- A/B Monadic Test
- A/B Pre-Roll Test
- Key Driver Analysis
- Multiple Implicit
- Penalty Reward
- Price Sensitivity
- Segmentation
- Single Implicit
- Category Exploration
- Competitive Landscape
- Consumer Segmentation
- Innovation & Renovation
- Product Portfolio
- Marketing Creatives
- Advertising
- Shelf Optimization
- Performance Monitoring
- Better Brand Health Tracking
- Ad Tracking
- Trend Tracking
- Satisfaction Tracking
- AI Insights
- Case Studies
quantilope is the Consumer Intelligence Platform for all end-to-end research needs

Survey Results: How To Analyze Data and Report on Findings

In this blog, learn how to effectively analyze dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110320">survey data and report on findings that portray an dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110365">actionable insights story for key dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110354">stakeholders .
Table of Contents:
How to analyze survey results.
- How to present survey results
- How to write a survey report
- Common mistakes in analyzing survey results
- Best practices for presenting survey results
How quantilope streamlines the analysis and presentation of survey results
Analyzing dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110318">survey results can feel overwhelming, with so many variables to dig into when looking to pull out the most actionable, interesting consumer stories. Below we’ll walk through how to make the most of your dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110320">survey data through a thorough yet efficient analysis process.
Review your top dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110324">survey questions
Begin your data analysis by identifying the key dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110324">survey questions in your dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110367">questionnaire that align with your broader market dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110338">research questions or business objectives. These are the questions that most closely relate to what you’re trying to achieve with your research project and the ones you should focus on the most. Other variables throughout your survey are important - but they may be better leveraged as cross-analysis variables (i.e. variables you filter down major questions by) rather than ones to be analyzed independently. Which brings us to our next step...
Analyze and cross-analyze your dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110335">quantitative data
dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110335">Quantitative survey questions provide numerical information that can be statistically analyzed. Start by examining top-level numerical responses in your quantitative data (ratings, rankings, frequencies) for your most strategic dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110324">survey questions . Think about which variables might tell an even richer and more meaningful story when cut by dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110347">subgroups (i.e dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110337">cross-tabulation )- such as looking into buying behavior, cut by a dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110328">demographic variable (gender, age, etc). This deeper level of analysis uncovers insights from dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110342">survey dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110319">respondents that may not have been as apparent when examining survey variables in isolation. Take your time during this step to explore your data and identify interesting stories that you’ll eventually want to use in a final report. This is the fun part! At least us at quantilope think so...
Consider dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110346">statistical analysis
Next, run dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110346">statistical analysis on relevant questions. Traditional agencies typically require the help from a behavioral science/data processing team for this, but many automated platforms (like quantilope) can run dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110346">statistical analysis without any manual effort required.
dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110339">Statistical significance testing provides an added layer of validity to your data, giving dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110354">stakeholders even more confidence in the recommendations you’re making. Knowing which dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110345">data points are significantly stronger/weaker than others confirms where you can have the most confidence in your data.
Back to table of contents
How to present survey results
Data is a powerful tool, but it's only valuable if your audience can grasp its meaning. Visual representations of your dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110335">quantitative data can offer insights into patterns or trends that you may have missed when looking strictly at the numbers and they offer a clear, compelling way to present your findings to others.
dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110336">Data visualization can sometimes be done while you’re analyzing and cross-analyzing your data (if using an automated platform like quantilope). Otherwise, this is the step in your insights process when you’ll take the findings you found during the analysis stage and give them life through intuitive charts and dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110321">graphs .
Below are a few steps to clearly visualize insights once you dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110352">collect data :
Choose your chart types:
The first step is to select the right chart type for your data based on the dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110369">type of question asked. No one chart fits all dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110351">types of data . Choose a chart that clearly displays each of your dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110345">data points ’ stories in the most appropriate way. Below are a few commonly used chart types in dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110370">market research :
Column/ dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110368">bar dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110321">graphs : Great for comparing categories.
Line charts: Show trends and changes over time compared to an initial dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110331">benchmark (great for a brand tracking survey ).
dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110334">Pie charts : Used to display parts of a whole.
Scatter plots: Visualize the relationship between two variables (used in a Key Driver Analysis! ).
dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110356">Word clouds : Good for concise dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110358">open-ended responses (i.e. brand names) to see which words appear biggest/smallest (representing the volume of feedback, respectively).
The right chart type will clearly display meaningful patterns and insights. quantilope’s platform makes it easy to toggle between different chart types and choose the one that best represents your data - significance testing already included!
Leverage numerical tables:
Sometimes, nothing beats the precision and detail of a well-structured numerical table. When you need to provide exact values or compare specific dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110345">data points , numerical tables are your go-to. When using numerical tables to present your findings, make sure they are:
Clear: Use explanatory headings and proper, consistent formatting.
Concise: Present only the essential data without unnecessary clutter.
How to write a dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110332">survey report
Lastly, take your data analysis - complete with chart visualizations and dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110346">statistical analyses , and build a final report such as a slide report deck or an interactive dashboard.
This is where you’ll want to put your strategic thinking hat on to determine which charts, headlines, graphics, etc., are going to be most compelling/interesting to final dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110354">stakeholders and key decision makers; them buying into your data is not done purely on the data itself, rather how you organize and present it.
Below are a few considerations when building and writing your final dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110332">survey report :
Start with dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110340">methodology :
Start by clearly describing how you designed and administered your survey to dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110319">respondents . Include details like:
Sampling methods: How were participants selected ( random, convenience, representative )
dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110327">Sample size : How many people participated in your study?
Sampling timeframe: When did your study run?
Survey format: Where did you administer your survey? (online, phone, in-person, etc.)
Question types: dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110348">Multiple choice , dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110323">open-ended questions , dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110361">likert scales , and so on.
Advanced methods: Did you leverage any advanced dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110340">methodologies beyond standard usage and attitude questions such as NPS ( dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110341">net promoter score ) for dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110349">customer satisfaction or a segmentation for need-based dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110362">customer feedback ?
Your methodology background knowledge is helpful to those reading your report for added context and credibility. You can also use this section of your report to define any complex dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110340" style="background-color: transparent;">methodologies used in your study that might require added explanation to readers without a dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110370" style="background-color: transparent;">market research background.
Craft a story:
Don't make the mistake of throwing dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110345">data points at your audience. Part of reporting on your dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110359">online surveys includes crafting narratives that tie your data findings together to sell your story to your audience. What patterns emerge? Are there any surprises? Embed these stories into your charts through headlines and chart descriptions, and tie them back to your research objectives whenever possible. Think carefully about the following when crafting your data story:
The big takeaway: What's the core message you want to convey?
Context: Why does this story matter in the greater scheme of your business?
Implications: What business decisions or dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110354">stakeholder actions might come from these findings?
Organize your findings logically by themes or question categories, and include a summary/final takeaway at the end for readers who want a very quick and digestible understanding of your study. Your story is what dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110354">stakeholders and key decision makers look for in dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110370">market research - it’s your chance to impress them and ensure your data findings generate real impact.
Incorporate dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110333">infographics and other visual stimuli:
Aside from data charts, other visual stimuli add richness to your data presentation, making it more digestible and memorable. Consider these added visuals when presenting your data:
dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110333">Infographics : dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110330">Summarize key findings with icons, charts, and text.
Images: Add relatable pictures that resonate with your data and/or audience.
Color: Use color strategically to emphasize crucial points or to emulate a brand’s look/feel.
dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110329">Qualitative data : Include insightful quotes or video responses (if applicable) to add additional stories, trends, or opinions to your report.
Common mistakes in analyzing dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110318">survey results
Analyzing, presenting, and reporting on survey findings isn’t difficult when using the right tools and following the above best practices.
However, there are some things to keep in mind during these processes to avoid some common mistakes:
Avoid biased results in your final dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110326">survey analysis and presentation by controlling for things like sampling bias and reporting bias. Sampling bias occurs when you don’t use a truly representative sample of your target population; this can skew your results and portray inaccurate/misleadings findings. Reporting bias occurs when you don’t account for personal biases in what you choose to share (i.e. cherry picking the data that seems the most positive or that supports your personal pre-existing idea - often referred to as confirmation bias). Avoid survey biases by having a second (or even third) colleague review your work at each stage before sharing it with final dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110354">stakeholders .
Misinterpreting correlation as dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110343">causation
Just because two variables are related doesn't mean one causes the other. Be cautious about drawing causal conclusions without strong supporting evidence. The only real way to determine dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110343">causation is through a specialized dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110346">statistical analysis like regression analysis.
Looking into every dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110345">data point
Surveys produce a lot of really valuable information, but you need to focus your attention on the dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110360">metrics that generate impact for your research objective. It’s easy to get lost in an dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110325">excel data file or research platform when trying to look through every dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110322">survey response cut by as many variables as you can think of.
Start your analysis by strategically thinking about your research as a whole. What were you hoping to find out from your study? Start there. Once you start exploring your major dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110360">metrics , a story might naturally arise that leads you to further data cuts. Your data analysis should be comprehensive, yet efficient.
Best practices for presenting dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110318">survey results
While the above elements are things you’ll want to avoid in your research analysis, here are some a survey best practices you’ll want to keep in mind:
Know your audience
Tailor your report/presentation to your specific audience’s needs and understanding level. This might even mean creating different versions of your report that are geared toward different audiences. Some dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110354">stakeholders might be very technical and are looking for all the small details while others just want the bare minimum overview.
Keep it simple
Charts and dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110321">graphs should make data easier to understand, not more confusing. Avoid using too many chart types or overwhelming viewers with too much information. What are the charts that absolutely must be included to tell your full consumer story, and which are ‘nice to have’ if you had to pick and choose? Your final report doesn’t need to (and shouldn’t) house every possible dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110345">data point and data cut from your study. That’s what your raw data file is for - and you can always go back to reference this when needed. Your report however is the main takeaway and summary of your study; it should be concise and to the point. Provide enough information for your audience to understand how you reached your conclusions, but avoid burying them in irrelevant details. Any ‘extra’ data that you want to include but that doesn’t need to be front and center in your report can be included in an accompanying appendix.
Communicate clearly
Don't make your audience struggle to decode your visuals. Each chart should have a very clear takeaway that a reader of any skillset can digest almost instantly. More complex charts should have clear headlines or interpretation notes, written in simple language for your audience (non-technical or specialized terms). Back to table of contents
How quantilope streamlines the analysis and presentation of dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110318">survey results
quantilope’s automated Consumer Intelligence Platform saves clients from the tedious, manual processes of traditional dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110370">market research , offering an end-to-end resource for dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110367">questionnaire setup, real-time fielding, automated charting, and AI-assisted reporting.
From the start, work with your dedicated team of research consultants (or do it on your own through a DIY platform approach) to start building a dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110367">questionnaire with the simple drag and drop of U&A questions and advanced methods. Should you wish to streamline things even further, get a head start by leveraging a number of survey templates and customize as needed.
quantilope’s platform offers all dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110355">types of surveys - such as concept testing , ad effectiveness , and Better Brand Health Tracking to name a few. Available for use in these surveys is quantilope’s largest suite of automated advanced methods, making even the most complex dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110340">methodologies available to researchers of any background.
As soon as dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110319">respondents begin to complete your survey, monitor dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110344">response rates directly in the fielding tab - right at your fingertips. Get a jump start on dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110357">survey data dropdown#toggle" data-dropdown-menu-id-param="menu_term_292110357" data-dropdown-placement-param="top" data-term-id="292110357"> analysis as soon as you like, rather than waiting for fieldwork to close and to receive data files from a data processing team. Lean on quantilope’s AI co-pilot, quinn , to generate inspiration for chart headlines and report summaries/takeaways.
With quantilope, researchers have hands-on control of their dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110326">survey analysis and reporting processes, for the opportunity to make clear business recommendations based on dropdown#toggle" data-dropdown-placement-param="top" data-term-id="292110365">actionable insights .
Interested in learning more about quantilope’s Consumer Intelligence Platform? Get in touch below!
Get in touch to learn more about quantilope!
Related posts, unlocking your brand’s potential with white space analysis, effective concept testing in new product development, mastering retail price optimization for maximum profitability, quantilope academy is now open to the broader insights community.
Your Modern Business Guide To Data Analysis Methods And Techniques

Table of Contents
1) What Is Data Analysis?
2) Why Is Data Analysis Important?
3) What Is The Data Analysis Process?
4) Types Of Data Analysis Methods
5) Top Data Analysis Techniques To Apply
6) Quality Criteria For Data Analysis
7) Data Analysis Limitations & Barriers
8) Data Analysis Skills
9) Data Analysis In The Big Data Environment
In our data-rich age, understanding how to analyze and extract true meaning from our business’s digital insights is one of the primary drivers of success.
Despite the colossal volume of data we create every day, a mere 0.5% is actually analyzed and used for data discovery , improvement, and intelligence. While that may not seem like much, considering the amount of digital information we have at our fingertips, half a percent still accounts for a vast amount of data.
With so much data and so little time, knowing how to collect, curate, organize, and make sense of all of this potentially business-boosting information can be a minefield – but online data analysis is the solution.
In science, data analysis uses a more complex approach with advanced techniques to explore and experiment with data. On the other hand, in a business context, data is used to make data-driven decisions that will enable the company to improve its overall performance. In this post, we will cover the analysis of data from an organizational point of view while still going through the scientific and statistical foundations that are fundamental to understanding the basics of data analysis.
To put all of that into perspective, we will answer a host of important analytical questions, explore analytical methods and techniques, while demonstrating how to perform analysis in the real world with a 17-step blueprint for success.
What Is Data Analysis?
Data analysis is the process of collecting, modeling, and analyzing data using various statistical and logical methods and techniques. Businesses rely on analytics processes and tools to extract insights that support strategic and operational decision-making.
All these various methods are largely based on two core areas: quantitative and qualitative research.
To explain the key differences between qualitative and quantitative research, here’s a video for your viewing pleasure:
Gaining a better understanding of different techniques and methods in quantitative research as well as qualitative insights will give your analyzing efforts a more clearly defined direction, so it’s worth taking the time to allow this particular knowledge to sink in. Additionally, you will be able to create a comprehensive analytical report that will skyrocket your analysis.
Apart from qualitative and quantitative categories, there are also other types of data that you should be aware of before dividing into complex data analysis processes. These categories include:
- Big data: Refers to massive data sets that need to be analyzed using advanced software to reveal patterns and trends. It is considered to be one of the best analytical assets as it provides larger volumes of data at a faster rate.
- Metadata: Putting it simply, metadata is data that provides insights about other data. It summarizes key information about specific data that makes it easier to find and reuse for later purposes.
- Real time data: As its name suggests, real time data is presented as soon as it is acquired. From an organizational perspective, this is the most valuable data as it can help you make important decisions based on the latest developments. Our guide on real time analytics will tell you more about the topic.
- Machine data: This is more complex data that is generated solely by a machine such as phones, computers, or even websites and embedded systems, without previous human interaction.
Why Is Data Analysis Important?
Before we go into detail about the categories of analysis along with its methods and techniques, you must understand the potential that analyzing data can bring to your organization.
- Informed decision-making : From a management perspective, you can benefit from analyzing your data as it helps you make decisions based on facts and not simple intuition. For instance, you can understand where to invest your capital, detect growth opportunities, predict your income, or tackle uncommon situations before they become problems. Through this, you can extract relevant insights from all areas in your organization, and with the help of dashboard software , present the data in a professional and interactive way to different stakeholders.
- Reduce costs : Another great benefit is to reduce costs. With the help of advanced technologies such as predictive analytics, businesses can spot improvement opportunities, trends, and patterns in their data and plan their strategies accordingly. In time, this will help you save money and resources on implementing the wrong strategies. And not just that, by predicting different scenarios such as sales and demand you can also anticipate production and supply.
- Target customers better : Customers are arguably the most crucial element in any business. By using analytics to get a 360° vision of all aspects related to your customers, you can understand which channels they use to communicate with you, their demographics, interests, habits, purchasing behaviors, and more. In the long run, it will drive success to your marketing strategies, allow you to identify new potential customers, and avoid wasting resources on targeting the wrong people or sending the wrong message. You can also track customer satisfaction by analyzing your client’s reviews or your customer service department’s performance.
What Is The Data Analysis Process?

When we talk about analyzing data there is an order to follow in order to extract the needed conclusions. The analysis process consists of 5 key stages. We will cover each of them more in detail later in the post, but to start providing the needed context to understand what is coming next, here is a rundown of the 5 essential steps of data analysis.
- Identify: Before you get your hands dirty with data, you first need to identify why you need it in the first place. The identification is the stage in which you establish the questions you will need to answer. For example, what is the customer's perception of our brand? Or what type of packaging is more engaging to our potential customers? Once the questions are outlined you are ready for the next step.
- Collect: As its name suggests, this is the stage where you start collecting the needed data. Here, you define which sources of data you will use and how you will use them. The collection of data can come in different forms such as internal or external sources, surveys, interviews, questionnaires, and focus groups, among others. An important note here is that the way you collect the data will be different in a quantitative and qualitative scenario.
- Clean: Once you have the necessary data it is time to clean it and leave it ready for analysis. Not all the data you collect will be useful, when collecting big amounts of data in different formats it is very likely that you will find yourself with duplicate or badly formatted data. To avoid this, before you start working with your data you need to make sure to erase any white spaces, duplicate records, or formatting errors. This way you avoid hurting your analysis with bad-quality data.
- Analyze : With the help of various techniques such as statistical analysis, regressions, neural networks, text analysis, and more, you can start analyzing and manipulating your data to extract relevant conclusions. At this stage, you find trends, correlations, variations, and patterns that can help you answer the questions you first thought of in the identify stage. Various technologies in the market assist researchers and average users with the management of their data. Some of them include business intelligence and visualization software, predictive analytics, and data mining, among others.
- Interpret: Last but not least you have one of the most important steps: it is time to interpret your results. This stage is where the researcher comes up with courses of action based on the findings. For example, here you would understand if your clients prefer packaging that is red or green, plastic or paper, etc. Additionally, at this stage, you can also find some limitations and work on them.
Now that you have a basic understanding of the key data analysis steps, let’s look at the top 17 essential methods.
17 Essential Types Of Data Analysis Methods
Before diving into the 17 essential types of methods, it is important that we go over really fast through the main analysis categories. Starting with the category of descriptive up to prescriptive analysis, the complexity and effort of data evaluation increases, but also the added value for the company.
a) Descriptive analysis - What happened.
The descriptive analysis method is the starting point for any analytic reflection, and it aims to answer the question of what happened? It does this by ordering, manipulating, and interpreting raw data from various sources to turn it into valuable insights for your organization.
Performing descriptive analysis is essential, as it enables us to present our insights in a meaningful way. Although it is relevant to mention that this analysis on its own will not allow you to predict future outcomes or tell you the answer to questions like why something happened, it will leave your data organized and ready to conduct further investigations.
b) Exploratory analysis - How to explore data relationships.
As its name suggests, the main aim of the exploratory analysis is to explore. Prior to it, there is still no notion of the relationship between the data and the variables. Once the data is investigated, exploratory analysis helps you to find connections and generate hypotheses and solutions for specific problems. A typical area of application for it is data mining.
c) Diagnostic analysis - Why it happened.
Diagnostic data analytics empowers analysts and executives by helping them gain a firm contextual understanding of why something happened. If you know why something happened as well as how it happened, you will be able to pinpoint the exact ways of tackling the issue or challenge.
Designed to provide direct and actionable answers to specific questions, this is one of the world’s most important methods in research, among its other key organizational functions such as retail analytics , e.g.
c) Predictive analysis - What will happen.
The predictive method allows you to look into the future to answer the question: what will happen? In order to do this, it uses the results of the previously mentioned descriptive, exploratory, and diagnostic analysis, in addition to machine learning (ML) and artificial intelligence (AI). Through this, you can uncover future trends, potential problems or inefficiencies, connections, and casualties in your data.
With predictive analysis, you can unfold and develop initiatives that will not only enhance your various operational processes but also help you gain an all-important edge over the competition. If you understand why a trend, pattern, or event happened through data, you will be able to develop an informed projection of how things may unfold in particular areas of the business.
e) Prescriptive analysis - How will it happen.
Another of the most effective types of analysis methods in research. Prescriptive data techniques cross over from predictive analysis in the way that it revolves around using patterns or trends to develop responsive, practical business strategies.
By drilling down into prescriptive analysis, you will play an active role in the data consumption process by taking well-arranged sets of visual data and using it as a powerful fix to emerging issues in a number of key areas, including marketing, sales, customer experience, HR, fulfillment, finance, logistics analytics , and others.

As mentioned at the beginning of the post, data analysis methods can be divided into two big categories: quantitative and qualitative. Each of these categories holds a powerful analytical value that changes depending on the scenario and type of data you are working with. Below, we will discuss 17 methods that are divided into qualitative and quantitative approaches.
Without further ado, here are the 17 essential types of data analysis methods with some use cases in the business world:
A. Quantitative Methods
To put it simply, quantitative analysis refers to all methods that use numerical data or data that can be turned into numbers (e.g. category variables like gender, age, etc.) to extract valuable insights. It is used to extract valuable conclusions about relationships, differences, and test hypotheses. Below we discuss some of the key quantitative methods.
1. Cluster analysis
The action of grouping a set of data elements in a way that said elements are more similar (in a particular sense) to each other than to those in other groups – hence the term ‘cluster.’ Since there is no target variable when clustering, the method is often used to find hidden patterns in the data. The approach is also used to provide additional context to a trend or dataset.
Let's look at it from an organizational perspective. In a perfect world, marketers would be able to analyze each customer separately and give them the best-personalized service, but let's face it, with a large customer base, it is timely impossible to do that. That's where clustering comes in. By grouping customers into clusters based on demographics, purchasing behaviors, monetary value, or any other factor that might be relevant for your company, you will be able to immediately optimize your efforts and give your customers the best experience based on their needs.
2. Cohort analysis
This type of data analysis approach uses historical data to examine and compare a determined segment of users' behavior, which can then be grouped with others with similar characteristics. By using this methodology, it's possible to gain a wealth of insight into consumer needs or a firm understanding of a broader target group.
Cohort analysis can be really useful for performing analysis in marketing as it will allow you to understand the impact of your campaigns on specific groups of customers. To exemplify, imagine you send an email campaign encouraging customers to sign up for your site. For this, you create two versions of the campaign with different designs, CTAs, and ad content. Later on, you can use cohort analysis to track the performance of the campaign for a longer period of time and understand which type of content is driving your customers to sign up, repurchase, or engage in other ways.
A useful tool to start performing cohort analysis method is Google Analytics. You can learn more about the benefits and limitations of using cohorts in GA in this useful guide . In the bottom image, you see an example of how you visualize a cohort in this tool. The segments (devices traffic) are divided into date cohorts (usage of devices) and then analyzed week by week to extract insights into performance.

3. Regression analysis
Regression uses historical data to understand how a dependent variable's value is affected when one (linear regression) or more independent variables (multiple regression) change or stay the same. By understanding each variable's relationship and how it developed in the past, you can anticipate possible outcomes and make better decisions in the future.
Let's bring it down with an example. Imagine you did a regression analysis of your sales in 2019 and discovered that variables like product quality, store design, customer service, marketing campaigns, and sales channels affected the overall result. Now you want to use regression to analyze which of these variables changed or if any new ones appeared during 2020. For example, you couldn’t sell as much in your physical store due to COVID lockdowns. Therefore, your sales could’ve either dropped in general or increased in your online channels. Through this, you can understand which independent variables affected the overall performance of your dependent variable, annual sales.
If you want to go deeper into this type of analysis, check out this article and learn more about how you can benefit from regression.
4. Neural networks
The neural network forms the basis for the intelligent algorithms of machine learning. It is a form of analytics that attempts, with minimal intervention, to understand how the human brain would generate insights and predict values. Neural networks learn from each and every data transaction, meaning that they evolve and advance over time.
A typical area of application for neural networks is predictive analytics. There are BI reporting tools that have this feature implemented within them, such as the Predictive Analytics Tool from datapine. This tool enables users to quickly and easily generate all kinds of predictions. All you have to do is select the data to be processed based on your KPIs, and the software automatically calculates forecasts based on historical and current data. Thanks to its user-friendly interface, anyone in your organization can manage it; there’s no need to be an advanced scientist.
Here is an example of how you can use the predictive analysis tool from datapine:

**click to enlarge**
5. Factor analysis
The factor analysis also called “dimension reduction” is a type of data analysis used to describe variability among observed, correlated variables in terms of a potentially lower number of unobserved variables called factors. The aim here is to uncover independent latent variables, an ideal method for streamlining specific segments.
A good way to understand this data analysis method is a customer evaluation of a product. The initial assessment is based on different variables like color, shape, wearability, current trends, materials, comfort, the place where they bought the product, and frequency of usage. Like this, the list can be endless, depending on what you want to track. In this case, factor analysis comes into the picture by summarizing all of these variables into homogenous groups, for example, by grouping the variables color, materials, quality, and trends into a brother latent variable of design.
If you want to start analyzing data using factor analysis we recommend you take a look at this practical guide from UCLA.
6. Data mining
A method of data analysis that is the umbrella term for engineering metrics and insights for additional value, direction, and context. By using exploratory statistical evaluation, data mining aims to identify dependencies, relations, patterns, and trends to generate advanced knowledge. When considering how to analyze data, adopting a data mining mindset is essential to success - as such, it’s an area that is worth exploring in greater detail.
An excellent use case of data mining is datapine intelligent data alerts . With the help of artificial intelligence and machine learning, they provide automated signals based on particular commands or occurrences within a dataset. For example, if you’re monitoring supply chain KPIs , you could set an intelligent alarm to trigger when invalid or low-quality data appears. By doing so, you will be able to drill down deep into the issue and fix it swiftly and effectively.
In the following picture, you can see how the intelligent alarms from datapine work. By setting up ranges on daily orders, sessions, and revenues, the alarms will notify you if the goal was not completed or if it exceeded expectations.

7. Time series analysis
As its name suggests, time series analysis is used to analyze a set of data points collected over a specified period of time. Although analysts use this method to monitor the data points in a specific interval of time rather than just monitoring them intermittently, the time series analysis is not uniquely used for the purpose of collecting data over time. Instead, it allows researchers to understand if variables changed during the duration of the study, how the different variables are dependent, and how did it reach the end result.
In a business context, this method is used to understand the causes of different trends and patterns to extract valuable insights. Another way of using this method is with the help of time series forecasting. Powered by predictive technologies, businesses can analyze various data sets over a period of time and forecast different future events.
A great use case to put time series analysis into perspective is seasonality effects on sales. By using time series forecasting to analyze sales data of a specific product over time, you can understand if sales rise over a specific period of time (e.g. swimwear during summertime, or candy during Halloween). These insights allow you to predict demand and prepare production accordingly.
8. Decision Trees
The decision tree analysis aims to act as a support tool to make smart and strategic decisions. By visually displaying potential outcomes, consequences, and costs in a tree-like model, researchers and company users can easily evaluate all factors involved and choose the best course of action. Decision trees are helpful to analyze quantitative data and they allow for an improved decision-making process by helping you spot improvement opportunities, reduce costs, and enhance operational efficiency and production.
But how does a decision tree actually works? This method works like a flowchart that starts with the main decision that you need to make and branches out based on the different outcomes and consequences of each decision. Each outcome will outline its own consequences, costs, and gains and, at the end of the analysis, you can compare each of them and make the smartest decision.
Businesses can use them to understand which project is more cost-effective and will bring more earnings in the long run. For example, imagine you need to decide if you want to update your software app or build a new app entirely. Here you would compare the total costs, the time needed to be invested, potential revenue, and any other factor that might affect your decision. In the end, you would be able to see which of these two options is more realistic and attainable for your company or research.
9. Conjoint analysis
Last but not least, we have the conjoint analysis. This approach is usually used in surveys to understand how individuals value different attributes of a product or service and it is one of the most effective methods to extract consumer preferences. When it comes to purchasing, some clients might be more price-focused, others more features-focused, and others might have a sustainable focus. Whatever your customer's preferences are, you can find them with conjoint analysis. Through this, companies can define pricing strategies, packaging options, subscription packages, and more.
A great example of conjoint analysis is in marketing and sales. For instance, a cupcake brand might use conjoint analysis and find that its clients prefer gluten-free options and cupcakes with healthier toppings over super sugary ones. Thus, the cupcake brand can turn these insights into advertisements and promotions to increase sales of this particular type of product. And not just that, conjoint analysis can also help businesses segment their customers based on their interests. This allows them to send different messaging that will bring value to each of the segments.
10. Correspondence Analysis
Also known as reciprocal averaging, correspondence analysis is a method used to analyze the relationship between categorical variables presented within a contingency table. A contingency table is a table that displays two (simple correspondence analysis) or more (multiple correspondence analysis) categorical variables across rows and columns that show the distribution of the data, which is usually answers to a survey or questionnaire on a specific topic.
This method starts by calculating an “expected value” which is done by multiplying row and column averages and dividing it by the overall original value of the specific table cell. The “expected value” is then subtracted from the original value resulting in a “residual number” which is what allows you to extract conclusions about relationships and distribution. The results of this analysis are later displayed using a map that represents the relationship between the different values. The closest two values are in the map, the bigger the relationship. Let’s put it into perspective with an example.
Imagine you are carrying out a market research analysis about outdoor clothing brands and how they are perceived by the public. For this analysis, you ask a group of people to match each brand with a certain attribute which can be durability, innovation, quality materials, etc. When calculating the residual numbers, you can see that brand A has a positive residual for innovation but a negative one for durability. This means that brand A is not positioned as a durable brand in the market, something that competitors could take advantage of.
11. Multidimensional Scaling (MDS)
MDS is a method used to observe the similarities or disparities between objects which can be colors, brands, people, geographical coordinates, and more. The objects are plotted using an “MDS map” that positions similar objects together and disparate ones far apart. The (dis) similarities between objects are represented using one or more dimensions that can be observed using a numerical scale. For example, if you want to know how people feel about the COVID-19 vaccine, you can use 1 for “don’t believe in the vaccine at all” and 10 for “firmly believe in the vaccine” and a scale of 2 to 9 for in between responses. When analyzing an MDS map the only thing that matters is the distance between the objects, the orientation of the dimensions is arbitrary and has no meaning at all.
Multidimensional scaling is a valuable technique for market research, especially when it comes to evaluating product or brand positioning. For instance, if a cupcake brand wants to know how they are positioned compared to competitors, it can define 2-3 dimensions such as taste, ingredients, shopping experience, or more, and do a multidimensional scaling analysis to find improvement opportunities as well as areas in which competitors are currently leading.
Another business example is in procurement when deciding on different suppliers. Decision makers can generate an MDS map to see how the different prices, delivery times, technical services, and more of the different suppliers differ and pick the one that suits their needs the best.
A final example proposed by a research paper on "An Improved Study of Multilevel Semantic Network Visualization for Analyzing Sentiment Word of Movie Review Data". Researchers picked a two-dimensional MDS map to display the distances and relationships between different sentiments in movie reviews. They used 36 sentiment words and distributed them based on their emotional distance as we can see in the image below where the words "outraged" and "sweet" are on opposite sides of the map, marking the distance between the two emotions very clearly.

Aside from being a valuable technique to analyze dissimilarities, MDS also serves as a dimension-reduction technique for large dimensional data.
B. Qualitative Methods
Qualitative data analysis methods are defined as the observation of non-numerical data that is gathered and produced using methods of observation such as interviews, focus groups, questionnaires, and more. As opposed to quantitative methods, qualitative data is more subjective and highly valuable in analyzing customer retention and product development.
12. Text analysis
Text analysis, also known in the industry as text mining, works by taking large sets of textual data and arranging them in a way that makes it easier to manage. By working through this cleansing process in stringent detail, you will be able to extract the data that is truly relevant to your organization and use it to develop actionable insights that will propel you forward.
Modern software accelerate the application of text analytics. Thanks to the combination of machine learning and intelligent algorithms, you can perform advanced analytical processes such as sentiment analysis. This technique allows you to understand the intentions and emotions of a text, for example, if it's positive, negative, or neutral, and then give it a score depending on certain factors and categories that are relevant to your brand. Sentiment analysis is often used to monitor brand and product reputation and to understand how successful your customer experience is. To learn more about the topic check out this insightful article .
By analyzing data from various word-based sources, including product reviews, articles, social media communications, and survey responses, you will gain invaluable insights into your audience, as well as their needs, preferences, and pain points. This will allow you to create campaigns, services, and communications that meet your prospects’ needs on a personal level, growing your audience while boosting customer retention. There are various other “sub-methods” that are an extension of text analysis. Each of them serves a more specific purpose and we will look at them in detail next.
13. Content Analysis
This is a straightforward and very popular method that examines the presence and frequency of certain words, concepts, and subjects in different content formats such as text, image, audio, or video. For example, the number of times the name of a celebrity is mentioned on social media or online tabloids. It does this by coding text data that is later categorized and tabulated in a way that can provide valuable insights, making it the perfect mix of quantitative and qualitative analysis.
There are two types of content analysis. The first one is the conceptual analysis which focuses on explicit data, for instance, the number of times a concept or word is mentioned in a piece of content. The second one is relational analysis, which focuses on the relationship between different concepts or words and how they are connected within a specific context.
Content analysis is often used by marketers to measure brand reputation and customer behavior. For example, by analyzing customer reviews. It can also be used to analyze customer interviews and find directions for new product development. It is also important to note, that in order to extract the maximum potential out of this analysis method, it is necessary to have a clearly defined research question.
14. Thematic Analysis
Very similar to content analysis, thematic analysis also helps in identifying and interpreting patterns in qualitative data with the main difference being that the first one can also be applied to quantitative analysis. The thematic method analyzes large pieces of text data such as focus group transcripts or interviews and groups them into themes or categories that come up frequently within the text. It is a great method when trying to figure out peoples view’s and opinions about a certain topic. For example, if you are a brand that cares about sustainability, you can do a survey of your customers to analyze their views and opinions about sustainability and how they apply it to their lives. You can also analyze customer service calls transcripts to find common issues and improve your service.
Thematic analysis is a very subjective technique that relies on the researcher’s judgment. Therefore, to avoid biases, it has 6 steps that include familiarization, coding, generating themes, reviewing themes, defining and naming themes, and writing up. It is also important to note that, because it is a flexible approach, the data can be interpreted in multiple ways and it can be hard to select what data is more important to emphasize.
15. Narrative Analysis
A bit more complex in nature than the two previous ones, narrative analysis is used to explore the meaning behind the stories that people tell and most importantly, how they tell them. By looking into the words that people use to describe a situation you can extract valuable conclusions about their perspective on a specific topic. Common sources for narrative data include autobiographies, family stories, opinion pieces, and testimonials, among others.
From a business perspective, narrative analysis can be useful to analyze customer behaviors and feelings towards a specific product, service, feature, or others. It provides unique and deep insights that can be extremely valuable. However, it has some drawbacks.
The biggest weakness of this method is that the sample sizes are usually very small due to the complexity and time-consuming nature of the collection of narrative data. Plus, the way a subject tells a story will be significantly influenced by his or her specific experiences, making it very hard to replicate in a subsequent study.
16. Discourse Analysis
Discourse analysis is used to understand the meaning behind any type of written, verbal, or symbolic discourse based on its political, social, or cultural context. It mixes the analysis of languages and situations together. This means that the way the content is constructed and the meaning behind it is significantly influenced by the culture and society it takes place in. For example, if you are analyzing political speeches you need to consider different context elements such as the politician's background, the current political context of the country, the audience to which the speech is directed, and so on.
From a business point of view, discourse analysis is a great market research tool. It allows marketers to understand how the norms and ideas of the specific market work and how their customers relate to those ideas. It can be very useful to build a brand mission or develop a unique tone of voice.
17. Grounded Theory Analysis
Traditionally, researchers decide on a method and hypothesis and start to collect the data to prove that hypothesis. The grounded theory is the only method that doesn’t require an initial research question or hypothesis as its value lies in the generation of new theories. With the grounded theory method, you can go into the analysis process with an open mind and explore the data to generate new theories through tests and revisions. In fact, it is not necessary to collect the data and then start to analyze it. Researchers usually start to find valuable insights as they are gathering the data.
All of these elements make grounded theory a very valuable method as theories are fully backed by data instead of initial assumptions. It is a great technique to analyze poorly researched topics or find the causes behind specific company outcomes. For example, product managers and marketers might use the grounded theory to find the causes of high levels of customer churn and look into customer surveys and reviews to develop new theories about the causes.
How To Analyze Data? Top 17 Data Analysis Techniques To Apply

Now that we’ve answered the questions “what is data analysis’”, why is it important, and covered the different data analysis types, it’s time to dig deeper into how to perform your analysis by working through these 17 essential techniques.
1. Collaborate your needs
Before you begin analyzing or drilling down into any techniques, it’s crucial to sit down collaboratively with all key stakeholders within your organization, decide on your primary campaign or strategic goals, and gain a fundamental understanding of the types of insights that will best benefit your progress or provide you with the level of vision you need to evolve your organization.
2. Establish your questions
Once you’ve outlined your core objectives, you should consider which questions will need answering to help you achieve your mission. This is one of the most important techniques as it will shape the very foundations of your success.
To help you ask the right things and ensure your data works for you, you have to ask the right data analysis questions .
3. Data democratization
After giving your data analytics methodology some real direction, and knowing which questions need answering to extract optimum value from the information available to your organization, you should continue with democratization.
Data democratization is an action that aims to connect data from various sources efficiently and quickly so that anyone in your organization can access it at any given moment. You can extract data in text, images, videos, numbers, or any other format. And then perform cross-database analysis to achieve more advanced insights to share with the rest of the company interactively.
Once you have decided on your most valuable sources, you need to take all of this into a structured format to start collecting your insights. For this purpose, datapine offers an easy all-in-one data connectors feature to integrate all your internal and external sources and manage them at your will. Additionally, datapine’s end-to-end solution automatically updates your data, allowing you to save time and focus on performing the right analysis to grow your company.

4. Think of governance
When collecting data in a business or research context you always need to think about security and privacy. With data breaches becoming a topic of concern for businesses, the need to protect your client's or subject’s sensitive information becomes critical.
To ensure that all this is taken care of, you need to think of a data governance strategy. According to Gartner , this concept refers to “ the specification of decision rights and an accountability framework to ensure the appropriate behavior in the valuation, creation, consumption, and control of data and analytics .” In simpler words, data governance is a collection of processes, roles, and policies, that ensure the efficient use of data while still achieving the main company goals. It ensures that clear roles are in place for who can access the information and how they can access it. In time, this not only ensures that sensitive information is protected but also allows for an efficient analysis as a whole.
5. Clean your data
After harvesting from so many sources you will be left with a vast amount of information that can be overwhelming to deal with. At the same time, you can be faced with incorrect data that can be misleading to your analysis. The smartest thing you can do to avoid dealing with this in the future is to clean the data. This is fundamental before visualizing it, as it will ensure that the insights you extract from it are correct.
There are many things that you need to look for in the cleaning process. The most important one is to eliminate any duplicate observations; this usually appears when using multiple internal and external sources of information. You can also add any missing codes, fix empty fields, and eliminate incorrectly formatted data.
Another usual form of cleaning is done with text data. As we mentioned earlier, most companies today analyze customer reviews, social media comments, questionnaires, and several other text inputs. In order for algorithms to detect patterns, text data needs to be revised to avoid invalid characters or any syntax or spelling errors.
Most importantly, the aim of cleaning is to prevent you from arriving at false conclusions that can damage your company in the long run. By using clean data, you will also help BI solutions to interact better with your information and create better reports for your organization.
6. Set your KPIs
Once you’ve set your sources, cleaned your data, and established clear-cut questions you want your insights to answer, you need to set a host of key performance indicators (KPIs) that will help you track, measure, and shape your progress in a number of key areas.
KPIs are critical to both qualitative and quantitative analysis research. This is one of the primary methods of data analysis you certainly shouldn’t overlook.
To help you set the best possible KPIs for your initiatives and activities, here is an example of a relevant logistics KPI : transportation-related costs. If you want to see more go explore our collection of key performance indicator examples .

7. Omit useless data
Having bestowed your data analysis tools and techniques with true purpose and defined your mission, you should explore the raw data you’ve collected from all sources and use your KPIs as a reference for chopping out any information you deem to be useless.
Trimming the informational fat is one of the most crucial methods of analysis as it will allow you to focus your analytical efforts and squeeze every drop of value from the remaining ‘lean’ information.
Any stats, facts, figures, or metrics that don’t align with your business goals or fit with your KPI management strategies should be eliminated from the equation.
8. Build a data management roadmap
While, at this point, this particular step is optional (you will have already gained a wealth of insight and formed a fairly sound strategy by now), creating a data governance roadmap will help your data analysis methods and techniques become successful on a more sustainable basis. These roadmaps, if developed properly, are also built so they can be tweaked and scaled over time.
Invest ample time in developing a roadmap that will help you store, manage, and handle your data internally, and you will make your analysis techniques all the more fluid and functional – one of the most powerful types of data analysis methods available today.
9. Integrate technology
There are many ways to analyze data, but one of the most vital aspects of analytical success in a business context is integrating the right decision support software and technology.
Robust analysis platforms will not only allow you to pull critical data from your most valuable sources while working with dynamic KPIs that will offer you actionable insights; it will also present them in a digestible, visual, interactive format from one central, live dashboard . A data methodology you can count on.
By integrating the right technology within your data analysis methodology, you’ll avoid fragmenting your insights, saving you time and effort while allowing you to enjoy the maximum value from your business’s most valuable insights.
For a look at the power of software for the purpose of analysis and to enhance your methods of analyzing, glance over our selection of dashboard examples .
10. Answer your questions
By considering each of the above efforts, working with the right technology, and fostering a cohesive internal culture where everyone buys into the different ways to analyze data as well as the power of digital intelligence, you will swiftly start to answer your most burning business questions. Arguably, the best way to make your data concepts accessible across the organization is through data visualization.
11. Visualize your data
Online data visualization is a powerful tool as it lets you tell a story with your metrics, allowing users across the organization to extract meaningful insights that aid business evolution – and it covers all the different ways to analyze data.
The purpose of analyzing is to make your entire organization more informed and intelligent, and with the right platform or dashboard, this is simpler than you think, as demonstrated by our marketing dashboard .

This visual, dynamic, and interactive online dashboard is a data analysis example designed to give Chief Marketing Officers (CMO) an overview of relevant metrics to help them understand if they achieved their monthly goals.
In detail, this example generated with a modern dashboard creator displays interactive charts for monthly revenues, costs, net income, and net income per customer; all of them are compared with the previous month so that you can understand how the data fluctuated. In addition, it shows a detailed summary of the number of users, customers, SQLs, and MQLs per month to visualize the whole picture and extract relevant insights or trends for your marketing reports .
The CMO dashboard is perfect for c-level management as it can help them monitor the strategic outcome of their marketing efforts and make data-driven decisions that can benefit the company exponentially.
12. Be careful with the interpretation
We already dedicated an entire post to data interpretation as it is a fundamental part of the process of data analysis. It gives meaning to the analytical information and aims to drive a concise conclusion from the analysis results. Since most of the time companies are dealing with data from many different sources, the interpretation stage needs to be done carefully and properly in order to avoid misinterpretations.
To help you through the process, here we list three common practices that you need to avoid at all costs when looking at your data:
- Correlation vs. causation: The human brain is formatted to find patterns. This behavior leads to one of the most common mistakes when performing interpretation: confusing correlation with causation. Although these two aspects can exist simultaneously, it is not correct to assume that because two things happened together, one provoked the other. A piece of advice to avoid falling into this mistake is never to trust just intuition, trust the data. If there is no objective evidence of causation, then always stick to correlation.
- Confirmation bias: This phenomenon describes the tendency to select and interpret only the data necessary to prove one hypothesis, often ignoring the elements that might disprove it. Even if it's not done on purpose, confirmation bias can represent a real problem, as excluding relevant information can lead to false conclusions and, therefore, bad business decisions. To avoid it, always try to disprove your hypothesis instead of proving it, share your analysis with other team members, and avoid drawing any conclusions before the entire analytical project is finalized.
- Statistical significance: To put it in short words, statistical significance helps analysts understand if a result is actually accurate or if it happened because of a sampling error or pure chance. The level of statistical significance needed might depend on the sample size and the industry being analyzed. In any case, ignoring the significance of a result when it might influence decision-making can be a huge mistake.
13. Build a narrative
Now, we’re going to look at how you can bring all of these elements together in a way that will benefit your business - starting with a little something called data storytelling.
The human brain responds incredibly well to strong stories or narratives. Once you’ve cleansed, shaped, and visualized your most invaluable data using various BI dashboard tools , you should strive to tell a story - one with a clear-cut beginning, middle, and end.
By doing so, you will make your analytical efforts more accessible, digestible, and universal, empowering more people within your organization to use your discoveries to their actionable advantage.
14. Consider autonomous technology
Autonomous technologies, such as artificial intelligence (AI) and machine learning (ML), play a significant role in the advancement of understanding how to analyze data more effectively.
Gartner predicts that by the end of this year, 80% of emerging technologies will be developed with AI foundations. This is a testament to the ever-growing power and value of autonomous technologies.
At the moment, these technologies are revolutionizing the analysis industry. Some examples that we mentioned earlier are neural networks, intelligent alarms, and sentiment analysis.
15. Share the load
If you work with the right tools and dashboards, you will be able to present your metrics in a digestible, value-driven format, allowing almost everyone in the organization to connect with and use relevant data to their advantage.
Modern dashboards consolidate data from various sources, providing access to a wealth of insights in one centralized location, no matter if you need to monitor recruitment metrics or generate reports that need to be sent across numerous departments. Moreover, these cutting-edge tools offer access to dashboards from a multitude of devices, meaning that everyone within the business can connect with practical insights remotely - and share the load.
Once everyone is able to work with a data-driven mindset, you will catalyze the success of your business in ways you never thought possible. And when it comes to knowing how to analyze data, this kind of collaborative approach is essential.
16. Data analysis tools
In order to perform high-quality analysis of data, it is fundamental to use tools and software that will ensure the best results. Here we leave you a small summary of four fundamental categories of data analysis tools for your organization.
- Business Intelligence: BI tools allow you to process significant amounts of data from several sources in any format. Through this, you can not only analyze and monitor your data to extract relevant insights but also create interactive reports and dashboards to visualize your KPIs and use them for your company's good. datapine is an amazing online BI software that is focused on delivering powerful online analysis features that are accessible to beginner and advanced users. Like this, it offers a full-service solution that includes cutting-edge analysis of data, KPIs visualization, live dashboards, reporting, and artificial intelligence technologies to predict trends and minimize risk.
- Statistical analysis: These tools are usually designed for scientists, statisticians, market researchers, and mathematicians, as they allow them to perform complex statistical analyses with methods like regression analysis, predictive analysis, and statistical modeling. A good tool to perform this type of analysis is R-Studio as it offers a powerful data modeling and hypothesis testing feature that can cover both academic and general data analysis. This tool is one of the favorite ones in the industry, due to its capability for data cleaning, data reduction, and performing advanced analysis with several statistical methods. Another relevant tool to mention is SPSS from IBM. The software offers advanced statistical analysis for users of all skill levels. Thanks to a vast library of machine learning algorithms, text analysis, and a hypothesis testing approach it can help your company find relevant insights to drive better decisions. SPSS also works as a cloud service that enables you to run it anywhere.
- SQL Consoles: SQL is a programming language often used to handle structured data in relational databases. Tools like these are popular among data scientists as they are extremely effective in unlocking these databases' value. Undoubtedly, one of the most used SQL software in the market is MySQL Workbench . This tool offers several features such as a visual tool for database modeling and monitoring, complete SQL optimization, administration tools, and visual performance dashboards to keep track of KPIs.
- Data Visualization: These tools are used to represent your data through charts, graphs, and maps that allow you to find patterns and trends in the data. datapine's already mentioned BI platform also offers a wealth of powerful online data visualization tools with several benefits. Some of them include: delivering compelling data-driven presentations to share with your entire company, the ability to see your data online with any device wherever you are, an interactive dashboard design feature that enables you to showcase your results in an interactive and understandable way, and to perform online self-service reports that can be used simultaneously with several other people to enhance team productivity.
17. Refine your process constantly
Last is a step that might seem obvious to some people, but it can be easily ignored if you think you are done. Once you have extracted the needed results, you should always take a retrospective look at your project and think about what you can improve. As you saw throughout this long list of techniques, data analysis is a complex process that requires constant refinement. For this reason, you should always go one step further and keep improving.
Quality Criteria For Data Analysis
So far we’ve covered a list of methods and techniques that should help you perform efficient data analysis. But how do you measure the quality and validity of your results? This is done with the help of some science quality criteria. Here we will go into a more theoretical area that is critical to understanding the fundamentals of statistical analysis in science. However, you should also be aware of these steps in a business context, as they will allow you to assess the quality of your results in the correct way. Let’s dig in.
- Internal validity: The results of a survey are internally valid if they measure what they are supposed to measure and thus provide credible results. In other words , internal validity measures the trustworthiness of the results and how they can be affected by factors such as the research design, operational definitions, how the variables are measured, and more. For instance, imagine you are doing an interview to ask people if they brush their teeth two times a day. While most of them will answer yes, you can still notice that their answers correspond to what is socially acceptable, which is to brush your teeth at least twice a day. In this case, you can’t be 100% sure if respondents actually brush their teeth twice a day or if they just say that they do, therefore, the internal validity of this interview is very low.
- External validity: Essentially, external validity refers to the extent to which the results of your research can be applied to a broader context. It basically aims to prove that the findings of a study can be applied in the real world. If the research can be applied to other settings, individuals, and times, then the external validity is high.
- Reliability : If your research is reliable, it means that it can be reproduced. If your measurement were repeated under the same conditions, it would produce similar results. This means that your measuring instrument consistently produces reliable results. For example, imagine a doctor building a symptoms questionnaire to detect a specific disease in a patient. Then, various other doctors use this questionnaire but end up diagnosing the same patient with a different condition. This means the questionnaire is not reliable in detecting the initial disease. Another important note here is that in order for your research to be reliable, it also needs to be objective. If the results of a study are the same, independent of who assesses them or interprets them, the study can be considered reliable. Let’s see the objectivity criteria in more detail now.
- Objectivity: In data science, objectivity means that the researcher needs to stay fully objective when it comes to its analysis. The results of a study need to be affected by objective criteria and not by the beliefs, personality, or values of the researcher. Objectivity needs to be ensured when you are gathering the data, for example, when interviewing individuals, the questions need to be asked in a way that doesn't influence the results. Paired with this, objectivity also needs to be thought of when interpreting the data. If different researchers reach the same conclusions, then the study is objective. For this last point, you can set predefined criteria to interpret the results to ensure all researchers follow the same steps.
The discussed quality criteria cover mostly potential influences in a quantitative context. Analysis in qualitative research has by default additional subjective influences that must be controlled in a different way. Therefore, there are other quality criteria for this kind of research such as credibility, transferability, dependability, and confirmability. You can see each of them more in detail on this resource .
Data Analysis Limitations & Barriers
Analyzing data is not an easy task. As you’ve seen throughout this post, there are many steps and techniques that you need to apply in order to extract useful information from your research. While a well-performed analysis can bring various benefits to your organization it doesn't come without limitations. In this section, we will discuss some of the main barriers you might encounter when conducting an analysis. Let’s see them more in detail.
- Lack of clear goals: No matter how good your data or analysis might be if you don’t have clear goals or a hypothesis the process might be worthless. While we mentioned some methods that don’t require a predefined hypothesis, it is always better to enter the analytical process with some clear guidelines of what you are expecting to get out of it, especially in a business context in which data is utilized to support important strategic decisions.
- Objectivity: Arguably one of the biggest barriers when it comes to data analysis in research is to stay objective. When trying to prove a hypothesis, researchers might find themselves, intentionally or unintentionally, directing the results toward an outcome that they want. To avoid this, always question your assumptions and avoid confusing facts with opinions. You can also show your findings to a research partner or external person to confirm that your results are objective.
- Data representation: A fundamental part of the analytical procedure is the way you represent your data. You can use various graphs and charts to represent your findings, but not all of them will work for all purposes. Choosing the wrong visual can not only damage your analysis but can mislead your audience, therefore, it is important to understand when to use each type of data depending on your analytical goals. Our complete guide on the types of graphs and charts lists 20 different visuals with examples of when to use them.
- Flawed correlation : Misleading statistics can significantly damage your research. We’ve already pointed out a few interpretation issues previously in the post, but it is an important barrier that we can't avoid addressing here as well. Flawed correlations occur when two variables appear related to each other but they are not. Confusing correlations with causation can lead to a wrong interpretation of results which can lead to building wrong strategies and loss of resources, therefore, it is very important to identify the different interpretation mistakes and avoid them.
- Sample size: A very common barrier to a reliable and efficient analysis process is the sample size. In order for the results to be trustworthy, the sample size should be representative of what you are analyzing. For example, imagine you have a company of 1000 employees and you ask the question “do you like working here?” to 50 employees of which 49 say yes, which means 95%. Now, imagine you ask the same question to the 1000 employees and 950 say yes, which also means 95%. Saying that 95% of employees like working in the company when the sample size was only 50 is not a representative or trustworthy conclusion. The significance of the results is way more accurate when surveying a bigger sample size.
- Privacy concerns: In some cases, data collection can be subjected to privacy regulations. Businesses gather all kinds of information from their customers from purchasing behaviors to addresses and phone numbers. If this falls into the wrong hands due to a breach, it can affect the security and confidentiality of your clients. To avoid this issue, you need to collect only the data that is needed for your research and, if you are using sensitive facts, make it anonymous so customers are protected. The misuse of customer data can severely damage a business's reputation, so it is important to keep an eye on privacy.
- Lack of communication between teams : When it comes to performing data analysis on a business level, it is very likely that each department and team will have different goals and strategies. However, they are all working for the same common goal of helping the business run smoothly and keep growing. When teams are not connected and communicating with each other, it can directly affect the way general strategies are built. To avoid these issues, tools such as data dashboards enable teams to stay connected through data in a visually appealing way.
- Innumeracy : Businesses are working with data more and more every day. While there are many BI tools available to perform effective analysis, data literacy is still a constant barrier. Not all employees know how to apply analysis techniques or extract insights from them. To prevent this from happening, you can implement different training opportunities that will prepare every relevant user to deal with data.
Key Data Analysis Skills
As you've learned throughout this lengthy guide, analyzing data is a complex task that requires a lot of knowledge and skills. That said, thanks to the rise of self-service tools the process is way more accessible and agile than it once was. Regardless, there are still some key skills that are valuable to have when working with data, we list the most important ones below.
- Critical and statistical thinking: To successfully analyze data you need to be creative and think out of the box. Yes, that might sound like a weird statement considering that data is often tight to facts. However, a great level of critical thinking is required to uncover connections, come up with a valuable hypothesis, and extract conclusions that go a step further from the surface. This, of course, needs to be complemented by statistical thinking and an understanding of numbers.
- Data cleaning: Anyone who has ever worked with data before will tell you that the cleaning and preparation process accounts for 80% of a data analyst's work, therefore, the skill is fundamental. But not just that, not cleaning the data adequately can also significantly damage the analysis which can lead to poor decision-making in a business scenario. While there are multiple tools that automate the cleaning process and eliminate the possibility of human error, it is still a valuable skill to dominate.
- Data visualization: Visuals make the information easier to understand and analyze, not only for professional users but especially for non-technical ones. Having the necessary skills to not only choose the right chart type but know when to apply it correctly is key. This also means being able to design visually compelling charts that make the data exploration process more efficient.
- SQL: The Structured Query Language or SQL is a programming language used to communicate with databases. It is fundamental knowledge as it enables you to update, manipulate, and organize data from relational databases which are the most common databases used by companies. It is fairly easy to learn and one of the most valuable skills when it comes to data analysis.
- Communication skills: This is a skill that is especially valuable in a business environment. Being able to clearly communicate analytical outcomes to colleagues is incredibly important, especially when the information you are trying to convey is complex for non-technical people. This applies to in-person communication as well as written format, for example, when generating a dashboard or report. While this might be considered a “soft” skill compared to the other ones we mentioned, it should not be ignored as you most likely will need to share analytical findings with others no matter the context.
Data Analysis In The Big Data Environment
Big data is invaluable to today’s businesses, and by using different methods for data analysis, it’s possible to view your data in a way that can help you turn insight into positive action.
To inspire your efforts and put the importance of big data into context, here are some insights that you should know:
- By 2026 the industry of big data is expected to be worth approximately $273.4 billion.
- 94% of enterprises say that analyzing data is important for their growth and digital transformation.
- Companies that exploit the full potential of their data can increase their operating margins by 60% .
- We already told you the benefits of Artificial Intelligence through this article. This industry's financial impact is expected to grow up to $40 billion by 2025.
Data analysis concepts may come in many forms, but fundamentally, any solid methodology will help to make your business more streamlined, cohesive, insightful, and successful than ever before.
Key Takeaways From Data Analysis
As we reach the end of our data analysis journey, we leave a small summary of the main methods and techniques to perform excellent analysis and grow your business.
17 Essential Types of Data Analysis Methods:
- Cluster analysis
- Cohort analysis
- Regression analysis
- Factor analysis
- Neural Networks
- Data Mining
- Text analysis
- Time series analysis
- Decision trees
- Conjoint analysis
- Correspondence Analysis
- Multidimensional Scaling
- Content analysis
- Thematic analysis
- Narrative analysis
- Grounded theory analysis
- Discourse analysis
Top 17 Data Analysis Techniques:
- Collaborate your needs
- Establish your questions
- Data democratization
- Think of data governance
- Clean your data
- Set your KPIs
- Omit useless data
- Build a data management roadmap
- Integrate technology
- Answer your questions
- Visualize your data
- Interpretation of data
- Consider autonomous technology
- Build a narrative
- Share the load
- Data Analysis tools
- Refine your process constantly
We’ve pondered the data analysis definition and drilled down into the practical applications of data-centric analytics, and one thing is clear: by taking measures to arrange your data and making your metrics work for you, it’s possible to transform raw information into action - the kind of that will push your business to the next level.
Yes, good data analytics techniques result in enhanced business intelligence (BI). To help you understand this notion in more detail, read our exploration of business intelligence reporting .
And, if you’re ready to perform your own analysis, drill down into your facts and figures while interacting with your data on astonishing visuals, you can try our software for a free, 14-day trial .
No products in the cart.
Preparing the presentation of qualitative findings: considering your roles and goals

Dr. Philip Adu is a Methodology Expert at The Chicago School of Professional Psychology (TCSPP). In this post he explains the things to consider when presenting your research findings.
This post follows on from his previous blog post “Perfecting the art of qualitative coding” in which he took us through the stages of qualitative coding and, along the way, outlined the features he found most useful.
In my previous blog post, I presented on making good use of the innovative features of NVivo across the three main stages of qualitative analysis. Expounding on the third stage which is the ‘ Post-Coding stage (Presenting your findings) ’, I want to throw light on things to consider when drafting and refining your presentation. The moment you reach a milestone of successfully using NVivo 12 (Version 12.1.249; QSR International Pty Ltd, 2018) to complete the data analysis process, the reality of preparing all of this data so you can present your findings sets in (Adu, 2016). Your methodical review of the qualitative data and development of codes, categories and themes has yielded massive and interesting NVivo outputs. The outcomes include but are not limited to; codes/nodes, categories/themes, Word Clouds, Word Tree, Framework Matrices, Cluster Tree, code-case matrices, and code-attribute matrices (see Figure 1). These findings need to be carefully examined – selecting the ones that will be useful in drafting a meaningful presentation. You can watch the presentation I developed below:

Source: https://www.youtube.com/watch?v=xEyGGFtVQFw
Note, not all of this information (i.e. the outcomes) needs to be presented to your audience (see Adu, 2019 ). Other questions that may arise as you develop your presentation include; what kind of results should you present? How do you engage with your audience when presenting your findings? How would you help your audience to understand and believe your findings?
In this post, I will discuss the three pertinent components a good presentation of qualitative findings should have. They are; background information, data analysis process and main findings.
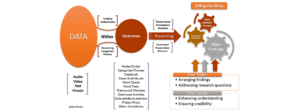
Figure 1. Presentation of findings
Presenting background information
Participants’ past and current situations influence the information they provide to you. Due to this, there is the need to provide readers a summary of who participants are and any background information which may help them to put the findings into the proper context. Also, as a researcher analyzing qualitative data, there is the likelihood of your own background impacting the data analysis process. In the same way, you need to let readers know who you are, what your background is and how you ‘bracketed’ them from not having an effect on the findings ( Adu, 2019 ).
Presenting the data analysis process
Qualitative analysis doesn’t only involve engaging in subjective development of codes and categories, but also promoting transparency in the coding and categorization process (Greckhamer & Cilesiz, 2014). Due to this, you are expected to describe the main and detailed steps you took to analyze your data to arrive at your findings and their respective outcomes. Addressing the following questions would be great:
- What coding strategy did you use?
- What kinds of codes did you assign to relevant excerpts of the data?
- What are the examples of codes you generated?
- What categorization technique did you use?
- How did you develop categories/themes out of the codes?
Your audience’s aim is not only consuming what you found but also learning more about how you came up with the results.
Presenting main findings
When it comes to the presentation of findings, there are two main structures you could choose from. You could present them based on the themes generated or based on the cases (participants or groups of participants) you have. The decision to either structure depends on the kind of research question(s) or the research purpose you have. For a detailed explanation of the types of presentation formats and how to select an appropriate structure, see Chapter 13 of the book, “ A Step-by-Step Guide to Qualitative Data Coding ”.
Considering your roles and goals
As you plan on how to communicate the above components, make sure you accomplish your goals and carry out your role as a communicator of qualitative data analysis outcomes (See Figure 1). Your roles are; to thoughtfully arrange the data analysis outcomes and to adequately address your research questions.
Liken the presentation of your findings to sharing a puzzle which has been solved. Your goal is to prevent a situation where the burden is put on the audience to piece together the puzzle of findings. In other words, you are expected to present the findings in a meaningful way that would enhance the audience’s understanding of the data analysis outcomes (Adu, 2016 & 2019). By so doing, they are more likely to trust what you found.
Let’s summarize the action items:
- Out of a pool of qualitative analysis outcomes, select the ones that would allow you to address your research questions and meaningfully communicate your findings.
- Decide on how you want to structure the presentation of the findings.
- Irrespective of the presentation format you choose, make sure you include background information, the data analysis process and main findings in your presentation.
- Make sure you are ‘narrating’ participants’ stories or what you found – making the numeric outputs include the tables and charts generated play a supporting role when presenting the main findings.
Adu, P. (2016). Presenting Qualitative Findings Using NVivo Output to Tell the Story. [PowerPoint slides]. SlideShare. Retrieved from https://www.slideshare.net/kontorphilip/presenting-qualitative-findings-using-nvivo-output-to-tell-the-story
QSR International Pty Ltd. (2018). NVivo 12. Version 12.1.249 [Computer software]. Retrieved from https://qsrinternational.com/nvivo-qualitative-data-analysis-software
Adu, P. (2019). A Step-by-Step Guide to Qualitative Data Coding . Oxford: Routledge
Greckhamer, T., & Cilesiz, S. (2014). Rigor, Transparency, Evidence, and Representation in Discourse Analysis: Challenges and Recommendations. International Journal of Qualitative Methods, 13(1), 422-443. doi:10.1177/160940691401300123
ABOUT THE AUTHOR

Dr. Philip Adu is a Methodology Expert at The Chicago School of Professional Psychology (TCSPP). His role is to provide support to dissertating students in TCSPP addressing their methodology related concerns. You could access some of his webinars at the ‘Methodology Related Presentations – TCSPP’ YouTube Channel. He completed his Doctoral degree in Education with a concentration in Learning, Instructional Design and Technology from West Virginia University (WVU). Dr. Adu recently authored a book titled, “A Step-by-Step Guide to Qualitative Data Coding” (available on routledge.com or amazon.com ). You could reach Dr. Adu at [email protected] and @drphilipadu on twitter.
Recent Articles
- SUGGESTED TOPICS
- The Magazine
- Newsletters
- Managing Yourself
- Managing Teams
- Work-life Balance
- The Big Idea
- Data & Visuals
- Reading Lists
- Case Selections
- HBR Learning
- Topic Feeds
- Account Settings
- Email Preferences
Present Your Data Like a Pro
- Joel Schwartzberg

Demystify the numbers. Your audience will thank you.
While a good presentation has data, data alone doesn’t guarantee a good presentation. It’s all about how that data is presented. The quickest way to confuse your audience is by sharing too many details at once. The only data points you should share are those that significantly support your point — and ideally, one point per chart. To avoid the debacle of sheepishly translating hard-to-see numbers and labels, rehearse your presentation with colleagues sitting as far away as the actual audience would. While you’ve been working with the same chart for weeks or months, your audience will be exposed to it for mere seconds. Give them the best chance of comprehending your data by using simple, clear, and complete language to identify X and Y axes, pie pieces, bars, and other diagrammatic elements. Try to avoid abbreviations that aren’t obvious, and don’t assume labeled components on one slide will be remembered on subsequent slides. Every valuable chart or pie graph has an “Aha!” zone — a number or range of data that reveals something crucial to your point. Make sure you visually highlight the “Aha!” zone, reinforcing the moment by explaining it to your audience.
With so many ways to spin and distort information these days, a presentation needs to do more than simply share great ideas — it needs to support those ideas with credible data. That’s true whether you’re an executive pitching new business clients, a vendor selling her services, or a CEO making a case for change.
- JS Joel Schwartzberg oversees executive communications for a major national nonprofit, is a professional presentation coach, and is the author of Get to the Point! Sharpen Your Message and Make Your Words Matter and The Language of Leadership: How to Engage and Inspire Your Team . You can find him on LinkedIn and X. TheJoelTruth
Partner Center
Research Guide
Chapter 7 presenting your findings.
Now that you have worked so hard in your project, how to ensure that you can communicate your findings in an effective and efficient way? In this section, I will introduce a few tips that could help you prepare your slides and preparing for your final presentation.
7.1 Sections of the Presentation
When preparing your slides, you need to ensure that you have a clear roadmap. You have a limited time to explain the context of your study, your results, and the main takeaways. Thus, you need to be organized and efficient when deciding what material will be included in the slides.
You need to ensure that your presentation contains the following sections:
- Motivation : Why did you choose your topic? What is the bigger question?
- Research question : Needs to be clear and concise. Include secondary questions, if available, but be clear about what is your research question.
- Literature Review : How does your paper fit in the overall literature? What are your contributions?
- Context : Give an overview of the issue and the population/countries that you analyzed
- Study Characteristics : This section is key, as it needs to include your model, identification strategy, and introduce your data (sources, summary statistics, etc.).
- Results : In this section, you need to answer your research question(s). Include tables that are readable.
- Additional analysis : Here, include any additional information that your public needs to know. For instance, did you try different specifications? did you find an obstacle (i.e. your data is very noisy, the sample is very small, something else) that may bias your results or create some issues in your analysis? Tell your audience! No research project is perfect, but you need to be clear about the imperfections of your project.
- Conclusion : Be repetitive! What was your research question? How did you answer it? What did you find? What is next in this topic?
7.2 How to prepare your slides
When preparing your slides, remember that humans have a limited capacity to pay attention. If you want to convey your convey your message in an effective way, you need to ensure that the message is simple and that you keep your audience attention. Here are some strategies that you may want to follow:
- Have a clear roadmap at the beginning of the presentation. Tell your audience what to expect.
- Number your slides. This will help you and your audience to know where you are in your analysis.
- Ensure that each slide has a purpose
- Ensure that each slide is connected to your key point.
- Make just one argument per slide
- State the objective of each slide in the headline
- Use bullet points. Do not include more than one sentence per bullet point.
- Choose a simple background.
- If you want to direct your audience attention to a specific point, make it more attractive (using a different font color)
- Each slide needs to have a similar structure (going from the general to the particular detauls).
- Use images/graphs when possible. Ensure that the axes for the graphs are clear.
- Use a large font for your tables. Keep them as simple as possible.
- If you can say it with an image, choose it over a table.
- Have an Appendix with slides that address potential questions.
7.3 How to prepare your presentation
One of the main constraints of having simple presentations is that you cannot rely on them and read them. Instead, you need to have extra notes and memorize them to explain things beyond what is on your slides. The following are some suggestions on how to ensure you communicate effectively during your presentation.
- Practice, practice, practice!
- Keep the right volume (practice will help you with that)
- Be journalistic about your presentation. Indicate what you want to say, then say it.
- Ensure that your audience knows where you are going
- Avoid passive voice.
- Be consistent with the terms you are using. You do not want to confuse your audience, even if using synonyms.
- Face your audience and keep an eye contact.
- Do not try reading your slides
- Ensure that your audience is focused on what you are presenting and there are no other distractions that you can control.
- Do not rush your presentation. Speak calmly and controlled.
- Be comprehensive when answering questions. Avoid yes/no answers. Instead, rephrase question (to ensure you are answering the right question), then give a short answer, then develop.
- If you lose track, do not panick. Go back a little bit or ask your audience for assistance.
- Again, practice is the secret.
You have worked so hard in your final project, and the presentation is your opportunity to share that work with the rest of the world. Use this opportunity to shine and enjoy it.
Since this is the first iteration of the Guide, I expect that there are going to be multiple typos and structure issues. Please feel free to let me know, and I will correct accordingly. ↩︎
Note that you would still need to refine some of the good questions even more. ↩︎
Skills for Learning : Research Skills
Data analysis is an ongoing process that should occur throughout your research project. Suitable data-analysis methods must be selected when you write your research proposal. The nature of your data (i.e. quantitative or qualitative) will be influenced by your research design and purpose. The data will also influence the analysis methods selected.
We run interactive workshops to help you develop skills related to doing research, such as data analysis, writing literature reviews and preparing for dissertations. Find out more on the Skills for Learning Workshops page.
We have online academic skills modules within MyBeckett for all levels of university study. These modules will help your academic development and support your success at LBU. You can work through the modules at your own pace, revisiting them as required. Find out more from our FAQ What academic skills modules are available?
Quantitative data analysis
Broadly speaking, 'statistics' refers to methods, tools and techniques used to collect, organise and interpret data. The goal of statistics is to gain understanding from data. Therefore, you need to know how to:
- Produce data – for example, by handing out a questionnaire or doing an experiment.
- Organise, summarise, present and analyse data.
- Draw valid conclusions from findings.
There are a number of statistical methods you can use to analyse data. Choosing an appropriate statistical method should follow naturally, however, from your research design. Therefore, you should think about data analysis at the early stages of your study design. You may need to consult a statistician for help with this.
Tips for working with statistical data
- Plan so that the data you get has a good chance of successfully tackling the research problem. This will involve reading literature on your subject, as well as on what makes a good study.
- To reach useful conclusions, you need to reduce uncertainties or 'noise'. Thus, you will need a sufficiently large data sample. A large sample will improve precision. However, this must be balanced against the 'costs' (time and money) of collection.
- Consider the logistics. Will there be problems in obtaining sufficient high-quality data? Think about accuracy, trustworthiness and completeness.
- Statistics are based on random samples. Consider whether your sample will be suited to this sort of analysis. Might there be biases to think about?
- How will you deal with missing values (any data that is not recorded for some reason)? These can result from gaps in a record or whole records being missed out.
- When analysing data, start by looking at each variable separately. Conduct initial/exploratory data analysis using graphical displays. Do this before looking at variables in conjunction or anything more complicated. This process can help locate errors in the data and also gives you a 'feel' for the data.
- Look out for patterns of 'missingness'. They are likely to alert you if there’s a problem. If the 'missingness' is not random, then it will have an impact on the results.
- Be vigilant and think through what you are doing at all times. Think critically. Statistics are not just mathematical tricks that a computer sorts out. Rather, analysing statistical data is a process that the human mind must interpret!
Top tips! Try inventing or generating the sort of data you might get and see if you can analyse it. Make sure that your process works before gathering actual data. Think what the output of an analytic procedure will look like before doing it for real.
(Note: it is actually difficult to generate realistic data. There are fraud-detection methods in place to identify data that has been fabricated. So, remember to get rid of your practice data before analysing the real stuff!)
Statistical software packages
Software packages can be used to analyse and present data. The most widely used ones are SPSS and NVivo.
SPSS is a statistical-analysis and data-management package for quantitative data analysis. Click on ‘ How do I install SPSS? ’ to learn how to download SPSS to your personal device. SPSS can perform a wide variety of statistical procedures. Some examples are:
- Data management (i.e. creating subsets of data or transforming data).
- Summarising, describing or presenting data (i.e. mean, median and frequency).
- Looking at the distribution of data (i.e. standard deviation).
- Comparing groups for significant differences using parametric (i.e. t-test) and non-parametric (i.e. Chi-square) tests.
- Identifying significant relationships between variables (i.e. correlation).
NVivo can be used for qualitative data analysis. It is suitable for use with a wide range of methodologies. Click on ‘ How do I access NVivo ’ to learn how to download NVivo to your personal device. NVivo supports grounded theory, survey data, case studies, focus groups, phenomenology, field research and action research.
- Process data such as interview transcripts, literature or media extracts, and historical documents.
- Code data on screen and explore all coding and documents interactively.
- Rearrange, restructure, extend and edit text, coding and coding relationships.
- Search imported text for words, phrases or patterns, and automatically code the results.
Qualitative data analysis
Miles and Huberman (1994) point out that there are diverse approaches to qualitative research and analysis. They suggest, however, that it is possible to identify 'a fairly classic set of analytic moves arranged in sequence'. This involves:
- Affixing codes to a set of field notes drawn from observation or interviews.
- Noting reflections or other remarks in the margins.
- Sorting/sifting through these materials to identify: a) similar phrases, relationships between variables, patterns and themes and b) distinct differences between subgroups and common sequences.
- Isolating these patterns/processes and commonalties/differences. Then, taking them out to the field in the next wave of data collection.
- Highlighting generalisations and relating them to your original research themes.
- Taking the generalisations and analysing them in relation to theoretical perspectives.
(Miles and Huberman, 1994.)
Patterns and generalisations are usually arrived at through a process of analytic induction (see above points 5 and 6). Qualitative analysis rarely involves statistical analysis of relationships between variables. Qualitative analysis aims to gain in-depth understanding of concepts, opinions or experiences.
Presenting information
There are a number of different ways of presenting and communicating information. The particular format you use is dependent upon the type of data generated from the methods you have employed.
Here are some appropriate ways of presenting information for different types of data:
Bar charts: These may be useful for comparing relative sizes. However, they tend to use a large amount of ink to display a relatively small amount of information. Consider a simple line chart as an alternative.
Pie charts: These have the benefit of indicating that the data must add up to 100%. However, they make it difficult for viewers to distinguish relative sizes, especially if two slices have a difference of less than 10%.
Other examples of presenting data in graphical form include line charts and scatter plots .
Qualitative data is more likely to be presented in text form. For example, using quotations from interviews or field diaries.
- Plan ahead, thinking carefully about how you will analyse and present your data.
- Think through possible restrictions to resources you may encounter and plan accordingly.
- Find out about the different IT packages available for analysing your data and select the most appropriate.
- If necessary, allow time to attend an introductory course on a particular computer package. You can book SPSS and NVivo workshops via MyHub .
- Code your data appropriately, assigning conceptual or numerical codes as suitable.
- Organise your data so it can be analysed and presented easily.
- Choose the most suitable way of presenting your information, according to the type of data collected. This will allow your information to be understood and interpreted better.
Primary, secondary and tertiary sources
Information sources are sometimes categorised as primary, secondary or tertiary sources depending on whether or not they are ‘original’ materials or data. For some research projects, you may need to use primary sources as well as secondary or tertiary sources. However the distinction between primary and secondary sources is not always clear and depends on the context. For example, a newspaper article might usually be categorised as a secondary source. But it could also be regarded as a primary source if it were an article giving a first-hand account of a historical event written close to the time it occurred.
- Primary sources
- Secondary sources
- Tertiary sources
- Grey literature
Primary sources are original sources of information that provide first-hand accounts of what is being experienced or researched. They enable you to get as close to the actual event or research as possible. They are useful for getting the most contemporary information about a topic.
Examples include diary entries, newspaper articles, census data, journal articles with original reports of research, letters, email or other correspondence, original manuscripts and archives, interviews, research data and reports, statistics, autobiographies, exhibitions, films, and artists' writings.
Some information will be available on an Open Access basis, freely accessible online. However, many academic sources are paywalled, and you may need to login as a Leeds Beckett student to access them. Where Leeds Beckett does not have access to a source, you can use our Request It! Service .
Secondary sources interpret, evaluate or analyse primary sources. They're useful for providing background information on a topic, or for looking back at an event from a current perspective. The majority of your literature searching will probably be done to find secondary sources on your topic.
Examples include journal articles which review or interpret original findings, popular magazine articles commenting on more serious research, textbooks and biographies.
The term tertiary sources isn't used a great deal. There's overlap between what might be considered a secondary source and a tertiary source. One definition is that a tertiary source brings together secondary sources.
Examples include almanacs, fact books, bibliographies, dictionaries and encyclopaedias, directories, indexes and abstracts. They can be useful for introductory information or an overview of a topic in the early stages of research.
Depending on your subject of study, grey literature may be another source you need to use. Grey literature includes technical or research reports, theses and dissertations, conference papers, government documents, white papers, and so on.
Artificial intelligence tools
Before using any generative artificial intelligence or paraphrasing tools in your assessments, you should check if this is permitted on your course.
If their use is permitted on your course, you must acknowledge any use of generative artificial intelligence tools such as ChatGPT or paraphrasing tools (e.g., Grammarly, Quillbot, etc.), even if you have only used them to generate ideas for your assessments or for proofreading.
- Academic Integrity Module in MyBeckett
- Assignment Calculator
- Building on Feedback
- Disability Advice
- Essay X-ray tool
- International Students' Academic Introduction
- Manchester Academic Phrasebank
- Quote, Unquote
- Skills and Subject Suppor t
- Turnitin Grammar Checker
{{You can add more boxes below for links specific to this page [this note will not appear on user pages] }}
- Research Methods Checklist
- Sampling Checklist
Skills for Learning FAQs

0113 812 1000
- University Disclaimer
- Accessibility
New Workshop! Market-Driven Discovery
10 Data Presentation Tips

There’s a popular joke in data circles that you might have already heard: Data practitioners spend 80% of their time preparing data and 20% complaining about preparing data. The truth is, there’s much more to being a data professional than this. Sure, you’ll prepare data — and complain about it sometimes — but you’ll also need to make data presentations to key stakeholders in your company. Remember, data doesn’t mean much until you provide context and present it clearly.
Thankfully, we’re here to help. Here are 10 data presentation tips to effectively communicate with executives, senior managers, marketing managers, and other stakeholders.
1. Choose a Communication Style
Every data professional has a different way of presenting data to their audience. Some people like to tell stories with data, illustrating solutions to existing and potential business problems. Others enjoy using personas to demonstrate how their data findings impact real people. And then some like to present data more conventionally and simply explain what different figures and statistics mean in a business context.
Whatever style you choose, think about the words you will use and how you will present your information. You’ll want to engage your audience as much as possible, even if your findings aren’t particularly interesting.
2. Break Down Complicated Information
Not everyone will comprehend data as well as you do. As a data practitioner, you’ll understand the nuances of data, such as how different data sets correlate with each other and how outliers can impact analysis. However, most people lack knowledge of these concepts.
That’s why you should simplify your data presentations and focus on key takeaways from your findings that stakeholders will understand. For example, instead of showing your audience a spreadsheet with lots of numbers, explain what those numbers prove and what they mean for the company you will work for.
3. Choose the Right Data Visualizations
Sharing cold, hard data sets with people won’t be very effective. Instead, use different data visualizations so your audience can understand the relationships between data sets and the context behind them. There are lots of different visualizations that help you communicate important information:
- Line graphs
- Scatter plots
The type of visualizations you choose depends on what information you’re trying to convey. Graphs, for example, help you showcase potential business outcomes to stakeholders clearly and consistently. Heat maps, on the other hand, let you highlight the most critical data values your audience should know about.
4. Choose the Right Visualization Tools
Numerous data visualization tools on the market will help you communicate data to people in your company. These tools include:
- Microsoft Power BI
- Google Charts
All of these tools are inherently better than presenting data in Excel. You’ll be able to communicate patterns and trends in data more effectively and encourage your audience to interact with your findings.
5. Get Your Audience Involved
Communication is a two-way process, so encourage those at your future data presentations to interact with your content. Before you begin your data presentation, you might want to tell your audience to interrupt you if they want more clarification about a particular data point or insight.
Alternatively, people can ask you questions at the end of your presentation if they don’t understand something or require additional context.
6. Be Authoritative
You’ll almost always present your data findings to key stakeholders in your business. Project confidence when sharing insights and make it clear you know what you’re talking about. Otherwise, your audience might lack confidence in your abilities. Ultimately, explain how you came to a particular conclusion and why you think it’s important to share.
Of course, there will be times when the data you present won’t be what your audience wants to hear. For example, a line graph might reveal that a business will lose revenue over time . In these scenarios, always communicate the facts, even if doing so puts you in an uncomfortable position.
7. Label Your Data Clearly
This point goes back to the fact that your audience won’t know as much about your data as you do. So, avoid using unfamiliar acronyms to label charts or complicated jargon that only other data practitioners would understand. Your role is to present information in a clear and visually compelling way to help stakeholders make better data-driven decisions .
8. Practice Your Data Presentation With Other Team Members
You can always have a dress rehearsal for a presentation before walking into the boardroom. Delivering your findings to other data practitioners on your team, data scientists, data engineers, or other data professionals in your department will help you identify any weak spots in your presentation and ensure you use the right communication style for your audience.
9. Allow Your Audience to Access Your Findings After Your Presentation
A 30- or 60-minute meeting normally won’t be long enough to communicate all your findings or receive stakeholder feedback. Audience members might also forget key points after it’s finished. So, share your insights after your presentation, perhaps in a document. You’ll be able to email colleagues your report so they can review important information. Alternatively, you can upload your presentation slides to Dropbox or your company’s intranet.
Data practitioners often worry about presenting their data to an audience, which is understandable. But you’ll develop a unique communication style and become more confident as the months and years go by. Just remember you’re not a doctor breaking bad news about an incurable health condition. You’re helping businesses understand data, which can be an exciting thing, so try to relax and enjoy yourself!

The Pragmatic Editorial Team comprises a diverse team of writers, researchers, and subject matter experts. We are trained to share Pragmatic Institute’s insights and useful information to guide product, data, and design professionals on their career development journeys. Pragmatic Institute is the global leader in Product, Data, and Design training and certification programs for working professionals. Since 1993, we’ve issued over 250,000 product management and product marketing certifications to professionals at companies around the globe. For questions or inquiries, please contact [email protected] .
Other Resources in this Series
Most Recent

The Data Incubator is Now Pragmatic Data

10 Technologies You Need To Build Your Data Pipeline

Which Machine Learning Language is better?

Data Storytelling

AI Prompts for Data Scientists
Other articles.

Sign up to stay up to date on the latest industry best practices.
Sign up to received invites to upcoming webinars, updates on our recent podcast episodes and the latest on industry best practices.

Research Guide: Data analysis and reporting findings
- Postgraduate Online Training subject guide This link opens in a new window
- Open Educational Resources (OERs)
- Library support
- Research ideas
- You and your supervisor
- Researcher skills
- Research Data Management This link opens in a new window
- Literature review
- Plagiarism This link opens in a new window
- Research Methods
- Data analysis and reporting findings
- Statistical support
- Writing support
- Researcher visibility
- Conferences and Presentations
- Postgraduate Forums
- Soft skills development
- Emotional support
- The Commons Informer (blog)
- Research Tip Archives
- RC Newsletter Archives
- Evaluation Forms
- Editing FAQs
Data analysis and findings
Data analysis is the most crucial part of any research. Data analysis summarizes collected data. It involves the interpretation of data gathered through the use of analytical and logical reasoning to determine patterns, relationships or trends.
Data Analysis Checklist
Cleaning data
* Did you capture and code your data in the right manner?
*Do you have all data or missing data?
* Do you have enough observations?
* Do you have any outliers? If yes, what is the remedy for outlier?
* Does your data have the potential to answer your questions?
Analyzing data
* Visualize your data, e.g. charts, tables, and graphs, to mention a few.
* Identify patterns, correlations, and trends
* Test your hypotheses
* Let your data tell a story
Reports the results
* Communicate and interpret the results
* Conclude and recommend
* Your targeted audience must understand your results
* Use more datasets and samples
* Use accessible and understandable data analytical tool
* Do not delegate your data analysis
* Clean data to confirm that they are complete and free from errors
* Analyze cleaned data
* Understand your results
* Keep in mind who will be reading your results and present it in a way that they will understand it
* Share the results with the supervisor oftentimes
Past presentations
- PhD Writing Retreat - Analysing_Fieldwork_Data by Cori Wielenga A clear and concise presentation on the ‘now what’ and ‘so what’ of data collection and analysis - compiled and originally presented by Cori Wielenga.
Online Resources

- Qualitative analysis of interview data: A step-by-step guide
- Qualitative Data Analysis - Coding & Developing Themes
Recommended Quantitative Data Analysis books

Recommended Qualitative Data Analysis books

- << Previous: Data collection techniques
- Next: Statistical support >>
- Last Updated: Jul 2, 2024 7:20 AM
- URL: https://library.up.ac.za/c.php?g=485435
Presentation of Quantitative Research Findings
- First Online: 30 August 2023
Cite this chapter

- Jan Koetsenruijter 3 &
- Michel Wensing 3
549 Accesses
Valid and clear presentation of research findings is an important aspect of health services research. This chapter presents recommendations and examples for the presentation of quantitative findings, focusing on tables and graphs. The recommendations in this field are largely experience-based. Tables and graphs should be tailored to the needs of the target audience, which partly reflects conventional formats. In many cases, simple formats of tables and graphs with precise information are recommended. Misleading presentation formats must be avoided, and uncertainty of findings should be clearly conveyed in the presentation. Research showed that the latter does not reduce trust in the presented data.
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
Subscribe and save.
- Get 10 units per month
- Download Article/Chapter or Ebook
- 1 Unit = 1 Article or 1 Chapter
- Cancel anytime
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Available as EPUB and PDF
- Durable hardcover edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
Tax calculation will be finalised at checkout
Purchases are for personal use only
Institutional subscriptions
Similar content being viewed by others

Quantitative Methods in Global Health Research

Quantitative Research
Recommended readings.
Designing tables: (Boers, 2018b) (from an article series in BMJ Heart).
Google Scholar
Practical guidelines for designing graphs: http://www.perceptualedge.com (Stephen Few).
Aronson, J. K., Barends, E., Boruch, R., et al. (2019). Key concepts for making informed choices. Nature , 572(7769), 303–306.
Boers, M. (2018a). Designing effective graphs to get your message across. Annals of the Rheumatic Diseases , 77(6), 833–839.
Boers, M. (2018b). Graphics and statistics for cardiology: designing effective tables for presentation and publication. Heart , 104(3), 192–200.
Bramwell, R., West, H., & Salmon, P. (2006). Health professionals’ and service users’ interpretation of screening test results: experimental study. British Medical Journal , 333 (7562), 284.
Cukier, K. (2010). Data, Data Everywhere: A Special Report on Managing Information . The Economist, 394, 3–5.
Duke, S. P., Bancken, F., Crowe, B., et al. (2015). Seeing is believing: Good graphic design principles for medical research. Statistics in Medicine , 34 (22), 3040–3059.
Few, S. (2005). Effectively Communicating Numbers: Selecting the Best Means and Manner of Display [White Paper]. Retrieved December 8, 2021, from http://www.perceptualedge.com/articles/Whitepapers/Communicating_Numbers.pdf
Fischhoff, B., & Davis, A. L. (2014). Communicating scientific uncertainty. Proceedings of the National Academy of Sciences , 111 (supplement_4), 13664–13671.
Gustafson, A., & Rice, R. E. (2020). A review of the effects of uncertainty in public science communication. Public Understanding of Science , 29 (6), 614–633.
Han, P. K. J., Klein, W. M. P., Lehman, T., et al. (2011). Communication of uncertainty regarding individualized cancer risk estimates: Effects and influential factors. Medical Decision Making , 31 (2), 354–366.
Johnston, B. C., Alonso-Coello, P., Friedrich, J. O., et al. (2016). Do clinicians understand the size of treatment effects? A randomized survey across 8 countries. Canadian Medical Association Journal , 188(1), 25–32.
Kelleher, C., & Wagener, T. (2011). Ten guidelines for effective data visualization in scientific publications. Environmental Modelling and Software , 26(6), 822–827.
Khasnabish, S., Burns, Z., Couch, M., et al. (2020). Best practices for data visualization: Creating and evaluating a report for an evidence-based fall prevention program. Journal of the American Medical Informatics Association , 27 (2), 308–314.
Lavis, J., Davies, H. T. O., Oxman, A., et al. (2005). Towards systematic reviews that inform health care management and policy-making. Journal of Health Services Research and Policy . 35–48.
Lopez, K. D., Wilkie, D. J., Yao, Y., et al. (2016). Nurses’ numeracy and graphical literacy: Informing studies of clinical decision support interfaces. Journal of Nursing Care Quality , 31 (2), 124–130.
Norton, E. C., Dowd, B. E., & Maciejewski, M. L. (2018). Odds ratios-current best practice and use. JAMA – Journal of the American Medical Association , 320 (1), 84–85.
Oudhoff, J. P., & Timmermans, D. R. M. (2015). The effect of different graphical and numerical likelihood formats on perception of likelihood and choice. Medical Decision Making , 35(4), 487–500.
Rougier, N. P., Droettboom, M., & Bourne, P. E. (2014). Ten simple rules for better figures. PLoS Computational Biology , 10 (9), 1–7.
Schmidt, C. O., & Kohlmann, T. (2008). Risk quantification in epidemiologic studies. International Journal of Public Health , 53 (2), 118–119.
Springer (2022). Writing a Journal Manuscript: Figures and tables. Retrieved April 10, 2022, from https://www.springer.com/gp/authors-editors/authorandreviewertutorials/writing-a-journal-manuscript/figures-and-tables/10285530
Trevena, L. J., Zikmund-Fisher, B. J., Edwards, A., et al. (2013). Presenting quantitative information about decision outcomes: A risk communication primer for patient decision aid developers. BMC Medical Informatics and Decision Making , 13 (SUPPL. 2), 1–15.
Tufte, E. R. (1983). The visual display of quantitative information. https://www.edwardtufte.com/tufte/books_vdqi
Wensing, M., Szecsenyi, J., Stock, C., et al. (2017). Evaluation of a program to strengthen general practice care for patients with chronic disease in Germany. BMC Health Services Research , 17, 62.
Wronski, P., Wensing, M., Ghosh, S., et al. (2021). Use of a quantitative data report in a hypothetical decision scenario for health policymaking: a computer-assisted laboratory study. BMC Medical Informatics and Decision Making , 21 (1), 32.
Download references
Author information
Authors and affiliations.
Department of General Practice and Health Services Research, Heidelberg University Hospital, Heidelberg, Germany
Jan Koetsenruijter & Michel Wensing
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Jan Koetsenruijter .
Editor information
Editors and affiliations.
Michel Wensing
Charlotte Ullrich
Rights and permissions
Reprints and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this chapter
Koetsenruijter, J., Wensing, M. (2023). Presentation of Quantitative Research Findings. In: Wensing, M., Ullrich, C. (eds) Foundations of Health Services Research. Springer, Cham. https://doi.org/10.1007/978-3-031-29998-8_5
Download citation
DOI : https://doi.org/10.1007/978-3-031-29998-8_5
Published : 30 August 2023
Publisher Name : Springer, Cham
Print ISBN : 978-3-031-29997-1
Online ISBN : 978-3-031-29998-8
eBook Packages : Medicine Medicine (R0)
Share this chapter
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Quantitative Data Analysis
9 Presenting the Results of Quantitative Analysis
Mikaila Mariel Lemonik Arthur
This chapter provides an overview of how to present the results of quantitative analysis, in particular how to create effective tables for displaying quantitative results and how to write quantitative research papers that effectively communicate the methods used and findings of quantitative analysis.
Writing the Quantitative Paper
Standard quantitative social science papers follow a specific format. They begin with a title page that includes a descriptive title, the author(s)’ name(s), and a 100 to 200 word abstract that summarizes the paper. Next is an introduction that makes clear the paper’s research question, details why this question is important, and previews what the paper will do. After that comes a literature review, which ends with a summary of the research question(s) and/or hypotheses. A methods section, which explains the source of data, sample, and variables and quantitative techniques used, follows. Many analysts will include a short discussion of their descriptive statistics in the methods section. A findings section details the findings of the analysis, supported by a variety of tables, and in some cases graphs, all of which are explained in the text. Some quantitative papers, especially those using more complex techniques, will include equations. Many papers follow the findings section with a discussion section, which provides an interpretation of the results in light of both the prior literature and theory presented in the literature review and the research questions/hypotheses. A conclusion ends the body of the paper. This conclusion should summarize the findings, answering the research questions and stating whether any hypotheses were supported, partially supported, or not supported. Limitations of the research are detailed. Papers typically include suggestions for future research, and where relevant, some papers include policy implications. After the body of the paper comes the works cited; some papers also have an Appendix that includes additional tables and figures that did not fit into the body of the paper or additional methodological details. While this basic format is similar for papers regardless of the type of data they utilize, there are specific concerns relating to quantitative research in terms of the methods and findings that will be discussed here.
In the methods section, researchers clearly describe the methods they used to obtain and analyze the data for their research. When relying on data collected specifically for a given paper, researchers will need to discuss the sample and data collection; in most cases, though, quantitative research relies on pre-existing datasets. In these cases, researchers need to provide information about the dataset, including the source of the data, the time it was collected, the population, and the sample size. Regardless of the source of the data, researchers need to be clear about which variables they are using in their research and any transformations or manipulations of those variables. They also need to explain the specific quantitative techniques that they are using in their analysis; if different techniques are used to test different hypotheses, this should be made clear. In some cases, publications will require that papers be submitted along with any code that was used to produce the analysis (in SPSS terms, the syntax files), which more advanced researchers will usually have on hand. In many cases, basic descriptive statistics are presented in tabular form and explained within the methods section.
The findings sections of quantitative papers are organized around explaining the results as shown in tables and figures. Not all results are depicted in tables and figures—some minor or null findings will simply be referenced—but tables and figures should be produced for all findings to be discussed at any length. If there are too many tables and figures, some can be moved to an appendix after the body of the text and referred to in the text (e.g. “See Table 12 in Appendix A”).
Discussions of the findings should not simply restate the contents of the table. Rather, they should explain and interpret it for readers, and they should do so in light of the hypothesis or hypotheses that are being tested. Conclusions—discussions of whether the hypothesis or hypotheses are supported or not supported—should wait for the conclusion of the paper.
Creating Effective Tables
When creating tables to display the results of quantitative analysis, the most important goals are to create tables that are clear and concise but that also meet standard conventions in the field. This means, first of all, paring down the volume of information produced in the statistical output to just include the information most necessary for interpreting the results, but doing so in keeping with standard table conventions. It also means making tables that are well-formatted and designed, so that readers can understand what the tables are saying without struggling to find information. For example, tables (as well as figures such as graphs) need clear captions; they are typically numbered and referred to by number in the text. Columns and rows should have clear headings. Depending on the content of the table, formatting tools may need to be used to set off header rows/columns and/or total rows/columns; cell-merging tools may be necessary; and shading may be important in tables with many rows or columns.
Here, you will find some instructions for creating tables of results from descriptive, crosstabulation, correlation, and regression analysis that are clear, concise, and meet normal standards for data display in social science. In addition, after the instructions for creating tables, you will find an example of how a paper incorporating each table might describe that table in the text.
Descriptive Statistics
When presenting the results of descriptive statistics, we create one table with columns for each type of descriptive statistic and rows for each variable. Note, of course, that depending on level of measurement only certain descriptive statistics are appropriate for a given variable, so there may be many cells in the table marked with an — to show that this statistic is not calculated for this variable. So, consider the set of descriptive statistics below, for occupational prestige, age, highest degree earned, and whether the respondent was born in this country.
To display these descriptive statistics in a paper, one might create a table like Table 2. Note that for discrete variables, we use the value label in the table, not the value.
If we were then to discuss our descriptive statistics in a quantitative paper, we might write something like this (note that we do not need to repeat every single detail from the table, as readers can peruse the table themselves): This analysis relies on four variables from the 2021 General Social Survey: occupational prestige score, age, highest degree earned, and whether the respondent was born in the United States. Descriptive statistics for all four variables are shown in Table 2. The median occupational prestige score is 47, with a range from 16 to 80. 50% of respondents had occupational prestige scores scores between 35 and 59. The median age of respondents is 53, with a range from 18 to 89. 50% of respondents are between ages 37 and 66. Both variables have little skew. Highest degree earned ranges from less than high school to a graduate degree; the median respondent has earned an associate’s degree, while the modal response (given by 39.8% of the respondents) is a high school degree. 88.8% of respondents were born in the United States. CrosstabulationWhen presenting the results of a crosstabulation, we simplify the table so that it highlights the most important information—the column percentages—and include the significance and association below the table. Consider the SPSS output below.
Table 4 shows how a table suitable for include in a paper might look if created from the SPSS output in Table 3. Note that we use asterisks to indicate the significance level of the results: * means p < 0.05; ** means p < 0.01; *** means p < 0.001; and no stars mean p > 0.05 (and thus that the result is not significant). Also note than N is the abbreviation for the number of respondents.
If we were going to discuss the results of this crosstabulation in a quantitative research paper, the discussion might look like this: A crosstabulation of respondent’s class identification and their highest degree earned, with class identification as the independent variable, is significant, with a Spearman correlation of 0.419, as shown in Table 4. Among lower class and working class respondents, more than 50% had earned a high school degree. Less than 20% of poor respondents and less than 40% of working-class respondents had earned more than a high school degree. In contrast, the majority of middle class and upper class respondents had earned at least a bachelor’s degree. In fact, 50% of upper class respondents had earned a graduate degree. CorrelationWhen presenting a correlating matrix, one of the most important things to note is that we only present half the table so as not to include duplicated results. Think of the line through the table where empty cells exist to represent the correlation between a variable and itself, and include only the triangle of data either above or below that line of cells. Consider the output in Table 5.
Table 6 shows what the contents of Table 5 might look like when a table is constructed in a fashion suitable for publication.
If we were to discuss the results of this bivariate correlation analysis in a quantitative paper, the discussion might look like this: Bivariate correlations were run among variables measuring age, occupational prestige, the highest year of school respondents completed, and family income in constant 1986 dollars, as shown in Table 6. Correlations between age and highest year of school completed and between age and family income are not significant. All other correlations are positive and significant at the p<0.001 level. The correlation between age and occupational prestige is weak; the correlations between income and occupational prestige and between income and educational attainment are moderate, and the correlation between education and occupational prestige is strong. To present the results of a regression, we create one table that includes all of the key information from the multiple tables of SPSS output. This includes the R 2 and significance of the regression, either the B or the beta values (different analysts have different preferences here) for each variable, and the standard error and significance of each variable. Consider the SPSS output in Table 7.
The regression output in shown in Table 7 contains a lot of information. We do not include all of this information when making tables suitable for publication. As can be seen in Table 8, we include the Beta (or the B), the standard error, and the significance asterisk for each variable; the R 2 and significance for the overall regression; the degrees of freedom (which tells readers the sample size or N); and the constant; along with the key to p/significance values.
If we were to discuss the results of this regression in a quantitative paper, the results might look like this: Table 8 shows the results of a regression in which age, occupational prestige, and highest year of school completed are the independent variables and family income is the dependent variable. The regression results are significant, and all of the independent variables taken together explain 15.6% of the variance in family income. Age is not a significant predictor of income, while occupational prestige and educational attainment are. Educational attainment has a larger effect on family income than does occupational prestige. For every year of additional education attained, family income goes up on average by $3,988.545; for every one-unit increase in occupational prestige score, family income goes up on average by $522.887. [1]
Social Data Analysis Copyright © 2021 by Mikaila Mariel Lemonik Arthur is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted. Jump to navigation Cochrane TrainingChapter 12: synthesizing and presenting findings using other methods. Joanne E McKenzie, Sue E Brennan Key Points:
Cite this chapter as: McKenzie JE, Brennan SE. Chapter 12: Synthesizing and presenting findings using other methods. In: Higgins JPT, Thomas J, Chandler J, Cumpston M, Li T, Page MJ, Welch VA (editors). Cochrane Handbook for Systematic Reviews of Interventions version 6.4 (updated August 2023). Cochrane, 2023. Available from www.training.cochrane.org/handbook . 12.1 Why a meta-analysis of effect estimates may not be possibleMeta-analysis of effect estimates has many potential advantages (see Chapter 10 and Chapter 11 ). However, there are circumstances where it may not be possible to undertake a meta-analysis and other statistical synthesis methods may be considered (McKenzie and Brennan 2014). Some common reasons why it may not be possible to undertake a meta-analysis are outlined in Table 12.1.a . Legitimate reasons include limited evidence; incompletely reported outcome/effect estimates, or different effect measures used across studies; and bias in the evidence. Other commonly cited reasons for not using meta-analysis are because of too much clinical or methodological diversity, or statistical heterogeneity (Achana et al 2014). However, meta-analysis methods should be considered in these circumstances, as they may provide important insights if undertaken and interpreted appropriately. Table 12.1.a Scenarios that may preclude meta-analysis, with possible solutions
12.2 Statistical synthesis when meta-analysis of effect estimates is not possibleA range of statistical synthesis methods are available, and these may be divided into three categories based on their preferability ( Table 12.2.a ). Preferable methods are the meta-analysis methods outlined in Chapter 10 and Chapter 11 , and are not discussed in detail here. This chapter focuses on methods that might be considered when a meta-analysis of effect estimates is not possible due to incompletely reported data in the primary studies. These methods divide into those that are ‘acceptable’ and ‘unacceptable’. The ‘acceptable’ methods differ in the data they require, the hypotheses they address, limitations around their use, and the conclusions and recommendations that can be drawn (see Section 12.2.1 ). The ‘unacceptable’ methods in common use are described (see Section 12.2.2 ), along with the reasons for why they are problematic. Compared with meta-analysis methods, the ‘acceptable’ synthesis methods provide more limited information for healthcare decision making. However, these ‘acceptable’ methods may be superior to a narrative that describes results study by study, which comes with the risk that some studies or findings are privileged above others without appropriate justification. Further, in reviews with little or no synthesis, readers are left to make sense of the research themselves, which may result in the use of seemingly simple yet problematic synthesis methods such as vote counting based on statistical significance (see Section 12.2.2.1 ). All methods first involve calculation of a ‘standardized metric’, followed by application of a synthesis method. In applying any of the following synthesis methods, it is important that only one outcome per study (or other independent unit, for example one comparison from a trial with multiple intervention groups) contributes to the synthesis. Chapter 9 outlines approaches for selecting an outcome when multiple have been measured. Similar to meta-analysis, sensitivity analyses can be undertaken to examine if the findings of the synthesis are robust to potentially influential decisions (see Chapter 10, Section 10.14 and Section 12.4 for examples). Authors should report the specific methods used in lieu of meta-analysis (including approaches used for presentation and visual display), rather than stating that they have conducted a ‘narrative synthesis’ or ‘narrative summary’ without elaboration. The limitations of the chosen methods must be described, and conclusions worded with appropriate caution. The aim of reporting this detail is to make the synthesis process more transparent and reproducible, and help ensure use of appropriate methods and interpretation. Table 12.2.a Summary of preferable and acceptable synthesis methods
12.2.1 Acceptable synthesis methods12.2.1.1 summarizing effect estimates. Description of method Summarizing effect estimates might be considered in the circumstance where estimates of intervention effect are available (or can be calculated), but the variances of the effects are not reported or are incorrect (and cannot be calculated from other statistics, or reasonably imputed) (Grimshaw et al 2003). Incorrect calculation of variances arises more commonly in non-standard study designs that involve clustering or matching ( Chapter 23 ). While missing variances may limit the possibility of meta-analysis, the (standardized) effects can be summarized using descriptive statistics such as the median, interquartile range, and the range. Calculating these statistics addresses the question ‘What is the range and distribution of observed effects?’ Reporting of methods and results The statistics that will be used to summarize the effects (e.g. median, interquartile range) should be reported. Box-and-whisker or bubble plots will complement reporting of the summary statistics by providing a visual display of the distribution of observed effects (Section 12.3.3 ). Tabulation of the available effect estimates will provide transparency for readers by linking the effects to the studies (Section 12.3.1 ). Limitations of the method should be acknowledged ( Table 12.2.a ). 12.2.1.2 Combining P valuesDescription of method Combining P values can be considered in the circumstance where there is no, or minimal, information reported beyond P values and the direction of effect; the types of outcomes and statistical tests differ across the studies; or results from non-parametric tests are reported (Borenstein et al 2009). Combining P values addresses the question ‘Is there evidence that there is an effect in at least one study?’ There are several methods available (Loughin 2004), with the method proposed by Fisher outlined here (Becker 1994). Fisher’s method combines the P values from statistical tests across k studies using the formula:  One-sided P values are used, since these contain information about the direction of effect. However, these P values must reflect the same directional hypothesis (e.g. all testing if intervention A is more effective than intervention B). This is analogous to standardizing the direction of effects before undertaking a meta-analysis. Two-sided P values, which do not contain information about the direction, must first be converted to one-sided P values. If the effect is consistent with the directional hypothesis (e.g. intervention A is beneficial compared with B), then the one-sided P value is calculated as  In studies that do not report an exact P value but report a conventional level of significance (e.g. P<0.05), a conservative option is to use the threshold (e.g. 0.05). The P values must have been computed from statistical tests that appropriately account for the features of the design, such as clustering or matching, otherwise they will likely be incorrect.  Reporting of methods and results There are several methods for combining P values (Loughin 2004), so the chosen method should be reported, along with details of sensitivity analyses that examine if the results are sensitive to the choice of method. The results from the test should be reported alongside any available effect estimates (either individual results or meta-analysis results of a subset of studies) using text, tabulation and appropriate visual displays (Section 12.3 ). The albatross plot is likely to complement the analysis (Section 12.3.4 ). Limitations of the method should be acknowledged ( Table 12.2.a ). 12.2.1.3 Vote counting based on the direction of effectDescription of method Vote counting based on the direction of effect might be considered in the circumstance where the direction of effect is reported (with no further information), or there is no consistent effect measure or data reported across studies. The essence of vote counting is to compare the number of effects showing benefit to the number of effects showing harm for a particular outcome. However, there is wide variation in the implementation of the method due to differences in how ‘benefit’ and ‘harm’ are defined. Rules based on subjective decisions or statistical significance are problematic and should be avoided (see Section 12.2.2 ). To undertake vote counting properly, each effect estimate is first categorized as showing benefit or harm based on the observed direction of effect alone, thereby creating a standardized binary metric. A count of the number of effects showing benefit is then compared with the number showing harm. Neither statistical significance nor the size of the effect are considered in the categorization. A sign test can be used to answer the question ‘is there any evidence of an effect?’ If there is no effect, the study effects will be distributed evenly around the null hypothesis of no difference. This is equivalent to testing if the true proportion of effects favouring the intervention (or comparator) is equal to 0.5 (Bushman and Wang 2009) (see Section 12.4.2.3 for guidance on implementing the sign test). An estimate of the proportion of effects favouring the intervention can be calculated ( p = u / n , where u = number of effects favouring the intervention, and n = number of studies) along with a confidence interval (e.g. using the Wilson or Jeffreys interval methods (Brown et al 2001)). Unless there are many studies contributing effects to the analysis, there will be large uncertainty in this estimated proportion. Reporting of methods and results The vote counting method should be reported in the ‘Data synthesis’ section of the review. Failure to recognize vote counting as a synthesis method has led to it being applied informally (and perhaps unintentionally) to summarize results (e.g. through the use of wording such as ‘3 of 10 studies showed improvement in the outcome with intervention compared to control’; ‘most studies found’; ‘the majority of studies’; ‘few studies’ etc). In such instances, the method is rarely reported, and it may not be possible to determine whether an unacceptable (invalid) rule has been used to define benefit and harm (Section 12.2.2 ). The results from vote counting should be reported alongside any available effect estimates (either individual results or meta-analysis results of a subset of studies) using text, tabulation and appropriate visual displays (Section 12.3 ). The number of studies contributing to a synthesis based on vote counting may be larger than a meta-analysis, because only minimal statistical information (i.e. direction of effect) is required from each study to vote count. Vote counting results are used to derive the harvest and effect direction plots, although often using unacceptable methods of vote counting (see Section 12.3.5 ). Limitations of the method should be acknowledged ( Table 12.2.a ). 12.2.2 Unacceptable synthesis methods12.2.2.1 vote counting based on statistical significance. Conventional forms of vote counting use rules based on statistical significance and direction to categorize effects. For example, effects may be categorized into three groups: those that favour the intervention and are statistically significant (based on some predefined P value), those that favour the comparator and are statistically significant, and those that are statistically non-significant (Hedges and Vevea 1998). In a simpler formulation, effects may be categorized into two groups: those that favour the intervention and are statistically significant, and all others (Friedman 2001). Regardless of the specific formulation, when based on statistical significance, all have serious limitations and can lead to the wrong conclusion. The conventional vote counting method fails because underpowered studies that do not rule out clinically important effects are counted as not showing benefit. Suppose, for example, the effect sizes estimated in two studies were identical. However, only one of the studies was adequately powered, and the effect in this study was statistically significant. Only this one effect (of the two identical effects) would be counted as showing ‘benefit’. Paradoxically, Hedges and Vevea showed that as the number of studies increases, the power of conventional vote counting tends to zero, except with large studies and at least moderate intervention effects (Hedges and Vevea 1998). Further, conventional vote counting suffers the same disadvantages as vote counting based on direction of effect, namely, that it does not provide information on the magnitude of effects and does not account for differences in the relative sizes of the studies. 12.2.2.2 Vote counting based on subjective rulesSubjective rules, involving a combination of direction, statistical significance and magnitude of effect, are sometimes used to categorize effects. For example, in a review examining the effectiveness of interventions for teaching quality improvement to clinicians, the authors categorized results as ‘beneficial effects’, ‘no effects’ or ‘detrimental effects’ (Boonyasai et al 2007). Categorization was based on direction of effect and statistical significance (using a predefined P value of 0.05) when available. If statistical significance was not reported, effects greater than 10% were categorized as ‘beneficial’ or ‘detrimental’, depending on their direction. These subjective rules often vary in the elements, cut-offs and algorithms used to categorize effects, and while detailed descriptions of the rules may provide a veneer of legitimacy, such rules have poor performance validity (Ioannidis et al 2008). A further problem occurs when the rules are not described in sufficient detail for the results to be reproduced (e.g. ter Wee et al 2012, Thornicroft et al 2016). This lack of transparency does not allow determination of whether an acceptable or unacceptable vote counting method has been used (Valentine et al 2010). 12.3 Visual display and presentation of the dataVisual display and presentation of data is especially important for transparent reporting in reviews without meta-analysis, and should be considered irrespective of whether synthesis is undertaken (see Table 12.2.a for a summary of plots associated with each synthesis method). Tables and plots structure information to show patterns in the data and convey detailed information more efficiently than text. This aids interpretation and helps readers assess the veracity of the review findings. 12.3.1 Structured tabulation of results across studiesOrdering studies alphabetically by study ID is the simplest approach to tabulation; however, more information can be conveyed when studies are grouped in subpanels or ordered by a characteristic important for interpreting findings. The grouping of studies in tables should generally follow the structure of the synthesis presented in the text, which should closely reflect the review questions. This grouping should help readers identify the data on which findings are based and verify the review authors’ interpretation. If the purpose of the table is comparative, grouping studies by any of following characteristics might be informative:
If the purpose of the table is complete and transparent reporting of data, then ordering the studies to increase the prominence of the most relevant and trustworthy evidence should be considered. Possibilities include:
One disadvantage of grouping by study characteristics is that it can be harder to locate specific studies than when tables are ordered by study ID alone, for example when cross-referencing between the text and tables. Ordering by study ID within categories may partly address this. The value of standardizing intervention and outcome labels is discussed in Chapter 3, Section 3.2.2 and Section 3.2.4 ), while the importance and methods for standardizing effect estimates is described in Chapter 6 . These practices can aid readers’ interpretation of tabulated data, especially when the purpose of a table is comparative. 12.3.2 Forest plotsForest plots and methods for preparing them are described elsewhere ( Chapter 10, Section 10.2 ). Some mention is warranted here of their importance for displaying study results when meta-analysis is not undertaken (i.e. without the summary diamond). Forest plots can aid interpretation of individual study results and convey overall patterns in the data, especially when studies are ordered by a characteristic important for interpreting results (e.g. dose and effect size, sample size). Similarly, grouping studies in subpanels based on characteristics thought to modify effects, such as population subgroups, variants of an intervention, or risk of bias, may help explore and explain differences across studies (Schriger et al 2010). These approaches to ordering provide important techniques for informally exploring heterogeneity in reviews without meta-analysis, and should be considered in preference to alphabetical ordering by study ID alone (Schriger et al 2010). 12.3.3 Box-and-whisker plots and bubble plotsBox-and-whisker plots (see Figure 12.4.a , Panel A) provide a visual display of the distribution of effect estimates (Section 12.2.1.1 ). The plot conventionally depicts five values. The upper and lower limits (or ‘hinges’) of the box, represent the 75th and 25th percentiles, respectively. The line within the box represents the 50th percentile (median), and the whiskers represent the extreme values (McGill et al 1978). Multiple box plots can be juxtaposed, providing a visual comparison of the distributions of effect estimates (Schriger et al 2006). For example, in a review examining the effects of audit and feedback on professional practice, the format of the feedback (verbal, written, both verbal and written) was hypothesized to be an effect modifier (Ivers et al 2012). Box-and-whisker plots of the risk differences were presented separately by the format of feedback, to allow visual comparison of the impact of format on the distribution of effects. When presenting multiple box-and-whisker plots, the width of the box can be varied to indicate the number of studies contributing to each. The plot’s common usage facilitates rapid and correct interpretation by readers (Schriger et al 2010). The individual studies contributing to the plot are not identified (as in a forest plot), however, and the plot is not appropriate when there are few studies (Schriger et al 2006). A bubble plot (see Figure 12.4.a , Panel B) can also be used to provide a visual display of the distribution of effects, and is more suited than the box-and-whisker plot when there are few studies (Schriger et al 2006). The plot is a scatter plot that can display multiple dimensions through the location, size and colour of the bubbles. In a review examining the effects of educational outreach visits on professional practice, a bubble plot was used to examine visually whether the distribution of effects was modified by the targeted behaviour (O’Brien et al 2007). Each bubble represented the effect size (y-axis) and whether the study targeted a prescribing or other behaviour (x-axis). The size of the bubbles reflected the number of study participants. However, different formulations of the bubble plot can display other characteristics of the data (e.g. precision, risk-of-bias assessments). 12.3.4 Albatross plotThe albatross plot (see Figure 12.4.a , Panel C) allows approximate examination of the underlying intervention effect sizes where there is minimal reporting of results within studies (Harrison et al 2017). The plot only requires a two-sided P value, sample size and direction of effect (or equivalently, a one-sided P value and a sample size) for each result. The plot is a scatter plot of the study sample sizes against two-sided P values, where the results are separated by the direction of effect. Superimposed on the plot are ‘effect size contours’ (inspiring the plot’s name). These contours are specific to the type of data (e.g. continuous, binary) and statistical methods used to calculate the P values. The contours allow interpretation of the approximate effect sizes of the studies, which would otherwise not be possible due to the limited reporting of the results. Characteristics of studies (e.g. type of study design) can be identified using different colours or symbols, allowing informal comparison of subgroups. The plot is likely to be more inclusive of the available studies than meta-analysis, because of its minimal data requirements. However, the plot should complement the results from a statistical synthesis, ideally a meta-analysis of available effects. 12.3.5 Harvest and effect direction plotsHarvest plots (see Figure 12.4.a , Panel D) provide a visual extension of vote counting results (Ogilvie et al 2008). In the plot, studies based on the categorization of their effects (e.g. ‘beneficial effects’, ‘no effects’ or ‘detrimental effects’) are grouped together. Each study is represented by a bar positioned according to its categorization. The bars can be ‘visually weighted’ (by height or width) and annotated to highlight study and outcome characteristics (e.g. risk-of-bias domains, proximal or distal outcomes, study design, sample size) (Ogilvie et al 2008, Crowther et al 2011). Annotation can also be used to identify the studies. A series of plots may be combined in a matrix that displays, for example, the vote counting results from different interventions or outcome domains. The methods papers describing harvest plots have employed vote counting based on statistical significance (Ogilvie et al 2008, Crowther et al 2011). For the reasons outlined in Section 12.2.2.1 , this can be misleading. However, an acceptable approach would be to display the results based on direction of effect. The effect direction plot is similar in concept to the harvest plot in the sense that both display information on the direction of effects (Thomson and Thomas 2013). In the first version of the effect direction plot, the direction of effects for each outcome within a single study are displayed, while the second version displays the direction of the effects for outcome domains across studies . In this second version, an algorithm is first applied to ‘synthesize’ the directions of effect for all outcomes within a domain (e.g. outcomes ‘sleep disturbed by wheeze’, ‘wheeze limits speech’, ‘wheeze during exercise’ in the outcome domain ‘respiratory’). This algorithm is based on the proportion of effects that are in a consistent direction and statistical significance. Arrows are used to indicate the reported direction of effect (for either outcomes or outcome domains). Features such as statistical significance, study design and sample size are denoted using size and colour. While this version of the plot conveys a large amount of information, it requires further development before its use can be recommended since the algorithm underlying the plot is likely to have poor performance validity. 12.4 Worked exampleThe example that follows uses four scenarios to illustrate methods for presentation and synthesis when meta-analysis is not possible. The first scenario contrasts a common approach to tabulation with alternative presentations that may enhance the transparency of reporting and interpretation of findings. Subsequent scenarios show the application of the synthesis approaches outlined in preceding sections of the chapter. Box 12.4.a summarizes the review comparisons and outcomes, and decisions taken by the review authors in planning their synthesis. While the example is loosely based on an actual review, the review description, scenarios and data are fabricated for illustration. Box 12.4.a The review
12.4.1 Scenario 1: structured reporting of effectsWe first address a scenario in which review authors have decided that the tools used to measure satisfaction measured concepts that were too dissimilar across studies for synthesis to be appropriate. Setting aside three of the 15 studies that reported on the birth partner’s satisfaction with care, a structured summary of effects is sought of the remaining 12 studies. To keep the example table short, only one outcome is shown per study for each of the measurement periods (antenatal, intrapartum or postpartum). Table 12.4.a depicts a common yet suboptimal approach to presenting results. Note two features.
Table 12.4.b shows an improved presentation of the same results. In line with best practice, here effect estimates have been calculated by the review authors for all outcomes, and a common metric computed to aid interpretation (in this case an odds ratio; see Chapter 6 for guidance on conversion of statistics to the desired format). Redundant information has been removed (‘statistical test’ and ‘P value’ columns). The studies have been re-ordered, first to group outcomes by period of care (intrapartum outcomes are shown here), and then by risk of bias. This re-ordering serves two purposes. Grouping by period of care aligns with the plan to consider outcomes for each period separately and ensures the table structure matches the order in which results are described in the text. Re-ordering by risk of bias increases the prominence of studies at lowest risk of bias, focusing attention on the results that should most influence conclusions. Had the review authors determined that a synthesis would be informative, then ordering to facilitate comparison across studies would be appropriate; for example, ordering by the type of satisfaction outcome (as pre-defined in the protocol, starting with global measures of satisfaction), or the comparisons made in the studies. The results may also be presented in a forest plot, as shown in Figure 12.4.b . In both the table and figure, studies are grouped by risk of bias to focus attention on the most trustworthy evidence. The pattern of effects across studies is immediately apparent in Figure 12.4.b and can be described efficiently without having to interpret each estimate (e.g. difference between studies at low and high risk of bias emerge), although these results should be interpreted with caution in the absence of a formal test for subgroup differences (see Chapter 10, Section 10.11 ). Only outcomes measured during the intrapartum period are displayed, although outcomes from other periods could be added, maximizing the information conveyed. An example description of the results from Scenario 1 is provided in Box 12.4.b . It shows that describing results study by study becomes unwieldy with more than a few studies, highlighting the importance of tables and plots. It also brings into focus the risk of presenting results without any synthesis, since it seems likely that the reader will try to make sense of the results by drawing inferences across studies. Since a synthesis was considered inappropriate, GRADE was applied to individual studies and then used to prioritize the reporting of results, focusing attention on the most relevant and trustworthy evidence. An alternative might be to report results at low risk of bias, an approach analogous to limiting a meta-analysis to studies at low risk of bias. Where possible, these and other approaches to prioritizing (or ordering) results from individual studies in text and tables should be pre-specified at the protocol stage. Table 12.4.a Scenario 1: table ordered by study ID, data as reported by study authors
* All scales operate in the same direction; higher scores indicate greater satisfaction. CI = confidence interval; MD = mean difference; OR = odds ratio; POR = proportional odds ratio; RD = risk difference; RR = risk ratio. Table 12.4.b Scenario 1: intrapartum outcome table ordered by risk of bias, standardized effect estimates calculated for all studies
* Outcomes operate in the same direction. A higher score, or an event, indicates greater satisfaction. ** Mean difference calculated for studies reporting continuous outcomes. † For binary outcomes, odds ratios were calculated from the reported summary statistics or were directly extracted from the study. For continuous outcomes, standardized mean differences were calculated and converted to odds ratios (see Chapter 6 ). CI = confidence interval; POR = proportional odds ratio. Figure 12.4.b Forest plot depicting standardized effect estimates (odds ratios) for satisfaction  Box 12.4.b How to describe the results from this structured summary
12.4.2 Overview of scenarios 2–4: synthesis approachesWe now address three scenarios in which review authors have decided that the outcomes reported in the 15 studies all broadly reflect satisfaction with care. While the measures were quite diverse, a synthesis is sought to help decision makers understand whether women and their birth partners were generally more satisfied with the care received in midwife-led continuity models compared with other models. The three scenarios differ according to the data available (see Table 12.4.c ), with each reflecting progressively less complete reporting of the effect estimates. The data available determine the synthesis method that can be applied.
For studies that reported multiple satisfaction outcomes, one result is selected for synthesis using the decision rules in Box 12.4.a (point 2). Table 12.4.c Scenarios 2, 3 and 4: available data for the selected outcome from each study
* All scales operate in the same direction. Higher scores indicate greater satisfaction. ** For a particular scenario, the ‘available data’ column indicates the data that were directly reported, or were calculated from the reported statistics, in terms of: effect estimate, direction of effect, confidence interval, precise P value, or statement regarding statistical significance (either statistically significant, or not). CI = confidence interval; direction = direction of effect reported or can be calculated; MD = mean difference; NS = not statistically significant; OR = odds ratio; RD = risk difference; RoB = risk of bias; RR = risk ratio; sig. = statistically significant; SMD = standardized mean difference; Stand. = standardized. 12.4.2.1 Scenario 2: summarizing effect estimatesIn Scenario 2, effect estimates are available for all outcomes. However, for most studies, a measure of variance is not reported, or cannot be calculated from the available data. We illustrate how the effect estimates may be summarized using descriptive statistics. In this scenario, it is possible to calculate odds ratios for all studies. For the continuous outcomes, this involves first calculating a standardized mean difference, and then converting this to an odds ratio ( Chapter 10, Section 10.6 ). The median odds ratio is 1.32 with an interquartile range of 1.02 to 1.53 (15 studies). Box-and-whisker plots may be used to display these results and examine informally whether the distribution of effects differs by the overall risk-of-bias assessment ( Figure 12.4.a , Panel A). However, because there are relatively few effects, a reasonable alternative would be to present bubble plots ( Figure 12.4.a , Panel B). An example description of the results from the synthesis is provided in Box 12.4.c . Box 12.4.c How to describe the results from this synthesis
12.4.2.2 Scenario 3: combining P valuesIn Scenario 3, there is minimal reporting of the data, and the type of data and statistical methods and tests vary. However, 11 of the 15 studies provide a precise P value and direction of effect, and a further two report a P value less than a threshold (<0.001) and direction. We use this scenario to illustrate a synthesis of P values. Since the reported P values are two-sided ( Table 12.4.c , column 6), they must first be converted to one-sided P values, which incorporate the direction of effect ( Table 12.4.c , column 7). Fisher’s method for combining P values involved calculating the following statistic:  The combination of P values suggests there is strong evidence of benefit of midwife-led models of care in at least one study (P < 0.001 from a Chi 2 test, 13 studies). Restricting this analysis to those studies judged to be at an overall low risk of bias (sensitivity analysis), there is no longer evidence to reject the null hypothesis of no benefit of midwife-led model of care in any studies (P = 0.314, 3 studies). For the five studies reporting continuous satisfaction outcomes, sufficient data (precise P value, direction, total sample size) are reported to construct an albatross plot ( Figure 12.4.a , Panel C). The location of the points relative to the standardized mean difference contours indicate that the likely effects of the intervention in these studies are small. An example description of the results from the synthesis is provided in Box 12.4.d . Box 12.4.d How to describe the results from this synthesis
12.4.2.3 Scenario 4: vote counting based on direction of effectIn Scenario 4, there is minimal reporting of the data, and the type of effect measure (when used) varies across the studies (e.g. mean difference, proportional odds ratio). Of the 15 results, only five report data suitable for meta-analysis (effect estimate and measure of precision; Table 12.4.c , column 8), and no studies reported precise P values. We use this scenario to illustrate vote counting based on direction of effect. For each study, the effect is categorized as beneficial or harmful based on the direction of effect (indicated as a binary metric; Table 12.4.c , column 9). Of the 15 studies, we exclude three because they do not provide information on the direction of effect, leaving 12 studies to contribute to the synthesis. Of these 12, 10 effects favour midwife-led models of care (83%). The probability of observing this result if midwife-led models of care are truly ineffective is 0.039 (from a binomial probability test, or equivalently, the sign test). The 95% confidence interval for the percentage of effects favouring midwife-led care is wide (55% to 95%). The binomial test can be implemented using standard computer spreadsheet or statistical packages. For example, the two-sided P value from the binomial probability test presented can be obtained from Microsoft Excel by typing =2*BINOM.DIST(2, 12, 0.5, TRUE) into any cell in the spreadsheet. The syntax requires the smaller of the ‘number of effects favouring the intervention’ or ‘the number of effects favouring the control’ (here, the smaller of these counts is 2), the number of effects (here 12), and the null value (true proportion of effects favouring the intervention = 0.5). In Stata, the bitest command could be used (e.g. bitesti 12 10 0.5 ). A harvest plot can be used to display the results ( Figure 12.4.a , Panel D), with characteristics of the studies represented using different heights and shading. A sensitivity analysis might be considered, restricting the analysis to those studies judged to be at an overall low risk of bias. However, only four studies were judged to be at a low risk of bias (of which, three favoured midwife-led models of care), precluding reasonable interpretation of the count. An example description of the results from the synthesis is provided in Box 12.4.e . Box 12.4.e How to describe the results from this synthesis
Figure 12.4.a Possible graphical displays of different types of data. (A) Box-and-whisker plots of odds ratios for all outcomes and separately by overall risk of bias. (B) Bubble plot of odds ratios for all outcomes and separately by the model of care. The colours of the bubbles represent the overall risk of bias judgement (green = low risk of bias; yellow = some concerns; red = high risk of bias). (C) Albatross plot of the study sample size against P values (for the five continuous outcomes in Table 12.4.c , column 6). The effect contours represent standardized mean differences. (D) Harvest plot (height depicts overall risk of bias judgement (tall = low risk of bias; medium = some concerns; short = high risk of bias), shading depicts model of care (light grey = caseload; dark grey = team), alphabet characters represent the studies)
12.5 Chapter informationAuthors: Joanne E McKenzie, Sue E Brennan Acknowledgements: Sections of this chapter build on chapter 9 of version 5.1 of the Handbook , with editors Jonathan J Deeks, Julian PT Higgins and Douglas G Altman. We are grateful to the following for commenting helpfully on earlier drafts: Miranda Cumpston, Jamie Hartmann-Boyce, Tianjing Li, Rebecca Ryan and Hilary Thomson. Funding: JEM is supported by an Australian National Health and Medical Research Council (NHMRC) Career Development Fellowship (1143429). SEB’s position is supported by the NHMRC Cochrane Collaboration Funding Program. 12.6 ReferencesAchana F, Hubbard S, Sutton A, Kendrick D, Cooper N. An exploration of synthesis methods in public health evaluations of interventions concludes that the use of modern statistical methods would be beneficial. Journal of Clinical Epidemiology 2014; 67 : 376–390. Becker BJ. Combining significance levels. In: Cooper H, Hedges LV, editors. A handbook of research synthesis . New York (NY): Russell Sage; 1994. p. 215–235. Boonyasai RT, Windish DM, Chakraborti C, Feldman LS, Rubin HR, Bass EB. Effectiveness of teaching quality improvement to clinicians: a systematic review. JAMA 2007; 298 : 1023–1037. Borenstein M, Hedges LV, Higgins JPT, Rothstein HR. Meta-Analysis methods based on direction and p-values. Introduction to Meta-Analysis . Chichester (UK): John Wiley & Sons, Ltd; 2009. pp. 325–330. Brown LD, Cai TT, DasGupta A. Interval estimation for a binomial proportion. Statistical Science 2001; 16 : 101–117. Bushman BJ, Wang MC. Vote-counting procedures in meta-analysis. In: Cooper H, Hedges LV, Valentine JC, editors. Handbook of Research Synthesis and Meta-Analysis . 2nd ed. New York (NY): Russell Sage Foundation; 2009. p. 207–220. Crowther M, Avenell A, MacLennan G, Mowatt G. A further use for the Harvest plot: a novel method for the presentation of data synthesis. Research Synthesis Methods 2011; 2 : 79–83. Friedman L. Why vote-count reviews don’t count. Biological Psychiatry 2001; 49 : 161–162. Grimshaw J, McAuley LM, Bero LA, Grilli R, Oxman AD, Ramsay C, Vale L, Zwarenstein M. Systematic reviews of the effectiveness of quality improvement strategies and programmes. Quality and Safety in Health Care 2003; 12 : 298–303. Harrison S, Jones HE, Martin RM, Lewis SJ, Higgins JPT. The albatross plot: a novel graphical tool for presenting results of diversely reported studies in a systematic review. Research Synthesis Methods 2017; 8 : 281–289. Hedges L, Vevea J. Fixed- and random-effects models in meta-analysis. Psychological Methods 1998; 3 : 486–504. Ioannidis JP, Patsopoulos NA, Rothstein HR. Reasons or excuses for avoiding meta-analysis in forest plots. BMJ 2008; 336 : 1413–1415. Ivers N, Jamtvedt G, Flottorp S, Young JM, Odgaard-Jensen J, French SD, O’Brien MA, Johansen M, Grimshaw J, Oxman AD. Audit and feedback: effects on professional practice and healthcare outcomes. Cochrane Database of Systematic Reviews 2012; 6 : CD000259. Jones DR. Meta-analysis: weighing the evidence. Statistics in Medicine 1995; 14 : 137–149. Loughin TM. A systematic comparison of methods for combining p-values from independent tests. Computational Statistics & Data Analysis 2004; 47 : 467–485. McGill R, Tukey JW, Larsen WA. Variations of box plots. The American Statistician 1978; 32 : 12–16. McKenzie JE, Brennan SE. Complex reviews: methods and considerations for summarising and synthesising results in systematic reviews with complexity. Report to the Australian National Health and Medical Research Council. 2014. O’Brien MA, Rogers S, Jamtvedt G, Oxman AD, Odgaard-Jensen J, Kristoffersen DT, Forsetlund L, Bainbridge D, Freemantle N, Davis DA, Haynes RB, Harvey EL. Educational outreach visits: effects on professional practice and health care outcomes. Cochrane Database of Systematic Reviews 2007; 4 : CD000409. Ogilvie D, Fayter D, Petticrew M, Sowden A, Thomas S, Whitehead M, Worthy G. The harvest plot: a method for synthesising evidence about the differential effects of interventions. BMC Medical Research Methodology 2008; 8 : 8. Riley RD, Higgins JP, Deeks JJ. Interpretation of random effects meta-analyses. BMJ 2011; 342 : d549. Schriger DL, Sinha R, Schroter S, Liu PY, Altman DG. From submission to publication: a retrospective review of the tables and figures in a cohort of randomized controlled trials submitted to the British Medical Journal. Annals of Emergency Medicine 2006; 48 : 750–756, 756 e751–721. Schriger DL, Altman DG, Vetter JA, Heafner T, Moher D. Forest plots in reports of systematic reviews: a cross-sectional study reviewing current practice. International Journal of Epidemiology 2010; 39 : 421–429. ter Wee MM, Lems WF, Usan H, Gulpen A, Boonen A. The effect of biological agents on work participation in rheumatoid arthritis patients: a systematic review. Annals of the Rheumatic Diseases 2012; 71 : 161–171. Thomson HJ, Thomas S. The effect direction plot: visual display of non-standardised effects across multiple outcome domains. Research Synthesis Methods 2013; 4 : 95–101. Thornicroft G, Mehta N, Clement S, Evans-Lacko S, Doherty M, Rose D, Koschorke M, Shidhaye R, O’Reilly C, Henderson C. Evidence for effective interventions to reduce mental-health-related stigma and discrimination. Lancet 2016; 387 : 1123–1132. Valentine JC, Pigott TD, Rothstein HR. How many studies do you need?: a primer on statistical power for meta-analysis. Journal of Educational and Behavioral Statistics 2010; 35 : 215–247. For permission to re-use material from the Handbook (either academic or commercial), please see here for full details. Analysing and Interpreting Data in Your Dissertation: Making Sense of Your FindingsIntroduction Understanding Data Analysis Preparing Your Data for Analysis Quantitative Data Analysis Techniques Qualitative Data Analysis Techniques Interpreting Your Findings Presenting Your Data Common Challenges and How to Overcome Them Conclusion Additional Resources Introductionas the bridge between the raw data you collect and the conclusions you draw. This stage of your research process is vital because it transforms data into meaningful insights, allowing you to address your research questions and hypotheses comprehensively. Proper analysis and interpretation not only validate your findings but also enhance the overall quality and credibility of your dissertation. Effective data analysis involves using appropriate statistical or qualitative techniques to examine your data systematically. Interpretation goes a step further, making sense of the results and explaining their implications in the context of your study. Together, these processes ensure that your research contributions are clear, well-founded, and significant. This article aims to provide a comprehensive guide for analysing and interpreting data in your dissertation. It will cover essential topics such as preparing your data, applying quantitative and qualitative analysis techniques, and effectively presenting and interpreting your findings. By following this guide, you will gain tools and knowledge needed to make sense of your data, ultimately enhancing the impact and credibility of your dissertation. Understanding Data AnalysisDefinition and scope of data analysis in the context of a dissertation. Data analysis in a dissertation involves systematically applying statistical or logical techniques to describe and evaluate data. This process transforms raw data into meaningful information, enabling researchers to draw conclusions and support their hypotheses. In a dissertation, data analysis is crucial as it directly influences the validity and reliability of your findings. The scope of data analysis includes data collection, data cleaning, statistical analysis, and interpretation of results. It encompasses both quantitative and qualitative methods, depending on the nature of the research question and the type of data collected. Differences Between Quantitative and Qualitative Data AnalysisQuantitative data analysis involves numerical data and statistical methods to test hypotheses and identify patterns. Common techniques include descriptive statistics, inferential statistics, and various forms of regression analysis. Quantitative analysis aims to quantify variables and generalize results from a sample to a larger population. On the other hand, qualitative data analysis focuses on non-numerical data such as interviews, observations, and text. It involves identifying themes, patterns, and narratives to provide deeper insights into the research problem. Techniques include thematic analysis, content analysis, and discourse analysis. While quantitative analysis seeks to measure and predict, qualitative analysis aims to understand and interpret complex phenomena. Importance of Choosing the Right Analysis Methods for Your Research Questions and Data TypesChoosing the right analysis methods is crucial for accurately answering your research questions and ensuring the validity of your findings. The selected methods should align with your research objectives, the nature of your data, and the overall research design. For quantitative research, statistical techniques must match the level of measurement and the distribution of your data. For qualitative research, the chosen methods should facilitate an in-depth understanding of the data. Incorrect analysis methods can lead to invalid conclusions, misinterpretation of data, and ultimately, a flawed dissertation. Therefore, a thorough understanding of both quantitative and qualitative analysis techniques is essential for any researcher. Preparing Your Data for AnalysisSteps to clean and organize your data. Before analysing your data, it is essential to clean and organize it to ensure accuracy and reliability. Data cleaning involves identifying and correcting errors, such as duplicates, missing values, and inconsistencies. Start by reviewing your dataset for any obvious mistakes or anomalies. Next, handle missing data by deciding whether to delete, replace, or impute missing values based on the extent and nature of the missing data. Organize your data by categorizing variables, ensuring consistent naming conventions, and creating a clear structure for your dataset. Handling Missing Data and OutliersMissing data and outliers can significantly impact the results of your analysis. For missing data, several strategies can be employed, such as deletion (removing incomplete cases), mean imputation (replacing missing values with the mean), or more advanced techniques like multiple imputation. The choice of method depends on the proportion and pattern of missing data. Outliers, which are extreme values that deviate from other observations, should be carefully examined. Determine whether outliers are errors or genuine observations. If they are errors, correct or remove them. If they are legitimate, consider their potential impact on your analysis and decide whether to include or exclude them. Data Coding and Categorization for Qualitative DataIn qualitative research, data coding is a critical step that involves categorizing and labelling data to identify themes and patterns. Start by familiarizing yourself with the data through repeated readings. Next, create codes that represent key concepts and assign these codes to relevant data segments. Group similar codes into categories and identify overarching themes. This process helps in organizing qualitative data in a way that facilitates in-depth analysis and interpretation. Tools and Software for Data Preparation and OrganizationSeveral tools and software can assist in data preparation and organization: SPSS: Ideal for statistical analysis and data management in quantitative research. NVivo: Suitable for qualitative data analysis, providing tools for coding, categorization, and theme identification. Excel: Useful for basic data cleaning, organization, and preliminary analysis. R: An open-source software for advanced statistical analysis and data manipulation. Python: Widely used for data cleaning, analysis, and visualization, especially with libraries like Pandas and NumPy. Quantitative Data Analysis TechniquesOverview of common quantitative analysis methods. Quantitative data analysis involves the application of statistical methods to test hypotheses and uncover patterns in numerical data. Common techniques include descriptive statistics, which summarize data, and inferential statistics, which allow researchers to draw conclusions and make predictions based on sample data. Descriptive Statistics (Mean, Median, Mode, Standard Deviation)Descriptive statistics provide a basic summary of the data. The mean (average) indicates the central tendency of the data, while the median (middle value) and mode (most frequent value) offer alternative measures of central tendency. The standard deviation measures the spread or variability of the data, indicating how much individual data points differ from the mean. Inferential Statistics (Regression Analysis, ANOVA, t-tests)Inferential statistics enable researchers to make inferences about a population based on sample data. Common methods include: Regression Analysis: Examines the relationship between dependent and independent variables, predicting the impact of changes in the latter on the former. ANOVA (Analysis of Variance): Compares the means of three or more groups to determine if there are significant differences among them. t-tests: Compare the means of two groups to see if they are significantly different from each other. How to Choose the Appropriate Statistical Tests for Your DataSelecting the right statistical test depends on the nature of your research question, the type of data, and the research design. Consider the level of measurement (nominal, ordinal, interval, or ratio) and the distribution of your data. Use parametric tests (like t-tests and ANOVA) for normally distributed data with equal variances, and non-parametric tests (like Mann-Whitney U and Kruskal-Wallis) for data that do not meet these assumptions. Step-by-Step Guide to Performing Quantitative AnalysisDefine Your Hypotheses: Clearly state the null and alternative hypotheses. Select Your Statistical Test: Choose the test that matches your data and research question. Prepare Your Data: Ensure your data is clean and properly formatted. Perform the Analysis: Use statistical software to conduct the analysis. Interpret the Results: Evaluate the statistical significance and practical implications of your findings. Using Software Tools Like SPSS, R, or PythonSoftware tools simplify the process of quantitative analysis: SPSS: Offers a user-friendly interface for performing a wide range of statistical tests. R: Provides powerful statistical packages and customization options for advanced analysis. Python: Features libraries like Pandas and SciPy for data manipulation and statistical analysis. Qualitative Data Analysis TechniquesOverview of common qualitative analysis methods. Qualitative data analysis involves examining non-numerical data to identify patterns, themes, and meanings. Common methods include thematic analysis, content analysis, and discourse analysis. Thematic AnalysisThematic analysis is a method for identifying, analyzing, and reporting patterns (themes) within data. It involves coding the data, searching for themes, reviewing and defining these themes, and reporting the findings. Content AnalysisContent analysis quantifies and analyzes the presence, meanings, and relationships of certain words, themes, or concepts within qualitative data. It can be used to interpret text data by systematically categorizing content. Discourse AnalysisDiscourse analysis examines how language is used in texts and contexts, exploring how language constructs meaning and how power, knowledge, and social relations are communicated. How to Code and Categorize Qualitative DataInitial Familiarization: Read through your data to get a sense of the content. Generate Initial Codes: Identify and label key features of the data that are relevant to your research questions. Search for Themes: Group codes into potential themes. Review Themes: Refine themes by checking them against the data. Define and Name Themes: Clearly define what each theme represents and name them accordingly. Write Up: Summarize the findings and illustrate them with quotes from the data. Step-by-Step Guide to Performing Qualitative AnalysisPrepare Your Data: Transcribe interviews, organize field notes, or collect relevant documents. Familiarize Yourself with the Data: Read and re-read the data to immerse yourself in it. Generate Codes: Systematically code interesting features of the data. Identify Themes: Collate codes into potential themes and gather all data relevant to each theme. Review Themes: Refine themes to ensure they accurately represent the data. Define Themes: Define the specifics of each theme and how it relates to your research questions. Write Up: Present the analysis in a coherent and compelling narrative. Using Software Tools Like NVivo or ATLAS.tiNVivo: Facilitates qualitative data analysis by allowing researchers to organize, code, and visualize data. ATLAS.ti: Offers tools for qualitative data management and analysis, helping to uncover complex phenomena through a systematic approach. Interpreting Your FindingsThe difference between data analysis and data interpretation. Data analysis involves processing data to uncover patterns and insights, while data interpretation involves making sense of these patterns and understanding their implications in the context of your research questions and hypotheses. Interpretation connects the numerical or thematic results of your analysis with broader theoretical and practical implications. Strategies for Interpreting Quantitative FindingsStatistical Significance: Assess whether your findings are statistically significant using p-values and confidence intervals. Effect Size: Evaluate the practical significance of your results by examining effect sizes. Contextualize Findings: Relate your statistical findings to your research questions and theoretical framework. Visualize Data: Use graphs and charts to illustrate your findings clearly. Making Sense of Statistical Significance and Confidence IntervalsStatistical Significance: Indicates whether an observed effect is likely due to chance. A p-value below a predetermined threshold (e.g., 0.05) suggests significance. Confidence Intervals: Provide a range within which the true population parameter is likely to fall, offering insight into the precision of your estimate. Connecting Results to Research Questions and HypothesesInterpret your results in the context of your original research questions and hypotheses. Discuss whether your findings support or refute your hypotheses and how they contribute to the existing body of knowledge. Strategies for Interpreting Qualitative FindingsIdentify Patterns and Themes: Look for recurring themes and patterns in the data. Contextualize Findings: Relate themes to your research questions and theoretical framework. Use Exemplary Quotes: Support your interpretations with direct quotes from your data. Reflect on the Research Process: Consider how your data collection and analysis processes might have influenced your findings. Identifying Patterns and ThemesSystematically review your coded data to identify consistent patterns and themes. Use these patterns to build a narrative that addresses your research questions. Drawing Meaningful Insights and Conclusions from Qualitative DataInterpret qualitative findings by relating them to your research questions and theoretical framework. Draw conclusions that provide a deeper understanding of the research problem and suggest implications for practice, policy, or further research. Presenting Your DataBest practices for presenting data in your dissertation. Effective data presentation is crucial for communicating your findings clearly and convincingly. Use tables, charts, and narratives to present your data in an accessible and engaging manner. Creating Clear and Informative Tables and ChartsChoose the Right Type: Select tables and charts that best represent your data (e.g., bar charts for categorical data, line graphs for trends over time). Label Clearly: Ensure all tables and charts have clear titles, labels, and legends. Simplify: Avoid clutter and focus on presenting key information. Writing Up Your Findings in a Coherent and Structured MannerOrganize your findings logically, following a structure that aligns with your research questions and hypotheses. Use headings and subheadings to guide readers through your analysis and interpretation. How to Integrate Data Presentation with InterpretationLink your data presentation directly to your interpretation. Use visual aids to illustrate key points and enhance the narrative flow. Linking Visual Data Representations with Your NarrativeEnsure that tables, charts, and graphs are integrated into the text and discussed in detail. Explain what each visual representation shows and how it relates to your research questions. Tips for Making Your Data Presentation Accessible and EngagingConsistency: Use consistent formatting for tables and charts. Clarity: Avoid technical jargon and explain complex concepts in simple terms. Engagement: Use visual aids and narratives to keep your readers engaged. By following these guidelines, you can ensure that your data analysis, interpretation, and presentation are thorough, accurate, and compelling, ultimately enhancing the overall quality and impact of your dissertation. Common Challenges and How to Overcome ThemData analysis and interpretation in a dissertation come with several challenges. Common pitfalls include misinterpreting statistical results, where researchers may draw incorrect conclusions from p-values or overlook the importance of effect sizes. Overlooking important themes in qualitative data is another frequent issue, often due to inadequate coding or failure to recognize subtle patterns. To avoid these challenges, it's crucial to follow a few key practices: 1. Understand Statistical Results: Ensure you have a solid grasp of statistical concepts and methods. Use resources such as textbooks, online courses, or statistical consultants to improve your understanding. Pay attention to both statistical significance and practical significance. 2. Thorough Qualitative Analysis: Spend ample time coding qualitative data and revisit the data multiple times to identify emerging themes. Use software tools like NVivo to organize and analyze the data systematically. 3. Seek Feedback: Regularly seek feedback from advisors, peers, or experts in your field. They can provide fresh perspectives and identify potential issues you might have missed. 4. Validation Techniques: Employ validation techniques such as triangulation, which involves using multiple data sources or methods to cross-verify findings. This enhances the reliability and validity of your results. By being mindful of these common challenges and proactively seeking solutions, you can significantly improve the quality and credibility of your dissertation's data analysis and interpretation. Data analysis and interpretation are critical stages in your dissertation that transform raw data into meaningful insights, directly impacting the quality and credibility of your research. This guide has provided a comprehensive overview of the steps and techniques necessary for effectively analysing and interpreting your data. Understanding the scope of data analysis, including the differences between quantitative and qualitative methods, is fundamental. Choosing the appropriate analysis methods that align with your research questions and data types ensures accurate and valid conclusions. Preparing your data through thorough cleaning and organization is the first step toward reliable analysis, whether dealing with missing data, outliers, or coding qualitative data. For quantitative data, techniques such as descriptive and inferential statistics help summarize and make inferences about your data, while qualitative methods like thematic and content analysis offer deep insights into non-numerical data. Using the right software tools, such as SPSS, NVivo, R, and Python, can significantly streamline and enhance your analysis process. Interpreting your findings involves connecting your analysis to your research questions and hypotheses, making sense of statistical significance, and drawing meaningful conclusions from qualitative data. Effective presentation of your data, through clear tables, charts, and well-structured narratives, ensures that your findings are communicated clearly and compellingly. Common challenges in data analysis and interpretation, such as misinterpreting statistical results or overlooking themes in qualitative data, can be mitigated by seeking feedback, understanding statistical concepts, and using validation techniques like triangulation. By following these best practices and utilizing the tools and techniques discussed, you can enhance the rigor and impact of your dissertation, making a significant contribution to your field of study. Remember, the thorough and thoughtful analysis and interpretation of your data are what ultimately make your research findings credible and valuable. Additional ResourcesTo further enhance your understanding and skills in writing a dissertation methodology, consider exploring the following resources: Books and Guides: "Research Design: Qualitative, Quantitative, and Mixed Methods Approaches" by John W. Creswell and J. David Creswell : This book provides a comprehensive overview of various research design methodologies and their applications. "Data Analysis Using Regression and Multilevel/Hierarchical Models" by Andrew Gelman and Jennifer Hill : A detailed guide to advanced statistical techniques, particularly useful for quantitative researchers. "Qualitative Data Analysis: Practical Strategies" by Patricia Bazeley : Offers practical approaches and strategies for analysing qualitative data effectively. "SPSS for Dummies" by Keith McCormick, Jesus Salcedo, and Aaron Poh : A beginner-friendly guide that simplifies the complexities of SPSS, making statistical analysis accessible to all. "Best Practices in Data Cleaning: How to Clean Your Data to Improve Accuracy" by Ronald D. Fricker Jr. and Mark A. Reardon: This article provides practical tips for data cleaning, a crucial step in the analysis process. "Qualitative Data Analysis: A Practical Example" by Sarah E. Gibson: An article that walks through a real-life example of qualitative data analysis, providing insights into the process. "The Importance of Effect Sizes in Reporting Statistical Results: Essential Details for the Researcher" by Lisa F. Smith and Thomas F. E. Smith: This article highlights the significance of effect sizes in interpreting statistical results. Lined and Blank Notebooks: Available for purchase from Amazon , we offer a selection of lined and blank notebooks designed for students to capture all dissertation-related thoughts and research in one centralized place, ensuring that you can easily access and review your work as the project evolves. The lined notebooks provide a structured format for detailed notetaking and organizing research questions systematically The blank notebooks offer a free-form space ideal for sketching out ideas, diagrams, and unstructured notes. By utilizing these resources, you can deepen your understanding of secondary research methods, enhance your research skills, and ensure your dissertation is well-supported by comprehensive and credible secondary research. As an Amazon Associate, I may earn from qualifying purchases. Writing Your Dissertation Hypothesis: A Comprehensive Guide for StudentsSecondary research for your dissertation: a research guide. Data Analysis, Interpretation, and Presentation Techniques: A Guide to Making Sense of Your Research Databy Prince Kumar Last updated: 27 February 2023 Table of Contents Data analysis, interpretation, and presentation are crucial aspects of conducting high-quality research. Data analysis involves processing and analyzing the data to derive meaningful insights, while data interpretation involves making sense of the insights and drawing conclusions. Data presentation involves presenting the data in a clear and concise way to communicate the research findings. In this article, we will discuss the techniques for data analysis, interpretation, and presentation. 1. Data Analysis TechniquesData analysis techniques involve processing and analyzing the data to derive meaningful insights. The choice of data analysis technique depends on the research question and objectives. Some common data analysis techniques are: a. Descriptive StatisticsDescriptive statistics involves summarizing and describing the data using measures such as mean, median, and standard deviation. b. Inferential StatisticsInferential statistics involves making inferences about the population based on the sample data. This technique involves hypothesis testing, confidence intervals, and regression analysis. c. Content AnalysisContent analysis involves analyzing the text, images, or videos to identify patterns and themes. d. Data MiningData mining involves using statistical and machine learning techniques to analyze large datasets and identify patterns. 2. Data Interpretation TechniquesData interpretation involves making sense of the insights derived from the data analysis. The choice of data interpretation technique depends on the research question and objectives. Some common data interpretation techniques are: a. Data VisualizationData visualization involves presenting the data in a visual format, such as charts, graphs, or tables, to communicate the insights effectively. b. StorytellingStorytelling involves presenting the data in a narrative format, such as a story, to make the insights more relatable and memorable. c. Comparative AnalysisComparative analysis involves comparing the research findings with the existing literature or benchmarks to draw conclusions. 3. Data Presentation TechniquesData presentation involves presenting the data in a clear and concise way to communicate the research findings. The choice of data presentation technique depends on the research question and objectives. Some common data presentation techniques are: a. Tables and GraphsTables and graphs are effective data presentation techniques for presenting numerical data. b. InfographicsInfographics are effective data presentation techniques for presenting complex data in a visual and easy-to-understand format. c. Data StorytellingData storytelling involves presenting the data in a narrative format to communicate the research findings effectively. In conclusion, data analysis, interpretation, and presentation are crucial aspects of conducting high-quality research. By using the appropriate data analysis, interpretation, and presentation techniques, researchers can derive meaningful insights, make sense of the insights, and communicate the research findings effectively. By conducting high-quality data analysis, interpretation, and presentation in research, researchers can provide valuable insights into the research question and objectives. How useful was this post? 5 star mean very useful & 1 star means not useful at all. Average rating / 5. Vote count: No votes so far! Be the first to rate this post. We are sorry that this post was not useful for you! 😔 Let us improve this post! Tell us how we can improve this post? Syllabus – Research Methodology01 Introduction To Research Methodology
02 Research Design
03 Sample Design
04 Methods of Data Collection
05 Data Analysis Interpretation and Presentation Techniques
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
A retrospective analysis of the clinical profile and factors associated with mortality and poor hospital outcomes in adult Guillain–Barre syndrome patients
Scientific Reports volume 14 , Article number: 15520 ( 2024 ) Cite this article Metrics details
Guillain–Barré syndrome (GBS) is an acute autoimmune polyneuropathy with substantial geographic variations in demography, antecedent events, clinical manifestations, electrophysiological sub-types, diagnostic findings, treatment modalities, and prognostic indicators. However, there is limited contemporary data on GBS patient profiles and prognostic factors from low-resource settings like Ethiopia. The objective of this study is to investigate the clinical profile, factors associated with mortality, and hospital outcomes among GBS patients admitted to Tikur Anbessa Specialized Hospital (TASH) in Addis Ababa, Ethiopia. A retrospective cross-sectional study was conducted among 60 GBS patients admitted to TASH from January 2018 to December 2022. Data on demographics, clinical features, treatments, complications, and outcomes were extracted from medical records. Bivariate and multivariate logistic regression analyses identified factors associated with mortality and poor hospital outcomes. The cohort had a mean age of 28.5 years, with 76.7% aged 14–34 years. Males comprised 61.7% of cases. Ascending paralysis (76.7%) was the predominant presentation. Absent or reduced reflexes were seen in 91.7% of patients. The most common antecedent event was gastroenteritis (26.7%), followed by upper respiratory tract infection (URTI) (15%) and vaccination (11.7%). The mean interval from symptom onset to hospital presentation was 8.77 days, and the peak symptom severity was 4.47 days. The axonal variant (75.5%) was the most common subtype, followed by the demyelinating variant (24.5%). Intravenous immunoglobulin was administered to 41.7% of patients. Respiratory failure requiring invasive mechanical ventilator (MV) support occurred in 26.7% of cases. The mortality rate was 10%, with mechanical ventilation being the only factor significantly associated with mortality (95% CI 2.067–184.858; P < 0.010). At discharge, 55% had a good outcome, and 45% had a poor outcome, according to the Hughes Functional Disability Scale (HFDS). Mechanical ventilation (AOR 0.024, 95% CI 0.001–0.607) and a GBS disability score > 3 (AOR 0.106, 95% CI 0.024–0.467) were factors significantly associated with poor hospital outcomes. GBS in this cohort primarily affected individuals of young age, commonly preceded by gastroenteritis and characterized by a high frequency of the axonal variant. Mechanical ventilation was found to be significantly linked to mortality. Alongside mechanical ventilation requirements, severe disability upon presentation emerged as a crucial determinant of poor outcomes upon discharge, underscoring the importance of early identification of high-risk patients and prompt interventions. IntroductionGuillain–Barré syndrome (GBS) is an acute polyradiculoneuropathy characterized by immune-mediated damage to the peripheral nervous system, leading to varying degrees of motor dysfunction, sensory impairment, and autonomic instability 1 . It represents the most common cause of acute flaccid paralysis globally, exerting a substantial burden on healthcare systems due to the intensity of care required during the acute phase and the long-term rehabilitation requirements 2 , 3 . Epidemiological data from North America and Europe indicate an annual incidence of GBS ranging from 0.8 to 1.9 cases per 100,000 person-years 4 . GBS exhibits notable variations in incidence, demographic distribution, preceding events, clinical manifestations, electrophysiological subtypes, diagnostic approaches, therapeutic interventions, and prognostic outcomes across different geographical regions 5 , 6 , 7 , 8 . These variations can be attributed to multifaceted factors. Firstly, regional differences in the prevalence and strains of infectious agents such as cytomegalovirus (CMV), Epstein-Barr virus (EBV), and Campylobacter contribute to regional discrepancies in GBS incidence rates 9 . Moreover, variations in hygiene practices across regions affect exposure to these pathogens, potentially influencing GBS development 10 . Dietary habits and nutrient deficiencies also affect disease progression 11 . Environmental factors unique to specific regions also serve as potential triggers for the onset of GBS 12 . Furthermore, genetic variations among populations influence susceptibility to GBS and disease severity 12 , 13 . In regions with limited access to advanced diagnostic tools, underdiagnosis or misdiagnosis of GBS subtypes may occur, impacting reported incidence rates 10 . Moreover, slight differences in diagnostic criteria and disease reporting practices across regions further complicate the accurate assessment of GBS burden 5 , 10 . The absence of affordable and effective treatments significantly worsens outcomes in low- and middle-income countries. Furthermore, socioeconomic factors such as poverty, inadequate infrastructure, and healthcare disparities further compound the difficulties in accessing timely and appropriate care 10 . Most comprehensive studies investigating GBS patient profiles and outcomes originate from high-income regions, particularly North America and Europe. Consequently, there exists a need for more contemporary data on GBS from low- and middle-income countries, including Africa, with limited representation from Ethiopia, thereby impeding a comprehensive understanding of geographical variations in the disease. Moreover, existing studies from the region need to be updated, to accurately depict the current GBS landscape in Ethiopia. This study aims to address this gap in the literature by thoroughly investigating the clinical profile and factors associated with mortality and hospital outcomes among patients diagnosed with GBS admitted to Tikur Anbessa Specialized Hospital (TASH), Ethiopia. By elucidating the contemporary epidemiological, clinical, and prognostic features of GBS in the Ethiopian context, this research endeavors to provide invaluable insights into managing and treating the condition within the local healthcare setting. MethodologyStudy design and setting. A retrospective cross-sectional chart review study was conducted at TASH, focusing on patients admitted to the medical intensive care unit (MICU) and medical ward who were diagnosed with GBS during the period from January 1, 2018, to December 30, 2022. The inclusion criteria encompassed patients aged 14 years and older whose clinical records provided comprehensive information. Excluded from the study were individuals with missing and incomplete medical documentation. Data encompassing clinical and paraclinical variables, inclusive of sociodemographic factors, primary presenting symptoms, symptom and in-hospital stay duration, antecedent events, complications, utilized treatment modalities, mechanical ventilation requirement, and investigation outcomes such as lumbar puncture cytochemistry and nerve conduction studies, were obtained. Patients were stratified based on GBS diagnostic certainty as per Brighton’s criteria 14 , alongside their functional status at hospital admission, assessed utilizing the Hughes Functional Disability Scale (HFDS), also known as the GBS disability score 15 , 16 (see Supplementary Table S1 ). The classification of patients' nerve conduction studies into electrophysiological variants of GBS relied on Rajabally's electrophysiological criteria following a single nerve conduction study 17 . Operational definitionsIn our study, dysautonomia is defined by the presence of blood pressure fluctuations (hypertension or hypotension), occurrences of postural hypotension (a drop of 20 mmHg in systolic blood pressure or 10 mmHg in diastolic blood pressure within 5 min of rising from a supine or seated position), and manifestations of cardiac dysrhythmias (tachycardia or bradycardia) attributable solely to autonomic nervous system dysfunction 18 , 19 . Assessment of the need for mechanical ventilator support encompassed evaluations of respiratory rate, single breath count, incapacity to lift the head, and oxygen saturation levels. A poor outcome was identified by the inability to ambulate independently, denoted by a GBS disability score of 3 or higher upon hospital discharge 20 . Ethical approvalThe present research received ethical clearance from the Institution of Health Research Ethics Review Committee of Tikur Anbessa Specialized Hospital, Internal Medicine Department. The study was conducted in strict accordance with the relevant guidelines and regulations set forth by the committee. Informed consent was waived by the Institutional Health Research Ethics Review Committee of TASH due to the retrospective nature of the study, following established protocols. Statistical analysisWe utilized SPSS version 26 for data analysis. Before analysis, data completeness was ensured. Socio-demographic characteristics were presented in tabular format, detailing both numbers and percentages. A bivariate analysis was conducted to identify independent variables at a significance level of 5%, which were subsequently incorporated into the multivariate binary logistic regression analysis. In the multivariate logistic regression, a 95% confidence interval was calculated for the adjusted odds ratio (AOR), with variables exhibiting a p-value ≤ 0.05 considered statistically associated with poor hospital outcomes among GBS patients. Ethics approval and consent to participateEthical clearance for the study was obtained from the Institution of Health Research Ethics Review Committee of Tikur Anbessa Specialized Hospital, Internal Medicine Department. Officials at various levels within the study area were duly informed through official letters issued by the Internal Medicine Department. Throughout the study, strict measures were implemented to uphold the confidentiality of collected information, and the privacy of participants was meticulously maintained, ensuring compliance with ethical standards and safeguarding the rights of all involved individuals. Informed consent was waived due to the retrospective nature of the study by the Institutional Health Research Ethics Review Committee of TASH. During the study period spanning from January 2018 to December 2022, a total of 60 GBS patient charts were thoroughly reviewed and included in the analysis for the study (see Fig. 1 ).  Flow chart showing the number of identified and excluded medical records of patients. Sociodemographic and clinical profile of patientsThe study exhibited a mean age of 28.5 ± 12.5 years, ranging from 14 to 70 years. The male-to-female ratio was calculated as 1.61, with males comprising 37 individuals (61.7%). Analysis of the age distribution revealed that most cases, comprising 46 (76.7%), fell within the age bracket of 14–34 years (see Table 1 ). Ascending weakness emerged as the predominant presenting symptom among GBS patients, accounting for 46 (76.7%) cases. Bulbar nerve involvement (cranial nerves IX and X) resulting in dysphagia was observed in 11 patients (18.3%), while cranial nerve VII involvement causing facial palsy was noted in 6 patients (10%). Details are provided in Table 1 . The primary antecedent event identified in this study was gastroenteritis, observed in 16 (26.7%) cases. Post-vaccination GBS was seen in 7 (11.7%) cases. Of the 7 vaccination instances, 6 pertained to anti-rabies vaccines and 1 to the COVID-19 vaccine. Notably, COVID-19 infection preceded the onset of GBS in 1 patient. Conversely, 27 (45%) patients exhibited no antecedent infection. 16 (26.7%) patients required mechanical ventilation (see Table 1 ). Additionally, six patients presented with comorbid illnesses, including 4 cases of hypertension (HTN), 1 case of dilated cardiomyopathy (DCMP), and 1 case of chronic myeloid leukemia (CML). The mean interval from the onset of symptoms to presentation at the hospital was 8.77 (± 7.25) days, ranging from 1 to 40 days. Additionally, the mean duration from the initial symptom to peak symptomatology was 4.47 (± 4.78) days, ranging from 1 to 21 days. Hospitalization durations varied widely, ranging from 2 to 180 days, with a mean stay of 26.08 (± 31.08) days. Among the 16 patients who required mechanical ventilation (MV) support, the mean duration of MV support was 25.50 (± 18.79) days, ranging from 8 to 82 days. Diagnosis, laboratory, and nerve conduction profile of patientsRegarding the laboratory tests, lumbar puncture was conducted on 47 patients, revealing albuminocytological dissociation in 39 cases (82.9%). Nerve conduction studies were performed on 45 individuals. The predominant GBS variant observed in this study was the axonal variant, present in 34 out of 45 cases (75.5%), followed by the demyelinating variant in 11 out of 45 cases (24.5%). Among the axonal variant cases, 28 cases (82.3%) were classified as acute motor axonal neuropathy (AMAN), while 6 cases (17.7%) were classified as acute motor and sensory axonal neuropathy (AMSAN). None of the 33 patients who underwent serological testing for HIV yielded reactive results (see Table 2 ). The diagnostic certainty of patients in this study is depicted in Fig. 2 . A Brighton score of 2 was the most common score, observed in half of the patients, totaling 30 cases (50%). Similarly, nearly half of the patients had a Brighton score of 1, comprising 26 cases (43.3%).  Brighton criteria level of diagnostic certainty of diagnosis of GBS in TASH, Addis Ababa, Ethiopia, Jan 2018–Dec 2022 (n = 60). Treatment and outcomes of patientsIntravenous immunoglobulin (IVIg) treatment was administered to 25 patients, accounting for 41.7% of the cohort. Additionally, one patient received steroids for a severe hospital-acquired infection, while none of the patients underwent plasmapheresis. Notably, specific treatment was not provided to 34 patients (56.7%), with only supportive care being administered. Upon bivariate logistic regression analysis, IVIg treatment did not demonstrate an association with either death (p = 0.22) or hospital outcome (p = 0.90). Furthermore, a Mann–Whitney U test revealed that the length of hospital stays for patients receiving IVIg (mean rank = 34.9 days) was not significantly different from those not receiving IVIg (mean rank = 27.3 days), with a p-value of 0.096). Despite a shorter duration of mechanical ventilation support observed in patients who received IVIg (mean = 20.6 days, SD = 11.7 days) compared to those who did not (mean = 30.3 days, SD = 23.7 days), this difference was not statistically significant according to t-test analysis (t(16) = − 1.041, p = 0.316). The hospital mortality rate among patients diagnosed with GBS in this study was determined to be 10%, with 6 out of 60 patients succumbing to their condition. The causes of death were attributed to sudden cardiac arrest in 3 patients, respiratory arrest in 2 patients, and uncontrolled urosepsis in 1 patient. Notably, the requirement for mechanical ventilation support was significantly associated with death on bivariate analysis (5 out of 6 cases; 95% CI 2.067–184.858; p < 0.010). Common complications observed in this study included infections in 19 cases (31.7%), comprising catheter-associated urinary tract infections (CA-UTI) in 12 cases, hospital-acquired pneumonia (HAP) in 10 cases, COVID-19 infection in 1 case, and thrombophlebitis in 1 case. Autonomic dysfunction was noted in 17 cases (28.3%), while bed sores were observed in 4 cases (6.7%). Additionally, tracheoesophageal fistula (TEF) occurred in 3 cases (5%), and pneumothorax was documented in 2 cases (3.3%). Among the total of 60 patients admitted in this study, 33 patients (55%) had a good outcome at discharge, while 27 patients (45%) experienced a poor outcome, as indicated by a high Hughes score. Factors associated with poor hospital outcome (high Hughes score) at dischargeIn bivariate binary logistic regression analysis conducted at a 95% level of significance (p < 0.05), several factors were identified as significantly associated with poor hospital outcomes. These factors included respiratory failure at presentation, the requirement for MV support, autonomic dysfunction, infection, and a GBS functional disability score > 3 at admission, as delineated in Table 3 . However, upon conducting multivariable binary logistic regression analysis, only the need for MV support and a GBS functional disability score > 3 at admission were found to be significantly associated with a poor hospital outcome at discharge (p < 0.05). LimitationsThe limitation of our study is its retrospective nature, relying on chart reviews, which are contingent upon the accuracy and completeness of documentation. Additionally, the relatively small sample size represents another limitation, diminishing the statistical power of the findings and impeding their generalizability to broader patient populations. Sociodemographic and clinical profiles of patientsGBS affects all age groups, with prevalence generally increasing with age 21 , 22 . While common in children, it is less frequent than in adults 23 . Notably, studies show a bimodal distribution of the disease 22 , 24 . The first peak occurs between ages 15 and 34, a trend corroborated by our study. The second peak occurs after age 50. Some studies reported mean ages of 30 and 29.3 years 25 , 26 . Conversely, others have documented comparatively older mean ages, ranging from 40.69 to 52.6 years 22 , 27 , 28 , 29 , 30 . The age-related variations in GBS may stem from immune system changes 31 , declining nerve repair mechanisms 32 , and varied exposure to infectious agents 9 . GBS is more prevalent in males than females, with ratios ranging from 1.1:1 to 1.7:1 23 , 33 . Interestingly, while girls and adolescent females are more likely to develop GBS, this trend reverses in older age groups 34 . The higher prevalence in males may be due to sex differences in immune response, but factors like sex hormones, genetics, and environmental influences also play significant roles, warranting further investigation 33 . In our study, the predominant GBS presentation was ascending paralysis, consistent with other studies 35 , 36 , 37 . The mean interval from symptom onset to hospital presentation in Ethiopia improved from 11.2 days two decades ago to 8.77 days in our study, likely due to better awareness and healthcare access 38 , 39 . IVIg use increased to 41.7% from 6.2%, indicating improved treatment 38 . However, the mean hospital stay remains longer than in Thailand (14.2 days) and the Netherlands (17 days), reflecting ongoing healthcare challenges in Ethiopia 29 , 40 . Albuminocytological dissociation (ACD), a hallmark diagnostic feature of GBS with reported incidences ranging from 44 to 81%, was observed in 82.9% of participants in our study 14 , 41 , 42 . This high prevalence may be due to delayed healthcare presentation, lumbar puncture procedures conducted later in disease progression, and the absence of localized variants in our cohort 43 , 44 . In our study, the predominant variant of GBS was axonal, accounting for 75.5%. This aligns with findings from studies in northern China, India, and Mexico 26 , 45 , 46 . However, it contrasts with studies in southern China, the Balkans, Wuhan-China, Thailand, and Canada, where acute inflammatory demyelinating polyneuropathy (AIDP) is more common. 14 , 29 , 47 , 48 . The difference may be attributed to a higher prevalence of preceding gastroenteritis and a younger age distribution in our cohort, factors often associated with axonal variants. Factors associated with mortality and poor hospital outcomesIn our study, the observed mortality rate of 10% in GBS patients aligns with the reported range (1–18%) and is higher among those requiring mechanical ventilation (12–20%) 49 . Mortality was primarily associated with the need for MV, reflecting the severity of nerve involvement and risks such as ventilator-associated pneumonia (VAP) and ventilator-induced lung injury (VILI) 50 , 51 . These complications underscore the challenges and increased mortality risks associated with MV in GBS. Additionally, a significant subset (45%) experienced poor outcomes at discharge, characterized by a GBS disability score > 3 at discharge. Factors significantly associated with a poor hospital outcome (p < 0.05) include the requirement for MV support and a GBS disability score > 3 at admission. A GBS disability score > 3 at admission can exacerbate complications like pneumonia and deep vein thrombosis (DVT) 52 , 53 . Early mobilization and proactive management strategies are crucial to mitigate these risks and improve patient recovery and outcomes. In conclusion, this retrospective cross-sectional study provides valuable insights into the contemporary clinical profile and factors influencing the outcomes and mortality of GBS patients in Ethiopia. The study addresses a notable gap in the literature by examining this neurological condition within the context of a low-resource setting. Key findings revealed a predominance of the axonal variant of GBS, with the majority of patients presenting with ascending paralysis. Mechanical ventilation requirements and a GBS disability score > 3 at admission emerged as significant risk factors associated with poor hospital outcomes. Moreover, the need for mechanical ventilation was identified as a predictor of mortality risk. While the observed overall mortality rate aligned with global estimates, a substantial proportion of discharged patients exhibited residual functional disability. These findings underscore the complexities of managing GBS and highlight the need for early identification of high-risk patients, prompt initiation of appropriate treatments, and the implementation of comprehensive rehabilitation strategies tailored to the local healthcare environment. By elucidating the challenges and prognostic factors in the Ethiopian context, this study provides a foundation for developing targeted interventions and optimizing resource allocation to improve care delivery and mitigate the burden of GBS in similar resource-constrained settings. Data availabilityThe data supporting the findings of this study will be available from the corresponding author upon reasonable request. van den Berg, B. et al. Guillain–Barré syndrome: Pathogenesis, diagnosis, treatment and prognosis. Nat. Rev. Neurol. 10 (8), 469–482. https://doi.org/10.1038/nrneurol.2014.121 (2014). Article CAS PubMed Google Scholar Frenzen, P. D. Economic cost of Guillain–Barré syndrome in the United States. Neurology 71 (1), 21–27. https://doi.org/10.1212/01.wnl.0000316393.54258.d1 (2008). Kim, A.-Y., Lee, H., Lee, Y.-M. & Kang, H.-Y. Epidemiological features and economic burden of Guillain–Barré syndrome in South Korea: A nationwide population-based study. J. Clin. Neurol. Seoul Korea 17 (2), 257–264. https://doi.org/10.3988/jcn.2021.17.2.257 (2021). Article Google Scholar Abbassi, N. & Ambegaonkar, G. Guillain–Barre syndrome: A review. Paediatr. Child Health 29 (11), 459–462. https://doi.org/10.1016/j.paed.2019.07.008 (2019). Doets, A. Y. et al. Regional variation of Guillain–Barré syndrome. Brain J. Neurol. 141 (10), 2866–2877. https://doi.org/10.1093/brain/awy232 (2018). Arends, S. et al. Electrodiagnosis of Guillain–Barre syndrome in the International GBS Outcome Study: Differences in methods and reference values. Clin. Neurophysiol. Off. J. Int. Fed. Clin. Neurophysiol. 138 , 231–240. https://doi.org/10.1016/j.clinph.2021.12.014 (2022). Webb, A. J. S., Brain, S. A. E., Wood, R., Rinaldi, S. & Turner, M. R. Seasonal variation in Guillain–Barré syndrome: A systematic review, meta-analysis and Oxfordshire cohort study. J. Neurol. Neurosurg. Psychiatry 86 (11), 1196–1201. https://doi.org/10.1136/jnnp-2014-309056 (2015). Article PubMed Google Scholar Yao, J., Liu, Y., Liu, S. & Lu, Z. Regional differences of Guillain–Barré syndrome in China: From south to north. Front. Aging Neurosci. https://doi.org/10.3389/fnagi.2022.831890 (2022). Article PubMed PubMed Central Google Scholar Hao, Y. et al. Antecedent infections in Guillain–Barré syndrome: A single-center, prospective study. Ann. Clin. Transl. Neurol. 6 (12), 2510. https://doi.org/10.1002/acn3.50946 (2019). Article CAS PubMed PubMed Central Google Scholar Papri, N. et al. Guillain–Barré syndrome in low-income and middle-income countries: Challenges and prospects. Nat. Rev. Neurol. 17 (5), 285–296. https://doi.org/10.1038/s41582-021-00467-y (2021). Gao, Y. et al. Serum folate correlates with severity of Guillain–Barré syndrome and predicts disease progression. BioMed Res. Int. 2018 , 5703279. https://doi.org/10.1155/2018/5703279 (2018). Article ADS CAS PubMed PubMed Central Google Scholar Acosta-Ampudia, Y., Monsalve, D. M. & Ramírez-Santana, C. Identifying the culprits in neurological autoimmune diseases. J. Transl. Autoimmun. 2 , 100015. https://doi.org/10.1016/j.jtauto.2019.100015 (2019). Safa, A., Azimi, T., Sayad, A., Taheri, M. & Ghafouri-Fard, S. A review of the role of genetic factors in Guillain–Barré syndrome. J. Mol. Neurosci. MN 71 (5), 902–920. https://doi.org/10.1007/s12031-020-01720-7 (2021). Fokke, C. et al. Diagnosis of Guillain–Barré syndrome and validation of Brighton criteria. Brain J. Neurol. 137 (Pt 1), 33–43. https://doi.org/10.1093/brain/awt285 (2014). Hughes, R. A. C., Newsom-Davis, J. M., Perkin, G. D. & Pierce, J. M. Controlled trial of prednisolone in acute polyneuropathy. Lancet 312 (8093), 750–753. https://doi.org/10.1016/S0140-6736(78)92644-2 (1978). van Koningsveld, R. et al. A clinical prognostic scoring system for Guillain–Barré syndrome. Lancet Neurol. 6 (7), 589–594. https://doi.org/10.1016/S1474-4422(07)70130-8 (2007). Rajabally, Y. A., Hiew, F. L. & Winer, J. B. Influence of timing on electrodiagnosis of Guillain–Barré syndrome in the first six weeks: A retrospective study. J. Neurol. Sci. 357 (1), 143–145. https://doi.org/10.1016/j.jns.2015.07.018 (2015). Chakraborty, T., Kramer, C. L., Wijdicks, E. F. M. & Rabinstein, A. A. Dysautonomia in Guillain–Barré syndrome: Prevalence, clinical spectrum, and outcomes. Neurocrit. Care 32 (1), 113–120. https://doi.org/10.1007/s12028-019-00781-w (2020). Zaeem, Z., Siddiqi, Z. A. & Zochodne, D. W. Autonomic involvement in Guillain–Barré syndrome: An update. Clin. Auton. Res. Off. J. Clin. Auton. Res. Soc. 29 (3), 289–299. https://doi.org/10.1007/s10286-018-0542-y (2019). “Frontiers | Disability evaluation in patients with Guillain–Barre syndrome and SARS-CoV-2 infection”. https://doi.org/10.3389/fneur.2023.1191520/full (accessed 02 Apr 2024). Sejvar, J. J., Baughman, A. L., Wise, M. & Morgan, O. W. Population incidence of Guillain–Barré syndrome: A systematic review and meta-analysis. Neuroepidemiology 36 (2), 123–133. https://doi.org/10.1159/000324710 (2011). Shrivastava, M., Nehal, S. & Seema, N. Guillain–Barre syndrome: Demographics, clinical profile and seasonal variation in a tertiary care centre of central India. Indian J. Med. Res. 145 (2), 203–208. https://doi.org/10.4103/ijmr.IJMR_995_14 (2017). Al-Hakem, H. et al. Guillain–Barré syndrome in Denmark: A population-based study on epidemiology, diagnosis and clinical severity. J. Neurol. 266 (2), 440–449. https://doi.org/10.1007/s00415-018-9151-x (2019). McGrogan, A., Madle, G. C., Seaman, H. E. & de Vries, C. S. The epidemiology of Guillain–Barré syndrome worldwide. A systematic literature review. Neuroepidemiology 32 (2), 150–163. https://doi.org/10.1159/000184748 (2009). Ralot, T. K., Parmar, S., Gujar, R., Sarkar, S. & Meghwal, H. Study of clinical profile and prognosis in various subtypes of Guillain–Barre syndrome patients. IP Indian J. Neurosci. 4 (4), 204–208 (2020). Verma, R., Chaudhari, T. S., Raut, T. P. & Garg, R. K. Clinico-electrophysiological profile and predictors of functional outcome in Guillain–Barre syndrome (GBS). J. Neurol. Sci. 335 (1–2), 105–111. https://doi.org/10.1016/j.jns.2013.09.002 (2013). AlKahtani, N. A. et al. Guillain–Barré syndrome in adults in a decade: The largest, single-center, cross-sectional study from the Kingdom of Saudi Arabia. Cureus 15 (6), e40995. https://doi.org/10.7759/cureus.40995 (2023). González-Suárez, I., Sanz-Gallego, I., Rodríguez de Rivera, F. J. & Arpa, J. Guillain–Barré syndrome: natural history and prognostic factors: A retrospective review of 106 cases. BMC Neurol. 13 , 95. https://doi.org/10.1186/1471-2377-13-95 (2013). Kulkantrakorn, K. & Sukphulloprat, P. Outcome of Guillain–Barré syndrome in tertiary care centers in Thailand. J. Clin. Neuromuscul. Dis. 19 (2), 51–56. https://doi.org/10.1097/CND.0000000000000176 (2017). Peric, S. et al. Clinical and epidemiological features of Guillain–Barré syndrome in the Western Balkans. J. Peripher. Nerv. Syst. JPNS 19 (4), 317–321. https://doi.org/10.1111/jns.12096 (2014). Hughes, R. A. & Rees, J. H. Clinical and epidemiologic features of Guillain–Barré syndrome. J. Infect. Dis. 176 (Suppl 2), S92-98. https://doi.org/10.1086/513793 (1997). Hagen, K. M. & Ousman, S. S. The neuroimmunology of Guillain–Barré syndrome and the potential role of an aging immune system. Front. Aging Neurosci. 12 , 613628. https://doi.org/10.3389/fnagi.2020.613628 (2021). McCombe, P. A., Hardy, T. A., Nona, R. J. & Greer, J. M. Sex differences in Guillain–Barré syndrome, chronic inflammatory demyelinating polyradiculoneuropathy and experimental autoimmune neuritis. Front. Immunol. 13 , 1038411. https://doi.org/10.3389/fimmu.2022.1038411 (2022). Sipilä, J. O. T., Soilu-Hänninen, M., Ruuskanen, J. O., Rautava, P. & Kytö, V. Epidemiology of Guillain–Barré syndrome in Finland 2004–2014. J. Peripher. Nerv. Syst. 22 (4), 440–445. https://doi.org/10.1111/jns.12239 (2017). Amante, J. M. G. & Preysler, M. G. Clinical profile and outcomes of Guillain–Barre syndrome: A four-year retrospective study at a tertiary hospital in the Philippines. Clin. Profile Outcomes Guillain–Barre. Syndr. Four-Year Retrosp. Study Tert. Hosp. Philipp. 73 (1), 1 (2021). Google Scholar Head, V. A. & Wakerley, B. R. Guillain–Barré syndrome in general practice: Clinical features suggestive of early diagnosis. Br. J. Gen. Pract. 66 (645), 218–219. https://doi.org/10.3399/bjgp16X684733 (2016). Maawali, S. M. A., Shibani, A. Y. A., Nadeem, A. S. & Al-Salti, A. M. Guillain–Barre syndrome: Demographics, clinical features, and outcome in a single tertiary care hospital, Oman. Neurosci. J. 25 (5), 369–374. https://doi.org/10.17712/nsj.2020.5.20200057 (2020). Melaku, Z., Zenebe, G. & Bekele, A. Guillain–Barré syndrome in Ethiopian patients. Ethiop. Med. J. 43 (1), 21–26 (2005). PubMed Google Scholar Assefa, Y. et al. Primary health care contributions to universal health coverage, Ethiopia. Bull. World Health Organ. 98 (12), 894-905A. https://doi.org/10.2471/BLT.19.248328 (2020). van Leeuwen, N. et al. Hospital admissions, transfers and costs of Guillain–Barré syndrome. PLoS One 11 (2), e0143837. https://doi.org/10.1371/journal.pone.0143837 (2016). Bourque, P. R., Brooks, J., McCudden, C. R., Warman-Chardon, J. & Breiner, A. Age matters. Neurol. Neuroimmunol. Neuroinflamm. 6 (4), e576. https://doi.org/10.1212/NXI.0000000000000576 (2019). Bourque, P. R., Brooks, J., Warman-Chardon, J. & Breiner, A. Cerebrospinal fluid total protein in Guillain–Barré syndrome variants: Correlations with clinical category, severity, and electrophysiology. J. Neurol. 267 (3), 746–751. https://doi.org/10.1007/s00415-019-09634-0 (2020). Nishimoto, Y., Odaka, M., Hirata, K. & Yuki, N. Usefulness of anti-GQ1b IgG antibody testing in Fisher syndrome compared with cerebrospinal fluid examination. J. Neuroimmunol. 148 (1), 200–205. https://doi.org/10.1016/j.jneuroim.2003.11.017 (2004). Guillain–Barré syndrome in Taiwan: A clinical study of 167 patients. J. Neurol. Neurosurg. Psychiatry . https://jnnp.bmj.com/content/63/4/494 (accessed 28 Mar 2024). Ho, T. W. et al. Guillain–Barré syndrome in northern China. Relationship to Campylobacter jejuni infection and anti-glycolipid antibodies. Brain J. Neurol. 118 (Pt 3), 597–605. https://doi.org/10.1093/brain/118.3.597 (1995). Ruiz-Sandoval, J. L. et al. Clinical characteristics and predictors of short-term outcome in Mexican adult patients with Guillain–Barré syndrome. Neurol. India 69 (1), 107–114. https://doi.org/10.4103/0028-3886.310063 (2021). Liu, S. et al. Guillain–Barré syndrome in southern China: Retrospective analysis of hospitalised patients from 14 provinces in the area south of the Huaihe River. J. Neurol. Neurosurg. Psychiatry 89 (6), 618–626. https://doi.org/10.1136/jnnp-2017-316930 (2018). Zeng, Y. et al. Clinical features and the validation of the brighton criteria in Guillain–Barré syndrome: Retrospective analysis of 72 hospitalized patients in three years. Eur. Neurol. 81 (5–6), 231–238. https://doi.org/10.1159/000503101 (2019). Netto, A. B., Taly, A. B., Kulkarni, G. B., Rao, U. G. S. & Rao, S. Mortality in mechanically ventilated patients of Guillain–Barré syndrome. Ann. Indian Acad. Neurol. 14 (4), 262–266. https://doi.org/10.4103/0972-2327.91942 (2011). Melone, M.-A. et al. Early mechanical ventilation in patients with Guillain–Barré syndrome at high risk of respiratory failure: A randomized trial. Ann. Intensive Care 10 , 128. https://doi.org/10.1186/s13613-020-00742-z (2020). Orlikowski, D. et al. Prognosis and risk factors of early onset pneumonia in ventilated patients with Guillain–Barré syndrome. Intensive Care Med. 32 (12), 1962–1969. https://doi.org/10.1007/s00134-006-0332-1 (2006). Parry, S. M. & Puthucheary, Z. A. The impact of extended bed rest on the musculoskeletal system in the critical care environment. Extreme Physiol. Med. 4 , 16. https://doi.org/10.1186/s13728-015-0036-7 (2015). Teasell, R. & Dittmer, D. K. Complications of immobilization and bed rest. Part 2: Other complications. Can. Fam. Physician 39 , 1440 (1993). CAS PubMed PubMed Central Google Scholar Download references Author informationAuthors and affiliations. Department of Internal Medicine, College of Health Science, Mekelle University, Mekelle, Ethiopia Zinabu Derso Tewedaj Division of Pulmonary and Critical Care Medicine, Department of Internal Medicine, College of Health Sciences, Addis Ababa University, Addis Ababa, Ethiopia Dawit Kebede Huluka Department of Medicine, Faculty of Medical Sciences, Institute of Health, Jimma University, Jimma, Ethiopia Yabets Tesfaye Kebede & Abel Tezera Abebe Department of Internal Medicine, Ethio-Tebib General Hospital, Addis Ababa, Ethiopia Meksud Shemsu Hussen & Bekri Delil Mohammed Department of Internal Medicine, St. Paul’s Hospital Millennium Medical College, Addis Ababa, Ethiopia Leja Hamza Juhar You can also search for this author in PubMed Google Scholar ContributionsZ.D.T. contributed to the study’s conception, design, initial drafting, and data analysis. Y.T.K. and B.D.M. contributed to manuscript revision, data analysis, and final intellectual content assembly. D.K.H. and L.H.J. guided the design, initial drafting, and data analysis phases. A.T.A. and M.S.H. contributed to data acquisition and proofreading. Corresponding authorCorrespondence to Yabets Tesfaye Kebede . Ethics declarationsCompeting interests. The authors declare no competing interests. Additional informationPublisher's note. Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations. Supplementary InformationSupplementary table s1., rights and permissions. Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . Reprints and permissions About this articleCite this article. Tewedaj, Z.D., Huluka, D.K., Kebede, Y.T. et al. A retrospective analysis of the clinical profile and factors associated with mortality and poor hospital outcomes in adult Guillain–Barre syndrome patients. Sci Rep 14 , 15520 (2024). https://doi.org/10.1038/s41598-024-65265-0 Download citation Received : 05 April 2024 Accepted : 18 June 2024 Published : 05 July 2024 DOI : https://doi.org/10.1038/s41598-024-65265-0 Share this articleAnyone you share the following link with will be able to read this content: Sorry, a shareable link is not currently available for this article. Provided by the Springer Nature SharedIt content-sharing initiative
By submitting a comment you agree to abide by our Terms and Community Guidelines . If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate. Quick links
Sign up for the Nature Briefing newsletter — what matters in science, free to your inbox daily. 
Understanding the challenges of identifying, supporting, and signposting patients with alcohol use disorder in secondary care hospitals, post COVID-19: a qualitative analysis from the North East and North Cumbria, England
BMC Health Services Research volume 24 , Article number: 772 ( 2024 ) Cite this article 120 Accesses Metrics details Alcohol-related mortality and morbidity increased during the COVID-19 pandemic in England, with people from lower-socioeconomic groups disproportionately affected. The North East and North Cumbria (NENC) region has high levels of deprivation and the highest rates of alcohol-related harm in England. Consequently, there is an urgent need for the implementation of evidence-based preventative approaches such as identifying people at risk of alcohol harm and providing them with appropriate support. Non-alcohol specialist secondary care clinicians could play a key role in delivering these interventions, but current implementation remains limited. In this study we aimed to explore current practices and challenges around identifying, supporting, and signposting patients with Alcohol Use Disorder (AUD) in secondary care hospitals in the NENC through the accounts of staff in the post COVID-19 context. Semi-structured qualitative interviews were conducted with 30 non-alcohol specialist staff (10 doctors, 20 nurses) in eight secondary care hospitals across the NENC between June and October 2021. Data were analysed inductively and deductively to identify key codes and themes, with Normalisation Process Theory (NPT) then used to structure the findings. Findings were grouped using the NPT domains ‘implementation contexts’ and ‘implementation mechanisms’. The following implementation contexts were identified as key factors limiting the implementation of alcohol prevention work: poverty which has been exacerbated by COVID-19 and the prioritisation of acute presentations (negotiating capacity); structural stigma (strategic intentions); and relational stigma (reframing organisational logics). Implementation mechanisms identified as barriers were: workforce knowledge and skills (cognitive participation); the perception that other departments and roles were better placed to deliver this preventative work than their own (collective action); and the perceived futility and negative feedback cycle (reflexive monitoring). ConclusionsCOVID-19, has generated additional challenges to identifying, supporting, and signposting patients with AUD in secondary care hospitals in the NENC. Our interpretation suggests that implementation contexts, in particular structural stigma and growing economic disparity, are the greatest barriers to implementation of evidence-based care in this area. Thus, while some implementation mechanisms can be addressed at a local policy and practice level via improved training and support, system-wide action is needed to enable sustained delivery of preventative alcohol work in these settings. Peer Review reports Alcohol is now the leading risk factor for ill-health, early mortality, and disability amongst working age adults (aged 15 to 49) in England, and the fifth leading risk factor for ill-health across all age groups [ 1 ]. Evidence also shows significant socioeconomic inequalities in alcohol-related harm [ 2 ]. Over half of the one million hospital admissions relating to alcohol in England each year occur in the lowest three socioeconomic deciles [ 3 ] and rates of alcohol-related deaths increase with decreasing socioeconomic status [ 4 ]. In 2020 people under 75 years living in the most deprived areas in England had a 4.8 times greater likelihood of premature mortality from alcohol-related liver disease than those living in the most affluent areas [ 5 ]. Although globally, there is mixed evidence about the impact of the COVID-19 pandemic and associated social and economic restrictions on alcohol consumption [ 6 ], some studies suggest that people who were already drinking alcohol heavily increased their intake during this period [ 7 , 8 ]. Latest data for England show that the total number of deaths from conditions that were wholly attributed to alcohol rose by 20% in a single year in 2020, the largest increase on record [ 9 ]. In England, and elsewhere, it has been argued that COVID-19 should be regarded as a syndemic rather than a pandemic, as it has interacted with, and most adversely affected those in the most deprived social groups who were already experiencing the greatest inequalities [ 10 ]. In the case of alcohol use, COVID-19 may have interacted with and exacerbated the social conditions associated with alcohol use such as poverty, and loneliness and isolation [ 11 , 12 ]. Moreover, with evidence that alcohol-related harms will continue to increase, there is concern this will further widen health inequalities for those communities and regions who are likely to be most affected [ 8 , 13 ]. Thus, there is an urgent need for the implementation of evidence-based preventative strategies to reduce alcohol harm and associated inequalities, as part of a wider system level approach that includes primary, secondary and specialist care settings [ 8 ]. From here we use the term Alcohol Use Disorder (AUD), to refer to a spectrum of alcohol use from harmful to dependent alcohol use [ 14 ]. In secondary care hospitals, the UK government prioritised the implementation of Alcohol Care Teams (ACTs) in England in the National Health Service (NHS) Long Term Plan with the aim of improving care and reducing alcohol-related harms [ 15 ]. ACTs are clinician-led, multidisciplinary teams designed to support provision of integrated alcohol treatment pathways across primary, secondary and community care, and have been shown to reduce alcohol harms through reductions in avoidable bed days; readmissions; Accident and Emergency Department (AED) attendances; and ambulance call outs [ 16 ]. However, the non-specialist secondary care workforce also has an essential role in identifying and managing people at risk, using evidence-based approaches such as screening patients for excessive alcohol use and the provision brief advice [ 17 ]. Given that people may not always present primarily with alcohol-related concerns, routine screening provides an important opportunity to identify people at an earlier stage in their drinking and thereby prevent escalation of alcohol-related problems. Current NHS clinical guidance [ 18 ] requires that non-specialist healthcare staff ‘should be competent to identify harmful drinking (high-risk drinking) and alcohol dependence’ (p46). This includes having the skills to assess the need for an intervention or to provide an appropriate referral. Despite this guidance however, evidence from prior to the pandemic suggests a range of barriers exist in the delivery and widespread implementation of alcohol prevention work by non-specialist secondary care staff. These include time pressures, limited knowledge and awareness of AUD, and a lack of training, skills, and financial support [ 19 , 20 , 21 , 22 ]. Many studies also highlight that the delivery of preventative support for AUD in secondary care is hampered by wider social cultural challenges such as the stigma of heavy alcohol use and widespread belief that problematic alcohol use is a personal responsibility and represents moral failing, leading to an emphasis on individuals to manage their own care [ 22 ]. Additionally, as AUD frequently co-occurs with other physical and mental health conditions [ 23 ], non-specialist healthcare staff can find themselves ill-equipped to provide the best standard of care for these patients who have multiple and complex needs [ 24 ]. Moreover, in England, as in other health systems, the impact of COVID-19 has created additional pressures and challenges for the whole NHS, including secondary hospitals. There are more people visiting AED than before the pandemic, with longer waiting lists for treatment and fewer hospital beds [ 25 ]. There is also record dissatisfaction amongst the workforce, with more doctors now stating they want to leave the NHS than before the pandemic [ 26 ]. Given the clear need for preventive work to reduce inequalities in alcohol-related harm and the current challenges within secondary care in a post-COVID-19 context, there is value in exploring the views of secondary care staff about supporting patients with AUD since the pandemic. Moreover, the low levels of delivery of preventative support for AUD across different sites suggest there is merit in using implementation science theory [ 27 ] to support improved explanation and understanding of this situation [ 27 , 28 ]. Normalisation Process Theory [ 29 ] has been used extensively in studies conducted in other health settings to understand and evaluate past and future implementation efforts e.g. [ 28 , 30 , 31 , 48 , 33 ], including in relation to alcohol screening and brief intervention in England and Australia [ 30 , 31 ]. NPT is a sociological implementation theory that identifies three domains as shaping the implementation of a new intervention or practice: contexts; mechanisms; and outcomes. Contexts refer to the ‘events in systems unfolding over time within and between settings in which implementation work is done.’ [ 34 ]; mechanisms are factors that ‘motivate and shape the work that people do when they participate in implementation processes’ [ 34 ]; outcomes refer to what changes occur when interventions are implemented. NPT is a conceptual tool and can be used at different stages of the research process [ 29 ]. In this study NPT has been used retrospectively during the analysis stage. The aim of the present study is to use NPT to elucidate possible explanations for why the preventative practice of identifying, supporting, and referring patients with AUD to appropriate support is not consistently taking place in secondary care in the NENC in the post COVID-19 context. We also aim to make recommendations for areas that should be targeted by policy and practice initiatives. Study settingWe conducted a qualitative study with health care professionals working in eight secondary care hospitals in the eight NHS Trusts in the North East and North Cumbria (NENC) region of England. The NENC experiences significant health inequalities [ 35 ], including health inequalities in alcohol-related harm. In 2021, the region had the highest reported alcohol specific and alcohol related mortality and the most alcohol related and alcohol specific admissions in England [ 36 ]. The data collection was carried out between June and October 2021. At this time, most COVID-19 restrictions had just been lifted in the NENC [ 37 ] but the impacts of COVID-19 on patients, staff and health care delivery were still ongoing. As such, the study was planned to contribute to a baseline understanding of support for AUD in secondary care in the NENC conducted as part of a wider regional alcohol health needs assessment (2022) which would inform and direct strategic action and resource allocation in secondary care to improve alcohol-related outcomes post-COVID-19. The Principal Investigator (PI) for the study was the alcohol lead for the NENC Integrated Care System (SH), and the wider study team included representation from Primary Care, Secondary Care, Public Health, and Academia. We used the method of qualitative semi-structured interviews to enable us to focus on issues that we wanted to explore, as well as allowing the participants flexibility to discuss the issues that were important to them [ 38 ]. We adopted a critical realist approach to the interpretation of data which purports that data can be taken as evidence for ‘real phenomena and processes’, but also recognises that the knowledge generated through qualitative research is situated and partial [ 39 ]. As part of a wider ambition to build research capacity in the study region, a novel aspect of the study design is that six junior doctors from the Gastroenterology Research and Audit through North Trainees, were trained in qualitative interview skills by a qualitative methodologist from the NIHR Applied Research Collaboration (ARC) North East and North Cumbria (NENC) and supported by members of the study team to recruit staff and carry out the interviews with secondary care clinicians. ParticipantsWe used a form of stratified purposive sampling [ 40 ] as the recruitment of healthcare professionals was structured to provide insights across all the NHS Trusts in the study region, a range of clinical specialities, and a range of points across the clinical pathway, with both medical and nursing staff. As such, professionals working in AED, Medical specialties, Psychiatric Liaison (PL), Gastroenterology or Surgical specialties were eligible to participate. Junior doctor interviewers or the PI contacted potential participants either by email or face-to-face and explained the purpose of the study. People who expressed an interest were then provided with the study participant information sheet and consent form. The sampling was deemed complete when the quota of participants was met for each trust. Data collection involved semi-structured interviews based on a topic guide. The topic guide was developed by the study team and was informed by the National Institute for Clinical Excellence – Quality Standard 11 [ 41 ], which contains guidance about identifying and supporting adults and young people who may have an AUD and caring for people with alcohol-related health problems (see Additional file 1 ). All interviews were conducted via Microsoft Teams, lasted an average of 33 min, were audio recorded and transcribed by professional transcriptionists before being fully anonymised by KJ and IL. Data analysis involved three stages: Stage 1: Generating descriptive codes from each area of the data set In the first stage of analysis, once all transcripts were available, in order to generate insights that could contribute to the baseline understanding of the current situation with regards to support for AUD in secondary care, one researcher (IL) used a method of thematic analysis [ 42 ] and drew on deductive and inductive reasoning to identify descriptive codes against each focus question area of the interview topic guide. This researcher read and re-read the full data set, allowing them to identify descriptive codes across staff accounts. Stage 2: Generating descriptive and interpretive codes and themes from across the full data set Following this, to generate insights which went beyond the question areas of the topic guide a second researcher (KJ) familiarised themselves with the data. In contrast to Stage 1, they were less restricted by the original topic guide and through a process of constant comparison began to identify both descriptive and interpretive broad thematic topic areas and codes, across the different areas of the interviews. After the first half of the interview transcripts were coded by the researcher in this way, the broad thematic topic areas were discussed with the wider study team in two meetings. In these meetings the broad topic areas and associated coding framework were refined. This refined framework was applied to future transcripts, with flexibility to add further codes as the analysis progressed. At the end of this process, a decision was made by the team to focus the interpretation for this paper on current practices around identifying, supporting, and signposting patients with AUD in secondary care hospitals because it was felt that this focus could make a meaningful contribution to the existing literature in a post-pandemic context. Stage 3: Applying Normalisation Process Theory retrospectively to data to generate the final interpretation To ensure the usefulness of the findings of the current analysis to support the design and delivery of future policy and practice to reduce inequalities in alcohol related harm, academic members of the team suggested using an appropriate implementation theory, namely NPT, to guide our interpretation and understanding of data from this point in the analysis [ 34 ]. NPT had not been used in the study to this point and has been used retrospectively as a sensitising, and partial structuring, device, as seen in previous comparable research e.g. [ 28 , 43 ]. [ 29 , 34 ]. First, when applying NPT, we returned to the codes identified at Stage 2 to identify those that related to the practice of identifying, supporting, and signposting patients with AUD to explore how they may fit alongside the domains of NPT. At this point it was evident that most of the codes related to how implementation contexts and mechanisms were felt to adversely affect provision of support for patients with AUD. In contrast, we found negligible data related to the third NPT domain of outcomes (i.e. what changes occur when interventions are implemented). It was therefore agreed that applying the context and mechanisms domains could be valuable to show how contexts and mechanisms limit the implementation of the phenomena of interest. For transparency however, data not included at this stage is indicated in Additional file 2 . Next, we separated the codes generated in Stage 2 into overarching thematic areas, these were then labelled as either contexts or mechanisms. For example, poverty and austerity were labelled as contexts, and workforce skills and knowledge were labelled as mechanisms. Details of each stage of the analysis and where the codes generated at Stage 2 of the analysis were mapped, against the NPT context and mechanism domains are shown in Additional file 2 . Following this we endeavoured to align the thematic topic areas in each NPT domain into its associated constructs. It should be noted that our initial researcher-generated thematic areas aligned easily with three of the four NPT mechanism constructs. Conversely, as the NPT context constructs are a new addition to NPT theory, there were few practical examples of how these should be operationalised meaning it took more interpretive work to understand how our data mapped to these constructs. Through reflective discussions as a team, however, we identified that the researcher-generated themes aligned with three of the four context constructs. Table 1 below summarises the implementation context and mechanism constructs and identifies where our data do and do not map to these constructs. COVID-19 provides an overarching context to the study however as the timing of the interviews meant it penetrated almost all the data. In keeping with the critical realist approach which recognises the situatedness of knowledge, we see researcher positionality as important to consider in the interpretation of qualitative data. Research can never be value free but, it is necessary to be explicit about where positionality might have affected the interactions [ 45 ]. The junior doctor interviewers and the PI who collected the data had experience of clinical work on the topic of the research. Indeed, the transcripts indicated that there were times when the interviewers aligned themselves or discussed their own experiences in the interviews. Some of the junior doctor interviewers recorded reflexive notes about the interviews, these were used during Stages 1 and 2 of the analysis to support interpretation, but have not been used as data. The researcher who conducted Stage 1 of the analysis has a professional background in healthcare but no direct experience of the topic area. The researcher who led the rest of the analysis has experience of carrying out research about AUD, but no clinical experience of working with people experiencing AUD. Other members of the project team have direct experience of working in hospital settings with patients experiencing AUD. Agreement amongst this heterogeneous research team about the final interpretation gives us confidence that it is grounded in the data. Moreover, this agreement amongst the research team about the final interpretation, and the congruence of findings with the existing literature on the topic of the research prior to COVID-19, gives us confidence that the insider researchers did not compromise the quality of the original empirical data. In total, 30 staff in the study region were interviewed across the eight NHS Trusts, including 20 nurses and 10 doctors (see Table 2 ) based in five departments: AED; PL; Medical; Surgical; and Gastroenterology ( n = 6 each). Information related to participant gender and ethnicity are not available and we have not analysed the data with these as a focus. The absence of this data also helps to preserve the anonymity of participants because the geographical region of the study is named. Overall, participants’ accounts suggested that they were not consistently trying to identify AUD or assessing the need for intervention in the patients they worked with. Where any identification of AUD did take place, this appeared to often be through informal questioning rather than utilising formal, validated screening questionnaires. The following response was typical: We’ll just ask about units a week. I know that there is a screening tool, there is a chart of some sort and it’s a physical thing that I think the alcohol and drugs nurses use on medications. So we don’t use that on a regular basis. As of now, there’s still a paper–based documenting system, but we don’t use that necessarily. (Participant 14 – Doctor, Trust 4, AED) Conversely, some staff working in PL teams suggested they more commonly tried to identify AUD. Although again, validated screening questionnaires appeared to be used inconsistently: Substance misuse is always an integral part of the assessment that we do. . We do have specific packs that we are trained to carry out our assessments to. I think in practice, we often don’t follow those verbatim and we will just do a free form assessment and substances are always part of that… .: “Do you consider that’s an issue for you, is it something that you want help with?” We’re always having those conversations. (Participant 8 – Nurse, Trust 2, PL) Many staff’s accounts suggested they did not consistently signpost patients with identified AUD to a service that could provide an assessment of need or provide further care. Using NPT to frame our interpretation, in the next section we aim to highlight current practice around these phenomena and identify areas that appeared to be key barriers to implementation. Implementation contextsThe successful implementation of interventions requires supportive implementation environments both within and outside the settings in which they are delivered. Our data highlighted several key aspects of the implementation context/s that are barriers to the widespread implementation of asking about, supporting, and signposting patients with AUD in secondary care in the study region. As the data collection was conducted very soon after COVID-19 restrictions ended, COVID-19 was an overarching context of the staffs’ accounts. Widespread poverty, austerity, and the prioritisation of acute conditions – negotiating capacityNegotiating capacity refers to how contexts shape the extent to which interventions can fit into existing ways of working [ 34 ]. Through the participants’ accounts we identified two aspects of context which appear to limit negotiating capacity: widespread poverty and austerity within the study region; and the focus of secondary care hospitals on the acute and presenting health needs of patients. Most staff accounts suggested they perceived AUD to be common in the communities their hospitals covered and the patients they saw. Many staff linked the prevalence of AUD in the region to the high rates of poverty. To illustrate, Participant 23 commented that the basic provision for patients with AUD in the hospital, was in stark contrast to the apparent need in the community: The demographic for around here, people are poor, they do drink, people do smoke,. . people take drugs a lot around here and the help, there isn’t [anything for them] it’s absolutely crazy. (Participant 23 - Nurse, Trust 6, Surgical) While the need to support patients with AUD was perceived to have been high prior to the COVID-19 pandemic, many staff noted that they had seen a rise in patients presenting with or showing signs of AUD following the pandemic, with some suggesting that they felt that the presentations of alcohol-related morbidity and mortality were likely to increase in the future: Our numbers [of patients with AUD] have gone up by 100% in five years. . So it’s not going anywhere, and I predict that at the beginning of next year we’re going to see huge influence on alcoholic dependence. Because we’ve already seen people who are having fits, first fits, people who were drinking prior to COVID or probably drinking too much, at high risk, not necessarily dependent and then, furloughed, have begun to drink every day and developed alcohol dependence. (Participant 25 - Nurse, Trust 7, Gastroenterology) A small number of participants mentioned that because of the observed high levels of AUD in the study region it was harder to decide how to prioritise who to ask about alcohol. They indicated that they were unlikely to ask patients about alcohol if they were drinking at what they saw as lower levels, as they perceived most people were drinking a lot. For example, Participant 7 said: If they were a binge drinker or they drank more than was recommended, it’s kind of like, where do you take that? How do I talk to my patients about that? Thinking about where we live, our demographic of the type of patients that we see, it’s very common that patients would drink more alcohol than the recommended. So, I guess that is the challenge of how you would approach that to the patient, without coming across like you were being judgmental or self-righteous when you’re trying to give them this advice. And actually asking them; ‘do you even see it as a problem?’ A lot of patients that you would speak to you wouldn’t even say that that is a problem. (Participant 7 - Nurse, Trust 2, Surgical) Thus, these accounts indicated that the normalisation and prevalence of heavy drinking in some communities actively constrained the extent to which staff could integrate asking about and supporting patients with alcohol use into their day to day work . Conversely, and illustrating how contexts can be barriers to implementation in one setting but facilitate it in others [ 44 ], some staff working in PL described how they had recently begun doing more systematic screening for AUD because it was recognised as being so prevalent in the patients they saw. [Previously] unless alcohol was kind of front and centre and was an issue that was discussed from the get-go, it wasn’t always something that was really looked into in great detail as part of our assessments. Whereas now that we do the AUDIT, there’s an AUDIT-C tool with all patients. (Participant 4 – Nurse, Trust 1, PL) Nonetheless, staff accounts more commonly focused on the need to tackle severe alcohol harm rather than preventative work. In-keeping with other research studies and clinical knowledge, the participants’ suggested that a key reason that patients aren’t routinely being asked about AUD in secondary care is because staff need to prioritise the presenting acute condition/s. Something which is colloquially termed ‘the rule of rescue’. Thus, any identification of AUD, where it did happen, was primarily focused on managing patients whose alcohol use was already affecting, or had the potential to affect, the treatment of their acute physical or mental illness. Participants almost always linked this to the pressurised setting and the restricted time they had to work with patients, as further limiting their capacity to address a patient’s drinking. This context is illustrated in the following quotes: ‘I’m asking [about alcohol] because it effects how I care for that patient and not necessarily about educating them’ (Participant 15 – Doctor, Trust 4, Medical). . .I think asking about the preventative problems, and screening for problems, is something that we just don’t do. If someone comes in and they’re alcohol dependent, realistically the thing you think about most is, right well we need to make sure that we’ve got the right things for if they withdraw, you don’t think, oh well shall we see if there’s anything we can do and to be fair, you don’t really have the time, I don’t think. (Participant 6 - Doctor, Trust 2, AED) Overall, time and the focus on acute conditions, were commonly cited by staff as key contextual factors, that limited their negotiating capacity to ask patients about alcohol and to provide follow-up support. Stigma at a structural level – strategic intentionsStrategic intentions refers to how contexts shape the formulation and planning of interventions. Many staff accounts suggested that they perceived there was little visible commitment to the prevention of AUD within their NHS trust or at a national NHS level. Many staff suggested they had seen no communications about providing preventative support to patients with AUD from their trust: There’s nothing to my knowledge, Trust–wide, of how we help this cohort of patients. There doesn’t seem to be anything written in stone, on the help that we provide. (Participant 21 – Nurse, Trust 6, AED) Others emphasised that although they had seen some communications about alcohol from their trust, these were limited. Some participants’ accounts indicated a sense of frustration that alcohol was not being prioritised by the NHS and moreover that any care offered to patients with AUD was voluntary rather than a designated part of their core work. For example, in one trust it was noted that the role of the Alcohol Lead was not formalised: At the moment it’s almost voluntary and there’s always something else that comes along that’s more immediate, more important or seems that way. People aren’t taking the longer view that if we don’t address this problem now then the tsunami of liver disease will just continue. (Participant 10 - Doctor, Trust 3, Gastroenterology) Relational stigma – reframing organisational logicReframing organisational logic refers to the extent to which social structural and social cognitive resources shape the implementation environment [ 34 ]. The stigma which was evident at a structural level was also directly perceived to impact the care of patients with AUD at a relational level. Many staff mentioned that the identification of AUD and subsequent signposting for patients who drink heavily are obstructed because some staff perceive that heavy alcohol use is a personal failing and individual problem. Indeed, judgement or stigma was explicitly proposed by participants as one of the key reasons that AUD prevention and treatment interventions were not implemented, or attempts weren’t made to help people with AUD: People find them incredibly frustrating and [like] they’re not real patients or people who need [help]. (Participant 4 - Nurse, Trust 4, PL) This judgement was also seen to be compounded by austerity and the increased demands on health and social care post COVID-19, meaning those who were more challenging or difficult to help were often the easiest group to not manage. Relational stigma appeared evident in the reluctance of some staff to speak to patients about alcohol. For example, a few participants expressed concern about how patients would respond if they were to ask them about their alcohol use because heavy alcohol consumption can sometimes be perceived by patients and wider society as a personal failing or as evidence of a lack of control: It’s quite a personal conversation to have with somebody and you’ve got a small thin curtain between every single patient and having those conversations when everybody hears the conversation that you have in the bay, so I think that sometimes contributes to it. (Participant 24 – Nurse, Trust 7, Medicine) Moreover, the effects of stigma seemed evident in the extent to which staff perceived people would be honest about or disclose their heavy drinking and the extent to which would subsequently make adaptions to investigate further. Some staff said that they did not have the time to build rapport with patients to generate a context where they perceived patients might be more likely to be truthful about their drinking: It comes down to them being honest. If they say that they don’t drink a lot then we wouldn’t give any advice. (Participant 26 – Nurse, Trust 7, Surgical) The data also suggests that the extent to which staff appeared willing to identify or support patients with AUD is related to them not seeing it as relevant to the presenting problem which relates to the prioritisation of acute conditions and the negotiating capacity. Implementation mechanismsAlongside contexts, we identified a number of mechanisms that appeared to be barriers to implementation across our participants’ accounts. Workforce knowledge and skills – cognitive participationAll participants’ accounts suggested that there was no mandatory training within trusts to support staff to deliver alcohol prevention work. While participants acknowledged there was indeed very little mandatory training about most conditions, many staff suggested they had not been trained post-University in how to have conversations with patients about alcohol, to assess need, or how to refer and signpost on: . . we’ve got team days where we go through mandatory training and do little courses and do all our training, but there’s nothing about alcohol on there whereas it might be quite useful because we do get a lot of patients with alcohol issues so that would be beneficial. . we’ve had no training or updates on what’s out there in the community. (Participant 9 – Nurse, Trust 2, Medical) In a small number of trusts, some staff with a specific remit around alcohol stated they were in the process of developing training about identification within their teams and appeared optimistic about the spread and impact of this. Where staff did ask about alcohol, a barrier to referring people with AUD to appropriate services was their limited awareness of relevant services within the community. Indeed, a few participants conveyed the sentiment of Participant 11 who described their perception of asking about alcohol in their hospital as a ‘ tick box exercise rather than purposeful tool .’ (Nurse, Trust 3, Medical). Only a small number of participants seemed very knowledgeable about local community services; like Participant 9 above, most staff accounts suggested a lack of awareness of relevant organisations they could refer patients to. Some staff indicated that knowledge of appropriate services was made more challenging because of the frequent change in service provision and cuts and short-term commissioning of relevant voluntary and community sector services: It is a bit vague at the moment as to exactly what they are going to do with the provider changing over. . when the Covid stuff started, they stopped coming in and just did electronic stuff. But I think they’ve started coming in again. But I don’t quite know what hours they are planning to come in, with the new changeover of people. (Participant 1 – Doctor, Trust 1, Gastroenterology) In a context of frequent service changeovers and decommissioning, widespread poverty and austerity, and limited awareness of appropriate local services, there appeared to be a heavy reliance on referrals to primary care by staff, even when they didn’t know what primary care would offer patients. This is illustrated by this quote from Participant 15: Sometimes if people ask me, or if I’ve found that they’ve got like deranged liver functions, I’ll often just sort of say to them, if it fits with an alcohol picture, I would say: “It does look like your alcohol use is affecting your liver, it might be something you think about cutting down,” but at that point I’m not always sure where to refer them to, so I usually end up saying you can get support from your GP. Yes. (Participant 15 – Doctor, Trust 4, Medical) Role legitimacy – collective actionWhen asked directly in the interviews about whether they felt that managing AUD was their responsibility most participants stated that it was. However, their wider accounts indicated that many participants and their colleagues relied heavily on calling on staff in other departments to manage patients with AUD who they saw as better placed to address these patients’ needs. In particular, the participants commonly suggested that alcohol nurses or other staff in gastroenterology were most able to help: In our trust, I’m not sure if it’s the same as any others, when we do the nurse’s admission, we ask how many units they’ve had and if they score over ten then they automatically get pinged to the alcohol nurses who will come and see them. Or we refer them and call the alcohol nurses here. . (Participant 28 – Nurse, Trust 8, AED) Staff in the site where an ACT had recently been set-up suggested that the introduction of this service had significantly improved the care that they could offer people with visible presentations of AUD and provided a clearer route for signposting. However, the reliance on this service also served to illustrate the limited support prior to this in these sites and the significant care gap at other sites who did not have this provision. Moreover, the accounts of a few participants suggested that due to the high level of need for alcohol dependent support, the ACTs appeared to have little capacity to do preventative work: The alcohol care team nurses are building up good relationships with some of our more frequent members that are coming on ward. And then they’re able to get permission off them to do more like referrals to [community alcohol service], discussions about tapering down or alcohol reduction therapy, discussions about cognitive behavioural therapies, discussions with housing officers and things, discussions with safeguarding. . having said that, like I say they are getting an abundance of referrals daily now and I think unfortunately it’s ended up a lot bigger than they were expecting, a bit of a mammoth task. (Participant 2 – Nurse, Trust 1, Medical) In contrast to staff in other departments, as mentioned above, staff from PL teams suggested that identifying patients’ patterns of alcohol use, usually through formalised screening, had relatively recently become part of their core work. Nonetheless, the focus was still on management of AUD rather than prevention, as most indicated that the implementation of this was in response to the prevalence of heavy drinking in the patients they saw. Here the mechanism of collective action appears to be shaped by the context of poverty and austerity. Perceived futility and negative feedback cycle – reflexive monitoringParticipants’ accounts indicated that they had little information about the outcomes of the people that they saw with AUD. Some staff mentioned that the only time they saw patients again, whether or not they delivered an intervention, was when they re-attended. The following response was typical: We put them on file with the GP letter, and we don’t know what happens after that. (Participant 26 – Nurse, Trust 7, Surgical) In the context of this perceived futility, staff appeared to find it difficult to have hope for patients when they experienced only negative reinforcement. Compounding this it was also evident that the recording of information about alcohol use and any advice or signposting were limited in most departments. Although some PL services and some trusts seemed to be trying to record screening more systematically at the time of the research, it was still not mandatory and was not always prioritised as the following quote illustrates: [We] have the AUDIT -C put on e-records, and that provided some challenges as well. . there’s a lot of things that are recorded, you get a lot of alerts, we know that. . staff just tap off them, if they’re not mandatory, So, it was about trying to sell it is an important message. (Participant 25 - Nurse, Trust 7, Gastroenterology) Here again we see the link between contexts and mechanisms whereby the lack of systematic recording of patients’ alcohol use is likely to be influenced by the context of structural stigma and its impact on strategic intentions. This paper reports the findings of a collaborative study between practitioners, policy makers, and academics which aimed to explore the challenges to the delivery of identification, support, and subsequent signposting for AUD in the secondary care settings in the NENC region post- COVID-19. Our findings broadly concur with what was already known about the challenges of implementing identification and support for AUD in secondary care hospitals prior to the COVID-19 pandemic. For example, the persistent contextual challenge of time pressures, and the lack of key enabling mechanisms, such as having a workforce with the skills and knowledge to confidently ask about alcohol and signpost patients appropriately [ 22 ]. However, our findings extend existing evidence by highlighting some additional barriers to alcohol prevention work in secondary care in the post-COVID-19 context. Moreover, the use of theory, specifically NPT domains, enables us to illuminate the interplay of context and mechanisms which make implementation of AUD care especially difficult in this setting. A key contribution of this study to the extant literature is that it provides empirical evidence of how COVID-19 has served to amplify the challenges already experienced by secondary care staff trying to delivery preventative alcohol work in hospital settings. Many staff indicated that the sheer scale of people presenting with possible AUD since COVID-19, meant they did not have the time to ask people or to prioritise asking people about alcohol. Where people were identified as experiencing AUD, provision of effective signposting and support for patients was adversely affected by lack of staff awareness about relevant care providers and lack of capacity in local services due to the impact of austerity and cuts to public services. Two trusts in the study region had ACTs in place at the time of the interviews, as part of the wider NHS commitment to reduction alcohol harm in England [ 16 ]. This appeared to have increased the capacity of the non-specialist workforce at these two sites to refer patients identified as experiencing AUD onto appropriate specialist support. However, a tentative, but notable, finding of this study was that while ACTs were making a difference in these trusts for those with existing alcohol dependence, they were limited in their capacity to deliver more preventative work around AUD (initially part of their remit) due to the high level of need amongst the dependent patient population. This warrants further exploration, with further insights potentially to come via the wider programme of work around ACTs that is currently ongoing in England [ 46 ]. Overall, the study provides empirical evidence that the implementation of the preventative practices to support a reduction in AUD may be particularly difficult in areas of deprivation such as the NENC meaning that inequalities are likely to be widening with other more affluent regions. Stigma, the process of marking certain groups as being somehow contagious or of less value than others [ 47 ], is internationally recognised as a significant constraining factor to the delivery of compassionate and appropriate healthcare for patients with AUD and other substance use in secondary care and other health and social care settings [ 47 , 48 ]. In this study we chose to approach stigma as a structural and relational concept, seeing relational stigma as developing from structural stigma [ 49 ]. The role of structural stigma for limiting the implementation of identifying, supporting, and signposting patients with AUD was striking, as our data highlighted that the prevention of heavy alcohol use does not appear to be a visible priority within individual trusts, and arguably the wider NHS. Limited resources were perceived available for this area of care, and little visible commitment to support patients with AUD despite the scale of the problem. Stigma was also evident at a relational level in our participants accounts of the interactions between staff and patients, notably staff’s reluctance to ask about alcohol use and their perception that patients did not want to disclose their AUD. However, it should be noted that many of the staff who took part in the study suggested that they did not perceive patients in this way yet continued to struggle to provide alcohol prevention care. Thus, this relational stigma is likely an important, but only partial explanation for limited care provision. Nonetheless, our findings suggest that structural stigma is one of the main barriers to the identification of alcohol use and care in secondary care settings in the NENC. This echoes the damning findings of the ‘Remeasuring the Units’ report, also published since the pandemic, that argued that stigma contributes to the missed opportunities in secondary care for patients who ultimately die from alcohol-related liver disease [ 5 ]. This study was conducted primarily as a vehicle to understand and bring about change in workforce practice around the prevention of alcohol harm in NENC secondary care services. It was an integral component of a broader Health Care Needs Assessment (2022) on alcohol undertaken in response to increasing levels of alcohol harm in this region of the UK, which led to recommendations over four overarching themes: service delivery; workforce; data; and leadership from the healthcare system. The results of the study have directly shaped the regional strategy for the reduction of alcohol harm, a key element of which is the integrated alcohol workforce strategy for the NENC which aims to better support the NHS workforce to prevent alcohol harm through: increased awareness of the Chief Medical Officer alcohol guidance; improved pathways to community-based alcohol treatment and recovery support; workforce training and development; and support for staff to address their own drinking. The evidence highlighting the importance of stigma have additionally led to a strategic drive for senior leaders to acknowledge the impact alcohol has on their organisation and the communities they serve, and to take action to work in partnership to reduce this. There is also cross-system support to tackle relational stigma, initially though a co-ordinated multi-agency media campaign. Overall, our interpretation has signalled areas of policy and practice which can be targeted to try to increase the uptake of these preventive strategies in the secondary care settings. However, ultimately the findings illustrate that the challenge for implementation of these evidence based preventative measures is not just upskilling the workforce or increasing resources. It also indicates that we need to address the complex interplay of contextual factors and implementation mechanisms which have been compounded by the pandemic and contribute to reinforcing and increasing existing inequalities. The works contributes to calls for a multi-layered response to reducing alcohol harm and wider cultural change for how alcohol use and substance use is perceived. Study strengths and limitationsA strength of the study is that it was undertaken in an area experiencing some of the greatest inequalities from the COVID-19 pandemic. This allowed us to see the challenges to delivering preventative work in these contexts, which might be similar in other regions. A further strength is that mapping the empirical data onto an evidence-based implementation theory, which has been widely use in different settings, enabled us to focus on the aspects of the implementation, that are likely to be important across other settings too. Framing the interpretation using the NPT domains has helped us to emphasise how contexts and mechanisms interact to make the implementation at this particular time and place difficult. A key limitation of the study is that as it was based in one region of England, we cannot know for sure if these insights are transferrable beyond this context. Secondary care hospitals are an important setting for the delivery of preventative care for AUD, due to the frequency with which AUD co-occurs with other physical and mental health conditions. Prior to the pandemic there was evidence that non-specialist healthcare staff can find caring for patients with alcohol-related presentations difficult, meaning that identifying, supporting, and that signposting patients was happening inconsistently. In this study, we highlight the additional challenges facing secondary care staff due to post-pandemic pressures and the significant rise in alcohol-related harm in some regions such as the NENC. Thus, whilst the mechanisms for implementing alcohol prevention work in secondary care need attention, our findings suggest that the greatest barrier is contextual, including widespread structural stigma. Data availabilityNo datasets were generated or analysed during the current study. AbbreviationsNormalisation Process Theory Alcohol Care Teams North East and North Cumbria Alcohol Use Disorder Accident and Emergency Department Psychiatric Liaison Teams Alcohol Use Disorders Identification Test Alcohol Use Disorders Identification Test Consumption Burton R, Henn C, Lavoie D, O’Connor R, Perkins C, Sweeney K et al. The public health burden of alcohol and the effectiveness and cost-effectiveness of alcohol control policies: an evidence review. 2016. Boyd J, Bambra C, Purshouse RC, Holmes J. Beyond behaviour: how health inequality theory can enhance our understanding of the ‘alcohol-harm paradox’. Int J Environ Res Public Health. 2021;18(11):6025. Article PubMed PubMed Central Google Scholar NHS Digital. Statistics on Alcohol, England 2020 2020 [ https://digital.nhs.uk/data-and-information/publications/statistical/statistics-on-alcohol/2020 . Angus C, Pryce R, Holmes J, de Vocht F, Hickman M, Meier P, et al. Assessing the contribution of alcohol-specific causes to socio‐economic inequalities in mortality in England and Wales 2001–16. Addiction. 2020;115(12):2268–79. The National Confidential Enquiry into Patient Outcome and Death. REMEASURING THE UNITS An update on the organisation of alcohol-related liver disease services. 2022. Kilian C, O’Donnell A, Potapova N, López-Pelayo H, Schulte B, Miquel L, et al. Changes in alcohol use during the COVID‐19 pandemic in Europe: a meta‐analysis of observational studies. Drug Alcohol Rev. 2022;41(4):918–31. Garnett C, Jackson S, Oldham M, Brown J, Steptoe A, Fancourt D. Factors associated with drinking behaviour during COVID-19 social distancing and lockdown among adults in the UK. Drug Alcohol Depend. 2021;219:108461. Article CAS PubMed PubMed Central Google Scholar Boniface S, Card-Gowers J, Martin A, Retat L, Webber L. The COVID hangover: addressing long-term health impacts of changes in alcohol consumption during the pandemic. London: The Institute of Alcohol Studies; 2022. Google Scholar National Audit Office. Alcohol treatment services: A briefing by the National Audit Office. 2023. Horton R, Offline. COVID-19 is not a pandemic. Lancet. 2020;396(10255):874. Tucker JS, Rodriguez A, Green HD Jr, Pollard MS. Trajectories of alcohol use and problems during the COVID-19 pandemic: the role of social stressors and drinking motives for men and women. Drug Alcohol Depend. 2022;232:109285. Broadbent P, Thomson R, Kopasker D, McCartney G, Meier P, Richiardi M et al. The public health implications of the cost-of-living crisis: outlining mechanisms and modelling consequences. Lancet Reg Health – Europe. 2023;27. Angus C, Henney M, Pryce R. Modelling the impact of changes in alcohol consumption during the COVID-19 pandemic on future alcohol-related harm in England. The University of Sheffield. Report. The University of Sheffield.;; 2022. National Institute for Health and Clinical Excellence. Alcohol-use disorders: diagnosis, assessment and management of harmful drinking and alcohol dependence. 2011. NHS England. The NHS Long Term Plan 2019. Moriarty KJ. Alcohol care teams: where are we now? Frontline Gastroenterol. 2020;11(4):293–302. Article PubMed Google Scholar Kaner E, Beyer FR, Muirhead C, Campbell F, Pienaar ED, Bertholet N et al. Effectiveness of brief alcohol interventions in primary care populations. 2018. Rep No.: 1465–858 Contract 2. National Institute for Health and Care Excellence. Alcohol-use disorders: diagnosis, assessment and management of harmful drinking (high-risk drinking) and alcohol dependence. CG115 ed2011. Cryer HG. Barriers to interventions for alcohol problems in trauma centers. J Trauma Acute Care Surg. 2005;59(3):S104–11. Article Google Scholar Johnson M, Jackson R, Guillaume L, Meier P, Goyder E. Barriers and facilitators to implementing screening and brief intervention for alcohol misuse: a systematic review of qualitative evidence. J Public Health. 2011;33(3):412–21. Article CAS Google Scholar Subhani M, Elleray R, Bethea J, Morling JR, Ryder SD. Alcohol-related liver disease mortality and missed opportunities in secondary care: a United Kingdom retrospective observational study. Drug Alcohol Rev. 2022;41(6):1331–40. Gargaritano KL, Murphy C, Auyeung AB, Doyle F. Systematic Review of Clinician-Reported Barriers to Provision of Brief Advice for Alcohol Intake in Hospital Inpatient and Emergency Settings. Alcoholism: Clinical and Experimental Research. 2020;44(12):2386 – 400. Gomez KU, McBride O, Roberts E, Angus C, Keyes K, Drummond C, et al. The clustering of physical health conditions and associations with co-occurring mental health problems and problematic alcohol use: a cross-sectional study. BMC Psychiatry. 2023;23(1):89. Roberts E, Drummond C, British Medical. Journal Opinion. 2019. [05/10/23]. https://blogs.bmj.com/bmj/2019/07/30/alcohol-related-hospital-admissions-locking-door-horse-bolted/ . Baker C. NHS key statistics: England - Summary: NHS pressures before and after the Covid-19 pandemic. 2023. General Medical Council. The State of Medical Education and Practice in the UK, 2021. General Medical Council. 2021. Report No.: 0901458813. Nilsen P. Making sense of implementation theories, models, and frameworks. Implement Sci. 2020;30:53–79. Bamford C, Poole M, Brittain K, Chew-Graham C, Fox C, Iliffe S, et al. Understanding the challenges to implementing case management for people with dementia in primary care in England: a qualitative study using normalization process theory. BMC Health Serv Res. 2014;14(1):1–12. May C, Rapley T, Mair FS, Treweek S, Murray E, Ballini L et al. Normalization Process Theory On-line Users’ Manual, Toolkit and NoMAD instrument 2015 [ https://normalization-process-theory.northumbria.ac.uk/how-do-you-use-npt/qualitative-research/ . O’Donnell A, Kaner E. Are brief alcohol interventions adequately embedded in UK Primary Care? A qualitative study utilising normalisation process theory. Int J Environ Res Public Health. 2017;14(4):350. Sturgiss E, Advocat J, Lam T, Nielsen S, Ball L, Gunatillaka N, et al. Multifaceted intervention to increase the delivery of alcohol brief interventions in primary care: a mixed-methods process analysis. Br J Gen Pract. 2023;73(735):e778–88. McEvoy R, Ballini L, Maltoni S, O’Donnell CA, Mair FS, MacFarlane A. A qualitative systematic review of studies using the normalization process theory to research implementation processes. Implement Sci. 2014;9:1–13. Huddlestone L, Turner J, Eborall H, Hudson N, Davies M, Martin G. Application of normalisation process theory in understanding implementation processes in primary care settings in the UK: a systematic review. BMC Fam Pract. 2020;21:1–16. May CR, Albers B, Bracher M, Finch TL, Gilbert A, Girling M, et al. Translational framework for implementation evaluation and research: a normalisation process theory coding manual for qualitative research and instrument development. Implement Sci. 2022;17(1):1–15. Munford L, Bambra C, Davies H, Pickett K, Taylor-Robinson D. Health Equity North: 2023. Newcastle; 2023. Office for Health Improvement & Disparities. Official statistics: local alcohol profiles for England: short statistical commentary.; 2023 01/12/23. Government If. Timeline of UK government coronavirus lockdowns and measures, March 2020 to December 2021 2024 [ https://www.instituteforgovernment.org.uk/sites/default/files/2022-12/timeline-coronavirus-lockdown-december-2021.pdf . Edwards R, Holland J. What is qualitative interviewing? Bloomsbury Academic; 2013. Maxwell JA. Collecting qualitative data: A realist approach. The SAGE handbook of qualitative data collection. 2018:19–32. Patton MQ. Qualitative research and evaluation methods. Thousand Oaks: SAGE; 2002. National Institute for Health and Care Excellence. Alcohol-use disorders: diagnosis and management - Quality Standard 11. 2011. Fugard A, Potts H. Thematic analysis: Sage; 2020. Stevenson F. The use of electronic patient records for medical research: conflicts and contradictions. BMC Health Serv Res. 2015;15(1):1–8. May CR, Johnson M, Finch T. Implementation, context and complexity. Implement Sci. 2016;11(1):1–12. Malterud K. Qualitative research: standards, challenges, and guidelines. Lancet. 2001;358(9280):483–8. Article CAS PubMed Google Scholar National Institute for Health and Care Research. Programme of Research for Alcohol Care Teams: Impact, Value and Effectiveness (ProACTIVE) 2022 [ https://fundingawards.nihr.ac.uk/award/NIHR152084 . Addison M, McGovern W, McGovern R. Drugs, identity and stigma: Springer; 2022. Room R. Stigma, social inequality and alcohol and drug use. Drug Alcohol Rev. 2005;24(2):143–55. Hatzenbuehler ML, Link BG. Introduction to the special issue on structural stigma and health. Elsevier; 2014. pp. 1–6. Download references AcknowledgementsIn addition to co-authors WH and RB we are grateful to the four junior doctors Jamie Catlow, Rebecca Dunn, Sarah Manning and Satyasheel Ramful from the Gastroenterology Research and Audit through North Trainees who collected data for the study. We are grateful to Dr Matthew Breckons the qualitative methodologist who co-trained (with AOD and KJ) the junior doctors in qualitative interview skills. We are especially grateful to the thirty staff who gave up their time to participate in the research. The project was funded by the North East and North Cumbria Integrated Care System Prevention Programme. AO is Deputy Theme Lead – Prevention, Early Intervention and Behaviour Change within the NIHR Applied Research Collaboration (ARC) North East and North Cumbria (NENC) (NIHR200173). The views expressed are those of the author(s) and not necessarily those of the NIHR or the Department of Health and Social Care. AO and KJ are also part-funded by a NIHR Advanced Fellowship (ADEPT: Alcohol use disorder and DEpression Prevention and Treatment, Grant: NIHR300616). The NIHR have not had any role in the design, implementation, analysis, write-up and/or dissemination of this research. Author informationAuthors and affiliations. Newcastle University, Newcastle upon Tyne, UK Katherine Jackson & Amy O’Donnell North Tees and Hartlepool NHS Hospitals Foundation Trust, Stockton on Tees, UK Rosie Baker North East Commissioning Service, Newcastle upon Tyne, UK Iain Loughran Norfolk and Norwich University Hospitals NHS Foundation Trust, Norwich, UK William Hartrey North East and North Cumbria Integrated Care Board, Newcastle upon Tyne, UK Sarah Hulse You can also search for this author in PubMed Google Scholar ContributionsSH and RB designed the study; SH, RB and WH were involved in the data collection; IL and KJ analysed and interpreted the data with support from AOD, SH, RB and WH; KJ drafted the manuscript with support from SH, AOD, RB, IL and WH. All authors approved the submitted version. Corresponding authorCorrespondence to Katherine Jackson . Ethics declarationsEthics approval and consent to participate. Favourable ethical approval was granted for the study by the NHS HRA (Ref: 21/HRA/1383). All research was carried in accordance with the study protocol that was granted ethical approval. All participants gave written informed consent to participate through the study participant consent form. Consent for publicationParticipants gave written informed consent in the study consent form for their data to be analysed and included in research reports. Competing interestsThe authors declare no competing interests. Additional informationPublisher’s note. Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations. Electronic supplementary materialBelow is the link to the electronic supplementary material. Supplementary Material 1Supplementary material 2, rights and permissions. Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data. Reprints and permissions About this articleCite this article. Jackson, K., Baker, R., O’Donnell, A. et al. Understanding the challenges of identifying, supporting, and signposting patients with alcohol use disorder in secondary care hospitals, post COVID-19: a qualitative analysis from the North East and North Cumbria, England. BMC Health Serv Res 24 , 772 (2024). https://doi.org/10.1186/s12913-024-11232-4 Download citation Received : 18 December 2023 Accepted : 21 June 2024 Published : 01 July 2024 DOI : https://doi.org/10.1186/s12913-024-11232-4 Share this articleAnyone you share the following link with will be able to read this content: Sorry, a shareable link is not currently available for this article. Provided by the Springer Nature SharedIt content-sharing initiative
BMC Health Services ResearchISSN: 1472-6963
NTRS - NASA Technical Reports ServerFilter results, collections, top results, subject category, distribution. Macrophage-derived CD36 + exosome subpopulations as novel biomarkers of Candida albicans infection
Invasive candidiasis (IC) is a notable healthcare-associated fungal infection, characterized by high morbidity, mortality, and substantial treatment costs. Candida albicans emerges as a principal pathogen in this context. Recent academic advancements have shed light on the critical role of exosomes in key biological processes, such as immune responses and antigen presentation. This burgeoning body of research underscores the potential of exosomes in the realm of medical diagnostics and therapeutics, particularly in relation to fungal infections like IC. The exploration of exosomal functions in the pathophysiology of IC not only enhances our understanding of the disease but also opens new avenues for innovative therapeutic interventions. In this investigation, we focus on exosomes (Exos) secreted by macrophages, both uninfected and those infected with C. albicans. Our objective is to extract and analyze these exosomes, delving into the nuances of their protein compositions and subgroups. To achieve this, we employ an innovative technique known as Proximity Barcoding Assay (PBA). This methodology is pivotal in our quest to identify novel biological targets, which could significantly enhance the diagnostic and therapeutic approaches for C. albicans infection. The comparative analysis of exosomal contents from these two distinct cellular states promises to yield insightful data, potentially leading to breakthroughs in understanding and treating this invasive fungal infection. In our study, we analyzed differentially expressed proteins in exosomes from macrophages and C. albicans -infected macrophages, focusing on proteins such as ACE2, CD36, CAV1, LAMP2, CD27, and MPO. We also examined exosome subpopulations, finding a dominant expression of MPO in the most prevalent subgroup, and a distinct expression of CD36 in cluster14. These findings are crucial for understanding the host response to C. albicans and may inform targeted diagnostic and therapeutic approaches. Our study leads us to infer that MPO and CD36 proteins may play roles in the immune escape mechanisms of C. albicans. Additionally, the CD36 exosome subpopulations, identified through our analysis, could serve as potential biomarkers and therapeutic targets for C. albicans infection. This insight opens new avenues for understanding the infection's pathology and developing targeted treatments.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
VIDEO
COMMENTS
For long or complex papers, sometimes only one of several findings is the focus of the presentation. Of course, presentations for other audiences may be constructed differently, with greater attention to interesting elements of the data and findings as well as implications and less to the literature review and methods. Concluding Your Work
CHAPTER FOUR. DATA ANALYSIS AND PRESENTATION OF RES EARCH FINDINGS 4.1 Introduction. The chapter contains presentation, analysis and dis cussion of the data collected by the researcher. during the ...
DATA PRESENTATION, ANALYSIS AND INTERPRETATION. 4.0 Introduction. This chapter is concerned with data pres entation, of the findings obtained through the study. The. findings are presented in ...
Choose your chart types: The first step is to select the right chart type for your data based on the type of question asked. No one chart fits all types of data. Choose a chart that clearly displays each of your data points ' stories in the most appropriate way. Column/bar graphs: Great for comparing categories.
A method of data analysis that is the umbrella term for engineering metrics and insights for additional value, direction, and context. By using exploratory statistical evaluation, data mining aims to identify dependencies, relations, patterns, and trends to generate advanced knowledge.
In this post, I will discuss the three pertinent components a good presentation of qualitative findings should have. They are; background information, data analysis process and main findings. Figure 1. Presentation of findings. Presenting background information. Participants' past and current situations influence the information they provide ...
TheJoelTruth. While a good presentation has data, data alone doesn't guarantee a good presentation. It's all about how that data is presented. The quickest way to confuse your audience is by ...
7.1 Sections of the Presentation. When preparing your slides, you need to ensure that you have a clear roadmap. You have a limited time to explain the context of your study, your results, and the main takeaways. Thus, you need to be organized and efficient when deciding what material will be included in the slides.
Overview. Data analysis is an ongoing process that should occur throughout your research project. Suitable data-analysis methods must be selected when you write your research proposal. The nature of your data (i.e. quantitative or qualitative) will be influenced by your research design and purpose. The data will also influence the analysis ...
Here are 10 data presentation tips to effectively communicate with executives, senior managers, marketing managers, and other stakeholders. 1. Choose a Communication Style. Every data professional has a different way of presenting data to their audience. Some people like to tell stories with data, illustrating solutions to existing and ...
Data analysis and findings. Data analysis is the most crucial part of any research. Data analysis summarizes collected data. ... A clear and concise presentation on the 'now what' and 'so what' of data collection and analysis - compiled and originally presented by Cori Wielenga. Online Resources.
This chapter provided an introduction to the use of tables and graphs for the presentation of quantitative research findings. These should present data in a valid, clear and possibly attractive way to the audience and in a way that addresses their uncertainty and reading habits. In many cases, this means that relatively simple tables and graphs ...
9 Presenting the Results of Quantitative Analysis . Mikaila Mariel Lemonik Arthur. This chapter provides an overview of how to present the results of quantitative analysis, in particular how to create effective tables for displaying quantitative results and how to write quantitative research papers that effectively communicate the methods used and findings of quantitative analysis.
Presenting the findings • Only make claims that your data can support • The best way to present your findings depends on the audience, the purpose, and the data gathering and analysis undertaken ... Theory are theoretical frameworks to support data analysis •Presentation of the findings should not overstate the evidence.
4.3 Findings from Interview Data The qualitative data in this study comprises interviews and open-ended items in the questionnaire. In this section I discuss the findings from the interviews beginning with the response rates of chosen participants, moving to the emerging themes from the respondents' answers to questions posed to them.
12.3 Visual display and presentation of the data. Visual display and presentation of data is especially important for transparent reporting in reviews without meta-analysis, and should be considered irrespective of whether synthesis is undertaken (see Table 12.2.a for a summary of plots associated with each synthesis method). Tables and plots ...
In a dissertation, data analysis is crucial as it directly influences the validity and reliability of your findings. The scope of data analysis includes data collection, data cleaning, statistical analysis, and interpretation of results. ... Link your data presentation directly to your interpretation. Use visual aids to illustrate key points ...
chapter, data is interpreted in a descriptive form. This chapter comprises the analysis, presentation and interpretation of the findings resulting from this study. The analysis and interpretation of data is carried out in two phases. The first part, which is based on the results of the questionnaire, deals with a quantitative analysis of data.
According to Kothari (2004), Factor analysis is a s tatistical data reduction and analysis technique. that strives to explain correlations among multiple outcomes as the result of one or more ...
Data presentation involves presenting the data in a clear and concise way to communicate the research findings. In this article, we will discuss the techniques for data analysis, interpretation, and presentation. 1. Data Analysis Techniques. Data analysis techniques involve processing and analyzing the data to derive meaningful insights.
The data supporting the findings of this study will be available from the corresponding author upon reasonable request. References van den Berg, B. et al. Guillain-Barré syndrome: Pathogenesis ...
In the multivariable regression analysis which included only 323 participants with complete data on all the variables, "starting lipid-lowering drug treatment during follow-up" and "returning to normal BMI during follow-up" were statistically significantly associated with remission of hypertension.
To ensure the usefulness of the findings of the current analysis to support the design and delivery of future policy and practice to reduce inequalities in alcohol related harm, academic members of the team suggested using an appropriate implementation theory, namely NPT, to guide our interpretation and understanding of data from this point in ...
There's still plenty of time left in 2024 for GPs to see a reversal of their fortunes. Check out our mid-year review on the VC industry with our First Look data packs for the Q2 2024 PitchBook-NVCA Venture Monitor, Q2 2024 European Venture Report, and Global Venture Capital dataset.
This chapter focuses on data presentation, data analysis and discussion. The data was obtained. by CRDB in budgeting. position (job title) at CRDB in Arusha,T anzania. stage or degree of mental or ...
LIMITATIONS: Limitations of the study include the following: 1) a large number of case reports or small series, 2) a meta-analysis of proportions with no statistical comparison with a control group, and 3) the lack of access to patient-level data. CONCLUSIONS: Our findings suggest that double stent retriever thrombectomy may be safe and ...
NTRS - NASA Technical Reports Server. Search. more_vert
Objective Neonatal endotracheal intubation is a lifesaving but technically difficult procedure, particularly for inexperienced operators. This secondary analysis in a subgroup of inexperienced operators of the Stabilization with nasal High flow during Intubation of NEonates randomised trial aimed to identify the factors associated with successful intubation on the first attempt without ...
DATA PRESENTATION, ANALYSIS A ND DISCUSSION OF FINDINGS. 4.1 Introduction. This section gives a detailed description of the data collected for the st udy and t he procedure used to. analyse the ...
The comparative analysis of exosomal contents from these two distinct cellular states promises to yield insightful data, potentially leading to breakthroughs in understanding and treating this invasive fungal infection. ... These findings are crucial for understanding the host response to C. albicans and may inform targeted diagnostic and ...