoni,Sausage | 1.60 |
| Chicken,Extra Cheese,Pepperoni | 1.45 |
You can solve this McKinsey SQL problem interactively AND see alternate solutions, and get the full solution explanation .
14. Describe the differences between clustered and non-clustered indexes in SQL.
A clustered index determines the physical order of data in a table, while a non-clustered index does not. A table can have only one clustered index but multiple non-clustered indexes.
15. Follow-Up Airpod Percentage [Apple SQL Interview Questions]
The Apple retention team needs your help to investigate buying patterns. Write a query to determine the percentage of buyers who bought AirPods directly after they bought iPhones. Round your answer to a percentage (i.e. 20 for 20%, 50 for 50) with no decimals.
| transaction_id | integer |
| customer_id | integer |
| product_name | varchar |
| transaction_timestamp | datetime |
| 1 | 101 | iPhone | 08/08/2022 00:00:00 |
| 2 | 101 | AirPods | 08/08/2022 00:00:00 |
| 5 | 301 | iPhone | 09/05/2022 00:00:00 |
| 6 | 301 | iPad | 09/06/2022 00:00:00 |
| 7 | 301 | AirPods | 09/07/2022 00:00:00 |
| 50 |
You can solve this Apple SQL problem interactively, and get the full solution explanation .
Looking for more Apple SQL Interview Questions? Check out our Apple SQL Interview Guide for access to even more questions and solutions!
16. What is the purpose of the LAG and LEAD functions in SQL? Provide an example.
The LAG and LEAD functions allow accessing data from previous or subsequent rows in a result set.
17. Marketing Touch Streak [Snowflake SQL Interview Question]
As a Data Analyst on Snowflake's Marketing Analytics team, your objective is to analyze customer relationship management (CRM) data and identify contacts that satisfy two conditions:
- Contacts who had a marketing touch for three or more consecutive weeks.
- Contacts who had at least one marketing touch of the type 'trial_request'.
Marketing touches, also known as touch points, represent the interactions or points of contact between a brand and its customers.
Your goal is to generate a list of email addresses for these contacts.
| event_id | integer |
| contact_id | integer |
| event_type | string ('webinar', 'conference_registration', 'trial_request') |
| event_date | date |
| event_id | contact_id | event_type | event_date |
|---|---|---|---|
| 1 | 1 | webinar | 4/17/2022 |
| 2 | 1 | trial_request | 4/23/2022 |
| 3 | 1 | whitepaper_download | 4/30/2022 |
| 4 | 2 | handson_lab | 4/19/2022 |
| 5 | 2 | trial_request | 4/23/2022 |
| 6 | 2 | conference_registration | 4/24/2022 |
| 7 | 3 | whitepaper_download | 4/30/2022 |
| 8 | 4 | trial_request | 4/30/2022 |
| 9 | 4 | webinar | 5/14/2022 |
| contact_id | integer |
| string |
| 1 | |
| 2 | |
| 3 | |
| 4 |
You can solve this Snowflake SQL problem interactively, and get the full solution explanation .
Looking for more Snowflake SQL Interview Questions? Check out these 10 Snowflake SQL Interview Questions for access to even more questions and solutions!
18. Explain the purpose of the TRUNCATE statement in SQL. How is it different from DELETE?
The TRUNCATE statement removes all rows from a table but does not log individual row deletions, making it faster than DELETE, which removes rows one by one and logs each deletion. However, TRUNCATE cannot be rolled back, and it resets identity columns.
19. Bad Delivery Rate [DoorDash SQL Interview Question]
The Growth Team at DoorDash wants to ensure that new users, who make orders within their first 14 days on the platform, have a positive experience. However, they have noticed several issues with deliveries that result in a bad experience.
These issues include:
- Orders being completed incorrectly, with missing items or wrong orders.
- Orders not being received due to incorrect addresses or drop-off spots.
- Orders being delivered late, with the actual delivery time being 30 minutes later than the order placement time. Note that the is automatically set to 30 minutes after the .
Write a query that calculates the bad experience rate for new users who signed up in June 2022 during their first 14 days on the platform. The output should include the percentage of bad experiences, rounded to 2 decimal places. Table:
| Column Name | Type |
|---|---|
| order_id | integer |
| customer_id | integer |
| trip_id | integer |
| status | string ('completed successfully', 'completed incorrectly', 'never received') |
| order_timestamp | timestamp |
| order_id | customer_id | trip_id | status | order_timestamp |
|---|---|---|---|---|
| 727424 | 8472 | 100463 | completed successfully | 06/05/2022 09:12:00 |
| 242513 | 2341 | 100482 | completed incorrectly | 06/05/2022 14:40:00 |
| 141367 | 1314 | 100362 | completed incorrectly | 06/07/2022 15:03:00 |
| 582193 | 5421 | 100657 | never_received | 07/07/2022 15:22:00 |
| 253613 | 1314 | 100213 | completed successfully | 06/12/2022 13:43:00 |
| Column Name | Type |
|---|---|
| dasher_id | integer |
| trip_id | integer |
| estimated_delivery_timestamp | timestamp |
| actual_delivery_timestamp | timestamp |
| dasher_id | trip_id | estimated_delivery_timestamp | actual_delivery_timestamp |
|---|---|---|---|
| 101 | 100463 | 06/05/2022 09:42:00 | 06/05/2022 09:38:00 |
| 102 | 100482 | 06/05/2022 15:10:00 | 06/05/2022 15:46:00 |
| 101 | 100362 | 06/07/2022 15:33:00 | 06/07/2022 16:45:00 |
| 102 | 100657 | 07/07/2022 15:52:00 | - |
| 103 | 100213 | 06/12/2022 14:13:00 | 06/12/2022 14:10:00 |
| Column Name | Type |
|---|---|
| customer_id | integer |
| signup_timestamp | timestamp |
| customer_id | signup_timestamp |
|---|---|
| 8472 | 05/30/2022 00:00:00 |
| 2341 | 06/01/2022 00:00:00 |
| 1314 | 06/03/2022 00:00:00 |
| 1435 | 06/05/2022 00:00:00 |
| 5421 | 06/07/2022 00:00:00 |
| bad_experience_pct |
|---|
| 75.00 |
You can solve this DoorDash SQL problem interactively, and get the full solution explanation .
Looking for more DoorDash SQL Interview Questions? Check out these 8 DoorDash SQL Interview Questions for access to even more questions and solutions!
20. Describe the difference between a view and a materialized view in SQL.
A view is a virtual table based on the result of a SELECT query, while a materialized view is a physical copy of the result set of a query that is stored and updated periodically.
SQL Interview Tips
The best way to prepare for the SQL interview is to practice, practice, practice. Besides solving the earlier SQL interview questions, you should also solve the 200+ SQL coding questions which come from companies like FAANG tech companies and tech startups.
Each exercise has hints to guide you, step-by-step solutions and best of all, there is an interactive coding environment so you can right online code up your SQL query and have it checked. However, if your SQL skills are weak, forget about going right into solving questions – refresh your SQL knowledge with this DataLemur SQL Tutorial .
Data Science Interview Tips
To prepare for the Data Science interviews read the book Ace the Data Science Interview because it's got:
- 201 Interview Questions from Facebook, Google & startups
- A Crash Course covering Product Analytics, SQL & ML
- Amazing Reviews (900+ 5-star reviews on Amazon)
Interview Questions
Career resources.
69 SQL Interview Questions and Answers (Including Interview Tips)
Interviews can seem scary.
Especially programming interviews, where you may have to write some code (such as SQL) during the interview.
But, with a little revision of some SQL interview questions and some tips, they are much easier.
In this guide, you will…
- See over 60 questions and answers about working with SQL
- Learn some tips for your interview from real experiences
- Finally, become more confident with your interview skills
Let’s get into it!
This collection of interview questions on SQL has been collated from my experience with SQL and from various websites.
It contains a list of questions of different types:
- Definitions : These questions ask for a definition of a term or concept.
- Differences : Questions that ask for the difference between two similar concepts.
- Query examples : A sample data set has been provided, and you either need to write a query or explain what a query does.
So, read through the list and try to answer the questions yourself before reading the answer.
Or, read the question then the answer, and try to understand the answer and remember it.
It won’t cover every possible SQL interview question and answer, but it should help.
Also, this list of questions focuses on the SQL standard and on Oracle SQL or Oracle PL/SQL.
There are some differences if you’re looking for MySQL or SQL Server questions, but I’d say that 80% of these questions are applicable to all database management systems.
Let’s look at the questions.
Table of Contents
SQL Interview Tips
Job interviews are more than just learning the questions.
Knowing what might be included and what’s involved will make you feel more prepared and perform better during the interview.
Here are some tips for job interviews for SQL-related roles:
- You’ll generally get asked to explain the different JOIN types, normal forms, the difference between union and joins, how to determine uniqueness, and the difference between the types of keys. The questions in this article should prepare you for it.
- You may get asked a question about a case study and how you’d handle it . Use your experience with writing queries to explain your approach.
- Remember you’re there to solve problems, not just to write queries .
- You might get asked a “wrong question” . For example, “why is this data incorrect?”. You may be tempted to get straight into writing SQL or solving the problem. But you may need to analyse the issue and ask questions first: why do you think the data is incorrect? What is incorrect about it?
- If you don’t know something, admit it . If they ask you to guess, then explain your thought process and logic.
- Always think out loud . It helps the interviewer see how you solve problems.
- There may be more than one way to answer a question or solve a query. If you know there are multiple solutions, let the interviewer know: “Well, there are a few ways you can do that, but here’s one way..”
- There are differences between each vendor’s implementation of SQL, so find out which vendor the company is using. This will help when you answer questions, as the syntax and rules can be different.
- Don’t be afraid of getting the parameters around the wrong way . It’s hard to remember which parameter goes where – I forget all the time. As long as you explain what you’re doing, then the interviewer will understand.
Basic SQL Interview Questions
1. what is the difference between sql, oracle, mysql, and sql server.
SQL is the name of the language used to query databases and follows a standard. Oracle, MySQL and SQL Server are different implementations or versions of a database management system, which implement the SQL standard and build on it in different ways.
Oracle database is targeted at large companies, SQL Server is owned by Microsoft, and MySQL is owned by Oracle but targeted toward smaller companies and systems.
2. What is the difference between SQL and PL/SQL?
SQL is the language used to query databases. You run a query, such as SELECT or INSERT, and get a result.
PL/SQL stands for Procedural Language/Structured Query Language. It’s Oracle’s procedural language and is built on top of SQL. It allows for more programming logic to be used along with SQL.
3. What is the difference between SQL and T-SQL?
T-SQL stands for Transact-SQL and is a language and set of extensions for SQL Server that allows for further programming logic to be used with SQL.
4. What are the different DDL commands in SQL? Give a description of their purpose.
- CREATE : creates objects in the database
- ALTER : makes changes to objects in the database
- DROP : removes objects from the database
- TRUNCATE : deletes all data from a table
- COMMENT: adds comments to the data dictionary
- RENAME: renames an object in the database
5. What are the different DML commands in SQL? Give a description of their purpose.
- SELECT: retrieve or view data from the database
- INSERT : add new records into a table
- UPDATE : change existing records in a table
- DELETE : removes data from a table
- MERGE : performs an UPSERT operation, also known as insert or update.
- CALL: runs a PL/SQL procedure or Java program
- EXPLAIN PLAN: explains the way the data is loaded
- LOCK TABLE: helps control concurrency
6. What is the purpose of the BETWEEN keyword?
The BETWEEN keyword allows you to check that a value falls in between two other values in the WHERE clause.
It’s the same as checking if a value is greater than or equal to one value, and less than or equal to another value.
7. What is the purpose of the IN keyword?
The IN keyword allows you to check if a value matches one of a range of values. It’s often used with subqueries that return more than one row.
8. What is a view? When would you use one?
A view is a database object that allows you to run a saved query to view a set of data. You create a view by specifying a SELECT query to be used as the view, and then the view can be queried just like a table.
There are several reasons to use a view, such as to improve to security, create a layer of abstraction between the underlying tables and applications, and to simplify queries.
9. What’s the difference between a view and a materialized view?
A view is simply an SQL query that is stored on the database, without the results. Every time a view is queried, this definition of the view’s query is run. If the underlying tables have been updated, the view will load these results.
A materialized view is a query where the results have been stored in a permanent state, like a table. If the underlying tables are updated, then by default, the materialized views are not updated.
10. What is a primary key?
A primary key is a column or set of columns that uniquely identifies a row in a table. It’s created on a table and ensures that the values in that column or columns must be unique and not NULL.
This is often done using some kind of numeric ID field but doesn’t have to be.
11. What is a foreign key?
A foreign key is a field in a table that refers to a primary key in another table. It is used to link the record in the first table to the record in the second table.
12. What is a composite key?
A composite key is a primary key that is made up of two or more fields. Often, primary keys are single fields, but in some cases, a row is identified by multiple fields. This is what a composite key is.
13. What is a surrogate key?
A surrogate key is a field in a table that has been created solely for the purpose of being the primary key. It has no other purpose than an internal storage and reference number.
For example, a customer may have an account number that is unique to them, but a customer_id field might be created on the table and used as the primary key, in case business rules change and mean that the account number is no longer unique.
14. What is a unique constraint? How is it different from a primary key?
A unique constraint is a constraint on a table that says that a column or set of columns needs to have unique values.
It’s different to a primary key in that a table can only have one primary key, but a table can have zero, one, or many unique constraints.
Unique constraints can also allow NULL values, but primary keys cannot.
15. What is a synonym?
A synonym is a database object that allows you to create a kind of “link” or “alias” to another database object. This is often done to hide the name of the actual object for security reasons, or to improve maintenance of the code in the future.
16. If a table contains duplicate rows, will a query display duplicate values by default? How can you eliminate duplicate rows from a query result?
Yes, they will be displayed by default. To eliminate duplicate records, you use the DISTINCT keyword after the word SELECT.
17. What is wrong with this query (in Oracle)?
Even if you don’t need a table to get your data, you need to add a table to your SELECT query for it to run.
In this case, you can use the DUAL table that Oracle has created.
If you’re interested in an SQL interview questions PDF for you to study offline, you can download one from this page using the box below.
18. What are the different JOIN types and what do they do?
The different join types in Oracle SQL are:
- Inner join : Returns records that exist in both tables.
- Left join/left outer join : Returns records that exist in the first table and shows NULL for those values that don’t exist in the second table.
- Right join/right outer join : Returns records that exist in the second table and shows NULL for those values that don’t exist in the first table.
- Full join/full outer join : Returns records that exist in both the first and second table, and shows NULL for those values that don’t exist in the corresponding table.
- Cross join : Returns all combinations of all records in both tables.
- Natural join : an inner join with two tables on columns that have the same names.
- Self join : A join from one table to another record in the same table.
For more information and examples, check out this post on SQL Joins interview questions .
19. What is a “cross join”?
A cross join is a type of join where the results displayed contain the records from both tables in all possible combinations. There is no field used to perform the join.
For example, if table A has 10 records and table B has 8 records, then the cross join will result in 80 (or 10 x 8) records.
The result can also be called a “cartesian product”.
Related: SQL Joins: The Complete Guide
20. What is a self join and why would you use one?
A self-join is a type of join where a table is joined to itself.
You would use a self join when a table has a field that refers to another record in the same table. It’s often used in hierarchical structures , such as employee tables having a manager_id column where the manager_id refers to another employee record.
21. Given this ERD, write a query that shows the following information.

The customer ID, customer first and last name, the order ID of any orders the customer has placed (if any) and the date of the order. The data should be ordered by last name then first name, both in ascending order.
This question checks your ability to translate a normal English statement into a SELECT query.
You should have picked up on the need for a LEFT JOIN, the need for table aliases for ambiguous columns, and the ORDER BY.
Table aliases are good to use in any case, so experienced developers will use them for every query.
You might have several different variations of this interview question for SQL interviews. Knowing your query structure and focusing on the requirement for the query are important here.
Note: If you’re looking for a tool to create these kinds of diagrams, check out my guide on 76 Data Modeling Tools Compared .
Aggregation and Grouping
22. what is an aggregate function.
An aggregate function is an SQL function that reads data from multiple rows and displays a single value. Some examples of aggregate functions are COUNT, SUM, MIN, MAX, and AVG. They are often used with a GROUP BY clause but can be used by themselves.
23. Can you nest aggregate functions?
Yes, you can have nested aggregate functions up to two levels deep. For example, you can use MAX(COUNT(*)).
24. Does COUNT return the number of columns in a table?
No, it returns the number of records in a table.
25. What’s the difference between COUNT(column) and COUNT(DISTINCT column)?
COUNT(column) will return the number of non-NULL values in that column. COUNT(DISTINCT column) will return the number of unique non-NULL values in that column.
26. What is the difference between the WHERE and HAVING clauses?
The WHERE clause is run to remove data before grouping. The HAVING clause is run on data after it has been grouped.
This also means the WHERE clause cannot operate on aggregate functions calculated as part of the group.
More information: The Difference Between the WHERE and HAVING Clause
27. What’s wrong with this query?
There is no GROUP BY clause and it will display an error. Because we have used the COUNT function, which is an aggregate function, along with a database field, we need to add a GROUP BY clause. It should GROUP BY the department_id column.
28. What’s wrong with this query?
The WHERE clause cannot include any checks on the aggregate column – even if a GROUP BY has been performed.
This is because the WHERE happens before the grouping, so there is no way for the WHERE clause to know what the value of the COUNT function is.
To resolve this, use the HAVING clause to check for COUNT(*) > 5.
29. What is the default sort order using ORDER BY? How can it be changed?
The default sort order is ascending. This can be changed by specifying the word DESC after any column name in the ORDER BY clause. The word ASC can be used instead to specify ascending order.
30. Can you sort a column using a column alias?
Yes, you can sort by column aliases in an ORDER BY clause.
Analytic or window functions
31. what is a window function or analytic function.
A window function or analytic function is a function that performs a calculation across a set of related rows. It’s similar to an aggregate function, but a window function does not group any rows together. The window function accesses multiple rows “behind the scenes”.
I’ve written a guide here .
32. What is the difference between RANK and DENSE_RANK?
The difference between RANK and DENSE_RANK is where there is a tie or two records with the same value.
RANK will assign non-consecutive values, which means there will be gaps in numbers.
DENSE_RANK will assign consecutive values, which means there will be no gaps.
33. What’s the difference between ROWNUM and ROW_NUMBER?
ROWNUM is a pseudocolumn and has no parameters, where as ROW_NUMBER is an analytical function that takes parameters.
ROWNUM is calculated on all results but before ORDER BY. ROW_NUMBER is calculated as part of the column calculation
ROWNUM is unique. ROW_NUMBER can contain duplicates.
More information: What’s The Difference Between Oracle ROWNUM vs Oracle ROW_NUMBER?
Set Operators
34. what does union do what’s the difference between union and union all.
Union allows you to combine two sets of results into one result.
It’s different to UNION ALL because UNION removes duplicate values and UNION ALL does not.
35. What’s the difference between UNION and JOIN?
A join allows us to lookup data from one table in another table based on common fields (for example employees and departments). It requires us to have a field that is common in both tables.
A union allows us to combine the results of two queries into a single result. No join between the results is needed. Only the number and type of columns need to be the same.
36. What’s the difference between UNION, MINUS, and INTERSECT?
They are all set operators.
But, UNION will combine the results from query1 with query2 and remove duplicate records.
MINUS will display the results of query1 and remove those that match any records from query2.
INTERSECT will display the records that appear in both query1 and query2.
37. What is a subquery?
A subquery is a query within another query. This subquery can be in many places, such as in the FROM clause, the SELECT clause, or a WHERE clause.
It’s often used if you need to use the result of one query as an input into another query.
38. What is a correlated subquery?
A correlated subquery is a subquery that refers to a field in the outer query.
Subqueries can be standalone queries (non-correlated), or they can use fields in the outer query. These fields are often used in join conditions or in WHERE clauses.
39. Given these two queries and result sets, what will the result of this query be? Explain your answer.
| 1 | Michelle | Foster | 48000 | 8 | 162 | 27/Aug/11 |
| 2 | Cheryl | Turner | 79000 | 3 | 99 | 02/Jan/12 |
| 3 | Carolyn | Hudson | 47000 | 7 | 199 | 04/Dec/16 |
| 4 | Patrick | Berry | 51000 | 3 | 159 | 12/Oct/11 |
| 5 | Doris | Powell | 117000 | 1 | 15/Nov/11 | |
| 6 | Jessica | Elliott | 21000 | 7 | 70 | 02/Jul/10 |
| 7 | Sean | Burns | 76500 | 6 | 37 | 03/Oct/10 |
| 8 | Ann | Bowman | 34000 | 7 | 187 | 20/May/10 |
| 9 | Kathleen | Jones | 92000 | 7 | 131 | 15/Mar/15 |
| 84 | Jennifer | Long | 36000 | (null) | 4 | 25/Nov/14 |
| 1 | Executive |
| 2 | Sales |
| 3 | Customer Support |
| 4 | Hardware Development |
| 5 | Software Development |
| 6 | Marketing |
| 7 | Finance |
| 8 | Legal |
| 9 | Maintenance |
What will the result of this query be?
This will return an empty result set. This is because of how the NOT IN command treats NULL values.
If the set of data inside the NOT IN subquery contains any values that have a NULL value, then the outer query returns no rows.
To avoid this issue, add a check for NULL to the inner query:
40. Write a query to display the 5th highest employee salary in the employee table
This could also be done using the ROW_NUMBER function. It’s one of those interview questions in SQL that can have multiple answers, but as long as you provide an answer to it, you should be OK.
Database Design
41. what is cardinality.
Cardinality refers to the uniqueness of values in a column. High cardinality means that there is a large percentage of unique values. Low cardinality means there is a low percentage of unique values.
42. How can you create an empty table from an existing table?
You can use the CREATE TABLE AS SELECT command.
The SELECT statement will contain all of the columns that you want to have in your new table. To ensure it is empty, add a WHERE clause that evaluates to FALSE, such as WHERE 1=0.
43. What is normalisation?
Normalisation is the process of organising your data into tables that adhere to certain rules. It aims to make the process of selecting, inserting, updating, and deleting data more efficient and reduce data issues that may appear otherwise.
There are three popular normal forms, named first/second/third normal form. Third normal form is commonly used as a goal, but there are normal forms after third normal form that are occasionally used.
44. What is denormalisation?
Denormalisation is the process of converting a normalised database into a series of tables that are not normalised. These denormalised tables often contain records that refer to the same value, so updating them is not as efficient. However, the aim of this process is usually to prepare the data for a data warehouse , so the goal is the efficient reading of data.
It often results in a smaller number of tables, each of which has more columns than normalised tables.
45. What do OLTP and OLAP mean and how are they different?
OLTP stands for OnLine Transaction Processing and refers to databases that are designed for regular transactions of inserting, updating, and deleting data. This often includes a normalised database and is linked to an application used during business hours for people to do their job.
OLAP stands for OnLine Analytical Processing and refers to databases that are designed for analysis and reporting. They are focused on SELECT queries and often contain denormalised database designs. They are often used by reporting systems to analyse data from other OLTP systems.
46. What are the case manipulation functions in Oracle SQL?
To change the case of a string in Oracle SQL you can use UPPER, LOWER, or INITCAP. Read more here .
47. Which function or functions returns the remainder of a division operation?
The MOD function and REMAINDER function both return the remainder of a division operator.
This is one of the SQL interview questions which is Oracle specific, as the REMAINDER function does not exist in other database management systems.
48. What does the NVL function do, and how is it different from NVL2?
The NVL function checks if a value is NULL, and returns the value if it is not NULL. If the value is NULL, it returns a different value which you can specify.
NVL2 is slightly different in that you specify both the value to return if the checked value is NULL and if it is not NULL.
NVL takes two parameters and NVL2 takes three.
49. How can you perform conditional logic in an SQL statement?
This can be done using either the DECODE function or the CASE statement .
The CASE statement is more flexible and arguably easier to read than the DECODE function.
50. How can you search for a value in a column when you don’t have the exact match to search for?
If you don’t know the exact match, you can use wildcards along with LIKE. The wildcards are the % symbol for any number of characters, and the _ symbol for a single character.
Inserting and Updating Data
51. what does the merge statement do.
The MERGE statement allows you to check a set of data for a condition, and UPDATE a record if it exists or INSERT a record if it doesn’t exist.
52. Can you insert a NULL value into a column with the INSERT statement?
Yes, you can. You can do this by:
- Leaving the column out of the list of columns in the INSERT statement; or
- Specifying the value of NULL for the column in the VALUES clause
53. Can you INSERT data from one table into another table? If so, how?
Yes, you can do this using an INSERT INTO SELECT query. You start by writing an INSERT INTO statement, along with the columns you want, and then instead of the VALUES clause, you write a SELECT query.
This SELECT query can select data from the same table, or another table, or a combination of tables using JOINs, just like a regular SELECT query.
54. What happens if you don’t have a WHERE clause in an UPDATE statement?
All records in the table will be updated. You need to be sure that’s what you want to do.
55. What happens if you don’t have a WHERE clause in a DELETE statement?
All records will be deleted from the table. It will still run, and there will be no error. You need to be sure that’s what you want to do.
56. What’s the difference between DROP and DELETE?
DROP is used to remove database objects from the database, such as tables or views. DELETE is used to remove data from a table.
Also, DROP is a DDL statement and DELETE is a DML statement, which means DELETE can be rolled back but DROP cannot.
57. What’s the difference between TRUNCATE and DELETE?
There are several differences.
- TRUNCATE deletes all records from a table and you cannot specify a WHERE clause, but DELETE allows you to specify a WHERE clause if you want.
- TRUNCATE does not allow for rollbacks, and DELETE does.
- TRUNCATE is often faster because it does not generate an undo log, but DELETE does.
Other SQL Interview Questions
58. what is a clustered index.
A clustered index is a type of index that reorders how the records are stored on the disk. This allows for fast retrieval of data that uses this index.
A table can only have one clustered index. An alternative is a non-clustered index, which does not order the records on a disk but does offer other benefits of indexes.
59. What is DCL? Provide an explanation of some of the commands.
DCL stands for Data Control Language. The commands that come under DCL are:
- GRANT: give access privileges to a user
- REVOKE: withdraw access privileges from a user
60. What is TCL? Provide an explanation of some of the commands.
TCL stands for Transaction Control Language and it contains statements to manage changes made by DML statements. It includes:
- COMMIT: saves the data to the database
- ROLLBACK: undo the modifications made since the last COMMIT
- SAVEPOINT: create a point in a transaction that you can ROLLBACK to
- SET TRANSACTION: change the transaction options, such as isolation level
- SET ROLE: sets the current active role
61. What is an execution plan? How can you view the execution plan?
An execution plan is a graphic or text visualisation of how the database’s optimiser will run a query. They are useful for helping a developer understand and analyse the performance of their query.
To find the execution plan of a query, add the words “EXPLAIN PLAN FOR” before your query. The query won’t run, but the execution plan for the query will be displayed.
62. Is NULL the same as a zero or blank space? If not, what is the difference?
No, they are different. NULL represents an unknown value. Zero represents the number zero, and a blank space represents a character string with no data.
NULL is compared differently to a zero and a blank space and must use comparisons like IS NULL or IS NOT NULL.
63. What’s the difference between ANY and ALL?
The ANY keyword checks that a value meets at least one of the conditions in the following set of values. The ALL keyword checks that a value meets all of the conditions in the following set of values.
64. What’s the difference between VARCHAR2 and CHAR?
VARCHAR2 does not pad spaces at the end of a character string, but CHAR does . CHAR values are always the maximum length, but VARCHAR2 values are variable length.
65. List the ACID properties and explain what they are.
ACID stands for Atomicity, Consistency, Isolation, and Durability. They are a set of properties that ensure that database transactions are processed reliably.
- Atomicity means that each transaction be atomic, which means “all or nothing”. Either the entire transaction gets saved, or none of it gets saved.
- Consistency means that any transaction will bring the database from one consistent state to another. Data must be valid according to all business rules.
- Isolation means that transactions that are executed at the same time will give the same results as transactions executed one after the other. The effects of one transaction may not be visible to another transaction.
- Durability means that once a transaction has been committed, it remains committed. This is even if there is a disaster, such as power loss or other errors.
This SQL interview question should be relevant to all database management systems. It’s not Oracle-specific.
66. How can you create an auto-increment column in Oracle, in version 11 or earlier? What about in Oracle 12c?
In Oracle 11g, you can create an auto-increment column by using a combination of a sequence and a BEFORE INSERT trigger .
The sequence is used to generate new values, and the BEFORE INSERT trigger will read these new values and put them into the required column whenever you INSERT a new record.
In Oracle 12c , you can define a column as an Identity column by putting the words GENERATED AS IDENTITY after the column in the CREATE TABLE statement. This means new values are generated automatically.
67. What’s the difference between % and _ for pattern matching (e.g. in the LIKE operator)?
The difference is the % sign will match one or more characters, but the _ sign will match only one character.
68. What is a CTE?
CTE stands for Common Table Expression. It’s a SELECT query that returns a temporary result set that you can use within another SQL query.
They are often used to break up complex queries to make them simpler. They use the WITH clause in SQL. An example of a CTE would be:
This is a simple example, but more complicated queries will benefit from CTEs, both in performance and readability.
69. What is a temp table, and when would you use one?
A temp table (or temporary table) is a database table that exists temporarily on the system. It allows you to store the results of a query for use later in a session. They are useful if you have a large number of results and you want to use them again.
A temporary table, by default, is only accessible to you. Global temporary tables can be accessed by others.
Temporary tables are automatically deleted when the connection that created them is closed.
Interviews for SQL-heavy positions (ETL developer, BI developer, data analyst, for example) can seem daunting because of the wide range of technical questions that can be asked.
But they don’t have to be. Knowing your basics and a good level of SQL needed for the position you’re applying for is all the interviewer will want to know.
Study these questions and understand the topics, and along with any experience you have, you’ll be well prepared for an SQL interview.
13 thoughts on “69 SQL Interview Questions and Answers (Including Interview Tips)”

the question are good enough from fresher point of view. can u pls u add some more question related sql server(oracle).

Glad you like them! Sure I can add some more. What topics did you want me to cover?

Performance, Always On Availability, third part tools, replication , mirroring

Simple and excellent

Could you please tell me which certificates need for SQL Developer or Database Administrator in 2021? In fact, MCSA or MCSE had been retired on 31/01/2021. Thanks in advance.
Kind regards Thomas

#29 is actually not very correct — there is no default sort for group by officially. In most cases, it will be sorted in ascended order, but there is no guarantee. Actually, there was one case in my early practice, the app was doing some sort of grouping keeping in mind default sorting and all was fine for a year or more, but as I said — there is no guarantee and at some point, after a patch, restart or upgrade, this may just stop working like it was with that app. So it’s better to use order by ascending. Here is a thread in AskTomwith some links and docs quotations.
https://asktom.oracle.com/pls/apex/f?p=100:11:0 ::::P11_QUESTION_ID:6257473400346237629
BR, Mikhail

I think the author was saying if an ORDER BY clause is specified, what will the default sort order be (Asc or Desc)? The answer, like he said is Ascending.
But you’re right about something else. SQL does not guarantee results will be in a particular order if there is no ORDER BY clause specified.

Very awesome content! thank you so much!

Hi Ben, This is helpful, I was able to revise all in one document. I always follow your post. Thanks, Suman
Thanks Suman!

Excellent Ben, This is very good for fresher or someone with a couple years of experience. Do you have a post for advanced SQL interview questions for someone with 6 plus years of experience?
None the less, content you provide is top class.
Regards Bhargava

I had on interview What is deadlock

I want to learn more and more Database SQL
Leave a Comment Cancel Reply
Your email address will not be published. Required fields are marked *
This site uses Akismet to reduce spam. Learn how your comment data is processed .
By SQL Operations
Single Table
- SELECT, WHERE, ORDER, LIMIT
- COUNT, SUM, MAX, GROUP BY
- IN, BETWEEN, LIKE, CASE WHEN
Multi Table
Window Functions
- AVG, SUM, MAX/MIN
- ROW_NUMBER, RANK
By SQL Complexity
- Basic SQL Questions
- Common SQL Questions
- Complex SQL Questions
Company & Industry
- AI Mock Interview 🔥
- AI Resume Optimizer
- AI Resume Builder
- AI Career Copywriting
- AI Data Analytics
Master SQL Interview Questions: Practice Guide for Aspiring Data Experts
Introduction
Structured Query Language (SQL) is the backbone of data manipulation and storage in the modern tech world. This article is your ultimate practice guide to honing your SQL skills and acing those daunting interview questions. Whether you're a beginner or looking to polish your expertise, we delve into essential SQL concepts and provide targeted exercises to prepare you for your next interview.
- Key Highlights
- Importance of SQL in data management and interviews
- Tips for effective SQL practice and learning
- Exploring key SQL concepts through exercises
- Tackling complex SQL problems for interview preparation
- Best practices to impress interviewers with your SQL knowledge
- Understanding the SQL Landscape for Aspiring Data Experts

Before venturing into the realm of SQL interview questions, it's imperative to grasp the significance of Structured Query Language (SQL) as an invaluable asset for tech professionals. SQL stands as the cornerstone for data manipulation and retrieval across myriad industries. This initial exploration lays the groundwork for mastering SQL, a skill that is not just desired but required in today's data-centric job market.
The Indispensable Role of SQL in Data Management
SQL is the lifeblood of data management, powering the ability to store, retrieve, and manipulate data within relational databases. It's the standardized language for interacting with database management systems. For instance, consider a database containing customer information for an e-commerce platform. To extract a list of customers who made purchases over $500, one would use the SQL command:
This simple yet powerful example underscores SQL's role in extracting meaningful insights from data, a process crucial for business decisions.
SQL Expertise: A Currency in the Job Market
The demand for SQL knowledge spans various roles, from data analysts to software engineers. Employers seek candidates who can navigate databases with ease and precision. For example, a report by Burning Glass Technologies states that SQL is mentioned in nearly 50% of tech job postings. A data scientist might leverage SQL to perform a complex analysis, such as:
This command calculates the average sales per region, illustrating how SQL serves as a critical tool for data-driven roles.
Deciphering Interviewers' Quest for SQL Proficiency
During technical interviews, interviewers assess SQL proficiency through a variety of lenses. They evaluate not only the knowledge of syntax but also the understanding of database design, problem-solving abilities, and optimization techniques. Candidates might be presented with scenarios requiring them to design efficient schema or optimize slow-running queries. For instance, an interviewer might ask for the optimization of the following query:
The candidate’s approach to indexing the 'Price' column to speed up this query can showcase their depth of SQL knowledge and their potential as a data expert.
- Grasp SQL Fundamentals for Data Expertise

Embarking on a journey into the realm of data management begins with mastering the essentials of SQL. In this pivotal section of our guide, Master SQL Interview Questions: Practice Guide for Aspiring Data Experts , we delve into the core syntax and foundational commands that underpin SQL's powerful capabilities. Let's fortify your understanding with practical examples, ensuring you are well-equipped for the interviews and challenges ahead.
Mastering Basic SQL Commands
SQL's versatility in data manipulation is harnessed through its basic commands: SELECT , INSERT , UPDATE , and DELETE . These are the gateways to interacting with database content.
- SELECT retrieves data from a database, allowing you to specify columns and conditions: sql SELECT name, age FROM users WHERE age > 25;
- INSERT adds new data rows to a table: sql INSERT INTO users (name, age) VALUES ('Alice', 30);
- UPDATE modifies existing data: sql UPDATE users SET age = 31 WHERE name = 'Alice';
- DELETE removes data from a table: sql DELETE FROM users WHERE name = 'Alice'; Grasping these commands is crucial to perform basic database operations effectively.
Efficient Table Management with SQL
Creating and managing tables are fundamental tasks in SQL, as tables are the primary storage of data in databases. Let's explore how to CREATE a table, define its structure with various data types , and use keys for data integrity and relationships.
- To CREATE a table with columns and types: sql CREATE TABLE users (id INT PRIMARY KEY, name VARCHAR(50), age INT);
- Data types like VARCHAR, INT, and DATE define the nature of data: sql ALTER TABLE users ADD birthday DATE;
- PRIMARY KEY and FOREIGN KEY enforce uniqueness and relationships: sql ALTER TABLE orders ADD CONSTRAINT fk_user_id FOREIGN KEY (user_id) REFERENCES users(id); Understanding these concepts is essential for structuring robust and efficient databases.
Strategizing Effective Data Querying
Querying data effectively is a core skill for any SQL user. By leveraging the WHERE clause, ORDER BY , and various filtering options, you can refine your data retrieval to be both precise and efficient.
- Use the WHERE clause to filter results: sql SELECT * FROM sales WHERE amount > 500 AND region = 'East';
- Sort your results with ORDER BY : sql SELECT name, age FROM users ORDER BY age DESC, name ASC;
- Employ LIMIT to restrict the number of results: sql SELECT name FROM users LIMIT 10; Mastering these strategies will significantly enhance your ability to extract meaningful insights from any dataset.
- Intermediate SQL: Joins, Subqueries and Indexing

Progressing from the essential SQL syntax, we delve into the intermediate realm, tackling more intricate SQL constructs pivotal in tech interviews. This section provides practice exercises to hone your skills in joins , subqueries , and indexing —key areas for efficient data manipulation and retrieval.
Mastering SQL Joins
The ability to combine rows from two or more tables based on a related column is essential in SQL. Here, we explore:
- INNER JOIN: Fetches records with matching values in both tables. Example: SELECT * FROM Orders INNER JOIN Customers ON Orders.CustomerID = Customers.CustomerID;
- LEFT JOIN (or LEFT OUTER JOIN): Selects all records from the left table and matched records from the right table, returning NULL for unmatched right table records. Example: SELECT * FROM Orders LEFT JOIN Customers ON Orders.CustomerID = Customers.CustomerID;
- RIGHT JOIN (or RIGHT OUTER JOIN): Opposite of LEFT JOIN, it retrieves all records from the right table and matched records from the left table. Example: SELECT * FROM Orders RIGHT JOIN Customers ON Orders.CustomerID = Customers.CustomerID;
- FULL OUTER JOIN: Combines LEFT JOIN and RIGHT JOIN, getting all records when there is a match in either left or right table. Example: SELECT * FROM Orders FULL OUTER JOIN Customers ON Orders.CustomerID = Customers.CustomerID;
Practice these joins with various datasets to understand their nuances in data retrieval.
Harnessing the Power of Subqueries
Subqueries, or nested queries, are a powerful feature in SQL used to perform operations that require multiple query steps. For instance:
- Using a subquery to filter results: A common use is in the WHERE clause to filter records based on a condition evaluated in the subquery. Example: SELECT * FROM Employees WHERE DepartmentID IN (SELECT DepartmentID FROM Departments WHERE Location = 'New York');
- Correlated subqueries: These reference a column in the outer query, which is executed for every row of the outer query. Example: SELECT e.Name, e.Salary FROM Employees e WHERE e.Salary > (SELECT AVG(Salary) FROM Employees WHERE Department = e.Department);
Practice creating subqueries for different scenarios to improve problem-solving skills for complex data retrieval issues.
Indexing for Optimized SQL Performance
Indexes are pivotal for expediting search strategies within databases. They're akin to a book's index, directing the SQL engine to the data's location swiftly. Here's how they work:
- Creating an Index: This can drastically improve query performance, especially for large datasets. Example: CREATE INDEX idx_customer_name ON Customers (LastName, FirstName);
- Using Indexes: Properly designed indexes are used by the database management system to locate data without scanning the full table.
- Index Types: Understanding clustered and non-clustered indexes is crucial as they affect performance in different ways.
Incorporate indexing in practice exercises to witness the impact on query performance firsthand. Learn more about indexing .
- Conquer Advanced SQL Challenges: A Deep Dive for Prospective Data Experts

As you venture deeper into the realm of SQL, mastering advanced techniques is pivotal for those aiming to excel in data-related fields. This section delves into sophisticated topics and provides challenging exercises designed to mirror the complexities of real-world data analysis scenarios. Enhance your SQL prowess with these intricate practices, and prepare to impress during your technical interviews.
Complex Query Crafting Mastery
The ability to write complex SQL queries is essential for solving intricate data problems. Here are some exercises to hone your skills:
- Multi-table Aggregation: Craft a query that aggregates data across multiple tables using JOIN clauses and aggregate functions like SUM and COUNT .
- Analytical Window Functions: Utilize window functions such as ROW_NUMBER() or RANK() to perform advanced analytics.
These exercises will challenge you to integrate multiple SQL operations and functions, reflecting the Master SQL Interview Questions: Practice Guide for Aspiring Data Experts.
Principles of Pragmatic Database Design and Normalization
Understanding the principles of database design and normalization is crucial for data integrity and efficiency. Here are practical examples:
Normalization Exercise: Given a denormalized table, normalize it into 1NF, 2NF, and 3NF while ensuring data integrity.
ER Diagrams: Create an Entity-Relationship (ER) diagram to visualize the database structure, which aids in understanding relationships and designing normalized tables.
By mastering these principles, you align with the Master SQL Interview Questions: Practice Guide for Aspiring Data Experts, ensuring your database designs are robust and scalable.
SQL for Enhanced Data Analytics
SQL is invaluable for data analytics. Here's how you can leverage it:
- Grouping Data for Insights: Use GROUP BY in conjunction with aggregate functions like AVG to uncover trends.
- Conditional Aggregates: Apply the HAVING clause to filter aggregated data based on specific conditions.
These exercises will prepare you for analytical tasks in SQL interviews, as highlighted in the Master SQL Interview Questions: Practice Guide for Aspiring Data Experts.
- Ace Your SQL Interview with Confidence: A Comprehensive Preparation Guide

Embarking on a data-driven career path? Your SQL interview is a pivotal milestone. In this crucial section, we'll arm you with a toolkit of strategies and insights to confidently navigate SQL interview questions. Whether it's understanding the types of questions you'll face or mastering the articulation of your problem-solving prowess, we're here to guide you through the final stretch of your preparation journey.
Frequently Asked SQL Interview Questions: Your Ultimate Checklist
Dive into the heart of SQL interviews with a compilation of essential SQL interview questions . From classic queries to tasks that test your analytical acumen, mastering these questions will showcase your readiness. For instance:
- Explain the difference between INNER JOIN and LEFT JOIN .
- Write a query to find the second highest salary from a Employees table.
Understanding and practicing these queries will not only prepare you for common challenges but also sharpen your SQL skills for real-world applications.
Mock SQL Interview Scenarios: Simulate to Elevate Your Skills
Practice makes perfect, and with SQL, it's no different. Engage in simulated interview scenarios to refine your approach to problem-solving. Imagine you're tasked with optimizing a database's performance. How would you identify inefficient queries? What indexing strategies would you employ? Role-playing these situations will help you articulate your thought process clearly and demonstrate your problem-solving skills effectively. Remember, it's not just about the right answer, but also about the how and why behind your SQL solutions.
SQL Interview Success: Tips and Techniques to Impress
Beyond technical know-how, succeeding in an SQL interview demands a blend of clear communication and strategic presentation. Consider these actionable tips:
- Structure Your Responses : Begin with an overview, delve into specifics, and conclude with a summary.
- Optimize Your Query Examples : Ensure your code is readable, well-commented, and efficient.
- Project Confidence : Even if you're unsure of an answer, a calm and considered approach speaks volumes.
Incorporating these strategies will not only demonstrate your SQL acumen but also your professionalism and readiness for a tech-driven role.
SQL proficiency is an essential skill for data professionals and a critical component of the interview process. Through consistent practice, mastering fundamental to advanced SQL concepts, and employing smart preparation strategies, you can confidently showcase your expertise to potential employers. Remember, every SQL problem you solve not only brings you closer to acing your interview but also equips you with the practical skills needed for a successful career in the data realm.
Q: What is SQL and why is it important for data-related roles?
A: SQL, or Structured Query Language, is a standard language for accessing and manipulating databases. It is crucial for data-related roles as it allows professionals to efficiently query, update, insert, and modify data within databases.
Q: Can you explain what a JOIN is in SQL?
A: A JOIN is an SQL operation used to combine rows from two or more tables based on a related column between them. It's a fundamental concept for creating queries that involve multiple tables.
Q: How can you improve the performance of an SQL query?
A: Improving SQL query performance can involve indexing relevant columns, optimizing joins and WHERE clause conditions, avoiding subqueries and correlated subqueries when possible, and using query execution plans for analysis.
Q: What are some common SQL aggregate functions?
A: Common SQL aggregate functions include COUNT() , SUM() , AVG() (average), MAX() , and MIN() . These functions perform calculations on a set of values and return a single value.
Q: What does 'normalization' mean in the context of a database?
A: Normalization is the process of organizing data in a database to reduce redundancy and improve data integrity. It involves dividing a database into two or more tables and defining relationships between the tables.
Q: What is the difference between a primary key and a foreign key?
A: A primary key is a unique identifier for a record in a table, whereas a foreign key is a column or group of columns in a table that provides a link to the primary key in another table, establishing a relationship between the two tables.
Q: What is a subquery, and when would you use one?
A: A subquery is a query nested inside another query. It is used to perform operations that must be resolved before the main query can be completed, such as filtering results based on a complex condition.
Q: How do you handle NULL values in SQL?
A: Handling NULL values can involve using functions like IS NULL , IS NOT NULL , COALESCE() , and NULLIF() to test for NULLs or replace them, ensuring that the desired logic is applied to the data.
Table of Contents
Don't Let Your Dream Job Slip Away!
Discover the Blueprint to Master Data Job Interviews with Cutting-Edge Strategies!
Begin Your SQL, R & Python Odyssey
Elevate Your Data Skills and Potential Earnings
Master 230 SQL, R & Python Coding Challenges: Elevate Your Data Skills to Professional Levels with Targeted Practice and Our Premium Course Offerings
Related Articles
Meta Data Engineer Interview Guide
How to prepare a Data Engineer job interview at Meta, overview of the interview process, sample questions, timeline and case studies.

Master SQL Self Joins: An In-depth Guide
Explore the comprehensive guide on SQL Self Joins, mastering techniques for data analysis and manipulation with practical examples and best practices.

Ultimate Guide to SQL Interview Questions for Data Scientists in 2024
Ace your 2024 data scientist job interview with our comprehensive guide to SQL interview questions, tailored for aspiring data scientists.

Master SQL for Data Science: A Comprehensive Bootcamp Guide
Unlock the potential of SQL in data science with our comprehensive bootcamp guide. Essential training to fast-track your data science career.
Ace Your Next Data Interview
Land a dream position at Amazon! Hi Leon, I hope you're doing well. I wanted to reach out and say thanks for your interview prep—it really helped me land a position at Amazon. It's been a fulfilling experience!
David, Data Engineer at Amazon
Complete SQL Practice for Interviews

- SQL job market
- jobs and career
- sql interview questions
Table of Contents
Basic SQL Whiteboard Questions for Job Interviews
Sql exercise 1 – write a statement, sql exercise 2 – write a statement, sql exercise 3 – find the error, sql exercise 4 – find the result, sql exercise 5 – write a query, sql exercise 6 – write a date query, sql exercise 7 – write a query, sql exercise 8 – find and delete duplicates, sql exercise 9 – write a complex query, sql exercise 10 – write a complex query, advanced sql whiteboard questions.
Congratulations! Your SQL skills were strong enough to get you that job interview! Now, if you only knew what SQL questions and practical exercises a recruiter might ask you to do…
This article is meant as a SQL practice for interviews. I’ll help you prepare for the SQL and database aspects of your job interview.
In a previous article, I explained how can you boost your career by learning SQL . It opens up opportunities in and out of IT, as this query language is used practically everywhere . Let’s say you finally made your decision to use your SQL skills in a new job. Before you can start, though, you need to get through the job interview.
Your interviewer may use several kinds of SQL whiteboard questions: sometimes you’ll be asked to describe the differences between two elements; sometimes you’ll have to tell them the result of a specific query; you may even have to write some simple code.
This sounds stressful, but don’t worry too much. The best way to prepare for an interview is tons of practice. I recommend the SQL Practice track at LearnSQL.com. It contains over 600 interactive SQL exercises to help you review and practice SQL before an interview.
In this article, I’ll help you prepare for the by going over some common questions and SQL exercises that recruiters use during the interview process.
First, let’s focus on the more theoretical side of SQL. To assess your understanding here, the recruiter will likely ask you to verbally explain some simpler questions. These are usually mainly about the elementary parts of SQL. For example, you might be asked to answer some of the following SQL whiteboard questions:
- Enumerate and explain all the basic elements of an SQL query.
- What is the WHERE clause?
- What do the LIKE and NOT LIKE operators do?
- Explain the usage of AND , OR , and NOT clauses.
- What is a NULL value?
- What does a JOIN do? What are the different types of JOIN clauses?
- Explain the GROUP BY clause.
- What is the difference between the WHERE and HAVING clauses?
- What does ORDER BY do?
- What does UNION do? What is the difference between UNION and UNION ALL ?
- What do the INTERSECT and MINUS clauses do?
- What is the role of the DISTINCT keyword?
- Explain the use of aliases in queries.
Can you answer every question from my SQL practice for interviews? Even basic questions need good preparation and a lot of practice. Nobody is perfect, and sometimes you need to refresh your knowledge. our online courses can help you brush up on any semi-forgotten skills.
Practical SQL Exercises for Interview
Technical job interviews often have a practical side. This is where you need to prove your SQL skills as you would use them in real life – apart from answering typical SQL whiteboard questions, you’ll be asked to write a SQL statement, check a query for mistakes, or determine the result of a given query.
Below, I’ve copied ten SQL exercises of the types you might do on a technical job interview. They are sorted from easy to hard.
Write an SQL statement that lists school names, student names, and their cities only if the school and the student are in the same city and the student is not from New York.
Write an SQL statement that lists student names, subject names, subject lecturers, and the max amount of points for all subjects except Computer Science and any subjects with a max score between 100 and 200.
What is wrong with this SQL query?
Given the following tables …
… What will be the result of the query below?
The EMPLOYEE table has the following attributes: NAME , DEPT_ID , and SALARY . Write a query that shows the highest salary in each department.
Write an SQL query that displays the current date.
Write an SQL query that checks whether a date (1/04/12) passed to the query is in a given format (MM/YY/DD).
Write an SQL query to find duplicate rows in two tables ( EMPLOYEE and WORKERS ), and then write a query to delete the duplicates.
Write a query that lists courses’ subject names and the number of students taking the course only if the course has three or more students enrolled.
Write a query that displays the average age of workers in each company. The result should show the name of the company and the age of the company’s youngest worker.
OK, so we’ve already had some SQL practice for interviews but our exercises covered SQL basics. But what about a more advanced job, like SQL developer or database administrator? Recruiters will be interested in more than just your SQL knowledge; they will also need to know how savvy you are with databases in general. In that case, see how well you can verbally answer SQL whiteboard questions like these:
- What are primary and foreign keys?
- What is normalization? What is denormalization?
- What is an index? Can you briefly explain the different index types?
- Can you explain database relationships and relationship types?
- What is a database cursor?
- What is a constraint?
- What is a database transaction? A database lock?
- How do you use the NULLIF function?
- What is the purpose of the NVL function?
- What is the difference between the RANK() and the DENSE_RANK() functions?
- What is the difference between VARCHAR2 and CHAR datatypes?
Again, even if you know the answers to these questions, it pays to practice them. You may even want to practice answering them out loud!
So you see, SQL whiteboard questions and exercises are not as scary as you think. Of course, it’s also not a piece of cake, either. We’ve gone over some common skill-evaluation methods, but a lot depends on your interviewer’s imagination and experience. The most important thing is showing the recruiter that you understand how SQL works and that you can, if needed, find help on the Internet.
If you don’t have an interview on the horizon, now is the time to hone your SQL skills. Either way, I hope that this article has given you a substantial portion of SQL practice for interviews and helped you learn what to expect and how to prepare for an SQL-related job interview when you get one!
You may also like

How Do You Write a SELECT Statement in SQL?

What Is a Foreign Key in SQL?

Enumerate and Explain All the Basic Elements of an SQL Query
- For Individuals
- For Businesses
- For Universities
- For Governments
- Online Degrees
- Find your New Career
- Join for Free
SQL Interview Questions: A Data Analyst's Guide for Success
Prepare for the SQL portion of your interview with example questions and a framework for answering them.
![[Featured image] A person in a gray button-down sits at a computer workstation running SQL queries on a laptop](https://d3njjcbhbojbot.cloudfront.net/api/utilities/v1/imageproxy/https://images.ctfassets.net/wp1lcwdav1p1/5DfLE2XzVenV2FknMLkanb/1da6966bd2719a5b288cd333326ceb1b/SQL_Interview.png?w=1500&h=680&q=60&fit=fill&f=faces&fm=jpg&fl=progressive&auto=format%2Ccompress&dpr=1&w=1000 "sql interview questions case study")
Being able to use SQL, or Structured Query Language, ranks among the most important skills for data analysts to have. As you prepare to interview for data analyst jobs, you can expect that SQL will come up during the job interview process.
With this guide, you’ll learn more about SQL technical screenings, what type of screening you might encounter, and some common types of questions that come up during these interviews. You’ll also find some example questions, a step-by-step guide for writing SQL code during your interview, and tips for success. Let’s get started.
What to expect from SQL technical screenings
Data analysts use SQL to communicate with relational databases to access, clean, and analyze data. At the time of writing, more than 230,000 jobs on LinkedIn included SQL in the listing.
Since it’s such a critical skill, it’s common for data analyst interviews to include a SQL technical screening. This portion of the interview tasks you with solving real-world problems using SQL. While you may be asked some definitional questions more typical of a standard interview, the real point here is for the interviewer to verify that you can actually use SQL, not just talk about it.
These screenings typically take one of three forms:
1. Whiteboard test: The most common type of SQL screening is the whiteboard interview. In this type of screening, you’re given a whiteboard and a marker to write out your queries by hand. Since you won’t have a computer alerting you to any syntax or logical errors in your code, this is more about demonstrating that you can think through a problem and know the right SQL concepts to solve it.
2. Live coding: With this type of screening, you’ll be given SQL problems to solve in a live coding environment. This allows you to run your queries and check your work as you go, but since you’re running your code, syntax will matter. Since different databases use different tools, this type of screening isn’t as common as the whiteboard screening.
3. Take-home assignment: With this less-common screening technique, you’ll be given a problem or series of problems to take home and solve within a given period of time. This lets you write your queries in the comfort of your home, without the pressure of an interviewer looking over your shoulder. On the other hand, the coding challenges are often more complex.
Related: 5 SQL Certifications for Your Data Career
Types of SQL interview questions for data analysts
Just as there are three formats technical screenings might take, there are also three broad categories of questions you’ll typically be asked during this portion of the interview. We’ve arranged them here from the most simple to the most complex. Generally speaking, the easier, definitional questions will be fewer and less important than the live coding questions—something to keep in mind as you prepare.
1. Define a SQL term
If you’re interviewing for a data analyst role, chances are you know what SQL is (and your interviewer assumes you know this). It’s possible you’d be asked what SQL is, but it’s more likely you’ll be asked to explain more technical concepts in SQL, the difference between two (or more) related concepts, or how a concept is used. This is not an exhaustive list, but here are some examples of terms you should be ready to explain:
Trigger: a procedure stored within a database, which automatically happens whenever a specific event occurs.
Index: a special lookup table within a database used to increase data retrieval speed.
Cursor: a pointer, or identifier, associated with a single or group of rows.
Constraints: rules used to limit the type of data allowed within a table. Common constraints include primary key, foreign key, unique key, and NOT NULL.
ETL (Extract, transform, and load): a data integration process used to combine multiple data sources into one data store, such as a data warehouse .
Primary key, foreign key, and unique key: constraints used to identify records within a table.
Normalization vs. denormalization: techniques used to either divide data into multiple tables to achieve integrity ("normalization") or combine data into a table to increase the speed of data retrieval ("denormalization").
RDBMS vs. DBMS: two types of database management systems. Within a relational database management system (RDBMS) data is stored as a table, while in a database management system (DBMS) its stored as a file.
Clustered vs. non-clustered index: two types of indices used to sort and store data. A clustered index sorts data based on their key values, while a non-clustered index stores data and their records in separate locations.
Forms definitional questions may take:
What is the purpose of an index in a table? Explain the different types.
What are the types of joins in SQL?
What is the difference between DROP, TRUNCATE, and DELETE statements?
How do you use a cursor?
What is the difference between a HAVING clause and a WHERE clause?
Read more: SQL vs. MySQL: Differences, Similarities, Uses, and Benefits
2. Questions about a query
This second category gives you an SQL query and asks you a question about it. This tests your ability to read, interpret, analyze, and debug code written by others.
Forms query analysis questions may take:
Given a query,
Put the clauses in order by how SQL would run them.
Identify the error and correct it.
Predict what the query will return.
Explain what problem the query is meant to solve.
3. Write a query
The questions most commonly associated with the SQL technical screening ask you to solve a given problem by writing out a query in SQL. You’ll typically be given one or more tables and asked to write one or more queries to retrieve, edit, or remove data from those tables.
The difficulty of questions will likely vary based on the company and the role (entry-level vs. advanced). In general, you should be comfortable writing queries using the following concepts, statements, and clauses:
Categorization, aggregation, and ratio (CASE, COUNT, or SUM, numerator and denominator)
Joining two tables (JOIN inner vs. left or right)
Modifying a database (INSERT, UPDATE, and DELETE)
Comparison operators (Less than, greater than, equal to)
Organizing data (ORDER BY, GROUP BY, HAVING)
Subqueries
Forms query-writing questions may take:
Given a table or tables with a few sample rows,
List the three stores with the highest number of customer transactions.
Extract employee IDs for all employees who earned a three or higher on their last performance review.
Calculate the average monthly sales by product displayed in descending order.
Find and remove duplicates in the table without creating another table.
Identify the common records between two tables.
SQL interview tips for success
In addition to the process above, here are some tips to keep in mind when you’re in your SQL interview.
Talk through your process out loud. Your interviewer may or may not know SQL themselves, so be sure to explain the what, how, and why of each step.
Include written comments as to what each step of your query is meant to accomplish. This can help you keep track of where you are in the problem, and it can make your code easier to understand. If you’re coding in a live environment, you can type comments using a double hash (--). On a whiteboard, write your comments off to the side.
Use correct formatting. While your ability to problem solve is more important than precise syntax, you can avoid confusing the interviewer (and yourself) by keeping your hand-written code organized.
Embrace the awkwardness. It’s okay if the room is silent while you think through a problem. As you’re thinking out loud, you may find yourself re-starting sentences with a better way to explain something. That’s okay too.
Read more: How to Prepare for an Interview
Six-step strategy for your SQL interview
Sometimes the best way to keep nerves calm before an interview is to walk into the screening with a clear plan of action. No matter what type of query you’re asked to write, you can use this six-step process to organize your thoughts and guide you to a solution, even when you’re feeling nervous.
1. Restate the question to make sure you understand what you’re being asked to do.
2. Explore the data by asking questions. What data type is in each column? Do any columns contain unique data (such as user ID)?
3. Identify the columns you’ll need to solve the problem. This helps you focus on the data that matters so you’re not distracted by the data that is irrelevant to the query.
4. Think about what your answer should look like. Are you looking for a single value or a list? Will the answer be the result of a calculation? If so, should it be a float or an integer? Do you need to account for this in your code?
5. Write your code one step at a time. It can help to outline your approach first. By writing down the steps you plan to take, you’ll have a clear outline once you start writing your query (and you’ll give the interviewer a chance to correct you if there’s an issue with your approach).
Then code in increments, taking one step of your outline at a time. After you’re happy with your code for the first step, build onto that code with the second step.
6. Explain your solution as a whole. If there’s a more efficient way you could have written your code—using subqueries for example—explain that. And remember to answer the original question.
Explore practice resources
If you’re looking for more SQL interview prep, here are some free resources where you can practice writing queries.
HackerRank : This site lets you practice in many different coding languages, including SQL. Each challenge comes with a difficulty score and a success rate, so you can gradually move to more complex queries.
Codewars : When you practice on CodeWars, you can compare your solutions with other users to improve the efficiency of your queries.
LeetCode : Use the database problem sets to practice queries ranging from easy to hard, and track how many you’ve successfully solved.
TestDome : Practice on the same interview questions used by thousands of real companies.
Get ready for your SQL interview
Searching for a new job is an exciting, yet sometimes nerve-wracking, experience. If you're preparing for your next job search or interview, consider brushing up on your skills by taking a course or gaining a professional certificate through Coursera.
In the University of Maryland's Advanced Interview Techniques course, you'll learn detailed strategies for handling tough competency-based, or behavioral, interviews so that you can communicate the knowledge, skills, and abilities that you have and that employers demand.
In Google's Data Analytics Professional Certificate , meanwhile, you'll learn how to process and analyze data, use key analysis tools, apply R programming, and create visualizations that can inform key business decisions. Once completed, you'll receive a professional certificate that you can put on your resume to show off to employers.
Frequently asked questions (FAQ)
How do data analysts use sql .
Data analysts use SQL to communicate with relational databases. As a data analyst, you can use SQL to access, read, change, delete, or analyze data to help generate business insights.
Is SQL hard to learn?
SQL is generally considered to be one of the easier coding languages to learn. The structure and syntax of SQL is based on the English language, so it’s relatively easy to read and understand. You can also do a lot by learning a few basic commands, like SELECT, UPDATE, INSERT, and DELETE. Read up on tips for rising to the challenge .
Should I learn SQL or Python first?
SQL is typically considered simpler and narrower in scope than Python. If you’re new to writing code, SQL makes an excellent, beginner-friendly first language. Having said that, it’s also totally fine to learn Python first, or learn the two languages simultaneously.
Read more: Python or R for Data Analysis: Which Should I Learn?
What are the five basic SQL commands?
As you learn SQL, you’ll use five different types of commands:
- DDL (Data definition language) commands change the structure of a table by creating, modifying, or deleting data.
- DML (Data manipulation language) commands are used to modify relational databases where changes are not permanently saved and can be rolled back.
- DCL (Data control language) commands are used to grant and revoke access to database users.
- TCL (Transaction control language) commands are used alongside DML commands to save, undo, or roll back to a given save point.
- The DQL (Data query language) command—SELECT is the only one—fetches data from a database.
Keep reading
Coursera staff.
Editorial Team
Coursera’s editorial team is comprised of highly experienced professional editors, writers, and fact...
This content has been made available for informational purposes only. Learners are advised to conduct additional research to ensure that courses and other credentials pursued meet their personal, professional, and financial goals.
Member-only story
SQL Challenge: Case Study
Step-by-step walkthrough of a sql challenge asked by top tech company.
Chloe Lubin
Towards Data Science
In a previous post , I talked about how to use a framework to solve a SQL challenge. Today, I’m going to do a walkthrough of this challenge , asked by Microsoft in February 2021. Before you continue reading this article, I highly encourage you to try solving this question on your own. The more you practice solving SQL questions, the better you’ll get at them. Alright, let’s get into it!
Reading the Prompt
The question asks us to:
select the most popular client_id based on a count of the number of users who have at least 50% of their events from the following list: ‘video call received’, ‘video call sent’, ‘voice call received’, ‘voice call sent’.
Before I start working on this question, I like to visualize how the information appears in the dataset. Let’s run a simple SELECT statement to check the data stored in the table fact_events.
The query returns the following output:

Written by Chloe Lubin
Text to speech
Member-only story
Case Studies in SQL: Real-World Data Analysis with SQL Queries
SQL Programming
SQL (Structured Query Language) is a powerful tool for working with data, and it’s widely used in various industries for data analysis and decision-making. In this guide, we’ll explore real-world case studies that demonstrate the practical use of SQL queries to analyze data and derive valuable insights. Let’s dive into some intriguing scenarios with practical code examples.
Case Study 1: Retail Sales Analysis
Problem statement:.
A retail company wants to analyze its sales data to identify top-selling products, sales trends over time, and customer demographics.
SQL Queries:
Top-selling products:, sales trends over time:, customer demographics:, case study 2: healthcare analytics.

Written by SQL Programming
Daily SQL Contents
Text to speech
Introduction to SQL
What is a database definition, types and components.
- What is SQL and how to get started with it?
- SQL Basics – One Stop Solution for Beginners
- What are SQL Operators and how do they work?
- Understanding SQL Data Types – All You Need To Know About SQL Data Types
- SQL Tutorial : One Stop Solution to Learn SQL
- DBMS Tutorial : A Complete Crash Course on DBMS
- CREATE TABLE in SQL – Everything You Need To Know About Creating Tables in SQL
- What is a Schema in SQL and how to create it?
- What is a Cursor in SQL and how to implement it?
- Top 10 Reasons Why You Should Learn SQL
- Learn how to use SQL SELECT with examples
- SQL Functions: How to write a Function in SQL?
What is SQL Regex and how to implement it?
- SQL UPDATE : Learn How To Update Values In A Table
- SQL Union – A Comprehensive Guide on the UNION Operator
- Triggers in SQL – Learn With Examples
- INSERT Query SQL – All You Need to Know about the INSERT statement
How To Use Alter Table Statement In SQL?
- What is Normalization in SQL and what are its types?
- How to perform IF statement in SQL?
- What are SQL constraints and its different types?
- Learn How To Use CASE Statement In SQL
Primary Key In SQL : Everything You Need To Know About Primary Key Operations
- Foreign Key SQL : Everything You Need To Know About Foreign Key Operations
- SQL Commands - A Beginner's Guide To SQL
- How to Change Column Name in SQL?
How to retrieve a set of characters using SUBSTRING in SQL?
- What is the use of SQL GROUP BY statement?
- How To Use ORDER BY Clause In SQL?
- How to use Auto Increment in SQL?
Everything You Need to Know About LIKE Operator in SQL
- What is an index in SQL?
- Understanding SQL Joins – All You Need To Know About SQL Joins
- Differences Between SQL & NoSQL Databases – MySQL & MongoDB Comparison
- What is Database Testing and How to Perform it?
- SQL Pivot – Know how to convert rows to columns
Introduction To MySQL
- What is MySQL? – An Introduction To Database Management Systems
- How To Install MySQL on Windows 10? – Your One Stop Solution To Install MySQL
- MySQL Tutorial - A Beginner's Guide To Learn MySQL
- MySQL Data Types – An Overview Of The Data Types In MySQL
- How To Use CASE Statement in MySQL?
- DECODE in SQL – Syntax of Oracle Decode Function
What are basic MongoDB commands and how to use them?
- SSIS Tutorial For Beginners: Why, What and How?
- Learn About How To Use SQL Server Management Studio
- SQLite Tutorial: Everything You Need To Know
- What is SQLite browser and how to use it?
- MySQL Workbench Tutorial – A Comprehensive Guide To The RDBMS Tool
Postgre SQL
- PostgreSQL Tutorial For Beginners – All You Need To Know About PostgreSQL
- PL/SQL Tutorial : Everything You Need To Know About PL/SQL
- Learn How To Handle Exceptions In PL/SQL
SQL Interview Questions
Top 117 sql interview questions and answers for 2024.
- Top 50 MySQL Interview Questions You Must Prepare In 2024
- Top 50 DBMS Interview Questions You Need to know in 2024
RDBMS is one of the most commonly used databases to date, and therefore SQL skills are indispensable in most of the job roles. In this SQL Interview Questions article, I will introduce you to the most frequently asked interview questions on SQL (Structured Query Language). This article is the perfect guide for you to learn all the concepts related to SQL, Oracle, MS SQL Server, and MySQL database. Our Top 115 SQL Interview Questions article is the one-stop resource from where you can boost your SQL interview preparation.
Let’s get started!
- What is the difference between SQL and MySQL?
- What are the different subsets of SQL?
- What do you mean by DBMS? What are its different types?
- What do you mean by table and field in SQL?
- What are joins in SQL?
- What is the difference between CHAR and VARCHAR2 datatype in SQL?
- What is the Primary key?
- What are Constraints?
- What is the difference between DELETE and TRUNCATE statements?
- What is a Unique key?
Basic SQL Interview Questions
Q1. what is the difference between sql and mysql.
| SQL is a standard language which stands for Structured Query Language based on the English language | MySQL is a database management system. |
| SQL is the core of the relational database which is used for accessing and managing database | MySQL is an RDMS (Relational Database Management System) such as SQL Server, Informix etc. |
Q2. What are the different subsets of SQL?
- Data Definition Language (DDL) – It allows you to perform various operations on the database such as CREATE, ALTER, and DELETE objects.
- Data Manipulation Language(DML) – It allows you to access and manipulate data. It helps you to insert, update, delete and retrieve data from the database.
- Data Control Language(DCL) – It allows you to control access to the database. Example – Grant and Revoke access permissions.
Q3. What do you mean by DBMS? What are its different types?
A DBMS allows a user to interact with the database. The data stored in the database can be modified, retrieved and deleted and can be of any type like strings, numbers, images, etc.
There are two types of DBMS:
- Relational Database Management System : The data is stored in relations (tables). Example – MySQL.
- Non-Relational Database Management System : There is no concept of relations, tuples and attributes. Example – MongoDB
Let’s move to the next question in this SQL Interview Questions.
Q4. What is RDBMS? How is it different from DBMS?
A relational database management system (RDBMS) is a set of applications and features that allow IT professionals and others to develop, edit, administer, and interact with relational databases. Most commercial relational database management systems use Structured Query Language (SQL) to access the database, which is stored in the form of tables. RDBMS is the most widely used database system in businesses all over the world. It offers a stable means of storing and retrieving massive amounts of data.
Databases, in general, hold collections of data that may be accessed and used in other applications. The development, administration, and use of database platforms are all supported by a database management system.
A relational database management system (RDBMS) is a type of database management system (DBMS) that stores data in a row-based table structure that links related data components. An RDBMS contains functions that ensure the data’s security, accuracy, integrity, and consistency. This is not the same as the file storage utilized by a database management system.
The following are some further distinctions between database management systems and relational database management systems:
Number of users who are permitted to utilise the system DBMS can only handle one user at a time, whereas an RDBMS can handle numerous users. Hardware and software specifications In comparison to an RDBMS, a DBMS requires less software and hardware. Amount of information RDBMSes can handle any quantity of data, from tiny to enormous, whereas DBMSes are limited to small amounts. The structure of the database Data is stored in a hierarchical format in a DBMS, whereas an RDBMS uses a table with headers that serve as column names and rows that hold the associated values. Implementation of the ACID principle The atomicity, consistency, isolation, and durability (ACID) concept is not used by DBMSs for data storage. RDBMSes, on the other hand, use the ACID model to organize their data and ensure consistency. Databases that are distributed DBMS will not provide complete support for distributed databases, whereas RDBMS will. Programs that are managed DBMS focuses on keeping databases that are present within the computer network and system hard discs, whereas an RDBMS helps manage relationships between its incorporated tables of data. Normalization of databases is supported RDBMS can be normalized , but a DBMS cannot be normalized.
Q5. What is a Self-Join?
Self-join is a type of join that can be used to connect two tables. As a result, it is a unary relationship. Each row of the table is attached to itself and all other rows of the same table in a self-join. As a result, self-joining is mostly used to combine and compare rows from the same database table.
Q6. What is the SELECT statement?
The SELECT command gets zero or more rows from one or more database tables or views. SELECT the most frequent data manipulation language (DML) command in most applications. SELECT queries define a result set, but not how to calculate it, because SQL is a declarative programming language.
Q7. What are some common clauses used with SELECT query in SQL?
The following are some frequent SQL clauses used in conjunction with a SELECT query:
WHERE clause: In SQL, the WHERE clause is used to filter records that are required depending on certain criteria. ORDER BY clause: The ORDER BY clause in SQL is used to sort data in ascending (ASC) or descending (DESC) order depending on specified field(s) (DESC). GROUP BY clause: GROUP BY clause in SQL is used to group entries with identical data and may be used with aggregation methods to obtain summarised database results. HAVING clause in SQL is used to filter records in combination with the GROUP BY clause. It is different from WHERE, since the WHERE clause cannot filter aggregated records.
Q8. What are UNION, MINUS and INTERSECT commands?
The UNION operator is used to combine the results of two tables while also removing duplicate entries. The MINUS operator is used to return rows from the first query but not from the second query. The INTERSECT operator is used to combine the results of both queries into a single row. Before running either of the above SQL statements, certain requirements must be satisfied – Within the clause, each SELECT query must have the same number of columns. The data types in the columns must also be comparable. In each SELECT statement, the columns must be in the same order.
Q9. What is Cursor? How to use a Cursor?
After any variable declaration, DECLARE a cursor. A SELECT Statement must always be coupled with the cursor definition.
To start the result set, move the cursor over it. Before obtaining rows from the result set, the OPEN statement must be executed.
To retrieve it and go to the next row in the result set, use the FETCH command.
To disable the cursor, use the CLOSE command.
Finally, use the DEALLOCATE command to remove the cursor definition and free up the resources connected to it.
Q10. List the different types of relationships in SQL.
There are different types of relations in the database:
One-to-One – This is a connection between two tables in which each record in one table corresponds to the maximum of one record in the other.
One-to-Many and Many-to-One – This is the most frequent connection, in which a record in one table is linked to several records in another.
Many-to-Many – This is used when defining a relationship that requires several instances on each side.
Self-Referencing Relationships – When a table has to declare a connection with itself, this is the method to employ.
Q12. What is OLTP?
OLTP, or online transactional processing, allows huge groups of people to execute massive amounts of database transactions in real time, usually via the internet. A database transaction occurs when data in a database is changed, inserted, deleted, or queried.
Q13. What are the differences between OLTP and OLAP?
OLTP stands for online transaction processing, whereas OLAP stands for online analytical processing. OLTP is an online database modification system, whereas OLAP is an online database query response system.
Q14. How do I create empty tables with the same structure as another table?
To create empty tables: Using the INTO operator to fetch the records of one table into a new table while setting a WHERE clause to false for all entries, it is possible to create empty tables with the same structure. As a result, SQL creates a new table with a duplicate structure to accept the fetched entries, but nothing is stored into the new table since the WHERE clause is active.
Q15. What is PostgreSQL?
In 1986, a team lead by Computer Science Professor Michael Stonebraker created PostgreSQL under the name Postgres. It was created to aid developers in the development of enterprise-level applications by ensuring data integrity and fault tolerance in systems. PostgreSQL is an enterprise-level, versatile, resilient, open-source, object-relational database management system that supports variable workloads and concurrent users. The international developer community has constantly backed it. PostgreSQL has achieved significant appeal among developers because to its fault-tolerant characteristics. It’s a very reliable database management system, with more than two decades of community work to thank for its high levels of resiliency, integrity, and accuracy. Many online, mobile, geospatial, and analytics applications utilise PostgreSQL as their primary data storage or data warehouse.
SQL Interview Questions and Answers for Freshers
Q16. what are sql comments.
SQL Comments are used to clarify portions of SQL statements and to prevent SQL statements from being executed. Comments are quite important in many programming languages. The comments are not supported by a Microsoft Access database. As a result, the Microsoft Access database is used in the examples in Mozilla Firefox and Microsoft Edge. Single Line Comments: It starts with two consecutive hyphens (–). Multi-line Comments: It starts with /* and ends with */.
Q17. What is the usage of the NVL() function?
You may use the NVL function to replace null values with a default value. The function returns the value of the second parameter if the first parameter is null. If the first parameter is anything other than null, it is left alone.
This function is used in Oracle, not in SQL and MySQL. Instead of NVL() function, MySQL have IFNULL() and SQL Server have ISNULL() function.
Q18. Explain character-manipulation functions? Explains its different types in SQL.
Change, extract, and edit the character string using character manipulation routines. The function will do its action on the input strings and return the result when one or more characters and words are supplied into it.
The character manipulation functions in SQL are as follows:
A) CONCAT (joining two or more values): This function is used to join two or more values together. The second string is always appended to the end of the first string.
B) SUBSTR: This function returns a segment of a string from a given start point to a given endpoint.
C) LENGTH: This function returns the length of the string in numerical form, including blank spaces.
D) INSTR: This function calculates the precise numeric location of a character or word in a string.
E) LPAD: For right-justified values, it returns the padding of the left-side character value.
F) RPAD: For a left-justified value, it returns the padding of the right-side character value.
G) TRIM: This function removes all defined characters from the beginning, end, or both ends of a string. It also reduced the amount of wasted space.
H) REPLACE: This function replaces all instances of a word or a section of a string (substring) with the other string value specified.
Q19. Write the SQL query to get the third maximum salary of an employee from a table named employees.
Employee table
| employee_name | salary |
| A | 24000 |
| C | 34000 |
| D | 55000 |
| E | 75000 |
| F | 21000 |
| G | 40000 |
| H | 50000 |
SELECT * FROM(
SELECT employee_name, salary, DENSE_RANK()
OVER(ORDER BY salary DESC)r FROM Employee)
WHERE r=&n;
To find 3rd highest salary set n = 3
Q20. What is the difference between the RANK() and DENSE_RANK() functions?
The RANK() function in the result set defines the rank of each row within your ordered partition. If both rows have the same rank, the next number in the ranking will be the previous rank plus a number of duplicates. If we have three records at rank 4, for example, the next level indicated is 7.
The DENSE_RANK() function assigns a distinct rank to each row within a partition based on the provided column value, with no gaps. It always indicates a ranking in order of precedence. This function will assign the same rank to the two rows if they have the same rank, with the next rank being the next consecutive number. If we have three records at rank 4, for example, the next level indicated is 5.
Q21. What are Tables and Fields?
A table is a collection of data components organized in rows and columns in a relational database. A table can also be thought of as a useful representation of relationships. The most basic form of data storage is the table. An example of an Employee table is shown below.
| ID | Name | Department | Salary |
| 1 | Rahul | Sales | 24000 |
| 2 | Rohini | Marketing | 34000 |
| 3 | Shylesh | Sales | 24000 |
| 4 | Tarun | Analytics | 30000 |
A Record or Row is a single entry in a table. In a table, a record represents a collection of connected data. The Employee table, for example, has four records.
A table is made up of numerous records (rows), each of which can be split down into smaller units called Fields(columns). ID, Name, Department, and Salary are the four fields in the Employee table above.
Q22. What is a UNIQUE constraint?
The UNIQUE Constraint prevents identical values in a column from appearing in two records. The UNIQUE constraint guarantees that every value in a column is unique.
Q23. What is a Self-Join?
Self-join is a type of join that can be used to connect two tables. As a result, it is a unary relationship. Each row of the table is attached to itself and all other rows of the same table in a self-join. As a result, a self-join is mostly used to combine and compare rows from the same database table.
Q24. What is the SELECT statement?
A SELECT command gets zero or more rows from one or more database tables or views. SELECT the most frequent data manipulation language (DML) command is SELECT in most applications. SELECT queries define a result set, but not how to calculate it, because SQL is a declarative programming language.
Q25. What are some common clauses used with SELECT query in SQL?
Q26. what are union, minus and intersect commands.
The UNION operator is used to combine the results of two tables while also removing duplicate entries.
The MINUS operator is used to return rows from the first query but not from the second query.
The INTERSECT operator is used to combine the results of both queries into a single row. Before running either of the above SQL statements, certain requirements must be satisfied –
Within the clause, each SELECT query must have the same amount of columns.
The data types in the columns must also be comparable.
In each SELECT statement, the columns must be in the same order.
Q27. What is Cursor? How to use a Cursor?
To retrieve and go to the next row in the result set, use the FETCH command.
Finally, use the DEALLOCATE command to remove the cursor definition and free up the resources connected with it.
Q28. List the different types of relationships in SQL.
There are different types of relations in the database: One-to-One – This is a connection between two tables in which each record in one table corresponds to the maximum of one record in the other. One-to-Many and Many-to-One – This is the most frequent connection, in which a record in one table is linked to several records in another. Many-to-Many – This is used when defining a relationship that requires several instances on each sides. Self-Referencing Relationships – When a table has to declare a connection with itself, this is the method to employ.
Q29. What is SQL example?
SQL is a database query language that allows you to edit, remove, and request data from databases. The following statements are a few examples of SQL statements:
- SELECT
- INSERT
- CREATE DATABASE
- ALTER DATABASE
Q30. What are basic SQL skills?
SQL skills aid data analysts in the creation, maintenance, and retrieval of data from relational databases, which divide data into columns and rows. It also enables users to efficiently retrieve, update, manipulate, insert, and alter data.
The most fundamental abilities that a SQL expert should possess are:
- Database Management
- Structuring a Database
- Creating SQL clauses and statements
- SQL System SKills like MYSQL, PostgreSQL
- PHP expertise is useful.
- Analyze SQL data
- Using WAMP with SQL to create a database
- OLAP Skills
Q31. What is schema in SQL Server? A schema is a visual representation of the database that is logical. It builds and specifies the relationships among the database’s numerous entities. It refers to the several kinds of constraints that may be applied to a database. It also describes the various data kinds. It may also be used on Tables and Views.
Schemas come in a variety of shapes and sizes. Star schema and Snowflake schema are two of the most popular. The entities in a star schema are represented in a star form, whereas those in a snowflake schema are shown in a snowflake shape. Any database architecture is built on the foundation of schemas.
Q32. How to create a temp table in SQL Server?
Temporary tables are created in TempDB and are erased automatically after the last connection is closed. We may use Temporary Tables to store and process interim results. When we need to store temporary data, temporary tables come in handy. The following is the syntax for creating a Temporary Table: CREATE TABLE #Employee (id INT, name VARCHAR(25)) INSERT INTO #Employee VALUES (01, ‘Ashish’), (02, ‘Atul’)
Q33. How to install SQL Server in Windows 11?
Install SQL Server Management Studio In Windows 11
Step 1: Click on SSMS, which will take you to the SQL Server Management Studio page.
Step 2: Moreover, click on the SQL Server Management Studio link and tap on Save File.
Step 3: Save this file to your local drive and go to the folder.
Step 4: The setup window will appear, and here you can choose the location where you want to save the file. Step 5: Click on Install. Step 6: Close the window after the installation is complete. Step 7: Furthermore, go back to your Start Menu and search for SQL server management studio.
Step 8: Furthermore, double-click on it, and the login page will appear once it shows up.
Step 9: You should be able to see your server name. However, if that’s not visible, click on the drop-down arrow on the server and tap on Browse.
Step 10: Choose your SQL server and click on Connect.
After that, the SQL server will connect, and Windows 11 will run well.
Q34. What is the case when in SQL Server?
The CASE statement is used to construct logic in which one column’s value is determined by the values of other columns.
At least one set of WHEN and THEN commands makes up the SQL Server CASE Statement. The condition to be tested is specified by the WHEN statement. If the WHEN the condition returns TRUE, the THEN sentence explains what to do.
When none of the WHEN conditions return true, the ELSE statement is executed. The END keyword brings the CASE statement to a close.
Q35. NoSQL vs SQL
In summary, the following are the five major distinctions between SQL and NoSQL:
Relational databases are SQL, while non-relational databases are NoSQL.
SQL databases have a specified schema and employ structured query language. For unstructured data, NoSQL databases use dynamic schemas.
SQL databases scale vertically, but NoSQL databases scale horizontally.
NoSQL databases are document, key-value, graph, or wide-column stores, whereas SQL databases are table-based.
SQL databases excel in multi-row transactions, while NoSQL excels at unstructured data such as documents and JSON.
Q36. What is the difference between NOW() and CURRENT_DATE()? NOW() returns a constant time that indicates the time at which the statement began to execute. (Within a stored function or trigger, NOW() returns the time at which the function or triggering statement began to execute. The simple difference between NOW() and CURRENT_DATE() is that NOW() will fetch the current date and time both in format ‘YYYY-MM_DD HH:MM:SS’ while CURRENT_DATE() will fetch the date of the current day ‘YYYY-MM_DD’.
Q37. What is BLOB and TEXT in MySQL?
BLOB stands for Binary Huge Objects and can be used to store binary data, whereas TEXT may be used to store a large number of strings. BLOB may be used to store binary data, which includes images, movies, audio, and applications. BLOB values function similarly to byte strings, and they lack a character set. As a result, bytes’ numeric values are completely dependent on comparison and sorting. TEXT values behave similarly to a character string or a non-binary string. The comparison/sorting of TEXT is completely dependent on the character set collection.
SQL Interview Questions and Answers for Experienced
Q38. How to remove duplicate rows in SQL?
If the SQL table has duplicate rows, the duplicate rows must be removed.
Let’s assume the following table for our dataset:
| ID | Name | Age |
| 1 | A | 21 |
| 2 | B | 23 |
| 2 | B | 23 |
| 4 | D | 22 |
| 5 | E | 25 |
| 6 | G | 26 |
| 5 | E | 25 |
The following SQL query removes the duplicate ids from the table: DELETE FROM table WHERE ID IN ( SELECT ID, COUNT(ID) FROM table GROUP BY ID HAVING COUNT (ID) > 1);
Q39. How to create a stored procedure using SQL Server?
A stored procedure is a piece of prepared SQL code that you can save and reuse again and over. So, if you have a SQL query that you create frequently, save it as a stored procedure and then call it to run it. You may also supply parameters to a stored procedure so that it can act based on the value(s) of the parameter(s) given.
Stored Procedure Syntax
CREATE PROCEDURE procedure_name
sql_statement
Execute a Stored Procedure
EXEC procedure_name;
Q40. What is Database Black Box Testing?
Black Box Testing is a software testing approach that involves testing the functions of software applications without knowing the internal code structure, implementation details, or internal routes. Black Box Testing is a type of software testing that focuses on the input and output of software applications and is totally driven by software requirements and specifications. Behavioral testing is another name for it. Q41. What are the different types of SQL sandbox?
SQL Sandbox is a secure environment within SQL Server where untrusted programmes can be run. There are three different types of SQL sandboxes:
Safe Access Sandbox: In this environment, a user may execute SQL activities like as building stored procedures, triggers, and so on, but they can’t access the memory or create files.
Sandbox for External Access: Users can access files without having the ability to alter memory allocation.
Unsafe Access Sandbox: This contains untrustworthy code that allows a user to access memory.
Q42. Where MyISAM table is stored?
Prior to the introduction of MySQL 5.5 in December 2009, MyISAM was the default storage engine for MySQL relational database management system versions. It’s based on the older ISAM code, but it comes with a lot of extra features. Each MyISAM table is split into three files on disc (if it is not partitioned). The file names start with the table name and end with an extension that indicates the file type. The table definition is stored in a.frm file, however this file is not part of the MyISAM engine; instead, it is part of the server. The data file suffix is.MYD (MYData). The index file extension is.MYI (MYIndex). If you lose your index file, you may always restore it by recreating indexes. Q43. How to find the nth highest salary in SQL? The most typical interview question is to find the Nth highest pay in a table. This work can be accomplished using the dense rank() function. Employee table
To find to the 2nd highest salary set n = 2
To find 3rd highest salary set n = 3 and so on.
Q44. What do you mean by table and field in SQL?
A table refers to a collection of data in an organised manner in form of rows and columns. A field refers to the number of columns in a table. For example:
Table : StudentInformation Field : Stu Id, Stu Name, Stu Marks
Q45. What are joins in SQL?
A JOIN clause is used to combine rows from two or more tables, based on a related column between them. It is used to merge two tables or retrieve data from there. There are 4 types of joins, as you can refer to below:
- Inner join: Inner Join in SQL is the most common type of join. It is used to return all the rows from multiple tables where the join condition is satisfied.
Left Join: Left Join in SQL is used to return all the rows from the left table but only the matching rows from the right table where the join condition is fulfilled.
Right Join: Right Join in SQL is used to return all the rows from the right table but only the matching rows from the left table where the join condition is fulfilled.
Full Join: Full join returns all the records when there is a match in any of the tables. Therefore, it returns all the rows from the left-hand side table and all the rows from the right-hand side table.
Q46. What is the difference between CHAR and VARCHAR2 datatype in SQL?
Both Char and Varchar2 are used for character datatype but varchar2 is used for character strings of variable length whereas Char is used for strings of fixed length. For example, char(10) can only store 10 characters and will not be able to store a string of any other length whereas varchar2(10) can store any length i.e 6,8,2 in this variable.
Q47. What is a Primary key?
- Uniquely identifies a single row in the table
- Null values not allowed
Example- In the Student table, Stu_ID is the primary key.
Q48. What are Constraints?
Constraints in SQL are used to specify the limit on the data type of the table. It can be specified while creating or altering the table statement. The sample of constraints are:
- PRIMARY KEY
- FOREIGN KEY
Q49. What is the difference between DELETE and TRUNCATE statements?
| Delete command is used to delete a row in a table. | Truncate is used to delete all the rows from a table. |
| You can rollback data after using delete statement. | You cannot rollback data. |
| It is a DML command. | It is a DDL command. |
| It is slower than truncate statement. | It is faster. |
Q50. What is a Unique key?
- Uniquely identifies a single row in the table.
- Multiple values allowed per table.
- Null values allowed.
Apart from this SQL Interview Questions blog, if you want to get trained by professionals on this technology, you can opt for structured training from edureka!
Q51. What is a Foreign key in SQL?
- Foreign key maintains referential integrity by enforcing a link between the data in two tables.
- The foreign key in the child table references the primary key in the parent table.
- The foreign key constraint prevents actions that would destroy links between the child and parent tables.
Q52. What do you mean by data integrity?
Data Integrity defines the accuracy as well as the consistency of the data stored in a database. It also defines integrity constraints to enforce business rules on the data when it is entered into an application or a database.
Q53. What is the difference between clustered and non-clustered index in SQL?
The differences between the clustered and non clustered index in SQL are :
- Clustered index is used for easy retrieval of data from the database and its faster whereas reading from non clustered index is relatively slower.
- Clustered index alters the way records are stored in a database as it sorts out rows by the column which is set to be clustered index whereas in a non clustered index, it does not alter the way it was stored but it creates a separate object within a table which points back to the original table rows after searching.
One table can only have one clustered index whereas it can have many non clustered indexes.
Q54. Write a SQL query to display the current date?
In SQL, there is a built-in function called GetDate() which helps to return the current timestamp/date.
Q55. What do you understand from query optimization?
The phase that identifies a plan for the evaluation query with the least estimated cost is known as query optimization.
The advantages of query optimization are as follows:
- The output is provided faster
- A larger number of queries can be executed in less time
- Reduces time and space complexity
Find out our MS SQL Course in Top Cities
| India | India |
Denormalization refers to a technique which is used to access data from higher to lower forms of a database. It helps database managers to increase the performance of the entire infrastructure as it introduces redundancy into a table. It adds the redundant data into a table by incorporating database queries that combine data from various tables into a single table.
Q57. What are Entities and Relationships?
Entities : A person, place, or thing in the real world about which data can be stored in a database. Tables store data that represents one type of entity. For example – A bank database has a customer table to store customer information. The customer table stores this information as a set of attributes (columns within the table) for each customer.
Relationships : Relation or links between entities that have something to do with each other. For example – The customer’s name is related to the customer account number and contact information, which might be in the same table. There can also be relationships between separate tables (for example, customer to accounts).
Q58. What is an Index?
An index refers to a performance tuning method of allowing faster retrieval of records from the table. An index creates an entry for each value and hence it will be faster to retrieve data.
Q59 . Explain different types of index in SQL.
There are three types of index in SQL namely:
Unique Index:
This index does not allow the field to have duplicate values if the column is unique indexed. If a primary key is defined, a unique index can be applied automatically.
Clustered Index:
This index reorders the physical order of the table and searches based on the basis of key values. Each table can only have one clustered index.
Non-Clustered Index:
Non-Clustered Index does not alter the physical order of the table and maintains a logical order of the data. Each table can have many nonclustered indexes.
SQL Interview Questions for Data Analyst
Q60. what is normalization and what are the advantages of it.
Normalization in SQL is the process of organizing data to avoid duplication and redundancy. Some of the advantages are:
- Better Database organization
- More Tables with smaller rows
- Efficient data access
- Greater Flexibility for Queries
- Quickly find the information
- Easier to implement Security
- Allows easy modification
- Reduction of redundant and duplicate data
- More Compact Database
- Ensure Consistent data after modification
Apart from this SQL Interview Questions Blog, if you want to get trained by professionals on this technology, you can opt for structured training from edureka!
Q61. What is the difference between DROP and TRUNCATE commands?
DROP command removes a table and it cannot be rolled back from the database whereas TRUNCATE command removes all the rows from the table.
Q62. Explain the different types of Normalization.
There are many successive levels of normalization. These are called normal forms . Each consecutive normal form depends on the previous one.The first three normal forms are usually adequate.
Normal Forms are used in database tables to remove or decrease duplication. The following are the many forms:
First Normal Form: When every attribute in a relationship is a single-valued attribute, it is said to be in the first normal form. The first normal form is broken when a relation has a composite or multi-valued property.
Second Normal Form:
A relationship is in a second normal form if it meets the first normal form’s requirements and does not contain any partial dependencies. In 2NF, a relation has no partial dependence, which means it has no non-prime attribute that is dependent on any suitable subset of any table candidate key. Often, the problem may be solved by setting a single column Primary Key.
Third Normal Form: If a relation meets the requirements for the second normal form and there is no transitive dependency, it is said to be in the third normal form.
Q63. What is OLTP?
What are the differences between OLTP and OLAP?
Q64. How to create empty tables with the same structure as another table?
To create empty tables:
Using the INTO operator to fetch the records of one table into a new table while setting a WHERE clause to false for all entries, it is possible to create empty tables with the same structure. As a result, SQL creates a new table with a duplicate structure to accept the fetched entries, but nothing is stored into the new table since the WHERE clause is active.
Q65. What is PostgreSQL?
In 1986, a team lead by Computer Science Professor Michael Stonebraker created PostgreSQL under the name Postgres. It was created to aid developers in the development of enterprise-level applications by ensuring data integrity and fault tolerance in systems. PostgreSQL is an enterprise-level, versatile, resilient, open-source, object-relational database management system that supports variable workloads and concurrent users. The international developer community has consistently backed it. PostgreSQL has achieved significant appeal among developers because of its fault-tolerant characteristics. It’s a very reliable database management system, with more than two decades of community work to thank for its high levels of resiliency, integrity, and accuracy. Many online, mobile, geospatial, and analytics applications utilise PostgreSQL as their primary data storage or data warehouse.
Q66. What are SQL comments?
SQL Comments are used to clarify portions of SQL statements and to prevent SQL statements from being executed. Comments are quite important in many programming languages. These comments are not supported by the Microsoft Access database. As a result, the Microsoft Access database is used in the examples in Mozilla Firefox and Microsoft Edge. Single Line Comments: It starts with two consecutive hyphens (–). Multi-line Comments: It starts with /* and ends with */.
Q67. What is the difference between the RANK() and DENSE_RANK() functions?
Q68. What is SQL Injection?
SQL injection is a sort of flaw in website and web app code that allows attackers to take control of back-end processes and access, retrieve, and delete sensitive data stored in databases. In this approach, malicious SQL statements are entered into a database entry field, and the database becomes exposed to an attacker once they are executed. By utilising data-driven apps, this strategy is widely utilised to get access to sensitive data and execute administrative tasks on databases. SQLi attack is another name for it.
The following are some examples of SQL injection:
- Getting access to secret data in order to change a SQL query to acquire the desired results.
- UNION attacks are designed to steal data from several database tables.
- Examine the database to get information about the database’s version and structure
Q69. How many Aggregate functions are available in SQL?
SQL aggregate functions provide information about a database’s data. AVG, for example, returns the average of a database column’s values.
SQL provides seven (7) aggregate functions, which are given below:
AVG(): returns the average value from the specified columns. COUNT(): returns the number of table rows, including rows with null values. MAX(): returns the largest value among the group. MIN(): returns the smallest value among the group. SUM(): returns the total summed values(non-null) of the specified column. FIRST(): returns the first value of an expression. LAST(): returns the last value of an expression.
Q70. What is the default ordering of data using the ORDER BY clause? How could it be changed?
The ORDER BY clause in MySQL can be used without the ASC or DESC modifiers. The sort order is preset to ASC or ascending order when this attribute is absent from the ORDER BY clause.
Q71. How do we use the DISTINCT statement? What is its use?
The SQL DISTINCT keyword is combined with the SELECT query to remove all duplicate records and return only unique records. There may be times when a table has several duplicate records. The DISTINCT clause in SQL is used to eliminate duplicates from a SELECT statement’s result set.
Q72. What are the syntax and use of the COALESCE function?
From a succession of expressions, the COALESCE function returns the first non-NULL value. The expressions are evaluated in the order that they are supplied, and the function’s result is the first non-null value. Only if all of the inputs are null does the COALESCE method return NULL.
The syntax of COALESCE function is COALESCE (exp1, exp2, …. expn)
Q73. What is the ACID property in a database?
ACID stands for Atomicity, Consistency, Isolation, Durability. It is used to ensure that the data transactions are processed reliably in a database system.
- Atomicity: Atomicity refers to the transactions that are completely done or failed where transaction refers to a single logical operation of a data. It means if one part of any transaction fails, the entire transaction fails and the database state is left unchanged.
- Consistency: Consistency ensures that the data must meet all the validation rules. In simple words, you can say that your transaction never leaves the database without completing its state.
- Isolation: The main goal of isolation is concurrency control.
- Durability: Durability means that if a transaction has been committed, it will occur whatever may come in between such as power loss, crash or any sort of error.
Top 10 Trending Technologies to Learn in 2024 | Edureka
Q74. what do you mean by “trigger” in sql.
Trigger in SQL is are a special type of stored procedures that are defined to execute automatically in place or after data modifications. It allows you to execute a batch of code when an insert, update or any other query is executed against a specific table.
Q75. What are the different operators available in SQL?
There are three operators available in SQL , namely:
- Arithmetic Operators
- Logical Operators
- Comparison Operators
Apart from this SQL Interview Questions blog, if you want to get trained by professionals on this technology, you can opt for structured training from Edureka!
Q76. Are NULL values the same as that of zero or a blank space?
A NULL value is not at all the same as that of zero or a blank space. NULL values represent a value that is unavailable, unknown, assigned or not applicable whereas a zero is a number and a blank space is a character.
Q77. What is the difference between cross join and natural join?
The cross join produces the cross product or Cartesian product of two tables whereas the natural join is based on all the columns having the same name and data types in both the tables.
Q78. What is subquery in SQL?
A subquery is a query inside another query where a query is defined to retrieve data or information back from the database. In a subquery, the outer query is called as the main query whereas the inner query is called subquery. Subqueries are always executed first and the result of the subquery is passed on to the main query. It can be nested inside a SELECT, UPDATE or any other query. A subquery can also use any comparison operators such as >,< or =.
Q79. What are the different types of a subquery?
There are two types of subquery namely, Correlated and Non-Correlated.
Correlated subquery : These are queries which select the data from a table referenced in the outer query. This is not considered an independent query as it refers to another table and refers to the column in a table.
Non-Correlated subquery : This query is an independent query where the output of subquery is substituted in the main query.
Q80. List the ways to get the count of records in a table?
To count the number of records in a table in SQL , you can use the below commands:
Apart from this SQL Interview Questions Blog, if you want to get trained by professionals on this technology, you can opt for structured training from edureka!
Interview Questions for SQL Developer
Q81. write a sql query to find the names of employees that begin with ‘a’.
To display name of the employees that begin with ‘A’, type in the below command:
Q82. Write a SQL query to get the third-highest salary of an employee from employee_table?
Q83. what is the need for group functions in sql .
Group functions work on the set of rows and return one result per group. Some of the commonly used group functions are: AVG, COUNT, MAX, MIN, SUM, VARIANCE.
Q84. What is a Relationship and what are they?
Relation or links are between entities that have something to do with each other. Relationships are defined as the connection between the tables in a database. There are various relationships, namely:
- One to One Relationship.
- One to Many Relationship.
- Many to One Relationship.
- Self-Referencing Relationship.
Q85. How can you insert NULL values in a column while inserting the data?
NULL values in SQL can be inserted in the following ways:
- Implicitly by omitting column from column list.
- Explicitly by specifying NULL keyword in the VALUES clause
Q86. What is the main difference between ‘BETWEEN’ and ‘IN’ condition operators?
BETWEEN operator is used to display rows based on a range of values in a row whereas the IN condition operator is used to check for values contained in a specific set of values.
Example of BETWEEN:
Q87. why are sql functions used.
SQL functions are used for the following purposes:
- To perform some calculations on the data
- To modify individual data items
- To manipulate the output
- To format dates and numbers
- To convert the data types
Q88. What is the need for MERGE statement?
This statement allows conditional update or insertion of data into a table. It performs an UPDATE if a row exists, or an INSERT if the row does not exist.
Q89. What do you mean by recursive stored procedure?
Recursive stored procedure refers to a stored procedure which calls by itself until it reaches some boundary condition. This recursive function or procedure helps the programmers to use the same set of code n number of times.
Q90. What is CLAUSE in SQL?
SQL clause helps to limit the result set by providing a condition to the query. A clause helps to filter the rows from the entire set of records.
For example – WHERE, HAVING clause.
Apart from this SQL Interview Questions Blog, if you want to get trained by professionals on this technology, you can opt for a structured training from edureka! Click below to learn more.
Q91. What is the difference between ‘HAVING’ CLAUSE and a “where” clause?
HAVING clause can only be used only with SELECT statement. It is usually used in a GROUP BY clause and whenever GROUP BY is not used, HAVING behaves like a WHERE clause. Having Clause is only used with the GROUP BY function in a query whereas WHERE Clause is applied to each row before they are a part of the GROUP BY function in a query.
Q92. List the ways in which Dynamic SQL can be executed?
Following are the ways in which dynamic SQL can be executed:
- Write a query with parameters.
- Using EXEC.
- Using sp_executesql.
Q93. What are the various levels of constraints?
Constraints are the representation of a column to enforce data entity and consistency. There are two levels of a constraint, namely:
- column level constraint
- table level constraint
Q94. How can you fetch common records from two tables?
You can fetch common records from two tables using INTERSECT. For example:
Select studentID from student. <strong>INTERSECT </strong> Select StudentID from Exam
Q95. List some case manipulation functions in SQL?
There are three case manipulation functions in SQL, namely:
- LOWER: This function returns the string in lowercase. It takes a string as an argument and returns it by converting it into lower case. Syntax:
- UPPER: This function returns the string in uppercase. It takes a string as an argument and returns it by converting it into uppercase. Syntax:
- INITCAP: This function returns the string with the first letter in uppercase and rest of the letters in lowercase. Syntax:
Apart from this SQL Interview Questions blog, if you want to get trained by professionals on this technology, you can opt for a structured training from edureka! Click below to learn more.
Q96. What are the different set operators available in SQL?
Some of the available set operators are – Union, Intersect or Minus operators.
Q97. What is an ALIAS command?
ALIAS command in SQL is the name that can be given to any table or a column. The alias name can be referred in WHERE clause to identify a particular table or column.
For example-
In the above example, emp refers to alias name for employee table and dept refers to alias name for department table.
Q98. What are aggregate and scalar functions?
Aggregate functions are used to evaluate mathematical calculation and returns a single value. These calculations are done from the columns in a table. For example- max(),count() are calculated with respect to numeric.
Scalar functions return a single value based on the input value. For example – UCASE(), NOW() are calculated with respect to string.
Q99. How can you fetch alternate records from a table?
You can fetch alternate records i.e both odd and even row numbers. For example- To display even numbers, use the following command:
Select studentId from (Select rowno, studentId from student) where mod(rowno,2)=0
Now, to display odd numbers:
Q100. Name the operator which is used in the query for pattern matching?
LIKE an operator is used for pattern matching, and it can be used as -.
- % – It matches zero or more characters.
For example- select * from students where studentname like ‘a%’
_ (Underscore) – it matches exactly one character. For example- select * from student where studentname like ‘abc_’
Apart from this SQL Interview Questions Blog, if you want to get trained from professionals on this technology, you can opt for structured training from edureka!
Q101. How can you select unique records from a table?
You can select unique records from a table by using the DISTINCT keyword.
Using this command, it will print unique student id from the table Student.
Q102. How can you fetch the first 5 characters of the string?
There are a lot of ways to fetch characters from a string. For example:
Select SUBSTRING(StudentName,1,5) as studentname from student
Q103 . What is the main difference between SQL and PL/SQL?
SQL is a query language that allows you to issue a single query or execute a single insert/update/delete whereas PL/SQL is Oracle’s “Procedural Language” SQL, which allows you to write a full program (loops, variables, etc.) to accomplish multiple operations such as selects/inserts/updates/deletes.
Q104. What is a View?
A view is a virtual table which consists of a subset of data contained in a table. Since views are not present, it takes less space to store. View can have data from one or more tables combined and it depends on the relationship.
Q105. What are Views used for?
A view refers to a logical snapshot based on a table or another view. It is used for the following reasons:
- Restricting access to data.
- Making complex queries simple.
- Ensuring data independence.
- Providing different views of the same data.
Q106. What is a Stored Procedure?
A Stored Procedure is a function which consists of many SQL statements to access the database system. Several SQL statements are consolidated into a stored procedure and execute them whenever and wherever required which saves time and avoids writing code again and again.
Q107. List some advantages and disadvantages of Stored Procedure?
Advantages :.
A Stored Procedure can be used as a modular programming which means to create once, store and call several times whenever it is required. This supports faster execution. It also reduces network traffic and provides better security to the data.
Disadvantage :
The only disadvantage of Stored Procedure is that it can be executed only in the database and utilizes more memory in the database server.
Q108. List all the types of user-defined functions?
There are three types of user-defined functions, namely:
- Scalar Functions
- Inline Table-valued functions
- Multi-statement valued functions
Scalar returns the unit, variant defined the return clause. Other two types of defined functions return table.
Q109. What do you mean by Collation?
Collation is defined as a set of rules that determine how data can be sorted as well as compared. Character data is sorted using the rules that define the correct character sequence along with options for specifying case-sensitivity, character width etc.
Q110. What are the different types of Collation Sensitivity?
Following are the different types of collation sensitivity:
- Case Sensitivity: A and a and B and b.
- Kana Sensitivity: Japanese Kana characters.
- Width Sensitivity: Single byte character and double-byte character.
- Accent Sensitivity.
Apart from this SQL Interview Questions Blog, if you want to get trained by professionals on this technology, you can opt for structured training from Edureka!
Q111. What are the Local and Global variables?
Local variables:.
These variables can be used or exist only inside the function. These variables are not used or referred to by any other function.
Global variables:
These variables are the variables which can be accessed throughout the program. Global variables cannot be created whenever that function is called.
Q112. What is Auto Increment in SQL?
Autoincrement keyword allows the user to create a unique number to get generated whenever a new record is inserted into the table. This keyword is usually required whenever PRIMARY KEY in SQL is used.
AUTO INCREMENT keyword can be used in Oracle and IDENTITY keyword can be used in SQL SERVER.
Q113. What is a Datawarehouse?
Datawarehouse refers to a central repository of data where the data is assembled from multiple sources of information. Those data are consolidated, transformed and made available for mining as well as online processing. Warehouse data also has a subset of data called Data Marts.
Q114. What are the different authentication modes in SQL Server? How can it be changed?
Windows mode and Mixed Mode – SQL and Windows. You can go to the steps below to change authentication mode in SQL Server:
- Click Start> Programs> Microsoft SQL Server and click SQL Enterprise Manager to run SQL Enterprise Manager from the Microsoft SQL Server program group.
- Then select the server from the Tools menu.
- Select SQL Server Configuration Properties and choose the Security page.
Q115. What are STUFF and REPLACE function?
Q116. how do you add email validation using only one query.
You can use a regular expression within a SQL query to validate an email format. For example, in MySQL, you can do it like this:
SELECT email
FROM your_table_name
WHERE email REGEXP ‘^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}$’;
This query selects the email column from your_table_name where the email matches the specified regular expression pattern for a valid email format.
To get the last record from a table, you can use a query like this:
SELECT * FROM your_table_name ORDER BY your_primary_key_column DESC LIMIT 1;
Replace your_table_name with the name of your table and your_primary_key_column with the primary key column that defines the order of records. The DESC keyword sorts the records in descending order, and LIMIT 1 ensures you only get the last record.
So this brings us to the end of the SQL interview questions blog. I hope this set of SQL Interview Questions will help you ace your job interview. All the best for your interview!
Apart from this SQL Interview Questions Blog, if you want to get trained from professionals on SQL , you can opt for a structured training from edureka! Click below to know more.
Related Post Oracle SQL Interview Questions
Check out this MySQL DBA Certification Training by Edureka, a trusted online learning company with a network o f more than 250,000 satisfied learners spread across the globe. This course trains you on the core concepts & advanced tools and techniques to manage data and administer the MySQL Database. It includes hands-on learning on concepts like MySQL Workbench, MySQL Server, Data Modeling, MySQL Connector, Database Design, MySQL Command line, MySQL Functions etc. End of the training you will be able to create and administer your own MySQL Database and manage data.
If you wish to learn Microsoft SQL Server and build a career in the relational databases, functions, and queries, variables etc domain, then check out our interactive, live-online SQL Course here, which comes with 24*7 support to guide you throughout your learning period.
If you want to start a career in the MongoDB field then check out this MongoDB Developer Certification Course.
Got a question for us? Please mention it in the comments section of this “ SQL Interview Questions ” blog and we will get back to you as soon as possible.
| Course Name | Date | Details |
|---|---|---|
Class Starts on 3rd August,2024 3rd August SAT&SUN (Weekend Batch) |
Recommended videos for you
Build application with mongodb, introduction to mongodb, recommended blogs for you, gossip protocol in cassandra, what is the use of sql group by statement, understanding journaling in mongodb, sql alchemy tutorial, insert query sql – all you need to know about the insert statement, introduction to cassandra architecture, understanding sql data types – all you need to know about sql data types, development and production of mongodb, mongodb vs cassandra, what is dbms – a comprehensive guide to database management systems, mysql data types – an overview of the data types in mysql, introduction to column family with cassandra, sql views: how to work with views in sql.
The questions are amazing, covers almost all the topics. Can you upload exercise SQL QUERY questions that are asked to write during the interview. Thanks
These question set is very helpful to prepare and revise for interviews. Thanks :)
This is really helpful, but I managed to get this book on Amazon, got all the details I needed to prepare for my interview. Very well written, detailed and concise. Very good exercises as well, so easy to get through a difficult language of coding, especially if this is your first job interview. I recommend.
http://www.amazon.com/TOP-SQL-Interview-Coding-Tasks-ebook/dp/B07GC5RS3K
I needed a clarification about the question no. 6. Difference between char and varchar2.
You’ve explained with an example, char(10) – which can only store 10 characters and not able to store a string of any other length.
According to my knowledge, we can store the data of any length but it should not exceed 10 characters( if we define char(10)).
And if we insert less no.of characters say length 6, then oracle server automatically will add blank spaces in place of remaining 4 bits.
If I’m wrong, please correct me!
Nice set of questions, thanks
Can we join two table which have same data types but different column name ?
This question set is enough for interview.. 👍☺️ Enjoy the Study in Quarantine..
Join the discussion Cancel reply
Trending courses in databases, microsoft sql server certification training c ....
- 5k Enrolled Learners
SQL Essentials Training
- 12k Enrolled Learners
- Weekend/Weekday
MongoDB Certification Training Course
- 17k Enrolled Learners
MySQL DBA Certification Training
- 8k Enrolled Learners
Apache Cassandra Certification Training
- 13k Enrolled Learners
Teradata Certification Training
- 3k Enrolled Learners
Browse Categories
Subscribe to our newsletter, and get personalized recommendations..
Already have an account? Sign in .
20,00,000 learners love us! Get personalised resources in your inbox.
At least 1 upper-case and 1 lower-case letter
Minimum 8 characters and Maximum 50 characters
We have recieved your contact details.
You will recieve an email from us shortly.
- SQL Cheat Sheet
SQL Interview Questions
- MySQL Interview Questions
- PL/SQL Interview Questions
- Learn SQL and Database
SQL Interview Questions and Answers for Freshers
- 1.What is SQL?
- 2. What is a database?
- 3. Does SQL support programming language features?
- 4. What is the difference between CHAR and VARCHAR2 datatype in SQL?
- 5. What do you mean by data definition language?
6. What do you mean by data manipulation language?
- 7. What is the view in SQL?
- 8. What do you mean by foreign key?
- 9. What are table and Field?
- 10. What is the primary key?
- 11. What is a Default constraint?
- 12. What is normalization?
- 13. What is Denormalization?
- 14. What is a query?
- 15. What is a subquery?
- 16. What are the different operators available in SQL?
- 17. What is a Constraint?
- 18. What is Data Integrity?
- 19. What is Auto Increment?
- 20. What is MySQL collation?
- 21. What are user-defined functions?
- 22. What are all types of user-defined functions?
- 23. What is a stored procedure?
- 24. What are aggregate and scalar functions?
- 25. What is an ALIAS command?
- 26. What are Union, minus, and Interact commands?
- 27. What is a T-SQL?
- 28. What is ETL in SQL?
- 29. How to copy tables in SQL?
- 30. What is SQL injection?
- 31. Can we disable a trigger? If yes, how?
Intermediate SQL Interview Questions and Answers
- 32. What are the differences between SQL and PL/SQL?
- 33. What is the difference between BETWEEN and IN operators in SQL?
- 34. Write an SQL query to find the names of employees starting with ‘A’.
- 35. What is the difference between primary key and unique constraints?
- 36. What is a join in SQL? What are the types of joins?
- 37. What is an index?
- 38. What is the On Delete cascade constraint?
- 39. Explain WITH clause in SQL?
- 40. What are all the different attributes of indexes?
- 41. What is a Cursor?
- 42. Write down various types of relationships in SQL?
- 43. What is a trigger?
- 44. What is the difference between SQL DELETE and SQL TRUNCATE commands?
- 45. What is the difference between Cluster and Non-Cluster Index?
- 46. What is a Live Lock?
- 47. What is Case WHEN in SQL?
Advanced SQL Interview Questions and Answers
- 48. Name different types of case manipulation functions available in SQL.
- 49. What are local and global variables and their differences?
- 50. Name the function which is used to remove spaces at the end of a string?
- 51. What is the difference between TRUNCATE and DROP statements?
- 52. Which operator is used in queries for pattern matching?
- 53. Define SQL Order by the statement?
- 54. Explain SQL Having statement?
55. Explain SQL AND OR statement with an example?
- 56. Define BETWEEN statements in SQL?
- 57. Why do we use Commit and Rollback commands?
- 58. What are ACID properties?
- 59. Are NULL values the same as zero or a blank space?
- 60. What is the need for group functions in SQL?
- 61. What is the need for a MERGE statement?
- 62. How can you fetch common records from two tables?
- 63. What are the advantages of PL/SQL functions?
- 64. What is the SQL query to display the current date?
- 65. What are Nested Triggers?
- 66. How to find the available constraint information in the table?
- 67. How do we avoid getting duplicate entries in a query without using the distinct keyword?
- 68. The difference between NVL and NVL2 functions?
- 69. What is the difference between COALESCE() & ISNULL()?
- 70. Name the operator which is used in the query for appending two strings?
SQL is a standard database language used for accessing and manipulating data in databases. It stands for Structured Query Language and was developed by IBM Computer Scientists in the 1970s. By executing queries, SQL can create, update, delete, and retrieve data in databases like MySQL, Oracle, PostgreSQL, etc. Overall, SQL is a query language that communicates with databases.
In this article, we cover 70+ SQL Interview Questions with answers asked in SQL developer interviews at MAANG and other high-paying companies. Whether you are a fresher or an experienced professional with 2, 5, or 10 years of experience, this article gives you all the confidence you need to ace your next SQL interview.

Table of Content
1. What is SQL?
SQL stands for Structured Query Language. It is a language used to interact with the database, i.e to create a database, to create a table in the database, to retrieve data or update a table in the database, etc. SQL is an ANSI(American National Standards Institute) standard. Using SQL, we can do many things. For example – we can execute queries, we can insert records into a table, can update records, can create a database, can create a table, can delete a table, etc.
2. What is a database?
A Database is defined as a structured form of data storage in a computer or a collection of data in an organized manner and can be accessed in various ways. It is also the collection of schemas, tables, queries, views, etc. Databases help us with easily storing, accessing, and manipulating data held on a computer. The Database Management System allows a user to interact with the database.
3. Does SQL support programming language features?
It is true that SQL is a language, but it does not support programming as it is not a programming language, it is a command language. We do not have conditional statements in SQL like for loops or if..else, we only have commands which we can use to query, update, delete, etc. data in the database. SQL allows us to manipulate data in a database.
4. What is the difference between CHAR and VARCHAR2 datatype in SQL?
Both of these data types are used for characters, but varchar2 is used for character strings of variable length, whereas char is used for character strings of fixed length. For example , if we specify the type as char(5) then we will not be allowed to store a string of any other length in this variable, but if we specify the type of this variable as varchar2(5) then we will be allowed to store strings of variable length. We can store a string of length 3 or 4 or 2 in this variable.
5. What do you mean by data definition language?
Data definition language or DDL allows to execution of queries like CREATE, DROP, and ALTER. That is those queries that define the data.
Data manipulation Language or DML is used to access or manipulate data in the database. It allows us to perform the below-listed functions:
- Insert data or rows in a database
- Delete data from the database
- Retrieve or fetch data
- Update data in a database.
7. What is the view in SQL?
Views in SQL are a kind of virtual table. A view also has rows and columns as they are on a real table in the database. We can create a view by selecting fields from one or more tables present in the database. A View can either have all the rows of a table or specific rows based on certain conditions.
The CREATE VIEW statement of SQL is used for creating views.
Basic Syntax:
8. What do you mean by foreign key?
A Foreign key is a field that can uniquely identify each row in another table. And this constraint is used to specify a field as a Foreign key. That is this field points to the primary key of another table. This usually creates a kind of link between the two tables.
Consider the two tables as shown below:
| O_ID | ORDER_NO | C_ID |
|---|---|---|
| 1 | 2253 | 3 |
| 2 | 3325 | 3 |
| 3 | 4521 | 2 |
| 4 | 8532 | 1 |
| C_ID | NAME | ADDRESS |
|---|---|---|
| 1 | RAMESH | DELHI |
| 2 | SURESH | NOIDA |
| 3 | DHARMESH | GURGAON |
As we can see clearly, that the field C_ID in the Orders table is the primary key in the Customers’ table, i.e. it uniquely identifies each row in the Customers table. Therefore, it is a Foreign Key in the Orders table.
9. What are table and Field?
Table: A table has a combination of rows and columns. Rows are called records and columns are called fields. In MS SQL Server, the tables are being designated within the database and schema names.
Field: In DBMS, a database field can be defined as – a single piece of information from a record.
10. What is the primary key?
A Primary Key is one of the candidate keys. One of the candidate keys is selected as the most important and becomes the primary key. There cannot be more than one primary key in a table.
11. What is a Default constraint?
The DEFAULT constraint is used to fill a column with default and fixed values. The value will be added to all new records when no other value is provided.
12. What is normalization?
It is a process of analyzing the given relation schemas based on their functional dependencies and primary keys to achieve the following desirable properties:
- Minimizing Redundancy
- Minimizing the Insertion, Deletion, And Update Anomalies
Relation schemas that do not meet the properties are decomposed into smaller relation schemas that could meet desirable properties.
13. What is Denormalization?
Denormalization is a database optimization technique in which we add redundant data to one or more tables. This can help us avoid costly joins in a relational database. Note that denormalization does not mean not doing normalization. It is an optimization technique that is applied after normalization.
In a traditional normalized database, we store data in separate logical tables and attempt to minimize redundant data. We may strive to have only one copy of each piece of data in the database.
14. What is a query?
An SQL query is used to retrieve the required data from the database. However, there may be multiple SQL queries that yield the same results but with different levels of efficiency. An inefficient query can drain the database resources, reduce the database speed or result in a loss of service for other users. So it is very important to optimize the query to obtain the best database performance.
15. What is a subquery?
In SQL, a Subquery can be simply defined as a query within another query. In other words, we can say that a Subquery is a query that is embedded in the WHERE clause of another SQL query.
16. What are the different operators available in SQL?
There are three operators available in SQL namely:
- Arithmetic Operators
- Logical Operators
- Comparison Operators
17. What is a Constraint?
Constraints are the rules that we can apply to the type of data in a table. That is, we can specify the limit on the type of data that can be stored in a particular column in a table using constraints. For more details please refer to SQL|Constraints article.
18. What is Data Integrity?
Data integrity is defined as the data contained in the database being both correct and consistent. For this purpose, the data stored in the database must satisfy certain types of procedures (rules). The data in a database must be correct and consistent. So, data stored in the database must satisfy certain types of procedures (rules). DBMS provides different ways to implement such types of constraints (rules). This improves data integrity in a database. For more details please refer difference between data security and data integrity article.
19. What is Auto Increment?
Sometimes, while creating a table, we do not have a unique identifier within the table, hence we face difficulty in choosing Primary Key. So as to resolve such an issue, we’ve to manually provide unique keys to every record, but this is often also a tedious task. So we can use the Auto-Increment feature that automatically generates a numerical Primary key value for every new record inserted. The Auto Increment feature is supported by all the Databases. For more details please refer SQL Auto Increment article.
20. What is MySQL collation?
A MySQL collation is a well-defined set of rules which are used to compare characters of a particular character set by using their corresponding encoding. Each character set in MySQL might have more than one collation, and has, at least, one default collation. Two character sets cannot have the same collation. For more details please refer What are collation and character set in MySQL? article.
21. What are user-defined functions?
We can use User-defined functions in PL/SQL or Java to provide functionality that is not available in SQL or SQL built-in functions. SQL functions and User-defined functions can appear anywhere, that is, wherever an expression occurs.
For example, it can be used in:
- Select a list of SELECT statements.
- Condition of the WHERE clause.
- CONNECT BY, ORDER BY, START WITH, and GROUP BY
- The VALUES clause of the INSERT statement.
- The SET clause of the UPDATE statement.
22. What are all types of user-defined functions?
User-Defined Functions allow people to define their own T-SQL functions that can accept 0 or more parameters and return a single scalar data value or a table data type. Different Kinds of User-Defined Functions created are:
1. Scalar User-Defined Function A Scalar user-defined function returns one of the scalar data types. Text, image, and timestamp data types are not supported. These are the type of user-defined functions that most developers are used to in other programming languages. You pass in 0 to many parameters and you get a return value.
2. Inline Table-Value User-Defined Function An Inline Table-Value user-defined function returns a table data type and is an exceptional alternative to a view as the user-defined function can pass parameters into a T-SQL select command and, in essence, provide us with a parameterized, non-updateable view of the underlying tables.
3. Multi-statement Table-Value User-Defined Function A Multi-Statement Table-Value user-defined function returns a table and is also an exceptional alternative to a view, as the function can support multiple T-SQL statements to build the final result where the view is limited to a single SELECT statement. Also, the ability to pass parameters into a TSQL select command or a group of them gives us the capability to, in essence, create a parameterized, non-updateable view of the data in the underlying tables. Within the create function command you must define the table structure that is being returned. After creating this type of user-defined function, it can be used in the FROM clause of a T-SQL command, unlike the behavior found when using a stored procedure which can also return record sets.
23. What is a stored procedure?
Stored Procedures are created to perform one or more DML operations on databases. It is nothing but a group of SQL statements that accepts some input in the form of parameters and performs some task and may or may not return a value. For more details please refer to our Stored procedures in the SQL article.
24. What are aggregate and scalar functions?
For doing operations on data SQL has many built-in functions, they are categorized into two categories and further sub-categorized into seven different functions under each category. The categories are:
- Aggregate functions: These functions are used to do operations from the values of the column and a single value is returned.
- Scalar functions: These functions are based on user input, these too return a single value.
For more details, please read the SQL | Functions (Aggregate and Scalar Functions) article.
25. What is an ALIAS command?
Aliases are the temporary names given to a table or column for the purpose of a particular SQL query. It is used when the name of a column or table is used other than its original name, but the modified name is only temporary.
- Aliases are created to make table or column names more readable.
- The renaming is just a temporary change and the table name does not change in the original database.
- Aliases are useful when table or column names are big or not very readable.
- These are preferred when there is more than one table involved in a query.
For more details, please read the SQL | Aliases article.
26. What are Union, minus, and Interact commands?
Set Operations in SQL eliminate duplicate tuples and can be applied only to the relations which are union compatible. Set Operations available in SQL are :
- Set Intersection
- Set Difference
UNION Operation: This operation includes all the tuples which are present in either of the relations. For example: To find all the customers who have a loan or an account or both in a bank.
The union operation automatically eliminates duplicates. If all the duplicates are supposed to be retained, UNION ALL is used in place of UNION.
INTERSECT Operation: This operation includes the tuples which are present in both of the relations. For example: To find the customers who have a loan as well as an account in the bank:
The Intersect operation automatically eliminates duplicates. If all the duplicates are supposed to be retained, INTERSECT ALL is used in place of INTERSECT.
EXCEPT for Operation: This operation includes tuples that are present in one relationship but should not be present in another relationship. For example: To find customers who have an account but no loan at the bank:
The Except operation automatically eliminates the duplicates. If all the duplicates are supposed to be retained, EXCEPT ALL is used in place of EXCEPT.
27. What is a T-SQL?
T-SQL is an abbreviation for Transact Structure Query Language. It is a product by Microsoft and is an extension of SQL Language which is used to interact with relational databases. It is considered to perform best with Microsoft SQL servers. T-SQL statements are used to perform the transactions to the databases. T-SQL has huge importance since all the communications with an instance of an SQL server are done by sending Transact-SQL statements to the server. Users can also define functions using T-SQL.
Types of T-SQL functions are :
- Aggregate functions.
- Ranking functions. There are different types of ranking functions.
- Rowset function.
- Scalar functions.
28. What is ETL in SQL?
ETL is a process in Data Warehousing and it stands for Extract , Transform, and Load . It is a process in which an ETL tool extracts the data from various data source systems, transforms it in the staging area, and then finally, loads it into the Data Warehouse system. These are three database functions that are incorporated into one tool to pull data out from one database and put data into another database.
29. How to copy tables in SQL?
Sometimes, in SQL, we need to create an exact copy of an already defined (or created) table. MySQL enables you to perform this operation. Because we may need such duplicate tables for testing the data without having any impact on the original table and the data stored in it.
For more details, Please read Cloning Table in the MySQL article.
30. What is SQL injection?
SQL injection is a technique used to exploit user data through web page inputs by injecting SQL commands as statements. Basically, these statements can be used to manipulate the application’s web server by malicious users.
- SQL injection is a code injection technique that might destroy your database.
- SQL injection is one of the most common web hacking techniques.
- SQL injection is the placement of malicious code in SQL statements, via web page input.
For more details, please read the SQL | Injection article.
31. Can we disable a trigger? If yes, how?
Yes, we can disable a trigger in PL/SQL. If consider temporarily disabling a trigger and one of the following conditions is true:
- An object that the trigger references is not available.
- We must perform a large data load and want it to proceed quickly without firing triggers.
- We are loading data into the table to which the trigger applies.
- We disable a trigger using the ALTER TRIGGER statement with the DISABLE option.
- We can disable all triggers associated with a table at the same time using the ALTER TABLE statement with the DISABLE ALL TRIGGERS option.
32. What are the differences between SQL and PL/SQL?
Some common differences between SQL and PL/SQL are as shown below:
| SQL | PL/SQL |
|---|---|
| SQL is a query execution or commanding language | PL/SQL is a complete programming language |
| SQL is a data-oriented language. | PL/SQL is a procedural language |
| SQL is very declarative in nature. | PL/SQL has a procedural nature. |
| It is used for manipulating data. | It is used for creating applications. |
| We can execute one statement at a time in SQL | We can execute blocks of statements in PL/SQL |
| SQL tells databases, what to do? | PL/SQL tells databases how to do. |
| We can embed SQL in PL/SQL | We can not embed PL/SQL in SQL |
33. What is the difference between BETWEEN and IN operators in SQL?
BETWEEN: The BETWEEN operator is used to fetch rows based on a range of values. For example,
This query will select all those rows from the table. Students where the value of the field ROLL_NO lies between 20 and 30. IN: The IN operator is used to check for values contained in specific sets. For example,
This query will select all those rows from the table Students where the value of the field ROLL_NO is either 20 or 21 or 23.
34. Write an SQL query to find the names of employees starting with ‘A’.
The LIKE operator of SQL is used for this purpose. It is used to fetch filtered data by searching for a particular pattern in the where clause. The Syntax for using LIKE is,
SELECT column1,column2 FROM table_name WHERE column_name LIKE pattern; LIKE: operator name pattern: exact value extracted from the pattern to get related data in result set.
The required query is:
You may refer to this article WHERE clause for more details on the LIKE operator.
35. What is the difference between primary key and unique constraints?
The primary key cannot have NULL values, the unique constraints can have NULL values. There is only one primary key in a table, but there can be multiple unique constraints. The primary key creates the clustered index automatically but the unique key does not.
36. What is a join in SQL? What are the types of joins?
An SQL Join statement is used to combine data or rows from two or more tables based on a common field between them. Different types of Joins are:
- INNER JOIN : The INNER JOIN keyword selects all rows from both tables as long as the condition is satisfied. This keyword will create the result set by combining all rows from both the tables where the condition satisfies i.e. the value of the common field will be the same.
- LEFT JOIN : This join returns all the rows of the table on the left side of the join and matching rows for the table on the right side of the join. For the rows for which there is no matching row on the right side, the result set will be null. LEFT JOIN is also known as LEFT OUTER JOIN
- RIGHT JOIN : RIGHT JOIN is similar to LEFT JOIN. This join returns all the rows of the table on the right side of the join and matching rows for the table on the left side of the join. For the rows for which there is no matching row on the left side, the result set will contain null. RIGHT JOIN is also known as RIGHT OUTER JOIN.
- FULL JOIN : FULL JOIN creates the result set by combining the results of both LEFT JOIN and RIGHT JOIN. The result set will contain all the rows from both tables. For the rows for which there is no matching, the result set will contain NULL values.
37. What is an index?
A database index is a data structure that improves the speed of data retrieval operations on a database table at the cost of additional writes and the use of more storage space to maintain the extra copy of data. Data can be stored only in one order on a disk. To support faster access according to different values, a faster search like a binary search for different values is desired. For this purpose, indexes are created on tables. These indexes need extra space on the disk, but they allow faster search according to different frequently searched values.
38. What is the On Delete cascade constraint?
An ‘ON DELETE CASCADE’ constraint is used in MySQL to delete the rows from the child table automatically when the rows from the parent table are deleted. For more details, please read MySQL – On Delete Cascade constraint article.
39. Explain WITH clause in SQL?
The WITH clause provides a way relationship of defining a temporary relationship whose definition is available only to the query in which the with clause occurs. SQL applies predicates in the WITH clause after groups have been formed, so aggregate functions may be used.
40. What are all the different attributes of indexes?
The indexing has various attributes:
- Access Types : This refers to the type of access such as value-based search, range access, etc.
- Access Time : It refers to the time needed to find a particular data element or set of elements.
- Insertion Time : It refers to the time taken to find the appropriate space and insert new data.
- Deletion Time : Time is taken to find an item and delete it as well as update the index structure.
- Space Overhead : It refers to the additional space required by the index.
41. What is a Cursor?
The cursor is a Temporary Memory or Temporary Work Station. It is Allocated by Database Server at the Time of Performing DML operations on the Table by the User. Cursors are used to store Database Tables.
42. Write down various types of relationships in SQL?
There are various relationships, namely:
- One-to-One Relationship.
- One to Many Relationships.
- Many to One Relationship.
- Self-Referencing Relationship.
43. What is a trigger?
The trigger is a statement that a system executes automatically when there is any modification to the database. In a trigger, we first specify when the trigger is to be executed and then the action to be performed when the trigger executes. Triggers are used to specify certain integrity constraints and referential constraints that cannot be specified using the constraint mechanism of SQL.
44. What is the difference between SQL DELETE and SQL TRUNCATE commands?
|
|
|
|---|---|
| The DELETE statement removes rows one at a time and records an entry in the transaction log for each deleted row. | TRUNCATE TABLE removes the data by deallocating the data pages used to store the table data and records only the page deallocations in the transaction log. |
| DELETE command is slower than the identityTRUNCATE command. | While the TRUNCATE command is faster than the DELETE command. |
| To use Delete you need DELETE permission on the table. | To use Truncate on a table we need at least ALTER permission on the table. |
| The identity of the column retains the identity after using DELETE Statement on the table. | The identity of the column is reset to its seed value if the table contains an identity column. |
| The delete can be used with indexed views. | Truncate cannot be used with indexed views. |
45. What is the difference between Cluster and Non-Cluster Index?
| CLUSTERED INDEX | NON-CLUSTERED INDEX |
|---|---|
| The clustered index is faster. | The non-clustered index is slower. |
| The clustered index requires less memory for operations. | The non-Clustered index requires more memory for operations. |
| In a clustered index, the index is the main data. | In the Non-Clustered index, the index is a copy of data. |
| A table can have only one clustered index. | A table can have multiple non-clustered indexes. |
| The clustered index has an inherent ability to store data on the disk. | The non-Clustered index does not have the inherent ability to store data on the disk. |
| Clustered indexes store pointers to block not data. | The non-Clustered index store both value and a pointer to the the the actual row that holds data. |
| In Clustered index leaf nodes are actual data itself. | In a Non-Clustered index, leaf nodes are not the actual data itself rather they only contain included columns. |
| In the Clustered index, the Clustered key defines the order of data within the table. | In the Non-Clustered index, the index key defines the order of data within the index. |
| A Clustered index is a type of index in which table records are physically reordered to match the index. | A Non-Clustered index is a special type of index in which the logical order of index does not match the physical stored order of the rows on the disk. |
For more details please refer Difference between Clustered index and the No-Clustered index article.
46. What is a Live Lock?
Livelock occurs when two or more processes continually repeat the same interaction in response to changes in the other processes without doing any useful work. These processes are not in the waiting state, and they are running concurrently. This is different from a deadlock because in a deadlock all processes are in the waiting state.
47. What is Case WHEN in SQL?
Control statements form an important part of most languages since they control the execution of other sets of statements. These are found in SQL too and should be exploited for uses such as query filtering and query optimization through careful selection of tuples that match our requirements. In this post, we explore the Case-Switch statement in SQL. The CASE statement is SQL’s way of handling if/then logic.
CASE case_value WHEN when_value THEN statement_list [WHEN when_value THEN statement_list] … [ELSE statement_list]END CASE
CASE WHEN search_condition THEN statement_list [WHEN search_condition THEN statement_list] … [ELSE statement_list]END CASE
For more details, please read the SQL | Case Statement article.
48. Name different types of case manipulation functions available in SQL.
There are three types of case manipulation functions available in SQL. They are,
- LOWER : The purpose of this function is to return the string in lowercase. It takes a string as an argument and returns the string by converting it into lower case. Syntax:
LOWER(‘string’)
- UPPER : The purpose of this function is to return the string in uppercase. It takes a string as an argument and returns the string by converting it into uppercase. Syntax:
UPPER(‘string’)
- INITCAP : The purpose of this function is to return the string with the first letter in uppercase and the rest of the letters in lowercase. Syntax:
INITCAP(‘string’)
49. What are local and global variables and their differences?
Global Variable: In contrast, global variables are variables that are defined outside of functions. These variables have global scope, so they can be used by any function without passing them to the function as parameters.
Local Variable: Local variables are variables that are defined within functions. They have local scope, which means that they can only be used within the functions that define them.
50. Name the function which is used to remove spaces at the end of a string?
In SQL, the spaces at the end of the string are removed by a trim function.
Trim(s) , Where s is a any string.
51. What is the difference between TRUNCATE and DROP statements?
| SQL DROP | TRUNCATE |
|---|---|
| The DROP command is used to remove the table definition and its contents. | Whereas the TRUNCATE command is used to delete all the rows from the table. |
| In the DROP command, table space is freed from memory. | While the TRUNCATE command does not free the table space from memory. |
| DROP is a DDL(Data Definition Language) command. | Whereas the TRUNCATE is also a DDL(Data Definition Language) command. |
| In the DROP command, a view of the table does not exist. | While in this command, a view of the table exists. |
| In the DROP command, integrity constraints will be removed. | While in this command, integrity constraints will not be removed. |
| In the DROP command, undo space is not used. | While in this command, undo space is used but less than DELETE. |
| The DROP command is quick to perform but gives rise to complications. | While this command is faster than DROP. |
For more details, please read the Difference between DROP and TRUNCATE in the SQL article.
52. Which operator is used in queries for pattern matching?
LIKE operator: It is used to fetch filtered data by searching for a particular pattern in the where clause.
SELECT column1,column2 FROM table_name WHERE column_name LIKE pattern; LIKE: operator name
53. Define SQL Order by the statement?
The ORDER BY statement in SQL is used to sort the fetched data in either ascending or descending according to one or more columns.
- By default ORDER BY sorts the data in ascending order.
- We can use the keyword DESC to sort the data in descending order and the keyword ASC to sort in ascending order.
For more details please read SQL | ORDER BY article.
54. Explain SQL Having statement?
HAVING is used to specify a condition for a group or an aggregate function used in the select statement. The WHERE clause selects before grouping. The HAVING clause selects rows after grouping. Unlike the HAVING clause, the WHERE clause cannot contain aggregate functions. See Having vs Where Clause?
In SQL, the AND & OR operators are used for filtering the data and getting precise results based on conditions. The AND and OR operators are used with the WHERE clause.
These two operators are called conjunctive operators .
- AND Operator: This operator displays only those records where both conditions condition 1 and condition 2 evaluate to True.
- OR Operator: This operator displays the records where either one of the conditions condition 1 and condition 2 evaluates to True. That is, either condition1 is True or condition2 is True.
For more details please read the SQL | AND and OR operators article.
56. Define BETWEEN statements in SQL?
The SQL BETWEEN condition allows you to easily test if an expression is within a range of values (inclusive). The values can be text, date, or numbers. It can be used in a SELECT, INSERT, UPDATE, or DELETE statement. The SQL BETWEEN Condition will return the records where the expression is within the range of value1 and value2.
For more details please read SQL | Between & I operator article.
57. Why do we use Commit and Rollback commands?
| COMMIT | ROLLBACK |
|---|---|
| COMMIT permanently saves the changes made by the current transaction. | ROLLBACK undo the changes made by the current transaction. |
| The transaction can not undo changes after COMMIT execution. | Transaction reaches its previous state after ROLLBACK. |
| When the transaction is successful, COMMIT is applied. | When the transaction is aborted, ROLLBACK occurs. |
For more details please read the Difference between Commit and Rollback in SQL article.
58. What are ACID properties?
A transaction is a single logical unit of work that accesses and possibly modifies the contents of a database. Transactions access data using read-and-write operations. In order to maintain consistency in a database, before and after the transaction, certain properties are followed. These are called ACID properties. ACID (Atomicity, Consistency, Isolation, Durability) is a set of properties that guarantee that database transactions are processed reliably. For more details please read ACID properties in the DBMS article.
59. Are NULL values the same as zero or a blank space?
In SQL, zero or blank space can be compared with another zero or blank space. whereas one null may not be equal to another null. null means data might not be provided or there is no data.
60. What is the need for group functions in SQL?
In database management, group functions, also known as aggregate functions, is a function where the values of multiple rows are grouped together as input on certain criteria to form a single value of more significant meaning.
Various Group Functions
For more details please read the Aggregate functions in the SQL article.
61. What is the need for a MERGE statement?
The MERGE command in SQL is actually a combination of three SQL statements: INSERT, UPDATE, and DELETE . In simple words, the MERGE statement in SQL provides a convenient way to perform all these three operations together which can be very helpful when it comes to handling large running databases. But unlike INSERT, UPDATE, and DELETE statements MERGE statement requires a source table to perform these operations on the required table which is called a target table. For more details please read the SQL | MERGE Statement article.
62. How can you fetch common records from two tables?
The below statement could be used to get data from multiple tables, so, we need to use join to get data from multiple tables.
SELECT tablenmae1.colunmname, tablename2.columnnmae FROM tablenmae1 JOIN tablename2 ON tablenmae1.colunmnam = tablename2.columnnmae ORDER BY columnname;
For more details and examples, please read SQL | SELECT data from the Multiple Tables article.
63. What are the advantages of PL/SQL functions?
The advantages of PL / SQL functions are as follows:
- We can make a single call to the database to run a block of statements. Thus, it improves the performance against running SQL multiple times. This will reduce the number of calls between the database and the application.
- We can divide the overall work into small modules which becomes quite manageable, also enhancing the readability of the code.
- It promotes reusability.
- It is secure since the code stays inside the database, thus hiding internal database details from the application(user). The user only makes a call to the PL/SQL functions. Hence, security and data hiding is ensured.
64. What is the SQL query to display the current date?
CURRENT_DATE returns to the current date. This function returns the same value if it is executed more than once in a single statement, which means that the value is fixed, even if there is a long delay between fetching rows in a cursor.
CURRENT_DATE or CURRENT DATE
65. What are Nested Triggers?
A trigger can also contain INSERT, UPDATE, and DELETE logic within itself, so when the trigger is fired because of data modification it can also cause another data modification, thereby firing another trigger. A trigger that contains data modification logic within itself is called a nested trigger.
66. How to find the available constraint information in the table?
In SQL Server the data dictionary is a set of database tables used to store information about a database’s definition. One can use these data dictionaries to check the constraints on an already existing table and to change them(if possible). For more details please read SQL | Checking Existing Constraint on a table article.
67. How do we avoid getting duplicate entries in a query without using the distinct keyword?
DISTINCT is useful in certain circumstances, but it has drawbacks that it can increase the load on the query engine to perform the sort (since it needs to compare the result set to itself to remove duplicates). We can remove duplicate entries using the following options:
- Remove duplicates using row numbers.
- Remove duplicates using self-Join.
- Remove duplicates using group by.
For more details, please read SQL | Remove duplicates without distinct articles.
68. The difference between NVL and NVL2 functions?
These functions work with any data type and pertain to the use of null values in the expression list. These are all single-row functions i.e. provide one result per row.
NVL(expr1, expr2): In SQL, NVL() converts a null value to an actual value. Data types that can be used are date, character, and number. Data types must match with each other. i.e. expr1 and expr2 must be of the same data type.
NVL (expr1, expr2)
NVL2(expr1, expr2, expr3): The NVL2 function examines the first expression. If the first expression is not null, then the NVL2 function returns the second expression. If the first expression is null, then the third expression is returned i.e. If expr1 is not null, NVL2 returns expr2. If expr1 is null, NVL2 returns expr3. The argument expr1 can have any data type.
NVL2 (expr1, expr2, expr3)
For more details please read SQL general functions | NVL, NVL2, DECODE, COALESCE, NULLIF, LNNVL , and NANVL article.
69. What is the difference between COALESCE() & ISNULL()?
COALESCE(): COALESCE function in SQL returns the first non-NULL expression among its arguments. If all the expressions evaluate to null, then the COALESCE function will return null. Syntax:
SELECT column(s), CAOLESCE(expression_1,….,expression_n)FROM table_name;
ISNULL(): The ISNULL function has different uses in SQL Server and MySQL. In SQL Server, ISNULL() function is used to replace NULL values. Syntax:
SELECT column(s), ISNULL(column_name, value_to_replace)FROM table_name;
For more details, please read the SQL | Null functions article.
70. Name the operator which is used in the query for appending two strings?
In SQL for appending two strings, the ” Concentration operator” is used and its symbol is ” || “.
In conclusion, mastering SQL interview questions is crucial for data analysts, data engineers, and business analysts aiming to excel in their respective fields. This article has provided a comprehensive set of SQL interview questions and answers designed to prepare you thoroughly.
By understanding and practicing these questions, you enhance your ability to tackle the challenges posed in SQL-related interviews effectively, ultimately paving the way for a successful career in data handling and analysis. Remember, each question is an opportunity to demonstrate your analytical prowess and technical expertise, essential traits for any aspiring professional in these critical roles.
Please Login to comment...
Similar reads.
- interview-questions
- placement preparation
Improve your Coding Skills with Practice
What kind of Experience do you want to share?
Download Interview guide PDF
Sql query interview questions, download pdf.
SQL stands for Structured Query Language . Initially, it was named Structured English Query Language (SEQUEL). It is used in relational database management systems to store and manage data (RDMS).
It is a relational database system with standard language. A user can create, read, update, and delete relational databases and tables with it. SQL is the standard database language used by every RDBMS, including MySQL, Informix, Oracle, MS Access, and SQL Server. SQL allows users to query the database using English-like phrases in a variety of ways.
SQL is also distinct from other computer languages because it specifies what the user wants the machine to perform rather than how it should accomplish it. (In more technical terms, SQL is a declarative rather than procedural language.) There are no IF statements in SQL for testing conditions, and no GOTO, DO, or FOR statements for controlling program flow. SQL statements, on the other hand, indicate how a collection of data should be organized, as well as what data should be accessed or added to the database. The DBMS determines the sequence of actions to complete such tasks.
SQL queries are one of the most frequently asked interview questions. You can expect questions ranging from basic SQL queries to complex SQL queries:
- What is Query in SQL?
- Write an SQL query to report all the duplicate emails. You can return the result table in any order.
- Construct a SQL query to provide each player's first login date. You can return the result table in any order.
- Write an SQL query to report all customers who never order anything. You can return the result table in any order.
- Write an SQL query to report the movies with an odd-numbered ID and a description that is not "boring". Return the result table ordered by rating in descending order.
Construct a SQL query to display the names and balances of people who have a balance greater than $10,000. The balance of an account is equal to the sum of the amounts of all transactions involving that account. You can return the result table in any order.
- Write a SQL query that detects managers with at least 5 direct reports from the Employee table.
- Construct an SQL query for the following questions.
So, without any further ado, let us look at the most frequently asked SQL Query Interview Questions and Answers which are categorised into the following:
SQL Query Interview Questions for Freshers
Sql query interview questions for experienced, sql query mcq questions, 1. what is query in sql.
A query is a request for information or data from a database table or set of tables. For example, let us assume that we have a database that stores details about books written by various authors. Now, if we want to know how many books have been written by a particular author, then this question can be referred to as a query that we want to do to the database.
Use cases of SQL:
- SQL is an interactive question language. Users write SQL commands into interactive SQL software to extract information and display them on the screen, making it a useful and simple tool for ad hoc database queries.
- SQL is a database programming language. To access the information in a database, programmers incorporate SQL instructions into their utility packages. This method of database access is used by both user-written packages and database software packages
- SQL is a server/client language. SQL allows personal computer programs to interface with database servers that store shared data through a network. Many well-known enterprise-class apps use this client/server design.
- SQL is a distributed database language. SQL is used in distributed database control systems to help spread data across numerous linked computer structures. Every device's DBMS software program uses SQL to communicate with other systems, issuing requests for information access. Learn More
2. Let us consider the following schema:
Table: person.
| Column Name | Type |
|---|---|
| id | int |
| varchar |
Here, id is the primary key column for this table. Email represents the email id of the person. For the sake of simplicity, we assume that the emails will not contain uppercase letters. Write an SQL query to report all the duplicate emails. You can return the result table in any order.
Input: person table:.
| id | |
|---|---|
| 1 | [email protected] |
| 2 | [email protected] |
| 3 | [email protected] |
| [email protected] |
Explanation: [email protected] is repeated two times.
- Approach 1:
We can first have all the distinct email ids and their respective counts in our result set. For this, we can use the GROUP BY operator to group the tuples by their email id. We will use the COUNT operator to have the total number of a particular email id in the given table. The query for obtaining this resultant set can be written as:
Now, we query in the above resultant query set to find out all the tuples which have an email id count greater than 1. This can be achieved using the following query:
- Approach 2:
The HAVING clause, which is significantly simpler and more efficient, is a more popular technique to add a condition to a GROUP BY. So, we can first group the tuples by the email ids and then have a condition to check if their count is greater than 1, only then do we include it in our result set. So we may change the solution above to this one.
Approach 3:
We can use the concept of joins to solve this problem. We will self-join the Person table with the condition that their email ids should be the same and their ids should be different. Having done this, we just need to count the number of tuples in our resultant set with distinct email ids. For this, we use the DISTINCT operator. This can be achieved using the following query:
3. Let us consider the following schema:
Table: activity.
| Column Name | Type |
|---|---|
| playerId | int |
| deviceId | int |
| eventDate | date |
| gamesplayed | int |
This table's primary key is (playerId, eventDate). The activities of numerous game participants are depicted in this table. Each row indicates a person that logged in and played a particular number of games (perhaps 0) before moving on to another device at a later date. Construct a SQL query to provide each player's first login date. You can return the result table in any order.
Input: activity table:.
| PlayerId | deviceId | eventDate | gamesPlayed |
|---|---|---|---|
| 1 | 2 | 2021-08-09 | 9 |
| 1 | 2 | 2021-04-07 | 3 |
| 2 | 3 | 2021-06-25 | 1 |
| 3 | 1 | 2021-03-02 | 1 |
| 3 | 4 | 2021-07-03 | 3 |
| playerId | firstLogin |
|---|---|
| 1 | 2021-04-07 |
| 2 | 2021-06-25 |
| 3 | 2021-07-03 |
Explanation:
The player with playerId 1 has two login event dates in the example above. However, because the first login event date is 2021-04-07, we display it. Similarly, the first login event date for the player with playerId 2 is 2021-06-25, and the first login event date for the player with playerId 3 is 2021-07-03.
We can first group the tuples by their player_id. Now, we want the most initial date when the player logged in to the game. For this, we can use the MIN operator and find the initial date on which the player logged in. The query can be written as follows:
We can partition the tuples by the player_id and order them by their event_id such that all the tuples having the same player_id are grouped together. We then number every tuple in each of the groups starting with the number 1. Now, we just have to display the event_date for the tuple having row number 1. For this, we use the ROW_NUMBER operator. The SQL query for it can be written as follows:
We follow a similar kind of approach as used in Approach 2. But instead of using the ROW_NUMBER operator, we can use the FIRST_VALUE operator to find the first event_date. The SQL query for it can be written as follows:
4. Given the following schema:
Table: customers.
| Column Name | Type |
|---|---|
| id | int |
| name | varchar |
The primary key column for this table is id. Each row in the table represents a customer's ID and name.
Table: orders.
| Column Name | Type |
|---|---|
| id | int |
| customerId | int |
The primary key column for this table is id. customerId is a foreign key of the ID from the Customers table. The ID of an order and the ID of the customer who placed it are listed in each row of this table. Write an SQL query to report all customers who never order anything. You can return the result table in any order.
Input: customers table:.
| id | name |
|---|---|
| 1 | Ram |
| 2 | Sachin |
| 3 | Rajat |
| 4 | Ankit |
Orders table:
| id | customeId |
|---|---|
| 1 | 2 |
| 2 | 1 |
| Customers |
|---|
| Rajat |
| Ankit |
Explanation: Here, the customers Sachin and Ram have placed an order having order id 1 and 2 respectively. Thus, the customers Rajat and Ankit have never placed an order. So, we print their names in the result set.
In this approach, we first try to find the customers who have ordered at least once. After having found this, we find the customers whose customer Id is not present in the previously obtained result set. This gives us the customers who have not placed a single order yet. The SQL query for it can be written as follows
In this approach, we use the concept of JOIN. We will LEFT JOIN the customer table with the order table based on the condition that id of the customer table must be equal to that of the customer id of the order table. Now, in our joined resultant table, we just need to find those customers whose order id is null. The SQL query for this can be written as follows:
Here, we first create aliases of the tables Customers and Orders with the name ‘c’ and ‘o’ respectively. Having done so, we join them with the condition that o.customerId = c.id. At last, we check for the customers whose o.id is null.
5. Given the following schema:
Table: cinema.
| Column Name | Type |
|---|---|
| id | int |
| movie | varchar |
| description | varchar |
| rating | float |
The primary key for this table is id. Each row includes information about a movie's name, genre, and rating. rating is a float with two decimal digits in the range [0, 10]. Write an SQL query to report the movies with an odd-numbered ID and a description that is not "boring". Return the result table ordered by rating in descending order.
Input: cinema table:.
| id | movie | description | rating |
|---|---|---|---|
| 1 | War | thriller | 8.9 |
| 2 | Dhakkad | action | 2.1 |
| 3 | Gippi | boring | 1.2 |
| 4 | Dangal | wrestling | 8.6 |
| 5 | P.K. | Sci-Fi | 9.1 |
| id | movie | description | rating |
|---|---|---|---|
| 5 | P.K. | Sci-Fi | 9.1 |
| 1 | War | thriller | 8.9 |
Explanation:
There are three odd-numbered ID movies: 1, 3, and 5. We don't include the movie with ID = 3 in the answer because it's boring. We put the movie with id 5 at the top since it has the highest rating of 9.1.
This question has a bit of ambiguity on purpose. You should ask the interviewer whether we need to check for the description to exactly match “boring” or we need to check if the word “boring” is present in the description. We have provided solutions for both cases.
- Approach 1 (When the description should not be exactly “boring” but can include “boring” as a substring):
In this approach, we use the MOD operator to check whether the id of a movie is odd or not. Now, for all the odd-numbered id movies, we check if its description is not boring. At last, we sort the resultant data according to the descending order of the movie rating. The SQL query for this can be written as follows:
- Approach 2 (When the description should not even contain “boring” as a substring in our resultant answer):
In this approach, we use the LIKE operator to match the description having “boring” as a substring. We then use the NOT operator to eliminate all those results. For the odd-numbered id, we check it similarly as done in the previous approach. Finally, we order the result set according to the descending order of the movie rating. The SQL query for it can be written as follows:
- Software Dev
- Data Science
6. Consider the following schema:
Table: users.
| Column Name | Type |
|---|---|
| account_number | int |
| name | varchar |
The account is the primary key for this table. Each row of this table contains the account number of each user in the bank. There will be no two users having the same name in the table.
table: transactions.
| Column Name | Type |
|---|---|
| trans_id | int |
| account_number | int |
| amount | int |
| transacted_on | date |
trans_id is the primary key for this table. Each row of this table contains all changes made to all accounts. The amount is positive if the user received money and negative if they transferred money. All accounts start with a balance of 0.
Input: users table:.
| Account_number | name |
|---|---|
| 12300001 | Ram |
| 12300002 | Tim |
| 12300003 | Shyam |
Transactions table:
| trans_id | account_number | amount | transacted_on |
|---|---|---|---|
| 1 | 12300001 | 8000 | 2022-03-01 |
| 2 | 12300001 | 8000 | 2022-03-01 |
| 3 | 12300001 | -3000 | 2022-03-02 |
| 4 | 12300002 | 4000 | 2022-03-12 |
| 5 | 12300003 | 7000 | 2022-02-07 |
| 6 | 12300003 | 7000 | 2022-03-07 |
| 7 | 12300003 | -4000 | 2022-03-11 |
| name | balance |
|---|---|
| Ram | 13000 |
- Ram's balance is (8000 + 8000 - 3000) = 11000.
- Tim's balance is 4000.
- Shyam's balance is (7000 + 7000 - 4000) = 10000.
In this approach, we first create aliases of the given two tables' users and transactions. We can natural join the two tables and then group them by their account number. Next, we use the SUM operator to find the balance of each of the accounts after all the transactions have been processed. The SQL query for this can be written as follows:
7. Given the following schema:
Table: employee.
| Column Name | Type |
|---|---|
| id | int |
| name | varcahar |
| department | varchar |
| managerId | int |
All employees, including their managers, are present at the Employee table. There is an Id for each employee, as well as a column for the manager's Id. Write a SQL query that detects managers with at least 5 direct reports from the Employee table.
| Id | Name | Department | ManagerId |
|---|---|---|---|
| 201 | Ram | A | null |
| 202 | Naresh | A | 201 |
| 203 | Krishna | A | 201 |
| 204 | Vaibhav | A | 201 |
| 205 | Jainender | A | 201 |
| 206 | Sid | B | 201 |
| Name |
|---|
| Ram |
In this problem, we first find all the manager ids who have more than 5 employees under them. Next, we find all the employees having the manager id present in the previously obtained manager id set.
The SQL query for this can be written as follows:
8. Consider the following table schema:
Construct an sql query to retrieve duplicate records from the employee table..
| Column Name | Type |
|---|---|
| id | int |
| fname | varchar |
| lname | varchar |
| department | varchar |
| projectId | varchar |
| address | varchar |
| dateofbirth | varchar |
| gender | varchar |
Table: Salary
| Column Name | Type |
|---|---|
| id | int |
| position | varchar |
| dateofJoining | varchar |
| salary | varchar |
Now answer the following questions:
1. Construct an SQL query that retrieves the fname in upper case from the Employee table and uses the ALIAS name as the EmployeeName in the result.
2. Construct an SQL query to find out how many people work in the "HR" department
3. Construct an SQL query to retrieve the first four characters of the ‘lname’ column from the Employee table.
4. Construct a new table with data and structure that are copied from the existing table ‘Employee’ by writing a query. The name of the new table should be ‘SampleTable’.
5. Construct an SQL query to find the names of employees whose first names start with "S".
6. Construct an SQL query to count the number of employees grouped by gender whose dateOfBirth is between 01/03/1975 and 31/12/1976.
7. Construct an SQL query to retrieve all employees who are also managers.
8. Construct an SQL query to retrieve the employee count broken down by department and ordered by department count in ascending manner.
9. Construct an SQL query to retrieve duplicate records from the Employee table.
1. Consider the following Schema:
Table: tree.
| Column Name | Type |
|---|---|
| id | int |
| parent_id | int |
Here, id is the primary key column for this table. id represents the unique identity of a tree node and parent_id represents the unique identity of the parent of the current tree node. The id of a node and the id of its parent node in a tree are both listed in each row of this table. There is always a valid tree in the given structure.
Every node in the given tree can be categorized into one of the following types:, 1. "leaf": when the tree node is a leaf node, we label it as “leaf”, 2. "root": when the tree node is a root node, we label it as “root”, 3. "inner": when the tree node is an inner node, we label it as “inner”, write a sql query to find and return the type of each of the nodes in the given tree. you can return the result in any order. .

Input: Tree Table
| id | parent_id |
|---|---|
| 1 | null |
| 2 | 1 |
| 3 | 1 |
| 4 | 3 |
| 5 | 2 |
| id | type |
|---|---|
| 1 | Root |
| 2 | Inner |
| 3 | Inner |
| 4 | Leaf |
| 5 | Leaf |
- Because node 1’s parent node is null, and it has child nodes 2 and 3, Node 1 is the root node.
- Because node 2 and node 3 have parent node 1 and child nodes 5 and 4 respectively, Node 2 and node 3 are inner nodes.
- Because nodes 4 and 5 have parent nodes but no child nodes, nodes 4, and 5 are leaf nodes.
Approach 1:
In this approach, we subdivide our problem of categorizing the type of each of the nodes in the tree. We first find all the root nodes and add them to our resultant set with the type “root”. Then, we find all the leaf nodes and add them to our resultant set with the type “leaf”. Similarly, we find all the inner nodes and add them to our resultant set with the type “inner”. Now let us look at the query for finding each of the node types.
- For root nodes:
Here, we check if the parent_id of the node is null, then we assign the type of node as ‘Root’ and include it in our result set.
- For leaf nodes:
Here, we first find all the nodes that have a child node. Next, we check if the current node is present in the set of root nodes. If present, it cannot be a leaf node and we eliminate it from our answer set. We also check that the parent_id of the current node is not null. If both the conditions satisfy then we include it in our answer set.
- For inner nodes:
Here, we first find all the nodes that have a child node. Next, we check if the current node is present in the set of root nodes. If not present, it cannot be an inner node and we eliminate it from our answer set. We also check that the parent_id of the current node is not null. If both the conditions satisfy then we include it in our answer set.
At last, we combine all three resultant sets using the UNION operator. So, the final SQL query is as follows:
In this approach, we use the control statement CASE. This simplifies our query a lot from the previous approach. We first check if a node falls into the category of “Root”. If the node does not satisfy the conditions of a root node, it implies that the node will either be a “Leaf” node or an “Inner” node. Next, we check if the node falls into the category of “Inner” node. If it is not an “Inner” node, there is only one option left, which is the “Leaf” node.
The SQL query for this approach can be written as follows:
In this approach, we follow a similar logic as discussed in the previous approach. However, we will use the IF operator instead of the CASE operator. The SQL query for this approach can be written as follows:
2. Consider the following schema:
Table: seat.
| Column Name | type |
|---|---|
| id | int |
| student | varchar |
The table contains a list of students. Every tuple in the table consists of a seat id along with the name of the student. You can assume that the given table is sorted according to the seat id and that the seat ids are in continuous increments. Now, the class teacher wants to swap the seat id for alternate students in order to give them a last-minute surprise before the examination. You need to write a query that swaps alternate students' seat id and returns the result. If the number of students is odd, you can leave the seat id for the last student as it is.
| id | student |
|---|---|
| 1 | Ram |
| 2 | Shyam |
| 3 | Vaibhav |
| 4 | Govind |
| 5 | Krishna |
For the same input, the output is:
| id | student |
|---|---|
| 1 | Shyam |
| 2 | Ram |
| 3 | Govind |
| 4 | Vaibhav |
| 5 | Krishna |
In this approach, first we count the total number of students. Having done so, we consider the case when the seat id is odd but is not equal to the total number of students. In this case, we simply increment the seat id by 1. Next, we consider the case when the seat id is odd but is equal to the total number of students. In this case, the seat id remains the same. At last, we consider the case when the seat id is even. In this case, we decrement the seat id by 1.
In this approach, we use the ROW_NUMBER operator. We increment the id for the odd-numbered ids by 1 and decrement the even-numbered ids by 1. We then sort the tuples, according to the id values. Next, we assign the row number as the id for the sorted tuples. The SQL query for this approach can be written as follows:
3. Given the following schema:
| Column Name | type |
|---|---|
| id | int |
| name | varchar |
| salary | int |
| departmentId | int |
id is the primary key column for this table. departmentId is a foreign key of the ID from the Department table. Each row of this table indicates the ID, name, and salary of an employee. It also contains the ID of their department.
Table: department.
| Column Name | type |
|---|---|
| id | int |
| name | varchar |
id is the primary key column for this table. Each row of this table indicates the ID of a department and its name. The executives of an organization are interested in seeing who earns the most money in each department. A high earner in a department is someone who earns one of the department's top three unique salaries.
Construct a sql query to identify the high-earning employees in each department. you can return the result table in any order., input: employee table:.
| id | name | salary | departmentId |
|---|---|---|---|
| 1 | Ram | 85000 | 1 |
| 2 | Divya | 80000 | 2 |
| 3 | Tim | 60000 | 2 |
| 4 | Kim | 90000 | 1 |
| 5 | Priya | 69000 | 1 |
| 6 | Saket | 85000 | 1 |
| 7 | Will | 70000 | 1 |
Department table:
| id | name |
|---|---|
| 1 | Marketing |
| 2 | HR |
| Department | Employee | Salary |
|---|---|---|
| Marketing | Kim | 90000 |
| Marketing | Ram | 85000 |
| Marketing | Saket | 85000 |
| Marketing | Will | 70000 |
| HR | Divya | 80000 |
| HR | Tim | 60000 |
- Kim has the greatest unique income in the Marketing department - Ram and Saket have the second-highest unique salary.
- Will has the third-highest unique compensation.
In the HR department:
- Divya has the greatest unique income.
- Tim earns the second-highest salary.
- Because there are only two employees, there is no third-highest compensation.
In this approach, let us first assume that all the employees are from the same department. So let us first figure out how we can find the top 3 high-earner employees. This can be done by the following SQL query:
Here, we have created two aliases for the Employee table. For every tuple of the emp1 alias, we compare it with all the distinct salaries to find out how many salaries are less than it. If the number is less than 3, it falls into our answer set.
Next, we need to join the Employee table with the Department table in order to obtain the high-earner employees department-wise. For this, we run the following SQL command:
Here, we join the Employee table and the Department table based on the department ids in both tables. Also, while finding out the high-earner employees for a specific department, we compare the department ids of the employees as well to ensure that they belong to the same department.
In this approach, we use the concept of the DENSE_RANK function in SQL. We use the DENSE_RANK function and not the RANK function since we do not want the ranking number to be skipped. The SQL query using this approach can be written as follows:
Here, we first run a subquery where we partition the tuples by their department and rank them according to the decreasing order of the salaries of the employees. Next, we select those tuples from this set, whose rank is less than 4.
Table: Stadium
| Column Name | type |
| id | int |
| date_visited | date |
| count_people | int |
date_visited is the primary key for this table. The visit date, the stadium visit ID, and the total number of visitors are listed in each row of this table. No two rows will share the same visit date, and the dates get older as the id gets bigger. Construct a SQL query to display records that have three or more rows of consecutive ids and a total number of people higher than or equal to 100. Return the result table in ascending order by visit date.
Input: stadium table:.
| id | date_visited | count_people |
| 1 | 2022-03-01 | 6 |
| 2 | 2022-03-02 | 102 |
| 3 | 2022-03-03 | 135 |
| 4 | 2022-03-04 | 90 |
| 5 | 2022-03-05 | 123 |
| 6 | 2022-03-06 | 115 |
| 7 | 2022-03-07 | 101 |
| 8 | 2022-03-09 | 235 |
| id | date_visited | count_people |
| 5 | 2022-03-05 | 123 |
| 6 | 2022-03-06 | 115 |
| 7 | 2022-03-07 | 101 |
| 8 | 2022-03-09 | 235 |
The four rows with ids 5, 6, 7, and 8 have consecutive ids and each of them has >= 100 people attended. Note that row 8 was included even though the date_visited was not the next day after row 7.
The rows with ids 2 and 3 are not included because we need at least three consecutive ids.
In this approach, we first create three aliases of the given table and cross-join all of them. We filter the tuples such that the number of people in each of the alias’ should be greater than or equal to 100.
The query for this would be
Now, we have to check for the condition of consecutive 3 tuples. For this, we compare the ids of the three aliases to check if they form a possible triplet with consecutive ids. We do this by the following query:
The above query may contain duplicate triplets. So we remove them by using the DISTINCT operator. The final query becomes as follows:
In this approach, we first filter out all the tuples where the number of people is greater than or equal to 100. Next, for every tuple, we check, if there exist 2 other tuples with ids such that the three ids when grouped together form a consecutive triplet. The SQL query for this approach can be written as follows:
| Column Name | Type |
|---|---|
| id | int |
| company | varchar |
| salary | int |
Here, id is the id of the employee. company is the name of the company he/she is working in. salary is the salary of the employee Construct a SQL query to determine each company's median salary. If you can solve it without utilising any built-in SQL functions, you'll get bonus points.
| Id | Company | Salary |
|---|---|---|
| 1 | Amazon | 1100 |
| 2 | Amazon | 312 |
| 3 | Amazon | 150 |
| 4 | Amazon | 1300 |
| 5 | Amazon | 414 |
| 6 | Amazon | 700 |
| 7 | Microsoft | 110 |
| 8 | Microsoft | 105 |
| 9 | Microsoft | 470 |
| 10 | Microsoft | 1500 |
| 11 | Microsoft | 1100 |
| 12 | Microsoft | 290 |
| 13 | 2000 | |
| 14 | 2200 | |
| 15 | 2200 | |
| 16 | 2400 | |
| 17 | 1000 |
| Id | Company | Salary |
|---|---|---|
| 5 | Amazon | 414 |
| 6 | Amazon | 700 |
| 12 | Microsoft | 290 |
| 9 | Microsoft | 470 |
| 14 | 2200 |
In this approach, we have a subquery where we partition the tuples according to the company name and rank the tuples in the increasing order of salary and id. We also find the count of the total number of tuples in each company and then divide it by 2 in order to find the median tuple. After we have this result, we run an outer query to fetch the median salary and the employee id for each of the companies.
Additional Resources
- SQL Programming
- SQL Cheat Sheet
- SQL Commands
- 10 Best SQL Books
- SQL MCQ With Answers
- SQL Server Interview Questions and Answers
- DBMS Interview Questions and Answers
- SQL Joins Interview Questions and Answers
Which of the following are TCL commands?
Which of the following claims about SQL queries is TRUE?
P: Even if there is no GROUP BY clause in a SQL query, it can have a HAVING clause.
Q: If a SQL query has a GROUP BY clause, it can only have a HAVING clause.
R: The SELECT clause must include all attributes used in the GROUP BY clause.
S: The SELECT clause does not have to include all of the attributes used in the GROUP BY clause.
Following is a database table having the name Loan_Records.
What is the result of the SQL query below?
Consider the table employee(employeeId, name, department, salary) and the two queries Q1 , Q2 below. Assuming that department 5 has more than one employee, and we want to find the employees who get higher salaries than anyone in department 5, which one of the statements is TRUE for any arbitrary employee table?
Given the following statements:
P: A check assertion in SQL can always be used to replace a foreign key declaration.
Q: Assume that there is a table “Sample” with the attributes (p, q, r) where the primary key is (p, q). Given the table definition for the table “Sample”, the following table definition also holds true and valid.
Given the following schema:
employees(employeeId, firstName, lastName, hireDate, departmentId, salary)
departments(departmentId, departmentName, managerId, locationId)
For location ID 100, you are required to display the first names and hire dates of all recent hires in their respective departments. You run the following query for it:
Which of the following options is the correct outcome of the above query?
SQL allows tuples in relations, and correspondingly defines the multiplicity of tuples in the result of joins. Which one of the following queries always gives the same answer as the nested query shown below:
select * from R where a in (select S.a from S)
Consider the relation account (customer, balance), in which the customer is the primary key and no null values exist. Customers should be ranked in order of decreasing balance. The consumer with the highest balance is placed first. Ties are not broken, but ranks are skipped: if two customers have the same balance, they both get rank 1, and rank 2 is not issued.
Consider these statements about Query1 and Query2.
1. Query1 will produce the same row set as Query2 for some but not all databases.
2. Both Query1 and Query2 are correct implementations of the specification
3. Query1 is a correct implementation of the specification but Query2 is not
4. Neither Query1 nor Query2 is a correct implementation of the specification
5. Assigning rank with a pure relational query takes less time than scanning in decreasing balance order assigning ranks using ODBC.
Which of the following option is correct?
Consider the two relations: “enrolled(student, course)” and “paid(student, amount)”. In the relation enrolled(student, course), the primary key is (student, course) whereas in the relation “paid(student, amount)”, the primary key is a student. You can assume that there are no null values and no foreign keys or integrity constraints. Given the following four queries:
Which of the following statements is the most accurate?
The employee information in a company is stored in the relation:
Employee (name, sex, salary, deptName)
Consider the following SQL query
It returns the names of the departments in which
The relation book (title, price) contains the titles and prices of different books. Assuming that no two books have the same price, what does the following SQL query list?
- Privacy Policy

- Practice Questions
- Programming
- System Design
- Fast Track Courses
- Online Interviewbit Compilers
- Online C Compiler
- Online C++ Compiler
- Online Java Compiler
- Online Javascript Compiler
- Online Python Compiler
- Interview Preparation
- Java Interview Questions
- Sql Interview Questions
- Python Interview Questions
- Javascript Interview Questions
- Angular Interview Questions
- Networking Interview Questions
- Selenium Interview Questions
- Data Structure Interview Questions
- Data Science Interview Questions
- System Design Interview Questions
- Hr Interview Questions
- Html Interview Questions
- C Interview Questions
- Amazon Interview Questions
- Facebook Interview Questions
- Google Interview Questions
- Tcs Interview Questions
- Accenture Interview Questions
- Infosys Interview Questions
- Capgemini Interview Questions
- Wipro Interview Questions
- Cognizant Interview Questions
- Deloitte Interview Questions
- Zoho Interview Questions
- Hcl Interview Questions
- Highest Paying Jobs In India
- Exciting C Projects Ideas With Source Code
- Top Java 8 Features
- Angular Vs React
- 10 Best Data Structures And Algorithms Books
- Best Full Stack Developer Courses
- Best Data Science Courses
- Python Commands List
- Data Scientist Salary
- Maximum Subarray Sum Kadane’s Algorithm
- Python Cheat Sheet
- C++ Cheat Sheet
- Javascript Cheat Sheet
- Git Cheat Sheet
- Java Cheat Sheet
- Data Structure Mcq
- C Programming Mcq
- Javascript Mcq
1 Million +

The ML Engineer Insights

How I Aced Machine Learning Interviews: My Personal Playbook
Resources that helped me to prepare for ml interview rounds.

Getting ready for a machine learning interview at a big tech company or startup? It can feel overwhelming with all the different rounds, from testing your broad knowledge to diving deep into specific problems, system design, and coding challenges. When I first started, I felt completely lost and had to dig deep to piece together the right resources.
That’s why I’m writing this article – to share the resources that helped me, so you don’t have to struggle through the similar confusion and can confidently navigate your Machine Learning interviews. 🚀
Note: This article won't cover general software engineering interview rounds like DSA coding or specialized roles like Data Analyst, where the focus is on SQL or data-specific questions.
Let’s get started – but first, a quick disclaimer 1 .

The Four Types of Rounds:
📚 Machine Learning Breadth: This round tests your broad knowledge across various ML topics. I usually spend about 35% of my prep time here.
🔍 Machine Learning Depth: This round requires about 25% of my prep time, focusing on specialized topics and detailed case studies.
🛠️ Machine Learning System Design: This round evaluates your ability to design scalable ML systems. I allocate around 40% of my prep time here.
💻 Machine Learning Coding: In this round, you'll tackle coding challenges around basic algorithms. Since this round is generally rare, I dedicate about 0-10% of my prep time (shared with Breadth).

Note: This breakdown will vary depending on your experience level and background. Adapt your preparation strategy to best fit your needs.
📚 Machine Learning Breadth
This round assesses an engineer's understanding of ML fundamentals across various topics. It's often a rapid-fire session where interviewers may jump between different topics or might ask general questions within an area.
A common mistake is relying solely on online questionnaires. Interviewers often reframe questions, making it essential to understand concepts deeply. For example, I was once asked how to handle imbalanced classes in a user-click dataset (where one class, like user click, is much less common than the other class). I suggested "oversampling," which can distort the dataset distribution and affect the model's accuracy. Instead, with a large dataset, it's better not to change the data distribution.
Topics vary by company. For instance, self-driving car companies may ask computer vision fundamentals for junior or senior roles, while other companies might focus on general ML fundamentals.
Fundamental Topics (All Levels)
Supervised Learning: Classification (Logistic Regression, SVMs, Decision Trees), Regression (Linear and Ridge regression)
Unsupervised Learning: Clustering (k-means, hierarchical, DBSCAN), Dimensionality Reduction, Latent Semantic Analysis (LSA)
Ensemble Methods: Random Forest (Bagging), Gradient Boosting Machines
Deep Learning: Multi-layer Perceptron, CNNs
Model Evaluation Metrics: Classification vs Regression evaluation metrics, Bias vs Variance Tradeoff
Loss Functions: Different types of loss functions, Regularization, Overfitting vs Underfitting
Feature Selection and Importance: Techniques to identify important features like Correlation analysis, recursive feature elimination, Lasso
Statistics: P-values, r-square, regression analysis, Naive Bayes, distributions, maximum likelihood estimation, A/B testing
💡 Highly Recommended Resources General ML: Andrew Ng's Machine Learning Course Towards Data Science: Machine Learning Basics Deep Learning: Udacity's Deep Learning Nanodegree Coursera's Deep Learning Specialization Statistics: Statistics for Machine Learning "The Hundred-Page Machine Learning Book" by Andriy Burkov
Specialized Topics (Senior/Specialized Roles)
Time-Series and Sequential Data:
RNNs, LSTMs, Seq2Seq models: Understanding architectures designed for handling time-dependent and sequential data.
💡 Resources : Good tutorials for RNNs and LSTMs and Seq2Seq model
Natural Language Processing (NLP):
Word Embeddings: Techniques like Word2Vec, GloVe.
Attention Mechanisms and Transformer Models
LLM Fundamentals: Becoming increasingly more relevant.
💡 Great articles : A Dummy’s guide to Word2Vec Transformers and Attention Mechanisms
Computer Vision:
Not an expert on CV. You can consider this course: Udacity Computer Vision Nanodegree .
Reinforcement Learning [Rare]:
Relevant for robotics company roles
💡 Resources : Reinforcement Learning Overview , Tutorial
🚀 Next Steps
Once you understand the fundamentals, practice with sample interview questions, Some good resources for practicing sample questions:
GeeksforGeeks: Machine Learning Interview Questions
GitHub: ML Questions
AIML: Machine Learning Interview questions
🔍 Machine Learning Depth
This round is particularly interesting and the most open-ended of all interview types. It is generally aimed for above entry-level jobs with some experience. The goal of this interview is threefold:
Theoretical and practical understanding of a specific problem space
Designing a valid experiment and analyzing results
Communication skills
Expect interviewers to have a significant background knowledge in this area. While it's challenging to prepare specifically for this round, understanding the general directions it can take can be helpful. Here are some common directions this interview can take:
Past Experience : Discussing your academic or industrial projects and their shortcomings. Be prepared to discuss your projects in detail.
Theoretical Background : Delves into the theoretical aspects of a specialized field, especially if the role requires such specialization.
Some examples of specializations and their helpful resources:
NLP Resource:
Advanced Techniques in NLP
NLP MetaBlog by Pratik Bhavsar
LLMs Overview by Maxime Labonne
Computer Vision Resource :
Coursera: Computer Vision Basics
Reinforcement Learning Resource :
Github: Reinforcement Learning Overview
Learning to Rank Resource:
Towardsdatascience: Introduction to Ranking
Time-Series Forecasting Resource:
Medium: A complete guide to time-series forecasting
🛠️ Machine Learning System Design
This round resembles a typical software engineering system design interview, applying similar principles. You are given a product space (e.g., designing a YouTube recommendation ML system) and asked to define the problem, outline the design process, and communicate your thoughts, including tradeoffs.
Interviewers look for your problem-solving approach, thought process, and high-level design skills. During the interview, you may be asked to dive deeper into specific components. Generally most ML systems can be broken down into 5 critical components. Here’s main focus of each component:
1️⃣ Problem Definition
Clearly define the problem and formulate your hypothesis.
2️⃣ Evaluation Metrics
Understand the difference between model performance metrics and business metrics.
Model Metrics : Precision, Recall, MSE, etc.
Business Metrics : Revenue, number of clicks, number of frauds detected, etc.
3️⃣ Feature and Data
Handle offline and real-time data streaming pipelines and preprocess raw data to create features.
4️⃣ Model Development
Select appropriate models and discuss your rationale behind model choices. Provide details on the training process (one-time vs. recurrent vs. online training).
Evaluation :
Choose evaluation datasets and effectively evaluate model performance.
5️⃣ Inference Service and Deployment
Develop a deployment strategy, including the choice of technologies and ensuring the scalability of the inference service. Discuss your approach for automated deployment, evaluation, and A/B testing.
💡 Highly Recommended Courses Grokking the Machine Learning Interview Machine Learning System Design
💻 Machine Learning Coding
I've only encountered a Machine Learning-specific coding round once. This round is uncommon but more frequently seen in startups. Unless it's explicitly mentioned, I don't typically prepare for it. Always confirm with your recruiter if there will be ML coding questions in any of the rounds. If not, focus your preparation on other sections. If there is a specific ML coding round, reallocate some time from ML breadth to practice coding for a few days. The strategy is simple: merge your ML coding preparation with the fundamentals in ML breadth, practicing coding for basic models.
💡 Helpful Resources Github : 100 Days of ML Code Kaggle : Great platform where people share their code. For example, House Prices Prediction using TFDF AlgoExpert : For visual learners, check out AlgoExpert's ML Coding Questions . I tried it once and found it helpful.
Parting note 🌟
Preparing for machine learning interviews can be a challenging journey, but with the right resources and planning, you can navigate it confidently. Remember, every interview is a learning experience, bringing you one step closer to your dream job. Stay curious, keep learning, and don't hesitate to ask for clarifications from your recruiter. Good luck! 🚀
As a parting note, I want to share few more resources for quick references:
ML Cheatsheet for quick revisions: https://sites.google.com/view/datascience-cheat-sheets
ML Interview book: https://huyenchip.com/ml-interviews-book/ by Chip Huyen
🎉 Good Reads for the weekends
The problem with the problem with popularity bias by Samuel Flender
TinyLlama paper read by Grigory Sapunov
What does it take to be a data professional ? by Josep Ferrer
Poor Communication Blocking Promo? by Raviraj Achar
Is it still worth it for Big Tech ? by Akash Mukherjee
Please let me know if I missed anything in comments. If you like the article, please hit ❤️ button. Consider subscribing if you haven’t already.
Disclaimer : This blog is based on personal experiences and publicly available resources. Please note, the opinions expressed are solely my own and do not represent those of my past or current employers. Always refer to official resources and guidelines from hiring companies for the most accurate information.
| Liked by Kartik Singhal
|
| 1. Coding 2. Machine Learning Foundation 3. Machine Learning System Design 4. Past Machine Learning Project Experience (resume discussion)
|
Ready for more?
IMAGES
VIDEO
COMMENTS
Many SQL case study questions will ask you to investigate correlation. In this example SQL case question, we're looking into this issue: Unsubscribe rates have increased after a new notification system has been introduced. Question: Twitter wants to roll out more push notifications to users because they think users are missing out on good ...
The solution involved using the Case expression within an SQL query to assign each customer to a category based on their total spend. Here's a simplified version of the code: SELECT CustomerID, CASE. WHEN SUM (PurchaseAmount) > 10000 THEN 'High'. WHEN SUM (PurchaseAmount) BETWEEN 5000 AND 10000 THEN 'Medium'.
This article is packed with over 100 SQL interview questions and practical exercises, organized by topic, to help you prepare thoroughly and approach your interview with confidence. SQL is essential for many jobs, like data analysis, data science, software engineering, data engineering, testing, and many others.
Easy SQL Scenario Based Interview Questions. Easy SQL scenario based interview questions will test your ability to apply simple queries and solve basic problems. There will be limited use of subqueries or multiple tables. 1. Write a query to display the highest salaries in each department.
5 essential beginner scenario-based SQL interview questions with answers. To review your applicants' responses, use these straightforward sample answers to our scenario-based SQL interview questions. 1. Another employee needs help and asks you to explain what a database is.
METHOD-1: Using ROWID and ROW_NUMBER Analytic Function. An Oracle server assigns each row in each table with a unique ROWID to identify the row in the table. The ROWID is the address of the row which contains the data object number, the data block of the row, the row position and data file. STEP-1: Using ROW_NUMBER Analytic function, assign row ...
The steps are as follows: Step 1: Navigate to the bin folder of the PostgreSQL installation path. C:\>cd C:\Program Files\PostgreSQL\10.0\bin. Step 2: Execute pg_dump program to take the dump of data to a .tar folder as shown below: pg_dump -U postgres -W -F t sample_data > C:\Users\admin\pgbackup\sample_data.tar.
View answer. 5. Assume a schema of Emp ( Id, Name, DeptId ) , Dept ( Id, Name). If there are 10 records in the Emp table and 5 records in the Dept table, how many rows will be displayed in the result of the following SQL query: Select * From Emp, Dept.
A comprehensive collection of SQL case studies, queries, and solutions for real-world scenarios. This repository provides a hands-on approach to mastering SQL skills through a series of case studies, including table structures, sample data, and SQL queries. - GitHub - tituHere/SQL-Case-Study: A comprehensive collection of SQL case studies, queries, and solutions for real-world scenarios.
5. Monthly Merchant Balance [Visa SQL Interview Question] Say you have access to all the transactions for a given merchant account. Write a query to print the cumulative balance of the merchant account at the end of each day, with the total balance reset back to zero at the end of the month.
This collection of interview questions on SQL has been collated from my experience with SQL and from various websites. It contains a list of questions of different types: Definitions: These questions ask for a definition of a term or concept. Differences: Questions that ask for the difference between two similar concepts.
Dive into the heart of SQL interviews with a compilation of essential SQL interview questions. From classic queries to tasks that test your analytical acumen, mastering these questions will showcase your readiness. For instance: Explain the difference between INNER JOIN and LEFT JOIN.
This article contains the 27 most commonly asked advanced SQL interview questions and provides detailed answers and resources for further reading. We'll go through these four main concepts and a few more besides: JOINs. GROUP BY, WHERE, and HAVING. CTEs (Common Table Expressions) and recursive queries.
It contains over 600 interactive SQL exercises to help you review and practice SQL before an interview. In this article, I'll help you prepare for the by going over some common questions and SQL exercises that recruiters use during the interview process. Basic SQL Whiteboard Questions for Job Interviews
Generally speaking, the easier, definitional questions will be fewer and less important than the live coding questions—something to keep in mind as you prepare. 1. Define a SQL term. If you're interviewing for a data analyst role, chances are you know what SQL is (and your interviewer assumes you know this).
SQL Challenge: Case Study. ... The more you practice solving SQL questions, the better you'll get at them. Alright, let's get into it! Reading the Prompt. ... At this point in the interview, you would have taken the time to understand the challenge and communicated initial thoughts to the interviewer. In addition, feel free to ask the ...
SQL is a versatile language for data analysis, and these real-world case studies demonstrate its practical application in various domains. By using SQL queries, you can extract valuable insights ...
Relational Database Management System: The data is stored in relations (tables). Example - MySQL. Non-Relational Database Management System: There is no concept of relations, tuples and attributes. Example - MongoDB. Let's move to the next question in this SQL Interview Questions. Q4.
By executing queries, SQL can create, update, delete, and retrieve data in databases like MySQL, Oracle, PostgreSQL, etc. Overall, SQL is a query language that communicates with databases. In this article, we cover 70+ SQL Interview Questions with answers asked in SQL developer interviews at MAANG and other high-paying companies.
Check out the most commonly asked SQL Query Interview Questions ranging from basic to advanced SQL queries for freshers and experienced professionals (2 to 10 years). ... Create a free personalised study plan Create a FREE custom ... However, we will use the IF operator instead of the CASE operator. The SQL query for this approach can be ...
SQL: 80 Topic wise Practice Queries. Practice queries on Aggregates, Group by, Joins, Sub-queries and Case expressions. Solve over 80 SQL exercises using real life case studies. Please login to see the progress.
It is engaging enough, and is pretty much the closest thing to a real-world SQL use case as shows up online. It doesn't need a lot of skill to complete, but the more you know, the more cleanly and quickly you can do it. Very satisfying overall. Everything else strays quite quickly into weird, contrived cases where you are often asked to use SQL ...
The Four Types of Rounds: 📚 Machine Learning Breadth: This round tests your broad knowledge across various ML topics. I usually spend about 35% of my prep time here. 🔍 Machine Learning Depth: This round requires about 25% of my prep time, focusing on specialized topics and detailed case studies. 🛠️ Machine Learning System Design: This round evaluates your ability to design scalable ...