- Customer service and contact center

speech recognition
- Ben Lutkevich, Site Editor
- Karolina Kiwak
What is speech recognition?
Speech recognition, or speech-to-text, is the ability of a machine or program to identify words spoken aloud and convert them into readable text. Rudimentary speech recognition software has a limited vocabulary and may only identify words and phrases when spoken clearly. More sophisticated software can handle natural speech, different accents and various languages.
Speech recognition uses a broad array of research in computer science, linguistics and computer engineering. Many modern devices and text-focused programs have speech recognition functions in them to allow for easier or hands-free use of a device.
Speech recognition and voice recognition are two different technologies and should not be confused :
- Speech recognition is used to identify words in spoken language.
- Voice recognition is a biometric technology for identifying an individual's voice.
How does speech recognition work?
Speech recognition systems use computer algorithms to process and interpret spoken words and convert them into text. A software program turns the sound a microphone records into written language that computers and humans can understand, following these four steps:
- analyze the audio;
- break it into parts;
- digitize it into a computer-readable format; and
- use an algorithm to match it to the most suitable text representation.
Speech recognition software must adapt to the highly variable and context-specific nature of human speech. The software algorithms that process and organize audio into text are trained on different speech patterns, speaking styles, languages, dialects, accents and phrasings. The software also separates spoken audio from background noise that often accompanies the signal.
To meet these requirements, speech recognition systems use two types of models:
- Acoustic models. These represent the relationship between linguistic units of speech and audio signals.
- Language models. Here, sounds are matched with word sequences to distinguish between words that sound similar.
What applications is speech recognition used for?
Speech recognition systems have quite a few applications. Here is a sampling of them.
Mobile devices. Smartphones use voice commands for call routing, speech-to-text processing, voice dialing and voice search. Users can respond to a text without looking at their devices. On Apple iPhones, speech recognition powers the keyboard and Siri, the virtual assistant. Functionality is available in secondary languages, too. Speech recognition can also be found in word processing applications like Microsoft Word, where users can dictate words to be turned into text.

Education. Speech recognition software is used in language instruction. The software hears the user's speech and offers help with pronunciation.
Customer service. Automated voice assistants listen to customer queries and provides helpful resources.
Healthcare applications. Doctors can use speech recognition software to transcribe notes in real time into healthcare records.
Disability assistance. Speech recognition software can translate spoken words into text using closed captions to enable a person with hearing loss to understand what others are saying. Speech recognition can also enable those with limited use of their hands to work with computers, using voice commands instead of typing.
Court reporting. Software can be used to transcribe courtroom proceedings, precluding the need for human transcribers.
Emotion recognition. This technology can analyze certain vocal characteristics to determine what emotion the speaker is feeling. Paired with sentiment analysis, this can reveal how someone feels about a product or service.
Hands-free communication. Drivers use voice control for hands-free communication, controlling phones, radios and global positioning systems, for instance.

What are the features of speech recognition systems?
Good speech recognition programs let users customize them to their needs. The features that enable this include:
- Language weighting. This feature tells the algorithm to give special attention to certain words, such as those spoken frequently or that are unique to the conversation or subject. For example, the software can be trained to listen for specific product references.
- Acoustic training. The software tunes out ambient noise that pollutes spoken audio. Software programs with acoustic training can distinguish speaking style, pace and volume amid the din of many people speaking in an office.
- Speaker labeling. This capability enables a program to label individual participants and identify their specific contributions to a conversation.
- Profanity filtering. Here, the software filters out undesirable words and language.
What are the different speech recognition algorithms?
The power behind speech recognition features comes from a set of algorithms and technologies. They include the following:
- Hidden Markov model. HMMs are used in autonomous systems where a state is partially observable or when all of the information necessary to make a decision is not immediately available to the sensor (in speech recognition's case, a microphone). An example of this is in acoustic modeling, where a program must match linguistic units to audio signals using statistical probability.
- Natural language processing. NLP eases and accelerates the speech recognition process.
- N-grams. This simple approach to language models creates a probability distribution for a sequence. An example would be an algorithm that looks at the last few words spoken, approximates the history of the sample of speech and uses that to determine the probability of the next word or phrase that will be spoken.
- Artificial intelligence. AI and machine learning methods like deep learning and neural networks are common in advanced speech recognition software. These systems use grammar, structure, syntax and composition of audio and voice signals to process speech. Machine learning systems gain knowledge with each use, making them well suited for nuances like accents.
What are the advantages of speech recognition?
There are several advantages to using speech recognition software, including the following:
- Machine-to-human communication. The technology enables electronic devices to communicate with humans in natural language or conversational speech.
- Readily accessible. This software is frequently installed in computers and mobile devices, making it accessible.
- Easy to use. Well-designed software is straightforward to operate and often runs in the background.
- Continuous, automatic improvement. Speech recognition systems that incorporate AI become more effective and easier to use over time. As systems complete speech recognition tasks, they generate more data about human speech and get better at what they do.
What are the disadvantages of speech recognition?
While convenient, speech recognition technology still has a few issues to work through. Limitations include:
- Inconsistent performance. The systems may be unable to capture words accurately because of variations in pronunciation, lack of support for some languages and inability to sort through background noise. Ambient noise can be especially challenging. Acoustic training can help filter it out, but these programs aren't perfect. Sometimes it's impossible to isolate the human voice.
- Speed. Some speech recognition programs take time to deploy and master. The speech processing may feel relatively slow .
- Source file issues. Speech recognition success depends on the recording equipment used, not just the software.
The takeaway
Speech recognition is an evolving technology. It is one of the many ways people can communicate with computers with little or no typing. A variety of communications-based business applications capitalize on the convenience and speed of spoken communication that this technology enables.
Speech recognition programs have advanced greatly over 60 years of development. They are still improving, fueled in particular by AI.
Learn more about the AI-powered business transcription software in this Q&A with Wilfried Schaffner, chief technology officer of Speech Processing Solutions.
Continue Reading About speech recognition
- How can speech recognition technology support remote work?
- Automatic speech recognition may be better than you think
- Speech recognition use cases enable touchless collaboration
- Automated speech recognition gives CX vendor an edge
- Speech API from Mozilla's Web developer platform
Related Terms
Dig deeper on customer service and contact center.

7 ways AI is affecting the travel industry

natural language processing (NLP)

computational linguistics (CL)

Moving years' worth of SharePoint data out of on-premises storage to the cloud can be daunting, so choosing the correct migration...
Implementing an ECM system is not all about technology; it's also about the people. A proper rollout requires feedback from key ...
Incorporating consulting services and flexible accommodations for different LLMs, developer-focused Contentstack offers its own ...
Organizations have ramped up their use of communications platform as a service and APIs to expand communication channels between ...
Google will roll out new GenAI in Gmail and Docs first and then other apps throughout the year. In 2025, Google plans to ...
For successful hybrid meeting collaboration, businesses need to empower remote and on-site employees with a full suite of ...
The data management and analytics vendor's embeddable database now includes streaming capabilities via support for Kafka and ...
The vendor's latest update adds new customer insight capabilities, including an AI assistant, and industry-specific tools all ...
The data quality specialist's capabilities will enable customers to monitor unstructured text to ensure the health of data used ...
Arista, Cisco and HPE are racing to seize a share of the promising GenAI infrastructure market. Cisco and HPE have computing, ...
Explore the education, experience and skills needed to excel in the demanding yet rewarding field of NLP engineering, including ...
For business leaders, machine learning's predictive capabilities can forecast product demand, reduce equipment downtime and ...
Epicor continues its buying spree with PIM vendor Kyklo, enabling manufacturers and distributors to gain visibility into what ...
Supply chains have a range of connection points -- and vulnerabilities. Learn which vulnerabilities hackers look for first and ...
As supplier relationships become increasingly complex and major disruptions continue, it pays to understand the top supply chain ...
Speech Recognition: Everything You Need to Know in 2024
AIMultiple team adheres to the ethical standards summarized in our research commitments.
Speech recognition, also known as automatic speech recognition (ASR) , enables seamless communication between humans and machines. This technology empowers organizations to transform human speech into written text. Speech recognition technology can revolutionize many business applications , including customer service, healthcare, finance and sales.
In this comprehensive guide, we will explain speech recognition, exploring how it works, the algorithms involved, and the use cases of various industries.
If you require training data for your speech recognition system, here is a guide to finding the right speech data collection services.
What is speech recognition?
Speech recognition, also known as automatic speech recognition (ASR), speech-to-text (STT), and computer speech recognition, is a technology that enables a computer to recognize and convert spoken language into text.
Speech recognition technology uses AI and machine learning models to accurately identify and transcribe different accents, dialects, and speech patterns.
What are the features of speech recognition systems?
Speech recognition systems have several components that work together to understand and process human speech. Key features of effective speech recognition are:
- Audio preprocessing: After you have obtained the raw audio signal from an input device, you need to preprocess it to improve the quality of the speech input The main goal of audio preprocessing is to capture relevant speech data by removing any unwanted artifacts and reducing noise.
- Feature extraction: This stage converts the preprocessed audio signal into a more informative representation. This makes raw audio data more manageable for machine learning models in speech recognition systems.
- Language model weighting: Language weighting gives more weight to certain words and phrases, such as product references, in audio and voice signals. This makes those keywords more likely to be recognized in a subsequent speech by speech recognition systems.
- Acoustic modeling : It enables speech recognizers to capture and distinguish phonetic units within a speech signal. Acoustic models are trained on large datasets containing speech samples from a diverse set of speakers with different accents, speaking styles, and backgrounds.
- Speaker labeling: It enables speech recognition applications to determine the identities of multiple speakers in an audio recording. It assigns unique labels to each speaker in an audio recording, allowing the identification of which speaker was speaking at any given time.
- Profanity filtering: The process of removing offensive, inappropriate, or explicit words or phrases from audio data.
What are the different speech recognition algorithms?
Speech recognition uses various algorithms and computation techniques to convert spoken language into written language. The following are some of the most commonly used speech recognition methods:
- Hidden Markov Models (HMMs): Hidden Markov model is a statistical Markov model commonly used in traditional speech recognition systems. HMMs capture the relationship between the acoustic features and model the temporal dynamics of speech signals.
- Estimate the probability of word sequences in the recognized text
- Convert colloquial expressions and abbreviations in a spoken language into a standard written form
- Map phonetic units obtained from acoustic models to their corresponding words in the target language.
- Speaker Diarization (SD): Speaker diarization, or speaker labeling, is the process of identifying and attributing speech segments to their respective speakers (Figure 1). It allows for speaker-specific voice recognition and the identification of individuals in a conversation.
Figure 1: A flowchart illustrating the speaker diarization process

- Dynamic Time Warping (DTW): Speech recognition algorithms use Dynamic Time Warping (DTW) algorithm to find an optimal alignment between two sequences (Figure 2).
Figure 2: A speech recognizer using dynamic time warping to determine the optimal distance between elements

5. Deep neural networks: Neural networks process and transform input data by simulating the non-linear frequency perception of the human auditory system.
6. Connectionist Temporal Classification (CTC): It is a training objective introduced by Alex Graves in 2006. CTC is especially useful for sequence labeling tasks and end-to-end speech recognition systems. It allows the neural network to discover the relationship between input frames and align input frames with output labels.
Speech recognition vs voice recognition
Speech recognition is commonly confused with voice recognition, yet, they refer to distinct concepts. Speech recognition converts spoken words into written text, focusing on identifying the words and sentences spoken by a user, regardless of the speaker’s identity.
On the other hand, voice recognition is concerned with recognizing or verifying a speaker’s voice, aiming to determine the identity of an unknown speaker rather than focusing on understanding the content of the speech.
What are the challenges of speech recognition with solutions?
While speech recognition technology offers many benefits, it still faces a number of challenges that need to be addressed. Some of the main limitations of speech recognition include:
Acoustic Challenges:
- Assume a speech recognition model has been primarily trained on American English accents. If a speaker with a strong Scottish accent uses the system, they may encounter difficulties due to pronunciation differences. For example, the word “water” is pronounced differently in both accents. If the system is not familiar with this pronunciation, it may struggle to recognize the word “water.”
Solution: Addressing these challenges is crucial to enhancing speech recognition applications’ accuracy. To overcome pronunciation variations, it is essential to expand the training data to include samples from speakers with diverse accents. This approach helps the system recognize and understand a broader range of speech patterns.
- For instance, you can use data augmentation techniques to reduce the impact of noise on audio data. Data augmentation helps train speech recognition models with noisy data to improve model accuracy in real-world environments.
Figure 3: Examples of a target sentence (“The clown had a funny face”) in the background noise of babble, car and rain.

Linguistic Challenges:
- Out-of-vocabulary words: Since the speech recognizers model has not been trained on OOV words, they may incorrectly recognize them as different or fail to transcribe them when encountering them.
Figure 4: An example of detecting OOV word
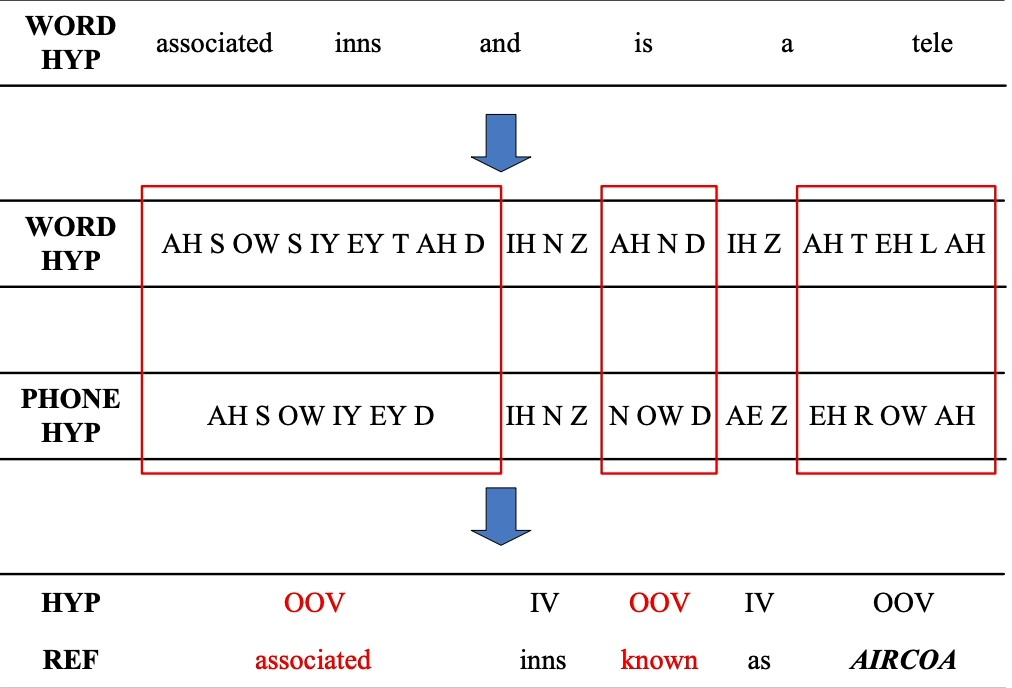
Solution: Word Error Rate (WER) is a common metric that is used to measure the accuracy of a speech recognition or machine translation system. The word error rate can be computed as:
Figure 5: Demonstrating how to calculate word error rate (WER)

- Homophones: Homophones are words that are pronounced identically but have different meanings, such as “to,” “too,” and “two”. Solution: Semantic analysis allows speech recognition programs to select the appropriate homophone based on its intended meaning in a given context. Addressing homophones improves the ability of the speech recognition process to understand and transcribe spoken words accurately.
Technical/System Challenges:
- Data privacy and security: Speech recognition systems involve processing and storing sensitive and personal information, such as financial information. An unauthorized party could use the captured information, leading to privacy breaches.
Solution: You can encrypt sensitive and personal audio information transmitted between the user’s device and the speech recognition software. Another technique for addressing data privacy and security in speech recognition systems is data masking. Data masking algorithms mask and replace sensitive speech data with structurally identical but acoustically different data.
Figure 6: An example of how data masking works

- Limited training data: Limited training data directly impacts the performance of speech recognition software. With insufficient training data, the speech recognition model may struggle to generalize different accents or recognize less common words.
Solution: To improve the quality and quantity of training data, you can expand the existing dataset using data augmentation and synthetic data generation technologies.
13 speech recognition use cases and applications
In this section, we will explain how speech recognition revolutionizes the communication landscape across industries and changes the way businesses interact with machines.
Customer Service and Support
- Interactive Voice Response (IVR) systems: Interactive voice response (IVR) is a technology that automates the process of routing callers to the appropriate department. It understands customer queries and routes calls to the relevant departments. This reduces the call volume for contact centers and minimizes wait times. IVR systems address simple customer questions without human intervention by employing pre-recorded messages or text-to-speech technology . Automatic Speech Recognition (ASR) allows IVR systems to comprehend and respond to customer inquiries and complaints in real time.
- Customer support automation and chatbots: According to a survey, 78% of consumers interacted with a chatbot in 2022, but 80% of respondents said using chatbots increased their frustration level.
- Sentiment analysis and call monitoring: Speech recognition technology converts spoken content from a call into text. After speech-to-text processing, natural language processing (NLP) techniques analyze the text and assign a sentiment score to the conversation, such as positive, negative, or neutral. By integrating speech recognition with sentiment analysis, organizations can address issues early on and gain valuable insights into customer preferences.
- Multilingual support: Speech recognition software can be trained in various languages to recognize and transcribe the language spoken by a user accurately. By integrating speech recognition technology into chatbots and Interactive Voice Response (IVR) systems, organizations can overcome language barriers and reach a global audience (Figure 7). Multilingual chatbots and IVR automatically detect the language spoken by a user and switch to the appropriate language model.
Figure 7: Showing how a multilingual chatbot recognizes words in another language
- Customer authentication with voice biometrics: Voice biometrics use speech recognition technologies to analyze a speaker’s voice and extract features such as accent and speed to verify their identity.
Sales and Marketing:
- Virtual sales assistants: Virtual sales assistants are AI-powered chatbots that assist customers with purchasing and communicate with them through voice interactions. Speech recognition allows virtual sales assistants to understand the intent behind spoken language and tailor their responses based on customer preferences.
- Transcription services : Speech recognition software records audio from sales calls and meetings and then converts the spoken words into written text using speech-to-text algorithms.
Automotive:
- Voice-activated controls: Voice-activated controls allow users to interact with devices and applications using voice commands. Drivers can operate features like climate control, phone calls, or navigation systems.
- Voice-assisted navigation: Voice-assisted navigation provides real-time voice-guided directions by utilizing the driver’s voice input for the destination. Drivers can request real-time traffic updates or search for nearby points of interest using voice commands without physical controls.
Healthcare:
- Recording the physician’s dictation
- Transcribing the audio recording into written text using speech recognition technology
- Editing the transcribed text for better accuracy and correcting errors as needed
- Formatting the document in accordance with legal and medical requirements.
- Virtual medical assistants: Virtual medical assistants (VMAs) use speech recognition, natural language processing, and machine learning algorithms to communicate with patients through voice or text. Speech recognition software allows VMAs to respond to voice commands, retrieve information from electronic health records (EHRs) and automate the medical transcription process.
- Electronic Health Records (EHR) integration: Healthcare professionals can use voice commands to navigate the EHR system , access patient data, and enter data into specific fields.
Technology:
- Virtual agents: Virtual agents utilize natural language processing (NLP) and speech recognition technologies to understand spoken language and convert it into text. Speech recognition enables virtual agents to process spoken language in real-time and respond promptly and accurately to user voice commands.
Further reading
- Top 5 Speech Recognition Data Collection Methods in 2023
- Top 11 Speech Recognition Applications in 2023
External Links
- 1. Databricks
- 2. PubMed Central
- 3. Qin, L. (2013). Learning Out-of-vocabulary Words in Automatic Speech Recognition . Carnegie Mellon University.
- 4. Wikipedia

Next to Read
Top 10 text to speech software analysis in 2024, top 5 speech recognition data collection methods in 2024, top 4 speech recognition challenges & solutions in 2024.
Your email address will not be published. All fields are required.
Related research

Why Should You Use Cloud Inference (Inference as a Service) in 2024?
Breaking: aiOla Surpasses OpenAI's Whisper
Breaking News: VentureBeat Reports aiOla Surpasses OpenAI's Whisper in Jargon Recognition!
Speech Recognition

What Is Speech Recognition?
Speech recognition is the technology that allows a computer to recognize human speech and process it into text. It’s also known as automatic speech recognition ( ASR ), speech-to-text, or computer speech recognition.
Speech recognition systems rely on technologies like artificial intelligence (AI) and machine learning (ML) to gain larger samples of speech, including different languages, accents, and dialects. AI is used to identify patterns of speech, words, and language to transcribe them into a written format.
In this blog post, we’ll take a deeper dive into speech recognition and look at how it works, its real-world applications, and how platforms like aiOla are using it to change the way we work.

Basic Speech Recognition Concepts
To start understanding speech recognition and all its applications, we need to first look at what it is and isn’t. While speech recognition is more than just the sum of its parts, it’s important to look at each of the parts that contribute to this technology to better grasp how it can make a real impact. Let’s take a look at some common concepts.
Speech Recognition vs. Speech Synthesis
Unlike speech recognition, which converts spoken language into a written format through a computer, speech synthesis does the same in reverse. In other words, speech synthesis is the creation of artificial speech derived from a written text, where a computer uses an AI-generated voice to simulate spoken language. For example, think of the language voice assistants like Siri or Alexa use to communicate information.
Phonetics and Phonology
Phonetics studies the physical sound of human speech, such as its acoustics and articulation. Alternatively, phonology looks at the abstract representation of sounds in a language including their patterns and how they’re organized. These two concepts need to be carefully weighed for speech AI algorithms to understand sound and language as a human might.
Acoustic Modeling
In acoustic modeling , the acoustic characteristics of audio and speech are looked at. When it comes to speech recognition systems, this process is essential since it helps analyze the audio features of each word, such as the frequency in which it’s used, the duration of a word, or the sounds it encompasses.
Language Modeling
Language modeling algorithms look at details like the likelihood of word sequences in a language. This type of modeling helps make speech recognition systems more accurate as it mimics real spoken language by looking at the probability of word combinations in phrases.
Speaker-Dependent vs. Speaker-Independent Systems
A system that’s dependent on a speaker is trained on the unique voice and speech patterns of a specific user, meaning the system might be highly accurate for that individual but not as much for other people. By contrast, a system that’s independent of a speaker can recognize speech for any number of speakers, and while more versatile, may be slightly less accurate.
How Does Speech Recognition Work?
There are a few different stages to speech recognition, each one providing another layer to how language is processed by a computer. Here are the different steps that make up the process.
- First, raw audio input undergoes a process called preprocessing , where background noise is removed to enhance sound quality and make recognition more manageable.
- Next, the audio goes through feature extraction , where algorithms identify distinct characteristics of sounds and words.
- Then, these extracted features go through acoustic modeling , which as we described earlier, is the stage where acoustic and language models decide the most accurate visual representation of the word. These acoustic modeling systems are based on extensive datasets, allowing them to learn the acoustic patterns of different spoken words.
- At the same time, language modeling looks at the structure and probability of words in a sequence, which helps provide context.
- After this, the output goes into a decoding sequence, where the speech recognition system matches data from the extracted features with the acoustic models. This helps determine the most likely word sequence.
- Finally, the audio and corresponding textual output go through post-processing , which refines the output by correcting errors and improving coherence to create a more accurate transcription.
When it comes to advanced systems, all of these stages are done nearly instantaneously, making this process almost invisible to the average user. All of these stages together have made speech recognition a highly versatile tool that can be used in many different ways, from virtual assistants to transcription services and beyond.
Types of Speech Recognition Systems
Speech recognition technology is used in many different ways today, transforming the way humans and machines interact and work together. From professional settings to helping us make our lives a little easier, this technology can take on many forms. Here are some of them.
Virtual Assistants
In 2022, 62% of US adults used a voice assistant on various mobile devices. Siri, Google Assistant, and Alexa are all examples of speech recognition in our daily lives. These applications respond to vocal commands and can interact with humans through natural language in order to complete tasks like sending messages, answering questions, or setting reminders.
Voice Search
Search engines like Google can be searched using voice instead of typing in a query, often with voice assistants. This allows users to conveniently search for a quick answer without sorting through content when they need to be hands-free, like when driving or multitasking. This technology has become so popular over the last few years that now 50% of US-based consumers use voice search every single day.
Transcription Services
Speech recognition has completely changed the transcription industry. It has enabled transcription services to automate the process of turning speech into text, increasing efficiency in many fields like education, legal services, healthcare, and even journalism.
Accessibility
With speech recognition, technologies that may have seemed out of reach are now accessible to people with disabilities. For example, for people with motor impairments or who are visually impaired, AI voice-to-text technology can help with the hands-free operation of things like keyboards, writing assistance for dictation, and voice commands to control devices.
Automotive Systems
Speech recognition is keeping drivers safer by giving them hands-free control over in-car features. Drivers can make calls, adjust the temperature, navigate, or even control the music without ever removing their hands from the wheel and instead just issuing voice commands to a speech-activated system.
How Does aiOla Use Speech Recognition?
aiOla’s AI-powered speech platform is revolutionizing the way certain industries work by bringing advanced speech recognition technology to companies in fields like aviation, fleet management, food safety, and manufacturing.
Traditionally, many processes in these industries were manual, forcing organizations to use a lot of time, budget, and resources to complete mission-critical tasks like inspections and maintenance. However, with aiOla’s advanced speech system, these otherwise labor and resource-intensive tasks can be reduced to a matter of minutes using natural language.
Rather than manually writing to record data during inspections, inspectors can speak about what they’re verifying and the data gets stored instantly. Similarly, through dissecting speech, aiOla can help with predictive maintenance of essential machinery, allowing food manufacturers to produce safer items and decrease downtime.
Since aiOla’s speech recognition platform understands over 100 languages and countless accents, dialects, and industry-specific jargon, the system is highly accurate and can help turn speech into action to go a step further and automate otherwise manual tasks.
Embracing Speech Recognition Technology
Looking ahead, we can only expect the technology that relies on speech recognition to improve and become more embedded into our day-to-day. Indeed, the market for this technology is expected to grow to $19.57 billion by 2030 . Whether it’s refining virtual assistants, improving voice search, or applying speech recognition to new industries, this technology is here to stay and enhance our personal and professional lives.
aiOla, while also a relatively new technology, is already making waves in industries like manufacturing, fleet management, and food safety. Through technological advancements in speech recognition, we only expect aiOla’s capabilities to continue to grow and support a larger variety of businesses and organizations.
Schedule a demo with one of our experts to see how aiOla’s AI speech recognition platform works in action.
What is speech recognition software? Speech recognition software is a technology that enables computers to convert speech into written words. This is done through algorithms that analyze audio signals along with AI, ML, and other technologies. What is a speech recognition example? A relatable example of speech recognition is asking a virtual assistant like Siri on a mobile device to check the day’s weather or set an alarm. While speech recognition can complete a lot more advanced tasks, this exemplifies how this technology is commonly used in everyday life. What is speech recognition in AI? Speech recognition in AI refers to how artificial intelligence processes are used to aid in recognizing voice and language using advanced models and algorithms trained on vast amounts of data. What are some different types of speech recognition? A few different types of speech recognition include speaker-dependent and speaker-independent systems, command and control systems, and continuous speech recognition. What is the difference between voice recognition and speech recognition? Speech recognition converts spoken language into text, while voice recognition works to identify a speaker’s unique vocal characteristics for authentication purposes. In essence, voice recognition is more tied to identity rather than transcription.
Ready to put your speech in motion? We’re listening.

Share your details to schedule a call
We will contact you soon!
- SUPPORT & DOCS

- By Use Case
- By Industry
- Book a Demo

What Is Speech Recognition?
Automatic Speech Recognition (ASR) software transforms voice commands or utterances into digital information that computers can use to process human speech as input. In a number of varying applications, speech recognition enables users to navigate a voice-user interface or interact with a computer system through spoken directives.
How It Works
Given the sheer number of words in every language as well as variations in pronunciation from region to region, ASR software has a very difficult task trying to understand us.
The software must first transform our analog voice into a digital format. It has to distinguish between words and sounds within words, which it does using phonemes—the smallest elements of any language (e.g., the splits into th and uh ).
ASR compares the phonemes in context with the other phonemes around them while also analyzing the preceding and following words, for context. The software uses complicated statistical modeling, such as Hidden Markov Models, to find the likely word.
Some speech recognition systems are speaker-dependent, meaning they require a training period to adjust to specific users’ voices for optimum performance. Other systems are speaker-independent, meaning they work without a training period and for any user.
All ASR systems incorporate noise reduction elements to filter out background noise from actual speech.
Speech Recognition vs. Voice Biometrics
While speech recognition software identifies what a speaker is saying, voice biometrics software identifies who’s speaking.
ASR Systems vs. Speech Recognition Engines
A speech recognition engine is a component of the larger speech recognition system, which uses a speech rec engine, a text-to-speech engine and a dialog manager. A speech recognition engine has several components: a language model or grammar, an acoustic model and a decoder.
Speech Recognition Applications
Most visibly, ASR is a key technology in the latest mobile devices with personal assistants (Siri, et cetera) and interactive voice response (IVR) systems that often couple ASR with speech synthesis .
Uses include data entry (password for IVR), voice dialing or texting, speech-to-text (dictation), device control (home appliances, et cetera) and direct voice input (voice commands in aviation).
Around since the 1960s, ASR has seen steady, incremental improvement over the years. It has benefited greatly from increased processing speed of computers in the last decade, entering the marketplace in the mid-2000s.
Early systems were acoustic phonetics-based and worked with small vocabularies to identify isolated words. Over the years, vocabularies have grown while ASR systems have become statistics-based (Hidden Markov Models). They now have large vocabularies and can recognize continuous speech.

Subscribe to our newsletter
Stay ahead of the curve with our AI insights and productivity tips delivered straight to your inbox.

- Productivity
What is Automatic Speech Recognition (ASR) Technology?

Automatic Speech Recognition (ASR) is revolutionizing the way we interact with technology, turning spoken words into text with incredible accuracy. But how does this magic work?

Automatic Speech Recognition (ASR), also known as Speech-to-Text (STT), is an artificial intelligence technology that converts spoken words into written text. Over the past decade, ASR has evolved to become an integral part of our daily lives, powering voice assistants, smart speakers, voice search, live captioning, and much more. Let's take a deep dive into how this fascinating technology works under the hood and the latest advancements transforming the field.
How ASR Works
At a high level, an ASR system takes in an audio signal containing speech as input, analyzes it, and outputs the corresponding text transcription. But a lot of complex processing happens in between those steps.
A typical ASR pipeline consists of several key components:
- Acoustic Model - This is usually a deep learning model trained to map audio features to phonemes, the distinct units of sound that distinguish one word from another in a language. The model is trained on many hours of transcribed speech data.
- Pronunciation Model - This contains a mapping of vocabulary words to their phonetic pronunciations. It helps the system determine what sounds make up each word.
- Language Model - The language model is trained on huge text corpora to learn the probability distributions of word sequences. This helps the system determine what word is likely to come next given the previous words, allowing it to handle homophones and pick the most probable word.
- Decoder - The decoder takes the outputs from the acoustic model, pronunciation model, and language model to search for and output the most likely word sequence that aligns with the input audio.
Early ASR systems used statistical models like Hidden Markov Models (HMMs) and Gaussian Mixture Models (GMMs). Today, state-of-the-art systems leverage the power of deep learning, using architectures like Recurrent Neural Networks (RNNs), Convolutional Neural Networks (CNNs), and Transformers to dramatically improve recognition accuracy.
End-to-end deep learning approaches like Connectionist Temporal Classification (CTC) and encoder-decoder models with attention have also gained popularity. These combine the various components of the traditional ASR pipeline into a single neural network that can be trained end-to-end, simplifying the system.
Despite the rapid progress, ASR still faces many challenges due to the immense complexity of human speech. Key challenges include:
- Accents & Pronunciations - Handling diverse speaker accents and pronunciations is difficult. Models need to be trained on speech data covering a wide variety of accents.
- Background Noise - Background sounds, muffled speech, and poor audio quality can drastically reduce transcription accuracy. A technique like speech enhancement is used to handle this.
- Different Languages - Supporting ASR for the thousands of languages worldwide, each with unique sounds, grammar, and scripts, is a massive undertaking. Techniques like transfer learning and multilingual models help, but collecting sufficient labeled training data for each language remains a bottleneck.
- Specialized Vocabulary - Many use cases like medical dictation involve very specialized domain-specific terminology that generic models struggle with. Custom models need to be trained with in-domain data for such specialized vocabularies.
Use Cases & Applications
ASR has a vast and rapidly growing range of applications, including:
- Voice Assistants & Smart Speakers - Siri, Alexa, and Google Assistant rely on ASR to understand spoken requests.
- Hands-free Computing - Voice-to-text allows dictating emails and documents, navigating apps, and issuing commands hands-free.
- Call Center Analytics - ASR allows analyzing support calls at scale to gauge customer sentiment, ensure compliance, and identify areas for agent coaching.
- Closed Captioning - Live ASR makes real-time captioning possible for lectures, news broadcasts, and video calls, enhancing accessibility.
- Medical Documentation - Healthcare professionals can dictate clinical notes for electronic health records.
- Meeting Transcription - ASR enables generating searchable transcripts and summaries of meetings, lectures, and depositions.
Latest Advancements
Some exciting recent advancements in ASR include:
- Contextual and Semantic Understanding - Beyond just transcribing the literal words, models are getting better at understanding intent and semantics using the whole conversation history as context.
- Emotion & Sentiment Recognition - Analyzing the prosody and intonation to recognize the underlying emotions in addition to the words.
- Ultra-low Latency Streaming - Reducing the latency of real-time transcription to under 100ms using techniques like blockwise streaming and speculative beam search.
- Improved Noise Robustness - Handling extremely noisy environments with signal-to-noise ratios as low as 0db.
- Personalizing to Voices - Improving accuracy for individuals by personalizing models for their unique voice, accent, and phrasing patterns.
- Huge Pre-trained Models - Leveraging self-supervised learning on unlabeled data to train massive models that can be fine-tuned for specific languages/domains with less labeled data, inspired by NLP successes like GPT-3.
The Future of ASR
As ASR technology continues to mature and permeate our lives and work, what does the future hold? We can expect the technology to become more accurate, more reliable in challenging acoustic environments, and more natural at interpreting meaning and intent beyond the literal spoken words.
Continuous personalization will allow ASR to adapt to your individual voice over time. We'll see more real-world products like earbuds with always-on voice interfaces. ASR will become more inclusive, supporting many more languages and niche use cases. Over time, talking to technology may become as natural as typing on a keyboard is today.
Advancements in ASR are intertwined with progress in natural language processing and dialog systems. As computers get better at truly understanding and engaging in human-like conversation, seamless human-computer interaction through natural spoken language will open up endless possibilities limited only by our imagination.
In conclusion, Automatic Speech Recognition has come a long way and is continuing to advance at a rapid pace. It's an exciting technology to keep an eye on as it shapes the future of how we interact with technology. From improving accessibility to transforming the way we work, the potential impact is immense.

What is Artificial General Intelligence (AGI)?

What are Foundation Models?

What is Generative AI?

What is Prompt Engineering?
Speech Recognition
Speech Recognition is the decoding of human speech into transcribed text through a computer program. To recognize spoken words, the program must transcribe the incoming sound signal into a digitized representation, which must then be compared to an enormous database of digitized representations of spoken words. To transcribe speech with any tolerable degree of accuracy, users must speak each word independently, with a pause between each word and this substantially slows the speed of speech-recognition systems and calls their utility into question, With the exception in the case of physical disabilities that would prevent input by other means. See discrete speech recognition.

Author Jennifer Spencer
You might also like.
No related photos.
- Random article
- Teaching guide
- Privacy & cookies

Speech recognition software
by Chris Woodford . Last updated: August 17, 2023.
I t's just as well people can understand speech. Imagine if you were like a computer: friends would have to "talk" to you by prodding away at a plastic keyboard connected to your brain by a long, curly wire. If you wanted to say "hello" to someone, you'd have to reach out, chatter your fingers over their keyboard, and wait for their eyes to light up; they'd have to do the same to you. Conversations would be a long, slow, elaborate nightmare—a silent dance of fingers on plastic; strange, abstract, and remote. We'd never put up with such clumsiness as humans, so why do we talk to our computers this way?
Scientists have long dreamed of building machines that can chatter and listen just like humans. But although computerized speech recognition has been around for decades, and is now built into most smartphones and PCs, few of us actually use it. Why? Possibly because we never even bother to try it out, working on the assumption that computers could never pull off a trick so complex as understanding the human voice. It's certainly true that speech recognition is a complex problem that's challenged some of the world's best computer scientists, mathematicians, and linguists. How well are they doing at cracking the problem? Will we all be chatting to our PCs one day soon? Let's take a closer look and find out!
Photo: A court reporter dictates notes into a laptop with a noise-cancelling microphone and speech-recogition software. Photo by Micha Pierce courtesy of US Marine Corps and DVIDS .
What is speech?
Language sets people far above our creeping, crawling animal friends. While the more intelligent creatures, such as dogs and dolphins, certainly know how to communicate with sounds, only humans enjoy the rich complexity of language. With just a couple of dozen letters, we can build any number of words (most dictionaries contain tens of thousands) and express an infinite number of thoughts.
Photo: Speech recognition has been popping up all over the place for quite a few years now. Even my old iPod Touch (dating from around 2012) has a built-in "voice control" program that let you pick out music just by saying "Play albums by U2," or whatever band you're in the mood for.
When we speak, our voices generate little sound packets called phones (which correspond to the sounds of letters or groups of letters in words); so speaking the word cat produces phones that correspond to the sounds "c," "a," and "t." Although you've probably never heard of these kinds of phones before, you might well be familiar with the related concept of phonemes : simply speaking, phonemes are the basic LEGO™ blocks of sound that all words are built from. Although the difference between phones and phonemes is complex and can be very confusing, this is one "quick-and-dirty" way to remember it: phones are actual bits of sound that we speak (real, concrete things), whereas phonemes are ideal bits of sound we store (in some sense) in our minds (abstract, theoretical sound fragments that are never actually spoken).
Computers and computer models can juggle around with phonemes, but the real bits of speech they analyze always involves processing phones. When we listen to speech, our ears catch phones flying through the air and our leaping brains flip them back into words, sentences, thoughts, and ideas—so quickly, that we often know what people are going to say before the words have fully fled from their mouths. Instant, easy, and quite dazzling, our amazing brains make this seem like a magic trick. And it's perhaps because listening seems so easy to us that we think computers (in many ways even more amazing than brains) should be able to hear, recognize, and decode spoken words as well. If only it were that simple!
Why is speech so hard to handle?
The trouble is, listening is much harder than it looks (or sounds): there are all sorts of different problems going on at the same time... When someone speaks to you in the street, there's the sheer difficulty of separating their words (what scientists would call the acoustic signal ) from the background noise —especially in something like a cocktail party, where the "noise" is similar speech from other conversations. When people talk quickly, and run all their words together in a long stream, how do we know exactly when one word ends and the next one begins? (Did they just say "dancing and smile" or "dance, sing, and smile"?) There's the problem of how everyone's voice is a little bit different, and the way our voices change from moment to moment. How do our brains figure out that a word like "bird" means exactly the same thing when it's trilled by a ten year-old girl or boomed by her forty-year-old father? What about words like "red" and "read" that sound identical but mean totally different things (homophones, as they're called)? How does our brain know which word the speaker means? What about sentences that are misheard to mean radically different things? There's the age-old military example of "send reinforcements, we're going to advance" being misheard for "send three and fourpence, we're going to a dance"—and all of us can probably think of song lyrics we've hilariously misunderstood the same way (I always chuckle when I hear Kate Bush singing about "the cattle burning over your shoulder"). On top of all that stuff, there are issues like syntax (the grammatical structure of language) and semantics (the meaning of words) and how they help our brain decode the words we hear, as we hear them. Weighing up all these factors, it's easy to see that recognizing and understanding spoken words in real time (as people speak to us) is an astonishing demonstration of blistering brainpower.
It shouldn't surprise or disappoint us that computers struggle to pull off the same dazzling tricks as our brains; it's quite amazing that they get anywhere near!
Photo: Using a headset microphone like this makes a huge difference to the accuracy of speech recognition: it reduces background sound, making it much easier for the computer to separate the signal (the all-important words you're speaking) from the noise (everything else).
How do computers recognize speech?
Speech recognition is one of the most complex areas of computer science —and partly because it's interdisciplinary: it involves a mixture of extremely complex linguistics, mathematics, and computing itself. If you read through some of the technical and scientific papers that have been published in this area (a few are listed in the references below), you may well struggle to make sense of the complexity. My objective is to give a rough flavor of how computers recognize speech, so—without any apology whatsoever—I'm going to simplify hugely and miss out most of the details.
Broadly speaking, there are four different approaches a computer can take if it wants to turn spoken sounds into written words:
1: Simple pattern matching

Ironically, the simplest kind of speech recognition isn't really anything of the sort. You'll have encountered it if you've ever phoned an automated call center and been answered by a computerized switchboard. Utility companies often have systems like this that you can use to leave meter readings, and banks sometimes use them to automate basic services like balance inquiries, statement orders, checkbook requests, and so on. You simply dial a number, wait for a recorded voice to answer, then either key in or speak your account number before pressing more keys (or speaking again) to select what you want to do. Crucially, all you ever get to do is choose one option from a very short list, so the computer at the other end never has to do anything as complex as parsing a sentence (splitting a string of spoken sound into separate words and figuring out their structure), much less trying to understand it; it needs no knowledge of syntax (language structure) or semantics (meaning). In other words, systems like this aren't really recognizing speech at all: they simply have to be able to distinguish between ten different sound patterns (the spoken words zero through nine) either using the bleeping sounds of a Touch-Tone phone keypad (technically called DTMF ) or the spoken sounds of your voice.
From a computational point of view, there's not a huge difference between recognizing phone tones and spoken numbers "zero", "one," "two," and so on: in each case, the system could solve the problem by comparing an entire chunk of sound to similar stored patterns in its memory. It's true that there can be quite a bit of variability in how different people say "three" or "four" (they'll speak in a different tone, more or less slowly, with different amounts of background noise) but the ten numbers are sufficiently different from one another for this not to present a huge computational challenge. And if the system can't figure out what you're saying, it's easy enough for the call to be transferred automatically to a human operator.
Photo: Voice-activated dialing on cellphones is little more than simple pattern matching. You simply train the phone to recognize the spoken version of a name in your phonebook. When you say a name, the phone doesn't do any particularly sophisticated analysis; it simply compares the sound pattern with ones you've stored previously and picks the best match. No big deal—which explains why even an old phone like this 2001 Motorola could do it.
2: Pattern and feature analysis
Automated switchboard systems generally work very reliably because they have such tiny vocabularies: usually, just ten words representing the ten basic digits. The vocabulary that a speech system works with is sometimes called its domain . Early speech systems were often optimized to work within very specific domains, such as transcribing doctor's notes, computer programming commands, or legal jargon, which made the speech recognition problem far simpler (because the vocabulary was smaller and technical terms were explicitly trained beforehand). Much like humans, modern speech recognition programs are so good that they work in any domain and can recognize tens of thousands of different words. How do they do it?
Most of us have relatively large vocabularies, made from hundreds of common words ("a," "the," "but" and so on, which we hear many times each day) and thousands of less common ones (like "discombobulate," "crepuscular," "balderdash," or whatever, which we might not hear from one year to the next). Theoretically, you could train a speech recognition system to understand any number of different words, just like an automated switchboard: all you'd need to do would be to get your speaker to read each word three or four times into a microphone, until the computer generalized the sound pattern into something it could recognize reliably.
The trouble with this approach is that it's hugely inefficient. Why learn to recognize every word in the dictionary when all those words are built from the same basic set of sounds? No-one wants to buy an off-the-shelf computer dictation system only to find they have to read three or four times through a dictionary, training it up to recognize every possible word they might ever speak, before they can do anything useful. So what's the alternative? How do humans do it? We don't need to have seen every Ford, Chevrolet, and Cadillac ever manufactured to recognize that an unknown, four-wheeled vehicle is a car: having seen many examples of cars throughout our lives, our brains somehow store what's called a prototype (the generalized concept of a car, something with four wheels, big enough to carry two to four passengers, that creeps down a road) and we figure out that an object we've never seen before is a car by comparing it with the prototype. In much the same way, we don't need to have heard every person on Earth read every word in the dictionary before we can understand what they're saying; somehow we can recognize words by analyzing the key features (or components) of the sounds we hear. Speech recognition systems take the same approach.
The recognition process
Practical speech recognition systems start by listening to a chunk of sound (technically called an utterance ) read through a microphone. The first step involves digitizing the sound (so the up-and-down, analog wiggle of the sound waves is turned into digital format, a string of numbers) by a piece of hardware (or software) called an analog-to-digital (A/D) converter (for a basic introduction, see our article on analog versus digital technology ). The digital data is converted into a spectrogram (a graph showing how the component frequencies of the sound change in intensity over time) using a mathematical technique called a Fast Fourier Transform (FFT) ), then broken into a series of overlapping chunks called acoustic frames , each one typically lasting 1/25 to 1/50 of a second. These are digitally processed in various ways and analyzed to find the components of speech they contain. Assuming we've separated the utterance into words, and identified the key features of each one, all we have to do is compare what we have with a phonetic dictionary (a list of known words and the sound fragments or features from which they're made) and we can identify what's probably been said. Probably is always the word in speech recognition: no-one but the speaker can ever know exactly what was said.)
Seeing speech
In theory, since spoken languages are built from only a few dozen phonemes (English uses about 46, while Spanish has only about 24), you could recognize any possible spoken utterance just by learning to pick out phones (or similar key features of spoken language such as formants , which are prominent frequencies that can be used to help identify vowels). Instead of having to recognize the sounds of (maybe) 40,000 words, you'd only need to recognize the 46 basic component sounds (or however many there are in your language), though you'd still need a large phonetic dictionary listing the phonemes that make up each word. This method of analyzing spoken words by identifying phones or phonemes is often called the beads-on-a-string model : a chunk of unknown speech (the string) is recognized by breaking it into phones or bits of phones (the beads); figure out the phones and you can figure out the words.
Most speech recognition programs get better as you use them because they learn as they go along using feedback you give them, either deliberately (by correcting mistakes) or by default (if you don't correct any mistakes, you're effectively saying everything was recognized perfectly—which is also feedback). If you've ever used a program like one of the Dragon dictation systems, you'll be familiar with the way you have to correct your errors straight away to ensure the program continues to work with high accuracy. If you don't correct mistakes, the program assumes it's recognized everything correctly, which means similar mistakes are even more likely to happen next time. If you force the system to go back and tell it which words it should have chosen, it will associate those corrected words with the sounds it heard—and do much better next time.
Screenshot: With speech dictation programs like Dragon NaturallySpeaking, shown here, it's important to go back and correct your mistakes if you want your words to be recognized accurately in future.
3: Statistical analysis
In practice, recognizing speech is much more complex than simply identifying phones and comparing them to stored patterns, and for a whole variety of reasons: Speech is extremely variable: different people speak in different ways (even though we're all saying the same words and, theoretically, they're all built from a standard set of phonemes) You don't always pronounce a certain word in exactly the same way; even if you did, the way you spoke a word (or even part of a word) might vary depending on the sounds or words that came before or after. As a speaker's vocabulary grows, the number of similar-sounding words grows too: the digits zero through nine all sound different when you speak them, but "zero" sounds like "hero," "one" sounds like "none," "two" could mean "two," "to," or "too"... and so on. So recognizing numbers is a tougher job for voice dictation on a PC, with a general 50,000-word vocabulary, than for an automated switchboard with a very specific, 10-word vocabulary containing only the ten digits. The more speakers a system has to recognize, the more variability it's going to encounter and the bigger the likelihood of making mistakes. For something like an off-the-shelf voice dictation program (one that listens to your voice and types your words on the screen), simple pattern recognition is clearly going to be a bit hit and miss. The basic principle of recognizing speech by identifying its component parts certainly holds good, but we can do an even better job of it by taking into account how language really works. In other words, we need to use what's called a language model .
When people speak, they're not simply muttering a series of random sounds. Every word you utter depends on the words that come before or after. For example, unless you're a contrary kind of poet, the word "example" is much more likely to follow words like "for," "an," "better," "good", "bad," and so on than words like "octopus," "table," or even the word "example" itself. Rules of grammar make it unlikely that a noun like "table" will be spoken before another noun ("table example" isn't something we say) while—in English at least—adjectives ("red," "good," "clear") come before nouns and not after them ("good example" is far more probable than "example good"). If a computer is trying to figure out some spoken text and gets as far as hearing "here is a ******* example," it can be reasonably confident that ******* is an adjective and not a noun. So it can use the rules of grammar to exclude nouns like "table" and the probability of pairs like "good example" and "bad example" to make an intelligent guess. If it's already identified a "g" sound instead of a "b", that's an added clue.
Virtually all modern speech recognition systems also use a bit of complex statistical hocus-pocus to help figure out what's being said. The probability of one phone following another, the probability of bits of silence occurring in between phones, and the likelihood of different words following other words are all factored in. Ultimately, the system builds what's called a hidden Markov model (HMM) of each speech segment, which is the computer's best guess at which beads are sitting on the string, based on all the things it's managed to glean from the sound spectrum and all the bits and pieces of phones and silence that it might reasonably contain. It's called a Markov model (or Markov chain), for Russian mathematician Andrey Markov , because it's a sequence of different things (bits of phones, words, or whatever) that change from one to the next with a certain probability. Confusingly, it's referred to as a "hidden" Markov model even though it's worked out in great detail and anything but hidden! "Hidden," in this case, simply means the contents of the model aren't observed directly but figured out indirectly from the sound spectrum. From the computer's viewpoint, speech recognition is always a probabilistic "best guess" and the right answer can never be known until the speaker either accepts or corrects the words that have been recognized. (Markov models can be processed with an extra bit of computer jiggery pokery called the Viterbi algorithm , but that's beyond the scope of this article.)
4: Artificial neural networks
HMMs have dominated speech recognition since the 1970s—for the simple reason that they work so well. But they're by no means the only technique we can use for recognizing speech. There's no reason to believe that the brain itself uses anything like a hidden Markov model. It's much more likely that we figure out what's being said using dense layers of brain cells that excite and suppress one another in intricate, interlinked ways according to the input signals they receive from our cochleas (the parts of our inner ear that recognize different sound frequencies).
Back in the 1980s, computer scientists developed "connectionist" computer models that could mimic how the brain learns to recognize patterns, which became known as artificial neural networks (sometimes called ANNs). A few speech recognition scientists explored using neural networks, but the dominance and effectiveness of HMMs relegated alternative approaches like this to the sidelines. More recently, scientists have explored using ANNs and HMMs side by side and found they give significantly higher accuracy over HMMs used alone.
Artwork: Neural networks are hugely simplified, computerized versions of the brain—or a tiny part of it that have inputs (where you feed in information), outputs (where results appear), and hidden units (connecting the two). If you train them with enough examples, they learn by gradually adjusting the strength of the connections between the different layers of units. Once a neural network is fully trained, if you show it an unknown example, it will attempt to recognize what it is based on the examples it's seen before.
Speech recognition: a summary
Artwork: A summary of some of the key stages of speech recognition and the computational processes happening behind the scenes.
What can we use speech recognition for?
We've already touched on a few of the more common applications of speech recognition, including automated telephone switchboards and computerized voice dictation systems. But there are plenty more examples where those came from.
Many of us (whether we know it or not) have cellphones with voice recognition built into them. Back in the late 1990s, state-of-the-art mobile phones offered voice-activated dialing , where, in effect, you recorded a sound snippet for each entry in your phonebook, such as the spoken word "Home," or whatever that the phone could then recognize when you spoke it in future. A few years later, systems like SpinVox became popular helping mobile phone users make sense of voice messages by converting them automatically into text (although a sneaky BBC investigation eventually claimed that some of its state-of-the-art speech automated speech recognition was actually being done by humans in developing countries!).
Today's smartphones make speech recognition even more of a feature. Apple's Siri , Google Assistant ("Hey Google..."), and Microsoft's Cortana are smartphone "personal assistant apps" who'll listen to what you say, figure out what you mean, then attempt to do what you ask, whether it's looking up a phone number or booking a table at a local restaurant. They work by linking speech recognition to complex natural language processing (NLP) systems, so they can figure out not just what you say , but what you actually mean , and what you really want to happen as a consequence. Pressed for time and hurtling down the street, mobile users theoretically find this kind of system a boon—at least if you believe the hype in the TV advertisements that Google and Microsoft have been running to promote their systems. (Google quietly incorporated speech recognition into its search engine some time ago, so you can Google just by talking to your smartphone, if you really want to.) If you have one of the latest voice-powered electronic assistants, such as Amazon's Echo/Alexa or Google Home, you don't need a computer of any kind (desktop, tablet, or smartphone): you just ask questions or give simple commands in your natural language to a thing that resembles a loudspeaker ... and it answers straight back.
Screenshot: When I asked Google "does speech recognition really work," it took it three attempts to recognize the question correctly.
Will speech recognition ever take off?
I'm a huge fan of speech recognition. After suffering with repetitive strain injury on and off for some time, I've been using computer dictation to write quite a lot of my stuff for about 15 years, and it's been amazing to see the improvements in off-the-shelf voice dictation over that time. The early Dragon NaturallySpeaking system I used on a Windows 95 laptop was fairly reliable, but I had to speak relatively slowly, pausing slightly between each word or word group, giving a horribly staccato style that tended to interrupt my train of thought. This slow, tedious one-word-at-a-time approach ("can – you – tell – what – I – am – saying – to – you") went by the name discrete speech recognition . A few years later, things had improved so much that virtually all the off-the-shelf programs like Dragon were offering continuous speech recognition , which meant I could speak at normal speed, in a normal way, and still be assured of very accurate word recognition. When you can speak normally to your computer, at a normal talking pace, voice dictation programs offer another advantage: they give clumsy, self-conscious writers a much more attractive, conversational style: "write like you speak" (always a good tip for writers) is easy to put into practice when you speak all your words as you write them!
Despite the technological advances, I still generally prefer to write with a keyboard and mouse . Ironically, I'm writing this article that way now. Why? Partly because it's what I'm used to. I often write highly technical stuff with a complex vocabulary that I know will defeat the best efforts of all those hidden Markov models and neural networks battling away inside my PC. It's easier to type "hidden Markov model" than to mutter those words somewhat hesitantly, watch "hiccup half a puddle" pop up on screen and then have to make corrections.
Screenshot: You an always add more words to a speech recognition program. Here, I've decided to train the Microsoft Windows built-in speech recognition engine to spot the words 'hidden Markov model.'
Mobile revolution?
You might think mobile devices—with their slippery touchscreens —would benefit enormously from speech recognition: no-one really wants to type an essay with two thumbs on a pop-up QWERTY keyboard. Ironically, mobile devices are heavily used by younger, tech-savvy kids who still prefer typing and pawing at screens to speaking out loud. Why? All sorts of reasons, from sheer familiarity (it's quick to type once you're used to it—and faster than fixing a computer's goofed-up guesses) to privacy and consideration for others (many of us use our mobile phones in public places and we don't want our thoughts wide open to scrutiny or howls of derision), and the sheer difficulty of speaking clearly and being clearly understood in noisy environments. Recently, I was walking down a street and overheard a small garden party where the sounds of happy laughter, drinking, and discreet background music were punctuated by a sudden grunt of "Alexa play Copacabana by Barry Manilow"—which silenced the conversation entirely and seemed jarringly out of place. Speech recognition has never been so indiscreet. What you're doing with your computer also makes a difference. If you've ever used speech recognition on a PC, you'll know that writing something like an essay (dictating hundreds or thousands of words of ordinary text) is a whole lot easier than editing it afterwards (where you laboriously try to select words or sentences and move them up or down so many lines with awkward cut and paste commands). And trying to open and close windows, start programs, or navigate around a computer screen by voice alone is clumsy, tedious, error-prone, and slow. It's far easier just to click your mouse or swipe your finger.
Photo: Here I'm using Google's Live Transcribe app to dictate the last paragraph of this article. As you can see, apart from the punctuation, the transcription is flawless, without any training at all. This is the fastest and most accurate speech recognition software I've ever used. It's mainly designed as an accessibility aid for deaf and hard of hearing people, but it can be used for dictation too.
Developers of speech recognition systems insist everything's about to change, largely thanks to natural language processing and smart search engines that can understand spoken queries. ("OK Google...") But people have been saying that for decades now: the brave new world is always just around the corner. According to speech pioneer James Baker, better speech recognition "would greatly increase the speed and ease with which humans could communicate with computers, and greatly speed and ease the ability with which humans could record and organize their own words and thoughts"—but he wrote (or perhaps voice dictated?) those words 25 years ago! Just because Google can now understand speech, it doesn't follow that we automatically want to speak our queries rather than type them—especially when you consider some of the wacky things people look for online. Humans didn't invent written language because others struggled to hear and understand what they were saying. Writing and speaking serve different purposes. Writing is a way to set out longer, more clearly expressed and elaborated thoughts without having to worry about the limitations of your short-term memory; speaking is much more off-the-cuff. Writing is grammatical; speech doesn't always play by the rules. Writing is introverted, intimate, and inherently private; it's carefully and thoughtfully composed. Speaking is an altogether different way of expressing your thoughts—and people don't always want to speak their minds. While technology may be ever advancing, it's far from certain that speech recognition will ever take off in quite the way that its developers would like. I'm typing these words, after all, not speaking them.
If you liked this article...
Find out more, on this website.
- Microphones
- Neural networks
- Speech synthesis
- Automatic Speech Recognition: A Deep Learning Approach by Dong Yu and Li Deng. Springer, 2015. Two Microsoft researchers review state-of-the-art, neural-network approaches to recognition.
- Theory and Applications of Digital Speech Processing by Lawrence R. Rabiner and Ronald W. Schafer. Pearson, 2011. An up-to-date review at undergraduate level.
- Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition by Daniel Jurafsky, James Martin. Prentice Hall, 2009. An up-to-date, interdisciplinary review of speech recognition technology.
- Statistical Methods for Speech Recognition by Frederick Jelinek. MIT Press, 1997. A detailed guide to Hidden Markov Models and the other statistical techniques that computers use to figure out human speech.
- Fundamentals of Speech Recognition by Lawrence R. Rabiner and Biing-Hwang Juang. PTR Prentice Hall, 1993. A little dated now, but still a good introduction to the basic concepts.
- Speech Recognition: Invited Papers Presented at the 1974 IEEE Symposium by D. R. Reddy (ed). Academic Press, 1975. A classic collection of pioneering papers from the golden age of the 1970s.
Easy-to-understand
- Lost voices, ignored words: Apple's speech recognition needs urgent reform by Colin Hughes, The Register, 16 August 2023. How speech recognition software ignores the needs of the people who need it most—disabled people with different accessibility needs.
- Android's Live Transcribe will let you save transcriptions and show 'sound events' by Dieter Bohn, The Verge, 16 May 2019. An introduction to Google's handy, 70-language transcription app.
- Hey, Siri: Read My Lips by Emily Waltz, IEEE Spectrum, 8 February 2019. How your computer can translate your words... without even listening.
- Interpol's New Software Will Recognize Criminals by Their Voices by Michael Dumiak, 16 May 2018. Is it acceptable for law enforcement agencies to store huge quantities of our voice samples if it helps them trap the occasional bad guy?
- Cypher: The Deep-Learning Software That Will Help Siri, Alexa, and Cortana Hear You : by Amy Nordrum. IEEE Spectrum, 24 October 2016. Cypher helps voice recognition programs to separate speech signals from background noise.
- In the Future, How Will We Talk to Our Technology? : by David Pierce. Wired, 27 September 2015. What sort of hardware will we use with future speech recognition software?
- The Holy Grail of Speech Recognition by Janie Chang: Microsoft Research, 29 August 2011. How neural networks are making a comeback in speech recognition research. [Archived via the Wayback Machine.]
- Audio Alchemy: Getting Computers to Understand Overlapping Speech by John R. Hershey et al. Scientific American, April 12, 2011. How can computers make sense of two people talking at once?
- How Siri Works: Interview with Tom Gruber by Nova Spivack, Minding the Planet, 26 January 2010. Gruber explains some of the technical tricks that allow Siri to understand natural language.
- A sound start for speech tech : by LJ Rich. BBC News, 15 May 2009. Cambridge University's Dr Tony Robinson talks us through the science of speech recognition.
- Speech Recognition by Computer by Stephen E. Levinson and Mark Y. Liberman, Scientific American, Vol. 244, No. 4 (April 1981), pp. 64–77. A more detailed overview of the basic concepts. A good article to continue with after you've read mine.
More technical
- An All-Neural On-Device Speech Recognizer by Johan Schalkwyk, Google AI Blog, March 12, 2019. Google announces a state-of-the-art speech recognition system based entirely on what are called recurrent neural network transducers (RNN-Ts).
- Improving End-to-End Models For Speech Recognition by Tara N. Sainath, and Yonghui Wu, Google Research Blog, December 14, 2017. A cutting-edge speech recognition model that integrates traditionally separate aspects of speech recognition into a single system.
- A Historical Perspective of Speech Recognition by Xuedong Huang, James Baker, Raj Reddy. Communications of the ACM, January 2014 (Vol. 57 No. 1), Pages 94–103.
- [PDF] Application Of Pretrained Deep Neural Networks To Large Vocabulary Speech Recognition by Navdeep Jaitly, Patrick Nguyen, Andrew Senior, Vincent Vanhoucke. Proceedings of Interspeech 2012. An insight into Google's use of neural networks for speech recognition.
- Context-Dependent Pre-trained Deep Neural Networks for Large Vocabulary Speech Recognition by George Dahl et al. IEEE Transactions on Audio, Speech, and Language Processing, Vol. 20 No. 1, January 2012. A review of Microsoft's recent research into using neural networks with HMMs.
- Speech Recognition Technology: A Critique by Stephen E. Levinson, Proceedings of the National Academy of Sciences of the United States of America. Vol. 92, No. 22, October 24, 1995, pp. 9953–9955.
- Hidden Markov Models for Speech Recognition by B. H. Juang and L. R. Rabiner, Technometrics, Vol. 33, No. 3, August, 1991, pp. 251–272.
- A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition by Lawrence R. Rabiner. Proceedings of the IEEE, Vol 77 No 2, February 1989. A classic introduction to Markov models, though non-mathematicians will find it tough going.
- US Patent: 4,783,803: Speech recognition apparatus and method by James K. Baker, Dragon Systems, 8 November 1988. One of Baker's first Dragon patents. Another Baker patent filed the following year follows on from this. See US Patent: 4,866,778: Interactive speech recognition apparatus by James K. Baker, Dragon Systems, 12 September 1989.
- US Patent 4,783,804: Hidden Markov model speech recognition arrangement by Stephen E. Levinson, Lawrence R. Rabiner, and Man M. Sondi, AT&T Bell Laboratories, 6 May 1986. Sets out one approach to probabilistic speech recognition using Markov models.
- US Patent: 4,363,102: Speaker identification system using word recognition templates by John E. Holmgren, Bell Labs, 7 December 1982. A method of recognizing a particular person's voice using analysis of key features.
- US Patent 2,938,079: Spectrum segmentation system for the automatic extraction of formant frequencies from human speech by James L. Flanagan, US Air Force, 24 May 1960. An early speech recognition system based on formant (peak frequency) analysis.
- A Historical Perspective of Speech Recognition by Raj Reddy (an AI researcher at Carnegie Mellon), James Baker (founder of Dragon), and Xuedong Huang (of Microsoft). Speech recognition pioneers look back on the advances they helped to inspire in this four-minute discussion.
Text copyright © Chris Woodford 2007, 2020. All rights reserved. Full copyright notice and terms of use .
Rate this page
Tell your friends, cite this page, more to explore on our website....
- Get the book
- Send feedback
How Does Speech Recognition Technology Work?
Last Updated July 12, 2021

Smart phones, TVs, tablets, speakers, laptops, automated cars are everywhere these days. But we take for granted how much work goes into creating speech recognition technology.
It seems straightforward to us now. But for every breakthrough in speech recognition, there have been countless failures and dead ends.
Learn more about our speech data solutions.
But between 2013 and 2017, Google’s word accuracy rate rose from 80% to an impressive 95%, and it was expected that 50% of all Google searches would be voice queries in 2020 .
That represents staggering growth, but it didn’t come easily.
It took decades to develop speech recognition technology , and we have yet to reach its zenith.
In this article, we will outline how speech recognition technology works. We’ll also discuss the obstacles that remain along the path of perfecting it.
The Basics of Speech Recognition Technology
At its core, speech recognition technology is the process of converting audio into text for the purpose of conversational AI and voice applications.
Speech recognition breaks down into three stages:
- Automated speech recognition (ASR) : The task of transcribing the audio
- Natural language processing (NLP) : Deriving meaning from speech data and the subsequent transcribed text
- Text-to-speech (TTS): Converts text to human-like speech
Where we see this play out most commonly is with virtual assistants. Think Amazon Alexa, Apple’s Siri, and Google Home, for example.
We speak, they interpret what we are trying to ask of them, and they respond to the best of their programmed abilities.
The process begins by digitizing a recorded speech sample with ASR . The speaker’s unique voice template is broken up into discrete segments made up of several tones.
These spectrograms are further divided into timesteps using the short-time Fourier transform .
Each spectrogram is analyzed and transcribed based on the NLP algorithm that predicts the probability of all words in a language’s vocabulary. A contextual layer is added to help correct any potential mistakes. Here the algorithm considers both what was said, and the likeliest next word based on its knowledge of the given language.
Finally, the device will verbalize the best possible response to what it has heard and analyzed using TTS.
It’s not all that unlike how we learn language as children.
How to Learn a Language
From day one of a child’s life, they hear words used all around them. Parents speak to the child knowing they can’t answer yet. But even though the child doesn’t respond, they are absorbing all kinds of verbal cues, including intonation, inflection, and pronunciation.
This is the input stage. The child’s brain is forming patterns and connections based on how their parents use language. Though humans are born to listen and understand, we train our entire lives to apply this natural ability to detecting patterns in one or more languages.
It takes five or six years to be able to have a full conversation, and then we spend the next 15 years in school collecting more data and increasing our vocabulary. By the time we reach adulthood, we can interpret meaning almost instantly.
Voice recognition technology works in a similar way. The speech recognition software breaks the speech down into bits it can interpret, converts it into a digital format, and analyzes the pieces of content.
It then makes determinations based on previous data and common speech patterns, making hypotheses about what the user is saying. After determining what the user most likely said, the smart device can offer back the best possible response.
But whereas humans have refined our process, we are still figuring out the best practices for AI. We have train them in the same way our parents and teachers trained us, and that involves a lot of manpower, research, and innovation .
Speech Recognition Technology in Action
Shazam is a great example of how speech recognition technology works. The popular app– purchased by Apple in 2018 for $400M —can identify music, movies, commercials, and TV shows based on a short audio sample using the microphone on your device.
When you hit the Shazam button, then, you’re starting an audio recording of your surroundings. It can differentiate the ambient noise from the intended source material, identify the song’s pattern, and compare the audio recording to its database.
It will then track down the specific track that was playing and supply the information to its curious end-user.
While this is a nice and simple example among other more recent innovations in speech technology , it’s not always that clean of a process.
The Challenges of Accurate Speech Recognition Technology
Imagine this: You’re driving around and make a voice request to call your friend Justin, but the software misunderstands you.
Instead, it starts blasting Justin Bieber’s latest infuriatingly catchy song. As you hurriedly attempt to change the song, you are obviously not in prime condition to be watching the road.
Speech recognition technology isn’t just about helping you to answer a trivia question, nor is it solely about making life easier.
It’s also about safety, and as beneficial as speech recognition technology may seem in an ideal scenario, it’s proven to be potentially hazardous when implemented before it has high enough accuracy.
Let’s look at the two main areas where challenges are most present.
Language & Speaker Differences
To take this technology around the word, engineers must program the ability to understand infinite more variations, including specific languages, dialects, and accents.
That requires the collection of massive amounts of data .
English speech recognition technology developed for North American accents and dialects does not work well in other parts of the world. For global projects, important considerations include:
- Different languages (e.g. English, French, and German)
- Non-native accents (e.g. A native-French speaker speaking English)
- Different phrasing (e.g. US vs. British English phrases)
Recording Challenges
Background noises can easily throw a speech recognition device off track. That’s because it doesn’t inherently have the ability to distinguish between your unique voice and sounds like a dog barking or a helicopter flying overhead.
Engineers have to program that ability into the device. They collect specific data that includes these ambient sounds and then program the device to filter them out.
The device or software separates the noise (individualistic vocal patterns, accents, ambient sounds, and so on) from the keywords and turns it into text that the software can understand.
Other recording challenges include:
- Low-quality recording tools
- More than one person speaking at a time
- Use of abbreviations or slang
- Homophones like ‘there/their/they’re,’ and ‘ ‘right/write’ that sound the same but have different meanings
There are a few ways around these issues. They’re typically solved through customized data collection projects.
Voiceover artists can be recruited to record specific phrases with specific intonations, or in-field collection can be used to collect speech in a more real-world scenario. For example, we collected speech data for Nuance directly from the cabin of a car to simulate the in-car audio environment.
So next time Siri fails to understand your existential questions, or your Amazon Alexa plays the wrong music, remember that this technology is mind-blowingly complex yet still impressively accurate.
A Work in Progress
Summa Linguae Technologies collects and processes training and testing data for AI-powered solutions , including voice assistants, wearables, autonomous vehicles, and more.
We have worked on a number of speech recognition-related projects, including in-car speech recognition data collection and voice-controlled fitness wearables .
Through these projects and many more, we have seen first-hand the complexities of speech recognition technology. We’ve also devised data solutions to help make the devices more usable and inclusive.
Contact us today to see how we can help your company with data solutions for your speech recognition technology.
Related Posts

How do life science companies use AI?
Thanks to AI, it’s become easier and more efficient to introduce new drugs and improve disease detection—t...

Amazon Flags Low-Quality Training Data for LLMs
The tools are out there to gather large swaths of training data for LLMS, but human touchpoints help clean...

Should you trust voice assistants for medical advice?
If you have specific health concerns or questions, it’s always best to consult a qualified healthcar...
Summa Linguae uses cookies to allow us to better understand how the site is used. By continuing to use this site, you consent to this policy.
How Does Speech Recognition Work? (9 Simple Questions Answered)
- by Team Experts
- July 2, 2023 July 3, 2023
Discover the Surprising Science Behind Speech Recognition – Learn How It Works in 9 Simple Questions!
Speech recognition is the process of converting spoken words into written or machine-readable text. It is achieved through a combination of natural language processing , audio inputs, machine learning , and voice recognition . Speech recognition systems analyze speech patterns to identify phonemes , the basic units of sound in a language. Acoustic modeling is used to match the phonemes to words , and word prediction algorithms are used to determine the most likely words based on context analysis . Finally, the words are converted into text.
What is Natural Language Processing and How Does it Relate to Speech Recognition?
How do audio inputs enable speech recognition, what role does machine learning play in speech recognition, how does voice recognition work, what are the different types of speech patterns used for speech recognition, how is acoustic modeling used for accurate phoneme detection in speech recognition systems, what is word prediction and why is it important for effective speech recognition technology, how can context analysis improve accuracy of automatic speech recognition systems, common mistakes and misconceptions.
Natural language processing (NLP) is a branch of artificial intelligence that deals with the analysis and understanding of human language. It is used to enable machines to interpret and process natural language, such as speech, text, and other forms of communication . NLP is used in a variety of applications , including automated speech recognition , voice recognition technology , language models, text analysis , text-to-speech synthesis , natural language understanding , natural language generation, semantic analysis , syntactic analysis, pragmatic analysis, sentiment analysis, and speech-to-text conversion. NLP is closely related to speech recognition , as it is used to interpret and understand spoken language in order to convert it into text.
Audio inputs enable speech recognition by providing digital audio recordings of spoken words . These recordings are then analyzed to extract acoustic features of speech, such as pitch, frequency, and amplitude. Feature extraction techniques , such as spectral analysis of sound waves, are used to identify and classify phonemes . Natural language processing (NLP) and machine learning models are then used to interpret the audio recordings and recognize speech. Neural networks and deep learning architectures are used to further improve the accuracy of voice recognition . Finally, Automatic Speech Recognition (ASR) systems are used to convert the speech into text, and noise reduction techniques and voice biometrics are used to improve accuracy .
Machine learning plays a key role in speech recognition , as it is used to develop algorithms that can interpret and understand spoken language. Natural language processing , pattern recognition techniques , artificial intelligence , neural networks, acoustic modeling , language models, statistical methods , feature extraction , hidden Markov models (HMMs), deep learning architectures , voice recognition systems, speech synthesis , and automatic speech recognition (ASR) are all used to create machine learning models that can accurately interpret and understand spoken language. Natural language understanding is also used to further refine the accuracy of the machine learning models .
Voice recognition works by using machine learning algorithms to analyze the acoustic properties of a person’s voice. This includes using voice recognition software to identify phonemes , speaker identification, text normalization , language models, noise cancellation techniques , prosody analysis , contextual understanding , artificial neural networks, voice biometrics , speech synthesis , and deep learning . The data collected is then used to create a voice profile that can be used to identify the speaker .
The different types of speech patterns used for speech recognition include prosody , contextual speech recognition , speaker adaptation , language models, hidden Markov models (HMMs), neural networks, Gaussian mixture models (GMMs) , discrete wavelet transform (DWT), Mel-frequency cepstral coefficients (MFCCs), vector quantization (VQ), dynamic time warping (DTW), continuous density hidden Markov model (CDHMM), support vector machines (SVM), and deep learning .
Acoustic modeling is used for accurate phoneme detection in speech recognition systems by utilizing statistical models such as Hidden Markov Models (HMMs) and Gaussian Mixture Models (GMMs). Feature extraction techniques such as Mel-frequency cepstral coefficients (MFCCs) are used to extract relevant features from the audio signal . Context-dependent models are also used to improve accuracy . Discriminative training techniques such as maximum likelihood estimation and the Viterbi algorithm are used to train the models. In recent years, neural networks and deep learning algorithms have been used to improve accuracy , as well as natural language processing techniques .
Word prediction is a feature of natural language processing and artificial intelligence that uses machine learning algorithms to predict the next word or phrase a user is likely to type or say. It is used in automated speech recognition systems to improve the accuracy of the system by reducing the amount of user effort and time spent typing or speaking words. Word prediction also enhances the user experience by providing faster response times and increased efficiency in data entry tasks. Additionally, it reduces errors due to incorrect spelling or grammar, and improves the understanding of natural language by machines. By using word prediction, speech recognition technology can be more effective , providing improved accuracy and enhanced ability for machines to interpret human speech.
Context analysis can improve the accuracy of automatic speech recognition systems by utilizing language models, acoustic models, statistical methods , and machine learning algorithms to analyze the semantic , syntactic, and pragmatic aspects of speech. This analysis can include word – level , sentence- level , and discourse-level context, as well as utterance understanding and ambiguity resolution. By taking into account the context of the speech, the accuracy of the automatic speech recognition system can be improved.
- Misconception : Speech recognition requires a person to speak in a robotic , monotone voice. Correct Viewpoint: Speech recognition technology is designed to recognize natural speech patterns and does not require users to speak in any particular way.
- Misconception : Speech recognition can understand all languages equally well. Correct Viewpoint: Different speech recognition systems are designed for different languages and dialects, so the accuracy of the system will vary depending on which language it is programmed for.
- Misconception: Speech recognition only works with pre-programmed commands or phrases . Correct Viewpoint: Modern speech recognition systems are capable of understanding conversational language as well as specific commands or phrases that have been programmed into them by developers.
Speech Recognition
Speech recognition technology enables machines to understand and transcribe human speech, paving the way for applications in various fields such as military, healthcare, and personal assistance. This article explores the advancements, challenges, and practical applications of speech recognition systems.
Speech recognition systems have evolved over the years, with recent developments focusing on enhancing their performance in noisy conditions and adapting to different accents. One approach to improve performance is through speech enhancement, which involves processing speech signals to reduce noise and improve recognition accuracy. Another approach is to use data augmentation techniques, such as generating synthesized speech, to train more robust models.
Recent research in the field of speech recognition has explored various aspects, such as:
1. Evaluating the effectiveness of Gammatone Frequency Cepstral Coefficients (GFCCs) compared to Mel Frequency Cepstral Coefficients (MFCCs) for emotion recognition in speech.
2. Investigating the feasibility of using synthesized speech for training speech recognition models and improving their performance.
3. Studying the impact of non-speech sounds, such as laughter, on speaker recognition systems.
These studies have shown promising results, with GFCCs outperforming MFCCs in speech emotion recognition and the inclusion of non-speech sounds during training improving speaker recognition performance.
Practical applications of speech recognition technology include:
1. Speech-driven text retrieval: Integrating speech recognition with text retrieval methods to enable users to search for information using spoken queries.
2. Emotion recognition: Analyzing speech signals to identify the emotional state of the speaker, which can be useful in customer service, mental health, and entertainment industries.
3. Assistive technologies: Developing tools for people with disabilities, such as speech-to-text systems for individuals with hearing impairments or voice-controlled devices for those with mobility limitations.
A company case study in this field is Mozilla's Deep Speech, an end-to-end speech recognition system based on deep learning. The system is trained using Recurrent Neural Networks (RNNs) and multiple GPUs, primarily on American-English accent datasets. By employing transfer learning and data augmentation techniques, researchers have adapted Deep Speech to recognize Indian-English accents, demonstrating the potential for the system to generalize to other English accents.
In conclusion, speech recognition technology has made significant strides in recent years, with advancements in machine learning and deep learning techniques driving improvements in performance and adaptability. As research continues to address current challenges and explore new applications, speech recognition systems will become increasingly integral to our daily lives, enabling seamless human-machine interaction.
What is a speech recognition example?
Speech recognition technology can be found in various applications, such as virtual assistants like Apple's Siri, Amazon's Alexa, and Google Assistant. These systems allow users to interact with their devices using voice commands, enabling hands-free control and natural language processing to perform tasks like setting reminders, searching the internet, or controlling smart home devices.
What do you mean by speech recognition?
Speech recognition refers to the process of converting spoken language into written text or commands that a computer can understand and process. It involves analyzing the acoustic properties of speech, such as pitch, intensity, and duration, to identify the words and phrases being spoken. This technology enables machines to understand human speech, allowing for more natural and intuitive interactions between humans and computers.
What are the three steps of speech recognition?
The three main steps of speech recognition are: 1. Feature extraction: This step involves analyzing the raw audio signal and extracting relevant features, such as pitch, intensity, and spectral characteristics. Commonly used features include Mel Frequency Cepstral Coefficients (MFCCs) and Gammatone Frequency Cepstral Coefficients (GFCCs). 2. Acoustic modeling: In this step, the extracted features are used to train a machine learning model, such as a Hidden Markov Model (HMM) or a deep learning model like a Recurrent Neural Network (RNN). The model learns to associate the features with specific phonemes or words, enabling it to recognize speech patterns. 3. Language modeling: This step involves creating a statistical model of the language being recognized, which helps the system predict the most likely sequence of words given the recognized phonemes. Language models can be based on n-grams, which are sequences of n words, or more advanced techniques like neural networks.
What is the difference between voice recognition and speech recognition?
Voice recognition, also known as speaker recognition, is the process of identifying a specific individual based on their unique vocal characteristics. It focuses on recognizing the speaker's identity rather than the content of their speech. In contrast, speech recognition is concerned with understanding and transcribing the words and phrases being spoken, regardless of the speaker's identity.
How does deep learning improve speech recognition?
Deep learning techniques, such as Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs), have significantly improved speech recognition performance by enabling the automatic extraction of complex features from raw audio signals. These models can learn hierarchical representations of speech data, capturing both short-term and long-term dependencies in the audio signal. Additionally, deep learning models can be trained on large amounts of data, allowing them to generalize better and recognize a wide range of accents and speaking styles.
What are the current challenges in speech recognition?
Some of the current challenges in speech recognition include: 1. Handling noisy environments: Recognizing speech in the presence of background noise or competing voices remains a significant challenge, as it can degrade the quality of the audio signal and make it difficult for the system to accurately identify words and phrases. 2. Adapting to different accents and dialects: Speech recognition systems need to be able to understand and adapt to various accents and dialects, as pronunciation and vocabulary can vary significantly between speakers. 3. Recognizing emotions and non-speech sounds: Identifying the emotional state of the speaker and recognizing non-speech sounds, such as laughter or sighs, can help improve the overall performance and usability of speech recognition systems.
What is the future of speech recognition technology?
The future of speech recognition technology is likely to involve continued advancements in machine learning and deep learning techniques, leading to improved performance and adaptability. We can expect to see more robust systems capable of handling noisy environments, recognizing a wider range of accents and dialects, and incorporating emotion recognition and non-speech sounds. Additionally, as speech recognition becomes more integrated into our daily lives, we will likely see new applications and use cases emerge, such as real-time language translation, advanced voice-controlled interfaces, and more personalized virtual assistants.
Speech Recognition Further Reading
Explore more machine learning terms & concepts.
Spectral clustering is a powerful technique for identifying clusters in data, particularly when the clusters have irregular shapes or are highly anisotropic. This article provides an overview of spectral clustering, its nuances, complexities, and current challenges, as well as recent research and practical applications. Spectral clustering works by using the global information embedded in eigenvectors of an inter-item similarity matrix. This allows it to identify clusters of irregular shapes, which is a limitation of traditional clustering approaches like k-means and agglomerative clustering. However, spectral clustering typically involves two steps: first, the eigenvectors of the associated graph Laplacian are used to embed the dataset, and second, the k-means clustering algorithm is applied to the embedded dataset to obtain the labels. This two-step process complicates the theoretical analysis of spectral clustering. Recent research has focused on improving the efficiency and stability of spectral clustering. For example, one study introduced a method called Fast Spectral Clustering based on quad-tree decomposition, which significantly reduces the computational complexity and memory cost of the algorithm. Another study assessed the stability of spectral clustering against edge perturbations in the input graph using the notion of average sensitivity, providing insights into the algorithm's performance in real-world applications. Practical applications of spectral clustering include image segmentation, natural language processing, and network analysis. In image segmentation, spectral clustering has been shown to outperform traditional methods like Normalized cut in terms of computational complexity and memory cost, while maintaining comparable clustering accuracy. In natural language processing, spectral clustering has been used to cluster lexicons of words, with results showing that spectral clusters produce similar results to Brown clusters and outperform other clustering methods. In network analysis, spectral clustering has been used to identify communities in large-scale networks, with experiments demonstrating its stability against edge perturbations when there is a clear cluster structure in the input graph. One company case study involves the use of spectral clustering in a lifelong machine learning framework, called Lifelong Spectral Clustering (L2SC). L2SC aims to efficiently learn a model for a new spectral clustering task by selectively transferring previously accumulated experience from a knowledge library. This approach has been shown to effectively improve clustering performance when compared to other state-of-the-art spectral clustering algorithms. In conclusion, spectral clustering is a versatile and powerful technique for identifying clusters in data, with applications in various domains. Recent research has focused on improving its efficiency, stability, and applicability to dynamic networks, making it an increasingly valuable tool for data analysis and machine learning.
Speech synthesis is the process of generating human-like speech from text, playing a crucial role in human-computer interaction. This article explores the advancements, challenges, and practical applications of speech synthesis technology. Speech synthesis has evolved significantly in recent years, with researchers focusing on improving the naturalness, emotion, and speaker identity of synthesized speech. One such development is the Multi-task Anthropomorphic Speech Synthesis Framework (MASS), which can generate speech with specified emotion and speaker identity. This framework consists of a base Text-to-Speech (TTS) module and two voice conversion modules, enabling more realistic and versatile speech synthesis. Recent research has also investigated the use of synthesized speech as a form of data augmentation for low-resource speech recognition. By experimenting with different types of synthesizers, researchers have identified new directions for future research in this area. Additionally, studies have explored the incorporation of linguistic knowledge to visualize and evaluate synthetic speech model training, such as analyzing vowel spaces to understand how a model learns the characteristics of a specific language or accent. Some practical applications of speech synthesis include: 1. Personalized spontaneous speech synthesis: This approach focuses on cloning an individual's voice timbre and speech disfluency, such as filled pauses, to create more human-like and spontaneous synthesized speech. 2. Articulation-to-speech synthesis: This method synthesizes speech from the movement of articulatory organs, with potential applications in Silent Speech Interfaces (SSIs). 3. Data augmentation for speech recognition: Synthesized speech can be used to enhance the training data for speech recognition systems, improving their performance in various domains. A company case study in this field is WaveCycleGAN2, which aims to bridge the gap between natural and synthesized speech waveforms. The company has developed a method that alleviates aliasing issues in processed speech waveforms, resulting in higher quality speech synthesis. In conclusion, speech synthesis technology has made significant strides in recent years, with researchers focusing on improving the naturalness, emotion, and speaker identity of synthesized speech. By incorporating linguistic knowledge and exploring new applications, speech synthesis has the potential to revolutionize human-computer interaction and enhance various industries.
- Subscribe to our newsletter for more articles like this

Voice Control
Command your products, devices, software, and applications.

Voice Dictation
Voice Dictation recognizes and transcribes spoken language into punctuated text.

Voice Synthesis
Voice Synthesis allows you to get instant audio feedback from devices.

Voice Biometrics
Voice Biometrics allows you to authenticate and identify users.

Speech Enhancement
Enhancing voice quality and facilitating smoother operation of voice-activated systems in professional noisy environments.

A word or a phrase that switches your device from standby to active listening mode.
Discover all our solutions

Allows users to trigger the speech recognition process.

Automatic Speech Recognition (ASR)
Transform human voice into text even with complex vocabulary.

Identify and/or authenticate users using a Voice Print.

Natural Language Understanding (NLU)
Enable users with flexible and natural voice commands.

Speech Synthesis (TTS)
Produce life-like voices able to humanize products and give audio feedback.

Audio Enhancement (AFE)
Make sure that the sound signal from voice is crystal clear to boost recognition’s accuracy.
Discover the Voice Development Kit
Smart Glasses & XR Wearables
Voice-enabled smart glasses & head-mounted displays…
Supply Chain & Industry 4.0
Productivity-oriented solutions like Voice Picking…
Field Services & Maintenance (MRO)
Using voice to fill maintenance and intervention reports…
Explore all the use cases
Why choose the VDK ?
Buidling Voice AIs with the VDK is nothing like other solutions, here’s why.
Documentation
Everything you need to know about the VDK in order to get started in the best possible way.
Start developing
Newsroom & Press
Learn more about Vivoka
Speech Recognition: How it works and what it is made of

Written by Aurélien Chapuzet
Discover | speech recognition, large language models and chatgpt, speech-to-text: uses & evolution, build a custom voice command in 5 easy steps.
Speech recognition is a proven technology. Indeed, voice interfaces and voice assistants are now more powerful than ever and are developing in many fields. This exponential and continuous growth is leading to a diversification of speech recognition applications and related technologies.
Currently, we are in an era governed by cognitive technologies where we find for instance virtual or augmented reality, visual recognition and speech recognition!
However, even if the “Voice Generation” are the most apt to conceptualize this technology because they are born in the middle of its expansion, many people talk about it, but few really know how it works and what solutions are available.
And it is for this very reason that we propose you to discover speech recognition in detail through this article. Of course, this is just the basics to understand the field of speech technologies, other articles in our blog cover some topics in more detail.
“Strength in numbers”: the components of speech recognition
For the following explanations, we assume that “speech recognition” corresponds to a complete cycle of voice use.
Speech recognition is based on the complementarity between several technologies from the same field. To present all this, we will detail each of them chronologically, from the moment the individual speaks, until the order is carried out.
It should be noted that the technologies presented below can be used independently of each other and cover a wide range of applications. We will come back to this later.
The wake word, activate speech recognition, with voice
The first step that initiates the whole process is called the wake word. The main purpose of this first technology in the cycle is to activate the user’s voice to detect the voice command he or she wishes to perform.
Here, it is literally a matter of “waking up” the system. Although there are other ways of proceeding to trigger the listening, keeping the use of the voice throughout the cycle is, in our opinion, essential. Indeed, it allows us to propose a linear experience with voice as the only interface.
The trigger keyword inherently has several interests with respect to the design of voice assistants .
In our context, one of the main fears about speech recognition is the protection of personal data related to audio recording. With the recent appearance of the GDPR (General Data Protection Regulation) , this fear regarding privacy and intimacy has been further amplified, leading to the creation of a treaty to regulate it.
This is why the trigger word is so important. By conditioning the voice recording phase with this action, as long as the trigger word has not been clearly identified, nothing is recorded theoretically. Yes, theoretically, because depending on the company’s data policy, everything is relative. To prevent this, embedded (offline) speech recognition is an alternative.
Once the activation is confirmed, only the sentences carrying the intent of the action to be performed will be recorded and analyzed to ensure the use case works.
To learn more about the Wake-up Word, we invite you to read our article on Google’s Wake-up Word and the best practices to find your own!
Speech to Text (STT) , identifying and transcribing voice into text
Once speech recognition is initiated with the trigger word, it is necessary to exploit the voice. To do this, it is first essential to record and digitize it with Speech to Text technology (also known as automatic speech recognition ).
During this stage, the voice is captured in sound frequencies (in the form of audio files, like music or any other noise) that can be used later.
Depending on the listening environment, sound pollution may or may not be present. In order to improve the recording of these frequencies and therefore their reliability, different treatments can be applied.
- Normalization to remove peaks and valleys in the frequencies in order to harmonize the whole.
- The removal of background noise to improve audio quality.
- The cutting of segments into phonemes (which are distinctive units within frequencies, expressed in thousandths of a second, allowing words to be distinguished from one another.
The frequencies, once recorded, can be analyzed in order to associate each phoneme with a word or a group of words to constitute a text. This step can be done in different ways, but one method in particular is the state of the art today: Machine Learning.
A sub-part of this technology is called Deep Learning: an algorithm recreating a neural network, capable of analyzing a large amount of information and building a database listing the associations between frequencies and words. Thus, each association will create a neuron that will be used to deduce new correspondences.
Therefore, the more information there is, the more precise the model is statistically speaking and capable of taking into account the general context to assign the best word according to the others already defined.
Limiting STT errors is essential to obtain the most reliable information to proceed with the next steps.
NLP (Natural Language Processing), translating human language into machine language
Once the previous steps have been completed, the textual data is sent directly to the NLP (Natural Language Processing) module. The main purpose of this technology is to analyze the sentence and extract a maximum of linguistic data.
To do this, it starts by associating tags to the words of the sentence, this is called tokenization. These are actually “tags” that are applied to each word in order to characterize it. For example, “Open” will be defined as the verb defining an action, “the” as the determinant referring to “ Voice Development Kit ” which is a proper noun but also a COD etc… and this for each element of the sentence.
Once these first elements have been identified, it is necessary to give meaning to the orders resulting from the speech recognition. This is why two complementary analyses are performed.
First of all, syntactic analysis aims to model the structure of the sentence. It is a question here of identifying the place of the words within the whole but also their relative position compared to the others in order to understand their relations.
To complete and finish, the semantic analysis which, once the nature and the position of the words are found, will try to understand their meaning individually but also when they are assembled in the sentence in order to translate a general intention of the user.
The importance of NLP in speech recognition lies in its ability to translate textual elements (i.e. words and sentences) into normalized orders, including meaning and intent, that can be interpreted by the associated artificial intelligence and carried out.
Artificial intelligence, a necessary ally of speech recognition
First of all, artificial intelligence, although integrated in the process of the previous technologies, is not always essential to achieve the use cases. Indeed, if we are talking about connected technologies (i.e. Cloud), AI will be useful. Especially since the complexity of some use cases, especially the information to be correlated to produce them, makes it mandatory.
For example, it is sometimes necessary to compare several pieces of information with actions to be carried out, integrations of external or internal services or databases to be consulted.
In other words, artificial intelligence is the use case itself, the concrete action that will result from the voice interface. Depending on the context of use and the nature of the order, the elements requested and the results given will be different.
Let’s take a case in point. Vivoka has created a connected motorcycle helmet that allows to use functionalities with the voice. Different uses are available, such as using GPS or music.
The request “Take me to a gas station on the way” will return a normalized command to the artificial intelligence with the user’s intention:
- Context: Vehicle fuel type, Price preference (affects distance travelled)
- External services: Call the API of the GPS solution provider
- Action to be performed: Keep the current route, add a step on the route
Here, the intelligence used by our system will submit information and a request to an external service that has a specialized intelligence to send us back the result to operate on the user.
AI is therefore a key component in many situations. However, for embedded functionalities (i.e. offline), the needs are less, being closer to the realization of simple commands such as navigation on an interface or the reporting of actions . It is a question here of having specific use cases that do not require consulting multiple information.
TTS (Text to Speech) , voice to answer and inform the user
Finally, the TTS (Text-to-Speech) concludes the process. It corresponds to the feedback of the system which is expressed through a synthetic voice. In the same spirit as the Wake-up Word, it closes the speech recognition by answering vocally in order to keep the homogeneity of the conversational interface.
The voice synthesis is built from human voices and sounds diversified according to language, gender, age or mood. Synthetic voices are thus generated in real time to dictate words or sentences through a phonetic assembly.
This speech recognition technology is useful for communicating information to the user, a symbol of a complete human-machine interface and also of a well-designed user experience.
Similarly, it represents an important dimension of Voice Marketing because the synthesized voices can be customized to match the image of the brands that use it.
The different speech recognition solutions
The speech recognition market is a fast-moving environment. As use cases are constantly being born and reinvented with technological progress, the adoption of speech solutions is driving innovation and attracting many players.
Today on the market, we can count major categories of uses related to speech recognition. Among them, we can mention :
Voice assistants
We find the GAFAs and their multi-support virtual assistants (smart speaker, telephone, etc.) but also initiatives from other companies. The personalization of voice assistants is a trend on the fringe of the market domination by GAFA, where brands want to regain their technical governance.
For example, KSH and its connected motorcycle helmet are among those players with specific needs, both marketing and functional.
Professional voice interfaces
We are talking about productivity tools for employees. One of the fastest growing sectors is the supply chain with the pick-by-voice . This is a voice device that allows operators to use speech recognition to work more efficiently and safely (hands-free, concentration…). The voice commands are similar to reports of actions and confirmations of operations performed.
There are many possibilities for companies to gain in productivity. Some use cases already exist and others will be created.
Speech recognition software
Voice dictation, for example, is a tool that is already used by thousands of individuals, personally or professionally (DS Avocats for instance). It allows you to dictate text (whether emails or reports) at a rate of 180 words per minute, whereas manual input is on average 60 words per minute. The tool brings productivity and comfort to document creation through a voice transcription engine adapted to dictation.
Connected objects (Internet of Things IoT)
The IoT world is also fond of voice innovations. This often concerns navigation or device use functionalities. Whether it is home automation equipment or more specialized products such as connected mirrors, speech recognition promises great prospects.
As the more experienced among you will have understood, this article explains in a succinct and introductory way a complex technology and uses. Similarly, the tools we have presented are a specific design of speech technologies, not the norm, although they are the most common designs.
To learn more about speech recognition and its capabilities, we recommend you browse our blog for more information or contact us directly to discuss the matter!
For developers, by developers
Try our voice solutions now
Sign up first on the console.
Before integrating with VDK, test our online playground: Vivoka Console.
Develop and test your use cases
Design, create and try all of your features.
Submit your project
Share your project and talk about it with our expert for real integration.

It's always the right time to learn more about voice technologies and their applications

Christophe Couvreur, Esteemed AI and Voice Technology Executive, Named CEO of Vivoka
Latest , Press Releases
Vivoka, a leader in voice-enabled technology solutions, is thrilled to announce the appointment of Dr. Christophe Couvreur as its new Chief Executive Officer. Christophe Couvreur brings over two...

Jun 19, 2023 | Discover , Latest

NLU model best practices to improve accuracy
Jun 5, 2023 | Adopt , Natural Language Understanding

The future of Warehousing: Voice Directed Warehouse Operations
May 23, 2023 | Adopt , Speech Recognition

5 business applications to leverage embedded NLU in your products & services
May 10, 2023 | Adopt , Natural Language Understanding , Technology

Natural Language Processing – An Overview on what makes an AI “conversational”
Apr 25, 2023 | Discover , Natural Language Understanding , Speech Recognition , Speech Synthesis , Technology
Privacy Overview
| Cookie | Duration | Description |
|---|---|---|
| cookielawinfo-checkbox-analytics | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics". |
| cookielawinfo-checkbox-functional | 11 months | The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional". |
| cookielawinfo-checkbox-necessary | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary". |
| cookielawinfo-checkbox-others | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other. |
| cookielawinfo-checkbox-performance | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance". |
| viewed_cookie_policy | 11 months | The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data. |
The 5 Best Open Source Speech Recognition Engines & APIs
Video content is taking over many spaces online – in fact, more than 80% of online traffic today consists of video. Video is a tool for brands to showcase their latest and greatest products, shoot amateur creators to the tops of the charts, and even help people connect with friends and family all over the world.
With this much video out in the world, it becomes more and more important to ensure that you’re meeting all accessibility requirements and making sure that your video can be viewed and understood by all – even if they’re not able to listen to the sound included within your content.
Learn More about Rev’s Best-in-Class Speech-to-Text Technology
Rev › Blog › Resources › Other Resources › Speech-to-Text APIs › The 5 Best Open Source Speech Recognition Engines & APIs
In this article, we provide a breakdown of five of the best free-to-use open source speech recognition services along with details on how you can get started.
Mozilla DeepSpeech
DeepSpeech is a Github project created by Mozilla, the famous open source organization which brought you the Firefox web browser. Their model is based on the Baidu Deep Speech research paper and is implemented using Tensorflow (which we’ll talk about later).
Pros of Mozilla DeepSpeech
- They provide a pre-trained English model, which means you can use it without sourcing your own data. However, if you do have your own data, you can train your own model, or take their pre-trained model and use transfer learning to fine tune it on your own data.
- DeepSpeech is a code-native solution, not an API . That means you can tweak it according to your own specifications, providing the highest level of customization.
- DeepSpeech also provides wrappers into the model in a number of different programming languages, including Python, Java, Javascript, C, and the .NET framework. It can also be compiled onto a Raspberry Pi device which is great if you’re looking to target that platform for applications.
Cons of Mozilla DeepSpeech
- Due to some layoffs and changes in organization priorities, Mozilla is winding down development on DeepSpeech and shifting its focus towards applications of the tech. This could mean much less support when bugs arise in the software and issues need to be addressed.
- The fact that DeepSpeech is provided solely as a Git repo means that it’s very bare bones. In order to integrate it into a larger application, your company’s developers would need to build an API around its inference methods and generate other pieces of utility code for handling various aspects of interfacing with the model.
2. Wav2Letter++
The Wav2Letter++ speech engine was created in December 2018 by the team at Facebook AI Research. They advertise it as the first speech recognition engine written entirely in C++ and among the fastest ever.
Pros of Wav2Letter++
- It is the first ASR system which utilizes only convolutional layers , not recurrent ones. Recurrent layers are common to nearly every modern speech recognition engine as they are particularly useful for language modeling and other tasks which contain long-range dependencies.
- Within Wav2Letter++ the code allows you to either train your own model or use one of their pretrained models. They also have recipes for matching results from various research papers, so you can mix and match components in order to fit your desired results and application.
Cons of Wav2Letter++
- The downsides of Wav2Letter++ are much the same as with DeepSpeech. While you get a very fast and powerful model, this power comes with a lot of complexity. You’ll need to have deep coding and infrastructure knowledge in order to be able to get things set up and working on your system.
Kaldi is an open-source speech recognition engine written in C++, which is a bit older and more mature than some of the others in this article. This maturity has both benefits and drawbacks.
Pros of Kaldi
- On the one hand, Kaldi is not really focused on deep learning, so you won’t see many of those models here. They do have a few, but deep learning is not the project’s bread and butter. Instead, it is focused more on classical speech recognition models such as HMMs, FSTs and Gaussian Mixture Models.
- Kaldi methods are very lightweight, fast, and portable.
- The code has been around a long time, so you can be assured that it’s very thoroughly tested and reliable.
- They have good support including helpful forums, mailing lists, and Github issues trackers which are frequented by the project developers.
- Kaldi can be compiled to work on some alternative devices such as Android.
Cons of Kaldi
- Because Kaldi is not focused on deep learning, you are unlikely to get the same accuracy that you would using a deep learning method.
4. Open Seq2Seq
Open Seq2Seq is an open-source project created at Nvidia. It is a bit more general in that it focuses on any type of seq2seq model, including those used for tasks such as machine translation, language modeling, and image classification. However, it also has a robust subset of models dedicated to speech recognition.
The project is somewhat more up-to-date than Mozilla’s DeepSpeech in that it supports three different speech recognition models: Jasper DR 10×5, Baidu’s DeepSpeech2, and Facebook’s Wav2Letter++.
Pros of Seq2Seq
- The best of these models, Jasper DR 10×5, has a word error rate of just 3.61%.
- Note that the models do take a fair amount of computational power to train. They estimate that training DeepSpeech2 should take about a day using a GPU with 12 GB of memory.
Cons of Seq2Seq
- One negative with Open Seq2Seq is that the project has been marked as archived on Github, meaning that development has most likely stopped. Thus, any errors that arise in the code will be up to users to solve individually as bug fixes are not being merged into the main codebase.
5. Tensorflow ASR
Tensorflow ASR is a speech recognition project on Github that implements a variety of speech recognition models using Tensorflow. While it is not as well known as the other projects, it seems more up to date with its most recent release occurring in just May of 2021.
The author describes it as “almost state of the art” speech recognition and implements many recent models including DeepSpeech 2, Conformer Transducer, Context Net, and Jasper. The models can be deployed using TFLite and they will likely integrate nicely into any existing machine-learning system which uses Tensorflow. It also contains pretrained models for a couple of foreign languages including Vietnamese and German.
What Makes Rev AI Different
While open-source speech recognition systems give you access to great models for free, they also undeniably make things complicated. This is simply because speech recognition is complicated. Even when using an open-source pre-trained model, it takes a lot of work to get the model fine-tuned on your data, hosted on a server, and to write APIs to interface with it. Then you have to worry about keeping the system running smoothly and handling bugs and crashes when they inevitably do occur.
The great thing about using a paid provider such as Rev is that they handle all those headaches for you. You get a system with guaranteed 99.9+% uptime with a callable API that you can easily hook your product into. In the unlikely event that something does go wrong, you also get direct access to Rev’s development team and fantastic client support.
Another advantage of Rev is that it’s the most accurate speech recognition engine in the world. Their system has been benchmarked against the ones provided by all the other major industry players such as Amazon, Google, Microsoft, etc. Rev comes out on top every single time with the lowest average word error rate across multiple, real-world datasets.

Finally, when you use a third-party solution such as Rev, you can get up and running immediately. You don’t have to wait around to hire a development team, to train models, or to get everything hosted on a server. Using a few simple API calls you can hook your frontend right into Rev’s ASR system and be ready to go that very same day. This ultimately saves you money and likely more than recoups the low cost that Rev charges.
More Caption & Subtitle Articles
Everybody’s Favorite Speech-to-Text Blog
We combine AI and a huge community of freelancers to make speech-to-text greatness every day. Wanna hear more about it?
- Python for Machine Learning
- Machine Learning with R
- Machine Learning Algorithms
- Math for Machine Learning
- Machine Learning Interview Questions
- ML Projects
- Deep Learning
- Computer vision
- Data Science
- Artificial Intelligence
Speech Recognition Module Python
- PyTorch for Speech Recognition
- Python | Speech recognition on large audio files
- Speech Recognition in Python using CMU Sphinx
- Python | Face recognition using GUI
- What is Speech Recognition?
- Automatic Speech Recognition using CTC
- How to Set Up Speech Recognition on Windows?
- Python word2number Module
- Automatic Speech Recognition using Whisper
- 5 Best AI Tools for Speech Recognition in 2024
- Speech Recognition in Hindi using Python
- Speech Recognition in Python using Google Speech API
- Python text2digits Module
- Python Text To Speech | pyttsx module
- Python - Get Today's Current Day using Speech Recognition
- Python winsound module
- TextaCy module in Python
- Python subprocess module
- Restart your Computer with Speech Recognition
Speech recognition, a field at the intersection of linguistics, computer science, and electrical engineering, aims at designing systems capable of recognizing and translating spoken language into text. Python, known for its simplicity and robust libraries, offers several modules to tackle speech recognition tasks effectively. In this article, we’ll explore the essence of speech recognition in Python, including an overview of its key libraries, how they can be implemented, and their practical applications.
Key Python Libraries for Speech Recognition
- SpeechRecognition : One of the most popular Python libraries for recognizing speech. It provides support for several engines and APIs, such as Google Web Speech API, Microsoft Bing Voice Recognition, and IBM Speech to Text. It’s known for its ease of use and flexibility, making it a great starting point for beginners and experienced developers alike.
- PyAudio : Essential for audio input and output in Python, PyAudio provides Python bindings for PortAudio, the cross-platform audio I/O library. It’s often used alongside SpeechRecognition to capture microphone input for real-time speech recognition.
- DeepSpeech : Developed by Mozilla, DeepSpeech is an open-source deep learning-based voice recognition system that uses models trained on the Baidu’s Deep Speech research project. It’s suitable for developers looking to implement more sophisticated speech recognition features with the power of deep learning.
Implementing Speech Recognition with Python
A basic implementation using the SpeechRecognition library involves several steps:
- Audio Capture : Capturing audio from the microphone using PyAudio.
- Audio Processing : Converting the audio signal into data that the SpeechRecognition library can work with.
- Recognition : Calling the recognize_google() method (or another available recognition method) on the SpeechRecognition library to convert the audio data into text.
Here’s a simple example:
Practical Applications
Speech recognition has a wide range of applications:
- Voice-activated Assistants: Creating personal assistants like Siri or Alexa.
- Accessibility Tools: Helping individuals with disabilities interact with technology.
- Home Automation: Enabling voice control over smart home devices.
- Transcription Services: Automatically transcribing meetings, lectures, and interviews.
Challenges and Considerations
While implementing speech recognition, developers might face challenges such as background noise interference, accents, and dialects. It’s crucial to consider these factors and test the application under various conditions. Furthermore, privacy and ethical considerations must be addressed, especially when handling sensitive audio data.
Speech recognition in Python offers a powerful way to build applications that can interact with users in natural language. With the help of libraries like SpeechRecognition, PyAudio, and DeepSpeech, developers can create a range of applications from simple voice commands to complex conversational interfaces. Despite the challenges, the potential for innovative applications is vast, making speech recognition an exciting area of development in Python.
FAQ on Speech Recognition Module in Python
What is the speech recognition module in python.
The Speech Recognition module, often referred to as SpeechRecognition, is a library that allows Python developers to convert spoken language into text by utilizing various speech recognition engines and APIs. It supports multiple services like Google Web Speech API, Microsoft Bing Voice Recognition, IBM Speech to Text, and others.
How can I install the Speech Recognition module?
You can install the Speech Recognition module by running the following command in your terminal or command prompt: pip install SpeechRecognition For capturing audio from the microphone, you might also need to install PyAudio. On most systems, this can be done via pip: pip install PyAudio
Do I need an internet connection to use the Speech Recognition module?
Yes, for most of the supported APIs like Google Web Speech, Microsoft Bing Voice Recognition, and IBM Speech to Text, an active internet connection is required. However, if you use the CMU Sphinx engine, you do not need an internet connection as it operates offline.
Please Login to comment...
Similar reads.
- AI-ML-DS With Python
- Python Framework
- Python-Library
- Machine Learning
Improve your Coding Skills with Practice
What kind of Experience do you want to share?
Quickly develop projects based on speech recognition, with a powerful and ready-to-use software library
The Arduino Speech Recognition Engine offers the quickest and easiest way to start talking to and with machines. Its extensive software library was developed by worldwide speech recognition leader Cyberon with ease of use and compatibility in mind, so you can instantly integrate new applications – even in existing solutions – and start using your voice to interact with devices.
Speech Recognition Engine is compatible with multiple Arduino boards and the Arduino IDE , and requires no additional hardware, software or Internet connectivity . Its AI/ML engine understands commands defined through text input in 40+ languages – regardless of the speaker’s actual voice, tone or accent. This means you can quickly configure multiple wake-up words and sequences, and don’t have to retrain for different users .

Speech Recognition Engine is ideal for industrial and building automation applications such as hands-free control of machinery, equipment and human-machine interactions based on voice recognition: information kiosks, vending machines and lockers, smart beds in hospitals, emergency alert systems and more.
Speech Recognition Engine is able to listen to anyone speaking to it, ignoring any background noise.
Get started with a free trial license.
Download, integrate, done: using a software library makes speech recognition easy to integrate and use
Using text input to define voice commands translates into instant results and flexibility over different tones and accents
Add it to your existing or new projects, in combination with different elements in the Arduino ecosystem
Build your next smart device to understand every major language in the world: rhwydd! (that’s “easy”, in Welsh)

- Powerful, yet extremely easy-to-use library with integrated AI/ML engine for phoneme-based modeling
- Recognition of multiple wake-up words and sequences of commands
- No vocal training required, commands configurable through text input
- Support for 40+ languages, independent from accent variations
- One configuration for multiple speakers, without retraining
- Recognition on the edge, no need for additional HW/SW or connectivity
- Suitable for noisy environments
- Expand existing projects with speech recognition capabilities
- Compatible with multiple Arduino Nano and Portenta products
- Compatible with Arduino IDE and Arduino CLI
| 1 | 1 | Unlimited | |
| 1 | 1 | Unlimited | |
| 20 max | 20 max | Unlimited*** | |
| 50 | Unlimited | Unlimited | |
| 20s | No | No |
*The dataset cannot be changed after deploying it and it is bound to a single Arduino board **Delay between entering the Trigger Mode and the recognition of the Wake-up Word ***Number of commands depend on available hardware resources
Get your Professional License for advanced users

Updated : 6 June 2024 Contributor : Jim Holdsworth
Natural language processing (NLP) is a subfield of computer science and artificial intelligence (AI) that uses machine learning to enable computers to understand and communicate with human language.
NLP enables computers and digital devices to recognize, understand and generate text and speech by combining computational linguistics—the rule-based modeling of human language—together with statistical modeling, machine learning (ML) and deep learning.
NLP research has enabled the era of generative AI, from the communication skills of large language models (LLMs) to the ability of image generation models to understand requests. NLP is already part of everyday life for many, powering search engines, prompting chatbots for customer service with spoken commands, voice-operated GPS systems and digital assistants on smartphones. NLP also plays a growing role in enterprise solutions that help streamline and automate business operations, increase employee productivity and simplify mission-critical business processes.
Use this model selection framework to choose the most appropriate model while balancing your performance requirements with cost, risks and deployment needs.
Register for the white paper on AI governance
A natural language processing system can work rapidly and efficiently: after NLP models are properly trained, it can take on administrative tasks, freeing staff for more productive work. Benefits can include:
Faster insight discovery : Organizations can find hidden patterns, trends and relationships between different pieces of content. Text data retrieval supports deeper insights and analysis, enabling better-informed decision-making and surfacing new business ideas.
Greater budget savings : With the massive volume of unstructured text data available, NLP can be used to automate the gathering, processing and organization of information with less manual effort.
Quick access to corporate data : An enterprise can build a knowledge base of organizational information to be efficiently accessed with AI search. For sales representatives, NLP can help quickly return relevant information, to improve customer service and help close sales.
NLP models are not perfect and probably never will be, just as human speech is prone to error. Risks might include:
Biased training : As with any AI function, biased data used in training will skew the answers. The more diverse the users of an NLP function, the more significant this risk becomes, such as in government services, healthcare and HR interactions. Training datasets scraped from the web, for example, are prone to bias.
Misinterpretation : As in programming, there is a risk of garbage in, garbage out (GIGO). NLP solutions might become confused if spoken input is in an obscure dialect, mumbled, too full of slang, homonyms, incorrect grammar, idioms, fragments, mispronunciations, contractions or recorded with too much background noise.
New vocabulary: New words are continually being invented or imported. The conventions of grammar can evolve or be intentionally broken. In these cases, NLP can either make a best guess or admit it’s unsure—and either way, this creates a complication.
Tone of voice : When people speak, their verbal delivery or even body language can give an entirely different meaning than the words alone. Exaggeration for effect, stressing words for importance or sarcasm can be confused by NLP, making the semantic analysis more difficult and less reliable.
Human language is filled with many ambiguities that make it difficult for programmers to write software that accurately determines the intended meaning of text or voice data. Human language might take years for humans to learn—and many never stop learning. But then programmers must teach natural language-driven applications to recognize and understand irregularities so their applications can be accurate and useful.
NLP combines the power of computational linguistics together with machine learning algorithms and deep learning. Computational linguistics is a discipline of linguistics that uses data science to analyze language and speech. It includes two main types of analysis: syntactical analysis and semantical analysis. Syntactical analysis determines the meaning of a word, phrase or sentence by parsing the syntax of the words and applying preprogrammed rules of grammar. Semantical analysis uses the syntactic output to draw meaning from the words and interpret their meaning within the sentence structure.
The parsing of words can take one of two forms. Dependency parsing looks at the relationships between words, such as identifying nouns and verbs, while constituency parsing then builds a parse tree (or syntax tree): a rooted and ordered representation of the syntactic structure of the sentence or string of words. The resulting parse trees underly the functions of language translators and speech recognition. Ideally, this analysis makes the output—either text or speech—understandable to both NLP models and people.
Self-supervised learning (SSL) in particular is useful for supporting NLP because NLP requires large amounts of labeled data to train state-of-the-art artificial intelligence (AI) models . Because these labeled datasets require time-consuming annotation—a process involving manual labeling by humans—gathering sufficient data can be prohibitively difficult. Self-supervised approaches can be more time-effective and cost-effective, as they replace some or all manually labeled training data. Three different approaches to NLP include:
Rules-based NLP : The earliest NLP applications were simple if-then decision trees, requiring preprogrammed rules. They are only able to provide answers in response to specific prompts, such as the original version of Moviefone. Because there is no machine learning or AI capability in rules-based NLP, this function is highly limited and not scalable.
Statistical NLP : Developed later, statistical NLP automatically extracts, classifies and labels elements of text and voice data, and then assigns a statistical likelihood to each possible meaning of those elements. This relies on machine learning, enabling a sophisticated breakdown of linguistics such as part-of-speech tagging. Statistical NLP introduced the essential technique of mapping language elements—such as words and grammatical rules—to a vector representation so that language can be modeled by using mathematical (statistical) methods, including regression or Markov models. This informed early NLP developments such as spellcheckers and T9 texting (Text on 9 keys, to be used on Touch-Tone telephones).
Deep learning NLP : Recently, deep learning models have become the dominant mode of NLP, by using huge volumes of raw, unstructured data—both text and voice—to become ever more accurate. Deep learning can be viewed as a further evolution of statistical NLP, with the difference that it uses neural network models. There are several subcategories of models:
- Sequence-to-Sequence (seq2seq) models : Based on recurrent neural networks (RNN) , they have mostly been used for machine translation by converting a phrase from one domain (such as the German language) into the phrase of another domain (such as English).
- Transformer models : They use tokenization of language (the position of each token—words or subwords) and self-attention (capturing dependencies and relationships) to calculate the relation of different language parts to one another. Transformer models can be efficiently trained by using self-supervised learning on massive text databases. A landmark in transformer models was Google’s bidirectional encoder representations from transformers (BERT), which became and remains the basis of how Google’s search engine works.
- Autoregressive models : This type of transformer model is trained specifically to predict the next word in a sequence, which represents a huge leap forward in the ability to generate text. Examples of autoregressive LLMs include GPT, Llama , Claude and the open-source Mistral.
- Foundation models : Prebuilt and curated foundation models can speed the launching of an NLP effort and boost trust in its operation. For example, the IBM Granite™ foundation models are widely applicable across industries. They support NLP tasks including content generation and insight extraction. Additionally, they facilitate retrieval-augmented generation, a framework for improving the quality of response by linking the model to external sources of knowledge. The models also perform named entity recognition which involves identifying and extracting key information in a text.
For a deeper dive into the nuances between multiple technologies and their learning approaches, see “ AI versus. machine learning versus deep learning versus neural networks: What’s the difference? ”
Several NLP tasks typically help process human text and voice data in ways that help the computer make sense of what it’s ingesting. Some of these tasks include:
Linguistic tasks
- Coreference resolution is the task of identifying if and when two words refer to the same entity. The most common example is determining the person or object to which a certain pronoun refers (such as, “she” = “Mary”). But it can also identify a metaphor or an idiom in the text (such as an instance in which “bear” isn’t an animal, but a large and hairy person).
- Named entity recognition ( NER ) identifies words or phrases as useful entities. NER identifies “London” as a location or “Maria” as a person's name.
- Part-of-speech tagging , also called grammatical tagging, is the process of determining which part of speech a word or piece of text is, based on its use and context. For example, part-of-speech identifies “make” as a verb in “I can make a paper plane,” and as a noun in “What make of car do you own?”
- Word sense disambiguation is the selection of a word meaning for a word with multiple possible meanings. This uses a process of semantic analysis to examine the word in context. For example, word sense disambiguation helps distinguish the meaning of the verb “make” in “make the grade” (to achieve) versus “make a bet” (to place). Sorting out “I will be merry when I marry Mary” requires a sophisticated NLP system.
User-supporting tasks
- Speech recognition , also known as speech-to-text , is the task of reliably converting voice data into text data. Speech recognition is part of any application that follows voice commands or answers spoken questions. What makes speech recognition especially challenging is the way people speak—quickly, running words together, with varying emphasis and intonation.
- Natural language generation (NLG) might be described as the opposite of speech recognition or speech-to-text: NLG is the task of putting structured information into conversational human language. Without NLG, computers would have little chance of passing the Turing test , where a computer tries to mimic a human conversation. Conversational agents such as Amazon’s Alexa and Apple’s Siri are already doing this well and assisting customers in real time.
- Natural language understanding (NLU) is a subset of NLP that focuses on analyzing the meaning behind sentences. NLU enables software to find similar meanings in different sentences or to process words that have different meanings.
- Sentiment analysis attempts to extract subjective qualities —attitudes, emotions, sarcasm, confusion or suspicion—from text. This is often used for routing communications to the system or the person most likely to make the next response.
See the blog post “ NLP vs. NLU vs. NLG: the differences between three natural language processing concepts ” for a deeper look into how these concepts relate.
The all-new enterprise studio that brings together traditional machine learning along with new generative AI capabilities powered by foundation models.
Organizations can use NLP to process communications that include email, SMS, audio, video, newsfeeds and social media. NLP is the driving force behind AI in many modern real-world applications. Here are a few examples:
- Customer assistance : Enterprises can deploy chatbots or virtual assistants to quickly respond to custom questions and requests. When questions become too difficult for the chatbot or virtual assistant, the NLP system moves the customer over to a human customer service agent. Virtual agents such as IBM watsonx™ Assistant , Apple’s Siri and Amazon’s Alexa use speech recognition to recognize patterns in voice commands and natural language generation to respond with appropriate actions or helpful comments. Chatbots respond to typed text entries. The best chatbots also learn to recognize contextual clues about human requests and use them to provide even better responses or options over time. The next enhancement for these applications is question answering, the ability to respond to questions—anticipated or not—with relevant and helpful answers in their own words. These automations help reduce costs, save agents from spending time on redundant queries and improve customer satisfaction. Not all chatbots are powered by AI, but state-of-the-art chatbots increasingly use conversational AI techniques, including NLP, to understand user questions and automate responses to them.
- FAQ : Not everyone wants to read to discover an answer. Fortunately, NLP can enhance FAQs: When the user asks a question, the NLP function looks for the best match among the available answers and brings that to the user’s screen. Many customer questions are of the who/what/when/where variety, so this function can save staff from having to repeatedly answer the same routine questions.
- Grammar correction : The rules of grammar can be applied within word processing or other programs, where the NLP function is trained to spot incorrect grammar and suggest corrected wordings.
- Machine translation: Google Translate is an example of widely available NLP technology at work. Truly useful machine translation involves more than replacing words from one language with words of another. Effective translation accurately captures the meaning and tone of the input language and translates it to text with the same meaning and desired impact in the output language. Machine translation tools are becoming more accurate. One way to test a machine translation tool is to translate text from one language and then back to the original. An oft-cited, classic example: Translating “ The spirit is willing, but the flesh is weak” from English to Russian and back again once yielded, “ The vodka is good, but the meat is rotten .” Recently, a closer result was “ The spirit desires, but the flesh is weak. ” Google translate can now take English to Russian to English and return the original, “ The spirit is willing, but the flesh is weak."
- Redaction of personally identifiable information (PII) : NLP models can be trained to quickly locate personal information in documents that might identify individuals. Industries that handle large volumes of sensitive information—financial, healthcare, insurance and legal firms—can quickly create versions with the PII removed.
- Sentiment analysis : After being trained on industry-specific or business-specific language, an NLP model can quickly scan incoming text for keywords and phrases to gauge a customer’s mood in real-time as positive, neutral or negative. The mood of the incoming communication can help determine how it will be handled. And the incoming communication doesn’t have to be live: NLP can also be used to analyze customer feedback or call center recordings. Another option is an NLP API that can enable after-the-fact text analytics. NLP can uncover actionable data insights from social media posts, responses or reviews to extract attitudes and emotions in response to products, promotions and events. Information companies can use sentiment analysis in product designs, advertising campaigns and more.
- Spam detection: Many people might not think of spam detection as an NLP solution, but the best spam detection technologies use NLP’s text classification capabilities to scan emails for language indicating spam or phishing. These indicators can include overuse of financial terms, characteristic bad grammar, threatening language, inappropriate urgency or misspelled company names.
- Text generation : NLP helps put the “generative” into generative AI. NLP enables computers to generate text or speech that is natural-sounding and realistic enough to be mistaken for human communication. The generated language might be used to create initial drafts of blogs, computer code, letters, memos or tweets. With an enterprise-grade system, the quality of generated language might be sufficient to be used in real time for autocomplete functions, chatbots or virtual assistants. Advancements in NLP are powering the reasoning engine behind generative AI systems, driving further opportunities. Microsoft® Copilot is an AI assistant designed to boost employee productivity and creativity across day-to-day tasks and is already at work in tools used every day.
- Text summarization: Text summarization uses NLP techniques to digest huge volumes of digital text and create summaries and synopses for indexes, research databases, for busy readers who don't have time to read the full text. The best text summarization applications use semantic reasoning and natural language generation (NLG) to add useful context and conclusions to summaries.
- Finance : In financial dealings, nanoseconds might make the difference between success and failure when accessing data, or making trades or deals. NLP can speed the mining of information from financial statements, annual and regulatory reports, news releases or even social media.
- Healthcare : New medical insights and breakthroughs can arrive faster than many healthcare professionals can keep up. NLP and AI-based tools can help speed the analysis of health records and medical research papers, making better-informed medical decisions possible, or assisting in the detection or even prevention of medical conditions.
- Insurance : NLP can analyze claims to look for patterns that can identify areas of concern and find inefficiencies in claims processing—leading to greater optimization of processing and employee efforts.
- Legal : Almost any legal case might require reviewing mounds of paperwork, background information and legal precedent. NLP can help automate legal discovery, assisting in the organization of information, speeding review and helping ensure that all relevant details are captured for consideration.
Python and the Natural Language Toolkit (NLTK)
The Python programing language provides a wide range of tools and libraries for performing specific NLP tasks. Many of these NLP tools are in the Natural Language Toolkit , or NLTK, an open-source collection of libraries, programs and education resources for building NLP programs.
The NLTK includes libraries for many NLP tasks and subtasks, such as sentence parsing , word segmentation , stemming and lemmatization (methods of trimming words down to their roots), and tokenization (for breaking phrases, sentences, paragraphs and passages into tokens that help the computer better understand the text). It also includes libraries for implementing capabilities such as semantic reasoning: the ability to reach logical conclusions based on facts extracted from text. Using NLTK, organizations can see the product of part-of-speech tagging. Tagging words might not seem to be complicated, but since words can have different meanings depending on where they are used, the process is complicated.
Generative AI platforms
Organizations can infuse the power of NLP into their digital solutions by leveraging user-friendly generative AI platforms such as IBM Watson NLP Library for Embed , a containerized library designed to empower IBM partners with greater AI capabilities. Developers can access and integrate it into their apps in their environment of their choice to create enterprise-ready solutions with robust AI models, extensive language coverage and scalable container orchestration.
More options include IBM ® watsonx.ai™ AI studio , which enables multiple options to craft model configurations that support a range of NLP tasks including question answering, content generation and summarization, text classification and extraction. Integrations can also enable more NLP capabilities. For example, with watsonx and Hugging Face AI builders can use pretrained models to support a range of NLP tasks.
Accelerate the business value of artificial intelligence with a powerful and flexible portfolio of libraries, services and applications.
Infuse powerful natural language AI into commercial applications with a containerized library designed to empower IBM partners with greater flexibility.
Learn the fundamental concepts for AI and generative AI, including prompt engineering, large language models and the best open source projects.
Learn about different NLP use cases in this NLP explainer.
Visit the IBM Developer's website to access blogs, articles, newsletters and more. Become an IBM partner and infuse IBM Watson embeddable AI in your commercial solutions today. Use IBM Watson NLP Library for Embed in your solutions.
Watch IBM Data and AI GM, Rob Thomas as he hosts NLP experts and clients, showcasing how NLP technologies are optimizing businesses across industries.
Learn about the Natural Language Understanding API with example requests and links to additional resources.
IBM has launched a new open-source toolkit, PrimeQA, to spur progress in multilingual question-answering systems to make it easier for anyone to quickly find information on the web.
Train, validate, tune and deploy generative AI, foundation models and machine learning capabilities with IBM watsonx.ai, a next-generation enterprise studio for AI builders. Build AI applications in a fraction of the time with a fraction of the data.
- Stack Overflow Public questions & answers
- Stack Overflow for Teams Where developers & technologists share private knowledge with coworkers
- Talent Build your employer brand
- Advertising Reach developers & technologists worldwide
- Labs The future of collective knowledge sharing
- About the company
Collectives™ on Stack Overflow
Find centralized, trusted content and collaborate around the technologies you use most.
Q&A for work
Connect and share knowledge within a single location that is structured and easy to search.
Get early access and see previews of new features.
C# SpeechRecognizer vs SpeechRecognitionEngine
Few questions,
What is the difference between the SpeechRecognizer and the SpeechRecognitionEngine classes? why use one over the other for speech recognition?
Is the speech recognition widget that I see in Windows 10 when I start my program has to be shown?
I loaded the SpeechRecognizer object with simple grammar such as "a", "b", "a r". it recognizes it perfectly but the time it takes is not ideal for my program, I would like it to be faster, any way to do that?
- speech-recognition
- text-to-speech
- Have you read documentations of those classes especially remarks sections? There is information to answer your 1. question. For 2. try and you will see. 3. Buy a better pc? – Renatas M. Commented Nov 6, 2018 at 14:12
- 1. I will, thanks. 2. What do you mean try and see? the widget opens everytime I start my program 3. I have a macbookpro i5, I don't think that's the problem – mountSin Commented Nov 6, 2018 at 14:20
- 2. I don't understand what do you mean by saying is it has to be shown if it is shown when you start. Maybe you want to know can you control or switch it off? 3. Then what is slow and fast in thins case? – Renatas M. Commented Nov 6, 2018 at 14:27
- 2. I'm talking about this widget: imgur.com/a/3IR2QqS , is there a way Windows can do the speech recognition in the background and not show it to me? 3. How exactly do I measure? I think it's taking approx 0.1 seconds to recoginze and I want it to take less – mountSin Commented Nov 6, 2018 at 15:06
- 2. I guess you need to use SpeechRecognizerEngine to be able to control this. 3. I want is not a measurement unit, you need to do speed comparison. Maybe 0.1s for your grammar is blazing fast. Also it might depend on million reasons. Do you run it in debug mode or is it release build? Have you compared speed with other grammars and applications? – Renatas M. Commented Nov 6, 2018 at 15:32
I think this has been answered in the past. See Using System.Speech.Recognition opens Windows Speech Recognition , does this help?
In general, you can use System.Speech as inproc or shared. When shared, you see a recognizer "widget" on the screen. If you use an inproc recognizer, you control the recognizer and windows does not add a UI. See good Speech recognition API for some more background.
Your Answer
Reminder: Answers generated by artificial intelligence tools are not allowed on Stack Overflow. Learn more
Sign up or log in
Post as a guest.
Required, but never shown
By clicking “Post Your Answer”, you agree to our terms of service and acknowledge you have read our privacy policy .
Not the answer you're looking for? Browse other questions tagged c# speech-recognition text-to-speech or ask your own question .
- Featured on Meta
- Upcoming sign-up experiments related to tags
- The 2024 Developer Survey Is Live
- Policy: Generative AI (e.g., ChatGPT) is banned
- The return of Staging Ground to Stack Overflow
Hot Network Questions
- How should I interpret the impedance of an SMA connector?
- What the difference between View Distance and Ray Length?
- Transactional Replication - how to set up alerts/notification to send alerts before transaction log space is full on publisher?
- Was Croatia the first country to recognize the sovereignity of the USA? Was Croatia expecting military help from USA that didn't come?
- What is the history and meaning of letters “v” and “e” in expressions +ve and -ve?
- Can we study scientifically the set of facts and behaviors if we have no scientific explanation for the source, origin or underlying mechanism of it?
- How to filter WFS by intersecting polygon
- What is the difference between a group representation and an isomorphism to GL(n,R)?
- Do sus24 chords exist?
- Can the laser light, in principle, take any wavelength in the EM spectrum?
- PostGIS ST_ClusterDBSCAN returns NULL
- How do I perform pandas cumsum while skipping rows that are duplicated in another field?
- Can my grant pay for a conference marginally related to award?
- Statement of Contribution in Dissertation
- How are secret encodings not a violation of amateur radio regulations?
- Properties of Hamilton cycles in hypercubes
- Is this crumbling concrete step salvageable?
- Why is "Colourless green ideas sleep furiously" considered meaningless?
- Recommendations Modifying/increasing a bicycles Max Weight limits
- Could an Alien decipher human languages using only comms traffic?
- Bibliographic references: “[19,31-33]”, “[33,19,31,32]” or “[33], [19], [31], [32]”?
- Did the NES CPU save die area by omitting BCD?
- What can I add to my too-wet tuna+potato patties to make them less mushy?
- How to count the number of lines in an array
- Get 7 Days Free
3Play Media Study Reveals Automatic Speech Recognition (ASR) Engines are Fine Tuning After a Year of Massive Improvement
After a year of significant developments, research finds Artificial Intelligence (AI) speech recognition tools are honing in on differentiation, but human-in-the-loop workflows remain critical for ASR captioning and transcription use cases.
After a year of profound improvement in accuracy, ASR providers are doubling down on improving the accuracy of their solutions and focusing on their differentiation, according to the latest State of ASR report by 3Play Media , the leading media accessibility provider in North America, released today.
“The ASR market continues to evolve and is fiercely competitive. It is clearly reaching a maturation stage in its evolution,” Josh Miller, co-CEO and co-Founder, 3Play Media, said. “After a year of revolutionary changes in the accuracy of the technology, the 2024 report finds vendors working on their differentiation based on specific use cases and fine-tuning their technologies accordingly.
“This year, it has become clear that not all errors are equal, challenging the standalone metric of accuracy rate. Ultimately, ASR alone is still insufficient for the captioning use case, especially regarding formatting and hallucinations. Human-in-the-loop captioning and transcription workflows remain critical for accuracy, quality, and accessibility.”
The annual study analyzes the general state of speech-to-text technology as it applies to the task of captioning and transcription. In addition to a surge in new advancements, 2023 brought several new players, such as Assembly and Whisper, whose ASR engines rivaled top competitors such as Speechmatics.
The new report investigates errors like hallucinations, where the engine generates incorrect words not present in the input. Whisper, a fast gainer in last year’s study, continues to be a competitive engine, but its hallucinations remain a cause for concern. These hallucinations appear more common than initially believed, and the consequences for accessibility – and ultimately a brand – are profound.
This year’s State of ASR report additionally highlights the need for a more nuanced evaluation framework that considers factors like Word Error Rate (WER), Formatted Error Rate (FER), and the Canadian NER Model. The top engines were found to have different strengths and weaknesses, and each prioritizes differing types of content or styles of transcription.
To obtain a free copy of The 2024 State of ASR report, please visit: https://go.3playmedia.com/rs-2024-asr .
About 3Play Media
3Play Media is an integrated media accessibility platform with patented solutions for closed captioning, transcription, live captioning, audio description, and subtitling. 3Play Media combines machine learning (ML), artificial intelligence (AI), and automatic speech recognition (ASR) with human review to provide innovative, highly accurate services. Customers span multiple industries, including media & entertainment, corporate, e-commerce, fitness, higher education, government, and eLearning.
Media Contact Phil LeClare [email protected] 617-209-9406 www.3playmedia.com @3playmedia
View source version on businesswire.com: https://www.businesswire.com/news/home/20240620085571/en/
Market Updates
After earnings, is broadcom stock a buy, a sell, or fairly valued, 4 wide-moat stocks to buy for the long term while they’re undervalued today, markets brief: four stocks made up 80% of the gains. can it last, is it time to ditch your money market fund for longer-term bonds, what’s happening in the markets this week, 4 reasons why today’s stock market is delivering impressive performance, what does nvidia’s stock split mean for investors, 5 undervalued stocks to buy as their stories play out, stock picks, the best cyclical stocks to buy, it’s a good year for stock-pickers. here’s why, the promise and perils of artificial intelligence, covered-call and buffer etfs: stock investing with less gain but less pain, micron stock soars with the ai boom—is it a buy or a sell, with a 4% dividend yield and significant growth potential, this stock is a buy, 10 stocks the best fund managers have been buying, ge aerospace stock has skyrocketed 86%. is it a buy, sponsor center.
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Open access
- Published: 07 June 2024
An enhanced speech emotion recognition using vision transformer
- Samson Akinpelu 1 ,
- Serestina Viriri 1 &
- Adekanmi Adegun 1
Scientific Reports volume 14 , Article number: 13126 ( 2024 ) Cite this article
326 Accesses
1 Altmetric
Metrics details
- Computer science
- Mathematics and computing
In human–computer interaction systems, speech emotion recognition (SER) plays a crucial role because it enables computers to understand and react to users’ emotions. In the past, SER has significantly emphasised acoustic properties extracted from speech signals. The use of visual signals for enhancing SER performance, however, has been made possible by recent developments in deep learning and computer vision. This work utilizes a lightweight Vision Transformer (ViT) model to propose a novel method for improving speech emotion recognition. We leverage the ViT model’s capabilities to capture spatial dependencies and high-level features in images which are adequate indicators of emotional states from mel spectrogram input fed into the model. To determine the efficiency of our proposed approach, we conduct a comprehensive experiment on two benchmark speech emotion datasets, the Toronto English Speech Set (TESS) and the Berlin Emotional Database (EMODB). The results of our extensive experiment demonstrate a considerable improvement in speech emotion recognition accuracy attesting to its generalizability as it achieved 98%, 91%, and 93% (TESS-EMODB) accuracy respectively on the datasets. The outcomes of the comparative experiment show that the non-overlapping patch-based feature extraction method substantially improves the discipline of speech emotion recognition. Our research indicates the potential for integrating vision transformer models into SER systems, opening up fresh opportunities for real-world applications requiring accurate emotion recognition from speech compared with other state-of-the-art techniques.
Similar content being viewed by others

Emotion recognition for human–computer interaction using high-level descriptors

Music video emotion classification using slow–fast audio–video network and unsupervised feature representation

Speech emotion classification using attention based network and regularized feature selection
Introduction.
Human–computer interactions (HCI) can be improved by paying more attention to emotional cues in human speech 1 . The need for speech recognition and enhancement of emotion recognition in achieving more natural interaction and better immersion is becoming more of a challenge as a result of the growing trend in artificial intelligence (AI) 2 , 3 . Coincidentally, with the development of deep neural networks, research on Speech Emotion Recognition (SER) systems has grown steadily by turning audio signals into feature maps that vividly describe the vocal traits of speech(auditory) samples. 4 .
Speech Emotion Recognition (SER) is a classification problem that seeks to classify audio samples into pre-defined emotions. SER has applications in affective computing, psychological wellness evaluation, and virtual assistants, and has become a crucial field of research in human–computer interaction 5 . Speech signals may be used to reliably detect and comprehend human emotions, which enables machines to react correctly and produce more interesting and tailored interactions 6 . By acquiring acoustic features from speech signals 7 , such as pitch, energy, and spectral qualities, and using machine learning algorithms to categorize emotions based on these features, has been the concentration of conventional approaches (Fig. 1 ) to SER 8 . Although these methods have yielded encouraging results, they frequently fail to pick up on nuances in emotional cues and are subject to noise and unpredictability in voice signals.

Traditional speech emotion recognition framework.
Researchers have been able to improve SER by using the spectral features of an audio sample as an image input to the impressive advancements in computer vision. Convolutional neural networks (CNNs), in particular, have shown astounding performance in deep learning 9 models for visual tasks like image processing and object detection. The weights of several convolutional layers have been utilized to create feature representations in this architecture 10 , 11 . Utilizing mel-spectrograms, this method can be used in SERs to convert audio data into visual audio signals based on its frequency components. Then, these representations that resemble images can be trained using a CNN network. Traditional CNN, however, only accepts a single frame as input and does not compute over a timestep sequence, therefore they are unable to remember previous data from the same sample while processing the subsequent timestamp.
Additionally, because of the number of parameters generated by the numerous convolutional layers, they provide large levels of computational complexity 12 . Researchers have been seeking alternative architectures that are more appropriate for handling visual data in the context of SER as a result of this constraint.
The Vision Transformer (ViT) is one such architectural design that has attracted significant interest. The ViT model, which was initially introduced for image classification tasks, completely changed the area of computer vision by exhibiting competitive performance without utilizing conventional CNN building blocks 13 . The ViT model makes use of a self-attention mechanism that enables it to directly learn global features from the input image and capture spatial dependencies. This unique model has demonstrated promising performance in several computer vision applications 14 , raising the question of whether it may be leveraged to enhance SER.
In this study, we addressed two core issues. At first, the computational complexity is reduced, we enhanced the accuracy of emotion recognition from speech signals by improving the state-of-the-art performance. We focus mainly on extracting features from the mel-spectrogram 15 and fed it into a novel lightweight ViT model with a self-attention mechanism for accurate speech emotion recognition. The spectrogram image is represented in time and frequency as width and length to enable our proposed model to learn emotionally rich features from speech signals. Computational cost is reduced as a result of fewer over-blotted parameters. The major contributions of this work are highlighted below.
We proposed a novel lightweight Vision Transformer (ViT) model with self-attention for learning deep features related to emotional cues from the mel-spectrogram to recognize emotion from speech.
Complexity is reduced for SER through fewer parameters and efficient layers that learn discriminative features from the input image.
We evaluated the proposed SER model on popular benchmark datasets which include TESS and EMO-DB. The result of our comparative experiments shows an improved performance in SER, confirming its suitability for real-time application.
The remaining part of this paper is split into other sections as follows. Section 2 presents the reviewed literature and related works, Section 3 highlights the proposed methodology and its detailed description. In Section 4, the experimental configuration, result and discussion are presented, while Section 5 illustrates the conclusion and future work to foster research progress in the SER domain.
Review of related works
The study of emotion recognition from speech signals as it plays a crucial role in behavioural patterns and enhances human–computer interaction in the past decade has come a long way. Identification of human emotional conditions from speech samples (natural or synthetic) has formed the basis for the development of Speech Emotion Recognition SER systems. Core among these emotional states are angry, sad, happy, neutral, etc. Researchers began with the conventional approach of recognizing these emotions with the use of orthodox machine learning models which includes Support Vector Machine(SVM) 16 , 17 , 18 , Gaussian Mixture Model(GMM) 19 ,k-nearest Neighbour(KNN) 20 and Hidden Markov Model (HMM) 21 among others. However, these classical machine learning classifiers are bewildered with the problem of high susceptibility to noise and the inability to efficiently handle large audio speech samples.
Therefore, neural network approaches such as Recurrent Neural Networks (RNN) 22 and Long Short Term Memory (LSTM) 23 , 24 , 25 have been proposed by researchers in the SER domain, because of their capability to handle sequence(time series) data and learn temporal information that is critical to emotion recognition using contextual dependencies. The adoption of these two techniques has littered several SER literature, because emotion recognition has been improved upon. However, RNN is prone to gradient descent problems 26
The common approach to SER in recent came as a result of unimaginable success through deep learning techniques 27 , 28 and prominent among this approach are Convolutional Neural Networks (CNN) 29 , Deep Neural Networks(DNN) 30 , 31 , 32 , Deep Belief Networks(DBN) 33 and Deep Boltzman Machine (DBM) 34 . In Zeng et al. 35 spectrogram feature extracted from Rayson Audio-Visual Database of Emotional Speech and Song(RAVDESSS) speech dataset was fed into DNN with gated residual network which yielded 65.97% accuracy of emotion recognition on tested data. In the same vein, a pre-trained VGG-16 convolutional neural network was utilized in Popova et al. 36 and they achieved an accuracy of 71% after extensive experiments. To increase the possibility of improving the recognition rate, the author Issa et al. 37 proposed a novel Deep Convolutional Neural Network (DNN) for SER. Multiple features Similarlyrances were extracted such as Mel Frequency Cepstral Coefficient, spectral contrast, and Mel-Spectrogram, and were fused to serve as their model input. Their method arrived at 71.61% accuracy for recognising eight different emotions from the RAVDESS dataset. Their method was also experimented on EMODB and IEMOCAP datasets for generalizability. However, their CNN model could not efficiently capture the spatial features and sequences peculiar to speech signals. In addressing the foregone, a multimodal approach of deep learning and temporal alignment techniques was proposed by Li et al. 38 . In their method, CNN, LSTM and Attention Mechanism were combined and they achieved the highest accuracy of 70.8% with semantic embeddings.
In recent times as well, the combination of CNN, LSTM or RNN for SER tasks has recorded significant improvement 39 . This approach relies heavily on the extraction of features from raw speech signals with CNN and passing them into the LSTM or RNN for extraction of long-term dependencies features that are peculiar to emotion recognition from auditory utterances 40 . Puri et al. 41 implemented a hybrid approach of utilizing LSTM and DNN on the RAVDESS dataset. They extracted MFCC from raw speech signals and fed it into their model. The ensemble technique of extracting salient features from speech utterances and passing the emotional features into a classifier, irrespective of the language and cultural background of the speakers has also aroused the interest of researchers in the SER field. High-level features from speech signals were extracted using DBN and then later fed into a Support Vector Machine classifier for emotion classification in Schuller et al. 42 . Similarly, Zhu et al. 43 utilized DNN and SVM and experimented with the efficiency of their model on the Chinese Academy of Chinese-based dataset. A separate study by Pawar et al. 44 proposed a deep learning approach for SER. Relevant features were extracted from speech signals using MFCC, as input to train the CNN model. They achieve a significant result of 93.8% accuracy on the EMODB dataset. The author in 45 proposed innovative lightweight multi-acoustic features-based DCNN techniques for speech emotion recognition. In their method, various features such as Zero Crossing Rate(ZCR), wavelet packet transform (WPT), spectral roll-off, linear prediction cepstral coefficients (LPCC), pitch, etc. were extracted and fed into one-dimensional DCNN and they obtained 93.31% on Berlin Database of Emotional Speech(EMODB) and 94.18% on RAVDESS respectively. Badshah et al. 46 presented present a double CNN-based model for SER with spectrogram from an audio signal. They utilized a pooling mechanism and kernel of different sizes with spectrogram input generated using Fast Fourier Transform (FFT). Their approach validates the importance of max-pooling operation in CNN.
The introduction of audio transformer to speech paralinguistics has contributed immensely to emotion recognition from speech signals. It involves analysis and synthesis of speech signals with features that are non-verbal 47 . Chen et al 48 proposed a novel full-stack audio transformer (WavLM) for speech analysis using a speech denoising approach for learning general speech representations from huge unannotated data. The performance of their proposed transformer model, benchmarked on the SUPERB dataset achieved a state-of-the-art result and improved many speech-related tasks such as speech emotion recognition and speaker verification or identification. Xu et al. 49 proposed a novel speech transformer-based that incorporated self-attention and local dense synthesizer attention (LDSA) for extracting both local and global features from speech signals. In a bid to enhance the efficiency of end-to-end speech recognition models while lowering computing complexity, the technique eliminates pairwise interactions and dot products and limits attention scope to a narrow region surrounding the current frame. A novel hybrid-based audio transformer, named Conformer-HuBERT was implemented by Shor et al. 50 . Their mechanism achieves a significant milestone in emotion recognition from speech signals and other paralinguistic tasks by learning from many large-scale unannotated data. Again, Chen et al. 51 proposed a novel SpeechFormer technique that combines the distinctive features of speech signals into transformer models. A hierarchical encoder that uses convolutional and pooling layers to shorten the input sequence is one of the three components of the framework. Another is a local self-attention module that records dependencies inside a predetermined window size, and a global self-attention module that records dependencies across various windows. Paraformer is another novel speech transformer model for non-autoregressive end-to-end speech recognition that employs parallel attention and parallel decoder approaches, introduced by Gao et al. 52 . The framework enables independent prediction of each output token without reliance on prior output tokens, and permits each decoder layer to handle all encoder outputs concurrently without waiting for previous decoder outputs. The study demonstrates that Paraformer achieves faster inference speed and higher accuracy on multiple speech recognition datasets compared to existing non-autoregressive models.
In the immediate past, efforts towards improving the efficiency of deep learning model performance and conquering the challenge of long-range dependencies peculiar to the CNN-base model for SER have been increased. The state-of-the-art transformer model has been introduced into SER 53 . A parallel architecture that utilized the ResNet and Transformer model was proposed in Han et al. 54 . Vijay et al. 55 implemented an audio-video multimodal transformer for emotion recognition. They adopted three self-attention and block embedding to capture relevant features from spectrogram images. Their model achieved 93.59%, 72.45%, and 99.17% on RAVDESS, CREMA-D and SAVEE datasets respectively, but huge computing resources were required because of the architecture. Not quite long after, Slimi et al. 56 proposed a transformer-based CNN for SER, with hybrid time distribution. They leverage the superior capability of the transformer and achieve a promising result of 82.72% accuracy. However, such a model is prone to high computational complexity due to huge parameters. The ability of CNN-based models to recognize long-range dependencies in speech signals is constrained by the fact that they frequently operate on fixed-size input windows. Speech emotion frequently displays temporal dynamics outside of the speech sequence’s local regions. Therefore, we proposed a lightweight Vision Transformer (ViT) model comprised of a self-attention mechanism 57 that enables it to capture global contextual information, making it possible to model long-range dependencies and enhance the representation of emotional speech patterns, hence improving speech emotion recognition.
Additionally, while a couple of research studies have looked at how to include visual cues in speech emotion recognition, they frequently treat visual and auditory modalities independently, resulting in an insufficient fusion of information or features. This study seeks to leverage the synergistic effects of multimodal information, enabling a more thorough comprehension of emotions and enhancing the accuracy of the SER system by using the ViT model 58 , 59 , capable of capturing salient features from the speech signal.
Proposed method
In this section, we delve into the overview of our proposed model (Fig. 2 ) for SER. We highlighted the overall details from speech collection, pre-processing, feature extraction, and feeding of ViT with feature vectors that eventually lead to emotion recognition.
Speech pre-processing
When background noise cannot be tolerated, pre-processing the speech sound is a crucial step. These systems, such as speech emotion recognition (SER) require effective feature extraction from audio files, where the majority of the spoken component consists of salient characteristics connected to emotions. This study used pre-emphasis and silent removal strategies to reach its goal 60 . Pre-emphasis uses Eq. ( 1 ) to increase the high-frequency parts of speech signals. The pre-emphasis technique can improve the signal-to-noise ratio by enhancing high frequencies in speech while leaving low frequencies untouched through the Finite impulse response (FIR) mechanism.
where z is the signal and \(\alpha \) is the energy level change across the frequency
Contrariwise, Eq. ( 2 ) is used in signal normalization to ensure that speech signals are equivalent despite any differences in magnitude.
where the signal’s mean and standard deviation are represented by \(\mu \) and, \(\sigma \) respectively, while the signal’s \(i^th\) portion is denoted by the \(S_i\) . The normalized \(i^th\) component of the signal is referred to as \(SN_i\) .

Propose Vision Transformer Architectural Framework.
Extraction of mel-spectrogram Feature
The quality of the feature set heavily influences the recognition performance of the model. As a result, inappropriate features could produce subpar recognition outcomes. To achieve acceptable recognition performance in the context of Deep Learning (DL), extracting a meaningful feature set is a vital task. According to 61 , feature extraction is a crucial step in deep learning since the SER model’s success or failure depends heavily on the variability of the features it uses to do the recognition task. If the derived traits have a strong correlation with the emotion class, recognition will be accurate, but if not, it will be challenging and inaccurate. The performance of recognition in SER is strongly influenced by the quality of the feature set.
The process of mel-spectrograms (Fig. 3 ) feature extraction involves pre-emphasis, framing, windowing and the discrete Short Time Fourier Transform. In our method, we generate a mel-spectrogram image by converting each speech sound sample into a 2D time-frequency matrix. We perform the discrete Short-Time Fourier Transform (STFT) computation for this. We employ an STFT length of 1024, hop size of 128, and 1024 window size (using Hanning as the window function). Additionally, we used 128 Mel bins to map the frequency onto the Mel scale. Each audio sound was split into frames of 25 ms, with a 10 ms gap between each frame, to avert information degradation. After the framing and windowing, we applied several mel-filter banks and the mel denotes the ears’ perceived frequency, which is computed using Eq. 3 .
where f represent the real frequency and Mel ( f ) represent the corresponding frequency of perception.

Mel-spectrogram of selected emotion.
- Vision transformer
Vision transformers are becoming the standard in the NLP (Natural Language Processing) domain. The attention mechanism is an important element of such a model. It may extract useful features from the input using a typical query, key, and value structure, where the similarity between queries and keys is pulled out by matrix multiplication between queries and keys. In order to effectively extract many scales, multiple resolutions, and high-level spatial features, vision transformers use a multi-head attention mechanism. The global average pooling system is then used to up-sample and concatenate the dense feature maps that have been produced. To be able to successfully learn and extract the intricate features relevant to emotion recognition in mel-spectrogram image, the method makes use of both local and global attention, as well as global average pooling. As illustrated in our proposed architecture, the entire model ranges from flattening to the classification of emotion. The input image is broken up into patches of defined size, fattened and linearly embedded, added to position embedding, and then transferred to the Transformer encoder.
The Vision Transformers have much less image-specific inductive bias than CNNs, hence, we leverage its capability to classify seven human emotions: angry, sad, disgust, fear, happiness, neutral and surprise as shown in our model. Our proposed vision transformer model for SER is not heavy, unlike many baseline models. It comprises 4, 166, 151 total and trainable parameters, with 0 non-trainable parameters, thereby it reduces computational complexity. In the first stage, a feature vector of shape \((n+1, d)\) is created by embedding an input image(spectrogram) of shape (height, width, and channels) into it 62 . Then, in raster order, the image is splatted into n square patches of shape ( t , t , c ), where t is a pre-defined value. Patches are then flattened, producing n line vectors with the shape \((1, t^2*c)\) . The flattened patches are multiplied by a trainable embedding tensor of shape \((t^2*c, d)\) that learns to linearly project each flat patch to dimension d. Our model dimension is 128, with 32 patch sizes.
The ViT model’s functional components and corresponding functions in the model architecture are succinctly summarized by the functional components as shown in Table 1 . Collectively, they improve the ViT model’s ability to identify spatial dependencies and extract relevant representations from speech signals for recognition of speech emotions.
Core module analysis of ViT
The proposed ViTSER model in this study utilizes two core audio transformer modules which are self-attention and multi-head attention. The first mechanism is self-attention, which computes representations for the inputs by relating various positions of input sequences. It employs three specific inputs: values ( V ), keys ( K ), and queries ( Q ). The result of a single query is calculated as the weighted sum of the values, with each weight being determined by a specially constructed query function that uses the associated key. Here, we employ an efficient self-attention method that is based on Dot-product 63 as computed in Eq. 4.
where the softmax function is prevented from entering regions with extremely small gradients by using the scalar \(\frac{1}{\sqrt{d_k}}\) .
Secondly, another core module of the audio transformer is multi-head attention, which is used to simultaneously exploit several attending representations. The calculation of multi-head attention is h times scaled Dot-Product Attention, where h is the number of heads. Three linear projections are used before each attention for transforming the queries, keys, and values, respectively, into more discriminating representations. Next, as shown in Eq. 5 , each Scaled Dot-Product Attention is computed separately and its outputs are concatenated.
where \( head_i=Attention({\textbf {QW}}^{Q}_{i}, {\textbf {KW}}^{K}_{i}, {\textbf {VW}}^{V}_{i})\)
We employed an activation function known as Gaussian Error Linear Unit (GELU), a high-performing activation function in many speech-related tasks and NLP 64 as compared to RELu (Reactivation Linear Unit). Rather than gating inputs by their sign as in ReLUs, the GELU non-linearity weights inputs according to their value. The GELU activation function is \(x\Phi (x)\) , for an input x is defined from Eq. 6 .
where \(\Phi (x)\) denotes the standard Gaussian cumulative distribution function.
Experimental result
In this section, the full details of how we carried out our extensive experiment and evaluation of our model are highlighted. To demonstrate the significance and robustness of our model for the SER utilizing speech spectrograms, we effectively validate our system in this part using two benchmark TESS and EMODB speech datasets. Using the same phenomena, we evaluated the effectiveness of our SER system and contrasted it with other baseline SER systems. The next sections go into further detail on the datasets that were used, the accuracy matrices, and the results of the study.
The Toronto English Speech Set, or TESS for short, one of the largest freely available datasets, has been used in numerous SER projects. The Auditory Laboratory at Northwestern University recorded TESS speech samples in 2010 65 . During the spontaneous event, two actors were given instructions to pronounce a couple of the 200 words. Their voices were recorded, providing a comprehensive collection of 2800 speech utterances. Seven different feelings were seen in the scenario: happy, angry, scared, disgusted, pleasant, surprised, sad, and neutral. Figure 4 provides an illustration of the TESS description based on each emotion’s contribution to the whole speech dataset.

TESS dataset emotion distribution.

EMODB dataset emotion distribution.
EMOD is one of the most predominantly utilized datasets, commonly known as the Berlin emotion dataset 66 or the EMO-DB. This well-known and well-liked dataset of speech emotions contains 535 voice utterances expressing seven different emotions. Five men and five women, all experts, read prescriptive words and recorded various emotions for the suggested dataset. Time is captured with a sampling rate of 16 kHz and an average duration of 2 to 3 seconds in the EMO-DB corpus. Every utterance has the same temporal scale, allowing the entire speech to fit within the window size. The EMO-DB corpus, which is widely used in the SER field, forms the foundation for several emotion recognition algorithms. Figure 5 illustrates the summary of the overall utterances, participation rate, and selected emotions.
Model implementation
The primary framework for the model implementation uses PyTorch 67 components. We modified the size of the images during the pre-processing stage to accommodate the dimensions of 224 x 224 on three separate channels (corresponding to the RGB channels); we have delved into more depth about speech data pre-processing in the previous section. The experiment was carried out on a computing resource that includes \([email protected] Ghz\) , 64GB RAM, and the Google Colab platform. We utilized the Adam optimizer with sparse categorical cross entropy loss function and \(3.63E-03\) as the learning rate during the training phase. We obtained optimum accuracy at 75 epoch. Finally, using a simple momentum of 0.9, we accelerated training and variable learning by the experiment’s chosen optimizer. Two public datasets (TESS and EMODB) are used, with the combination of the two datasets to form the third set of datasets (TESS-EMOD) for assessing the performance and generalizability of our model. The overall description of the hyperparameters utilized in this work is highlighted in Table 2
Evaluation metrics
Standard metrics are typically used to evaluate the effectiveness of deep learning models for emotion identification tasks. Based on several performance criteria, including precision, recall, accuracy, and F1-score as provided in Eqs. ( 6 )–( 9 ), the proposed method’s results are contrasted. Precision and recall reflect the qualitative and quantitative performance of the proposed SER system, whilst accuracy represents the percentage of accurate predictions out of the total number of cases analyzed. Recall (sensitivity) measures the proportion of actual positive cases from all actual positive cases, while precision measures the proportion of true positive (TP) cases from all predicted positive cases. The harmonic mean of the precision and recall are provided by the F1-score 68 .
Furthermore, we adopted the confusion matrix metric which gives a more meaningful insight into the outcome of our experiment. It uses variables such as FP (false positive), FN (false negative), TP (true positive), and TN (true negative) 69 in depicting the combinations of true and predicted classes from a given speech dataset.
Results of experiments and discussion
This section describes the result of our extensive experiments carried out to assess the performance of our proposed model for speech emotion recognition tasks. The collection of tests is utilized to assess how well the model recognizes unknown speech utterances. The system generalization error is approximately represented by the model prediction error 70 . The cross-validation estimation approach is used in this study to thoroughly assess each dataset. The database’s data is divided into two categories: training data and testing data. There are k fragments to the original data in which the k part of the data is utilized for training, while one portion is used as test data. K-fold cross-validation is a term used to describe the test procedure, which is carried out k times across various portions of all the data 71 . For an in-depth assessment of our technique, we applied a well-known 5-fold cross-validation assessment method. The visual representation of the model loss is shown in Fig. 6 . The uniqueness of our proposed model as displayed in the figure, indicates its effectiveness as the loss decreases on both training and testing data. The highest loss value for the three experiments were 0.13, 0.2 and 0.25 on TESS, EMODB and TESS-EMODB respectively.

The figure illustrates the proposed model’s performance loss curve for the three benchmarked datasets. ( a ) Loss diagram on TESS dataset ( b ) Loss diagram on EMODB dataset and ( c ) Loss diagram on TESS-EMODB dataset.
According to the speech databases used, which include a variety of emotions-seven distinct ones-selected following Ekman’s 72 postulation. We investigated the proposed model and presented the emotional level prediction performance in Tables 3 , 4 and 5 together with the resulting confusion matrices. Our model’s prediction performance displays precision, recall, F1-Score, weighted results, and un-weighted results, which amply demonstrates the model’s superiority over state-of-the-art techniques. According to the detailed classification(emotional level prediction) report, it is obvious that the highest recognition was obtained for precision, F1-score and recall on neutral emotion with 100% from the TESS dataset, followed by disgust with 99% from EMODB respectively, and the least recall rate was recorded on boredom with 76%.
We summarized the classification report in the above tables for each emotion using 3 metrics on 6 emotions as shown in Fig. 7 . Our method demonstrates higher performance than the state-of-the-art approach in terms of the overall recognition of emotions, especially for disgust, neutral, sad and fear respectively. Our model recognizes the emotions from the frequency pixels and salient features to enhance recognition accuracy and mitigate the overall computational cost. Most of the baseline models detected disgust emotions with low accuracy because of their paralinguistic content, however, our model outperformed others with high precision and recall of 99% with only happy emotion demonstrating the least recognition of 82% recall.

Summary of classification report for F1-Score, Recall and Precision.

Confusion matrix for TESS, EMODB and TESS-EMODB.

Test sample of emotion recognition output of the proposed model on three datasets: (i) represents recognition output on TESS dataset (ii) represents recognition output on EMODB dataset (iii) represent recognition output on TESS-EMODB dataset.
In furtherance of our investigation, we obtain a confusion matrix for the three datasets to show a class-wise recognition accuracy as shown in Fig. 8 . We achieved the highest recognition accuracy from the confusion matrix on angry, neutral and disgust with 99%, 98% and 95% respectively. Only boredom emotion showed the least recognition from our confusion matrix, but the classification report recorded a vivid minimum recognition of 76.0% recall and 88.0% precision. The hybrid dataset of TESS-EMODB recorded the lowest accuracy 74% on sad emotion and a 100% overall for angry emotion for six emotions, which further established the robustness of our proposed model for SER.
The simplicity of the model architectural design has in doubt contributed to its performance in enhancing the SER recognition rate, thereby, reducing misclassification of emotion and making it suitable for real-time applications in monitoring human behavioural patterns. The novelty of the model inappropriately recognizing emotion from speech utterances(mel-spectrogram) is also confirmed with selected emotion as shown in Fig. 9 . Only three emotions out of about thirty selected for the test had wrong predictions, but twenty-seven of the rest were rightly predicted as the actual emotion. The first label represents the actual emotion, while the second label directly under it is the predicted.
Performance evaluation
The comparative experiment aimed to evaluate the exact role that the Vision Transformer (ViT) model contributed to enhancing the speech emotion recognition ability that we observed. To carry out this extensive experiment, we substituted other deep learning-based architectures for the ViT model in our proposed framework, as shown in Table 6 .
Though, while processing visual data in a similar way to the ViT model, they did not possess the distinctive architectural features of the ViT in capturing long-range dependencies efficiently. Two speech datasets used in this work are represented by the SDT1 and SDT2. The comparative study’s results, which showed that the ViT model could enhance speech emotion recognition with fewer parameters while still achieving higher accuracy than other architectures, provided significant fresh insight. The apparent decrease in accuracy when utilizing other architectures highlights the significance of the self-attention mechanism of the ViT model in detecting nuanced spatial relationships that are essential for comprehending emotional nuances in human speech.
The comparative analysis of our proposed model’s superior performance with other existing methods was carried out as illustrated in Table 10 , using the selected speech emotion database, to demonstrate further our SER method’s generalizability and suitability for real-time applications. The proposed method demonstrates the recent success of deep learning transformer in the SER domain, which recognized all the emotions with high accuracy, including even the neutral emotion, using an unambiguous architecture. In the table, we reveal the surpassing results of the proposed system, which are substantially greater than other methods, indicating the efficiency of our method. We carried out ablation experiments as indicated in Tables 7 , 8 , 9 , with a focus on various patch sizes of the spectrogram image and removal of the embedded dropout layer component of the proposed model. The first experiment result obtained from Table 7 shows that the removal of the embedded dropout layer as a functional component of the model significantly reduces the speech emotion recognition accuracy. The accuracy dropped by 6%, and 2.03% on TESS and EMODB datasets respectively. Likewise, the second ablation experiment’s results from the two datasets with varying patch sizes indicated that the model declined in overall accuracy(OVA) as the patch size decreased. However, 14 and 32 represent the minimum and maximum patch sizes utilized in the experiments(Tables 8 and 9 ). It was obvious during the experiment that patch sizes above 32 increase the computational complexity, therefore we stopped at 32 which yielded an optimum accuracy without any need for parameter tuning (Table 10 ).
In this research, a novel Vision Transformer model based on the mel-spectrogram and deep features was developed for the problem of speech emotion recognition. To assure accuracy, a simple MLP head attention with 128 dimensions was utilized to extract the deep features. With flattening, tokenizer, 32 patch size, position embedding, self-attention, and MLP head layers for enhancing SER, we developed a vision transformer model. The computational complexity was minimized due to the compactness of our model architecture, which is responsible for reducing an excessive number of parameters. To demonstrate the efficacy along with the significance and generalization of the model, its performance was assessed using two benchmark datasets: TESS and EMO-DB as opposed to 25 . The proposed system outperformed the state-of-the-art in terms of prediction results. Extensive experiments using our model produced astounding recognition accuracy scores of 98% for the TESS dataset, 91% for the EMO-DB, and 93% when the two datasets were combined. In order to recognize all emotions with better accuracy and a smaller model size to produce computationally friendly output, the proposed model improved by 2% and 5% over the state-of-the-art accuracy. The results of the proposed approach demonstrated the capability of Vision Transformer to capture global contextual information, making it possible to model long-range dependencies and enhance the representation of emotional speech patterns, ultimately leading to improved speech emotion recognition. We will concentrate on implementing this kind of system in additional speech recognition-related task systems in the future and go into more detail. Similar to this, we will conduct some tests to evaluate the effectiveness of the proposed method and the obtained results on other datasets, including non-synthetic speech corpora. When combined with other deep learning techniques, the recognition rates are likely to rise. Utilizing additional speech features such as the Mel-Frequency Cepstral Coefficient (MFCC), Chromagram, and Tonnetz can enhance the investigation as they form part of our future work as well.
Data availability
The two publicly available datasets used or analysed for this study are available at: (i) the Tspace repository (https://tspace.library.utoronto.ca/handle/1807/24487) for the TESS dataset and (ii) Berlin Database of Emotional Speech repository (http://emodb.bilderbar.info/showresults/index.php) for EMODB dataset.
Alsabhan, W. Human-computer interaction with a real-time speech emotion recognition with ensembling techniques 1d. Sensors (Switzerland) 23 (1386), 1–21. https://doi.org/10.3390/s2303138 (2023).
Article Google Scholar
Yahia, A. C., Moussaoui, Frahta, N. & Moussaoui, A. Effective speech emotion recognition using deep learning approaches for Algerian Dialect. In In Proc. Intl. Conf. of Women in Data Science at Taif University, WiDSTaif 1–6 (2021). https://doi.org/10.1109/WIDSTAIF52235.2021.9430224
Blackwell, A. Human Computer Interaction-Lecture Notes Cambridge Computer Science Tripos, Part II. https://www.cl.cam.ac.uk/teaching/1011/HCI/HCI2010.pdf (2010)
Muthusamy, K. H., Polat, Yaacob, S. Improved emotion recognition using gaussian mixture model and extreme learning machine in speech and glottal signals. Math. Probl. Eng. (2015). https://doi.org/10.1155/2015/394083
Xie, J., Zhu, M. & Hu, K. Fusion-based speech emotion classification using two-stage feature selection. Speech Commun. 66 (6), 102955. https://doi.org/10.1016/j.specom.2023.102955 (2023).
Vryzas, N., Kotsakis, R., Liatsou, A., Dimoulas, C. & Kalliris, G. Speech emotion recognition for performance interaction. AES J. Audio Eng. Soc. 66 (6), 457–467. https://doi.org/10.17743/jaes.2018.0036 (2018).
Hemin, I., Chu Kiong, L. & Fady, A. Bidirectional parallel echo state network for speech emotion recognition. Neural Comput. Appl. 34 , 17581–17599. https://doi.org/10.1007/s00521-022-07410-2 (2022).
Vaaras, E., Ahlqvist-björkroth, S., Drossos, K. & Lehtonen, L. Development of a speech emotion recognizer for large-scale child-centered audio recordings from a hospital environment. Speech Commun. 148 (May), 9–22. https://doi.org/10.1016/j.specom.2023.02.001 (2022).
Dev Priya, G., Kushagra, M., Ngoc Duy, N., Natesan, S. & Chee Peng, L. Towards an efficient backbone for preserving features in speech emotion recognition: Deep-shallow convolution with recurrent neural network. Neural Comput. Appl. 35 , 2457–2469. https://doi.org/10.1007/s00521-022-07723-2 (2023).
Haider, F., Pollak, S., Albert, P. & Luz, S. Emotion recognition in low-resource settings: An evaluation of automatic feature selection methods. Comput. Speech Lang. 65 , 101119. https://doi.org/10.1016/j.csl.2020.101119 (2021).
Oh, S., Lee, J. Y. & Kim, D. K. The design of cnn architectures for optimal six basic emotion classification using multiple physiological signals. Sensors (Switzerland) 20 (3), 1–17. https://doi.org/10.3390/s20030866 (2020).
Kwon, S. A cnn-assisted enhanced audio signal processing. Sensors (Switzerland) https://doi.org/10.3390/s20010183 (2020).
Article PubMed Central Google Scholar
Dutta, S. & Ganapathy, S. Multimodal transformer with learnable frontend and self attention for emotion recognition. In In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Singapore, 23-27 May 6917–6921 (2022). https://doi.org/10.1109/ICEIC57457.2023.10049941
Chai, J., Zeng, H., Li, A. & Ngai, E. W. T. Deep learning in computer vision: A critical review of emerging techniques and application scenarios. Mach. Learn. Appl. 6 (August), 100134. https://doi.org/10.1016/j.mlwa.2021.100134 (2021).
Atsavasirilert, K., Theeramunkong, T., Usanavasin, S., Rugchatjaroen, A., Boonkla, S., Karnjana, J., Keerativittayanun, S. & Okumura, M. A light-weight deep convolutional neural network for speech emotion recognition using mel-spectrograms. In In 2019 14th International Joint Symposium on Artificial Intelligence and Natural Language Processing (iSAI-NLP) (2019)
Jain, M., Narayan, S., Balaji, K. P., Bharath, K., Bhowmick, A., Karthik, R. & Muthu, R. K. Speech emotion recognition using support vector machine. arXiv:2002.07590 . (2013)
Al Dujaili, M. J., Ebrahimi-Moghadam, A. & Fatlawi, A. Speech emotion recognition based on svm and knn classifications fusion. Int. J. Electr. Comput. Eng. (IJECE) 11 , 1259–1264 (2021).
Mansour, S., Mahdi, B. & Davood, G. Modular neural-svm scheme for speech emotion recognition using anova feature selection method. Neural Comput. Appl. 23 , 215–227 (2013).
Cheng, X. & Duan, Q. Speech emotion recognition using Gaussian mixture model. In In Proceedings of the 2012 International Conference on Computer Application and System Modeling (ICCASM) 1222–1225 (2012)
Lanjewar, R. B., Mathurkar, S. & Patel, N. Implementation and comparison of speech emotion recognition system using gaussian mixture model (gmm) and k- nearest neighbor (k-nn) techniques. Phys. Rev. E 49 , 50–57 (2015).
Google Scholar
Mao, X., Chen, L. & Fu, L. Multi-level speech emotion recognition based on HMM and ANN. In In Proceedings of the 2009 WRI World Congress on Computer Science and Information Engineering 225–229 (2009)
Mirsamadi, S., Barsoum, E. & Zhang, C. Automatic speech emotion recognition using recurrent neural networks with local attention. In In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2227–2231 (2017)
Atmaja, B. T. & Akagi, M. Speech emotion recognition based on speech segment using LSTM with attention model. In In Proceedings of the 2019 IEEE International Conference on Signals and Systems 40–44 (2019)
Xie, Y. et al. Speech emotion classification using attention-based lstm. IEEE/ACM Trans. Audio Speech Lang. Process 27 , 1675–1685. https://doi.org/10.1109/CCECE47787.2020.9255752 (2019).
Ayush Kumar, C., Das Maharana, A., Krishnan, S., Sri, S., Hanuma, S., Jyothish Lal, G. & Ravi, V. Speech emotion recognition using CNN-LSTM and vision transformer. In In Book Innovations in Bio-Inspired Computing and Applications (2023)
Diao, H., Hao, Y., Xu, S. & Li, G. Implementation of lightweight convolutional neural networks via layer-wise differentiable compression. Sensors https://doi.org/10.3390/s21103464 (2021).
Article PubMed PubMed Central Google Scholar
Manohar, K. & Logashanmugam, E. Hybrid deep learning with optimal feature selection for speech emotion recognition using improved meta-heuristic algorithm. Knowl. Based Syst. https://doi.org/10.1016/j.knosys.2022.108659 (2022).
Fagbuagun, O., Folorunsho, O. & Adewole, L. Akin-Olayemi: Breast cancer diagnosis in women using neural networks and deep learning. J. ICT Resour. Appl. 16 (2), 152–166 (2022).
Qayyum, A. B. A., Arefeen, A. & Shahnaz, C. Convolutional neural network (CNN) based speech-emotion recognition. In In Proceedings of the 2019 IEEE International Conference on Signal Processing, Information, Communication and Systems (SPICSCON) 122–125 (2019)
Harár, P., Burget, R. & Dutta, M. K. Speech emotion recognition with deep learning. In In Proceedings of the 2017 4th International Conference on Signal Processing and Integrated Networks (SPIN) 137–140 (2017)
Fahad, S., Deepak, A., Pradhan, G. & Yadav, J. Dnn-hmm-based speaker-adaptive emotion recognition using mfcc and epoch-based features. Circuits Syst. Signal Process 40 , 466–489 (2022).
Singh, P. & Saha, G. Modulation spectral features for speech emotion recognition using deep neural networks. Speech Commun. 146 , 53–69. https://doi.org/10.1016/j.specom.2022.11.005 (2023).
G., W., H., L., J., H., D., L. & E., X. Random deep belief networks for recognizing emotions from speech signals. Comput. Intell. Neurosci. 1–9 (2017)
Poon-Feng, K., Huang, D. Y., Dong, M. & Li, H. Acoustic emotion recognition based on fusion of multiple feature-dependent deep boltzmann machines. In In Proceedings of the 9th International Symposium on Chinese Spoken Language Processing 584–588 (2014)
Zeng, Y., Mao, H., Peng, D. & Yi, Z. Spectrogram based multi-task audio classification. Multimed. Tools Appl. 78 , 3705–3722 (2017).
Popova, A. S., Rassadin, A. G. & Ponomarenko, A. A. Emotion recognition in sound. In In Proceedings of the International Conference on Neuroinformatics, Moscow, Russia, 2-6 October 117–124 (Springer, 2017)
Issa, D., Fatih Demirci, M. & Yazici, A. Speech emotion recognition with deep convolutional neural networks. Biomed. Signal Process. Control 59 , 101894. https://doi.org/10.1016/j.bspc.2020.101894 (2020).
Li, H., Ding, W., Wu, Z. & Liu, Z. Learning fine-grained cross-modality excitement for speech emotion recognition. arXiv:2010.12733 (2010)
Zhao, J., Mao, X. & Chen, L. Speech emotion recognition using deep 1d and 2d cnn lstm networks. Biomed. Signal Process. Control 47 , 312–323. https://doi.org/10.1016/j.bspc.2018.08.035 (2019).
Zeng, M. & Xiao, N. Effective combination of densenet and bilstm for keyword spotting. IEEE Access 7 , 10767–10775 (2019).
Puri, T., Soni, M., Dhiman, G., Khalaf, O. I. & Khan, I. R. Detection of emotion of speech for ravdess audio using hybrid convolution neural network. Hindawi J. Healthc. Eng. ii https://doi.org/10.1155/2022/8472947 (2022).
Schuller, B., Steidl, S., Batliner, A., Vinciarelli, A., Scherer, K., Ringeval, F., Chetouani, M., Weninger, F., Eyben, F. & Marchi, E. The INTERSPEECH 2013 computational paralinguistics challenge: Social signals, conflict, emotion, autismn. In In Proceedings of the INTERSPEECH 2013, 14th Annual Conference of the International Speech Communication Association, Lyon, France (2013)
Zhu, L., Chen, L., Zhao, D., Zhou, J. & Zhang, W. Emotion recognition from Chinese speech for smart affective services using a combination of svm and dbn. Sensors 17 , 1694. https://doi.org/10.3390/s17071694 (2017).
Article ADS PubMed PubMed Central Google Scholar
Pawar, M. D. & Kokate, R. D. Convolution neural network based automatic speech emotion recognition using mel-frequency cepstrum coefficients. Multimed. Tools Appl. 80 , 15563–15587 (2021).
Bhangale, K. & Kothandaraman, M. Speech emotion recognition based on multiple acoustic features and deep convolutional neural network. Electronics (Switzerland) https://doi.org/10.3390/electronics12040839 (2023).
Badshah, A. M. et al. Deep features-based speech emotion recognition for smart affective services. Multimed. Tools Appl. 78 , 5571–5589. https://doi.org/10.1007/s11042-017-5292-7 (2019).
Latif, S., Zaidi, A., Cuayahuitl, H., Shamshad, F., Shoukat, M. & Qadir, J. Transformers in speech processing: A survey. http://arxiv.org/abs/2303.11607 16, 1–27 (2023)
Chen, S. et al. Wavlm: Large-scale self-supervised pre- training for full stack speech processing. IEEE J. Sel. Top. Signal Process. 16 , 1505–1518 (2022).
Article ADS Google Scholar
Xu, M., Li, S., X., Z.: Transformer-based end-to-end speech recognition with local dense synthesizer attention. In ICASSP 2021- 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 5899–5903 (IEEE, 2021)
Shor, J., Jansen, A., Han, W., Park, D. & Zhang, Y. Universal paralinguistic speech representations using self-supervised conformers. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 3169–3173 (IEEE, 2022)
Chen, W., Xing, X., Xu, X., Pang, J. & Du, L. Speechformer: A hierarchical efficient framework incorporating the characteristics of speech. arXiv preprint arXiv:2203.03812 (2022)
Gao, Z., Zhang, S., McLoughlin, I. & Yan, Z. Paraformer: Fast and accurate parallel transformer for non-autoregressive end-to-end speech recognition. arXiv preprint arXiv:2206.08317 (2022)
Kumawat, P. & Routray, A. Applying TDNN architectures for analyzing duration dependencies on speech emotion recognition. In In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH 561–565 (2021). https://doi.org/10.21437/Interspeech.2021-2168
Han, S., Leng, F. & Jin, Z. Speech emotion recognition with a ResNet-CNN-transformer parallel neural network. In In Proceedings of the International Conference on Communications, Information System and Computer Engineering(CISCE) 803–807 (2021)
John, V. & Kawanishi, Y. Audio and video-based emotion recognition using multimodal transformers. In In Proceedings of International Conference on Pattern Recognition 2582–2588 (2022)
Slimi, A., Nicolas, H. & Zrigui, M. Hybrid time distributed CNN-transformer for speech emotion recognition. In In Proceedings of the 17th International Conference on Software Technologies ICSOFT (2022)
Chaudhari, A., Bhatt, C., Krishna, A. & Mazzeo, P. L. Vitfer: Facial emotion recognition with vision transformers. Appl. Syst. Innov. https://doi.org/10.3390/asi5040080 (2022).
Arezzo, A. & Berretti, S. SPEAKER VGG CCT: Cross-corpus speech emotion recognition with speaker embedding and vision transformersn. In In Proceedings of the 4th ACM International Conference on Multimedia in Asia, MMAsia (2022)
Latif, S., Zaidi, A., Cuayahuitl, H., Shamshad, F., Shoukat, M. & Qadir, J. Benchmarks for testing community detection algorithms on directed and weighted graphs with overlapping communities. arxiv.org/abs/2303.11607 (2023)
Alluhaidan, A. S., Saidani, O., Jahangir, R., Nauman, M. A. & Neffati, O. S. Speech emotion recognition through hybrid features and convolutional neural network. Appl. Sci. (Switzerland) 13(8) (2023)
Domingos, P. A few useful things to know about machine learning. Commun. ACM 55 (2012)
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J. & Houlsby, N. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. In In Proceedings of ICLR 2021 AN (2021)
Dong, L., Xu, S. & Xu, B. Speech-transformer: A no-recurrence sequence-to-sequence model for speech recognition. In ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing - Proceedings 2236 (1), 5884–5888. https://doi.org/10.1109/ICASSP.2018.8462506 (2018).
Hendrycks, D. & Gimpel, K. Gaussian error linear units (gelus). ArXiv:1606.08415v5 [Cs.LG], 1–10 (2023)
Pichora-Fuller, M. K. & Dupuis, K. Toronto emotional speech set (tess). https://doi.org/10.5683/SP2/E8H2MF. (2020)
Burkhardt, F., Paeschke, A., Rolfes, M., Sendlmeier, W. F. & Weiss, B. A database of german emotional speech (emodb). INTERSPEECH, 1517–1520 (2005)
Paszke, A., Gross, S., Chintala, S., Chanan, G., Yang, E., DeVito, Z., Lin, Z., Desmaison, A., Antiga, L. & Lerer, A. Automatic Differentiation in Pytorch. In In Proceedings of Advances in NIPS (2017)
Xu, Y., Zhang, J. & Miao, D. Three-way confusion matrix for classification. A measure driven view. Inf. Sci. 507 , 772–794 (2020).
Article MathSciNet Google Scholar
Deng, X., Liu, Q., Deng, Y. & Mahadevan, S. An improved method to construct basic probability assignment based on the confusion matrix for classification problem. Inf. Sci. 340 , 250–261 (2016).
Snmez, Y., & Varol, A. In-depth analysis of speech production, auditory system, emotion theories and emotion recognition. In In Proceedings of the 2020 8th International Symposium on Digital Forensics and Security (ISDFS) (2020)
Shu, L. et al. A review of emotion recognition using physiological signals. Sensors 18 , 2074. https://doi.org/10.1007/978-3-319-58996-1_13 (2018).
Ekman, P. & Davidson, R. J. The Nature of Emotion: Fundamental Questions (Oxford University Press, 1994)
Chen, M., He, X., Yang, J., H., Z.: 3-d convolutional recurrent neural networks with attention model for speech emotion recognition. IEEE Signal Process. Lett. 25(10), 1440–1444 (2018)
Jiang, P., Fu, H., Tao, H., Lei, P. & Zhao, L. Parallelized convolutional recurrent neural network with spectral features for speech emotion recognition. IEEE Access 7 , 90368–90377. https://doi.org/10.1109/ACCESS.2019.2927384 (2019).
Meng, H., Yan, T., Yuan, F. & Wei, H. Speech emotion recognition from 3d log-mel spectrograms with deep learning network. IEEE Access 7 , 125868–12588 (2019).
Mustaqeem, M., Sajjad, M., & K, S. Clustering based speech emotion recognition by incorporating learned features and deep bilstm. IEEE Access (2020). https://doi.org/10.1109/ACCESS.2020.2990405
Mustaqeem, Kwon, S. Mlt-dnet: Speech emotion recognition using 1d dilated cnn based on multi-learning trick approach. Expert Syst. Appl. 114177 (2021). https://doi.org/10.1016/j.eswa.2020.114177
Guizzo, E., Weyde, T., Scardapane, S. & Comminiello, D. Learning speech emotion representations in the quaternion domain. IEEE/ACM Trans. Audio Speech Lang. Process. 31 , 1200–1212 (2022).
Wen, G. et al. Self-labeling with feature transfer for speech emotion recognition. Knowl. Based Syst. 254 , 109589 (2022).
Verma, D. & Mukhopadhyay, D. Age driven automatic speech emotion recognition system. In In Proceeding of IEEE International Conference on Computing, Communication and Automation (2017)
Praseetha, V. & Vadivel, S. Deep learning models for speech emotion recognition. J. Comput. Sci. 14(11) (2018)
Gao, Y. Speech-Based Emotion Recognition. https://libraetd.lib.virginia.edu/downloads/2f75r8498?filename=1GaoYe2019MS.pdf (2019)
Krishnan, P. T., Joseph Raj, A. N. & Rajangam, V. Emotion classification from speech signal based on empirical mode decomposition and non-linear features. Complex Intell. Syst. 7 (4), 1919–1934. https://doi.org/10.1007/s40747-021-00295-z (2021).
Chimthankar, P. P. Speech Emotion Recognition using Deep Learning. http://norma.ncirl.ie/5142/1/priychimtankar.pdf (2021)
Akinpelu, S. & Viriri, S. Robust feature selection-based speech emotion classification using deep transfer learning. Appl. Sci. 12 , 8265. https://doi.org/10.3390/app12168265 (2022).
Article CAS Google Scholar
Choudhary, R. R., Meena, G. & Mohbey, K. K. Speech emotion based sentiment recognition using deep neural networks. J. Phys. Conf. Ser. 2236 (1), 012003 (2022).
Download references
Author information
Authors and affiliations.
School of Mathematics, Statistics and Computer Science, University of KwaZulu-Natal, Durban, 4001, South Africa
Samson Akinpelu, Serestina Viriri & Adekanmi Adegun
You can also search for this author in PubMed Google Scholar
Contributions
Conceptualization, S.A. and V.S.; Methodology, A.A. and S.A.; Software, S.A.; Validation, S.V. and A. A; Formal analysis, S.V.; Investigation, S.A.; Resources, S.V.; Data curation, S.A.; Writing original draft preparation, S.A. and A.A; review and editing, S.V.
Corresponding author
Correspondence to Serestina Viriri .
Ethics declarations
Competing interests.
The authors declare no competing interests.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
Akinpelu, S., Viriri, S. & Adegun, A. An enhanced speech emotion recognition using vision transformer. Sci Rep 14 , 13126 (2024). https://doi.org/10.1038/s41598-024-63776-4
Download citation
Received : 09 September 2023
Accepted : 02 June 2024
Published : 07 June 2024
DOI : https://doi.org/10.1038/s41598-024-63776-4
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Human–computer interaction
- Deep learning
- Speech emotion recognition
- Mel spectrogram
By submitting a comment you agree to abide by our Terms and Community Guidelines . If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing: AI and Robotics newsletter — what matters in AI and robotics research, free to your inbox weekly.

- The Oxford English Dictionary
- OED Researchers Advisory Group
- The OED Community
- Research sub
- Language Datasets
- Indian Language Datasets
- Oxford Dictionaries API
- Dictionary Solutions
- Pronunciations Data
- Educational Assessment Platforms
- Assisted Writing Solutions
- Gamified Learning
- Semantic English Language Database
Dictionaries
- Dictionaries for your products
- Dictionary Apps
- Oxford Dictionaries Premium
- For English Learners
- For Children
- Creating Content
- Word of the Year
- Branding resources
- Case Studies
- Our dictionary data
Oxford Languages and Google
Google’s English dictionary is provided by Oxford Languages.
Oxford Languages is the world’s leading dictionary publisher, with over 150 years of experience creating and delivering authoritative dictionaries globally in more than 50 languages.
What is included in this English dictionary?
How do we create our dictionaries, why do we include vulgar and offensive words in our dictionaries, why do we include slang and regional dialects in our dictionaries, how do we source our example sentences.
Find out how Oxford Languages is responding to user feedback ⟶
If you would like to get in touch about a specific dictionary entry, please complete the form below.
IMAGES
VIDEO
COMMENTS
Speech recognition, also known as automatic speech recognition (ASR), computer speech recognition or speech-to-text, is a capability that enables a program to process human speech into a written format. While speech recognition is commonly confused with voice recognition, speech recognition focuses on the translation of speech from a verbal ...
Speech recognition is an interdisciplinary subfield of computer science and computational linguistics that develops methodologies and technologies that enable the recognition and translation of spoken language into text by computers. ... Front-end speech recognition is where the provider dictates into a speech-recognition engine, the recognized ...
voice portal (vortal): A voice portal (sometimes called a vortal ) is a Web portal that can be accessed entirely by voice. Ideally, any type of information, service, or transaction found on the Internet could be accessed through a voice portal.
Speech recognition, also known as automatic speech recognition (ASR), speech-to-text (STT), and computer speech recognition, is a technology that enables a computer to recognize and convert spoken language into text. Speech recognition technology uses AI and machine learning models to accurately identify and transcribe different accents ...
Speech recognition is the technology that allows a computer to recognize human speech and process it into text. It's also known as automatic speech recognition (ASR), speech-to-text, or computer speech recognition. Speech recognition systems rely on technologies like artificial intelligence (AI) and machine learning (ML) to gain larger ...
Automatic Speech Recognition (ASR), also known as speech-to-text, is the process by which a computer or electronic device converts human speech into written text. This technology is a subset of computational linguistics that deals with the interpretation and translation of spoken language into text by computers. It enables humans to speak ...
Get speech to text apis. Speech recognition is when a machine or computer program identifies and processes a person's spoken words and converts them into text displayed on a screen or monitor. The early stages of this technology utilized a limited vocabulary set that included common phrases and words. As the software and technology has ...
Some speech recognition systems are speaker-dependent, meaning they require a training period to adjust to specific users' voices for optimum performance. Other systems are speaker-independent, meaning they work without a training period and for any user. ... A speech recognition engine is a component of the larger speech recognition system ...
Automatic Speech Recognition (ASR), also known as Speech-to-Text (STT), is an artificial intelligence technology that converts spoken words into written text. Over the past decade, ASR has evolved to become an integral part of our daily lives, powering voice assistants, smart speakers, voice search, live captioning, and much more.
Speech Recognition is the decoding of human speech into transcribed text through a computer program. To recognize spoken words, the program must transcribe the incoming sound signal into a digitized representation, which must then be compared to an enormous database of digitized representations of spoken words. To transcribe speech with any ...
Automatic Speech Recognition (ASR) is a technology that enables computers to understand and transcribe spoken language into text. It works by analyzing audio input, such as spoken words, and converting them into written text, typically in real-time. ASR systems use algorithms and machine learning techniques to recognize and interpret speech ...
Seeing speech. Speech recognition programs start by turning utterances into a spectrogram:. It's a three-dimensional graph: Time is shown on the horizontal axis, flowing from left to right; Frequency is on the vertical axis, running from bottom to top; Energy is shown by the color of the chart, which indicates how much energy there is in each frequency of the sound at a given time.
At its core, speech recognition technology is the process of converting audio into text for the purpose of conversational AI and voice applications. Speech recognition breaks down into three stages: Automated speech recognition (ASR): The task of transcribing the audio. Natural language processing (NLP): Deriving meaning from speech data and ...
Speech recognition is the process of converting spoken words into written or machine-readable text. It is achieved through a combination of natural language processing, audio inputs, machine learning, and voice recognition. Speech recognition systems analyze speech patterns to identify phonemes, the basic units of sound in a language.
Speech recognition technology enables machines to understand and transcribe human speech, paving the way for applications in various fields such as military, healthcare, and personal assistance. This article explores the advancements, challenges, and practical applications of speech recognition systems.
Speech recognition, also called automatic speech recognition (ASR), computer speech recognition, or speech-to-text, is a form of artificial intelligence and refers to the ability of a computer or machine to interpret spoken words and translate them into text. Often confused with voice recognition, which identifies the speaker, rather than what ...
Speech Recognition & Synthesis, formerly known as Speech Services, is a screen reader application developed by Google for its Android operating system. It powers applications to read aloud (speak) the text on the screen, with support for many languages. Text-to-Speech may be used by apps such as Google Play Books for reading books aloud, Google Translate for reading aloud translations for the ...
The wake word, activate speech recognition, with voice. The first step that initiates the whole process is called the wake word. The main purpose of this first technology in the cycle is to activate the user's voice to detect the voice command he or she wishes to perform. Here, it is literally a matter of "waking up" the system.
The Wav2Letter++ speech engine was created in December 2018 by the team at Facebook AI Research. They advertise it as the first speech recognition engine written entirely in C++ and among the fastest ever. Pros of Wav2Letter++ It is the first ASR system which utilizes only convolutional layers, not recurrent ones. Recurrent layers are common to ...
The Speech Recognition module, often referred to as SpeechRecognition, is a library that allows Python developers to convert spoken language into text by utilizing various speech recognition engines and APIs. It supports multiple services like Google Web Speech API, Microsoft Bing Voice Recognition, IBM Speech to Text, and others.
Speech Recognition is available only in English, French, Spanish, German, Japanese, Simplified Chinese, and Traditional Chinese and only in the corresponding version of Windows; meaning you cannot use the speech recognition engine in one language if you use a version of Windows in another language.
The Arduino Speech Recognition Engine offers the quickest and easiest way to start talking to and with machines. Its extensive software library was developed by worldwide speech recognition leader Cyberon with ease of use and compatibility in mind, so you can instantly integrate new applications - even in existing solutions - and start using your voice to interact with devices.
What is artificial intelligence? Artificial intelligence (AI) is the theory and development of computer systems capable of performing tasks that historically required human intelligence, such as recognizing speech, making decisions, and identifying patterns. AI is an umbrella term that encompasses a wide variety of technologies, including machine learning, deep learning, and natural language ...
Natural language processing definition. Natural language processing (NLP) is a subset of artificial intelligence, computer science, and linguistics focused on making human communication, such as speech and text, comprehensible to computers. NLP is used in a wide variety of everyday products and services.
Speech recognition is part of any application that follows voice commands or answers spoken questions. What makes speech recognition especially challenging is the way people speak—quickly, running words together, with varying emphasis and intonation. Natural language generation (NLG) might be described as the opposite of speech recognition or ...
See Using System.Speech.Recognition opens Windows Speech Recognition, does this help? In general, you can use System.Speech as inproc or shared. When shared, you see a recognizer "widget" on the screen. If you use an inproc recognizer, you control the recognizer and windows does not add a UI. See good Speech recognition API for some more ...
3Play Media is an integrated media accessibility platform with patented solutions for closed captioning, transcription, live captioning, audio description, and subtitling. 3Play Media combines ...
In human-computer interaction systems, speech emotion recognition (SER) plays a crucial role because it enables computers to understand and react to users' emotions. In the past, SER has ...
The role of a descriptive dictionary is to record the existence and meaning of all words in a language, and to clearly identify their status. We include vulgar or offensive words in our dictionaries because such terms are a part of a language's lexicon. However, we label in our dictionaries words that fit into these categories to reflect ...